







Постановка задачи и предлагаемые решения
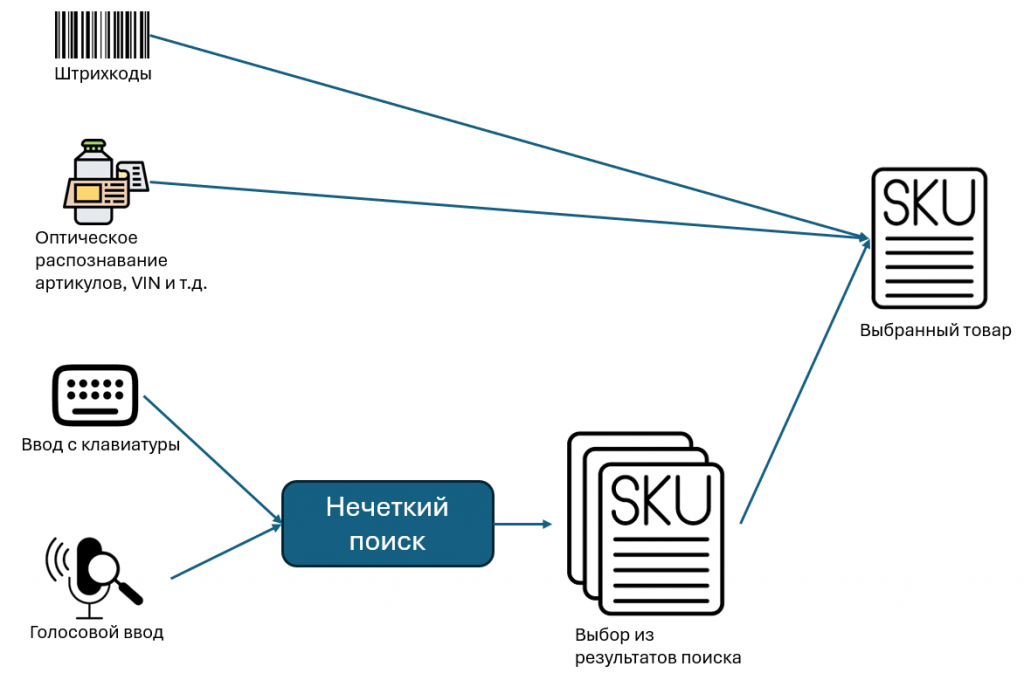
- Требуется идентифицировать товар с штрихкодами, без штрихкодов, но с каким-то текстовым идентификатором и без идентификатора. Т.е. условно 3 группы товаров.
- Все должно работать оффлайн – и сами справочники храниться оффлайн, и методы поиска тоже должны быть автономные. Потому что где-то есть покрытие, где-то нет. А даже если и есть 100% покрытие – зачем лишняя нагрузка на бек-систему? Офлайн быстрее.
С первыми двумя группами (штрихкоды и OCR) все понятно. OCR уже настолько же отработанная технология, как и штрихкоды. Для нее в Simple используется вторая генерация ActiveCV, почитать можно тут.
С оффлайном тоже все понятно – в Simple есть разные виды СУБД для хранения, но специально для «внешних данных» (справочников и прочих данных внешних систем) я сделал еще такой механизм, как «датасеты» - почитать можно тут: Датасеты меняют всё
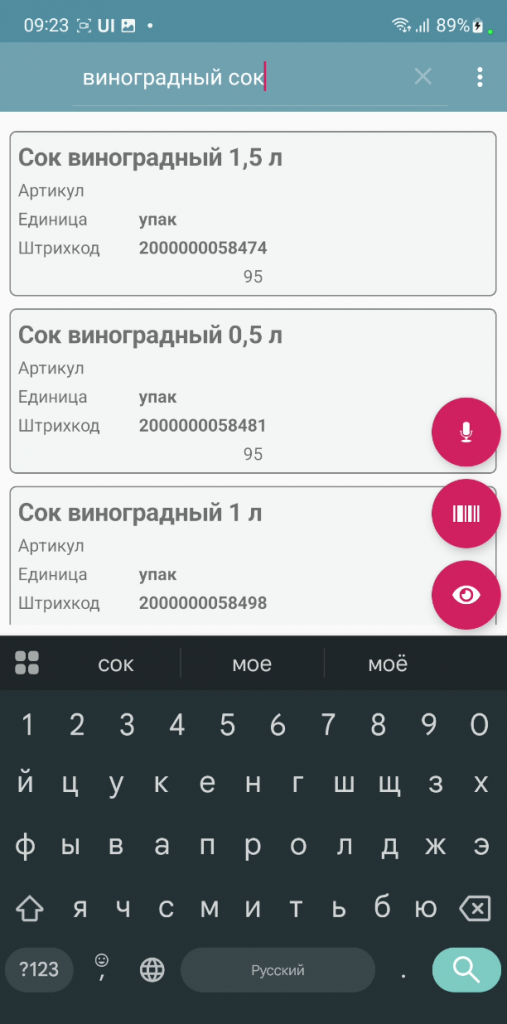
С третьей группой – чуть-чуть были вопросы. Просто дать экран с поиском по вхождению строки – не очень удобно на практике. Это на компе, с клавиатурой и большим монитором мы ищем в справочнике «Номенклатура». На ТСД это тоже можно делать, но очень неудобно. Получается, с таким товаром работа сильно замедлится? Но выход есть.
