Создаём новые шаги
Генерация обработок, реализующих шаги
Вывод текста модуля, вместо генерации внешней обработки
Доступность шагов из других сценариев в том же каталоге
Добавляем собственные шаги в форму выбора известных шагов (библиотечных шагов)
Создаём собственные библиотеки шагов
Указание путей к своим библиотекам
Где лучше располагать свои библиотеки?
Преобразуем новые шаги в простейшую библиотеку
Экспортные сценарии
Создаём и используем первые шаги, реализованные через экспортные сценарии
Игнорирование секции “Контекст” экспортного сценария при исполнении реализуемых им шагов
Исключаем экспортные сценарии из исполняемых с помощью тегов
Размещаем экспортный сценарий в собственной библиотеке шагов
Как передать таблицу в качестве параметра шага, реализуемого экспортным сценарием?
Практические примеры
Асинхронный шаг удаления файла с контролем успешности операции
Типовой шаг ожидания закрытия окна как образец асинхронного шага
Реализуем наш шаг удаления файла
Исполнение произвольного кода на сервере 1С
Экспортный сценарий: открытие формы последнего проведенного документа в тест-клиенте
Данная публикация, в отличе от трёх предыдущих, предназначена в первую очередь для разработчиков. Для практического применения информации, приведенной здесь, потребуются навыки программирования и реализации принципов переиспользования кода. Для аналитиков и QA-инженеров важной может оказаться информация о том, что возможности Vanessa-ADD с легкостью могут быть расширены под потребности проекта силами программистов и совсем не обязательно оставаться в рамках стандартных возможностей фреймворка. При этом возможность обновления фреймворка не теряется.
По информации от разработчиков параллельного проекта Vanessa-Automation https://github.com/Pr-Mex/vanessa-automation почти вся информация, приведённая здесь, является базовой (унаследованной от https://github.com/silverbulleters/vanessa-behavior) и справедлива также для этого проекта.
На примерах из прошлой публикации можно было увидеть, что далеко не всегда шаги встроенной в Vanessa-ADD библиотеки позволяют эффективно решать возникающие задачи, а для некоторых нужных операций во встроенной библиотеке ещё нет шагов. Часть связанных с этим ограничений можно обойти за счет шага выполнения произвольного кода на языке платформы 1С. Но есть и более эффективные пути для решения этой проблемы:
1) Создание собственных шагов и их реализация в автоматически генерируемых внешних обработках
2) Создание собственных шагов за счет экспортных сценариев, когда исполнение шага приводит не к вызову экспортного метода внешней обработки, а к поочерёдному выполнению шагов из другого сценария.
3) Объединение собственных шагов в библиотеки, что позволяет повторно использовать их уже не в одном, а в нескольких проектах.
Более того, эти возможности сближают Vanessa-ADD с аналогичными фреймворками для других платформ, такими как JBehave и Cucumber. Ведь в них именно программирование является средством реализации исходных шагов BDD-сценария. В отличии от инструментов для 1С, которые по-настоящему стремятся нас баловать ))
Сначала мы углубимся в рассмотрение механизмов Vanessa-ADD на простейших примерах, без стремления сразу увидеть прикладную пользу. Информация будет носить “академический” характер. Это позволит сосредоточиться на сути механизмов, а не на объемных листингах кода 1С или фича-файлов. А в конце публикации будут приведены практические примеры, которые позволят увидеть прикладную пользу и потенциал рассмотренных механизмов. Чтобы не копировать текст и не перепечатывать его со скриншотов можно воспользоваться репозиторием https://github.com/VladimirLitvinenko84/DevelopingAndTestingWithVanessa.
Создаём новые шаги
Генерация обработок, реализующих шаги
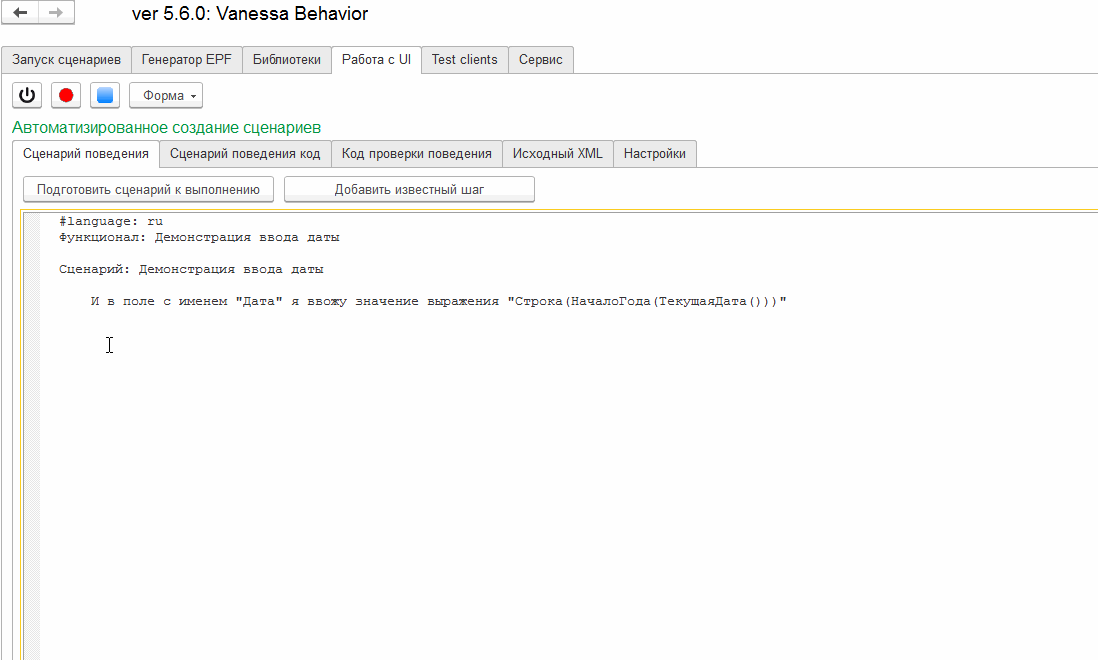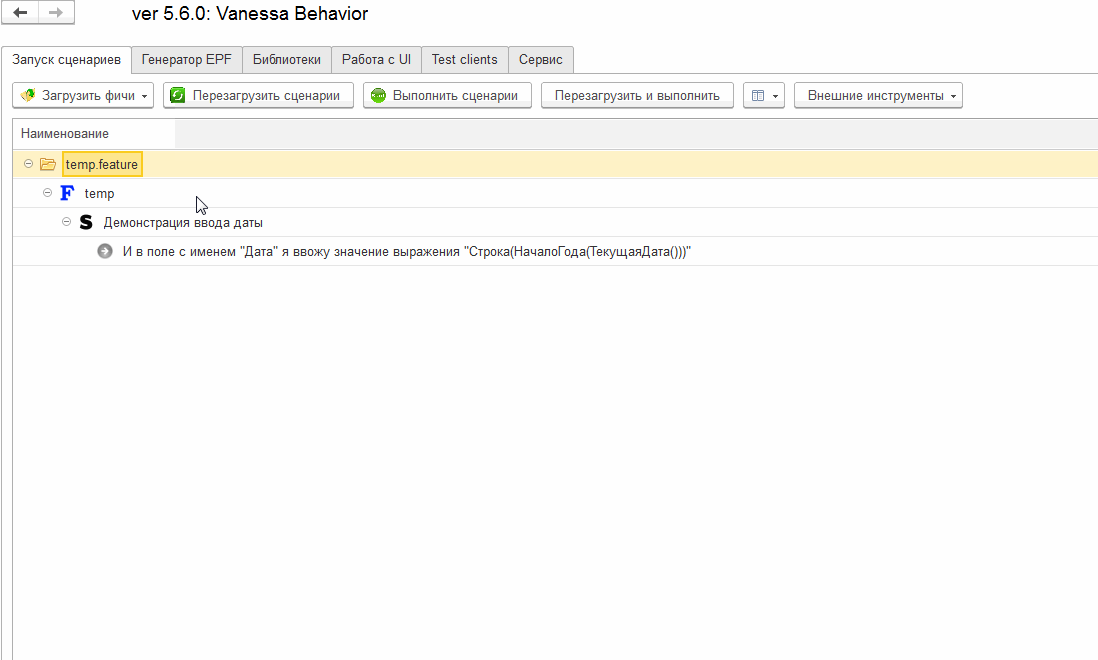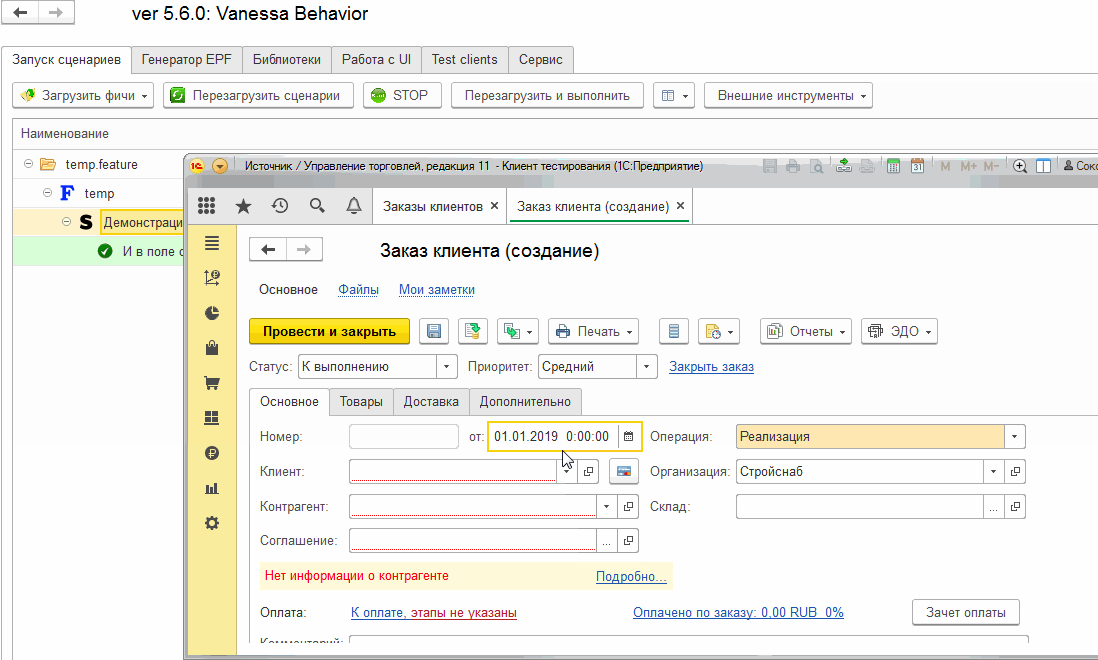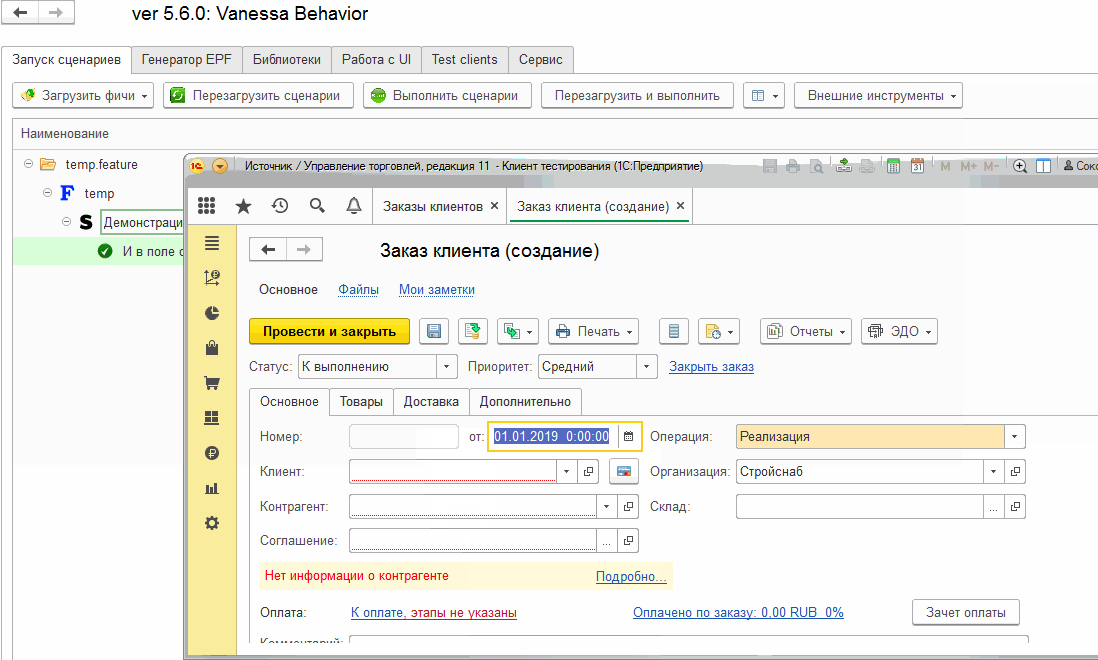
В публикации, посвященной обзору интерфейса Vanessa-ADD мы видели, как ведет себя обработка bddRunner, встречая в сценарии шаг, которого нет во встроенной библиотеке шагов:
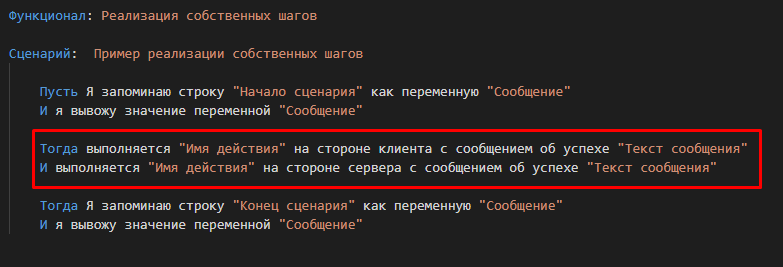
Этот шаг выделяется оранжевым цветом. Так Vanessa-ADD сообщает нам, что шаг воспринят как новый и пока неизвестный ей. Включив видимость соответствующих колонок мы можем увидеть, что путь к реализующей его внешней обработке не заполнен. Такое отображение шага можно увидеть, например, если мы отпечатались при написании шага встроенной библиотеки. Или неправильно разбили сценарий на группы шагов, из-за чего высокоуровневые шаги были восприняты как неизвестные исполняемые шаги.
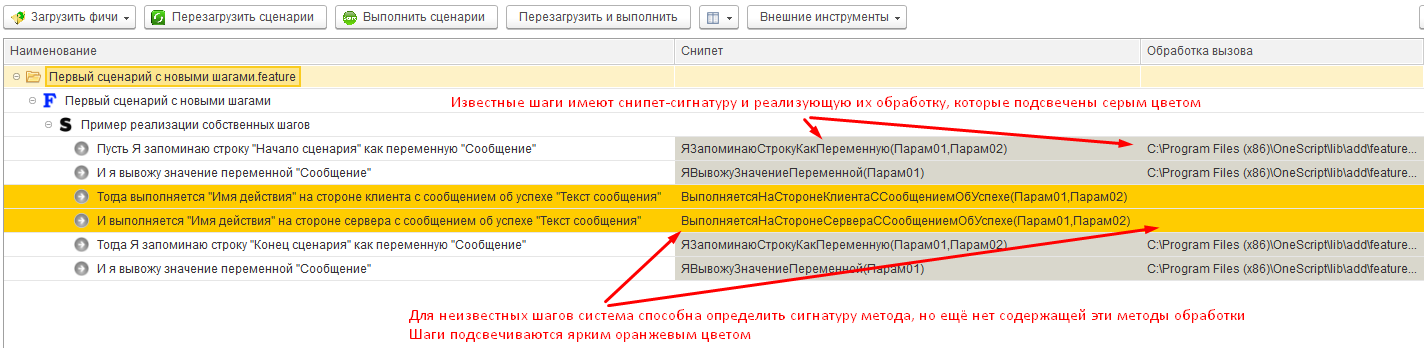
Однако это не просто сигнал об ошибке. Это также сигнал о том, что при желании мы можем автоматически создать реализацию этого нового шага в виде внешней обработки и её экспортного метода. После чего Vanessa-ADD уже сможет получить всю необходимую для его исполнения информацию. При этом сигнатура метода становится известна ещё до создания внешней обработки. Параметры шага определяются как числовые литералы или слова, заключенные в двойные или одинарные кавычки. Они же становятся параметрами реализующего шаг метода. А имя этого метода складывается из текста шага после удаления из него первого ключевого слова Gherkin и всех параметров.
То есть записав шаг в виде
И Это новый шаг с параметром "Парам 1", и параметром 'Парам 2' и параметром 15
мы получим сигнатуру соответствующего ему метода
ЭтоНовыйШагСПараметромИПараметромИПараметром(Парам01, Парам02, Парам03)
И если мы действительно хотим создать новый шаг, то сделать это можно нажав на кнопку “Создать и обновить шаблоны обработок” на вкладке “Генератор EPF”
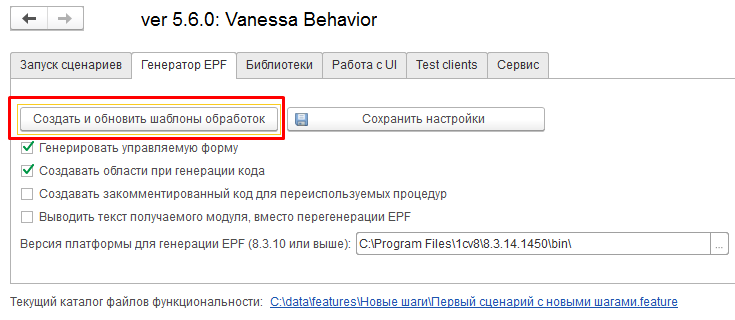
Если флаги-настройки выставлены по умолчанию, то её нажатие приводит к созданию подкаталога step_definitions в том же каталоге, в котором находится файл со сценарием. В этом каталоге автоматически создаётся внешняя обработка с основной управляемой формой (за это отвечает флаг “Генерировать управляемую форму”).
Если каталог step_definitions уже был создан ранее, то он не персоздаётся. Все файлы в нём сохраняются или обновляются, при необходимости создать реализацию для ещё одного нового шага.
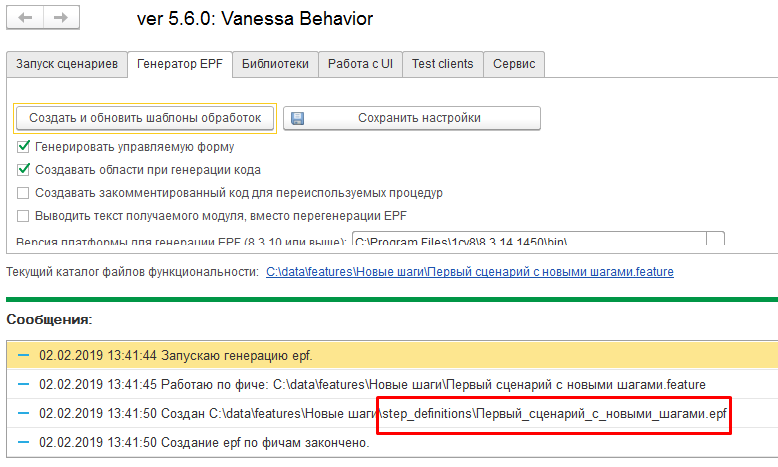
Сгенерировав внешнюю обработку и перезагрузив сценарий мы увидим, что Vanessa-ADD обнаружила обработку, которая реализует этот шаг :
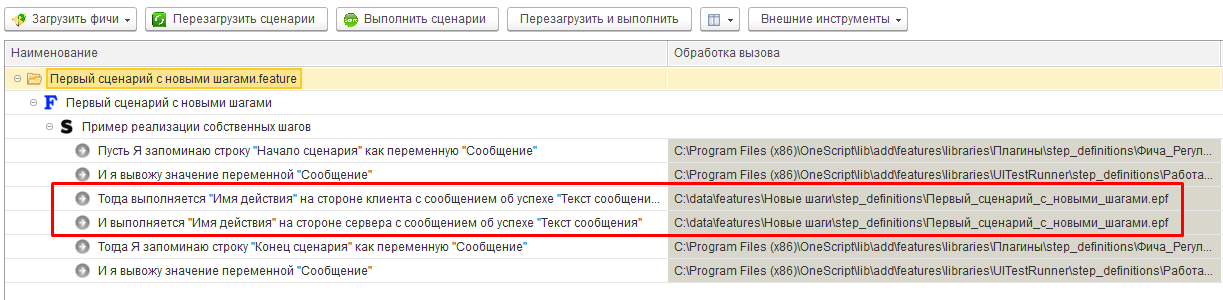
В данном примере примере у нас было два неизвестных шага. Теперь в созданной внешней обработке находятся описания и реализации этих шагов, которые использует Vanessa-ADD при их загрузке и исполнении. Откроем эту обработку, а в ней основную управляемую форму:
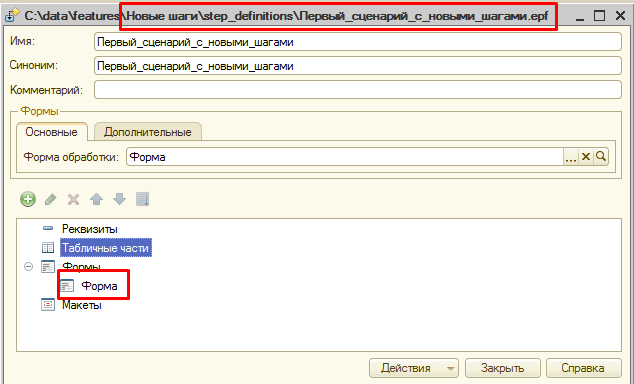
В модуле этой формы можно увидеть объявления уже знакомых нам переменных Ванесса, Контекст и КонтекстСохраняемый для того, чтобы мы смогли использовать их в методах, реализующих шаги. Также создаются экспортные методы. Один из них с именем ПолучитьСписокТестов отвечает за регистрацию новых шагов, их описание, определение имен реализующих их методов. Для этого внутри метода ПолучитьСписокТестов производятся вызовы метода Ванесса.ДобавитьШагВМассивТестов с соответствующими параметрами:
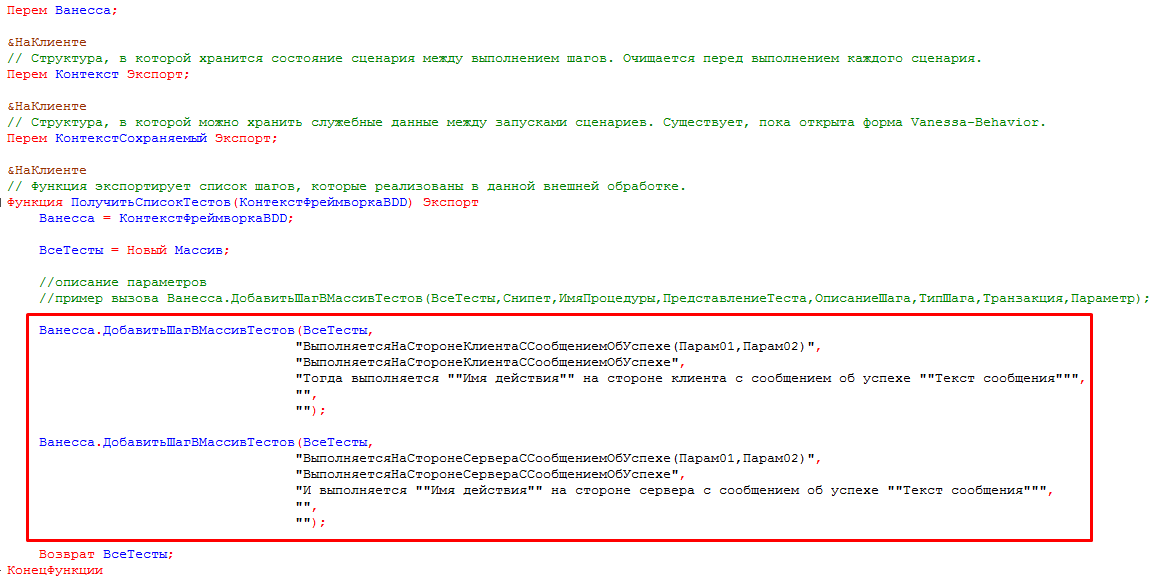
Далее модуль формы содержит методы, реализующие новые шаги - содержащие их исполняемый код:

При создании внешней обработки в эти методы были помещены строки, вызывающие исключения со специальным текстом “Не реализовано.”.
Когда в процессе исполнения сценария будет произведена попытка выполнить известный шаг, но в результате его выполнения возникнет исключение с таким текстом, то для механизма проигрывания сценария это будет сигналом, что шаг не реализован. На этом исполнение сценария остановится. Это поведение мы уже видели ранее здесь //infostart.ru/public/984854. Посмотрим еще раз :
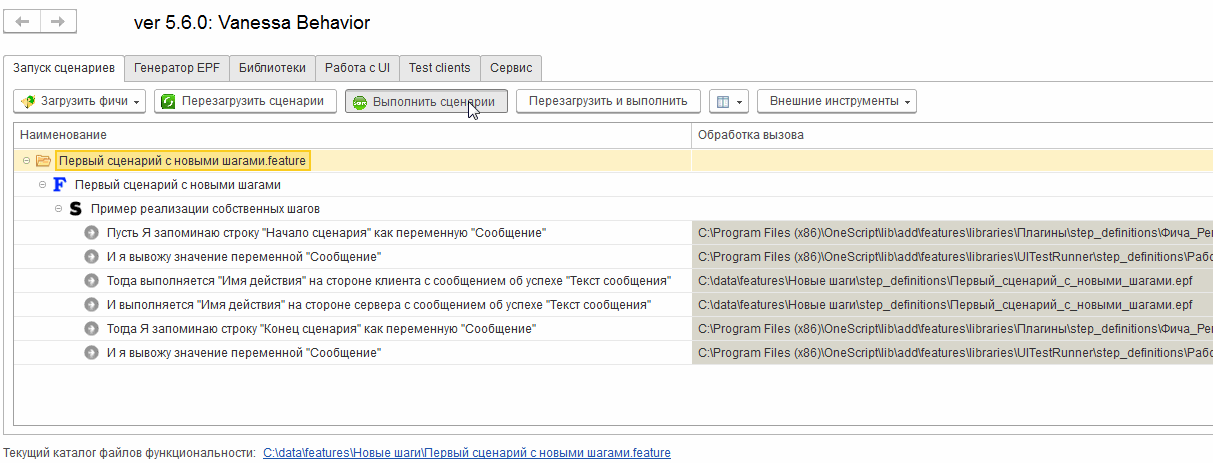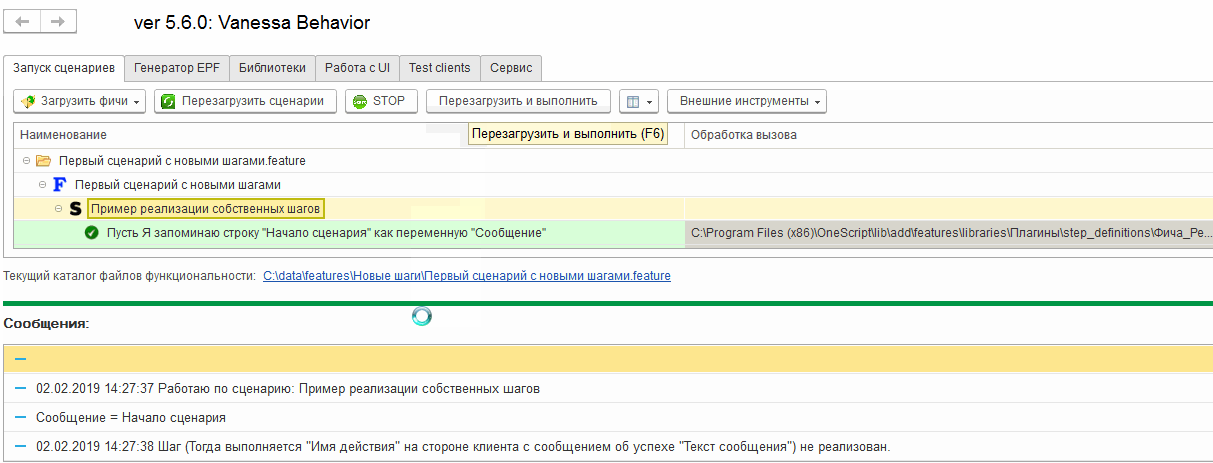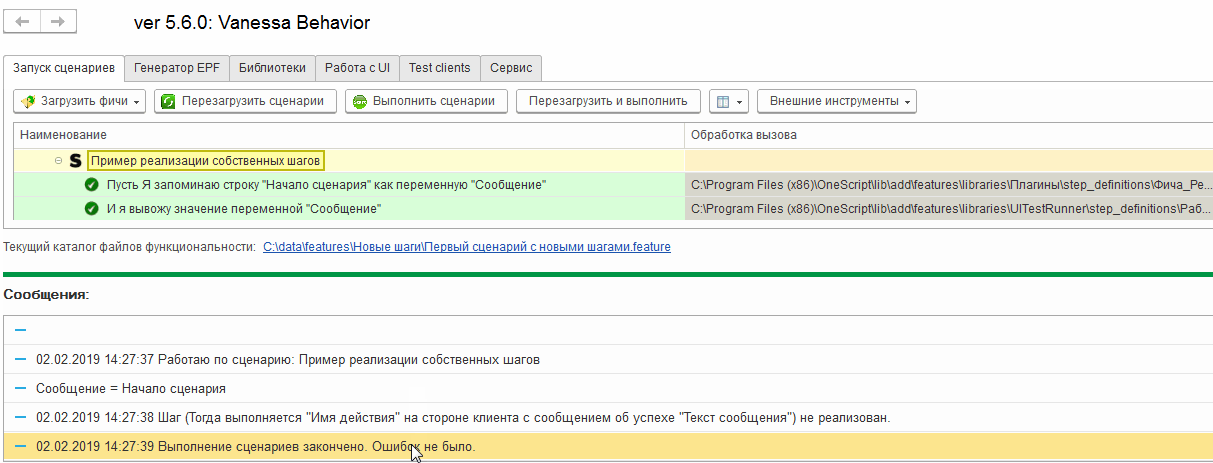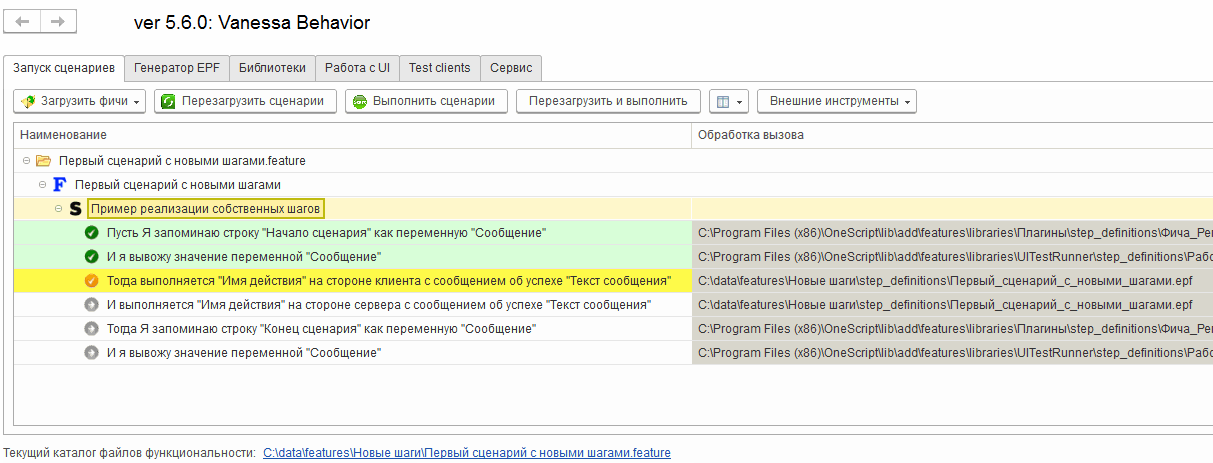
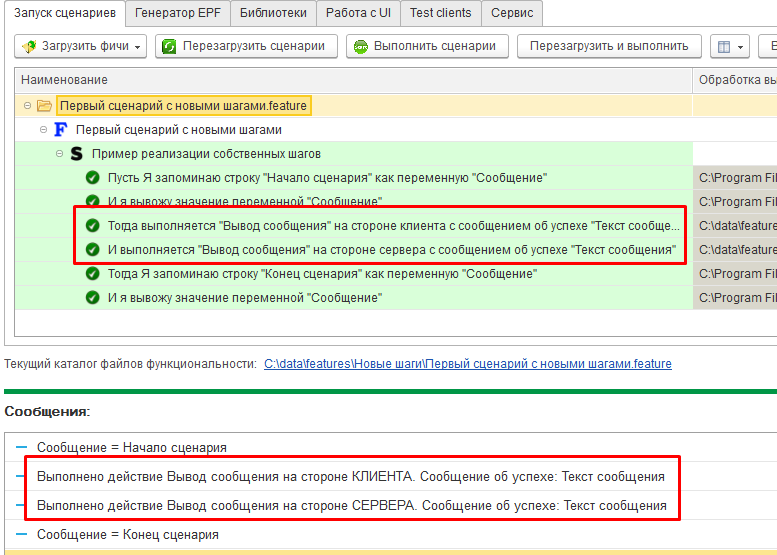
Первые два шага из встроенной библиотеки шагов исполнились, но на первом же из наших новых шагов система прекратила исполнение сценария, посчитав при этом, что ошибок не было. Произошло это по той самой причине, что мы вызвали исключение со специальным текстом “Не реализовано.”, говорящим, что работа над сценарием еще не закончена. Все следующие шаги сценария должны выполняться только после успешного завершения предыдущих. Наш шаг нельзя считать успешно завершённым и поэтому сценарий не может быть продолжен. Но в то же время нет причины считать, что произошла ошибка.
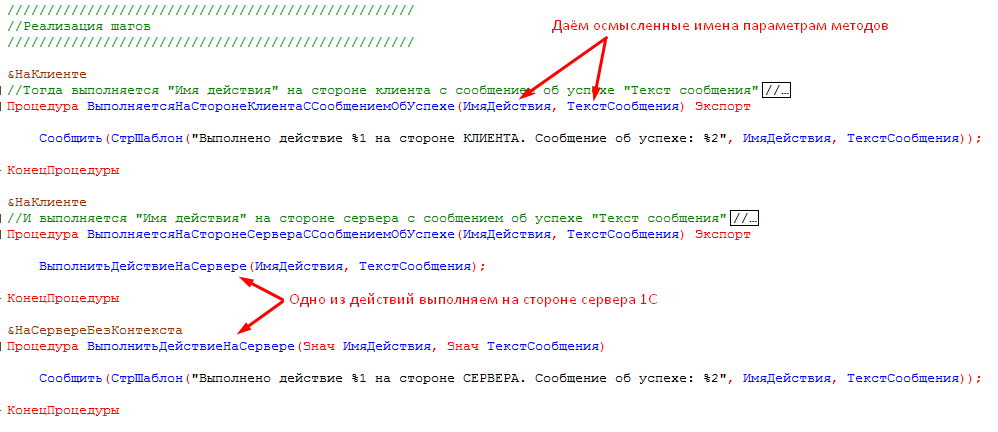
Реализуем теперь наши шаги в соответствии с логикой, заложенной в их названии. Также дадим параметрам методов более подходящие названия:
Выполнив сценарий еще раз мы увидим что исполнились все шаги, каждый из которых выдал своё сообщение, но одно из них пришло со стороны сервера 1С:
Вывод текста модуля, вместо генерации внешней обработки
Вернёмся ко вкладке “Генератор ERF”.
Флаг “Выводить текст получаемого модуля, вместо перегенерации ERF” можно использовать в случае отладки.
Также этот флаг будет необходим, если мы внесли значительные изменения в автоматически созданный код обработки и после этого хотим дополнить её кодом для новых шагов. Например если мы сделали переносы строк, там где это не сделала бы автоматика, изменили расположение методов друг относительно друга. При значительных правках кода автоматика не сможет определить как правильно дополнить уже существующий модуль новым кодом и либо выдаст ошибки, либо просто сломает существующий код. В таких случаях модификации модуля лучше делать самостоятельно, предварительно получив новую версию кода в окно сообщений.
