


Думаю, что Python не нуждается в представлении, а вот про R возможно кто-то и не слышал. Если коротко, то данные ЯП обладают огромным количеством свободно распространяемых библиотек на все случаи жизни, и поддержка их сервером MS SQL, на мой взгляд, предоставляет разработчикам новые возможности, особенно в части работы с big data, статистикой, анализом данных и т.п. В данной статье будут описаны только начальные принципы использования связки 1С-SQL-R. В дальнейшем, возможно, доберемся и до Python, но R, на данный момент, я знаю гораздо лучше и поэтому все примеры будут именно на данном языке.
1. Установка и настройка необходимых программ
Для начала необходимо установить SQL server с необходимыми дополнениями. На установке подробно останавливаться смысла нет, все стандартно и подробно расписано в msdn. С поддержкой R от MS не все прозрачно - для применения непосредственно из SQL нам нужна версия R in-database server. Имеются ещё варианты standalone - отдельной установки сервера machine learning и просто дистрибутив R open. У каждого продукта свое предназначение, свои версии R, свои пути установки - тут важно не запутаться и следить, например, за тем из под какой версии R и куда вы устанавливаете дополнительные пакеты.
После установки идем в SSMS, где включаем возможность выполнения внешних сценариев.
EXEC sp_configure 'external scripts enabled', 1
Рестартуем SQL server и проверяем, что все сделали правильно
EXEC sp_execute_external_script @language = N'R',
@script = N'
OutputDataSet <- InputDataSet;',
@input_data_1 = N'SELECT 1 AS hello'
WITH RESULT SETS (([hello] int not null));
GO
Результат должен быть следующим:

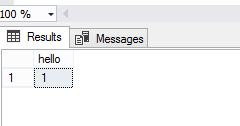
Общие принципы написания external_script: указываем, что хотим выполнить внешний скрипт, указываем язык скрипта, задаем сам текст, передаем набор данных, параметры, задаем имя выходного набора данных, типизируем и именуем выходные данные. С виду тоже все просто, но тут уже будут разные тонкости и нюансы.
Переходим к практике.
2. Постановка тестовой задачи
Выше уже я описал в качестве большого плюса R огромное количество библиотек. Так же у R имеется простая и удобная IDE R Studio. Считаю ее не заменимым и почти идеальным инструментом, хотя для наших задач будет достаточно стандартной консоли R.
Задача не сложная - для теста с некоторыми допущениями и условностями: предположим имеется УТ 11.х и справочник номенклатуры. Требуется загрузить в базу большое количество новой номенклатуры из какого-либо внешнего источника данных, при этом определить наличие пересечений по наименованию или просто найти и сопоставить свою номенклатуру с номенклатурой поставщика. Попробуем реализовать это с помощью R и MS SQL.
Задача сводится к обработке двух таблиц данных, для упрощения допустим следующую структуру:
Искомые данные - два столбца: код или порядковый номер (целочисленный, не отрицательный) и наименование товара (строка). В дальнейшем типы будут важны, т.к. будем писать все в таблицу БД
Каталог номенклатуры для поиска - код, имя, описание, вид номенклатуры: типы кода, имя и описания соответствуют типам MS SQL для справочника номенклатуры 1С, а вид номенклатуры пусть будет выведен строкой (для упрощения, т.к. если хотим иметь ссылку, то придется передавать в скрипт строку, а в обратном направлении преобразовывать обратно в varbinary).
Конечно данную задачу можно решить в самой 1С, написав определенный алгоритм, но мы не ищем простых путей, к тому же в 1С алгоритмы сверки строк будут гораздо медленнее.
Перейдем к написанию и объяснению кода на R. При этом целью не является обучение языку и это абсолютно не возможно в рамках одной статьи, но основы постараюсь расписать и код прокомментировать подробно.
Сначала нам надо установить дополнительные пакеты, packages, ибо без них использование R теряет смысл. Открываем Rgui, который находится где-то в районе [Program Files]\Microsoft SQL Server\[НазваниеВашегоЭкземпляраСервераСкуль]\R_SERVICES\bin\[ВашаРазрядность]\Rgui.exe (можно открыть R Studio с настройками применения данного экземпляра R) и вводим следующий код:
install.packages(c("dplyr", "stringdist"))
Таким нехитрым образом мы установили два пакета: dplyr, без которого ну просто никуда, используется для работы с типом data.frame (в переводе на язык 1С - таблица значений), и stringdist, в котором имеются различные метрики для сверки строк.
