
{kind=link}
Что конкретно делает эта утилита:
- Перезаписывает файлы технологического журнала в измененном формате;
- Событие ТЖ целиком укладывает в одну строку, байты CRLF ставятся только в конце события;
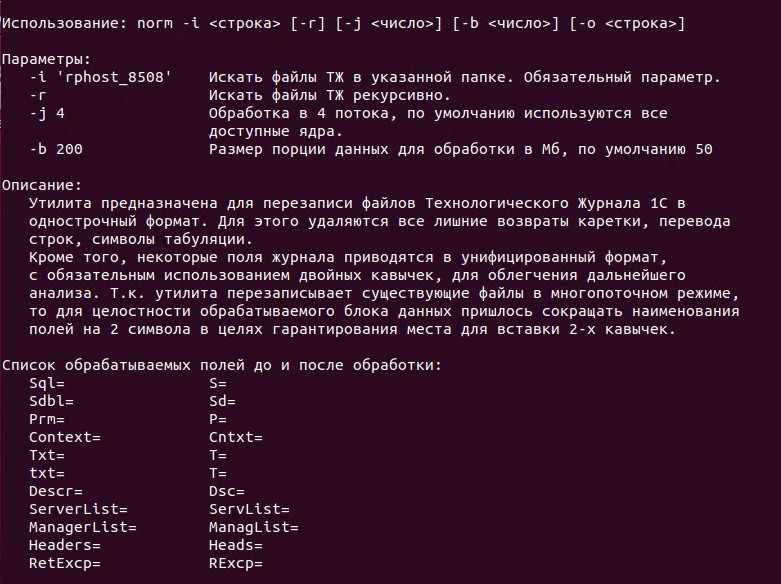
- Тексты всех полей Sql, Context, Txt и т.д. (всего на данный момент 11 полей) строго и безусловно заключаются в двойные кавычки. Полный список обрабатываемых полей можно получить, запустив утилиту без аргументов;
- Внутри текстов удаляются все переводы строк (CR, LF) и табы. Двойные кавычки и дважды двойные экранирующие внутри текста превращаются в одинарные. Благодаря этому и предыдущему пункту вы сможете значительно упростить регулярные выражения и ускорить их обработку для надежного извлечения полного текста события.
- Из имен временных таблиц в запросах SQL удаляются числа - это может понадобиться для группировки по тексту для поиска долгих запросов.
Важные особенности:
- утилита написана для GNU/Linux, но работает и в WSL (тестировалась под WSL Ubuntu);
- предназначена для обработки больших объемов ТЖ (сотни ГБ, возможно терабайты), поэтому переписывает существующие файлы с сохранением их размера и места; дополнительное место на диске не требуется (при отключении CoW);
- написана c использованием многопоточной обработки на C, без сторонних библиотек и регулярных выражений, поэтому теоретически выигрывает по скорости у bash-скриптов написанных с использованием perl и grep, но на практике космических скоростей конечно не будет: бутылочным горлышком станет скорость ваших дисков. 100% загрузку CPU вы вряд ли увидите, механические HDD и вовсе уравняют любые методы обработки;
- не имеет значения, обрабатываете ли вы один большой файл или множество мелких - утилита разбивает весь объём на порции данных, по умолчанию 50 МБ, но можно задать свой размер.
Ввиду необходимости сохранения размера файлов при многопоточной обработке и в связи с возможным отсутствием каких-либо кавычек в исходном ТЖ утилита производит сокращение наименований полей на 2 символа, например Sql= превращается в S=. Возможная недостача размера компенсируется с помощью дополнительных запятых после поля. Полный список полей и их новое сокращенное наименование можно получить, запустив утилиту без аргументов.
Пример использования:
./norm -i data -r
Число потоков: 6
Путь поиска: data
Рекурсивный поиск: да
#########################################################
#########################################################
#########################################################
#########################################################
###############
Время выполнения: 30.087497 сек.
Обработано данных: 10.77 Гб
Скорость обработки: 357.90 Мб/сек
Вступайте в нашу телеграмм-группу Инфостарт