При установке этого флага код модуля выводится в отдельное окно текстового документа, откуда его можно забрать через Ctrl+C, Ctrl+V :
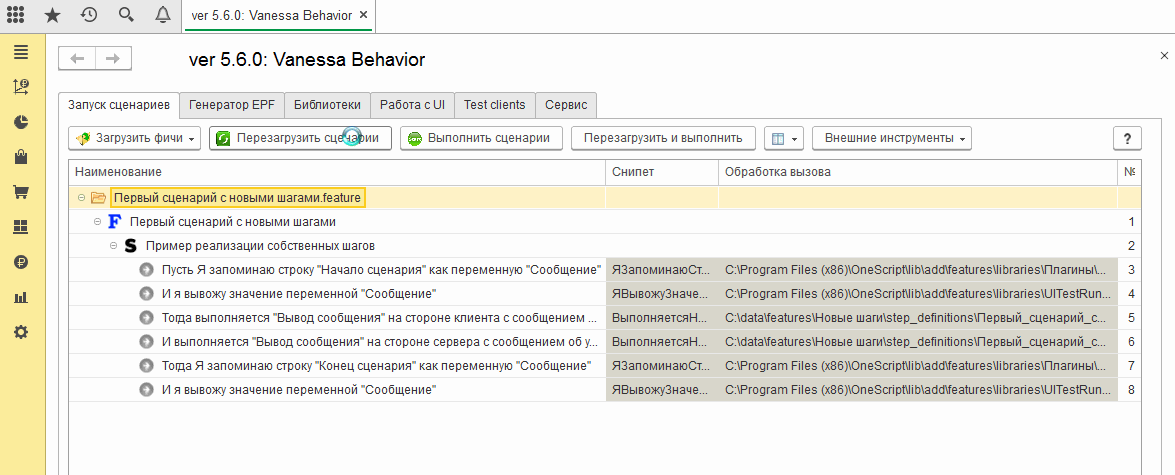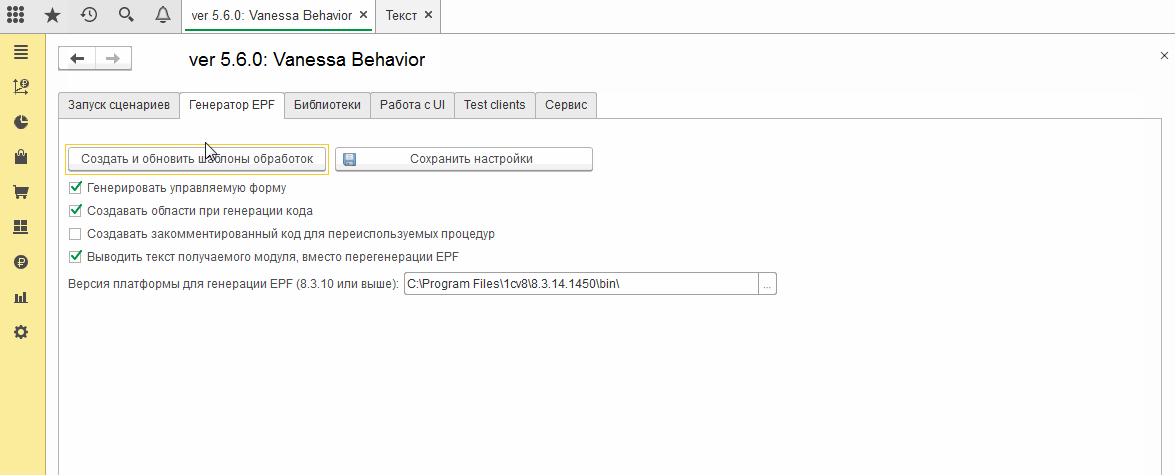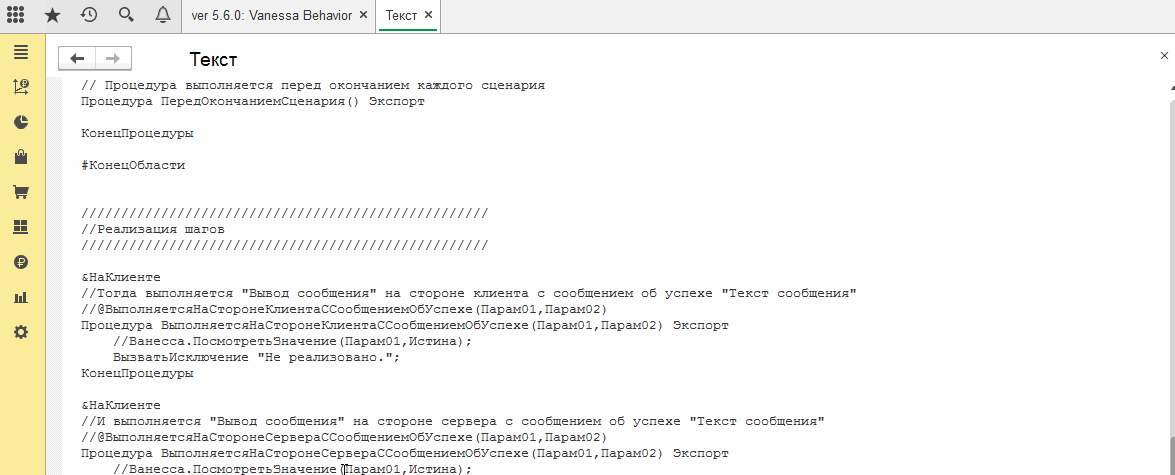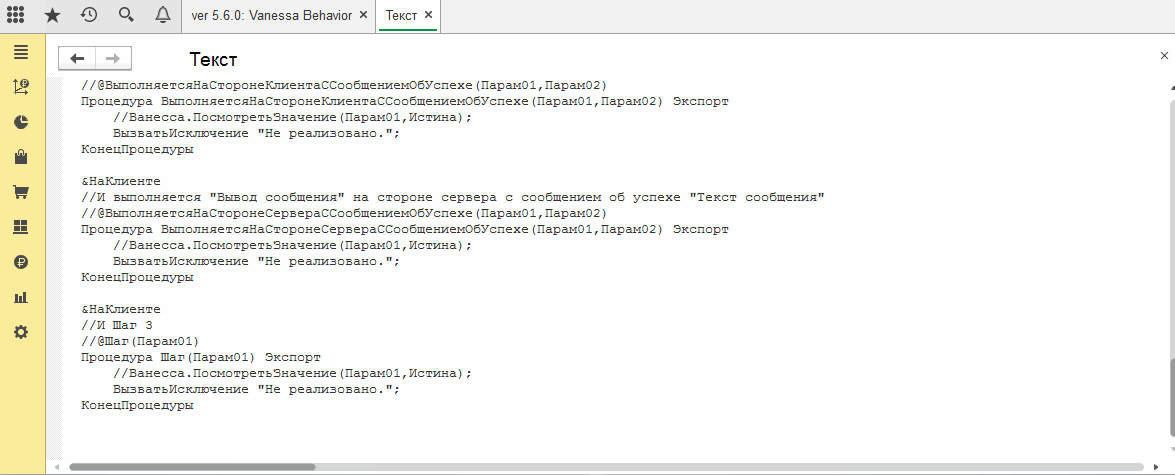
Произвольное расположение и наименование реализующих шаги обработок по отношению к исходному файлу сценария
Каталог, в котором находятся реализующая шаги внешняя обработка, был назван step_definitions. Но он не обязан так называться, это просто имя по-умолчанию которое использует механизм автоматической генерации обработок. Мы можем переименовать его как угодно и шаги всё равно будут обнаружены. Главное, чтобы обработка находилась в каталоге с загружаемым на исполнение фича-файлом или в одном из его подкаталогов. Более того, самой обработке также можно дать произвольное имя:
Механизмом автоматической генерации обработок для каждого сценария создаётся только одна внешняя обработка, реализующая его шаги. Но при желании мы можем разбить её на любое количество внешних обработок, если того требует логика нашего решения. Например, мы можем скопировать созданную внешнюю обработку, дать ей другое имя, чтобы избежать некорректного подключения. Оставить в каждой из них объявление и реализацию только одного метода. И в этом случае ранее продемонстрированный функционал по прежнему будет работать. Мы ещё вернёмся к этой особенности, когда будем говорить про библиотеки шагов :
Избегаем дублирования шагов
Во встроенной библиотеке уже есть много шагов. Фактически есть шаги для каждого интерактивного действия пользователя, которое может быть вызвано со стороны тест-менеджера. Корректно ли будет обработана ситуация, если мы случайно или нарочно задублируем шаг?
Да, это не приведёт к ошибкам. Но это приведёт к тому, что мы потеряем возможность использовать один из дублей. Продемонстрируем это на примере двух наших обработок, которые получились у нас после разделения исходной обработки на два файла. Вернём в одну из них объявление второго шага:
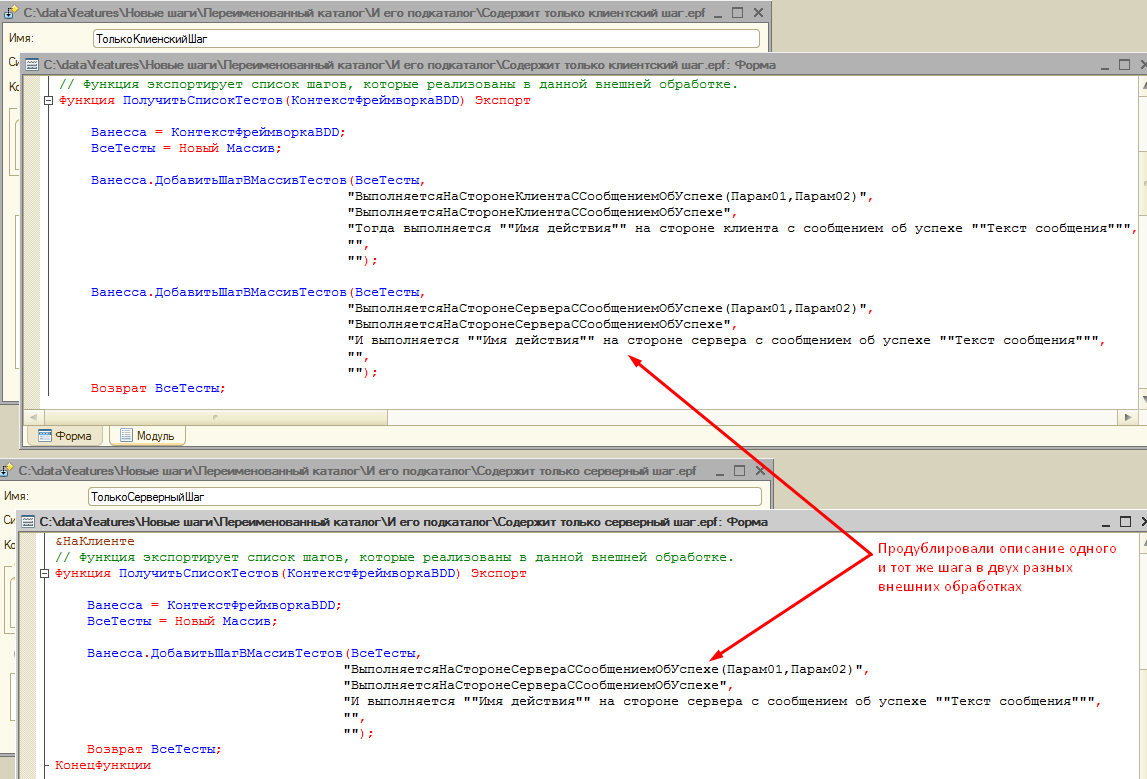
В результате загрузки сценария мы видим, что система сопоставила “серверный” шаг только с одной из его реализаций, которую и будет выполнять. Также она выдала предупреждение о том, что обнаружены дубли. Следует избегать таких ситуаций. Иначе даже если сценарий будет загружен и отправлен на исполнение, может оказаться, что в результате выполнения шага система произведет вовсе не те действия, которые мы ожидали:
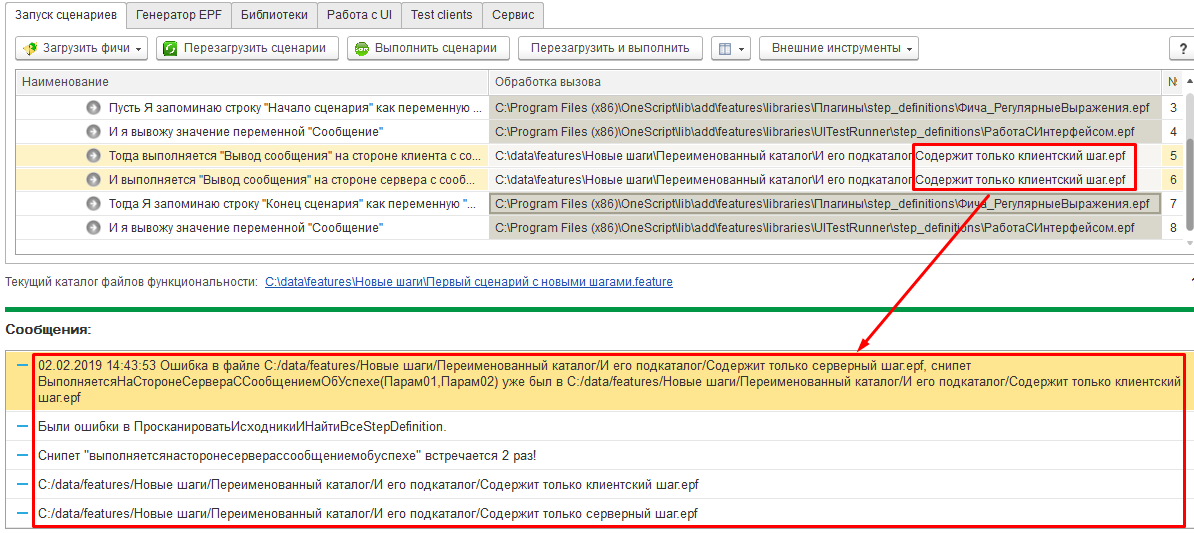
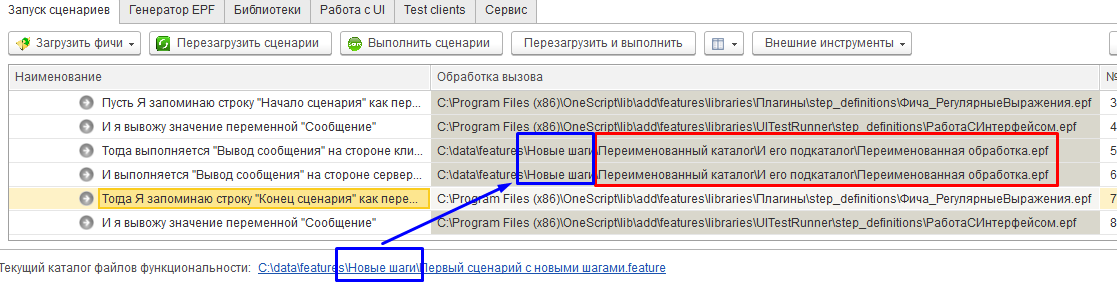
Доступность шагов из других сценариев в том же каталоге
Мы уже знаем, что расположение обработки, реализующей шаги, и расположение сценария, использующего эти шаги жёстко не связаны. Также не обязаны совпадать или быть похожими имена обработки и сценария.
Из этого можно сделать следующий вывод: рядом с исходным сценарием, по которому были сгенерированы внешние обработки, могут находится любые другие сценарии в других фича-файлах, которые используют те же самые шаги, и при этом для них не придётся генерировать новые внешние обработки. Из этих сценариев также будут доступны шаги из ранее созданных внешних обработок.
Посмотрим на это поведение. Наш сценарий находится в файле
C:\data\features\Новые шаги\Первый сценарий с новыми шагами.feature
Обработки, реализующие шаги, находятся в каталоге
C:\data\features\Новые шаги\Переименованный каталог\И его подкаталог
Создадим еще один сценарий, использующий те же самые шаги и добавим в него еще один новый неизвестный шаг:
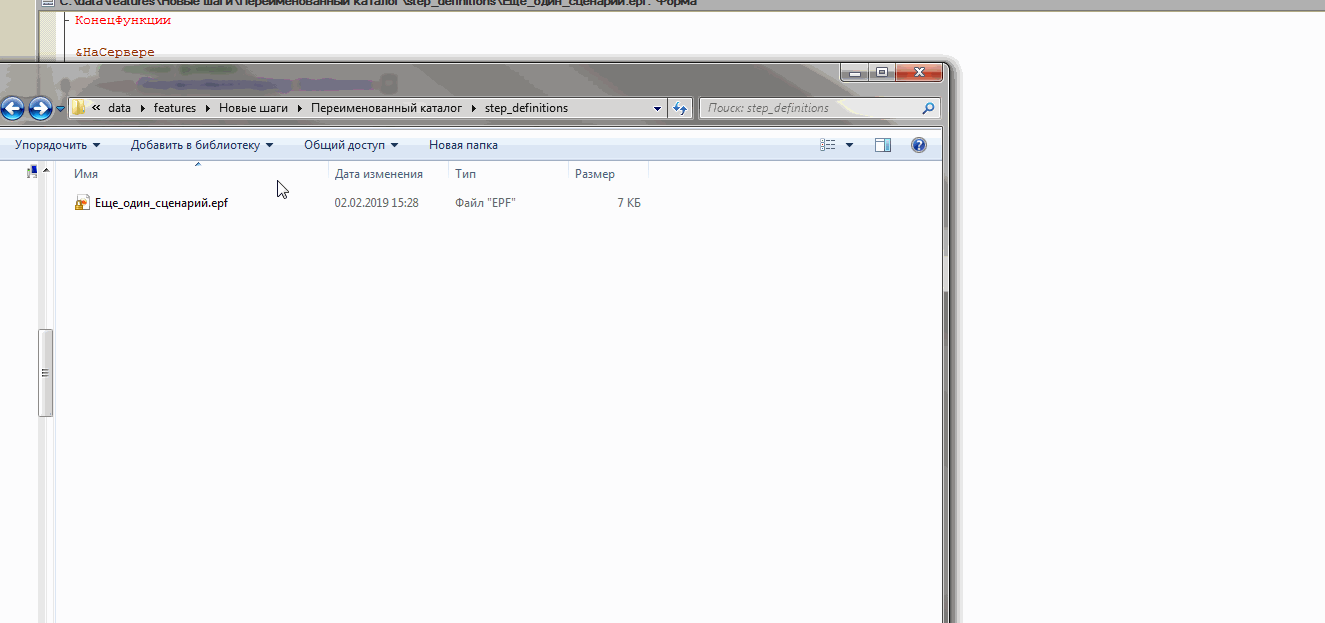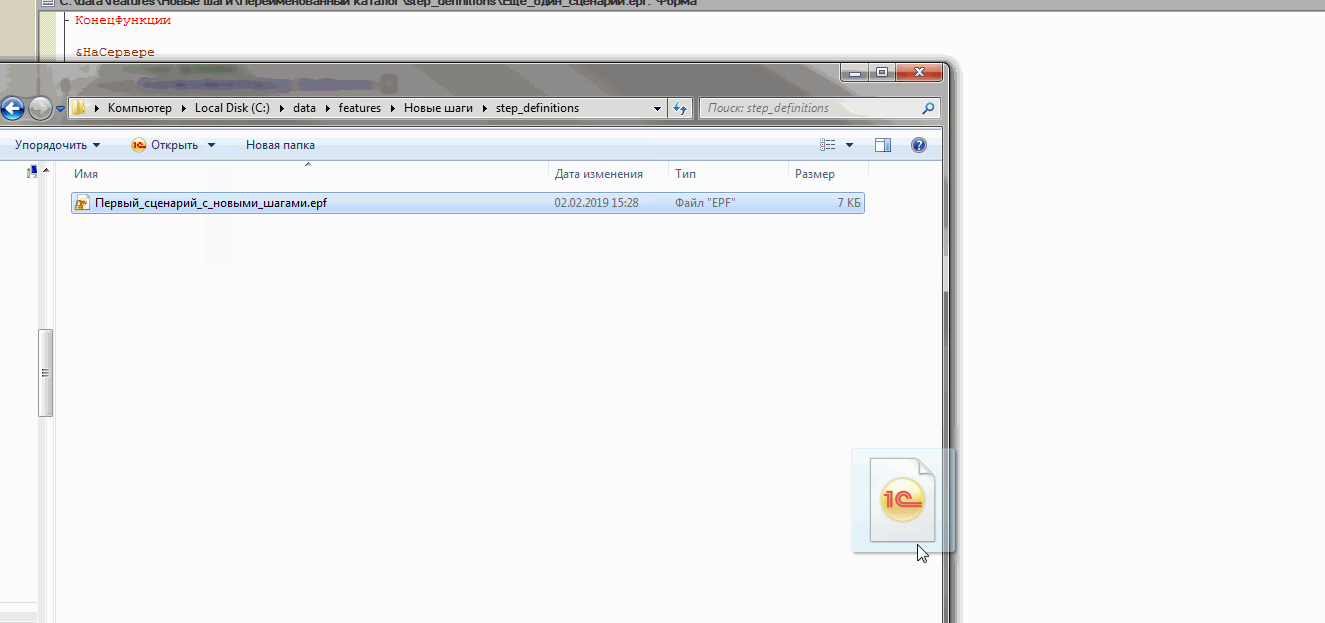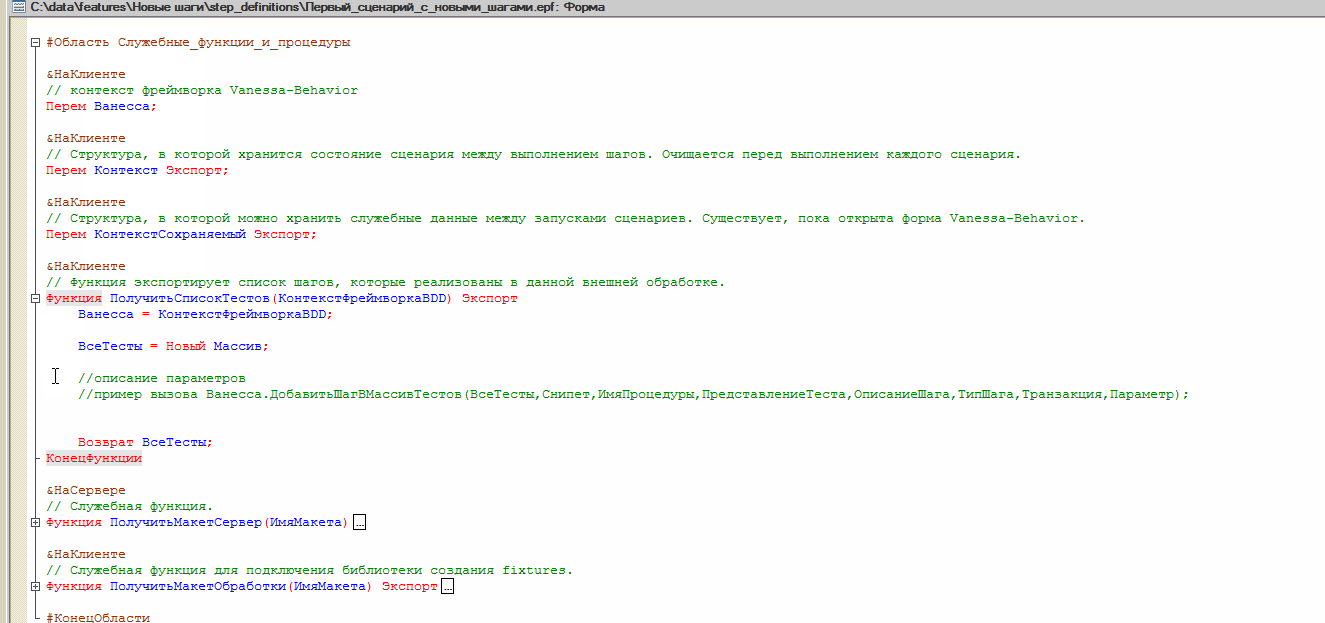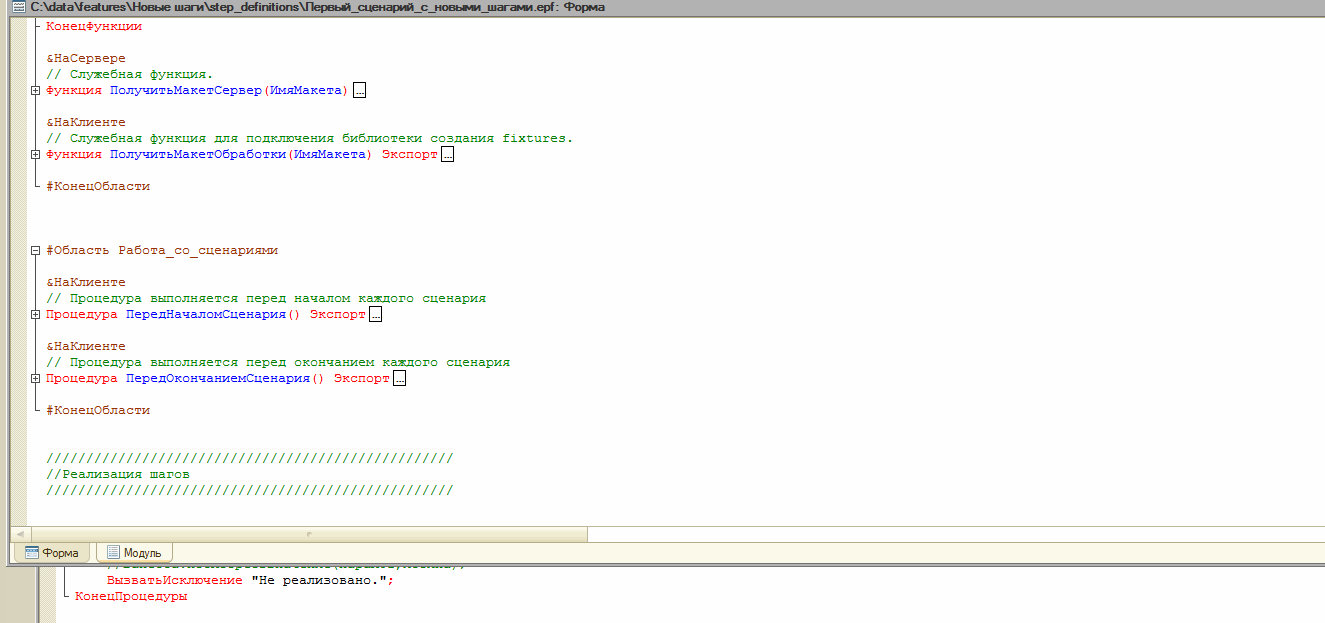
C:\data\features\Новые шаги\Переименованный каталог\Еще один сценарий.feature
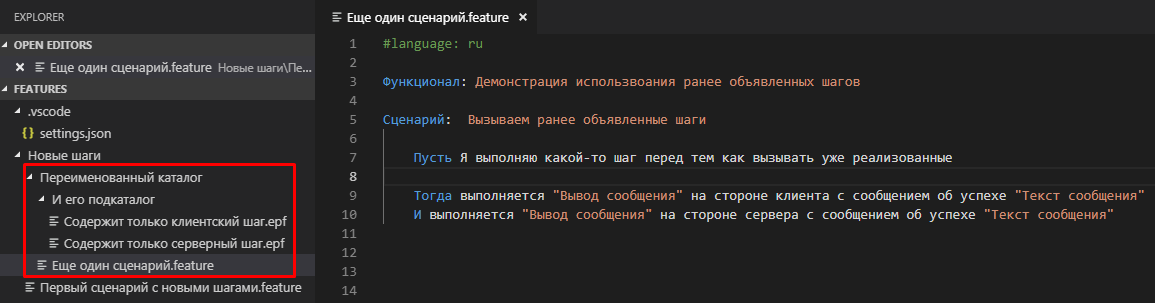
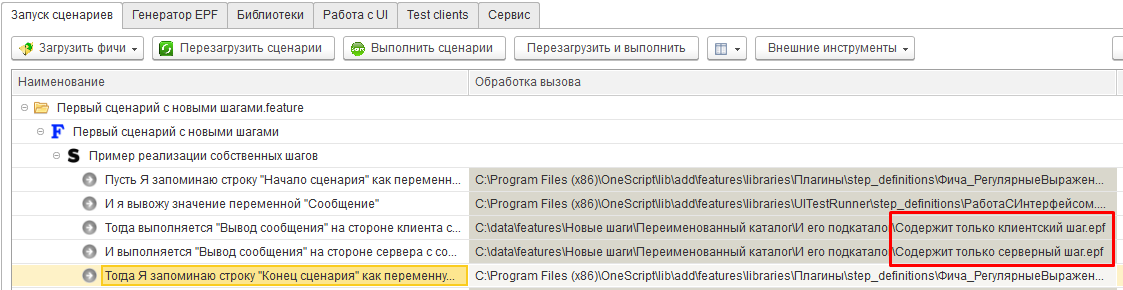
Загрузим для исполнения каталог C:\data\features\Новые шаги и увидим, что шаги из второго сценария связались с ранее созданными внешними обработками:
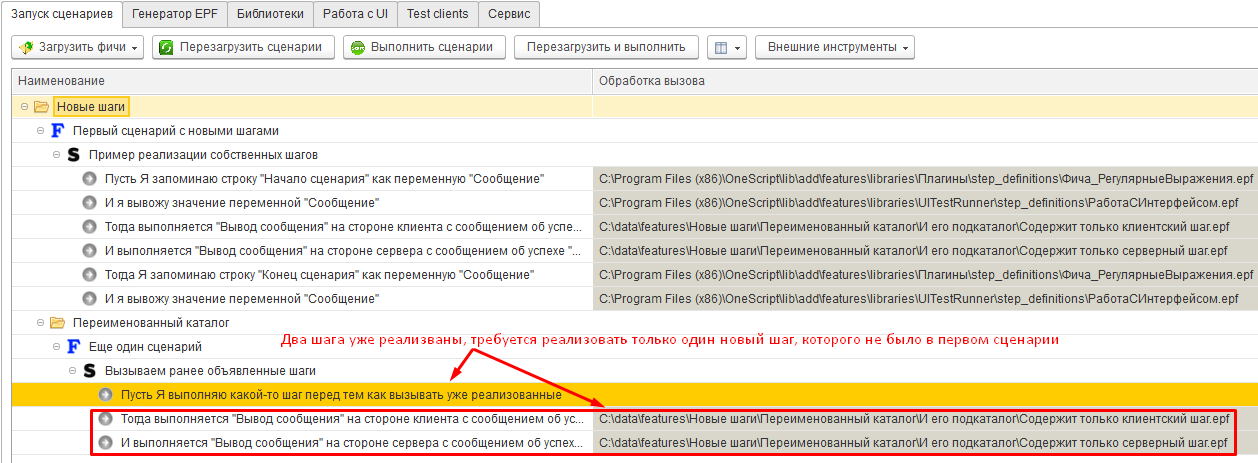
Теперь если мы перейдем на вкладку “Генератор ERF” и создадим внешнюю обработку, то получим новый каталог step_definitions в том же подкаталоге, где находится файл “Еще один сценарий.feature” и эта внешняя обработка будет содержать объявление и реализацию только одного неизвестного ранее шага “Пусть Я выполняю какой-то шаг перед тем как вызывать уже реализованные”:
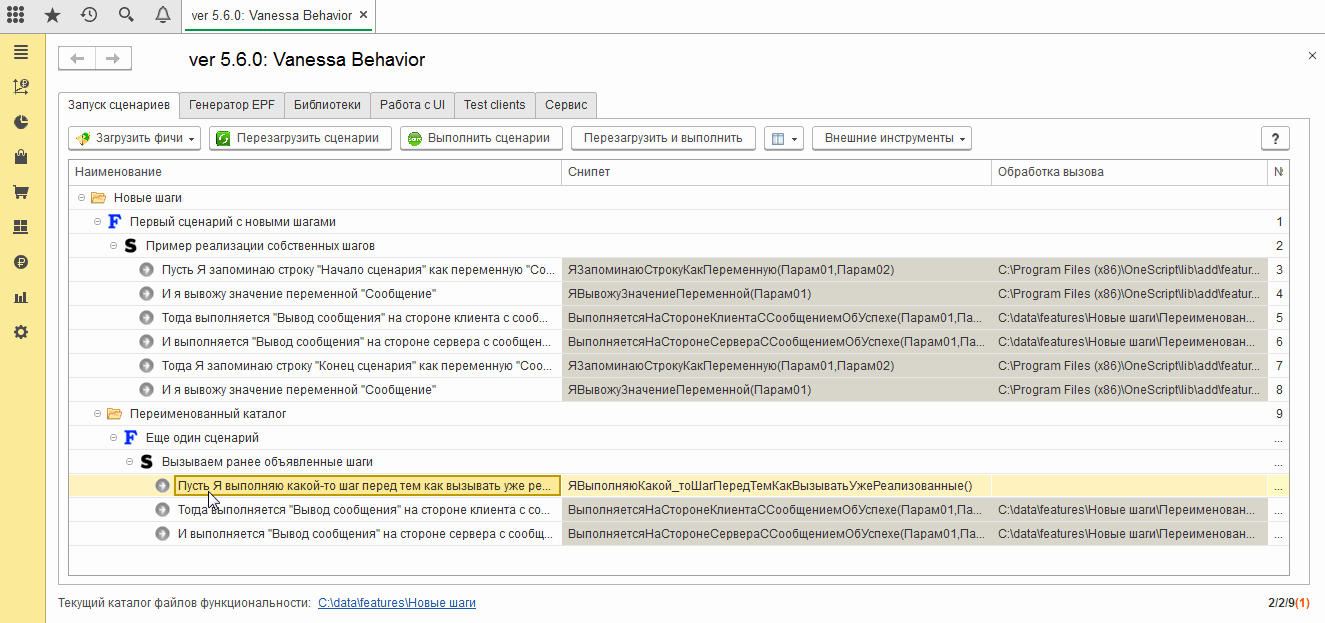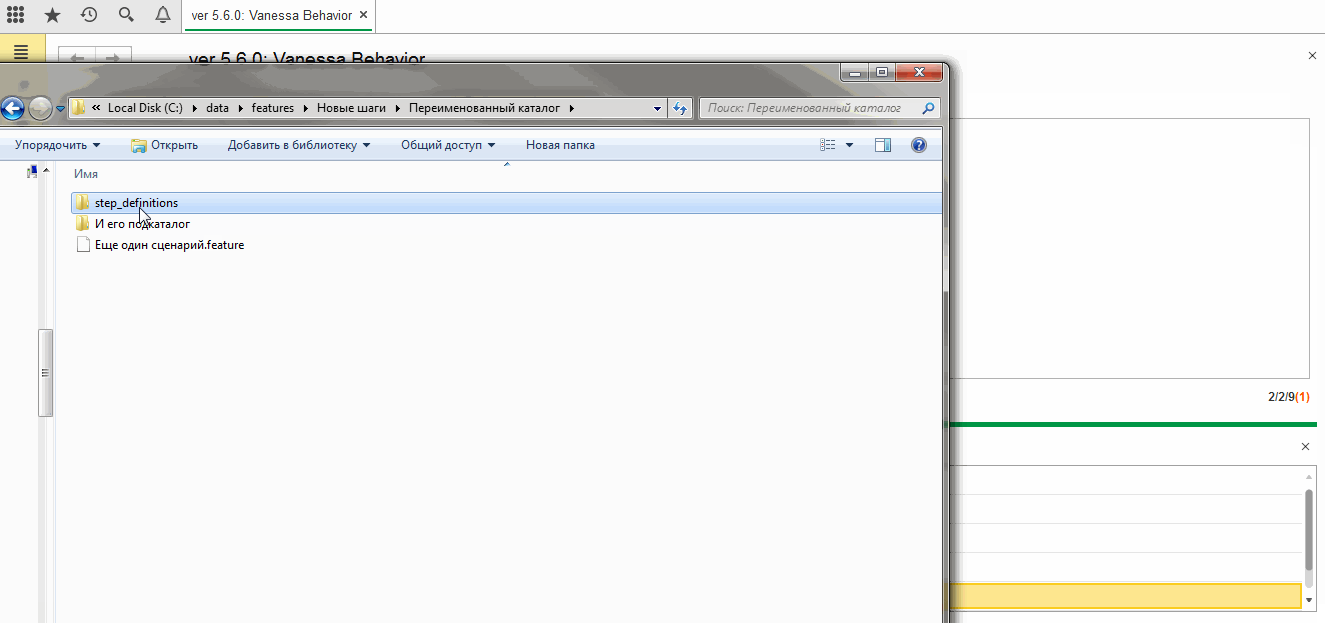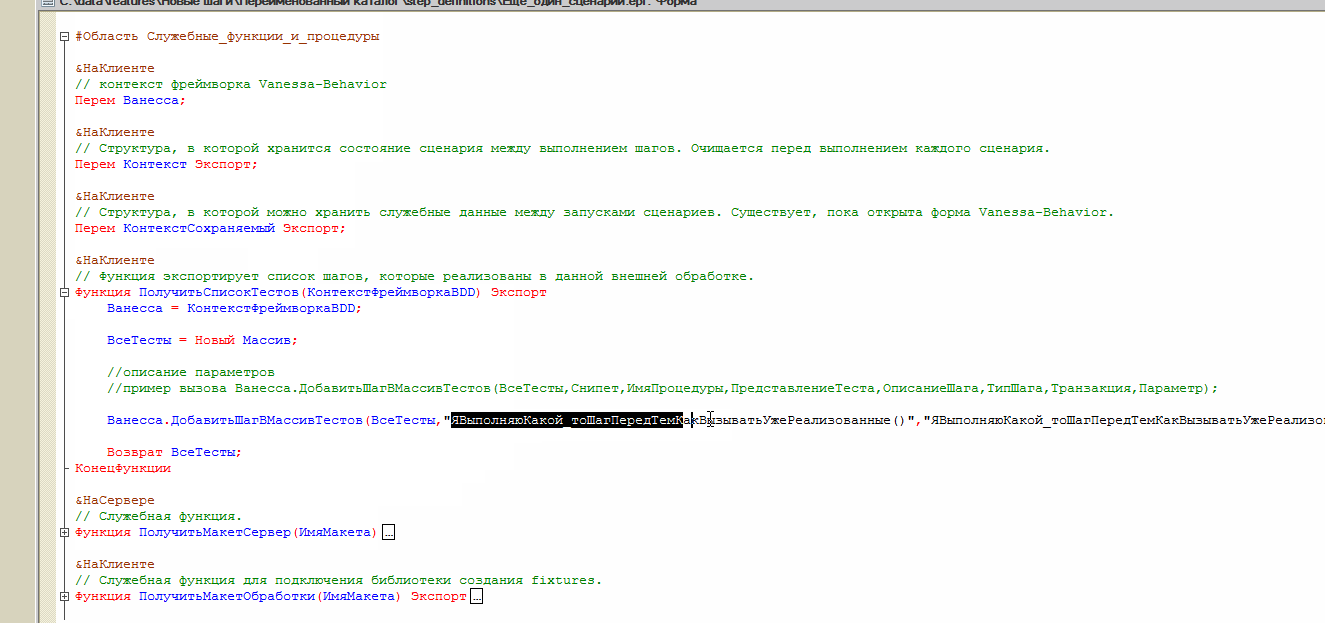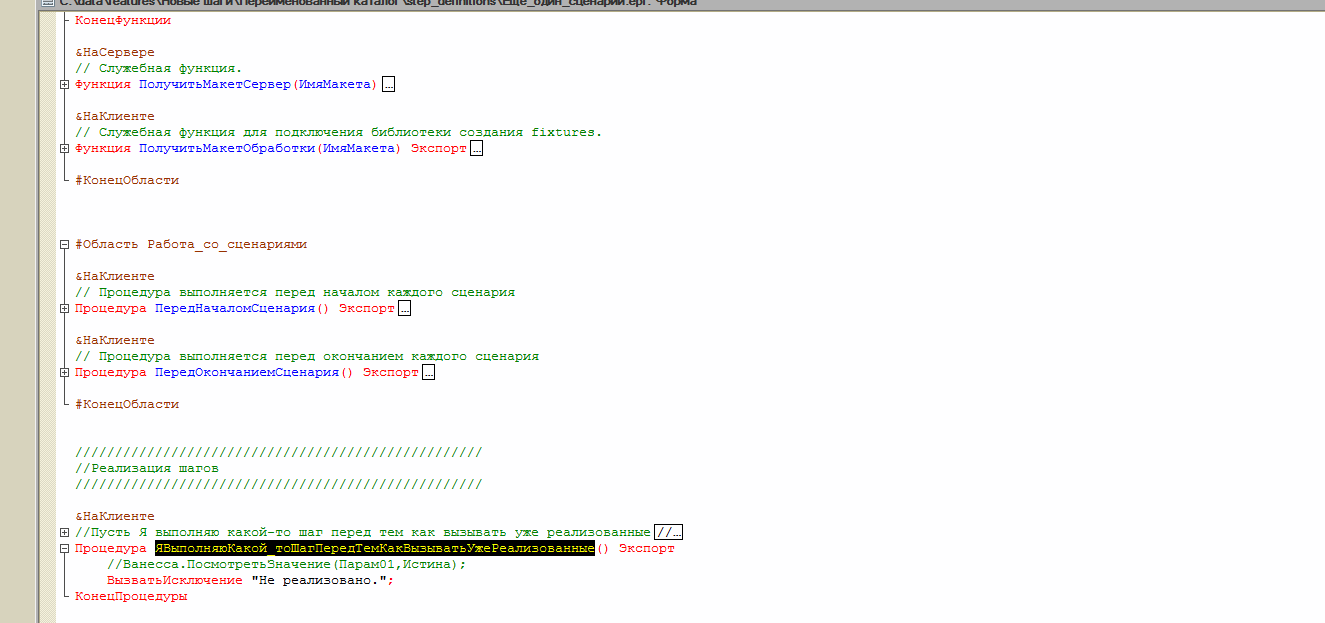
Также здесь мы столкнемся с поведением системы, которого вы возможно захотите избежать, применив уже рассмотренный ранее флаг “Выводить текст получаемого модуля, вместо перегенерации ERF”.
