
Почти все бизнесы сейчас основаны на данных. Если с данными проблемы – будут большие сложности.
В связи с этим многие руководители задаются вопросом – умеют ли сотрудники в моей компании работать с данными? Причем под сотрудниками в контексте данных обычно подразумеваются аналитики, потому что разработчикам, тестировщикам, DevOps-ам и админам работать с данными зачастую не нужно.
О роли аналитиков и пути данных в компании мы сейчас и поговорим.

Сегодня мы поговорим о таких понятиях, как:
-
аналитический ревматизм;
-
мир данных;
-
связь с ML;
-
bad & best practice – непосредственно плохие и хорошие практики;
-
и кто же такие аналитики – без этого нельзя, это наша ретроспектива.
Аналитический ревматизм
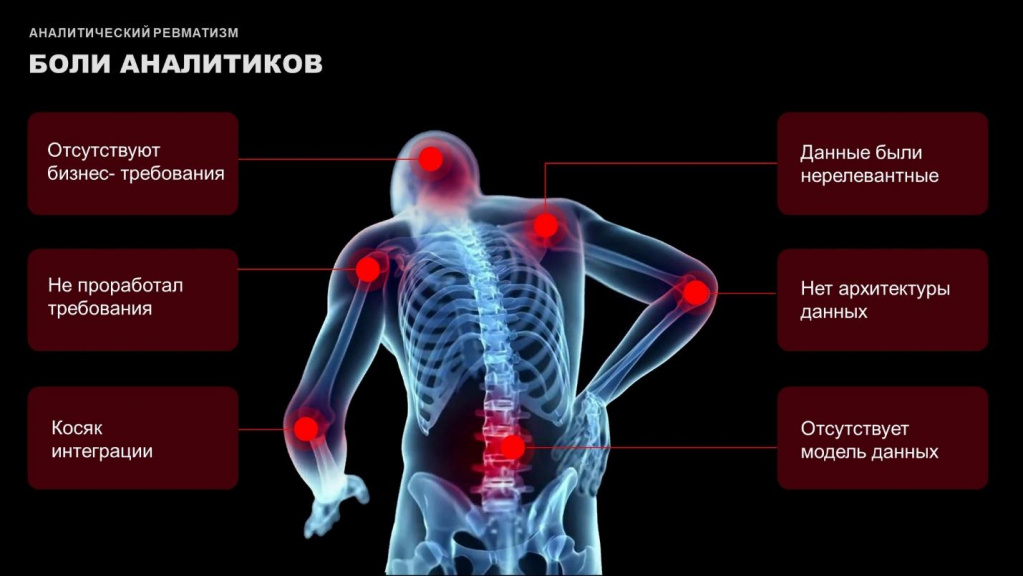
Какие могут быть боли у аналитиков? Причем, если эти боли не испытывает аналитик, их испытывает вся команда или ее руководство.
-
отсутствуют бизнес-требования;
-
требования не проработаны;
-
нет архитектуры данных;
-
отсутствует модель данных;
-
интеграция валится;
-
данные нерелевантные – вам предоставили какую-то синтетику, но она совершенно не соответствует природе вашего бизнеса.

Теперь про боли full-stack аналитиков.
Я говорю про full-stack аналитика, потому что в командах разработки на аналитика чаще всего смотрят не только как на системного, бизнес-аналитика или дата-аналитика – он каждый раз надевает на себя новую шляпу, выполняя все эти функции.
Какие боли у full-stack аналитика могут быть:
-
Отчет работает неправильно, хотя ТЗ на него было изначально поставлено корректно.
-
API реализовано, но его приходится постоянно дорабатывать через hotfixes.
-
Интеграция между системами прошла успешно, но обнаружились проблемы, которые тоже нужно исправлять.
-
Реализовали десяток витрин, но источники мигрируют с одной СУБД на другую (с Oracle на PostgreSQL с MS SQL на PostgreSQL или с MS SQL на ArenaData – в разных компаниях бывает по-разному). Если у вас нет моделей данных и основных артефактов, на которые можно опираться, а данные перешли из одной системы в другую и несколько раз преобразовались, их будет сложно отследить.