Проверим список установленных пакетов
EXECUTE sp_execute_external_script
@language=N'R'
,@script = N'str(OutputDataSet);
packagematrix <- installed.packages();
OutputDataSet <- as.data.frame(packagematrix[, 1]);'
,@input_data_1 = N'SELECT 1 as col'
WITH RESULT SETS ((PackageName nvarchar(250)))
Тут мы получаем список установленных пакетов встроенной функцией R. Эта функция возвращает объект класса matrix из которого нас интересует первая колонка. Вернуть нам надо таблицу данных типа data.frame, поэтому используем соответствующую функцию преобразования в данный тип. В последней строке с помощью конструкции WITH RESULT SETS мы типизируем и именуем колонки полученного из внешнего скрипта результата (это не обязательно, но для дальнейшей работы с результатом незаменимо да и просто не красиво в продакшне)
Для тех, кто мало знаком с R ещё один примерчик: вот тут мы получим таблицу данных с двумя колонками. Функция с() в примере формирует вектор строкового типа с названиями нужных нам колонок.
EXECUTE sp_execute_external_script
@language = N'R'
,@script = N'str(OutputDataSet);
packagematrix <- installed.packages();
OutputDataSet <- as.data.frame(packagematrix[, c("Package", "Version")]);'
WITH RESULT SETS ((PackageName nvarchar(250), PackageVersion nvarchar(20)))
Увидим ожидаемый вывод:
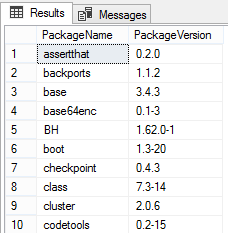
Если все работает и виден результат, то можно переходить к следующей части.
3. Запросы SQL
Все наверняка знают, что прямые запросы к СУБД в 1С не приветствуются и об этом явно говорится в лицензионном соглашении. Поэтому все что тут описано сделано в исследовательских целях и конечно же повторять это не рекомендуется.
Итак составим простейший прямой запрос к справочнику номенклатуры. Прямой запрос составляем кто как привык - через стандартную консоль запросов или руками, глядя в описание структуры хранения СУБД или же через профайлер MS SQL.
SELECT Items._Code AS Code
,Items._Description AS Name
,Items._Fld5586 AS Description
,Kind._Description AS Kind
,NULL AS ItemName
,0 AS ItemNum
FROM [ut_demo].[dbo].[_Reference215] AS Items
LEFT JOIN [ut_demo].[dbo]._Reference76 AS Kind
ON Items._Fld5567RRef = Kind._IDRRef
Получим таблицу с наименованием и кодом номенклатуры, ее описанием, и наименованием вида номенклатуры (просто для дополнительной информации)
4. Скрипты на R, sp_execute_external_script
Необходимо немного рассказать о принципах написания скрипта. Вот простейший пример, иллюстрирующий основы. Комментарии прилагаются.
DECLARE @par1 int = 2, @par2 int = 3 -- Добавляем переменные со значениями 1 и 2
EXECUTE sp_execute_external_script -- Объявляем начало внешнего исполняемого скрипта
@language=N'R' -- Указываем язык скрипта
,@script = N' # А тут уже комментарии на R
q1 <- Q_in[1,1] # Это исходные данные, всегда типа data.frame
# В данном примере получаем значение первой ячейки таблицы
q2 <- q_1; # А это первый входной параметр
q3 <- q_2; # А это второй
QQ <- data.frame(Q = c(q1, q2, q3)); # Составили список и привели его к типу data.frame, и возвращаем из скрипта результат
'
,@input_data_1 = N'SELECT 1 as col' -- Передаем в скрипт результат этого сложнейшего запроса
,@input_data_1_name = N'Q_in' -- Задаем наименование по которому будем обращаться в скрипте за входными данными
,@output_data_1_name = N'QQ' -- Задаем наименование для возвращаемых из скрипта данных
,@params = N'@q_1 int, @q_2 int' -- Задаем наименования параметров, в данном примере их два
,@q_1 = @par1 -- Значение первого параметра
,@q_2 = @par2 -- Значение второго параметра
WITH RESULT SETS ((Q int)) -- Тип и наименования результата
При решении подобной задачи возникает вопрос: нам же надо сравнивать одну таблицу (наименования товаров) с данными, полученными на прошлом этапе прямым запросом. Как нам передать в скрипт наши искомые данные? Поиск в интернете дает следующий ответ: пока никак. И цифра 1 в "input_data_1" никого не должна вводить в заблуждение, т.к. "input_data_2" не существует, так же как и не существует всех последующих "input_data_N". Конечно это неприятность, но маленькая. Вариантов обойти эту проблему несколько. В случае небольших наборов искомых данных вполне можно передать строковой параметр, например записать данные в формат json, с которым R прекрасно дружит (пакет jsonlite). Можно подключаться из самого R к базе данных (т.е. внутри скрипта), что, на первый взгляд, не совсем красиво выглядит и требует отдельного изучения.