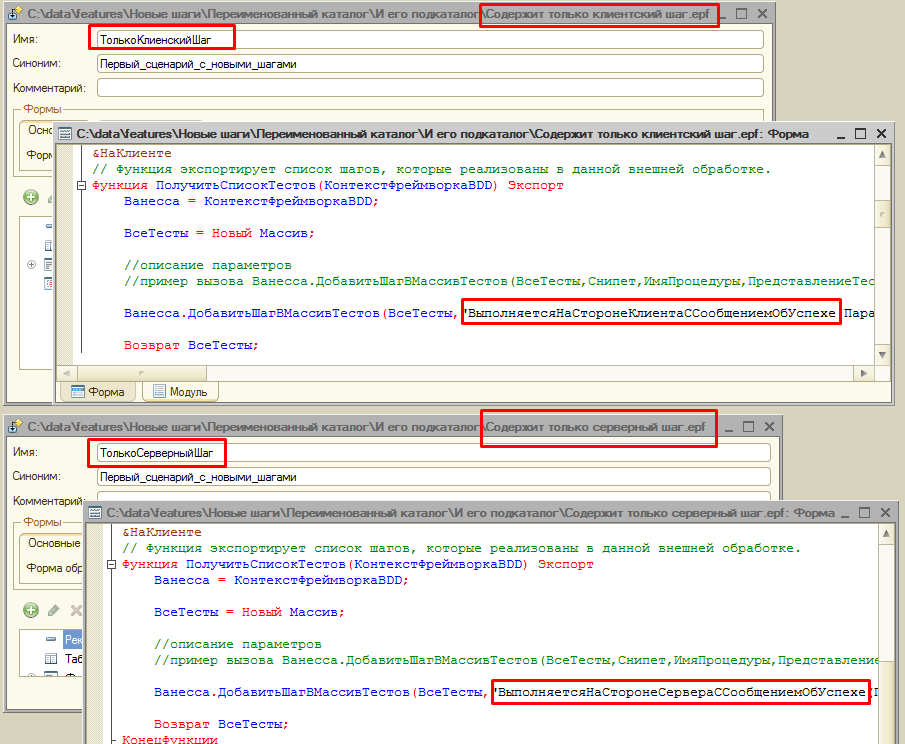
Несмотря на то, что для двух первых наших шагов уже были созданы внешние обработки, Vanessa всё равно создала каталог step_definitions для первого нашего сценария и даже одноимённую обработку. При этом модуль этой обработки не содержит описания или реализации каких бы то ни было шагов, потому что все шаги, использованные в этом сценарии уже имели реализацию. То есть для нас этот каталог и обработка абсолютно бесполезны и мы можем их удалить. Но таков алгоритм генерации ERF, он может создать внешнюю обработку даже если в ней нет необходимости:
Теперь можно подвести итог о том, как по умолчанию работает алгоритм генерации обработок и методов, реализующих шаги:
1) Для каждого сценария создаётся каталог step_definitions
2) В каталоге step_definitions создаётся одноимённая фича-файлу внешняя обработка.
3) В модуле формы этой обработки размещаются объявления и реализации только тех шагов, которые ещё не имели реализации на момент генерации обработки.
В специфичных случаях можно воспользоваться флагом “Выводить текст получаемого модуля, вместо перегенерации ERF” и избежать своевольного поведения генератора EPF. В этом случае можно самостоятельно изменить код ранее созданных обработок. Так например можно избежать создания обработок для каждого отдельного фича-файла, объединив все реализации шагов в рамках одной обработки.
Добавляем собственные шаги в форму выбора известных шагов (библиотечных шагов)
Мы создали объявление и реализацию новых шагов. Теперь, как мы видели выше, их можно использовать как в исходном сценарии, так и в любом другом сценарии, который будет загружен для проигрывания вместе с нашим сценарием.
Но эти шаги из числа тех, которые не записываются “кнопконажималкой”. Сейчас нам приходится набирать их вручную. Упростить набор помогает плагин Gherkin Autocomplete (его установка для Visual Studio Code описана здесь).
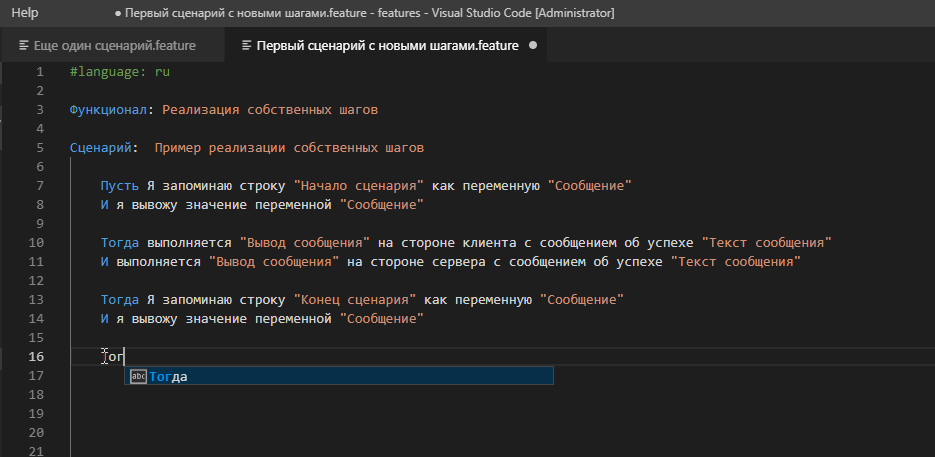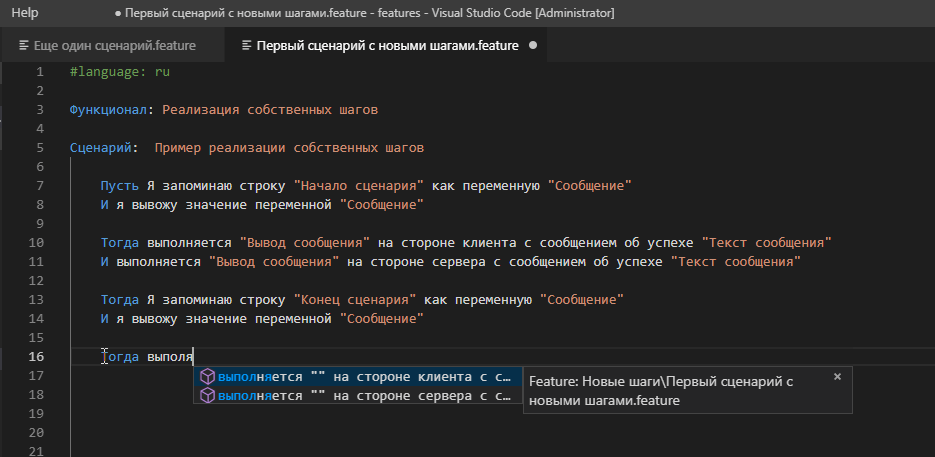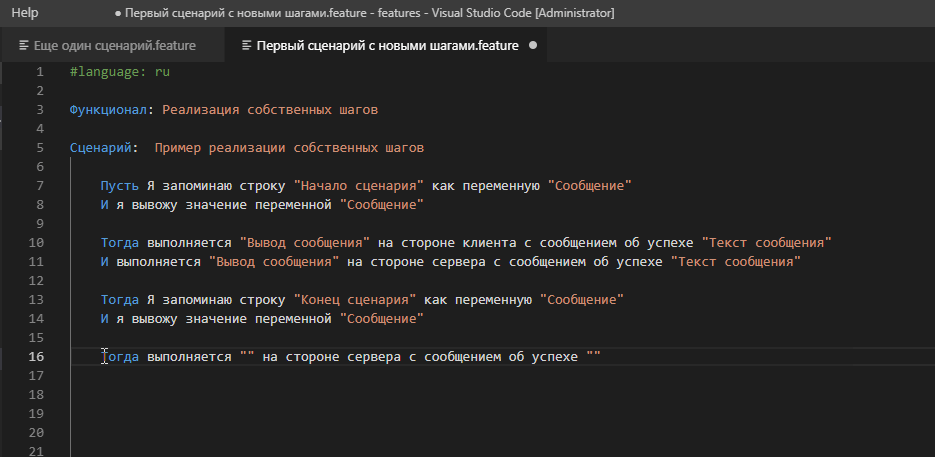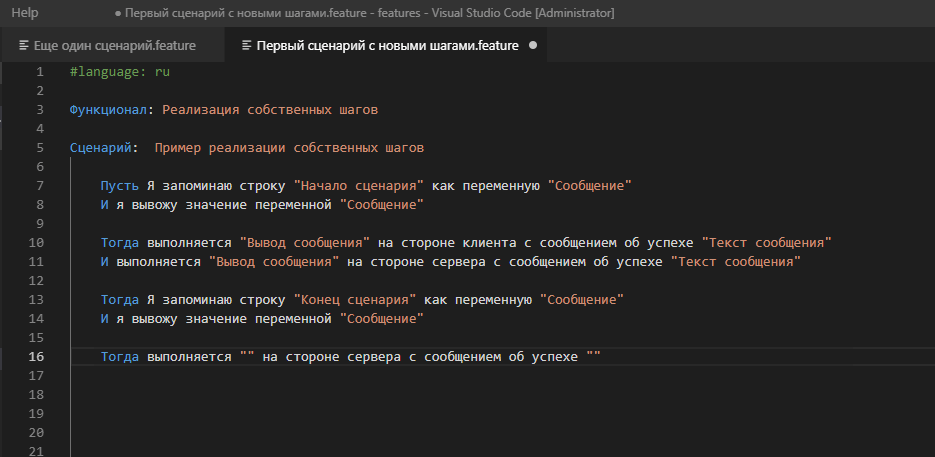
Часто более удобным способом быстрого набора шага является его выбор или копирование его описания из формы известных шагов. Но если сейчас мы зайдем в форму известных шагов и попытаемся найти там наше творчество по ключевым словам, то результата не получим :
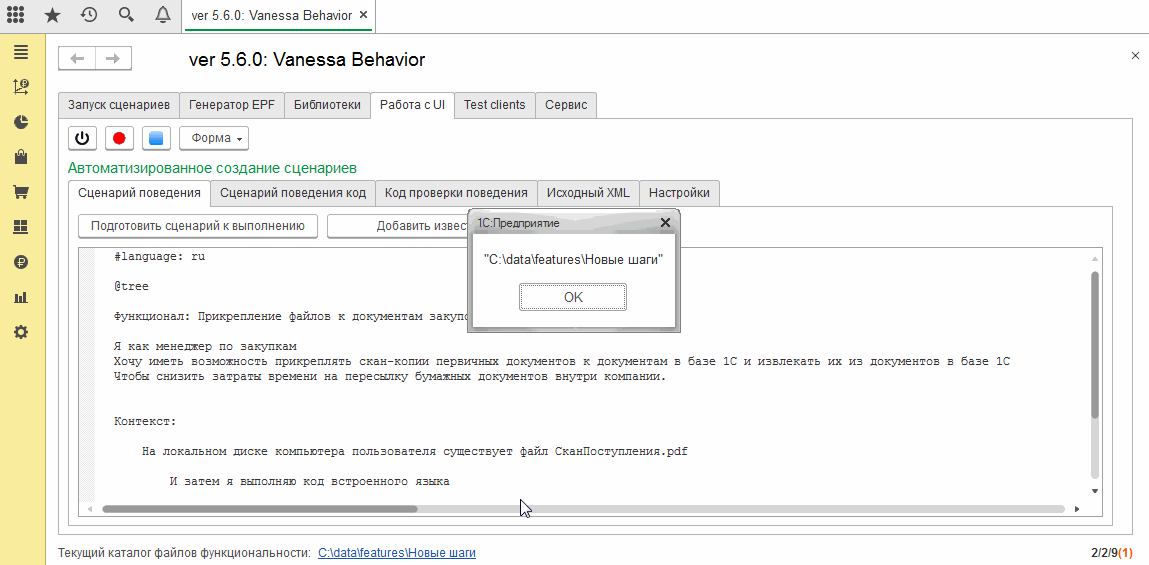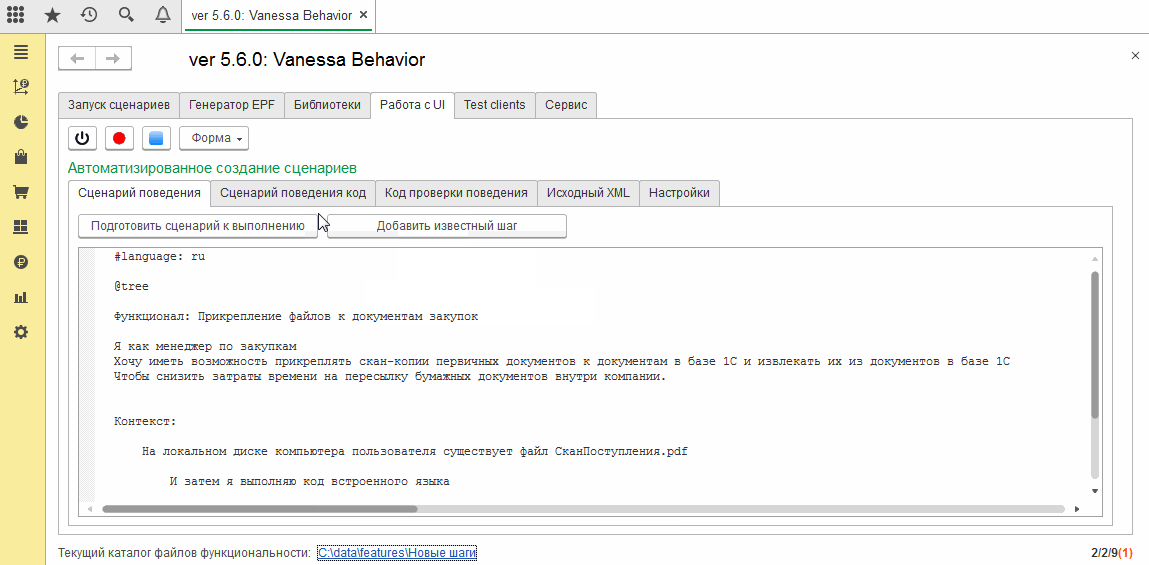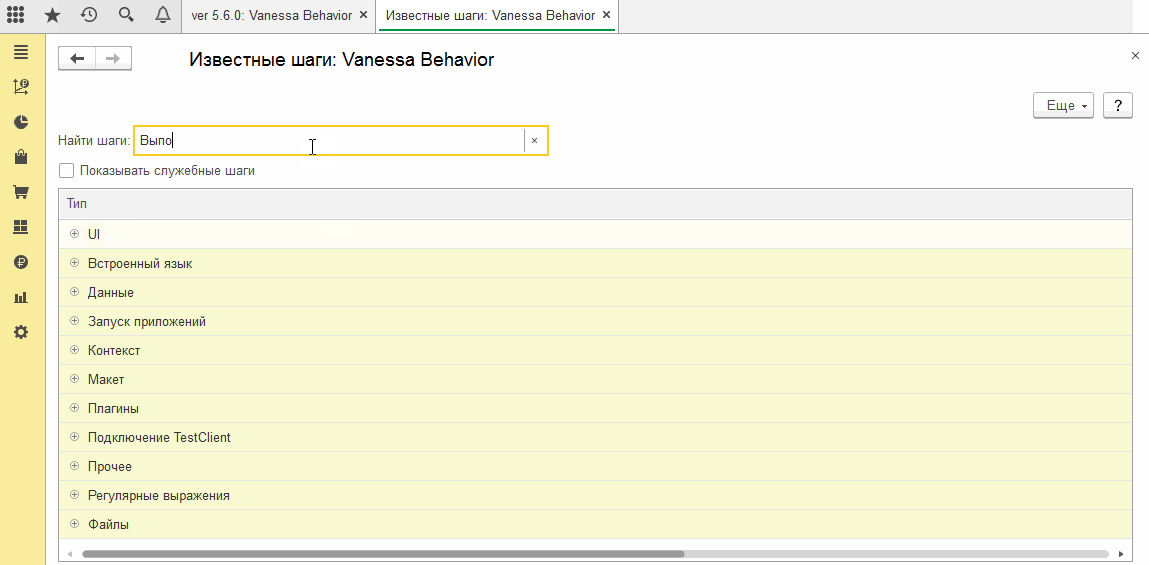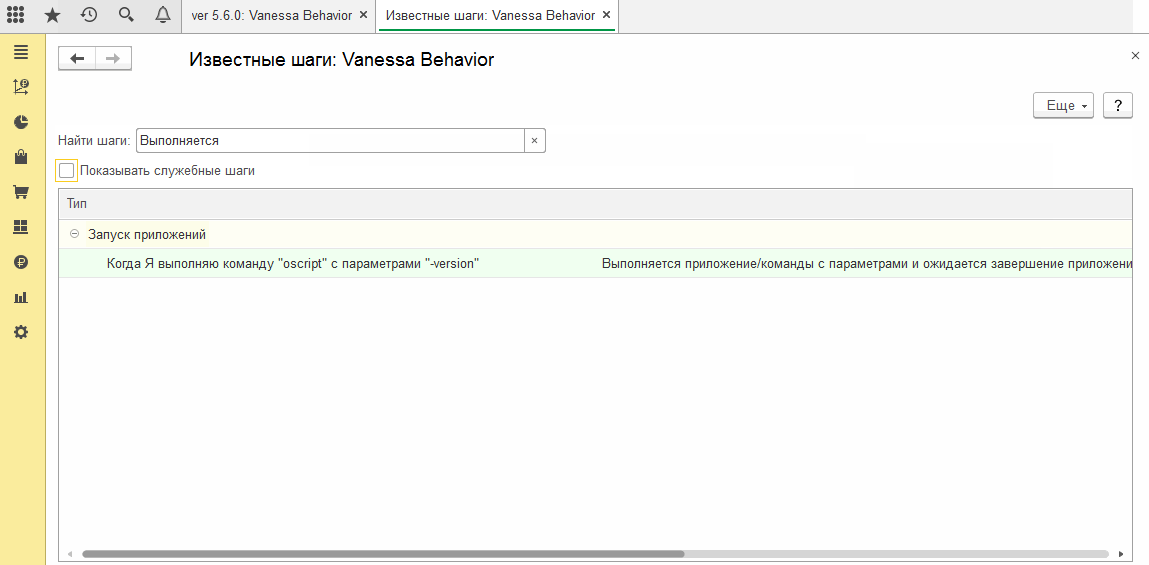
Можно было бы подумать, что здесь отображаются только шаги встроенной библиотеки. Но это не так. Обратимся к документации https://github.com/silverbulleters/add/blob/master/F.A.Q.MD и информации на формуме https://xdd.silverbulleters.org/t/add-a-mozhno-dobavit-svoi-bibliotechnye-shagi/2176:
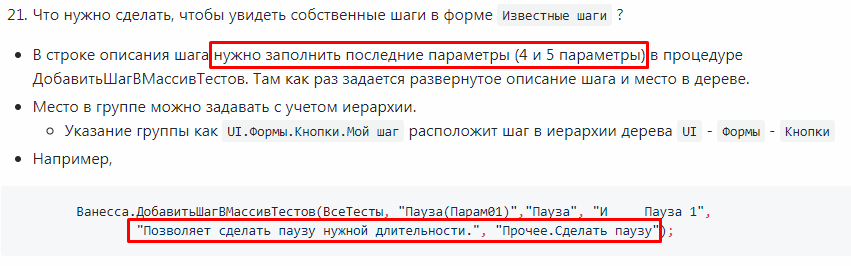
Оба параметра, о которых идёт речь, должны быть заполнены, иначе шаг не будет добавлен в форму выбора известных шагов.
Последний параметр определяет группу-папку шагов в форме выбора известных шагов. Если написать Папка 1.Папка 2.Папка 3, то это будет означать, что будет создано три группы, одна в другой. И шаг будет находится в последней из этих групп. (Здесь напрашивается аналогия со способом группировки событий в журнале регистрации).
Дополним описание наших шагов в соответствии с этой информацией и сохраним обработки :

Если перечитать загруженные для выполнения сценарии и снова обратиться к форме выбора известных шагов, то теперь мы увидим наши шаги. Мы сможем копировать их в Visual Studio Code через Ctrl+C , Ctrl+V и вставлять их в редактор bddRunner.epf двойным кликом по ним :
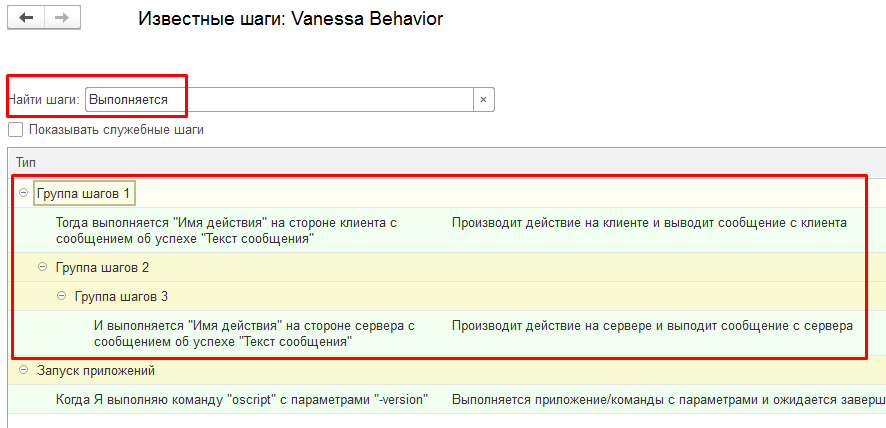
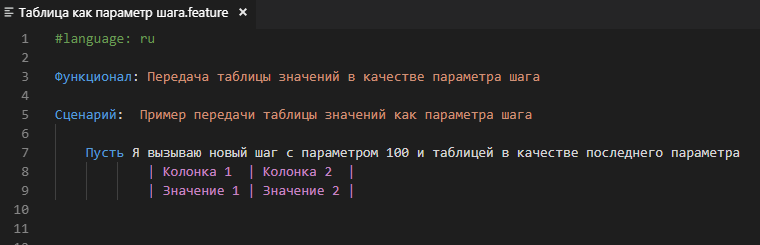
Таблица как параметр шага
В прошлых частях этого цикла публикаций мы уже не раз пользовались шагами, принимающими в качестве параметров таблицу. Из доступных примеров становится понятно, что среди параметров может быть только одна таблица и очевидно, что она выступает всегда последним параметром.
Реализуем свой шаг с таблицей в качестве параметра. Создадим сценарий с пока неизвестным шагом:
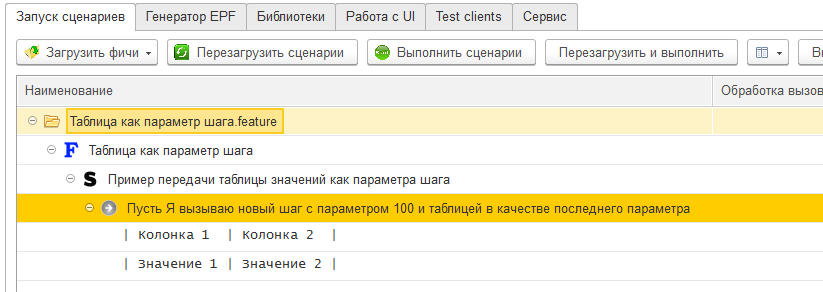
Сгенерируем для этого шага реализующую его внешнюю обработку :
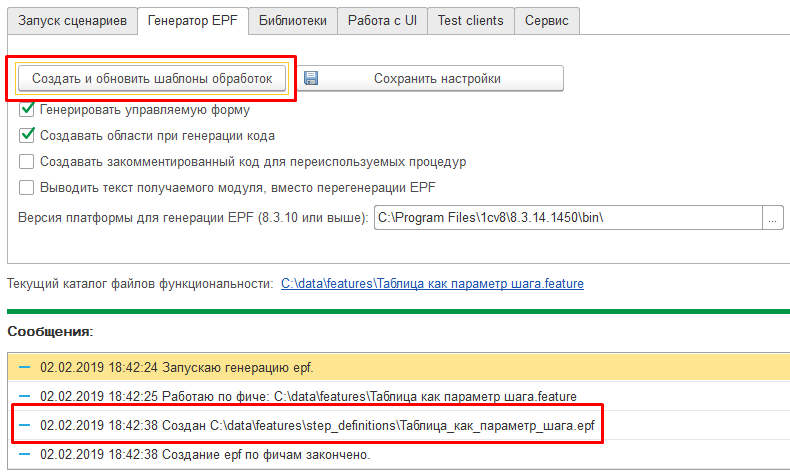
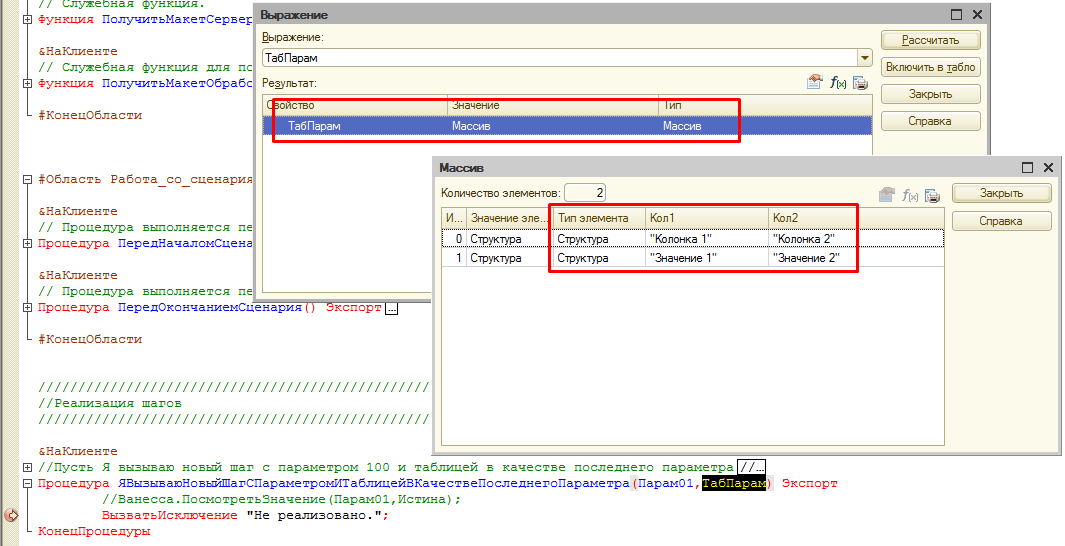
Уже в объявлении шага в модуле формы этой обработки видно, что шаг имеет два параметра и последний параметр был воспринят как таблица:
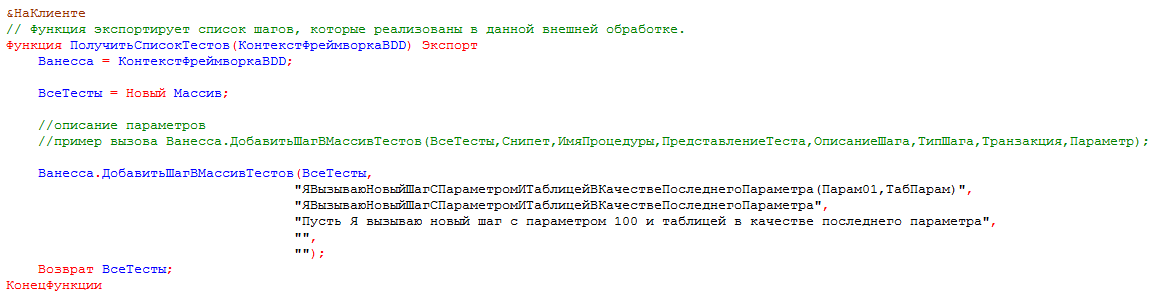
Попробуем вызвать исполнение этого шага и посмотрим, что приходит на вход реализующего его метода. Откроем реализующую шаг внешнюю обработку в конфигураторе и поставим точку останова в этом методе. После этого запустим сценарий с этим шагом на исполнение:
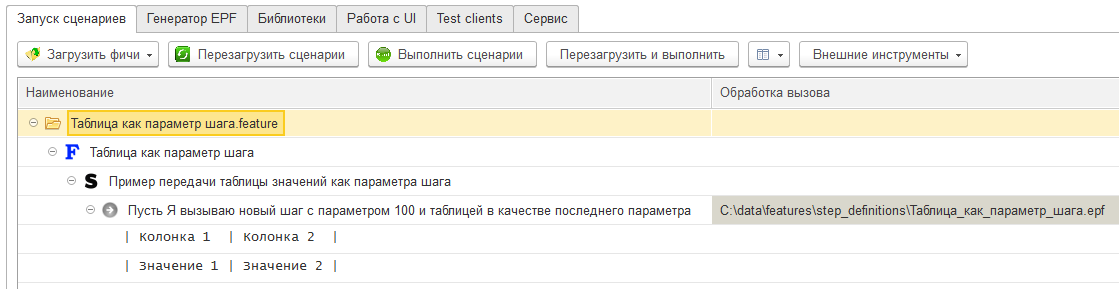
Так как исполнение шага всегда начинается со стороны клиента, то тип значения ТаблицаЗначений очевидно недоступен в методе, реализующем шаг. Вместо этого таблица представляется как массив структур.
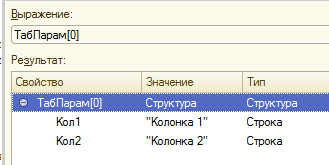
Но при этом компоновка данных в этом массиве необычная. Ключами структур являются автоматически сгенерированные имена: Кол1, Кол2, Кол3 и так далее. А уже значениями ключей являются строки, которые мы передавали шагу. Это объясняется тем, что не всегда возможно сделать значения из первой строки ключами структуры. Ведь даже в этом примере мы использовали в них пробелы: “Колонка 1”, “Колонка 2”... Такие ситуации должны корректно обрабатываться. Поэтому первая строка таблицы не воспринимается как строка с заголовками-ключами. Она является такой же строкой таблицы как и все остальные:
Создаём собственные библиотеки шагов
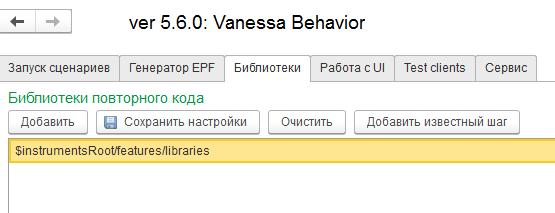
Перейдем ко вкладке “Библиотеки”. Здесь мы видим путь к встроенной в Vanessa-ADD библиотеки шагов. Она содержит все те шаги, которые автоматически записываются “кнопконажималкой” и множество дополнительных шагов, доступных для ручного добавления в сценарии :
Что такое библиотека шагов?
