
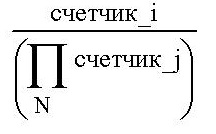










{kind=link}
Для начала рассмотрим общий вид запроса, в котором присутствуют две (или более) таблицы. Первый вариант:
SELECT
Таблица1.*,
Таблица2.*
FROM Таблица1, Таблица2
Второй вариант (по итогу этот вариант аналогичен первому):
SELECT
*
FROM Таблица1
LEFT JOIN Таблица2
ON Таблица1.ПолеСоединения = Таблица2.ПолеСоединения
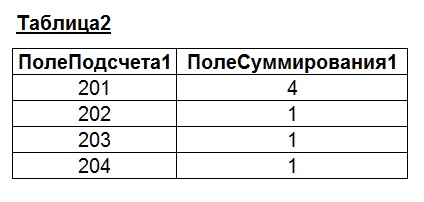
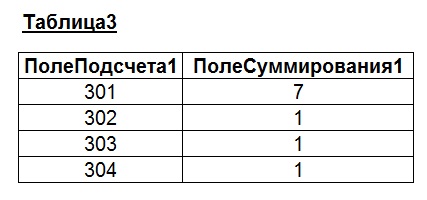
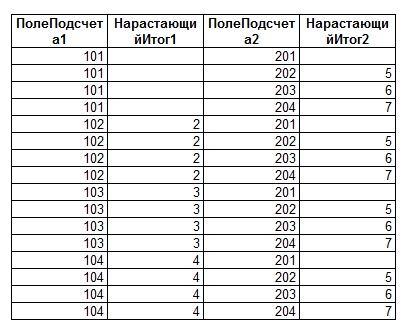
Примем, что в качестве «Таблицы1» и «Таблицы2» используются таблицы со следующей структурой и значениями:


В наши цели входит одновременное вычисление «нарастающего итога» для этих двух таблиц одновременно, в рамках одного запроса. Напишем подобный запрос:
SELECT
Таблица11.ПолеПодсчета1,
SUM( Таблица12.ПолеСуммирования1 ) AS СуммаПредПолей1,
Таблица21.ПолеПодсчета2,
SUM( Таблица22.ПолеСуммирования2 ) AS СуммаПредПолей2
FROM Таблица1 AS Таблица11
LEFT JOIN Таблица1 AS Таблица12
ON Таблица11.ПолеПодсчета1 > Таблица12.ПолеПодсчета1,
Таблица2 AS Таблица21
LEFT JOIN Таблица2 AS Таблица22
ON Таблица21.ПолеПодсчета2 > Таблица22.ПолеПодсчета2
GROUP BY Таблица11.ПолеПодсчета1, Таблица21.ПолеПодсчета2
На самом деле в этом запросе отсутствует вычисление самого «нарастающего итога» и есть только вычисление суммы по всем предыдущим значениям суммируемой колонки. Однако, как известно, «нарастающий итог» может быть получен простым суммированием суммы по предыдущим значениям суммируемой колонки и текущим значением для этой колонки. Для простоты первоначально сосредоточимся на главной составляющей «нарастающего итога» - сумме по всем предыдущим значениям суммируемой колонки.
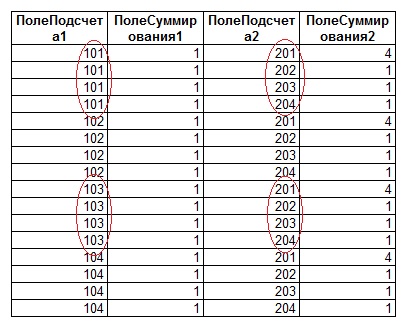
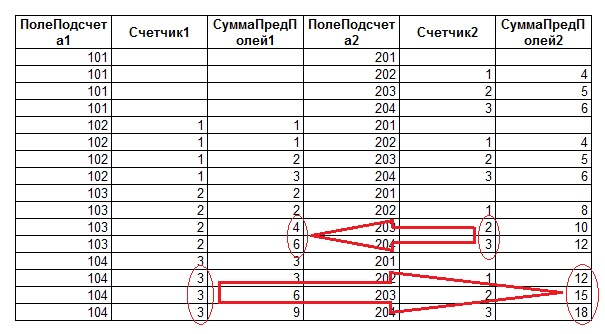
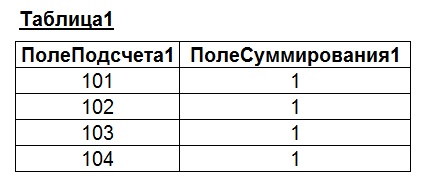
Итак, после применения приведенного выше запроса получаем следующую выходную таблицу:
Значения в «Таблице1» и «Таблице2» подобраны так, чтобы при вычислении сумм давать последовательные значения (2, 3, 4 и т.д.). Однако, как можно заметить из последнего рисунка, значения не всегда соответствуют ожидаемым (см. выделенные области на рисунке). Для пояснения причин подобных «ошибок суммирования» приведем результат запроса к «Таблице1» и «Таблице2» без группировки значений и подсчета сумм:
SELECT
Таблица1.*,
Таблица2.*
FROM Таблица1, Таблица2
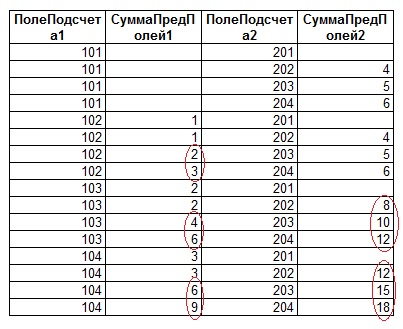
Как можно заметить, в полученной таблице для каждой строки из «Таблицы1» присутствуют все строки из «Таблицы2». Следовательно строки как из «Таблицы1», так и из «Таблицы2» просто повторяются, что и приводит в свою очередь к «неправильному суммированию».