Применим эффект подорожника.
-
Для первого случая с неправильно работающим отчетом применим модель данных;
-
Для случая с API – базовые артефакты тестирования;
-
Для интеграции – архитектуру с бизнес-анализом;
-
И для миграции источников данных – снова модель данных.
Данные и мир данных

Перед тем, как заходить к анализу DataFlow, поговорим вообще о данных.
Важны ли нам данные, когда мы делаем отчетность? Или когда менеджер принимает то или иное управленческое решение?
Данные имеют три агрегатных состояния.
-
Когда у вас в огромнейшем хранилище лежит несколько терабайт данных, не факт, что все эти данные вам нужны. Не факт, что нужно беспокоиться об их качестве, производить какую-то дополнительную репликацию или хранить эти данные на нескольких кластерах. Потому что информации как таковой там может не содержаться.
-
Второе агрегатное состояние характеризуется тем, что мы из данных извлекаем информацию.
-
И далее менеджер или тот, кто собирается принимать на основе информации те или иные решения, получает из информации знания. Аналитик предоставил отчет с цифрами, и если менеджер понял его, то у него есть знания.

Теперь давайте взглянем на мир данных глазами аналитика, разработчика – базовых ролей нашей команды.
Аналитик – это человек, который приносит пользу бизнесу. Он визуализирует, исследует, анализирует, прогнозирует, систематизирует.
Именно аналитик работает над агрегатными состояниями данных по цепочке «данные – информация – знания». Никто другой больше не будет погружаться в природу данных. Никому другому это не нужно.

Если аналитик не понимает, что такое метаданные, мастер-данные, НСИ (нормативно-справочная информация) или транзакционные данные – тут большая проблема. Пожалуйста, обучитесь – иначе вы потом не сможете принести пользу для бизнеса.
Это характерно для сеньоров или middle-plus аналитиков.

Еще раз, аналитик при работе с данными – исследует их, визуализирует, прогнозирует, систематизирует и анализирует.

Теперь посмотрим на данные с точки зрения разработчиков.
В привычном понимании, разработчик – это человек, который кодит. Но это тот же человек, который интегрирует, настраивает, запускает.
Разработчику не важна природа данных. Он запускает тот или иной конвейер, обрабатывает данные, но ему не важна их природа.
То же самое касается и тестировщика. Он проверяет, сопоставляет и всесторонне моделирует те или иные сложные ситуации для вашего продукта, но ему, опять же, не важна природа данных.
То же самое касается девопсера или администратора – ему тоже не важна природа данных.
Мы пришли к тому, что только аналитик смотрит на данные по всему их жизненному циклу и по всем агрегатным состояниям «данные – информация – знания». И только аналитик заглядывает в природу данных.
Паттерны работы с данными
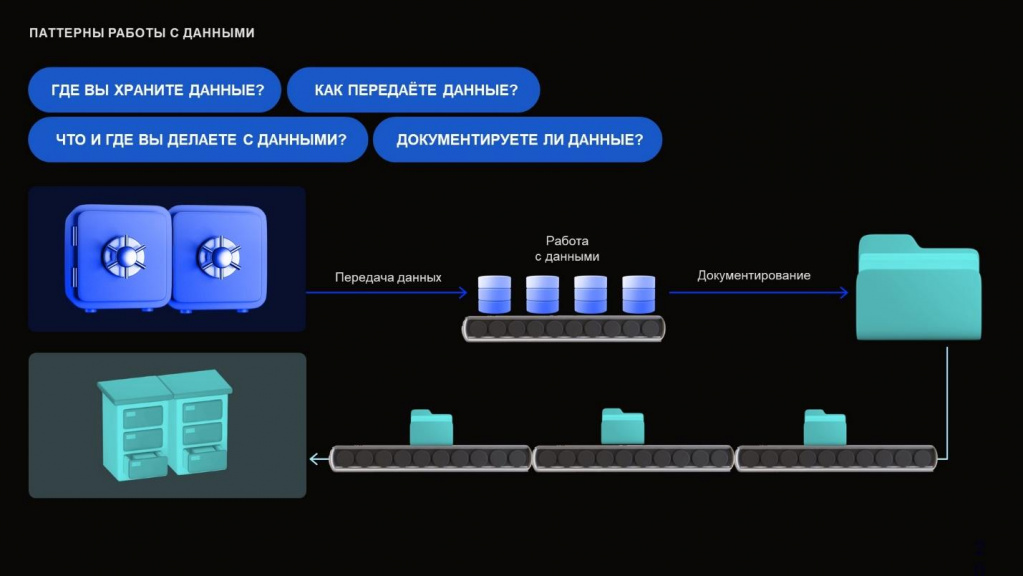
Перед тем, как мы вообще поговорим о том, что делать с данными, надо задаться главными вопросами:
-
Где вы храните ваши данные?
-
Как передаете данные?
-
Что вы с ними делаете?
-
И как документируете?