Библиотека шагов для Vanessa-ADD - это просто каталог со сценариями и внешними обработками, которые содержат описания шагов и методы, реализующие эти шаги. Любой каталог с файлами .feature и лежащими рядом с ними внешними обработками, содержащими объявления и реализации шагов может восприниматься как библиотека шагов.
Более того, когда мы открываем в Vanessa-ADD отдельный feature-файл на исполнение, то каталог, в котором он расположен, неявно обрабатывается точно также как библиотека шагов. Если мы открываем в Vanessa-ADD на исполнение целый каталог с фича-файлами, то весь этот каталог обрабатывается также как библиотека шагов. Открываемый на выполнение каталог является библиотекой шагов для самого себя. Именно благодаря этому мы можем создать шаг и его реализацию в одном feature-файле и внешней обработке, а обращаться к этому шагу в другом файле, находящимся в том же каталоге.
То есть Vanessa-ADD при открытии файлов на выполнение одинаково равноправно опрашивает:
1) каталоги указанные на вкладке “Библиотеки” (со всеми их подкаталогами)
2) каталог загруженный для выполнения во вкладку “Запуск сценариев” или каталог, содержащий загруженный на исполнение файл (со всеми его подкаталогами).
Таким образом, с точки зрения поиска шагов и их реализаций, каталоги библиотек ничем не отличаются от каталога с фича-файлами, загруженного для выполнения. Отличие библиотек не физическое, а логическое. Они не содержат фича-файлы предназначенные для непосредственного исполнения, а содержат описания шагов, предназначенных для использования в фича-файлах вне этих библиотек.
Все шаги, описание которых найдено в экспотрных методах ПолучитьСписокТестов модулей форм этих обработок, становятся доступными для исполнения в наших сценариях. Если же при вызове Ванесса.ДобавитьШагВМассивТестов в методах ПолучитьСписокТестов задать пользовательское описание этих шагов, то мы сможем видеть их и в форме выбора известных (библиотечных) шагов.
Также важно понимать, что Vanessa-ADD опрашивает именно внешние обработки, а не feature-файлы. Соответствующие им feature-файлы служат, во первых, как “человеческий” интерфейс, чтобы нам было проще понимать, что за шаги реализуются лежащими рядом с этими файлами внешними обработками. Во вторых, наличие feature-файлов позволяет использовать плагин автодополнения в Visual Studio Code. И в третьих, эти файлы изначально служат для генерации внешних обработок для этих библиотек.
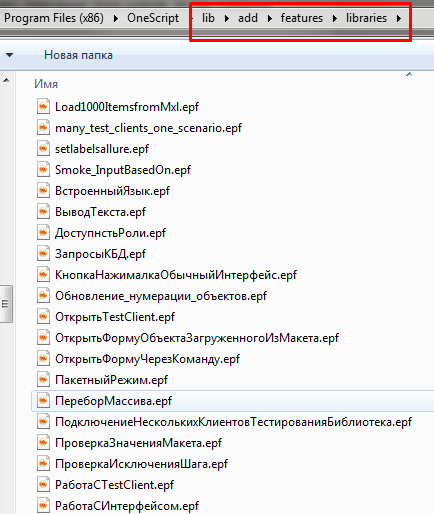
Так например если из каталога $instrumentsRoot/features/libraries (обычно это C:\Program Files (x86)\OneScript\lib\add\features\libraries) удалить все feature-файлы, но оставить внешние обработки, то почти все шаги этой встроенной библиотеки по прежнему будут загружаться в список известных шагов и выполняться в наших сценариях (за исключением шагов, реализуемых через экспортные сценарии, о которых пойдет речь далее). Разумеется при этом мы лишимся возможности заглянуть в feature-файл, где описана цель создания этих шагов, и в удобной форме увидеть описание этих шагов. И лишимся автодополнения в Visual Studio Code.
Закрепим также понимание, что расположение внешних обработок в подкаталогах не важно. Можно взять все внешние обработки и переместить их в корень $instrumentsRoot/features/libraries:
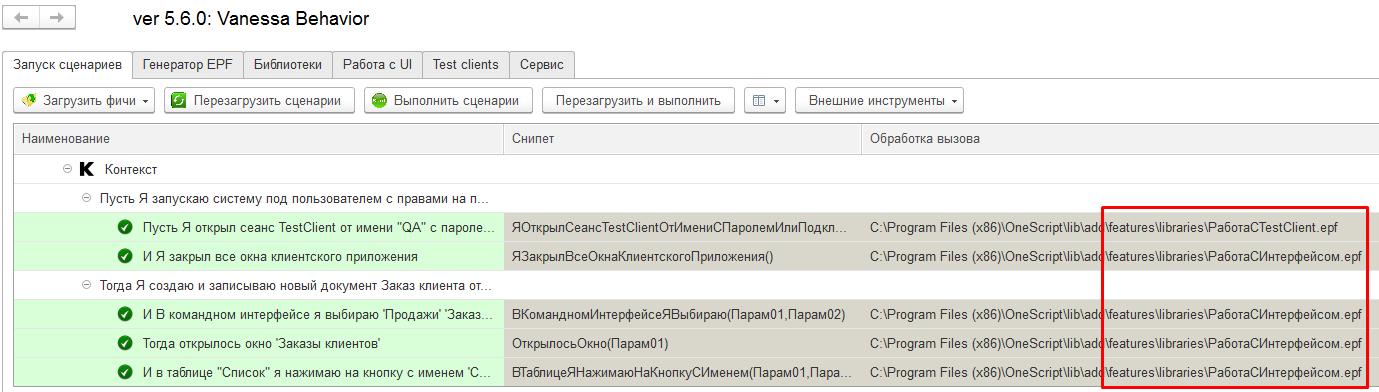
После этого библиотечные шаги продолжат не только успешно загружаться, но и будут успешно выполняться :
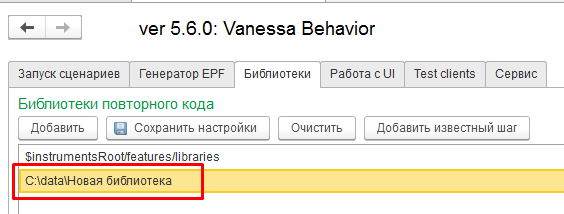
Указание путей к своим библиотекам
Пути к новым библиотекам шагов указываются на той же вкладке, что и путь ко встроенной библиотеке:
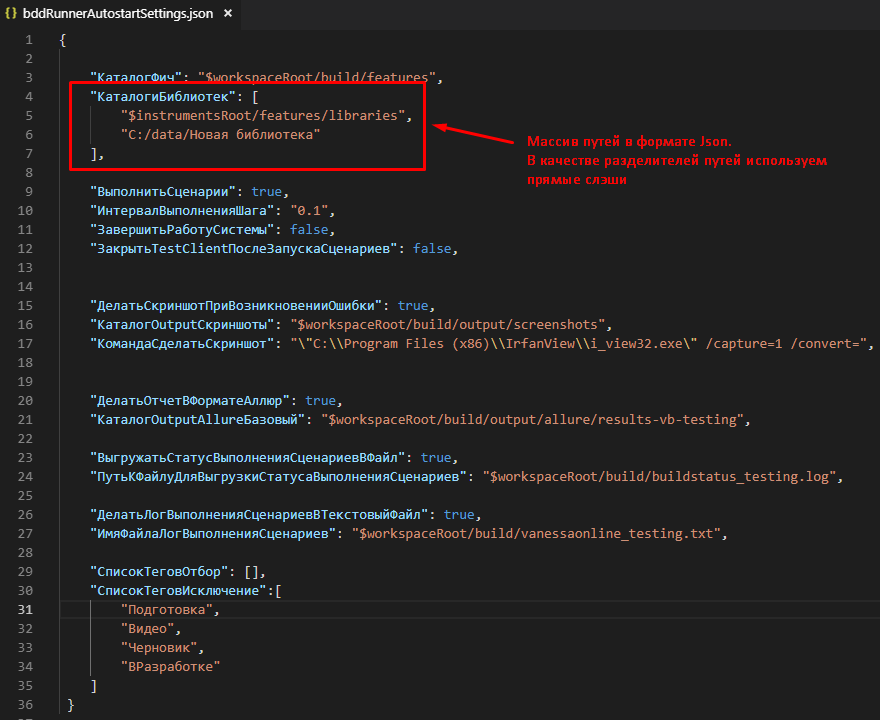
А при автоматическом запуске те же пути указываются в специальном json-файле :
Здесь хотелось бы сразу сказать, что на момент этой публикации в версии Vanessa-ADD 5.6.0 существует ошибка https://github.com/silverbulleters/add/issues/401, которая не позволяет через графический интерфейс сохранить на вкладке “Библиотеки” пути к нескольким библиотекам. При следующем открытии bddRunner.epf мы увидим опять только одну строку со встроенной библиотекой.
Эта ошибка будет устранена в ближайшем релизе Vanessa-ADD и уже отсутствует в develop-ветке продукта:
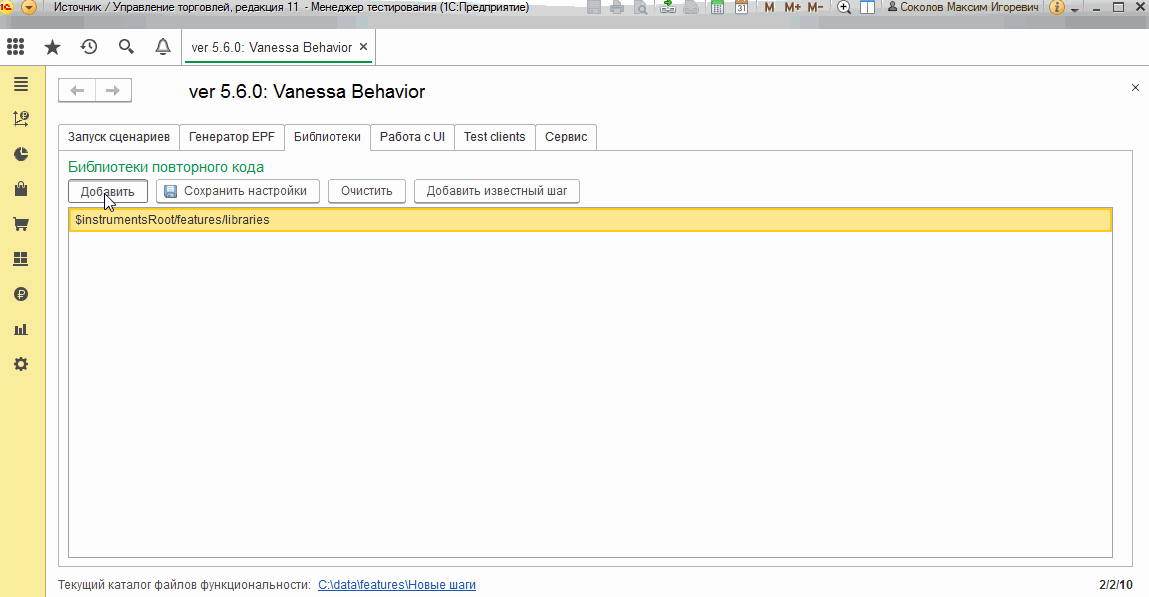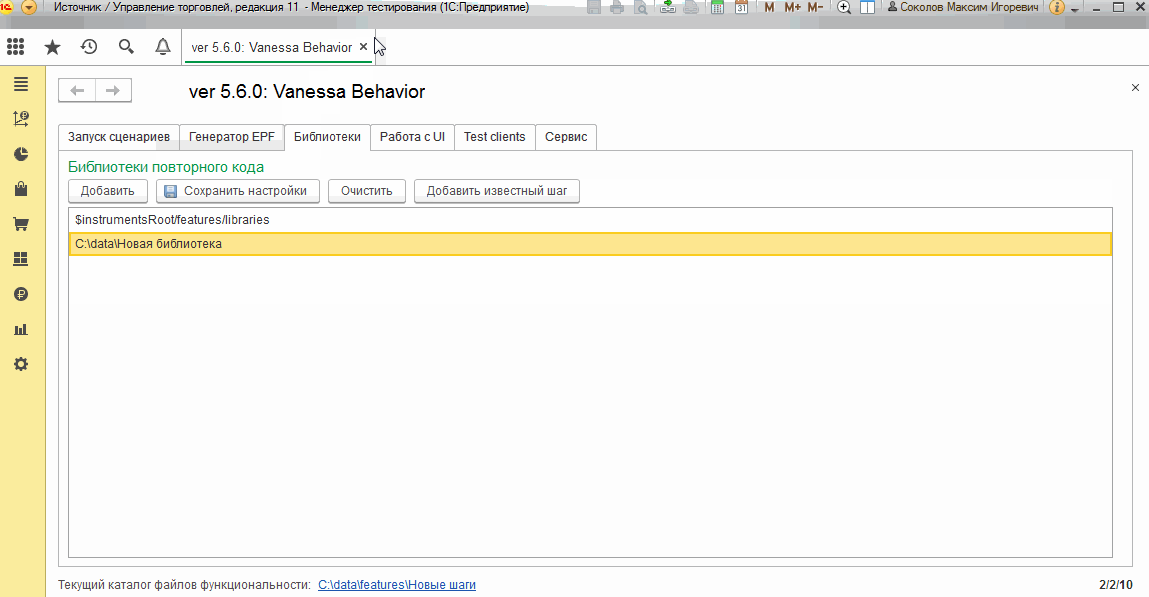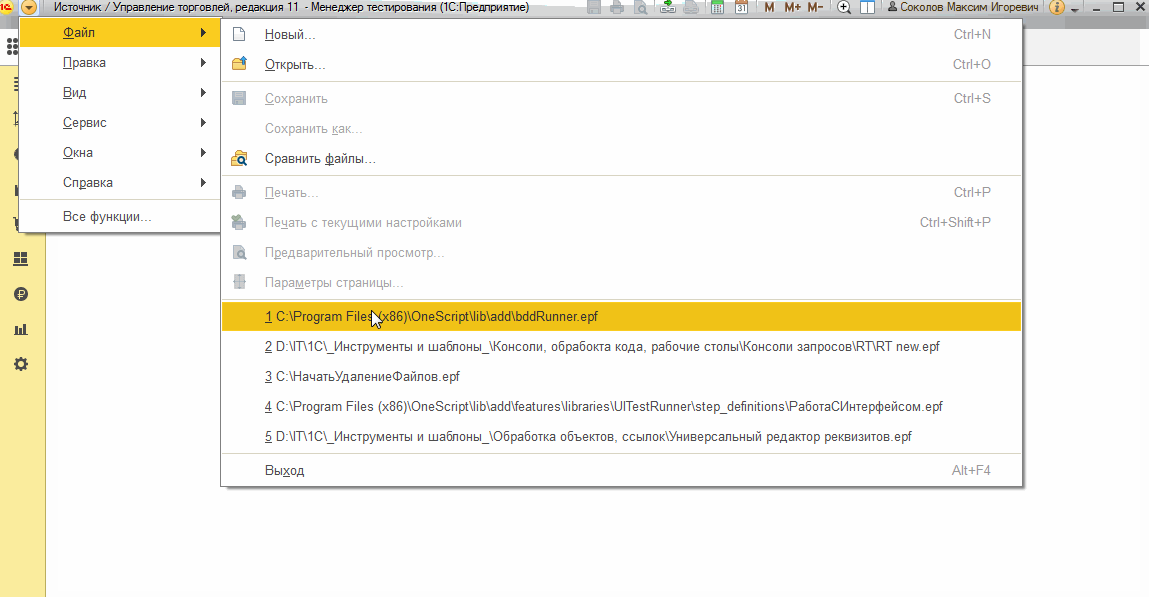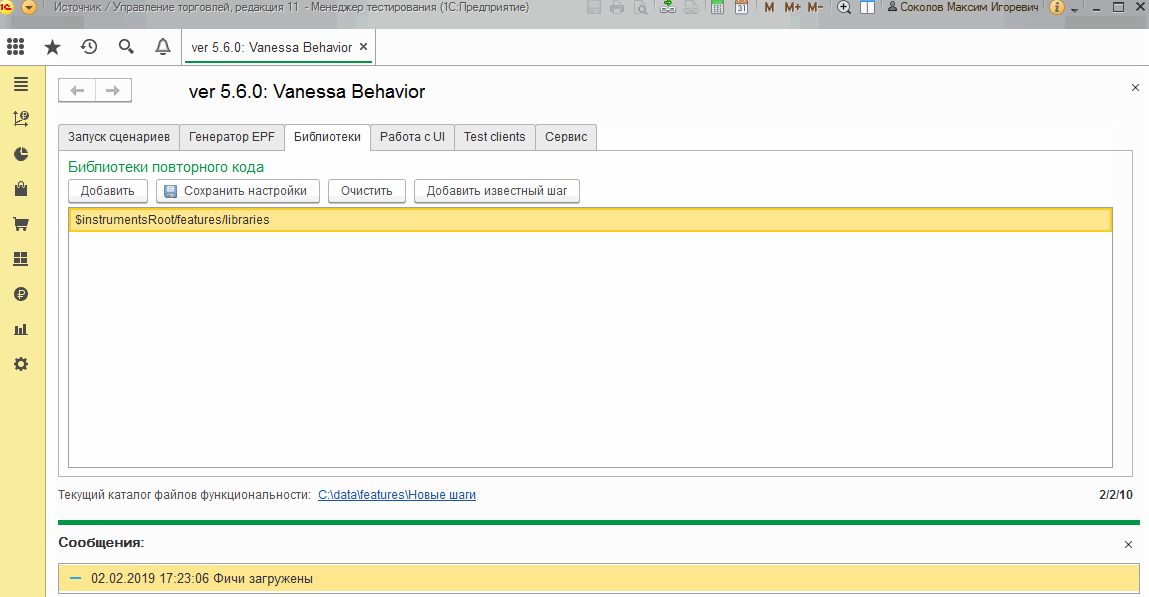
Несмотря на то, что мы не можем сохранить пути к библиотекам, мы всё же можем добавить их после открытия обработки bddRunner.epf и перечитать сценарии с шагами из новых библиотек. Также корректно работает механизм автозапуска с заданием библиотек в Json-файле (автозапуск и запуск из консоли - это тема следующей публикации, если Вы ещё не знакомы с этой темой, то сейчас на ней не стоит сосредотачиваться) :
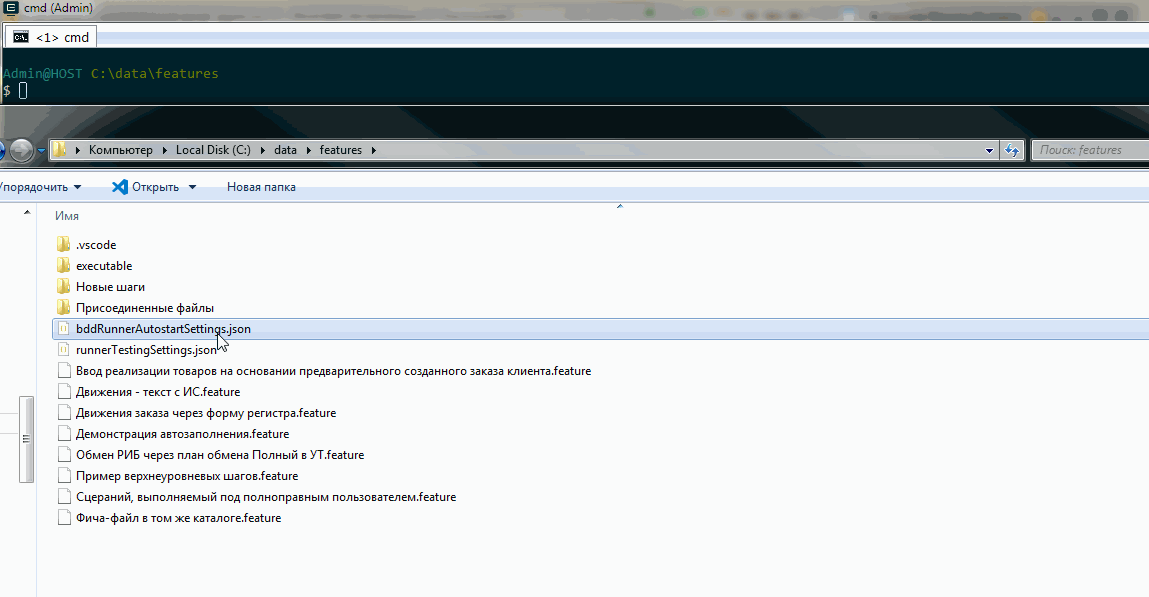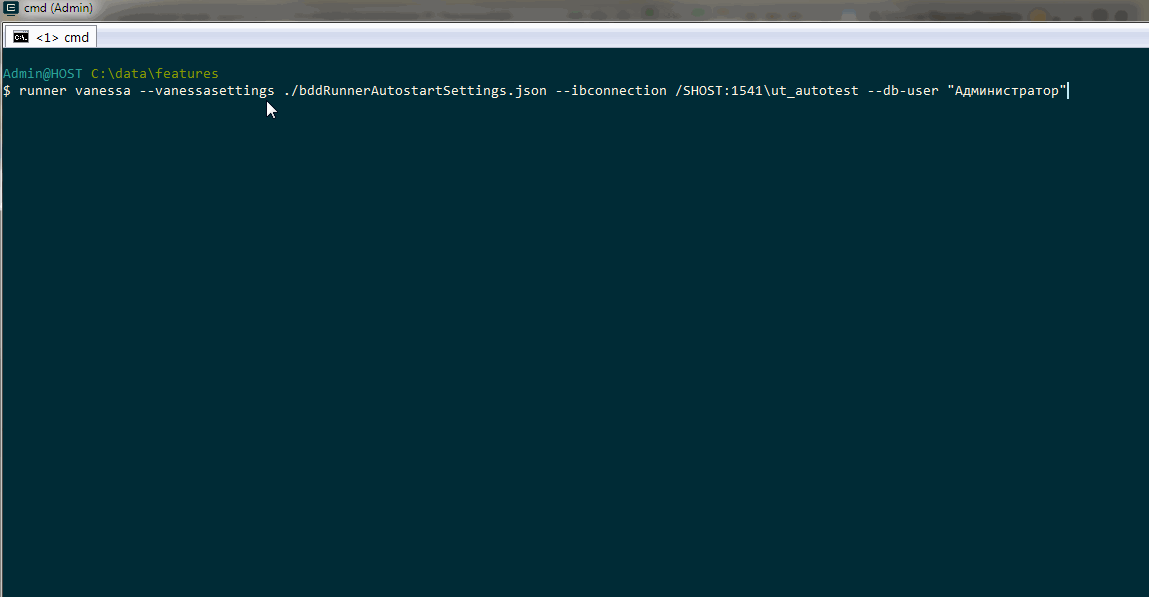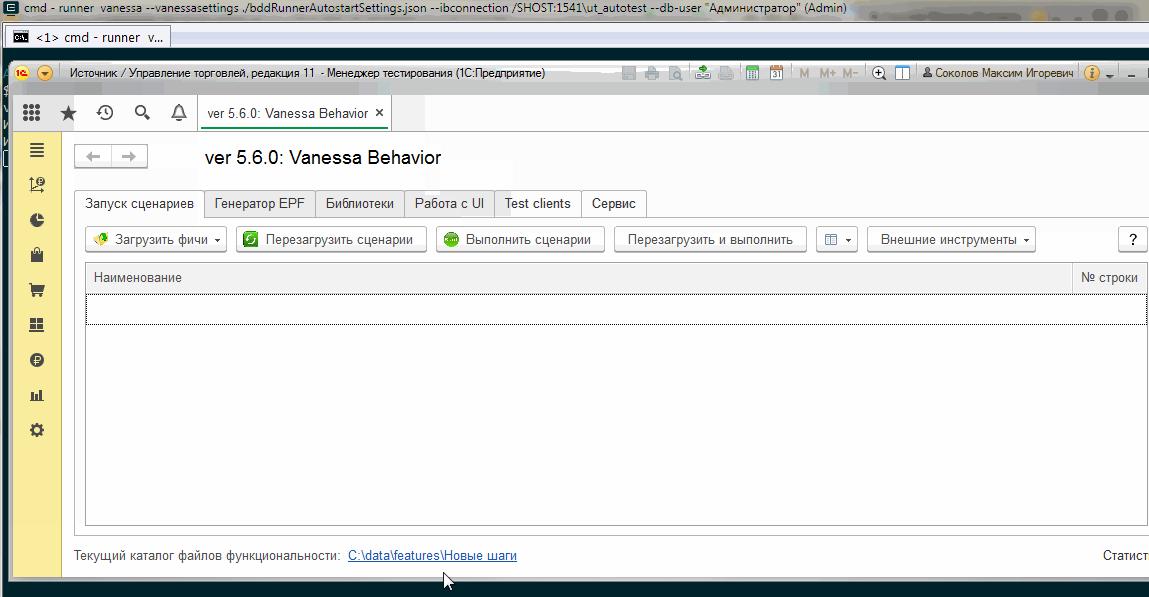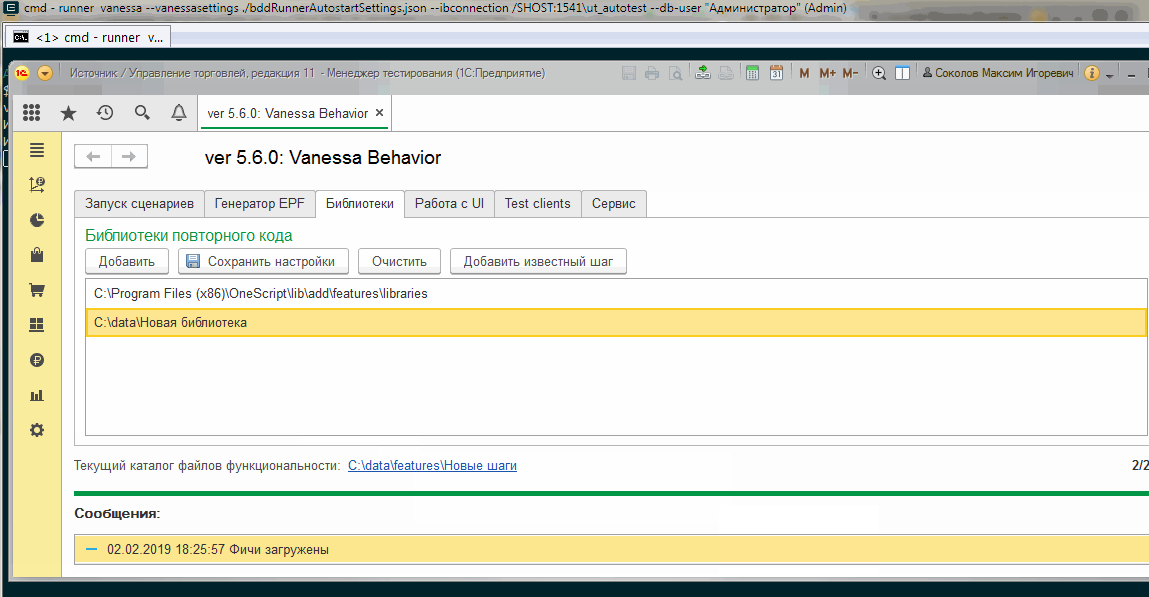
Таким образом несмотря на ошибку с восстановлением настроек при интерактивном открытии bddRunner.epf мы ориентируемся на то, что механизм подключения новых библиотек является рабочим и будем говорить о размещении библиотек исходя из того, что можем свободно добавлять их как на вкладку “Библиотеки” с последующей перезагрузкой сценариев, так и прописывать свои библиотеки в Json-файле для запуска из командной строки.
В примере выше мы указывали абсолютные пути к библиотекам.
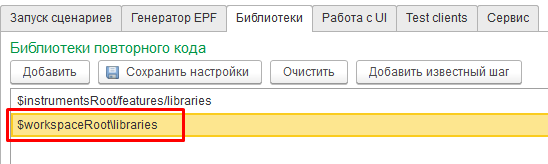
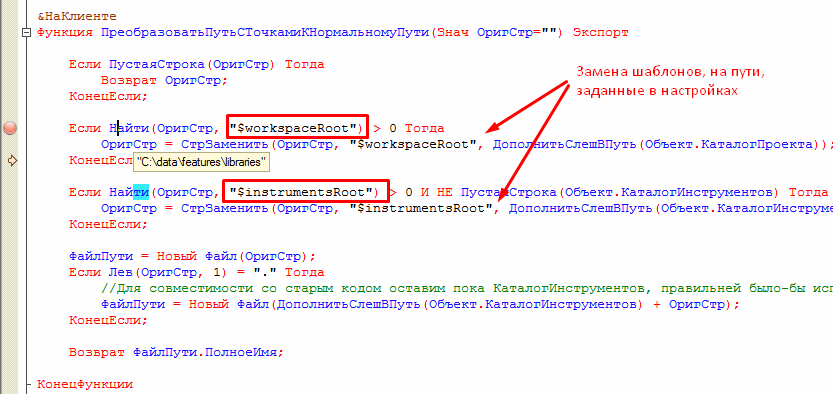
Но также можно задавать относительные пути. В качестве шаблонов подстановки при указании каталогов могут выступать $workspaceRoot (каталог проекта) и $instrumentsRoot (каталог установки Vanessa-ADD). Например в качестве пути можно указать $workspaceRoot\libraries:
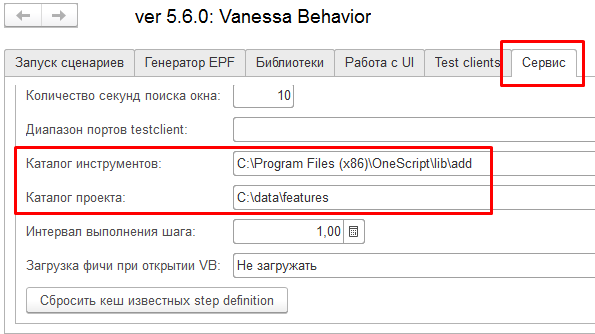
Как мы помним каталог инструментов $instrumentsRoot и каталог проекта $workspaceRoot задаются через интерфейс обработки на вкладке “Сервис”, а при запуске из консоли в файле json (который мы видели выше) :
Шаблоны, отличные от $instrumentsRoot и $workspaceRoot, при указании путей к библиотекам не поддерживаются. Для их поддержки можно внести модификацию в метод “ПреобразоватьПутьСТочкамиКНормальномуПути” модуля формы обработки bddRunner.epf, но в этом случае усложняется обновление Vanessa-ADD на новые релизы и после обновления модификацию необходимо будет повторить :
Все каталоги, перечисленные на вкладке “Библиотеки” должны существовать. Если хотя бы один из каталогов не будет существовать или не будет доступен, то Vanessa-ADD вообще не загрузит никаких шагов и при этом даже не сообщит об ошибках. Мы просто не увидим наш сценарий на вкладке “Запуск сценариев”.
Где лучше располагать свои библиотеки?
Итак, мы теперь знаем, что свои библиотеки можно размещать как по абсолютному пути, так и по относительному.
В прошлой публикации при создании сценария работы с прикрепленными файлами мы уже говорили о том, что абсолютных путей следует всячески избегать. То же самое справедливо и для библиотек шагов. Одним из основных направлений применения Vanessa-ADD является автоматизация регрессионного тестирования на CI-контуре, для которого абсолютные пути в настройках - это препятствие к масштабированию и гибкости конфигурирования. Таким образом лучше выбирать из двух оставшихся вариантов исходя из соображений представленных ниже.
1) Первым удобным вариантом расположения библиотек является их помещение непосредственно в каталог OneScript/lib/add/features или даже в OneScript/lib/add/features/libraries. Ни при обновлении библиотеки add через команду opm update add, ни при её переустановке через команду opm install add ваши собственные каталоги, находящиеся на любом уровне иерархии в OneScript/lib/add, не будут удалены.
Хотя конечно лучше позаботиться об их безопасности и работать со своей библиотекой например как с git-репозиторием.
Если библиотека шагов достаточно универсальна и используется для нескольких проектов (например проект и CI-контур для ERP может использовать ту же библиотеку, что и проект и CI-контур для ЗУП), то такой вариант расположения будет наиболее прост и удобен.
2) Вторым удобным вариантом расположения является помещение библиотек непосредственно в каталог проекта. Например указать $workspaceRoot\project_librararies. Сами же исполняемые фича-файлы можно расположить рядом, например в каталоге $workspaceRoot\features.
Этот вариант удобен, если библиотека специфична для какого-то проекта. Например если создана библиотека для работы с производственным контуром в ERP и конфигурация ERP у нас только одна, то не имеет смысла делать библиотеку общей для нескольких проектов и размещать ее в каталоге установки OneScript. Можно разместить ее рядом с каталогом, содержащим специфические фича-файлы для ERP.
Если же одна и та же библиотека используется в нескольких проектах, то при таком варианте размещения её придется продублировать для каждого проекта. В этом случае лучше задействовать git и его подмодули или поддеревья, иначе поддерживать актуальность одной и той же библиотеки в каждом проекте будет сложно. Либо рассмотреть первый вариант и размещать библиотеку в каталоге установки Vanessa-ADD.
Преобразуем новые шаги в простейшую библиотеку
Ранее мы создали три новых простых шага
Тогда выполняется "Имя действия" на стороне сервера с сообщением об успехе "Текст сообщения"
Тогда выполняется "Имя действия" на стороне клиента с сообщением об успехе "Текст сообщения"
И Я выполняю какой-то шаг перед тем как вызывать уже реализованные
Мы уже знаем, что каталог со сценариями, содержащими новые шаги, и внешними обработками, содержащими объявление и реализацию шагов, может восприниматься как библиотека шагов. До сих пор мы воспринимали их как исполняемые сценарии.
Теперь создадим в каталоге установки Vanessa-ADD подкаталог “Новая библиотека” в который переместим все наши сценарии и внешние обработки, созданные при экспериментах с новыми шагами.
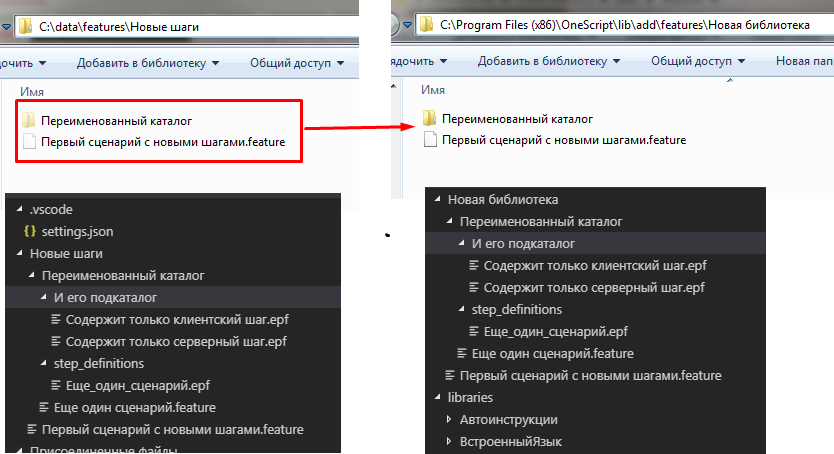
Собственно на этом создание первой библиотеки уже закончено )) Путь к этой библиотеке можно указывать как $instrumentsRoot/features/Новая библиотека.