В рассмотренном примере мы пошли другим путем и выбираем примитивное решение - создаем служебную таблицу, в которую записываем искомые данные. И затем объединяем с таблицей номенклатуры. И эти объединенные данные передаем в скрипт для обработки. Возможно это получится реализовать более элегантно, с помощью временных таблиц, но в рамках задачи для примера было решено сохранять искомые данные физически для определенных манипуляций по параллельным задачам и для тестирования. Так что просто запомним, что можно попробовать оптимизировать данную часть и уйти от хранения по сути лишних данных в физической таблице.
Подготовим базу данных и таблицу для хранения сравниваемой номенклатуры.
Запрос на создание служебной таблицы примерно такой
CREATE TABLE [integration].[dbo].[itemstofind](
[id] [int] NOT NULL IDENTITY(1,1),
[ItemName] [nvarchar](100) NULL,
[ItemNum] [int] NULL,
[Value] [int] NULL,
[Code] [nchar](11) NULL,
[Name] [nvarchar](100) NULL,
[Description] [nvarchar](1024) NULL,
[Kind] [nvarchar](100) NULL
CONSTRAINT PK_ID PRIMARY KEY(id)
)
4. Алгоритм поиска строк
Для поиска строк будет использоваться пакет stringdist. У данного не большого пакета есть несколько вариантов определения похожести строк. После некоторых тестов была выбрана метрика Жаро-Винклера
На R это будет выглядеть так:
stringdist("MARTHA", "MARHTA", method = 'jw', p = 0.1)
Первые два параметра - две строки, или строка и список строк, для определения "степени похожести". Вторым параметром указываем, что нам нужна именно метрика Жаро-Винклера. p - служебный параметр самого алгоритма. Схожесть в реализации алгоритма на R для одинаковых слов равна 0, для различных стремится к 1 (в алгоритме на вики наоборот)
Примеры:
> stringdist("MARTHA", "MARHTA", method = 'jw', p = 0.1)
[1] 0.03888889
> stringdist("DWAYNE", "DUANE", method = 'jw', p = 0.1)
[1] 0.16
Метод регистрозависим:
> stringdist("dWAYNE", "DUANE", method = 'jw', p = 0.1)
[1] 0.3
> stringdist("dWaYne", "DUANE", method = 'jw', p = 0.1)
[1] 1
5. Реализация через хранимые процедуры
Используем stored procedures в MS SQL для удобства использования алгоритма.