Для решения проблемы «неправильного суммирования» выполним следующий запрос:
SELECT
Таблица11.ПолеПодсчета1,
COUNT( DISTINCT Таблица12.ПолеПодсчета1 ) AS Счетчик1,
SUM( Таблица12.ПолеСуммирования1 ) AS СуммаПредПолей1,
Таблица21.ПолеПодсчета2,
COUNT( DISTINCT Таблица22.ПолеПодсчета2 ) AS Счетчик2,
SUM( Таблица22.ПолеСуммирования2 ) AS СуммаПредПолей2
FROM Таблица1 AS Таблица11
LEFT JOIN Таблица1 AS Таблица12
ON Таблица11.ПолеПодсчета1 > Таблица12.ПолеПодсчета1,
Таблица2 AS Таблица21
LEFT JOIN Таблица2 AS Таблица22
ON Таблица21.ПолеПодсчета2 > Таблица22.ПолеПодсчета2
GROUP BY Таблица11.ПолеПодсчета1, Таблица21.ПолеПодсчета2
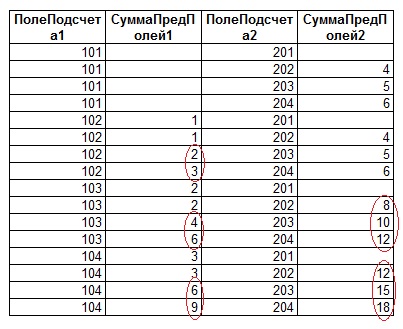
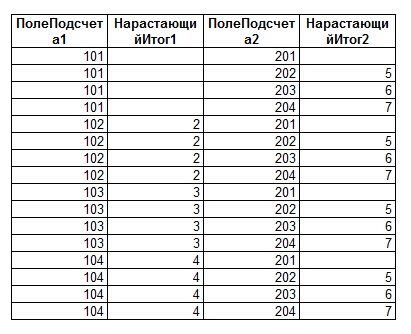
В результате выполнения данного запроса получим следующий результирующий набор:
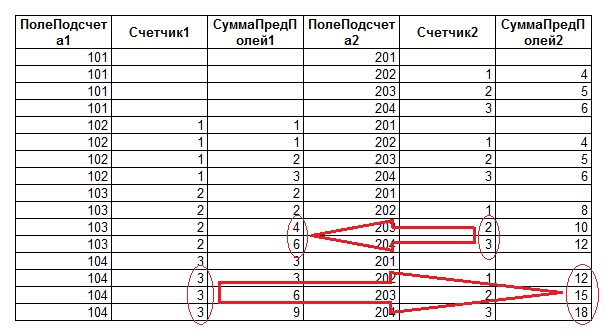
Как можно видеть из рисунка, имеется прямая связь между значениями счётчиков, и просуммированными значениями - суммированные значения превышают правильные данные ровно в то количество раз, которое и является значением соответствующего счётчика. Таким образом, правильное значение для сумм предыдущих значений суммируемой колонки можно получить, разделив первично вычисленное значение суммы на величину соответствующего счётчика. Один нюанс - счетчик может принимать значение «0», и в запросе следует предусмотреть этот вариант.