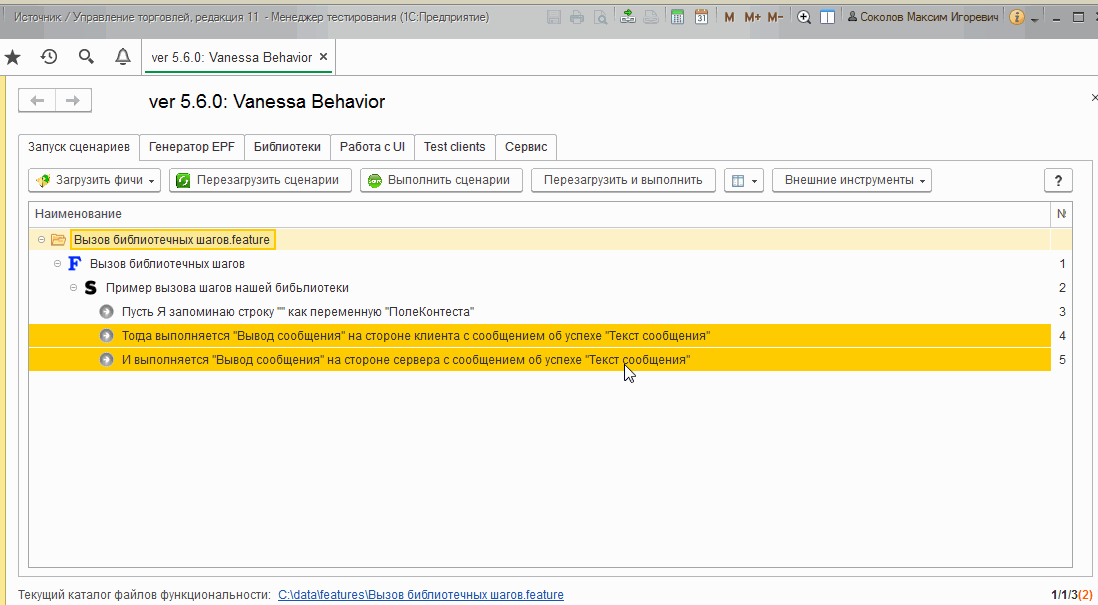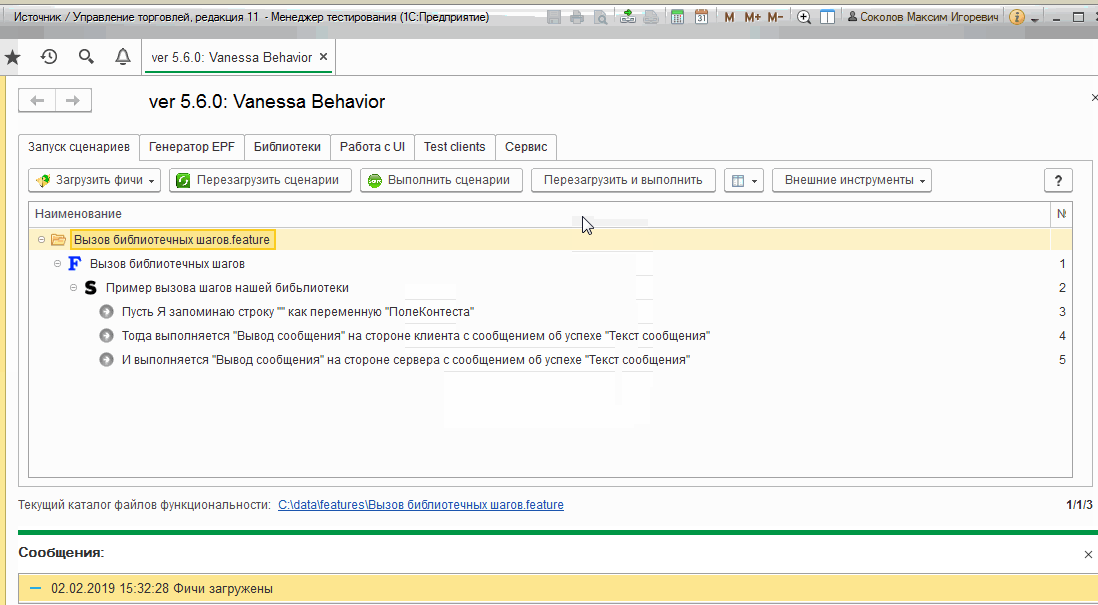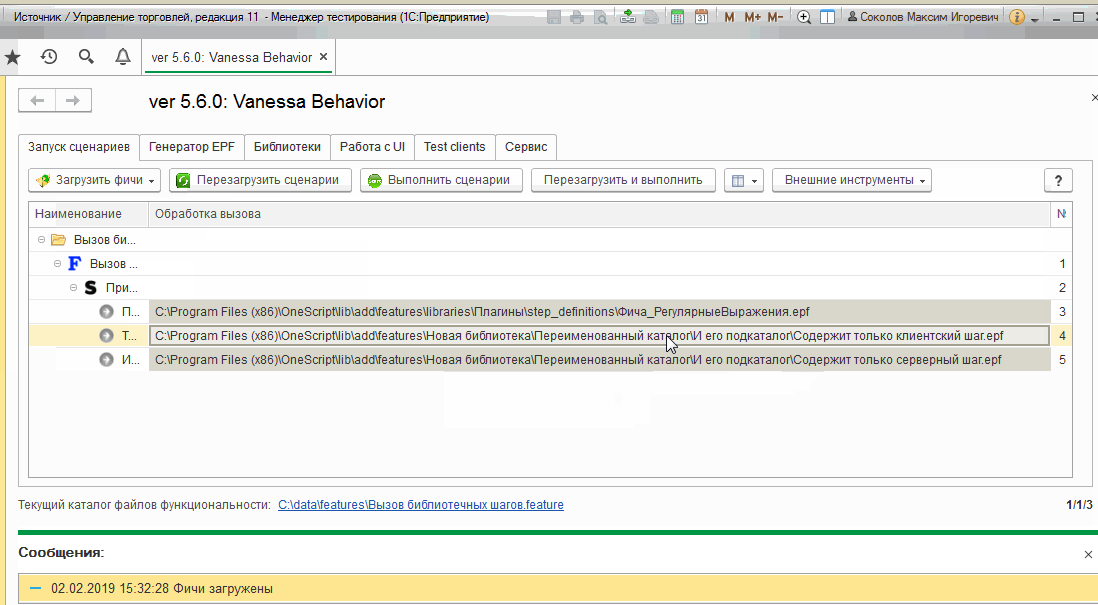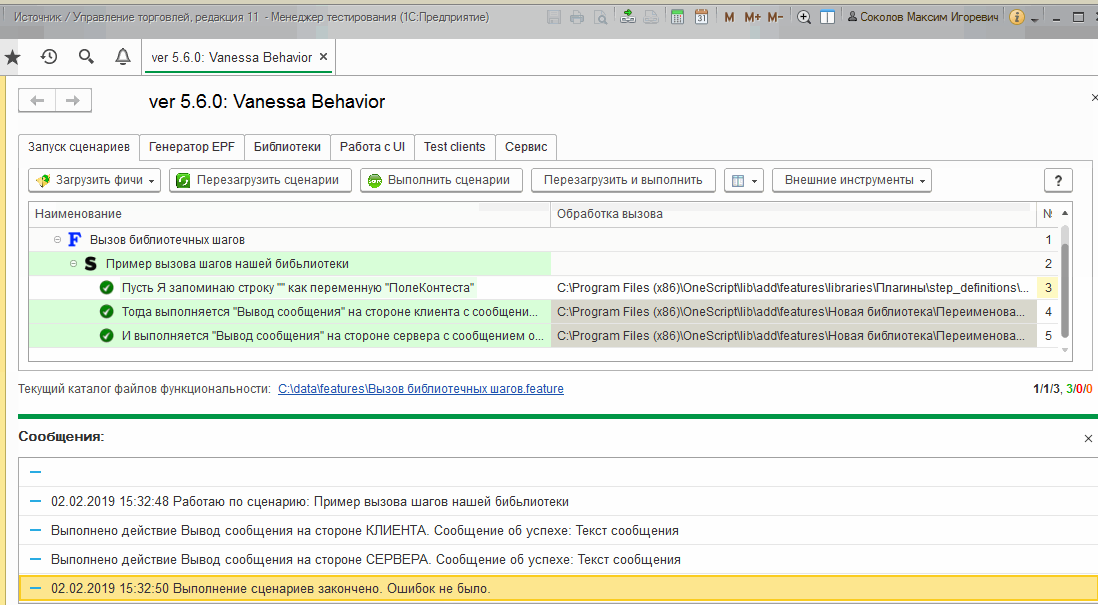
Создадим новый файл C:\data\features\Вызов библиотечных шагов.feature со следующим содержимым:
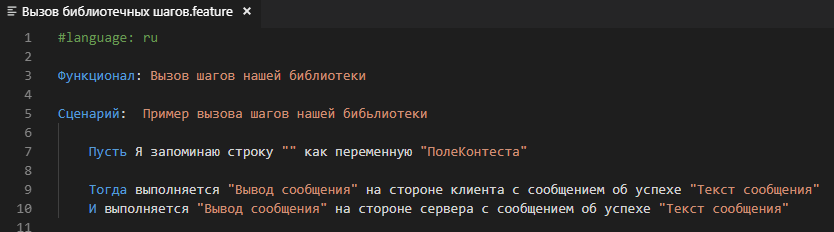
Теперь для исполнения наших новых библиотечных шагов после загрузки этого фича-файла достаточно добавить на вкладку “Библиотеки” путь $instrumentsRoot/features/Новая библиотека и ещё раз перезагрузить сценарии. Пути к реализующим шаги обработкам будут определены как пути к обработкам внутри нашей библиотеки:
При этом шаги нашей библиотеки по прежнему доступны для выбора из формы известных шагов, ведь их определение во внешних обработках осталось прежним :
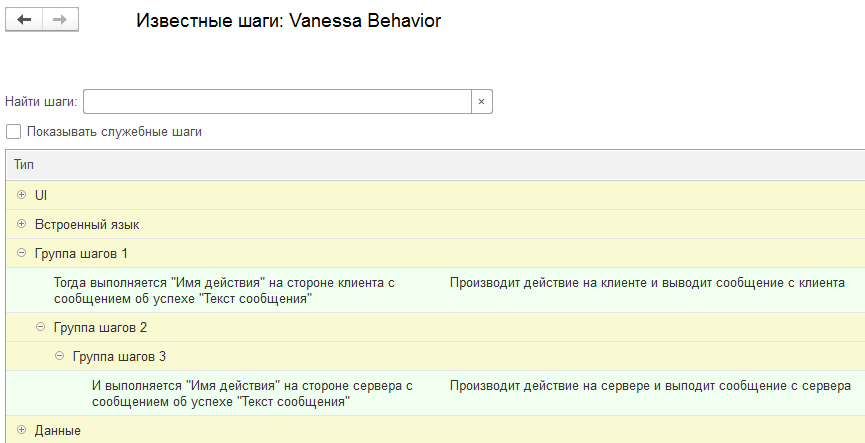
Конечно оформлять библиотеку таким образом, как сделано в этом примере некорректно, по крайней мере в отношении фича-файлов.
К написанию библиотечных фича-файлов следует подходить не менее дисциплинированно, чем к написанию функциональных фича-файлов. Так, чтобы заглянув в файл, можно было легко понять зачем нужны реализуемые библиотекой шаги и как их правильно использовать. Ведь смысл фича-файлов именно в том, чтобы быть понятными человеку.
За образец можно брать фича-файлы встроенной библиотеки шагов, которые как правило оформлены очень хорошо:
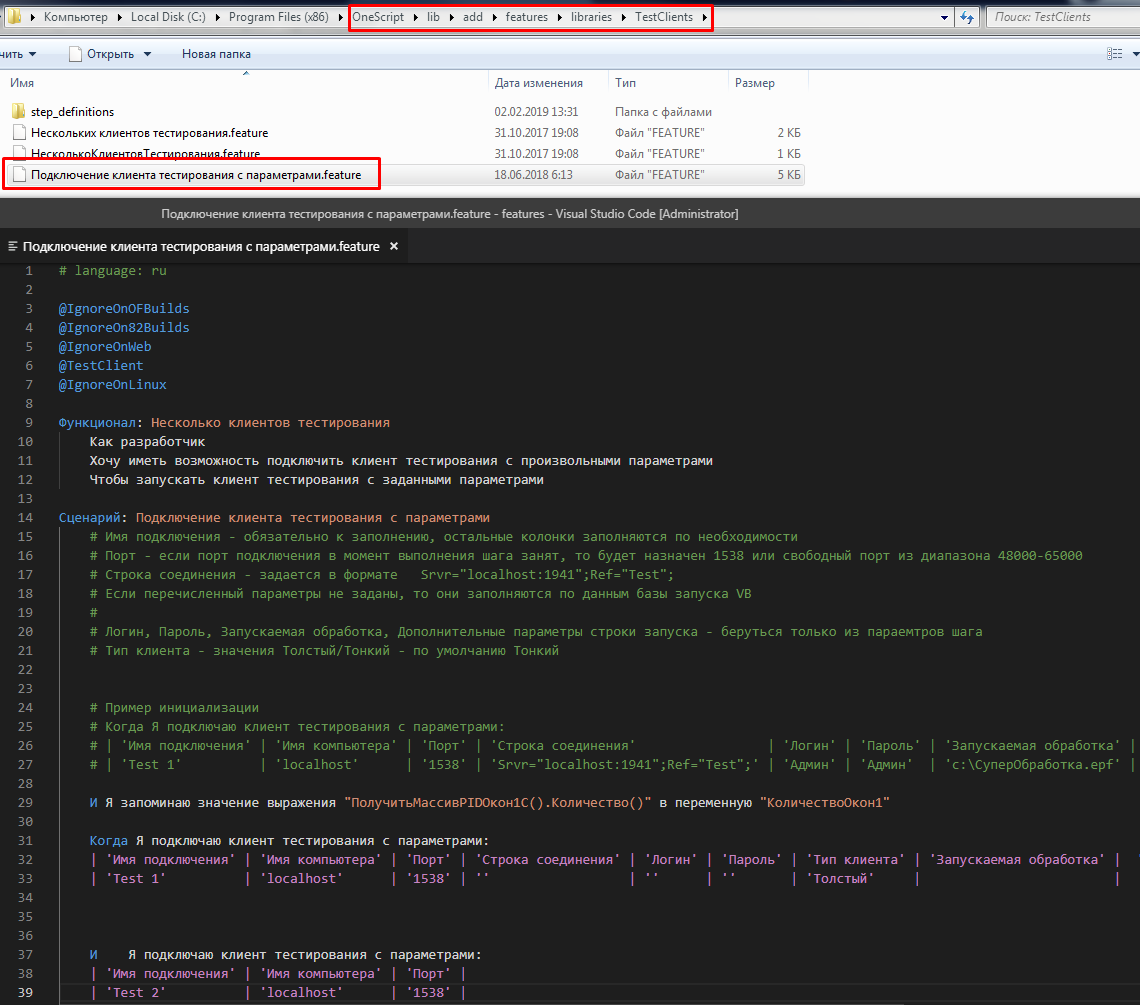
Экспортные сценарии
Получить обзорную информацию по экспортным сценариям можно на форуме xdd.silverbulleters.org по по ключевому слову ExportScenarios: https://xdd.silverbulleters.org/search?q=ExportScenarios
Также информация есть в вебинаре Леонида Паутова https://youtu.be/KbImzcrj_58?t=4840 (в ссылке таймстэмп на момент с которого начинается демонстрация).
Создаём и используем первые шаги, реализованные через экспортные сценарии
Что такое экспортный сценарий? Это реализация нового шага, но не через внешнюю обработку, а через набор последовательно исполняемых шагов Gherkin. Сами шаги экспортного сценария должны быть реализованы либо через внешние обработки, либо через другие экспортные сценарии. При этом представление шага, реализуемого экспортным сценарием совпадает с заголовком этого сценария.
Экспортные сценарии - это расширение языка Turbo Gherkin, разработанное для того, чтобы дать возможность многократно переиспользовать сценарии и повысить уровень абстракции в исполняемых сценариях.
Мы уже знакомы со служебным тегом @tree, позволяющим задействовать другое расширение языка Turbo Gherkin - возможность создавать группы шагов. Для того, чтобы превратить сценарии фича-файла в экспортные, нам потребуется ещё один служебный тег - @ExportScenarios.
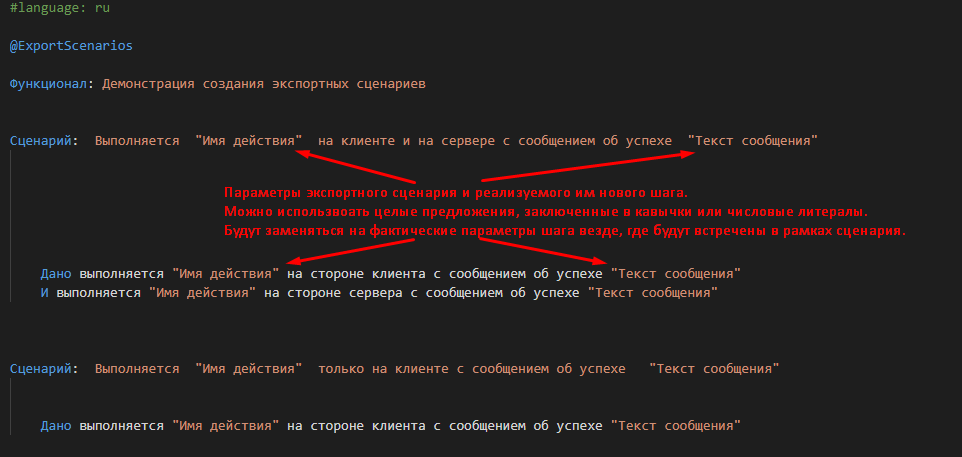
Создадим в нашем каталоге C:\data\features файл Первый экспортный сценарий.feature со следующим содержимым:
#language: ru
@ExportScenarios
Функционал: Демонстрация создания экспортных сценариев
Сценарий: Выполняется "Имя действия" на клиенте и на сервере с сообщением об успехе "Текст сообщения"
Дано выполняется "Имя действия" на стороне клиента с сообщением об успехе "Текст сообщения"
И выполняется "Имя действия" на стороне сервера с сообщением об успехе "Текст сообщения"
Сценарий: Выполняется "Имя действия" только на клиенте с сообщением об успехе "Текст сообщения"
Дано выполняется "Имя действия" на стороне клиента с сообщением об успехе "Текст сообщения"
При таком содержимом файла мы фактически создаём два новых шага
Выполняется "" на клиенте и на сервере с сообщением об успехе ""
и
Выполняется "" только на клиенте с сообщением об успехе ""
Строка “Имя действия” в рамках всего сценария будет восприниматься как параметр сценария. Точно также, как параметр сценария будет восприниматься вторая строка “Текст сообщения”. Вместо этих параметров будут подставляться фактически переданные в шаги значения:
Мы создали два экспортных сценария в одном файле и вместе с этим у нас появилось два новых шага. Давайте их используем в другом фича-файле со следующим содержанием :
#language: ru
Функционал: Демонстрация вызова экспотных сценариев
Сценарий: Пример вызова экспортых сценариев
Пусть Выполняется "Действие 1" на клиенте и на сервере с сообщением об успехе "Выполнено действие 1"
И Выполняется "Действие 2" только на клиенте с сообщением об успехе "Выполнено действие 2"
Благодаря плагину Gherkin Autocomplete при добавлении шагов, реализуемых экспортным сценарием в Visual Studio Code мы увидим информацию о том, что шаг реализован именно этим способом, а не через внешнюю обработку. И более того, сможем кликнув на подсказку с надписью “Export scenario” увидеть текст сценария и фича-файла, которым он реализован. А кликнув на заголовок всплывающей подсказки перейти непосредственно к файлу, содержащему этот экспортный сценарий. Это крайне полезная и удобная возможность:
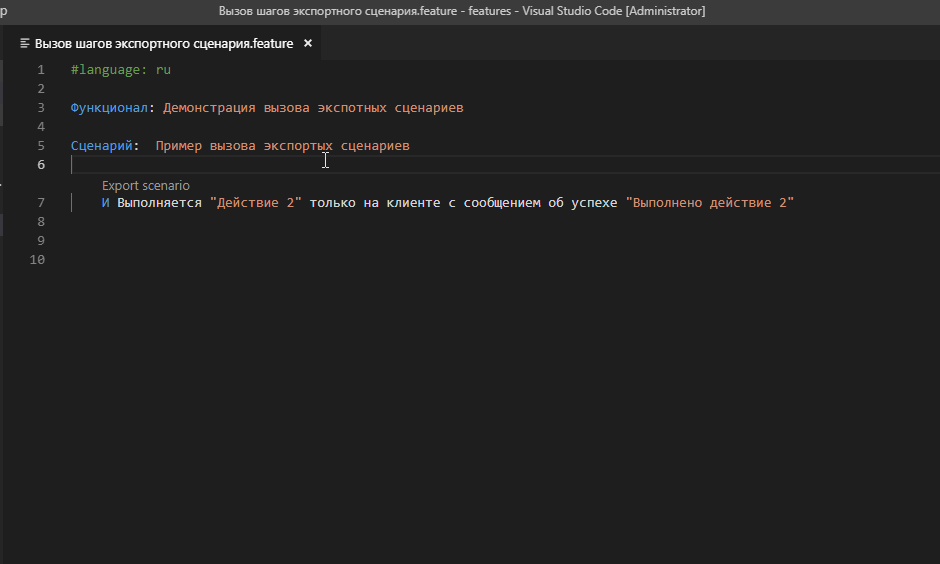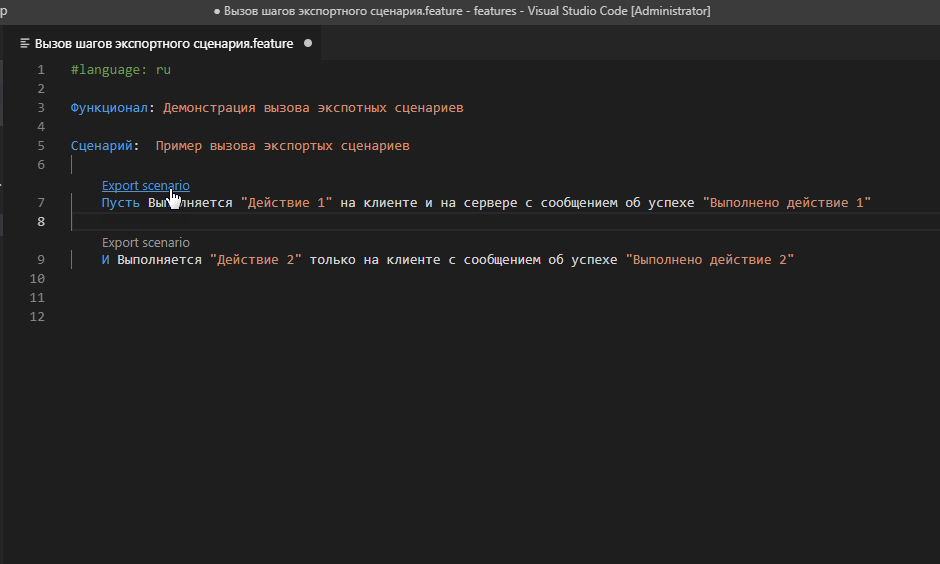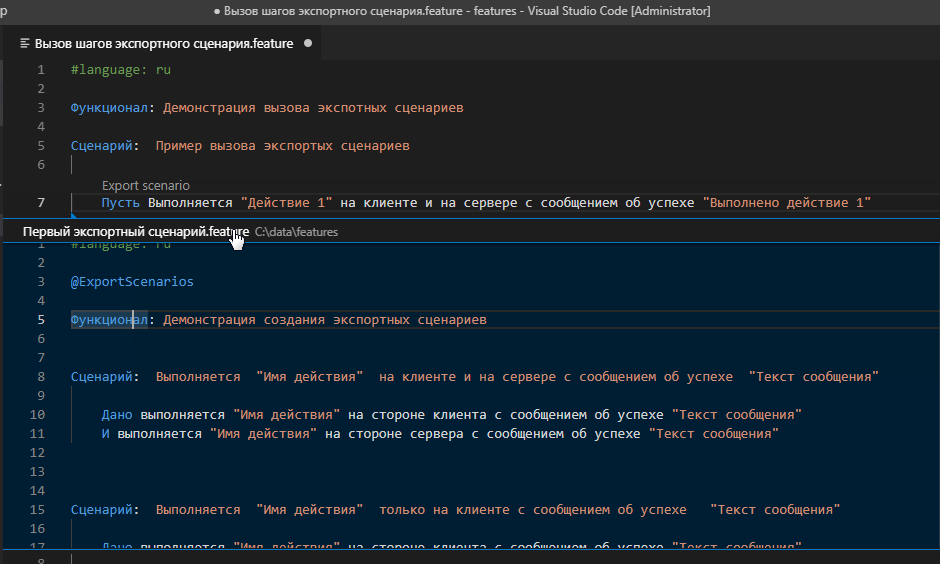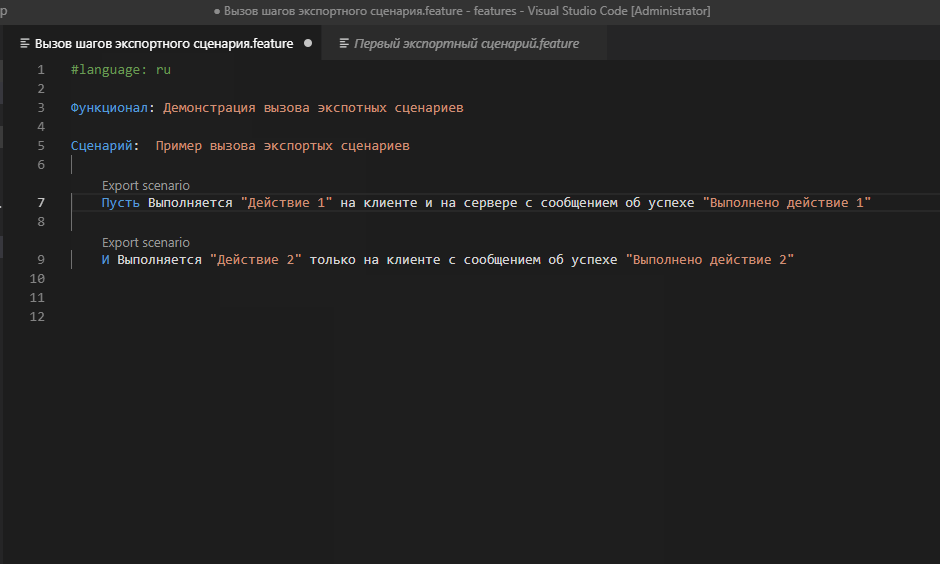
Теперь посмотрим как выглядит сценарий, использующий такие шаги (реализованные в экспортном сценарии) в плеере bddRunner.epf.
Загрузим сценарий, использующий эти шаги. Сразу можно увидеть, что поведение bddRunner.epf похоже на то, которое мы видели при использовании тега @tree и высокоуровневых шагов с расположенными под ними исполняемыми шагами:
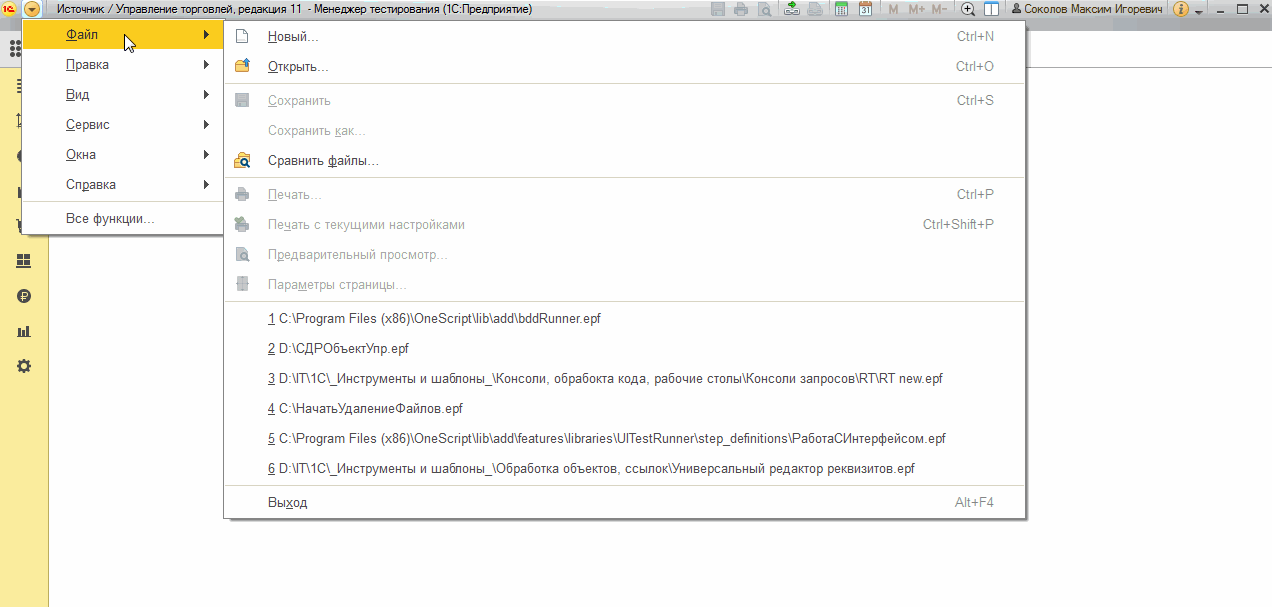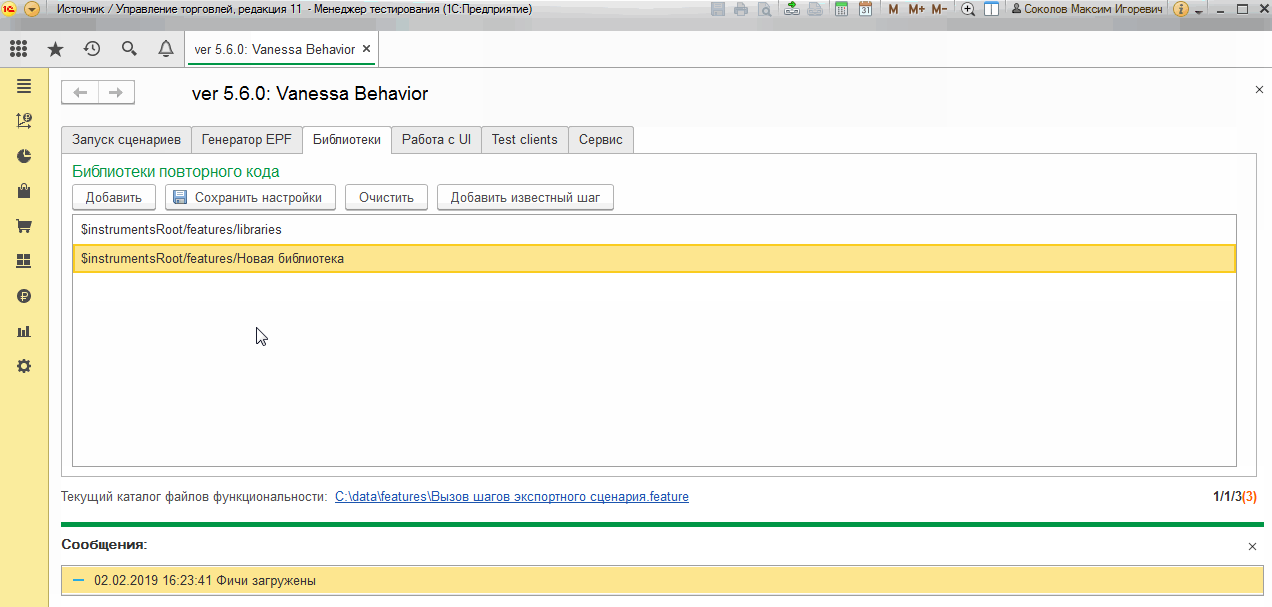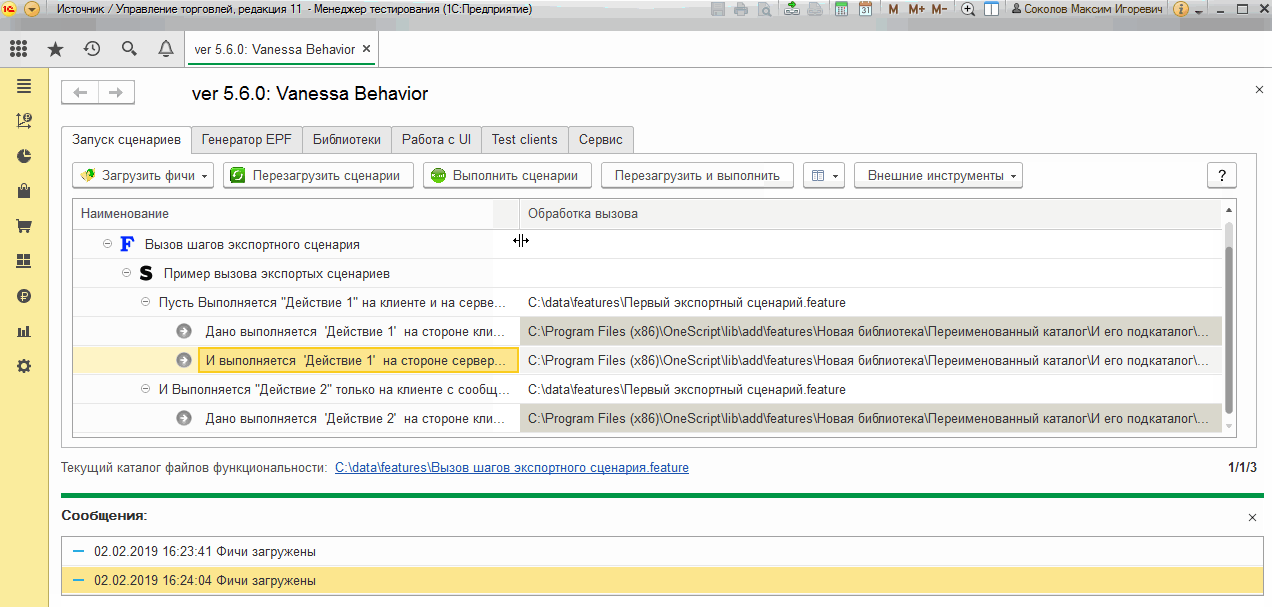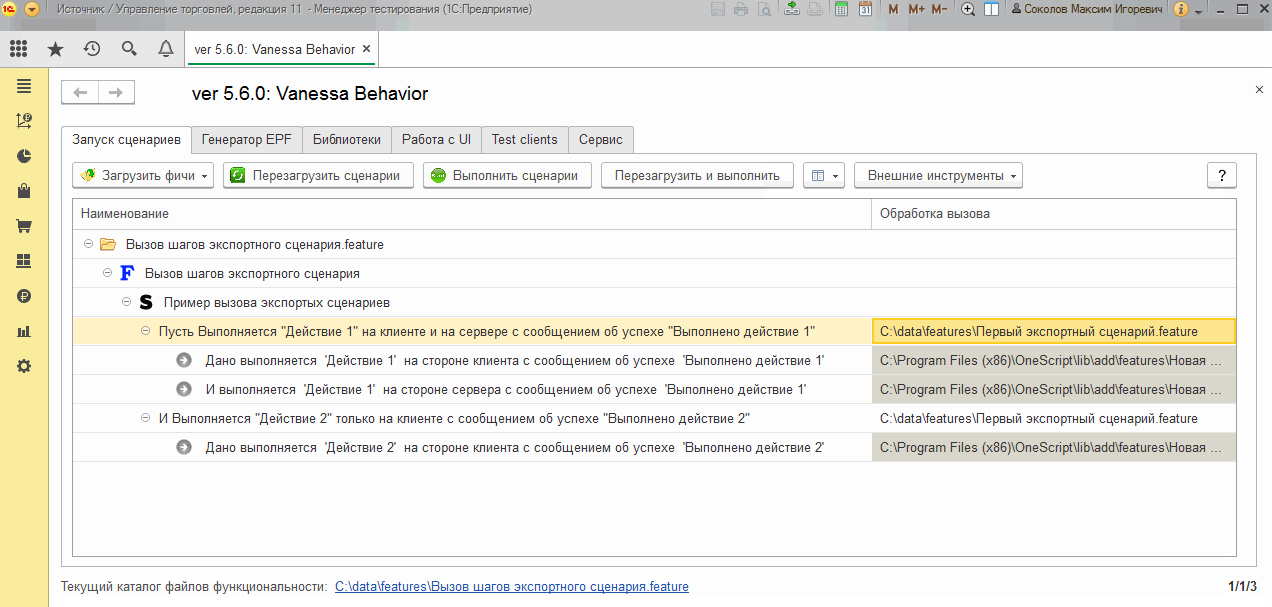
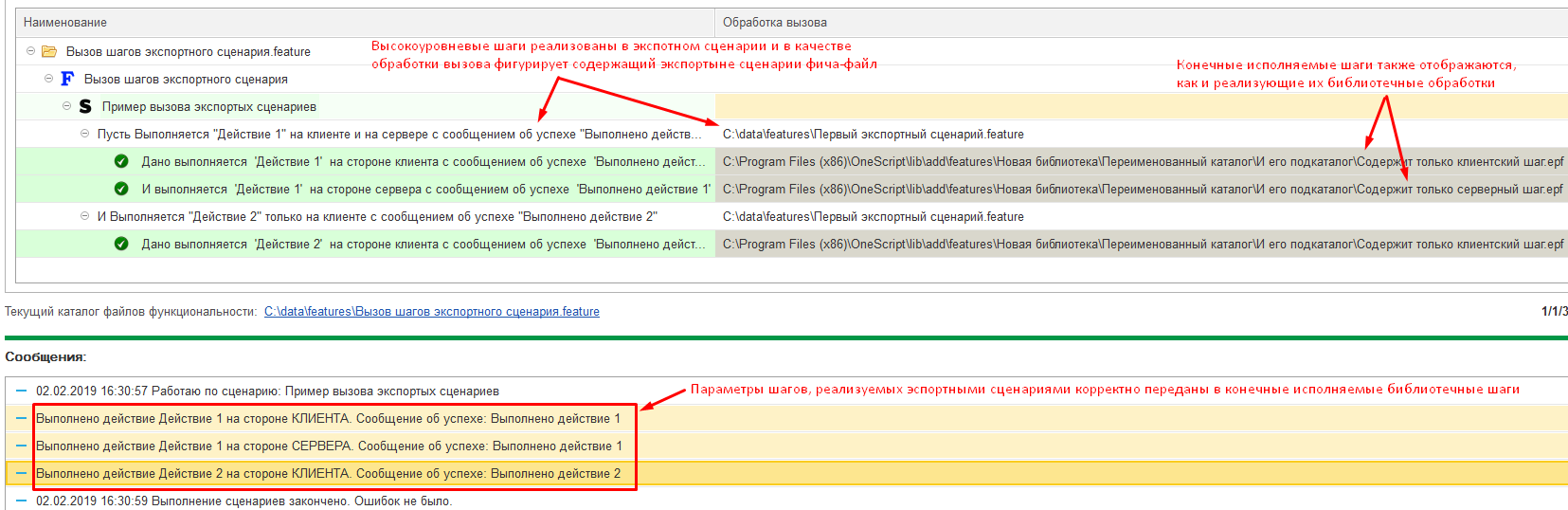
Шаги, реализуемые экспортными сценариями, выглядят как высокоуровневые, а шаги, которые задействованы для реализации экспортного сценария выглядят как исполняемые. При этом в качестве фактических параметров в них еще до выполнения (на этапе загрузки) подставляются фактические параметры шага, реализуемого экспортным сценарием.