USE [integration]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[CompareItems]
@quant int
AS
BEGIN
EXEC
sp_execute_external_script
@language = N'R'
, @script = N'
# Подключаем библиотеки
library(dplyr);
library(stringdist);
# Функция, для получения q минимальных совпадений с искомой строкой
get.res <- function(items.list, items.cat, q){
cat.names <- items.cat$Name;
item.name <- items.list[1];
item.num <- items.list[2];
# Функция сравнения "похожести" строк
m <- stringdist(items.list[1], as.character(items.cat$Name), method = "jw", p = 0.1);
# Приводим результат к чистому виду, удаляем мусор, сортируем
res <- as.data.frame(cbind(m, items.cat)) %>%
rename(Value = m) %>%
filter(tolower(Value)!="inf"&!is.na(Value)&!is.infinite(Value)) %>%
mutate(ItemName = item.name, ItemNum = item.num) %>%
arrange(Value);
# Возвращаем первые q строк
head(res, q)
}
# Формируем объект для поиска из входных данных
i.list <- items_cat %>%
filter(ItemNum > 0) %>%
select(ItemName, ItemNum) %>%
mutate(ItemName = tolower(as.character(ItemName)))
# Формируем данные среди которых происходит поиск
i.cat <- items_cat %>%
filter(ItemNum == 0) %>%
select(Code, Name, Description, Kind) %>%
mutate(Name = tolower(as.character(Name)))
# Для каждой строки датафрэйма искомых данных применяем функцию поиска
mres <- apply(i.list, 1, get.res, items.cat = i.cat, q = quant)
# Соединяем полученные результаты для возврата из скрипта
OutputDataSet <- do.call("rbind", mres);'
, @input_data_1 = N'
SELECT Items._Code AS Code
,Items._Description AS Name
,Items._Fld5586 AS Description
,Kind._Description AS Kind
,NULL AS ItemName
,0 AS ItemNum
FROM ut_demo.dbo._Reference215 AS Items
LEFT JOIN ut_demo.dbo._Reference76 AS Kind
ON Items._Fld5567RRef = Kind._IDRRef
UNION ALL
SELECT Code, Name, Description, Kind, ItemName, ItemNum FROM integration.dbo.itemstofind;'
, @input_data_1_name = N'items_cat'
, @output_data_1_name = N'OutputDataSet'
, @params = N'@quant int'
, @quant = @quant
WITH RESULT SETS ((Value real, Code [nchar](11), Name [nvarchar](100), Description [nvarchar](1024), Kind [nvarchar](100), ItemName [nvarchar](100), ItemNum int));
END
Комментарии добавил в сам код на R
В SQL quant - параметр, количество записей, наиболее близких по алгоритму распознавания, которые мы хотим получить по каждой строке поиска.
Заполним тестовые данные для поиска

Проверим работоспособность запросом в SQL
DECLARE @return_value int
EXEC @return_value = [dbo].[CompareItems]
@quant = 5
Результат на демобазе УТ 11:

{kind=link}
6. Код в 1С
Напишем обработку для тестирования. Код в 1С подробно расписывать не хочется, т.к. статья не об этом и примеров в инете море. Но и совсем без кода на 1С наверное нельзя.
ТоварныеПозиции - ТЗ с реквизитом Наименование. При создании формы заполняем нужным набором данных для поиска
Подключаемся к БД. Не забываем про права пользователя на используемые БД в MSSQL.
СтрокаПодключения = "DRIVER={SQL Server};
|SERVER=XXX;
|UID=XXX;
|PWD=XXX;
|DATABASE=integration";
Connection = Новый COMОбъект("ADODB.Connection");
Command = Новый COMОбъект("ADODB.Command");
RecordSet = Новый COMОбъект("ADODB.RecordSet");
Попытка
Connection.Open(СокрЛП(СтрокаПодключения));
Command.ActiveConnection = Connection;
Command.CommandText = "select * from sys.databases where name = 'integration'";
RecordSet = Command.Execute();
Если RecordSet.EOF() И RecordSet.BOF() Тогда
Возврат;
КонецЕсли;
RecordSet.MoveFirst();
Исключение
Сообщить(ОписаниеОшибки());
Возврат;
КонецПопытки;
Чистим таблицу и записываем данные, которые ищем. Запись лучше делать порциями для больших объемов данных.
// Почистим табличку скуля
Command.CommandText =
"USE integration
|TRUNCATE table dbo.itemstofind";
Command.Execute();
// Поместим в таблицу нужные нам данные
мСчет = 1;
мТекст = "USE integration
|INSERT INTO dbo.itemstofind (ItemName, ItemNum) VALUES";
Для Каждого Стр Из ТоварныеПозиции Цикл
мТекст = мТекст + "
|('" + Строка(Стр.Наименование) + "',
|" + Формат(мСчет, "ЧРД=.; ЧН=0; ЧГ=0") + "),";
КонецЦикла;
Command.CommandText = Лев(мТекст, СтрДлина(мТекст) - 1) + ";";
Command.Execute();
Обращаемся к хранимой процедуре
// дернем процедуру
Command.CommandText =
"USE [integration]
|SET NOCOUNT ON
|DECLARE @return_value int
|EXEC @return_value = [dbo].[CompareItems]
| @quant = 5
|";
RecordSet = Command.Execute();
Пока RecordSet <> Неопределено Цикл
Если RecordSet.Fields.Count > 0 Тогда
RecordSet.MoveFirst();
COMSafeArray = RecordSet.GetRows();
Array = COMSafeArray.Unload();
Для i = 0 По Array.UBound() Цикл
strArray = Array[i];
Если strArray.Count() < 2 Тогда
Продолжить;
КонецЕсли;
НовСтр = РезультатТест1.Добавить();
НовСтр.Наименование = strArray[5];
НовСтр.Код = strArray[1];
НовСтр.Номенклатура = Справочники.Номенклатура.НайтиПоКоду(НовСтр.Код);
НовСтр.ЗначениеПоказателя = strArray[0];
КонецЦикла;
КонецЕсли;
RecordSet = RecordSet.NextRecordSet();
КонецЦикла;
Command = Неопределено;
Connection = Неопределено;
RecordSet = Неопределено;
Осталось лишь прочитать ответ и записать куда надо. Или вывести на форму.