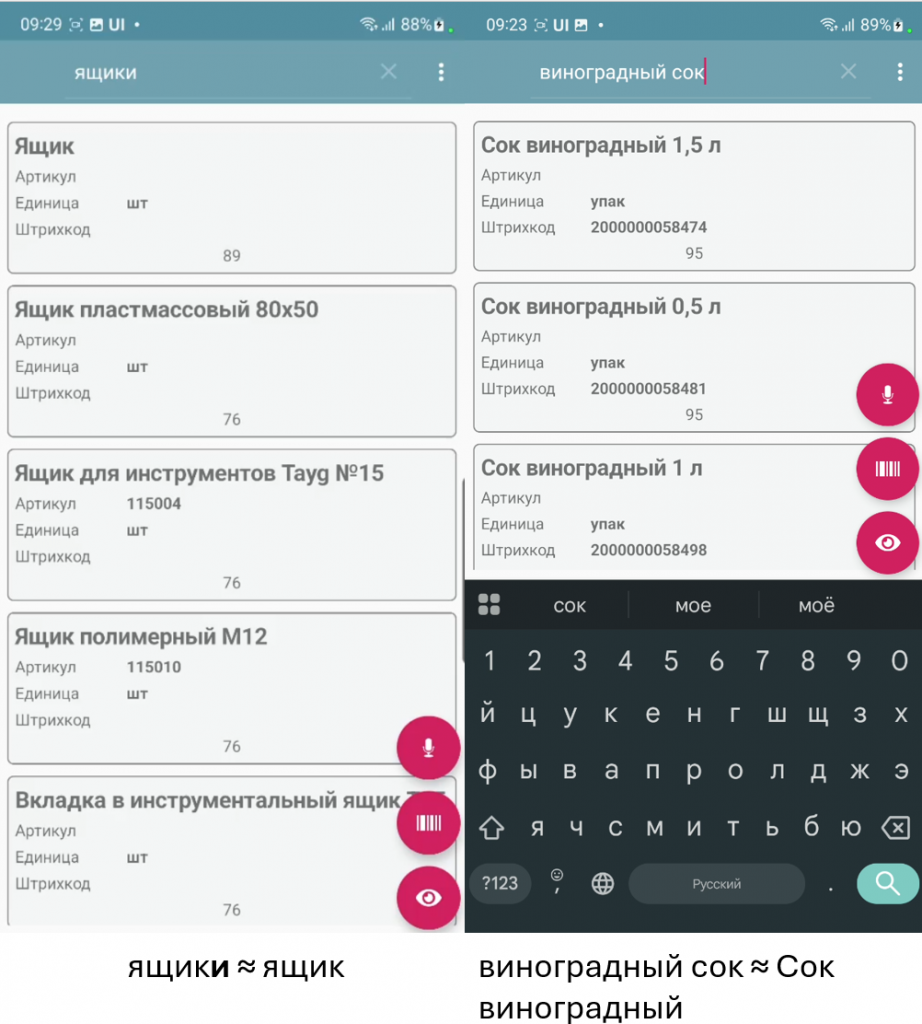
Первое, что было сделано – нечеткий поиск. Никакого предварительного индексирования, просто динамическая проверка расстояния Левенштейна по датасету. Работает быстро, сильно зависит от процессора устройства. Немного, конечно, медленнее, чем regex-поиск по вхождению строки, но зато и возможности поинтереснее. С нечетким поиском можно делать ошибки в словах и формулировать запрос более свободно. Это не вектора, эмбеддинги и векторные базы пока, но уже лучше, чем «вхождение строки»
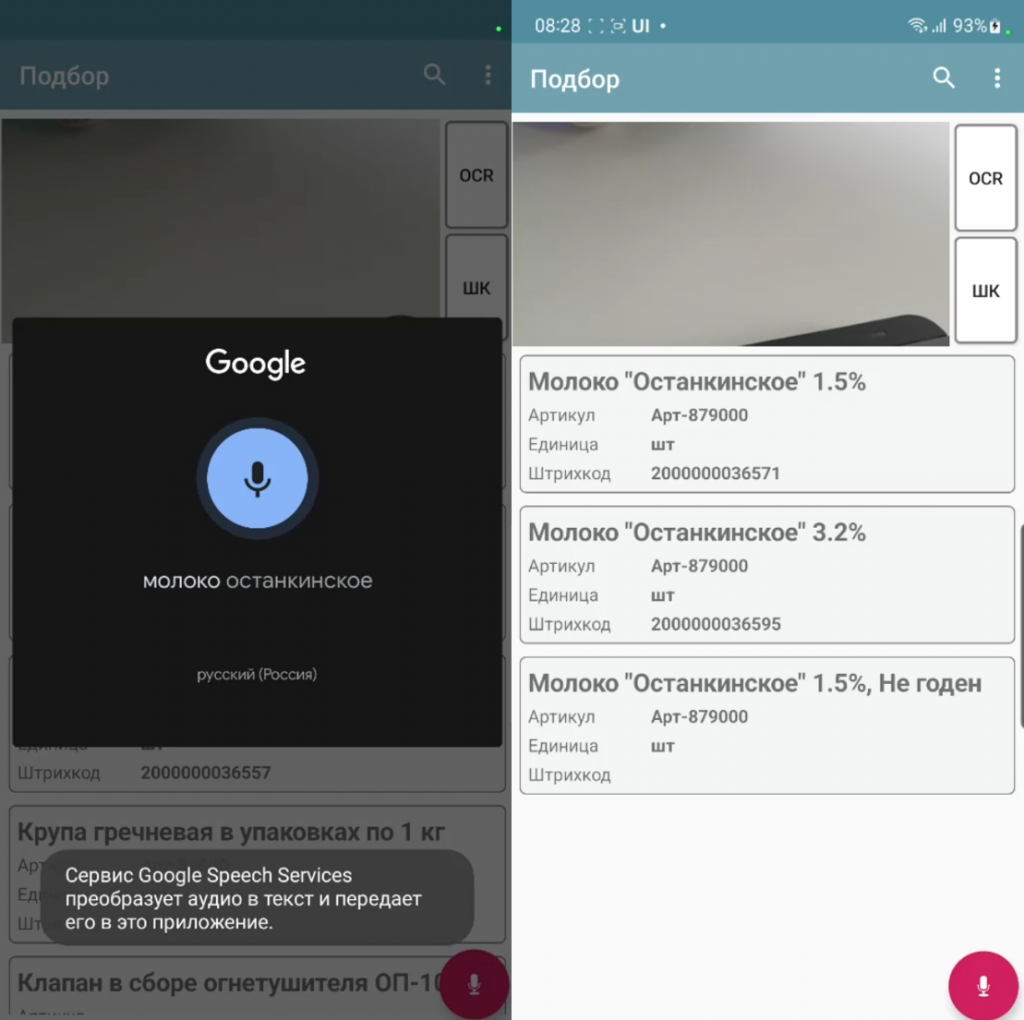
С нечетким поиском сразу напрашивается логическая связка – распознавание речи. Оно было в симпле, но я его сделал удобнее и с большими возможностями. Эта связка – «распознавание речи» + «нечеткий поиск» - это что-то! Это реально находка. Работает это так – нечеткий поиск выдает из датасета записи с точностью выше какой-то границы, отранжированные по убыванию. Наверху списка, соответсвенно, наиболее совпадающие. Т.е. получается в ситуации «пользователь абы что сказал -> как-то там оно распозналось (на самом деле распознавалка у Google отличная) -> что-то там нашлось и отранжировалось по релевантности» на каждом этапе ошибки возможны, но это частично нивелируется нечетким поиском, а частично тем, что пользователь сам делает выбор по результатам поиска. Да, имеем человеческий фактор. Но ускоряет это процесс? Однозначно.