Конечно же, библиотеки, реализующие исполняемые шаги через внешние обработки должны быть подключены. В нашем случае конечные исполняемые шаги мы реализовывали в своей собственной библиотеке, поэтому нужно её подключить. После этого мы увидим, что пути к реализующим шаги обработкам ведут к нашей библиотеке. А пути, прописанные в колонке “Обработка вызова” для групп шагов, ведут к файлу с экспортными сценариями:
Игнорирование секции “Контекст” экспортного сценария при исполнении реализуемых им шагов
Если экспортный сценарий вызывается при выполнении реализуемого им шага, то секция “Контекст” фича-файла не будет исполняться. То есть в этом случае сценарий служит исключительно как параметризуемая группа шагов, указанных непосредственно в сценарии. Шаги, перечисленные в секции “Контекст”, не становятся частью экспортного сценария.
Рассмотрим пример. Пусть в нашем фича-файле, содержащим экспортные сценарии появляется секция "Контекст", выводящая сообщение :
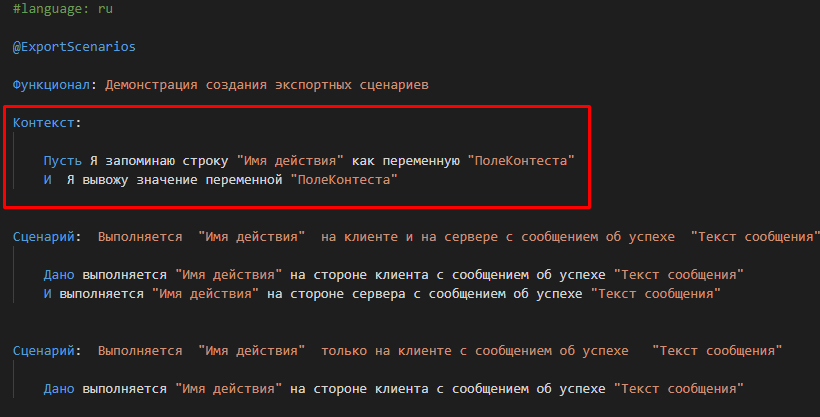
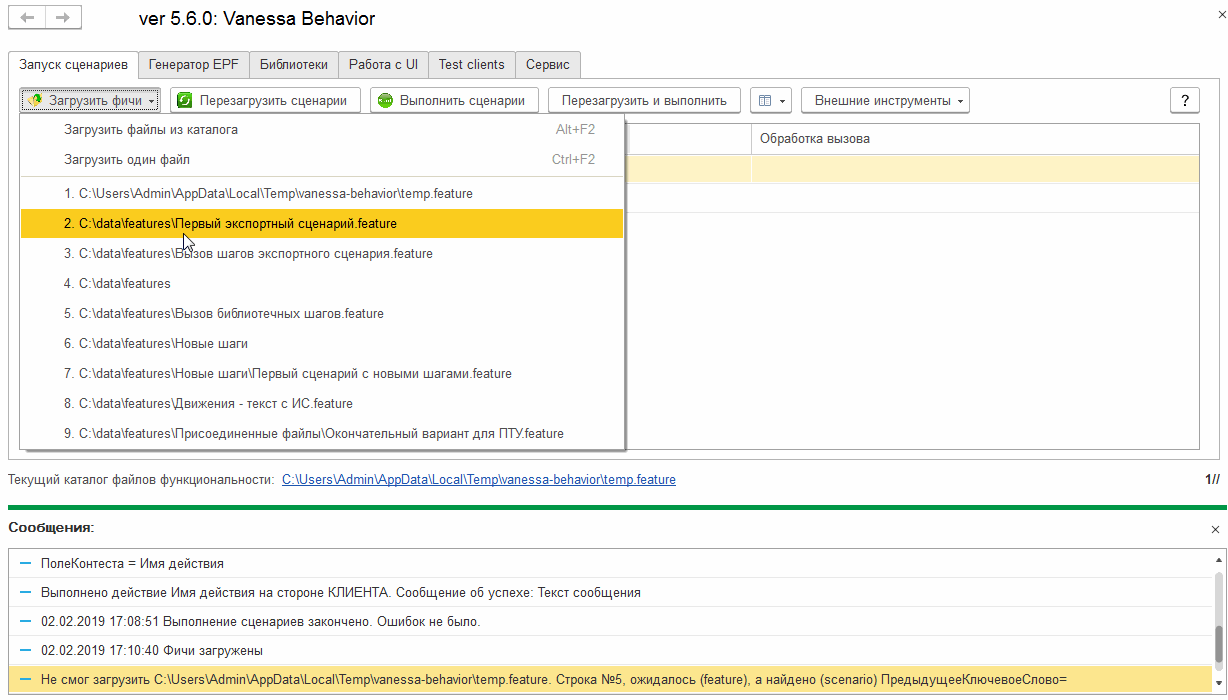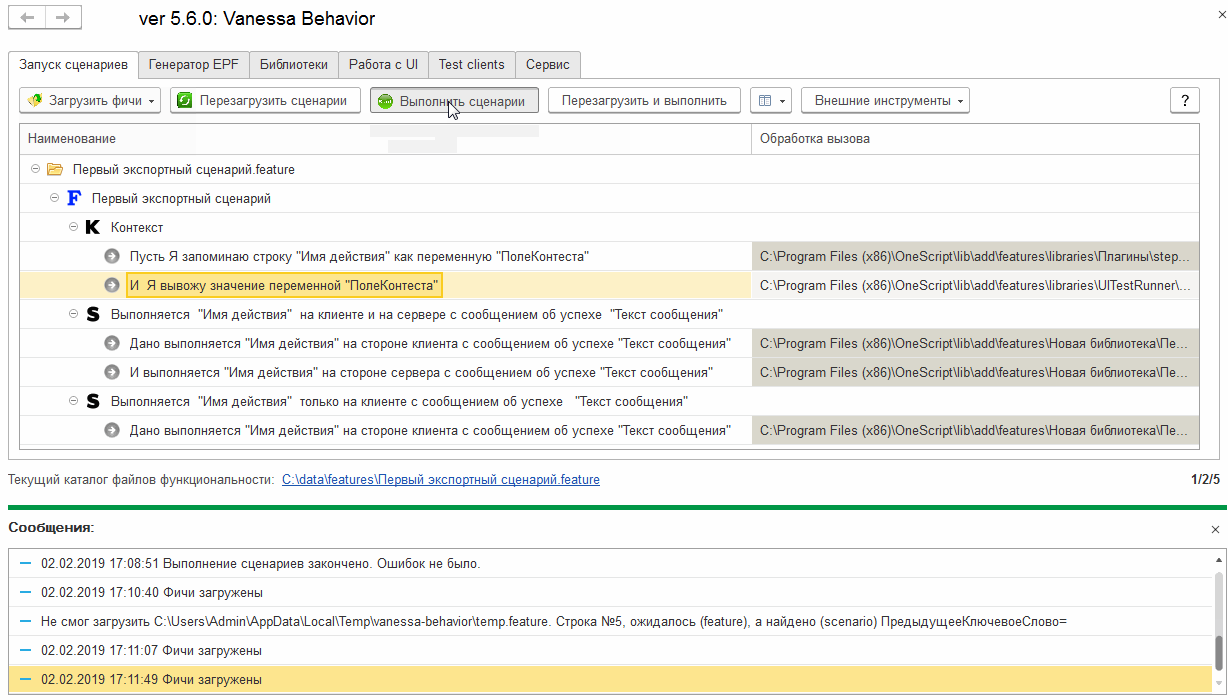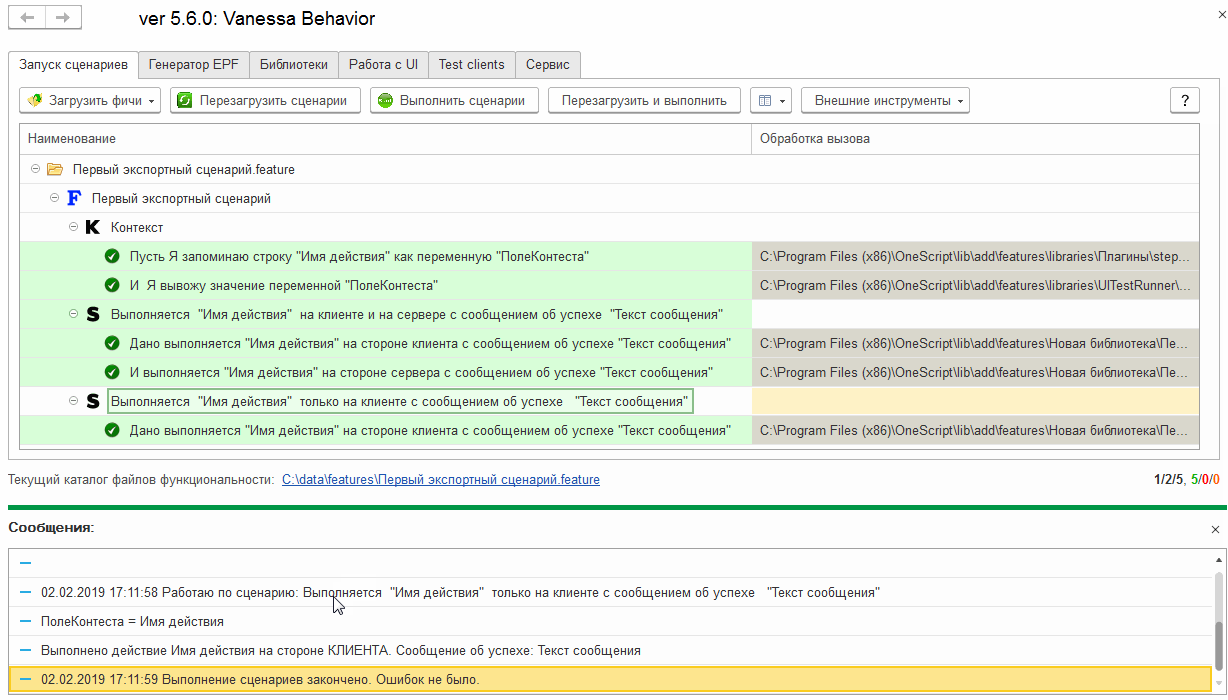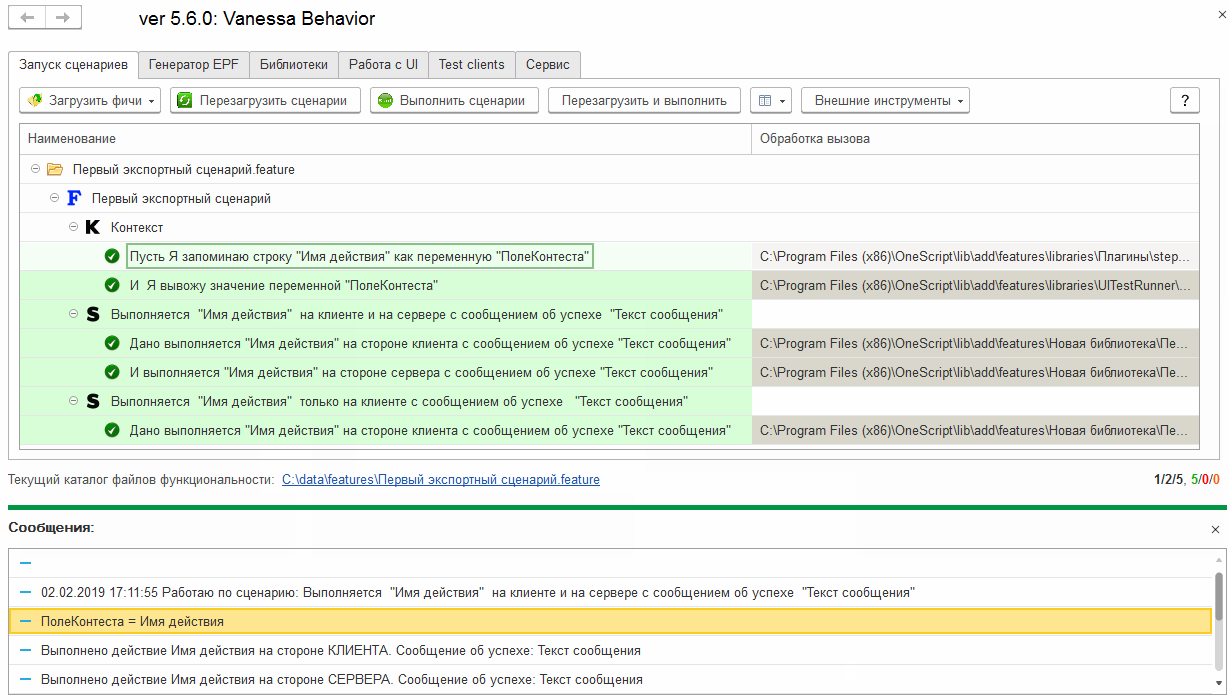
Выполнив шаги, реализуемые этим сценарием мы не увидим никаких дополнительных сообщений, которые выдавались бы при исполнении шагов из этой секции “Контекст”:
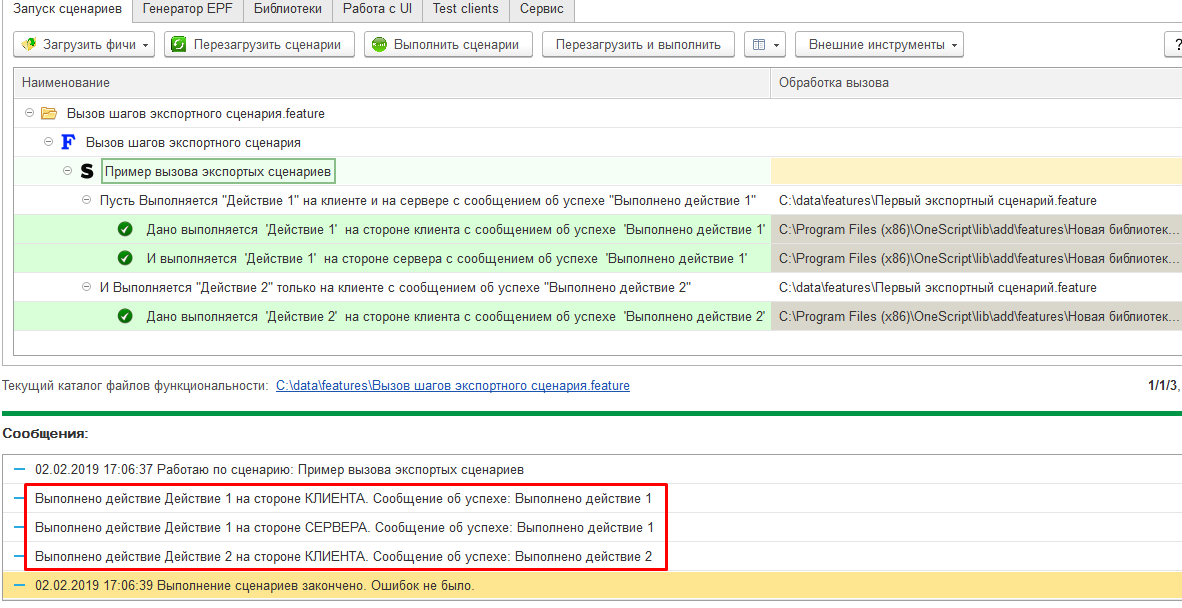
Однако, если мы откроем на исполнение сами экспортные сценарии, и будем не вызывать их извне через реализуемые ими шаги, а будем исполнять их непосредственно, как обычные сценарии, то секция “Контекст” опять станет частью каждого из сценариев и будет исполняться:
Исключаем экспортные сценарии из исполняемых с помощью тегов
Выше мы видели, что фича-файл, содержащий экспортные сценарии, может быть исполнен и сам по себе, а не только через вызов реализуемых им шагов. При открытии на исполнение каталога с фича-файлами этом может мешать. То, что сценарии являются экспортными, не помешает Vanessa-ADD при загрузке каталога загрузить содержащиеся в нём экспортные сценарии для исполнения:
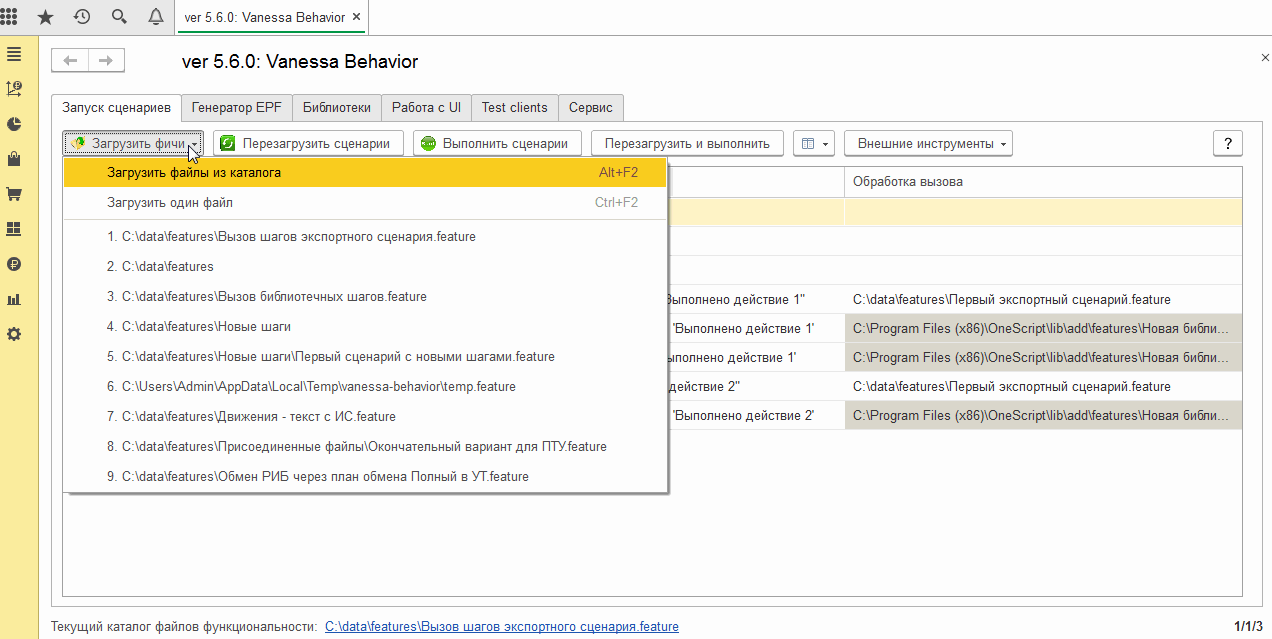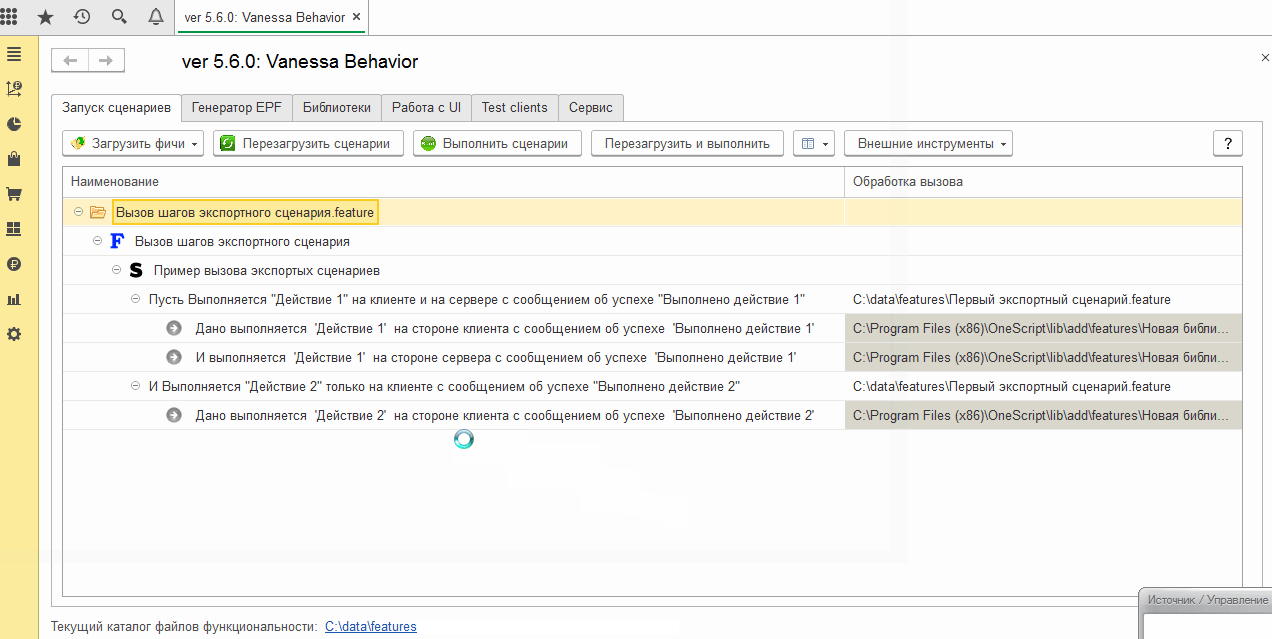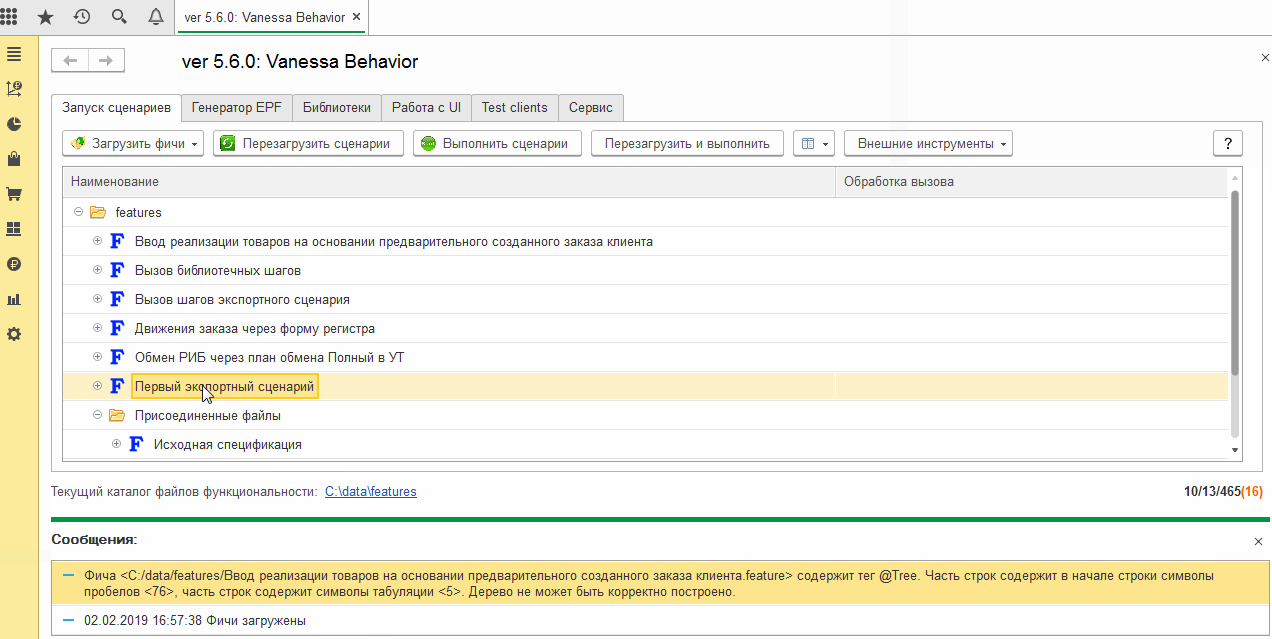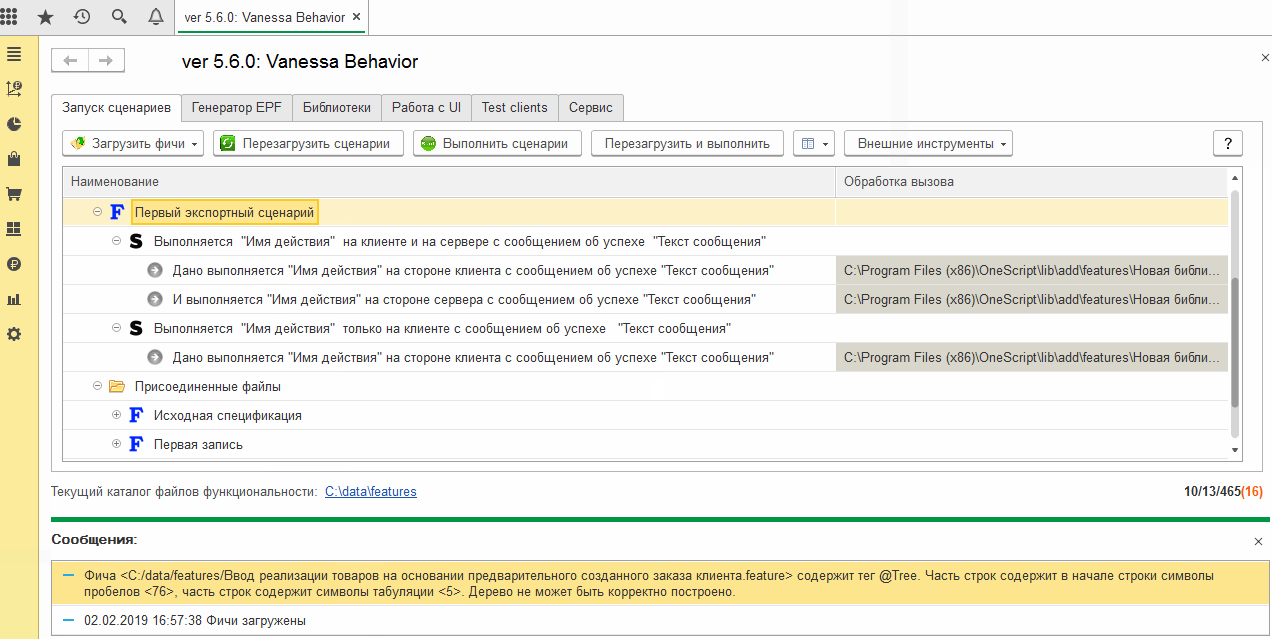
Но экспортные сценарии как правило не предназначены для самостоятельного выполнения. Они реализуют новые шаги, а не какую-то пользовательскую историю.
Для того чтобы исключить экспортные сценарии из исполнения их можно переместить в подключаемую библиотеку шагов, а не в загружаемый каталог (это мы сделаем далее) , но если сценарий специфичен для проекта и используется всего в нескольких исполняемых сценариях, то нет смысла помещать его в библиотеку. В этом случае можно воспользоваться таким такой возможностью, как исключение фича-файлов из загрузки на основе тегов.
Это можно сделать просто дополнив содержимое поля “Список исключаемых тегов” на вкладке “Сервис” :
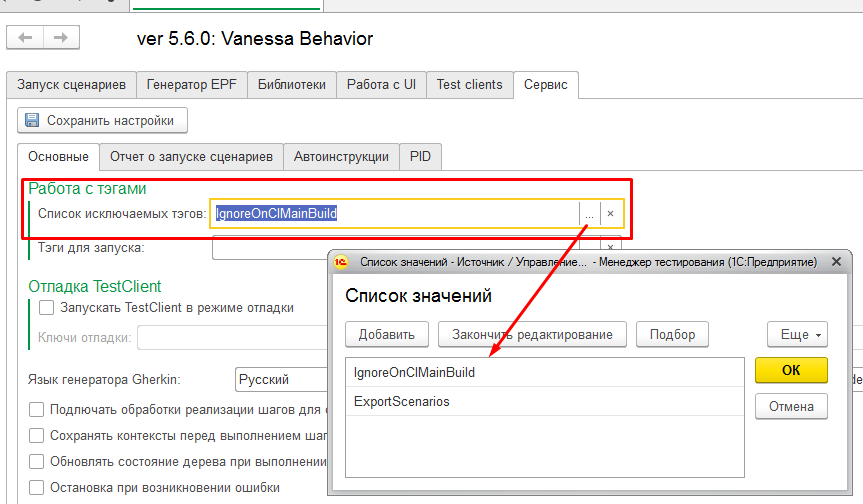
По умолчанию здесь уже есть один тег IgnoreOnCIMainBuild и можно было бы добавить в наши экспортные сценарии его. Но логичнее просто дополнить этот список тегом, который всегда присутствует в фича-файлах, содержащих экспортные сценарии - ExportScenarios.