Запишем правильный запрос для вычисления полноценного «нарастающего итога» для двух различных таблиц:
SELECT
Таблица11.ПолеПодсчета1,
SUM( Таблица12.ПолеСуммирования1 )
/
CASE
WHEN
COUNT( DISTINCT Таблица22.ПолеПодсчета2 ) = 0
THEN
1
ELSE
COUNT( DISTINCT Таблица22.ПолеПодсчета2 )
END + MAX( Таблица11.ПолеСуммирования1 ) AS НарастающийИтог1,
Таблица21.ПолеПодсчета2,
SUM( Таблица22.ПолеСуммирования2 )
/
CASE
WHEN
COUNT( DISTINCT Таблица12.ПолеПодсчета1 ) = 0
THEN
1
ELSE
COUNT( DISTINCT Таблица12.ПолеПодсчета1 )
END + MAX( Таблица21.ПолеСуммирования2 ) AS НарастающийИтог2
FROM Таблица1 AS Таблица11
LEFT JOIN Таблица1 AS Таблица12
ON Таблица11.ПолеПодсчета1 > Таблица12.ПолеПодсчета1,
Таблица2 AS Таблица21
LEFT JOIN Таблица2 AS Таблица22
ON Таблица21.ПолеПодсчета2 > Таблица22.ПолеПодсчета2
GROUP BY Таблица11.ПолеПодсчета1, Таблица21.ПолеПодсчета2
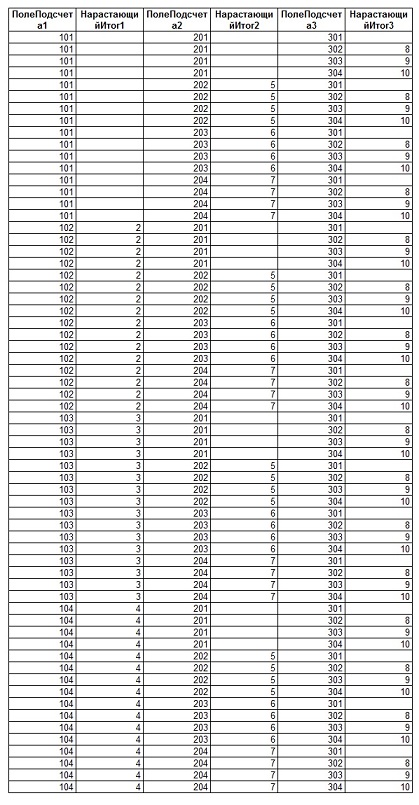
Теперь добавим в запрос третью таблицу со следующими значениями:

Опять выполним запрос, в котором будут объединены все три таблицы и будут присутствовать нужные нам значения счётчиков:
SELECT
Таблица11.ПолеПодсчета1,
COUNT( DISTINCT Таблица12.ПолеПодсчета1 ) AS Счетчик1,
SUM( Таблица12.ПолеСуммирования1 ) AS СуммаПредпПолей1,
Таблица21.ПолеПодсчета2,
COUNT( DISTINCT Таблица22.ПолеПодсчета2 ) AS Счетчик2,
SUM( Таблица22.ПолеСуммирования2 ) AS СммаПредпПолей2,
Таблица31.ПолеПодсчета3,
COUNT( DISTINCT Таблица32.ПолеПодсчета3 ) AS Счетчик3,
SUM( Таблица32.ПолеСуммирования3 ) AS СуммаПредпПолей3
FROM Таблица1 AS Таблица11
LEFT JOIN Таблица1 AS Таблица12
ON Таблица11.ПолеПодсчета1 > Таблица12.ПолеПодсчета1,
Таблица2 AS Таблица21
LEFT JOIN Таблица2 AS Таблица22
ON Таблица21.ПолеПодсчета2 > Таблица22.ПолеПодсчета2,
Таблица3 AS Таблица31
LEFT JOIN Таблица3 AS Таблица32
ON Таблица31.ПолеПодсчета3 > Таблица32.ПолеПодсчета3
GROUP BY Таблица11.ПолеПодсчета1, Таблица21.ПолеПодсчета2, Таблица31.ПолеПодсчета3
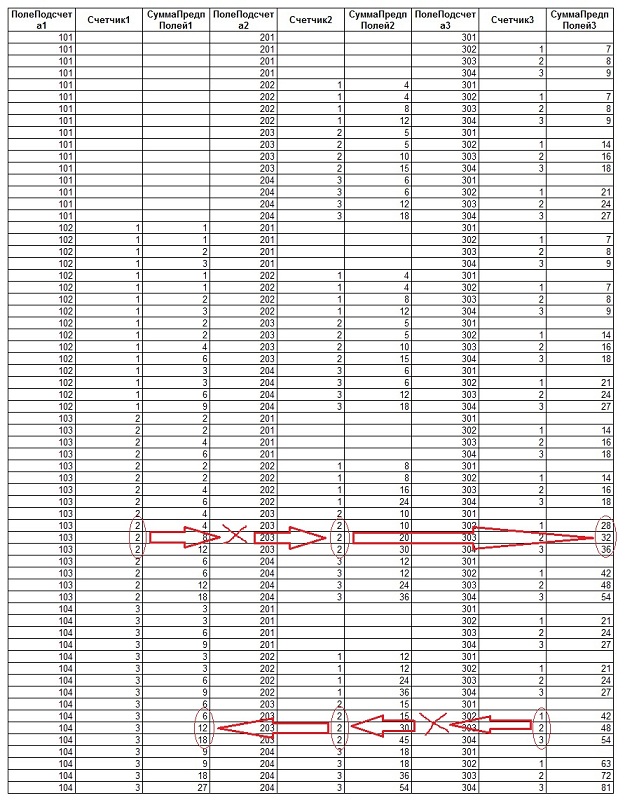
Как можно заметить, для получения правильных значений сумм необходимо деление не просто на значение для одного счётчика, а на их произведение.