Берем первые 10 записей справочника номенклатуры. Заполняем таблицу ТоварныеПозиции.
Вот это мы ищем:

А вот это получаем:
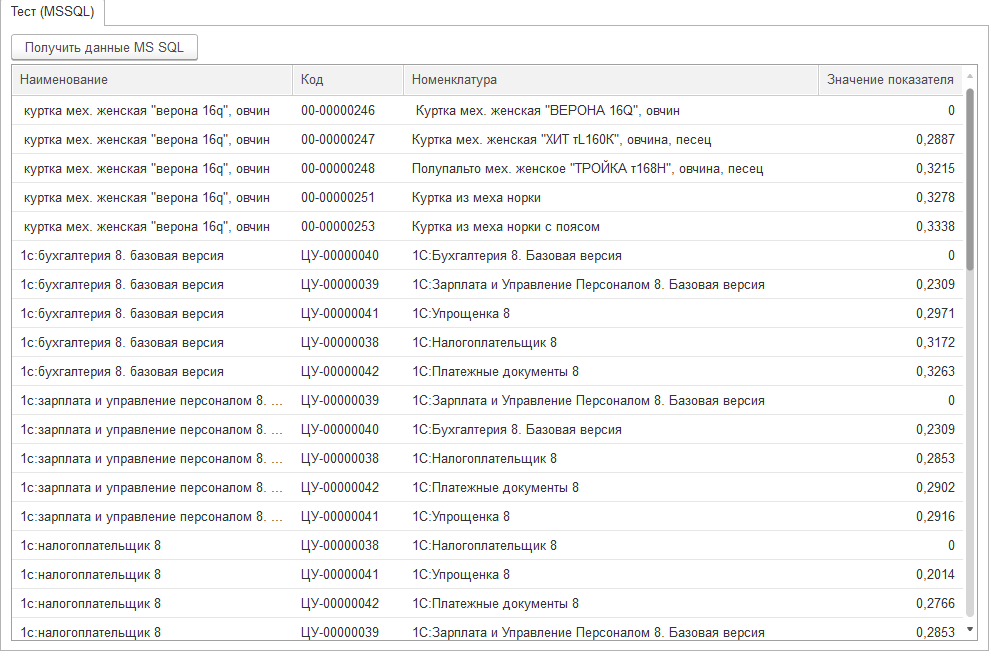
Проверяем, что поле значения показателя отображает корректный данные. Нулевое значение одно для каждой искомой строки при совпадении с номенклатурой. В остальных случаях "степень непохожести" достаточно большая на демо данных. Каждый индивидуально может определить свои допустимые пределы показателя исходя из задачи и, конечно, использовать различные комбинации метрик и дополнительные алгоритмы обработки.
7. Заключение
Думаю, данный подход является интересным опытом и в некоторых будущих задачах метод будет проверяться в рабочем высоконагруженном режиме. То, в каком виде он тут продемонстрирован, является лишь направлением к действию. Пример полностью работоспособный, но есть варианты оптимизации и более удобного использования. В первую очередь хочется уйти от использования физической таблицы с данными для поиска и улучшить расширяемость запроса SQL где идет объединение перед передачей в скрипт. Ещё будет хорошо сравнить производительность по различным вариантам. Есть ощущение, что обращение из R к SQL будет выигрывать в определенных случаях, особенно при использовании специализированных пакетов для R от MS (RevoScaleR).
Вступайте в нашу телеграмм-группу Инфостарт