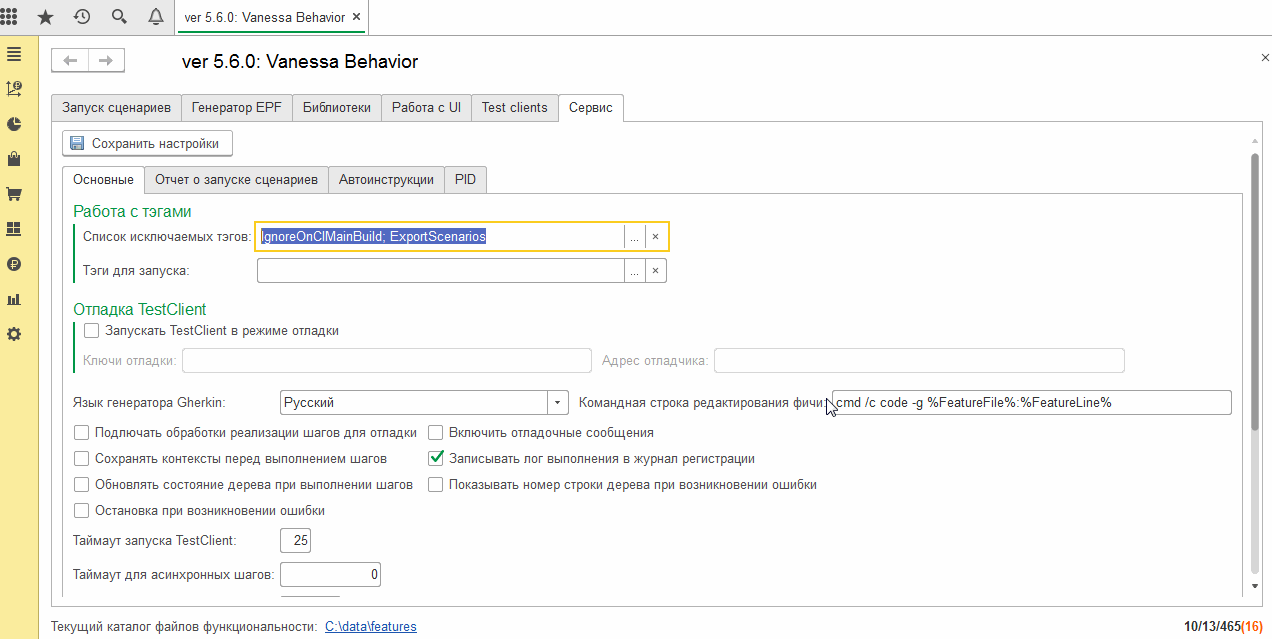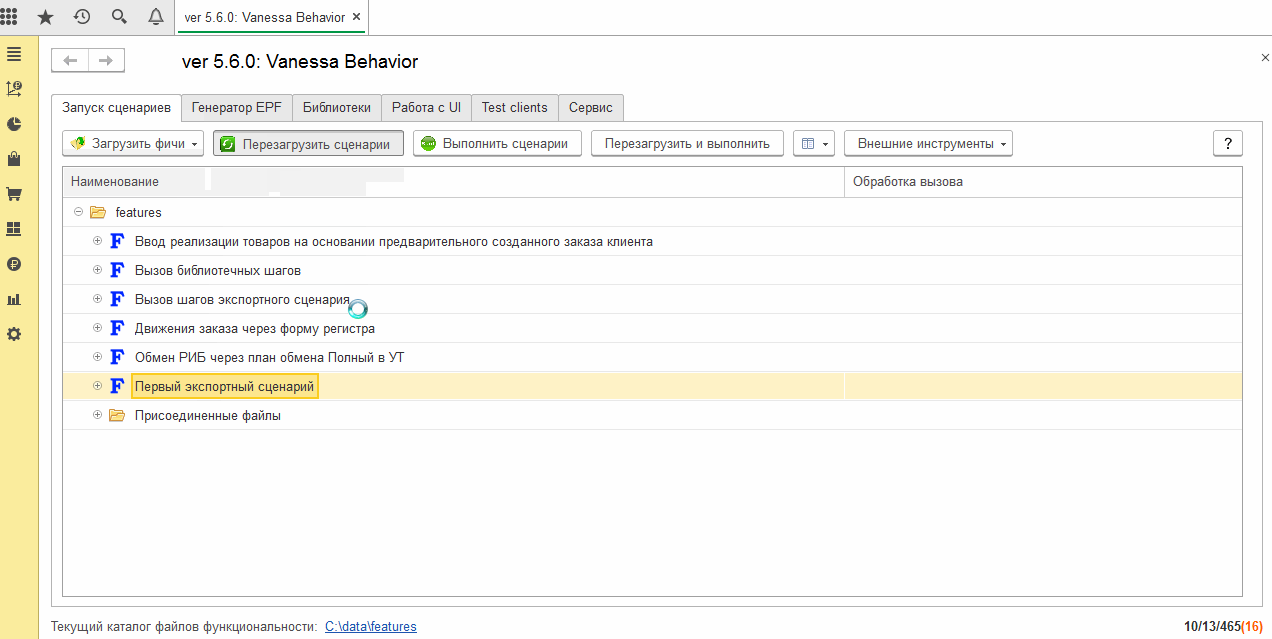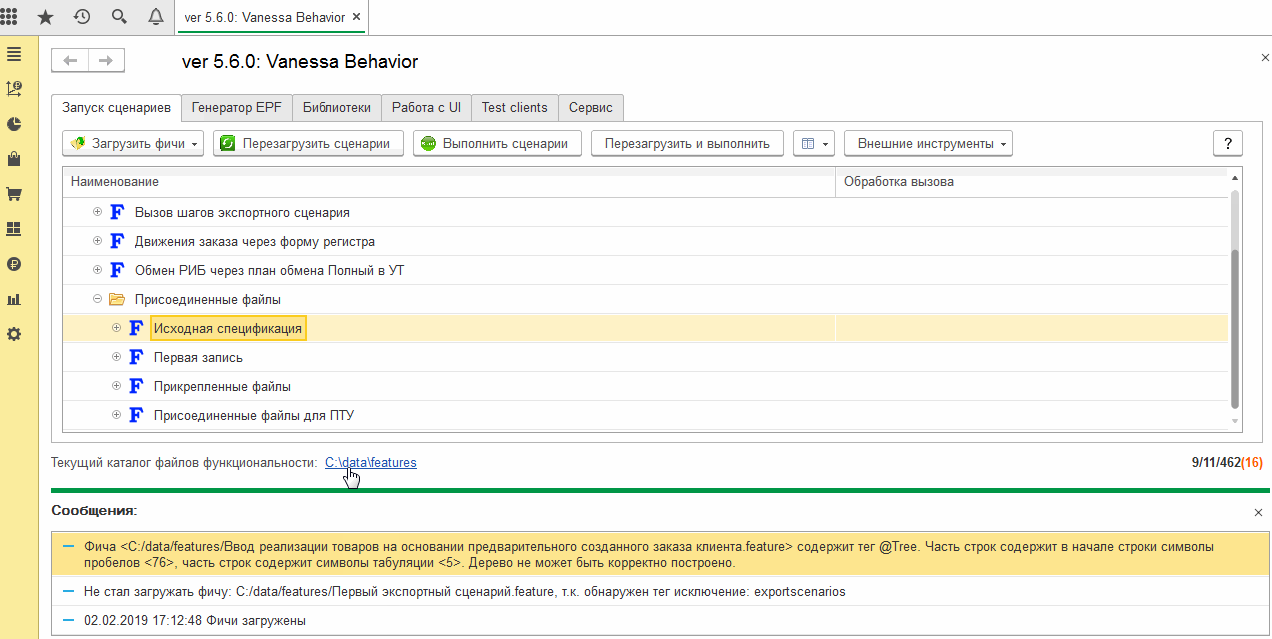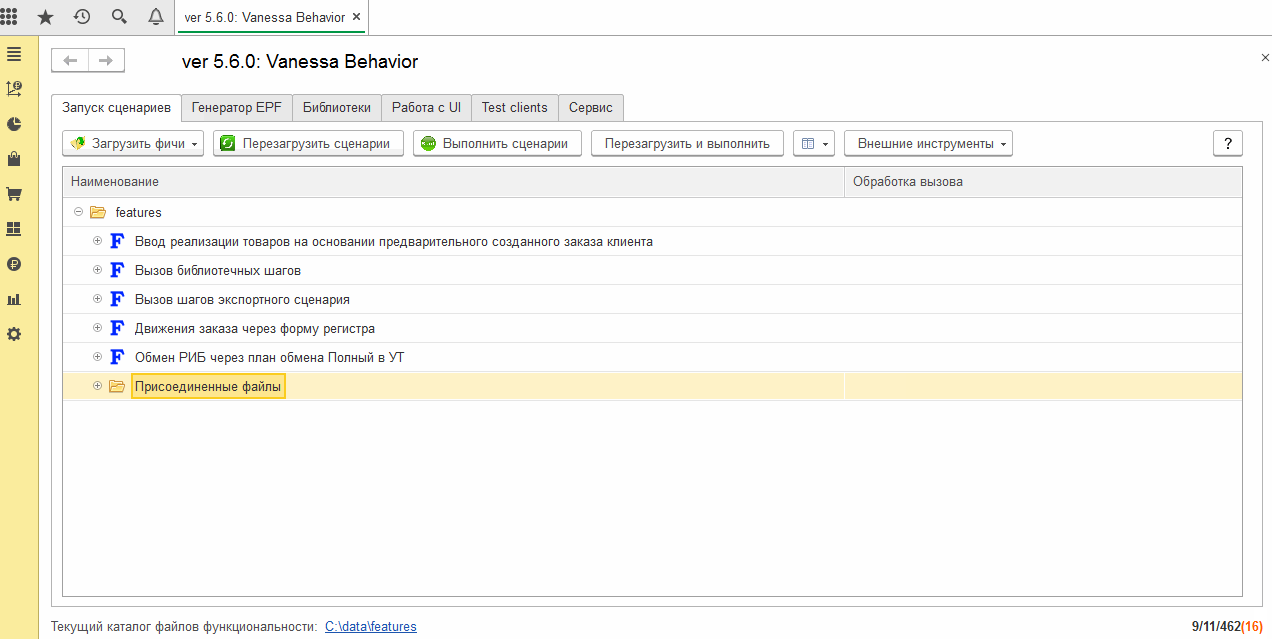
После этого при загрузке каталога для фича-файлы с экспортными сценариями перестанут загружаться для исполнения:
Аналогичная возможность имеется при создании Json-файла для запуска Vanessa-ADD из консоли.
Размещаем экспортный сценарий в собственной библиотеке шагов
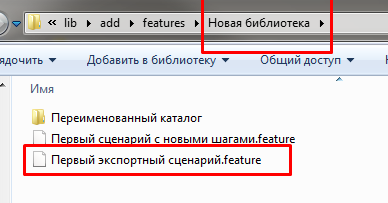
В размещении экспортного сценария в библиотеке шагов нет никаких особенностей. Точно также как и в случае с шагами, реализуемыми внешними обработками, нам достаточно просто переместить фича-файл с экспортными сценариями в каталог библиотеки. А перед вызовом шагов, реализуемых этим экспортным сценарием, указывать эту библиотеку в списке доступных.
Переместим наш файл “Первый экспортный сценарий.feature” в ранее созданную библиотеку шагов “C:\Program Files (x86)\OneScript\lib\add\features\Новая библиотека”.
В фича-файл, вызывающий экспортный сценарий не придётся вносить никаких изменений. Просто перед его исполнением мы будем добавлять путь “$instrumentsRoot/features/Новая библиотека” в список библиотек:
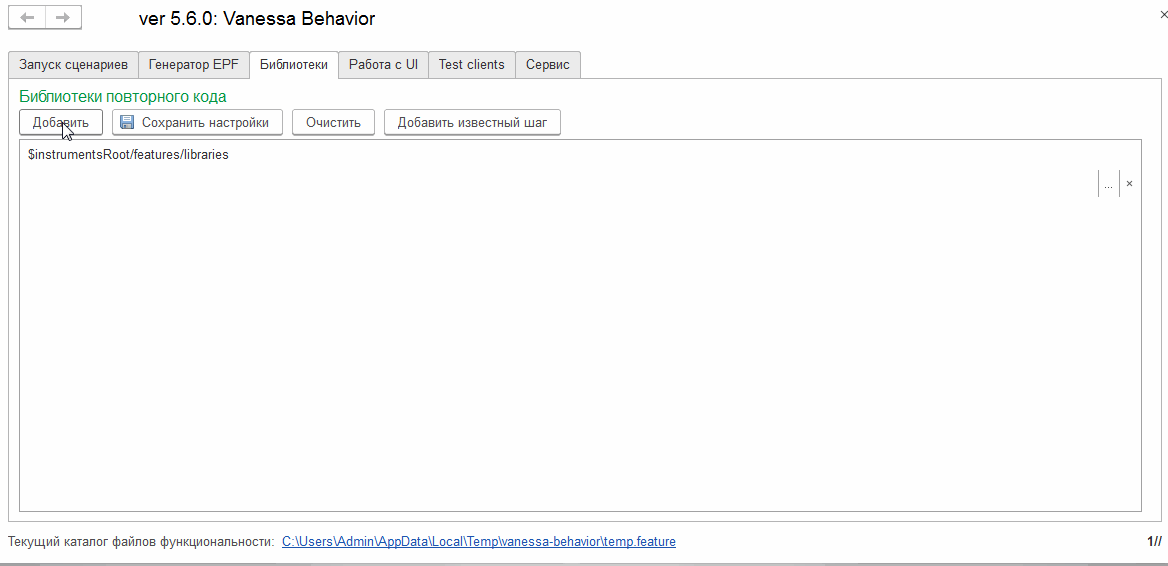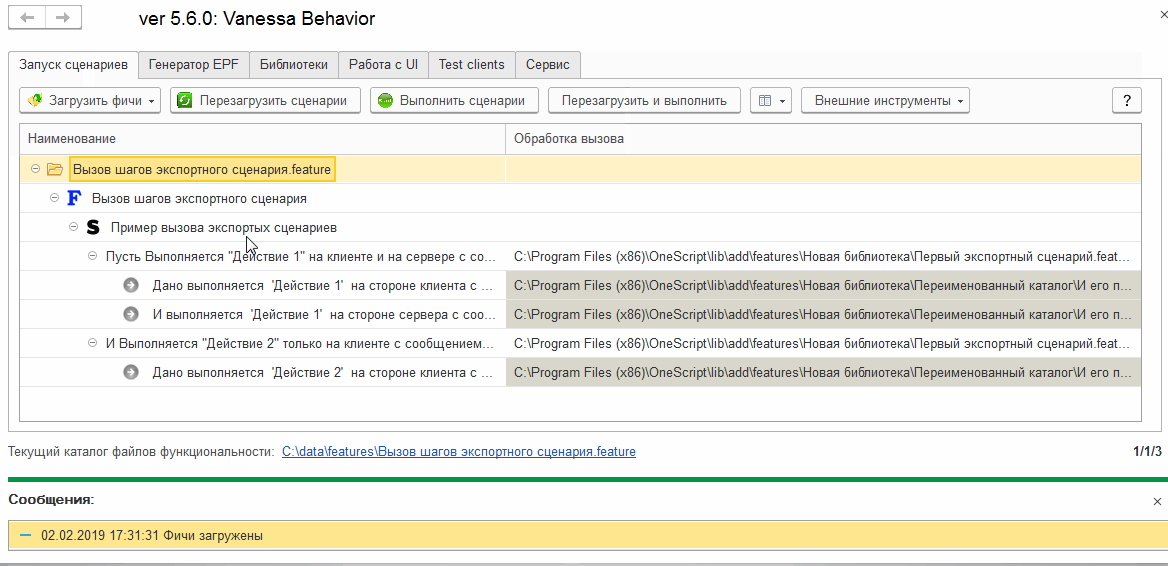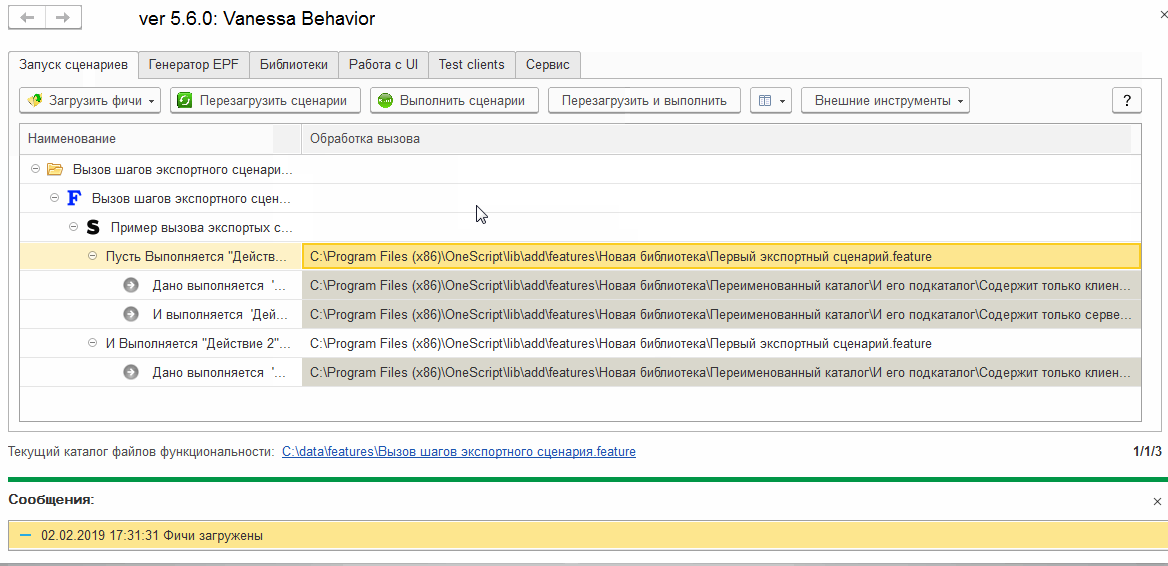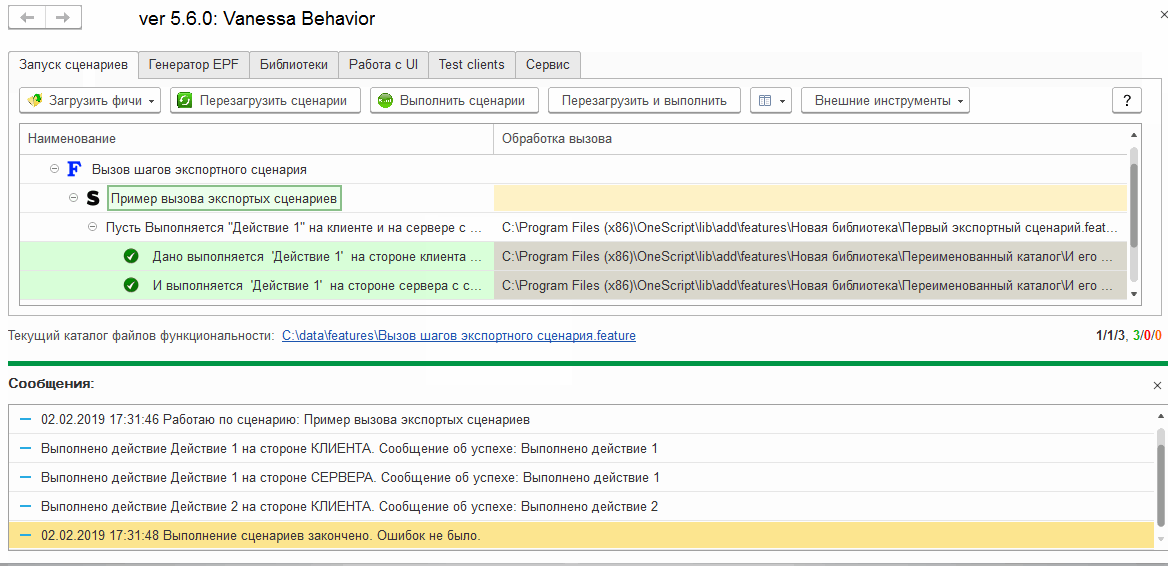
Добавляем шаги, реализуемые экспортными сценариями в форму выбора известных шагов (библиотечных шагов)
В случае с новыми шагами нам приходилось выполнять дополнительные действия, чтобы увидеть их в форме выбора известных шагов. Нам приходилось модифицировать вызовы метода Ванесса.ДобавитьШагВМассивТестов в экспортном методе ПолучитьСписокТестов модуля формы реализующих шаги внешней обработки.
В случае с шагами, реализуемыми экспортными сценариями также придётся выполнить дополнительные действия. Однако эти шаги реализуются не внешними обработками. Куда же необходимо добавить описание шагов?
Чтобы ответить на этот вопрос достаточно посмотреть на уже существующие примеры в стандартной библиотеке. В ней есть шаг “Я запускаю сценарий открытия TestClient или подключаю уже существующий”. Добавив его в наши сценарии можно увидеть, что он реализован экспортным сценарием в файле ОткрытьTestClient.feature:
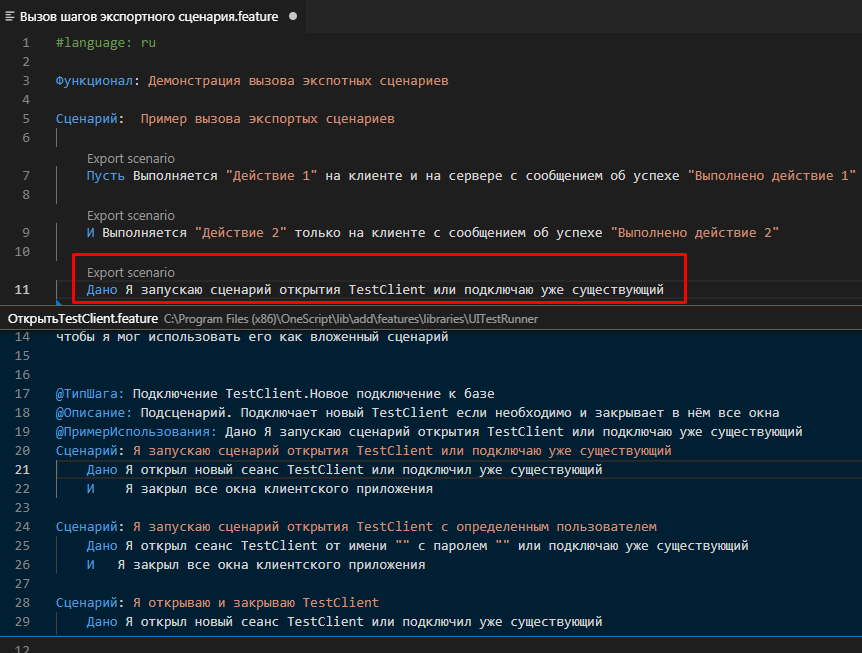
Сравним содержимое этого файла с тем, что мы видим в форме выбора известных шагов:
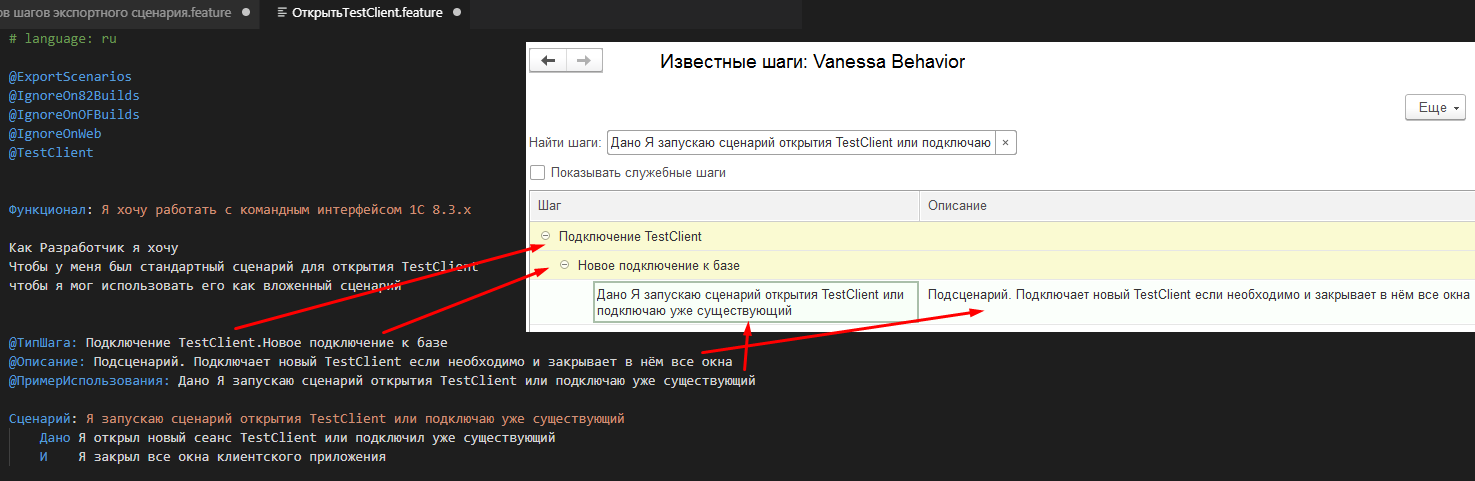
Можно увидеть, что управление отображением шагов в этой форме осуществляется с помощью специальных тегов, расположенных перед сценарием:
@ТипШага: - определяет группу шагов, в которых будет размещен реализуемый экспортным сценарием шаг
@Описание: - определяет текст в колонке “Описание” формы выбора известных шагов
@ПримерИспользования: - определяет текст шага в колонке “шаг” формы выбора известных шагов
Применим эту информацию к нашим экспортным сценариям, добавим теги, необходимые для появления наших шагов в форме выбора известных шагов:
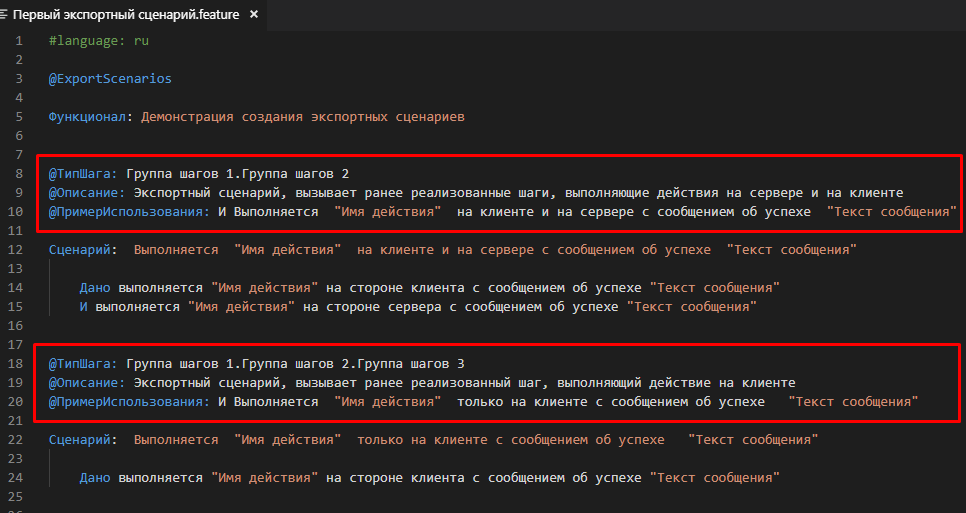
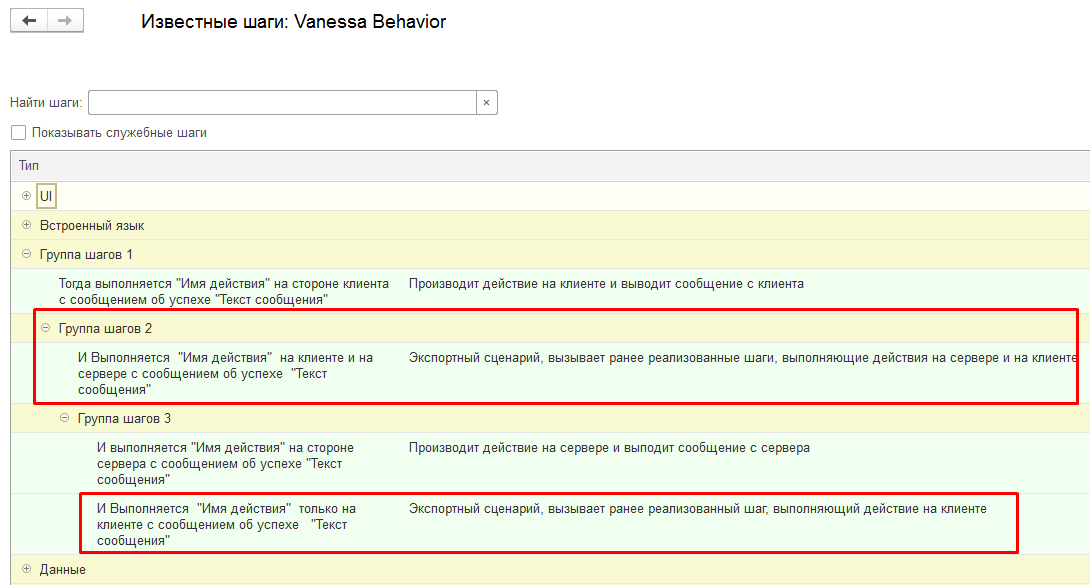
Результат будет следующим:
Как передать таблицу в качестве параметра шага, реализуемого экспортным сценарием?
Никак.
Реализуя шаги через внешние обработки мы имеем возможность передать в них таблицы, но в случае с экспортными шагами это видимо невозможно сделать. Здесь есть пример попытки сделать это https://xdd.silverbulleters.org/t/ui-testy-a-mozhno-parametrizovat/2165, но как правильно отмечено в комментариях, он не вполне корректен. Возможно после появления этой публикации в комментариях к ней всё же появится информация о том, как можно это сделать, однако сейчас этой информации нет.
Практические примеры
Для закрепления информации реализуем три шага, которые мы сможем использовать на практике:
- Удаление файла с контролем успешности операции
- Исполнение произвольного кода на сервере с возможностью помещения результата в поля структуры Контекст
- Открытие формы последнего проведенного документа в тест-клиенте
Асинхронный шаг удаления файла с контролем успешности операции
В удалении файла нет ничего сложного?
Не было бы, если бы не концепция асинхронного программирования в последних релизах платформы. Синхронные методы остались только для серверной части платформы 1С, на клиенте же мы должны использовать их асинхронные аналоги как для удаления файла, так и для проверки его существования.
В публикации с примерами на основе типовой конфигурации мы обходили это ограничение устанавливая паузу. Но само применение паузы выглядит некрасиво. А реализованные нами шаги для удаления файла через выполнение произвольного кода 1С выглядели громоздко и были сложны в повторном использовании:

Сделаем так, чтобы все эти строки мы могли заменить на всего одну. Для этого нам нужно реализовать шаг, использующий асинхронные методы платформы, и при этом не позволяющий выполняться следующим за ним шагам до тех пор, пока не будет достигнут положительный или отрицательный результат удаления файла.
Важно понимать, что весь код будет исполняться на стороне тест-менеджера, методы тест-клиента мы здесь вызывать не будем.
Типовой шаг ожидания закрытия окна как образец асинхронного шага
Самый простой способ разработать свой асинхронный шаг - это взять за образец какой-то из уже существующих. Во встроенной библиотеке есть множество асинхронных шагов. В качестве образца возьмем шаг ожидания закрытия окна в течение заданного количества секунд:

Заглянув в реализацию шага можно увидеть, что механизм асинхронных шагов следующий:
1) В начале асинхронного шага запрещается выполнение последующих шагов сценария
2) Подключается обработчик ожидания, который будет вызываться на протяжении заданного времени и в котором будет выполняться проверка либо наступления ожидаемого события, либо наступления таймаута.
3) Если ожидаемое событие наступило до истечения заданного в асинхронном шаге времени, то выполнение шагов продолжается без вызова исключения.
4) Если вместо ожидаемого события произошел таймаут, то вызывается тот же метод, что и в случае успеха. Но в этот раз ему передаются параметры, сигнализирующие о том, что шаг упал и соответствующий текст ошибки

Переменная “Ванесса” содержит ссылку на форму обработки bddRunner.epf, поэтому вызываемые через точку от этого объекта методы следует искать в этой форме:
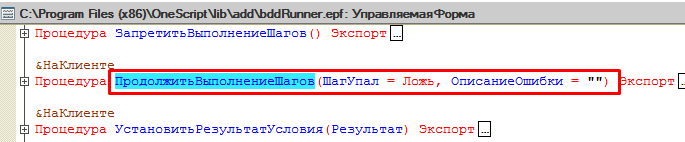
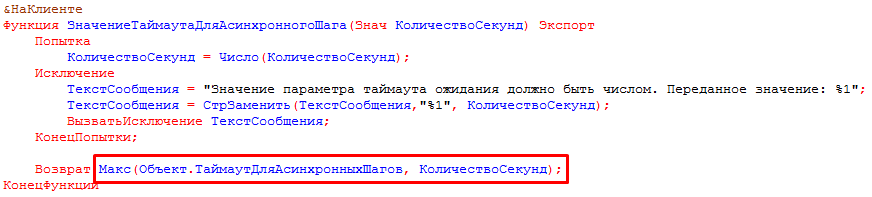
Реализуем наш шаг удаления файла
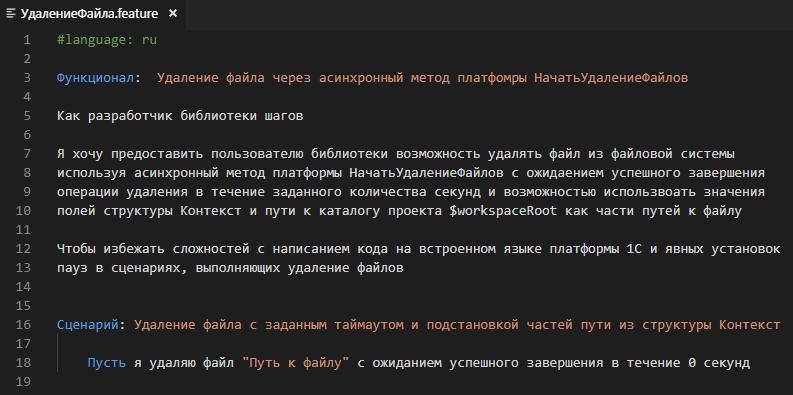
Напишем сценарий с нужным нам шагом:
Создадим внешнюю обработку реализующую этот шаг и откроем её на редактирование. В модуле формы разместим объявление служебных переменных:
&НаКлиенте
Перем ФайлУдаленУспешно;
&НаКлиенте
Перем ДатаНачалаОбработкиОжидания;
&НаКлиенте
Перем ТаймаутУдаленияФайла;
&НаКлиенте
Перем ПутьКФайлуДляУдаления;
Объявление шага будет выглядеть следующим образом:
// Функция экспортирует список шагов, которые реализованы в данной внешней обработке.