Приведем запрос, позволяющий вычислить «нарастающие итоги» для трех таблиц одновременно:
SELECT
Таблица11.ПолеПодсчета1,
SUM( Таблица12.ПолеСуммирования1 )
/
(
CASE
WHEN
COUNT( DISTINCT Таблица22.ПолеПодсчета2 ) = 0
THEN
1
ELSE
COUNT( DISTINCT Таблица22.ПолеПодсчета2 )
END
*
CASE
WHEN
COUNT( DISTINCT Таблица32.ПолеПодсчета3 ) = 0
THEN
1
ELSE
COUNT( DISTINCT Таблица32.ПолеПодсчета3 )
END
) + MAX( Таблица11.ПолеСуммирования1 ) AS НарастающийИтог1,
Таблица21.ПолеПодсчета2,
SUM( Таблица22.ПолеСуммирования2 )
/
(
CASE
WHEN
COUNT( DISTINCT Таблица12.ПолеПодсчета1 ) = 0
THEN
1
ELSE
COUNT( DISTINCT Таблица12.ПолеПодсчета1 )
END
*
CASE
WHEN
COUNT( DISTINCT Таблица32.ПолеПодсчета3 ) = 0
THEN
1
ELSE
COUNT( DISTINCT Таблица32.ПолеПодсчета3 )
END
) + MAX( Таблица21.ПолеСуммирования2 ) AS НарастающийИтог2,
Таблица31.ПолеПодсчета3,
SUM( Таблица32.ПолеСуммирования3 )
/
(
CASE
WHEN
COUNT( DISTINCT Таблица12.ПолеПодсчета1 ) = 0
THEN
1
ELSE
COUNT( DISTINCT Таблица12.ПолеПодсчета1 )
END
*
CASE
WHEN
COUNT( DISTINCT Таблица22.ПолеПодсчета2 ) = 0
THEN
1
ELSE
COUNT( DISTINCT Таблица22.ПолеПодсчета2 )
END
) + MAX( Таблица31.ПолеСуммирования3 ) AS НарастающийИтог3
FROM Таблица1 AS Таблица11
LEFT JOIN Таблица1 AS Таблица12
ON Таблица11.ПолеПодсчета1 > Таблица12.ПолеПодсчета1,
Таблица2 AS Таблица21
LEFT JOIN Таблица2 AS Таблица22
ON Таблица21.ПолеПодсчета2 > Таблица22.ПолеПодсчета2,
Таблица3 AS Таблица31
LEFT JOIN Таблица3 AS Таблица32
ON Таблица31.ПолеПодсчета3 > Таблица32.ПолеПодсчета3
GROUP BY Таблица11.ПолеПодсчета1, Таблица21.ПолеПодсчета2, Таблица31.ПолеПодсчета3
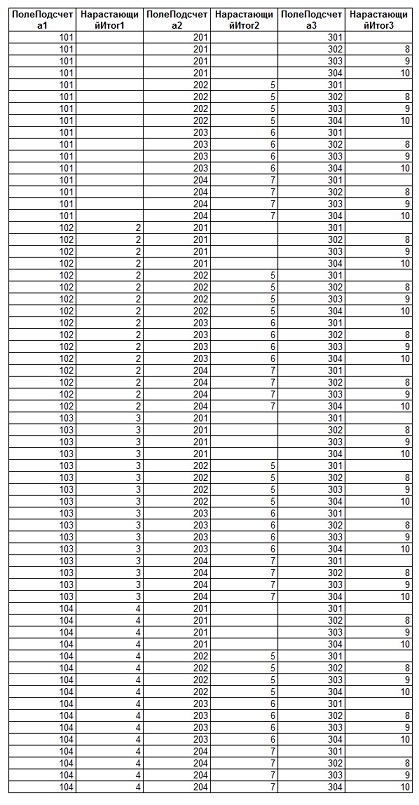
В общем случае, когда число соединяемых таблиц в одном запросе равно N, в качестве делителя для сумм следует использовать произведение счетчиков для всех других таблиц. В общем случае множитель для сумм таблицы с номером «i» будет выражаться формулой:
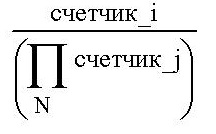
С уважением,
Юрий Строжевский
Вступайте в нашу телеграмм-группу Инфостарт