Данные можно хранить по-разному:
-
в базе данных;
-
на тех или иных видах накопителей – DWH и тому подобное;
-
в локальных каталогах;
-
либо в облаке.
Важно понимать, что где бы вы ни хранили ваши данные, если они важны для бизнеса, и вы их собираетесь дальше обрабатывать – пожалуйста, создавайте модели данных. Либо описи данных, опись данных — это самый простой вид модели данных.
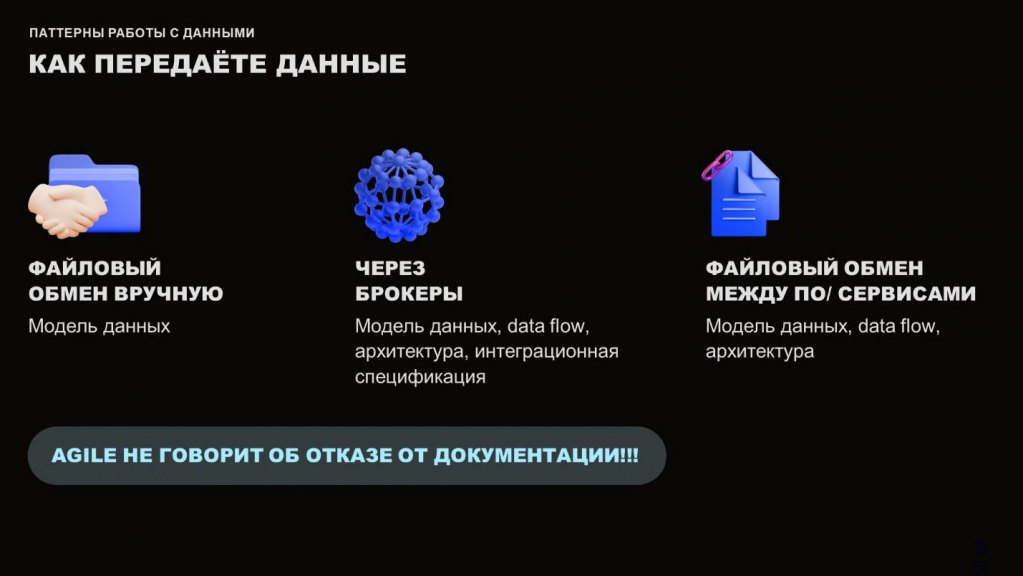
Какие артефакты нужно иметь, когда вы передаете данные? Без этих артефактов вы со временем либо забудете о том, что делали, либо будете долго делать hotfixes, либо получите недовольство от тех, кто будет поддерживать ваш обмен – им придется во всем разбираться с нуля.
-
Когда у нас происходит файловый обмен вручную, вы должны приложить к нему модель данных – передать на флешке или отправить сообщением.
-
Если у вас используется обмен через брокер, например, Kafka – сразу же составляем модель данных, DataFlow, архитектуру и интеграционную спецификацию.
-
Без интеграционной спецификации мы не сможем понять, какие параметры были у обмена.
-
Без DataFlow мы не понимаем, откуда и куда данные шли.
-
А без модели данных мы не понимаем, как они преобразовывались.
-
-
И если у вас используется обмен по API, обязательно составляйте модель данных, DataFlow и архитектуру.
Если вы сделали синхронизацию между двумя филиалами, а потом этот обмен надо масштабировать на 40 филиалов, и где-то это все объединить, вам будет крайне сложно это сделать без базовых составляющих артефактов. Придется нанимать человека, который будет все это копать и исследовать. И не факт, что он откопает – возможно, будет дешевле переделать все полностью.