&НаКлиенте
Функция ПолучитьСписокТестов(КонтекстФреймворкаBDD) Экспорт
Ванесса = КонтекстФреймворкаBDD;
ВсеТесты = Новый Массив;
Ванесса.ДобавитьШагВМассивТестов(
ВсеТесты,
"ЯУдаляюФайлСОжиданиемУспешногоЗавершенияВТечениеСекунд(ПутьКФайлу,Таймаут)",
"ЯУдаляюФайлСОжиданиемУспешногоЗавершенияВТечениеСекунд",
"Пусть я удаляю файл ""Путь к файлу"" с ожиданием успешного завершения в течение 0 секунд",
"Удаляет файл с диска с указанным таймаутом. В пути можно указывать $ИмяПеременной для подстановки значения из структуры Контекст",
"Практические примеры"
);
Возврат ВсеТесты;
КонецФункции
А реализацию шага можно сделать так:
&НаКлиенте
//Пусть я удаляю файл "Путь к файлу" с ожиданием успешного завершения в течение 0 секунд
//@ЯУдаляюФайлСОжиданиемУспешногоЗавершенияВТечениеСекунд(ПутьКФайлу, Таймаут)
Процедура ЯУдаляюФайлСОжиданиемУспешногоЗавершенияВТечениеСекунд(ПутьКФайлу, Таймаут) Экспорт
ФайлУдаленУспешно = Ложь;
ПутьКФайлуДляУдаления = ПутьКФайлу;
ТаймаутУдаленияФайла = Ванесса.ЗначениеТаймаутаДляАсинхронногоШага(Таймаут);
Если ЗначениеЗаполнено(Ванесса.Объект.КаталогПроекта) Тогда
ПутьКФайлуДляУдаления = СтрЗаменить(ПутьКФайлуДляУдаления, "$workspaceRoot", Ванесса.Объект.КаталогПроекта);
КонецЕсли;
Для Каждого ЭлементСтруктуры Из Контекст Цикл
ПутьКФайлуДляУдаления = СтрЗаменить(ПутьКФайлуДляУдаления, "$"+ЭлементСтруктуры.Ключ, ЭлементСтруктуры.Значение);
КонецЦикла;
ОбъектФайлаКУдалению = Новый Файл(ПутьКФайлуДляУдаления);
Ванесса.ЗапретитьВыполнениеШагов();
ДатаНачалаОбработкиОжидания = ТекущаяДата();
ПодключитьОбработчикОжидания("ОбработчикОжиданияУдаленияФайла", 1, Ложь);
НачатьУдалениеФайлов(,ПутьКФайлуДляУдаления);
ПроверитьСуществованиеФайлаАсинхронно();
КонецПроцедуры
&НаКлиенте
Процедура ПроверитьСуществованиеФайлаАсинхронно()
Оповещение = Новый ОписаниеОповещения("ОповещениеЗавершенияПроверкиСуществованияФайла", ЭтотОбъект);
Файл = Новый Файл(ПутьКФайлуДляУдаления);
Файл.НачатьПроверкуСуществования(Оповещение);
КонецПроцедуры
&НаКлиенте
Процедура ОповещениеЗавершенияПроверкиСуществованияФайла(Существует, ДополнительныеПараметры) Экспорт
ФайлУдаленУспешно = (Существует = Ложь);
КонецПроцедуры
&НаКлиенте
Процедура ОбработчикОжиданияУдаленияФайла() Экспорт
Если ФайлУдаленУспешно Тогда
ОтключитьОбработчикОжидания("ОбработчикОжиданияУдаленияФайла");
Ванесса.ПродолжитьВыполнениеШагов();
Возврат;
КонецЕсли;
Если (ТекущаяДата() - ДатаНачалаОбработкиОжидания) > ТаймаутУдаленияФайла Тогда
ТекстСообщения = "Ожидали в течение <%1> секунд, что будет удален файл <%2>, но файл по прежнему существует";
ТекстСообщения = СтрШаблон(ТекстСообщения, ТаймаутУдаленияФайла, ПутьКФайлуДляУдаления);
ОтключитьОбработчикОжидания("ОбработчикОжиданияУдаленияФайла");
Ванесса.ПродолжитьВыполнениеШагов(Истина,ТекстСообщения);
Возврат;
КонецЕсли;
ПроверитьСуществованиеФайлаАсинхронно();
Конецпроцедуры
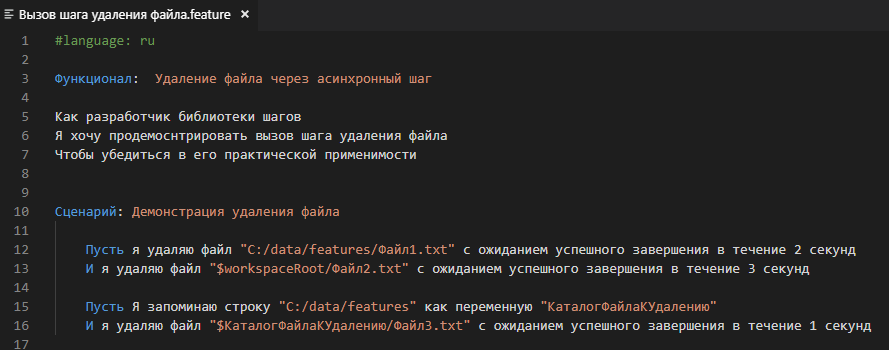
Что же, теперь создадим сценарий, вызывающий этот шаг с различными вариантами параметров, которые мы предусмотрели в алгоритме :
Посмотрим как он исполняется. Каждый из трёх файлов успешно удаляется:
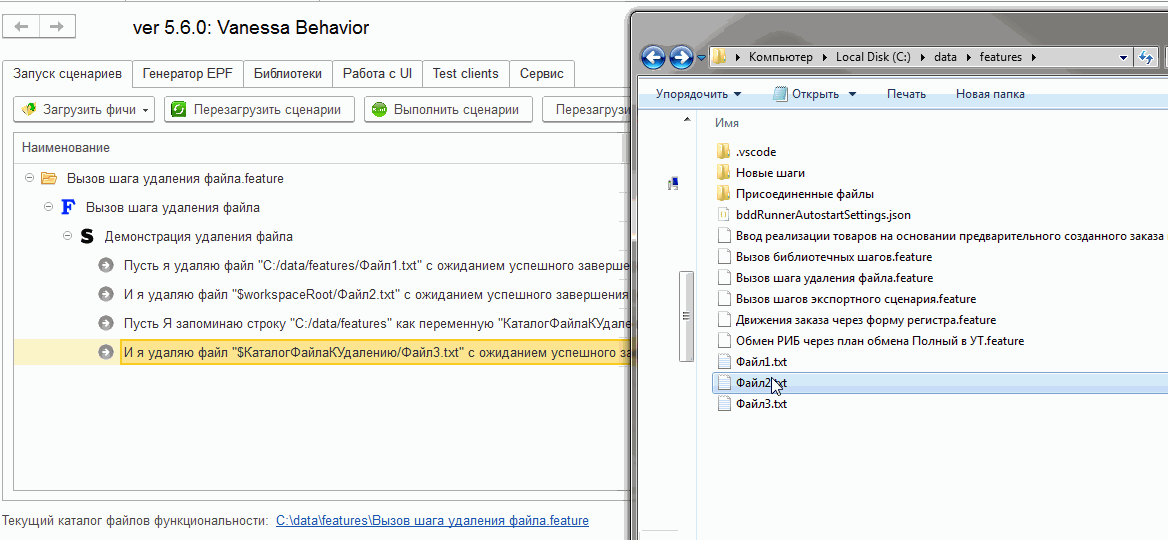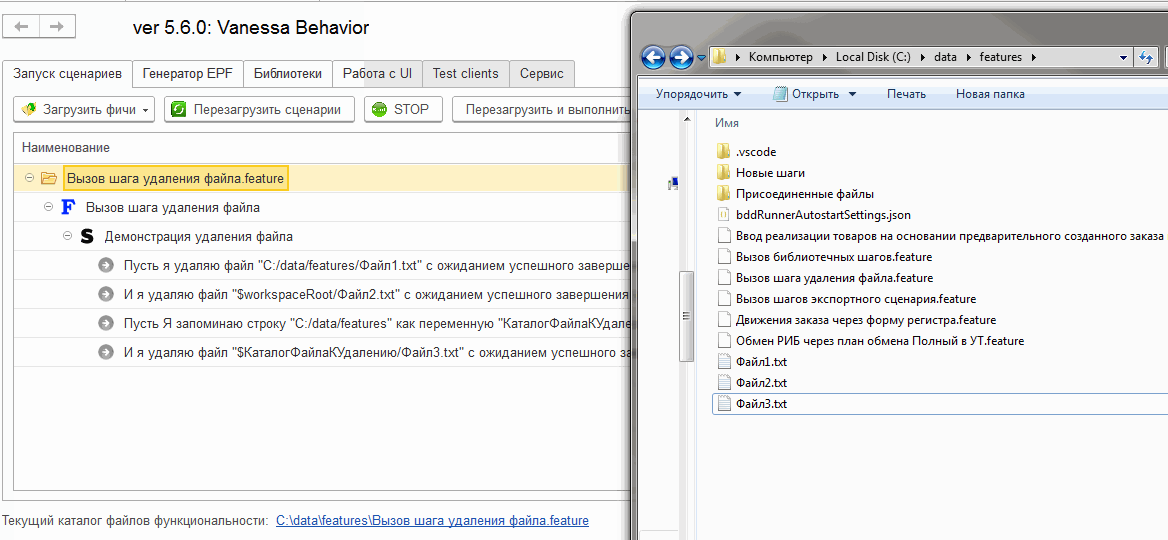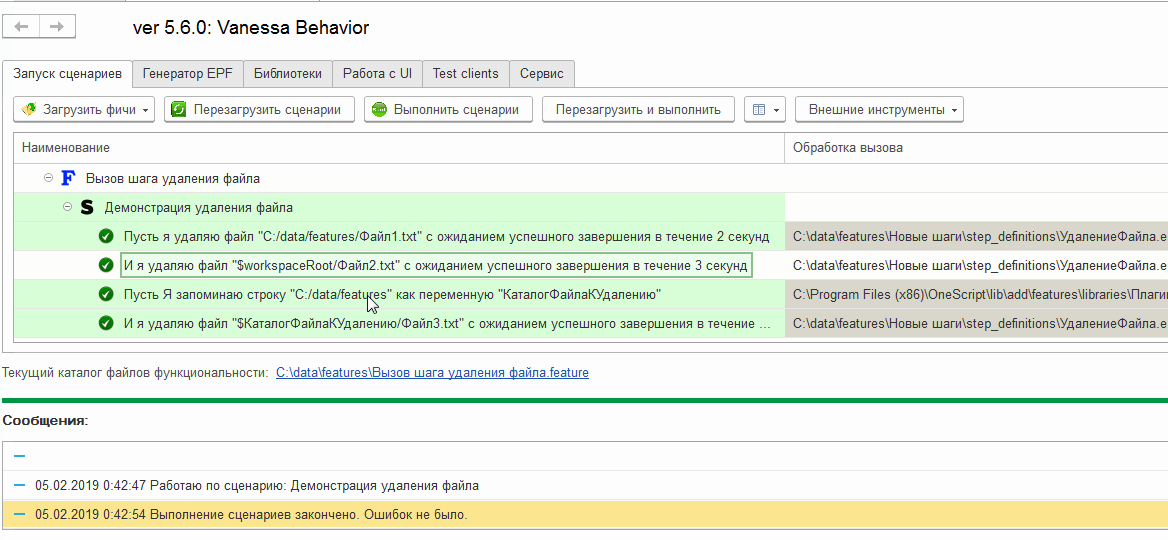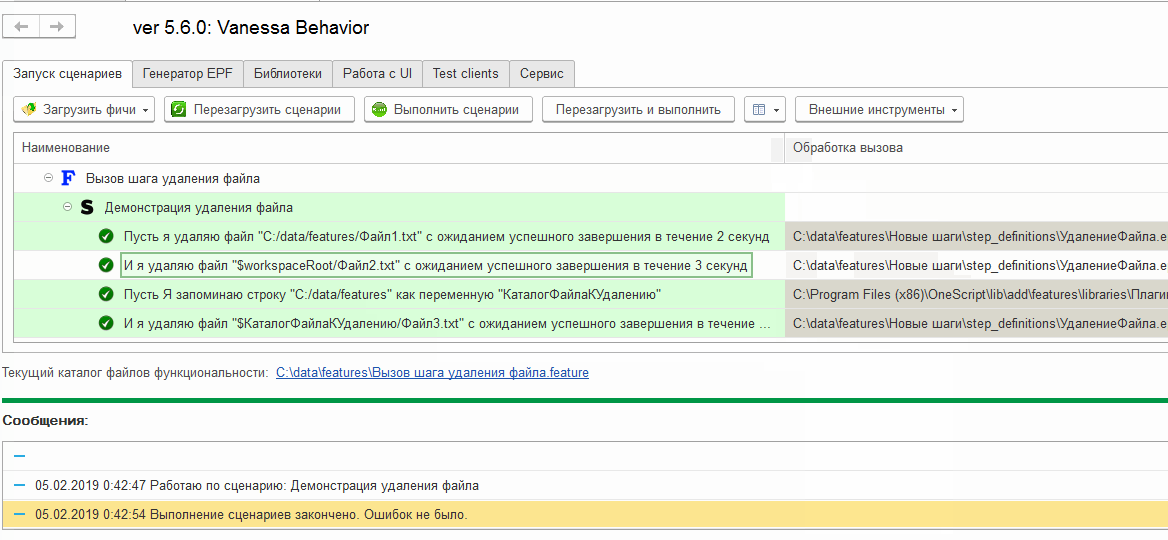
Исполнение произвольного кода на сервере 1С
За образец мы можем взять шаг “И затем я выполняю код встроенного языка” и создать на его основе шаг “И затем я выполняю код встроенного языка на сервере 1С”.
Но если бы мы просто исполнили код на сервере, то в этом было бы мало пользы. Мы могли бы удалить все документы, или сбросить настройки форм. Но мы бы не смогли каким-то образом передать результат нашего шага в следующие шаги. Поэтому обеспечим передачу структуры Контекст на сторону сервера и её возврат на сторону клиента.
Также добавим возможность подставлять в код строки, сохраненные в структуре Контекст. Эта возможность пригодится нам уже при реализации следующего шага на основе экспортного сценария, когда мы будем открывать форму последнего проведенного документа.
Библиотечный сценарий будет таким :
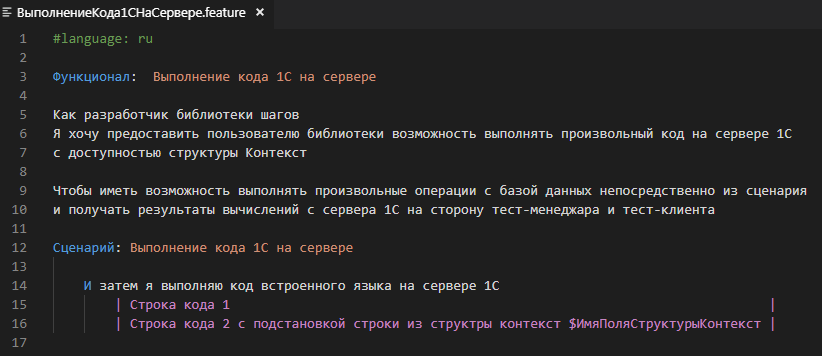
А реализующие его методы такими:
&НаКлиенте
Процедура ЗатемЯВыполняюКодВстроенногоЯзыкаНаСервере1С(ТаблицаВВидеМассиваСтруктур) Экспорт
КодКВыполнению = "";
Для Каждого СтрокаКода Из ТаблицаВВидеМассиваСтруктур Цикл
КодКВыполнению = КодКВыполнению + СтрокаКода.Кол1 + Символы.ПС;
КонецЦикла;
Для Каждого ЭлементСтруктуры Из Контекст Цикл
КодКВыполнению = СтрЗаменить(КодКВыполнению, "$"+ЭлементСтруктуры.Ключ, ЭлементСтруктуры.Значение);
КонецЦикла;
ВыполнитьНаСервере(КодКВыполнению, Контекст);
КонецПроцедуры
&НаСервере
Процедура ВыполнитьНаСервере(Знач КодКВыполнению, Контекст)
Выполнить(КодКВыполнению);
КонецПроцедуры
Проверим, как работает этот шаг :
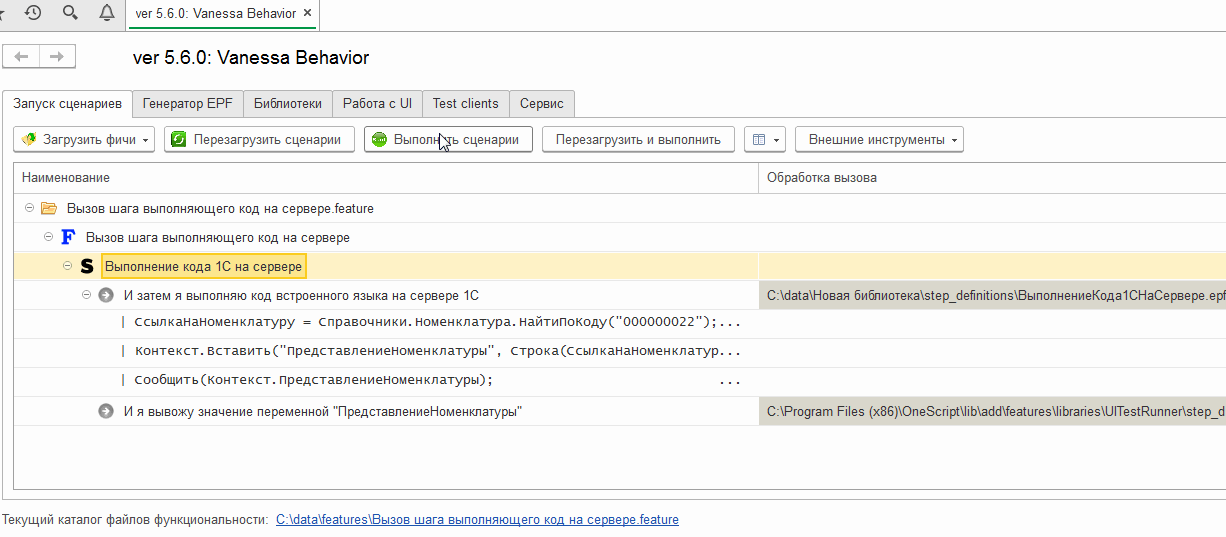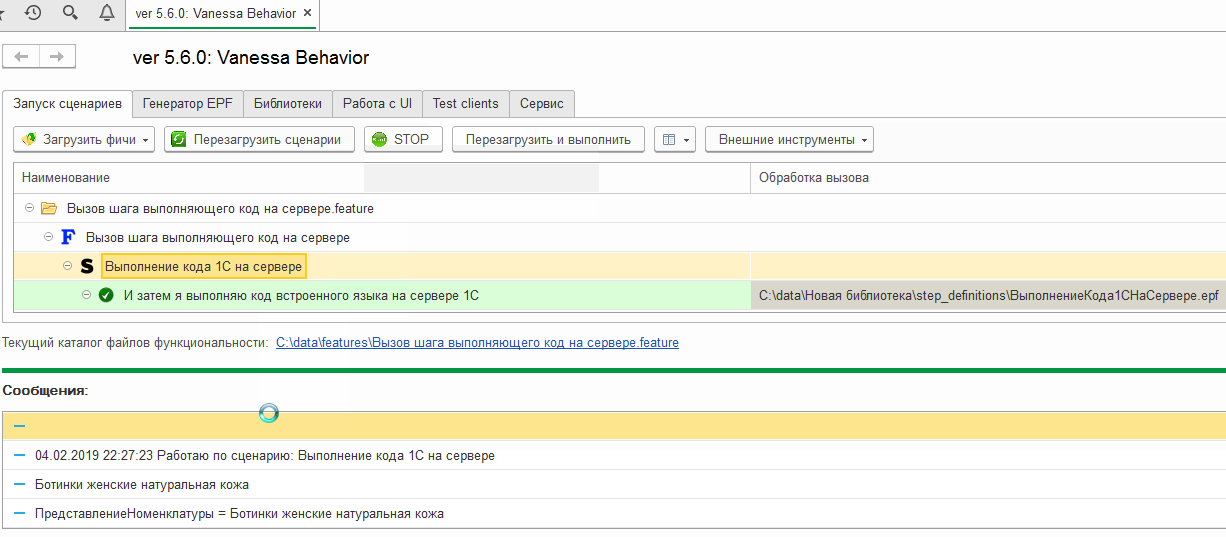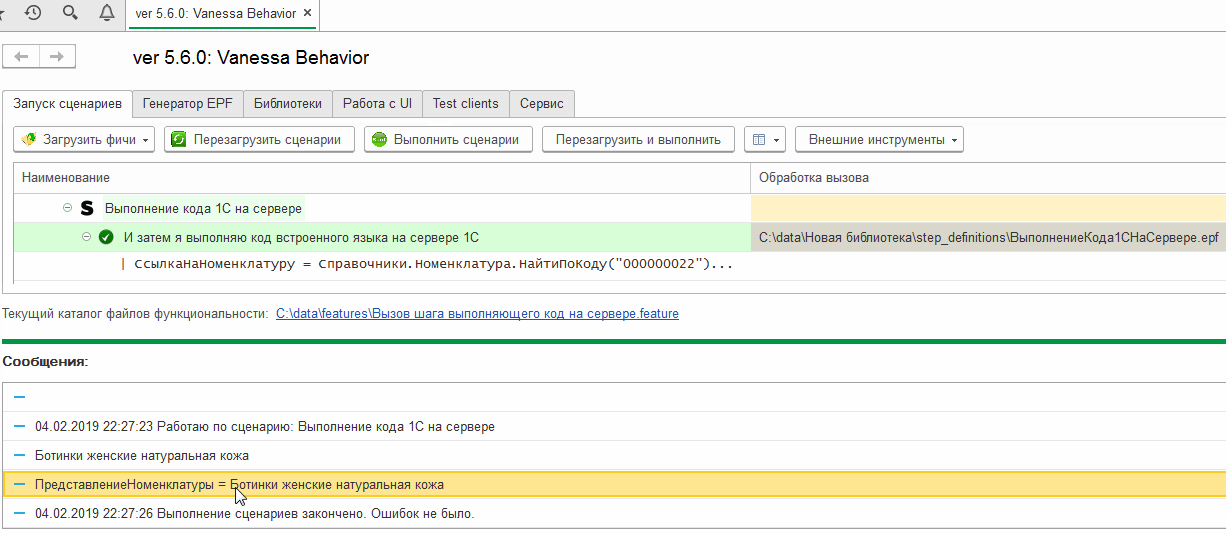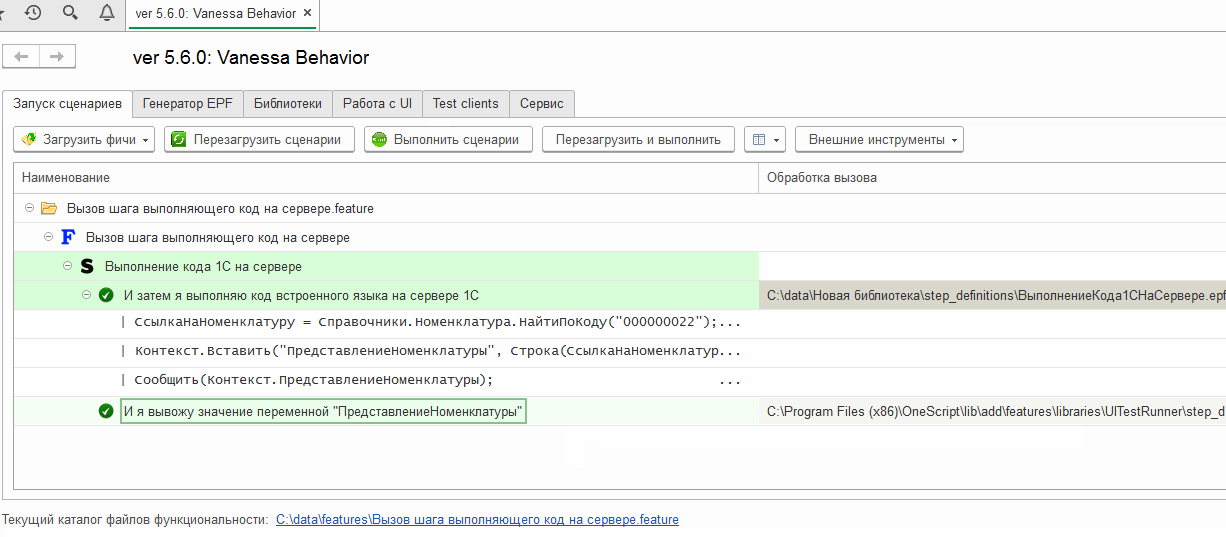
Экспортный сценарий: открытие формы последнего проведенного документа в тест-клиенте
Итак, теперь мы вооружены всем необходимым для создания комплексного шага, на основе ранее реализованного шага выполнения кода на сервере. Мы будем открывать форму последнего проведенного документа заданного типа.
Воспользуемся для этого экспортным сценарием. Конечно, этот шаг можно реализовать через внешнюю обработку и это было бы даже проще. Но в учебных целях воспользуемся экспортным сценарием. Это позволит еще раз посмотреть на работу с параметрами экспортного сценария.
Общий принцип будет следующим:
1) Получим ссылку на последний проведенный документ запросом.
2) От ссылки получим навигационную ссылку и запомним её в структуре контекст.
3) Когда структура Контекст окажется на клиенте мы откроем навигационную ссылку в тест-клиенте.
За образец кода открытия навигационной ссылки возьмем существующий шаг
Дано Я открываю навигационную ссылку "e1cib/data/Справочник.Справочник1?ref=ad018df0619b11d5458a440b8c472f30"
и его реализацию:

Этот шаг не умеет работать со структурой Контекст, но зато наш экспортный сценарий, выполняющий произвольный код, может всё что угодно! )) Экспортный сценарий будет выполнять код как на сервере 1С, так и код на клиенте. Вот он:
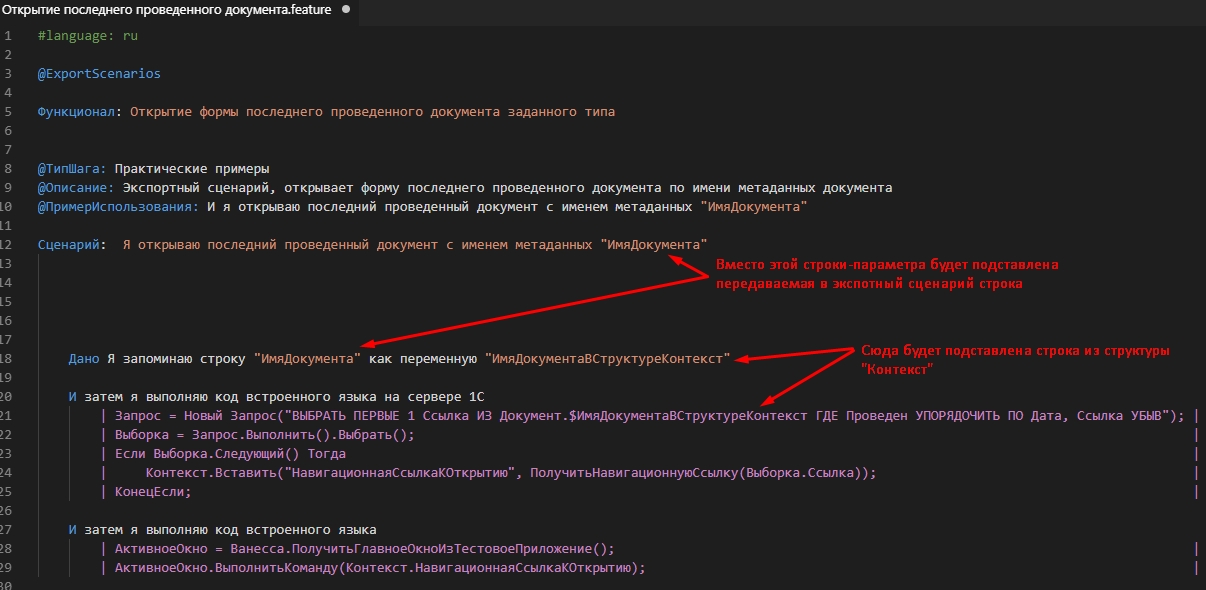
Проверить вызов сценария можно создав следующий фича-фал:
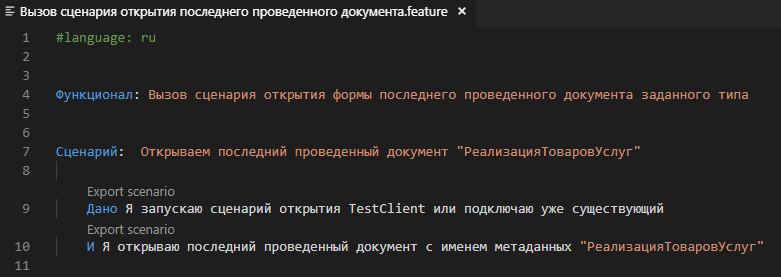
Загрузив его на исполнение можно увидеть что параметр шага был корректно поставлен в исполняемые шаги и в результате исполнения мы действительно получаем открытую форму последней проведённой реализации в тест-клиенте:
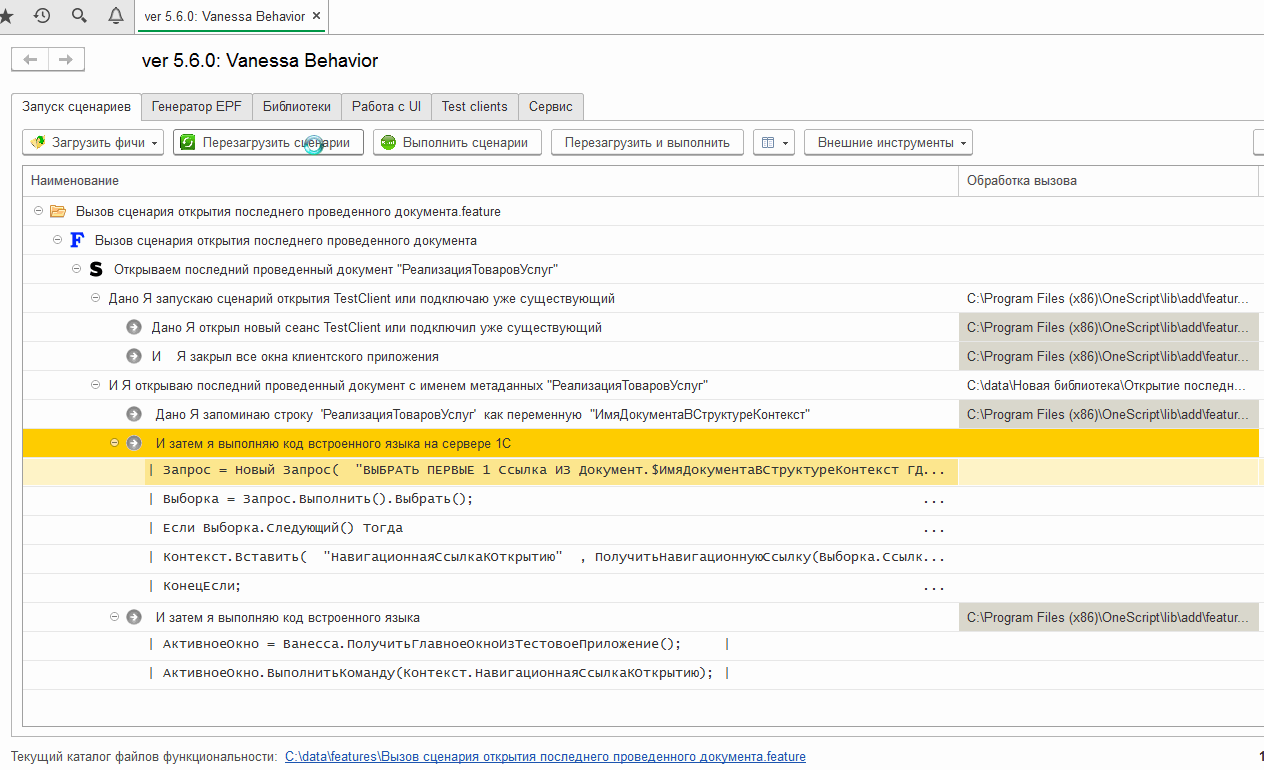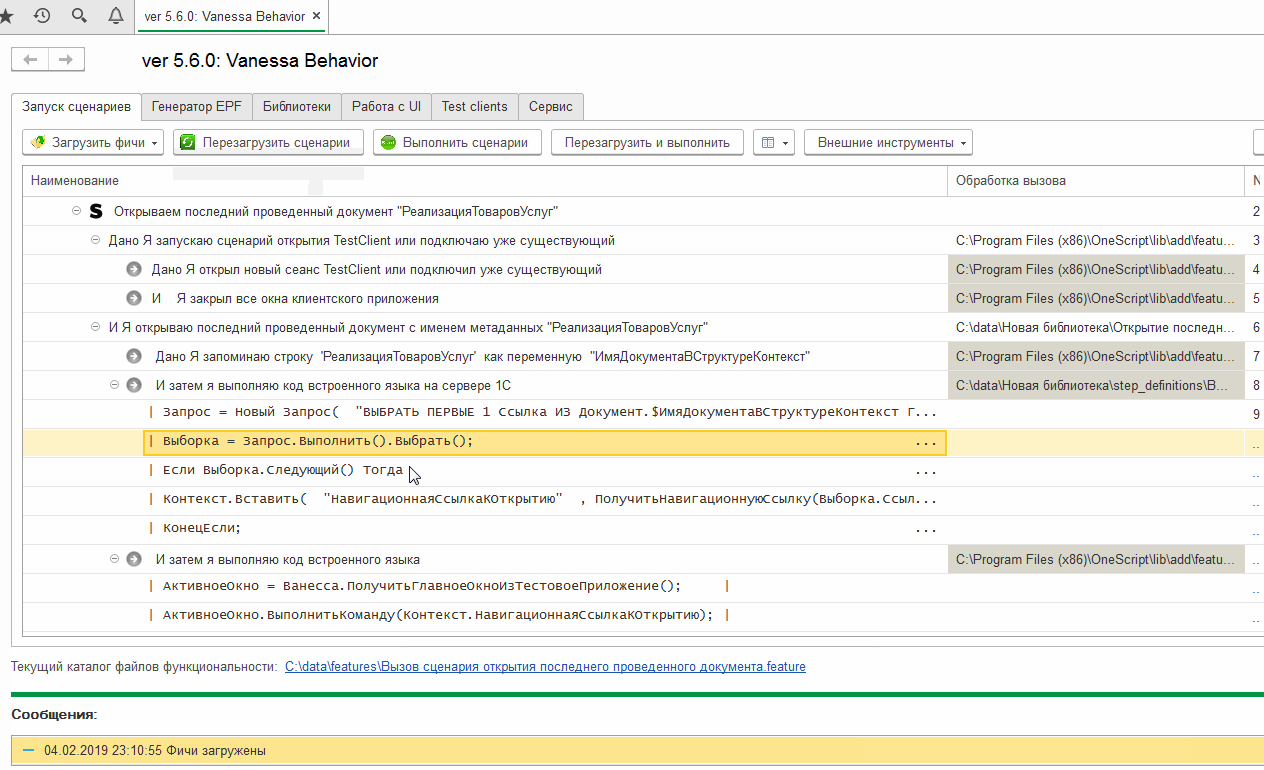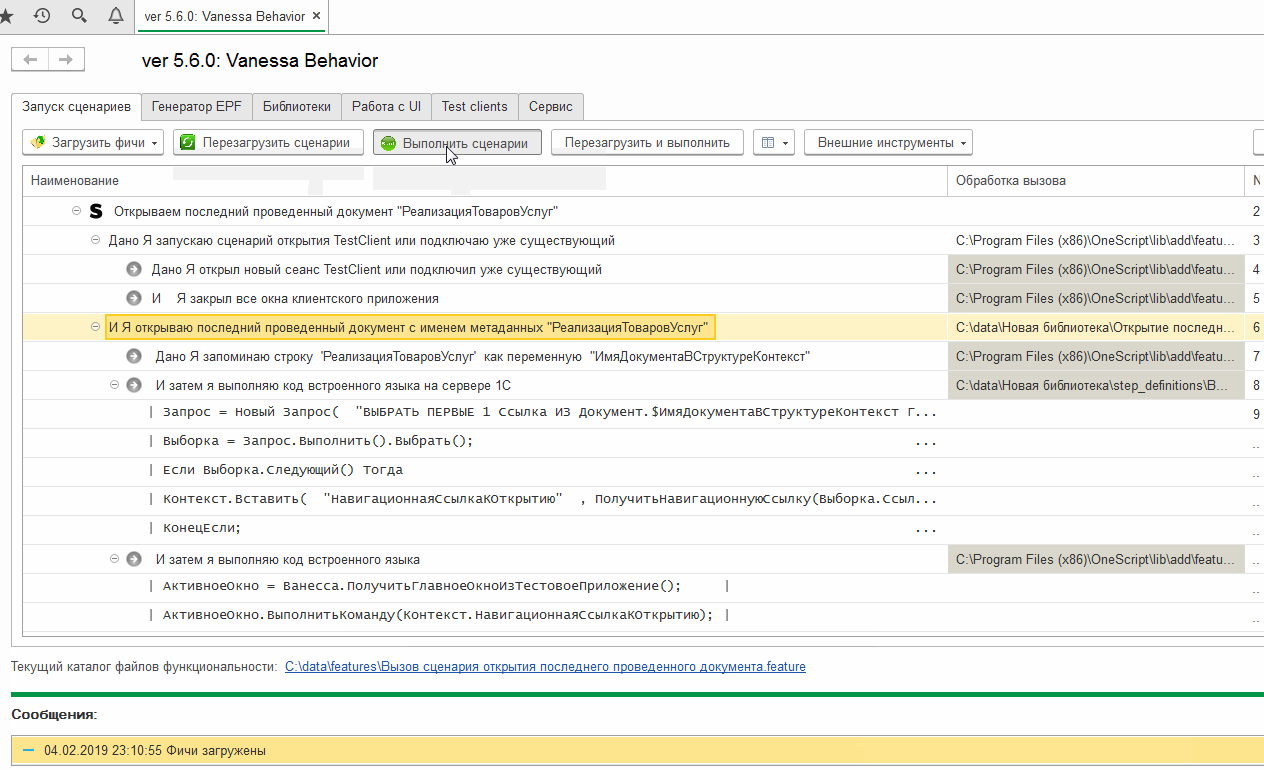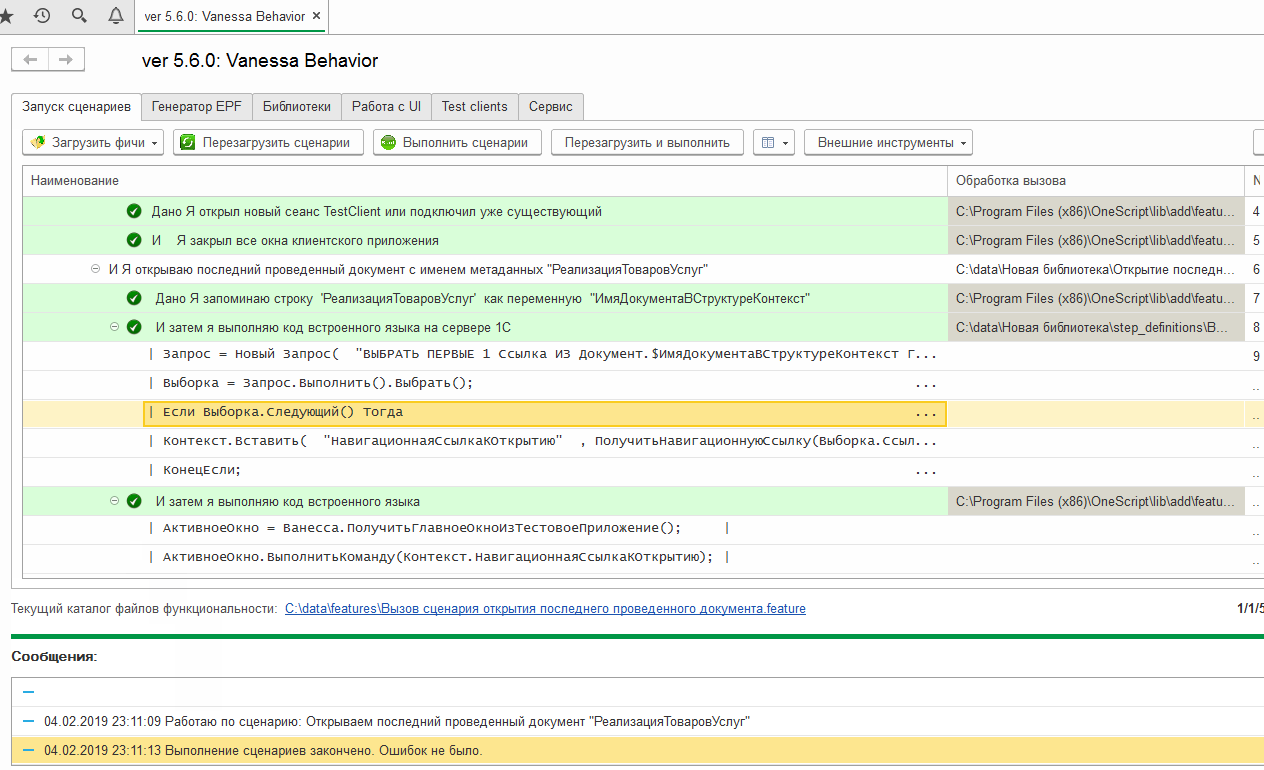
На этом мы заканчиваем рассмотрение собственных шагов, библиотек и экспортных сценариев. Надеюсь что приведённая здесь информация позволит Вам при необходимости расширять возможности встроенной библиотеки шагов и не ограничиваться её рамками.
В следующей заключительной части будут рассмотрены четыре темы:
- Запуск сценариев из консоли с применением стандартных консольных команд платформы 1С.
- Запуск сценариев из консоли с применением Vanessa-Runner (одной из библиотек OneScript).
- Формирование и открытие отчетов Allure по результатам выполнения сценариев.
- Снятие скриншотов в момент возникновения ошибки.
Понимание этих механизмов необходимо, чтобы начать построение CI-контура на основе Vanessa-ADD.
Не забывайте отмечать публикацию звёздочкой и делиться ссылкой - так вы поможете привлечь внимание сообщества к теме сценарного тестирования и окажете поддержку в выпуске следующей публикации на эту тему.
Вступайте в нашу телеграмм-группу Инфостарт