На самом деле с нечетким поиском напрашивается еще одна связка – OCR. Об этом – ниже.
Что добавлено в релизе
Доработано распознавание речи
listen() в python и команда-переменная “listen” можно вызвать распознавание речи из кода. Например, в примере я вызываю при клике по карточке или при считывании штрихкода/распознавании артикула. Но, кстати говоря, еще можно использовать в SimpleUI так: повесить на аппаратную кнопку ТСД. Люди иногда работают в перчатках/рукавицах, и нажимать на экране неудобно. А так – нажал кнопку на ТСД, сказал команду – красота.
Оба варианта работают в зависимости от контекста исполнения:
1) если открыт экран, то событие onInput экрана (listener - voice_success)+ переменная voice_result
2) если вне контекста экрана эти 2 команды - то в общее событие падает событие onRecognitionListenerResult и результат.
Добавлен нечеткий полнотекстовый поиск
Для датасетов добавлен нечеткий поиск из коробки по алгоритму расстояния Левенштейна. Описание алгоритма, если кому надо, тут. По большому счету в симпле python, а значит написать его можно было и так, но чтобы быстро работало и было доступно сразу в датасетах - это сделано в новом релизе.
Поиск работает в двух ипостасях:
1) В виде поиска в тулбаре. Для этого в опциях списка надо написать метод levenshtein, например, так (да, списки теперь определяются так)
j = { "customtable": {
"options":{
"search_enabled":True,
"dataset_search":{"method":"levenshtein", "keys":"name","min_length":3}
},
"layout": "^item",
"tabledata":"~goods"}
}
2) В виде метода датасета findTextLevenshtein(String text,int confidence), в который передается поисковая строка и требуемая точность
ds = GetDataSet("goods") #берем датасет с товарами
goods_select = CreateDataSet("goods_select") #создаем новый датасет для результатов поиска
results = ds.findTextLevenshtein("name",hashMap.get("voice_text"),75) #вызываем нечеткий поиск, точность 75
goods_select.put(results) #записываем результаты в новый датасет
В результате будут выданы записи для датасета, подходящей точности, отсортированные по точности в порядке убывания. В каждом элементе датасета будет добавлено поле точности - _confidence.
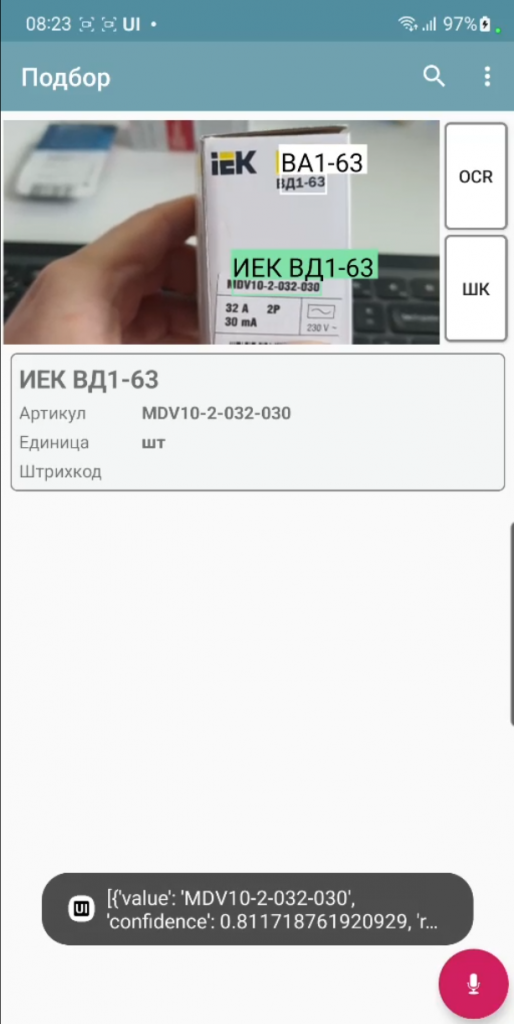
Добавлена команда для запуска ActiveCV на весь экран, с возвратом результата
RunCV2, <listener> - запускает из экрана ActiveCV на весь экран до считывания первого результата, после чего закрывает камеру и генерирует событие с указанным в параметре именем события. Эта возможность для ситуаций, когда что-то нужно быстро считать, а размещать на экране элемент ActiveCV не хочется или нет возможности (экран маленький). В примере ниже я использую чисто для распознавания OCR на новом движке ActiveCV2 для ТСД-варианта. На ТСД не нужен сканер через камеру (свой есть), а вот OCR нужен, но размещать на экране ActiveCV негде (экран маленький). Вот такое решение. Да, можно сделать отдельный экран, разместить на нем элемент ActiveCV и запускать его. Но мне показалось, что так удобнее.
Что еще планируется либо рассматривается по этой теме:
- Распознавание русского алфавита (грядет). Как следствие этого – не только распознавание артикулов, содержащее русские буквы, но и более интересное – распознавание названий на коробках с тем, чтобы скрестить это с нечетким поиском. Вот это будет интересно.
- Улучшенное распознавание текста с термальной/лазерной и другой не очень хорошо читаемой печати (грядет)
- Эмбеддинги русского языка – экспериментирую, но пока неясно. А так бы было неплохо говорить «долото» вместо «зубило» (под вопросом)
- Другие варианты нечеткого полнотекстового поиска (исследуется)
- Локальная LLM для работы с датасетами – тут все зависит от Google и его политики. Но планы есть. Это, конечно, все поменяет – тут не только поиск, но и отборы по товарам по промптам (под вопросом, но очень хочется)
- Подключение своих обученных моделей для классификации изображений. Если классов (товаров, которые надо распознавать по виду) не очень много – то тоже норм вариант. Но, например, «песок карьерный» от «песок речной» вряд ли она отличит (будет)
- Уже давно есть, но на ActiveCV-1, сейчас ActiveCV-2, туда еще не перетащил – one-shot распознавание 2-D объектов по фичам. Писал тут: https://telegra.ph/OpenCV-v-relize-SimpleUI-1150-04-20
Суперпоиски
Тестировалось на 1С:Предприятие 8.3 (8.3.16.1148) на конфигурации 1С:Комплексная автоматизация 2 (2.4.8.63)
В приложении к статье две конфигурации – это два варианта окна ввода товара и количества, т.е. своеобразная корзина. Ищется/вводится товар, вводится количество, данные складываются в датасет, который можно посмотреть в отдельном окошке. Это не самостоятельная конфигурация, а модуль для встройки в другие конфигурации, либо пример.
Со стороны 1С нужно опубликовать сервис OData и дать доступы на:
- Справочник Номенклатура
- Справочник УпаковкиЕдиницыИзмреения
- Регистр сведений ШтрихкодыНоменклатуры
В настройках вводятся данные подключения к OData 1С.
При загрузке данные справочников и регистра «склеиваются» в один датасет. Берутся товары только без характеристик. Для упрощения примера.
Он отображается в виде списка с нечетким поиском.
В обоих вариантах поддерживается голосовой ввод количества, см. видео.
Конфигурация «для телефонов»
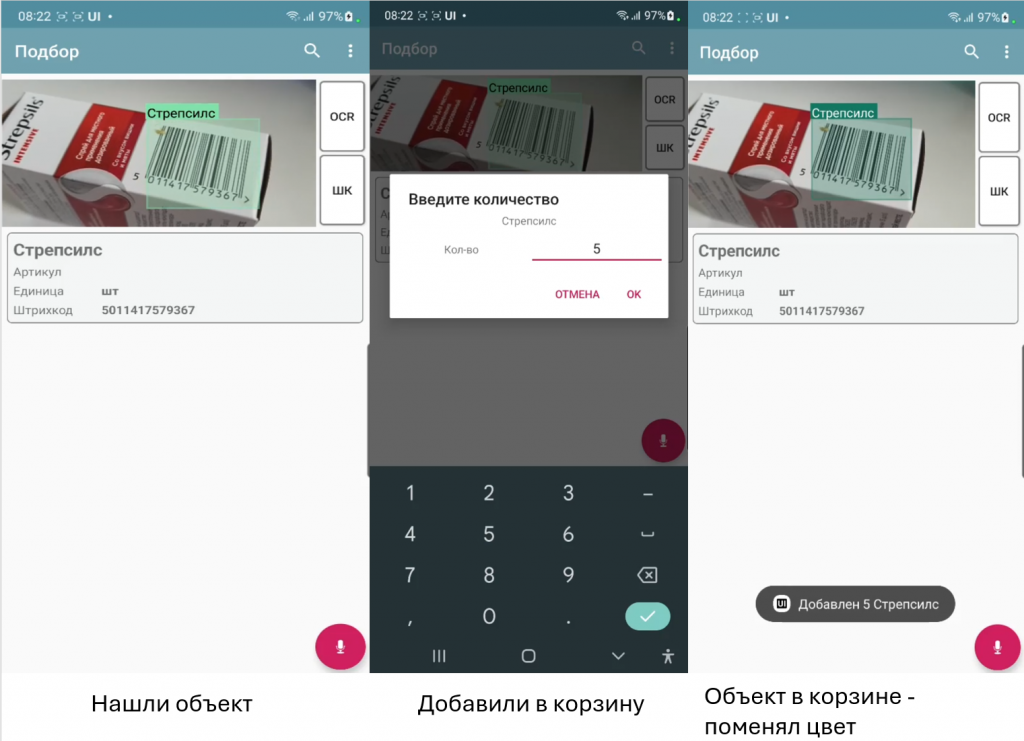
Окно распознавания штрихкодов/артикулов вписано в экран. Режим штрихкоды/артикулы переключается кнопками.
Подсветка объектов в ActiveCV переключается: если объект не найден – белая, если найден, но пока не в корзине – светло-зелёная, найден и в корзине – тёмно-зелёная.
Поиск может быть в тулбаре. Это нечеткий поиск. И также ввод поискового запроса голосом. Тоже нечеткий поиск.
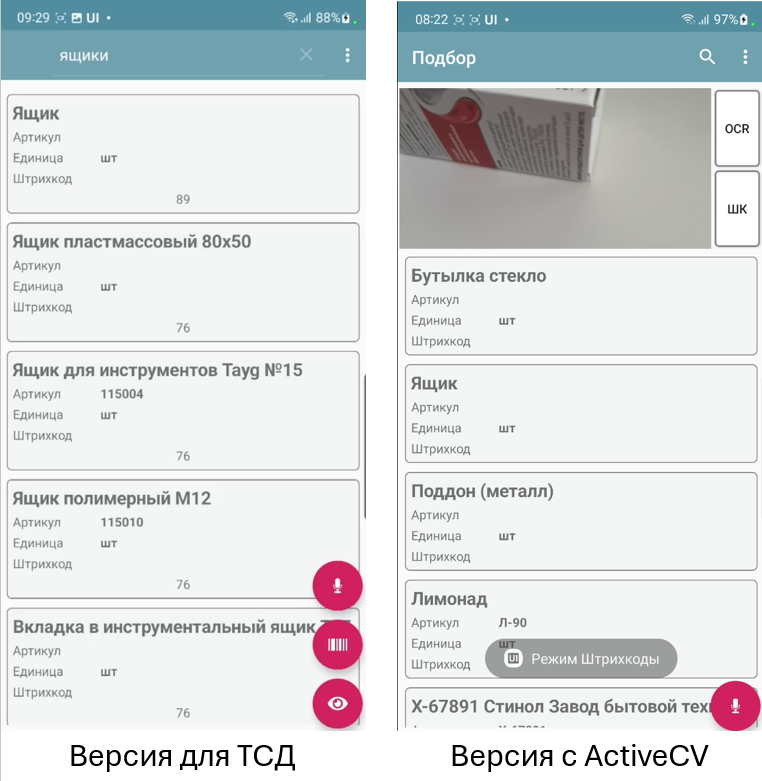
Конфигурация для ТСД
Для ТСД отличия в том, что нет окошка ActiveCV. OCR запускается отдельной кнопкой в отдельном окне. Штрихкоды считываются встроенным сканером. Остальное – аналогично.
Я решил в статьях также писать используемые технологии в примерах. Вот список технологий в этой статье:
- работа с датасетами и обновленный синтаксис списков
- работа с обновленным хранением ключ/значение (запись настроек непосредственно, без кнопки)
- новая работа с диалогом
- нечеткий поиск
- новая работа с распознаванием речи
- ActiveCV-2 и OCR на датасетах, запуск ActiveCV в новом окне с возвратом

Для работы примеров понадобится версия 14.35.55, ее можно скачать на моем сайте https://simpleui.ru/
Конечно же, Телеграмм-канал проекта, в котором масса всего полезного: https://t.me/devsimpleui
Вступайте в нашу телеграмм-группу Инфостарт