Теперь поговорим о том, что мы делаем с данными.
Базовый CRUD никто не отменял – мы создаем данные, читаем, изменяем, удаляем.
С точки зрения Data Governance – политики управления данными – у нас на этом этапе выделяются следующие роли:
-
владельцы данных – непосредственно те, кто отвечают за источники ваших данных (когда мы работаем с бизнесом, это непосредственно бизнес);
-
распорядители данных или так называемые дата-стюарды – те, кто распоряжается данными;
-
архитекторы – те, кто выстраивает непосредственно сами потоки данных;
-
и специалисты по информационной безопасности. Когда мы работаем с данными, которые являются собственностью других компаний, мы должны понимать, что храним у себя (действует ли на эти данные банковская либо коммерческая тайна) и какая безопасность у нас есть для этих данных – шардируем мы эти данные (на скольких кластерах храним), есть ли у нас для них то или иное геораспределение.

Теперь поговорим о таком артефакте, как модель данных. Без модели делать какие-либо преобразования с данными нежелательно – если у вас 10, 20, 30, 40 витрин, и вы сделали преобразование из 15-17 источников, без модели вы это потом не соберете.

12 шагов создания модели данных:
-
Изменение атрибута;
-
Тип данных источника;
-
Слои источника;
-
Схема источника;
-
Витрина-источник;
-
Описание преобразования.
-
Следующие шаги описывают, куда мы все это укладываем в целевом виде. Причем слои там можно опускать, если у нас происходит интеграция между системами, где слоев как таковых нет. Например, в 1С есть PostgreSQL, и для разработчика неважно, как это все устроено. Но если мы сами выстраиваем хранилище и хотим понимать природу, мы определяем, в какой целевой слой мы должны эти данные положить.
-
Далее описываем.
-
И приводим пример.
Эти 12 атрибутов будут вашей «рыбой» для любого артефакта модели данных.
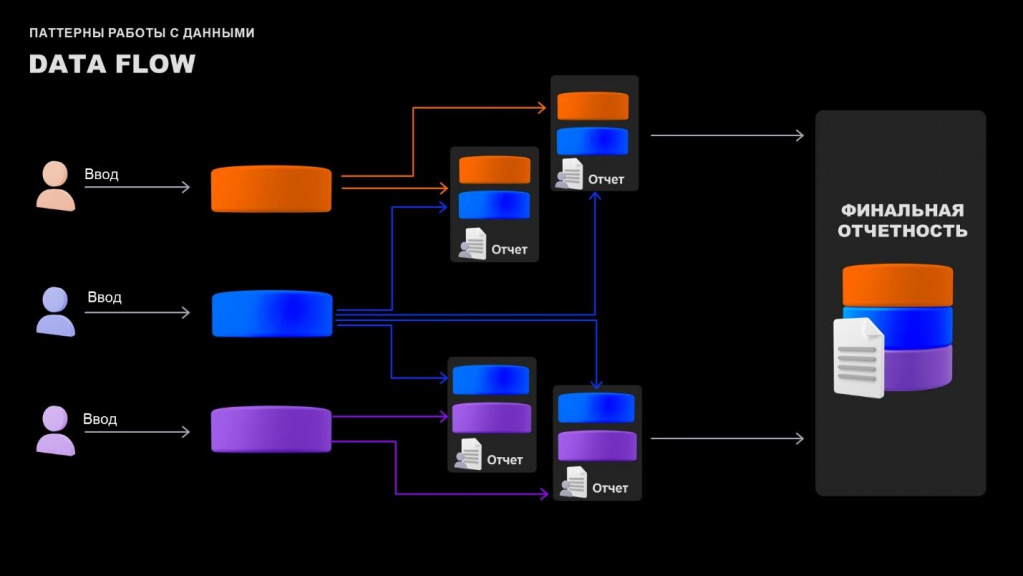
Теперь несколько слов о DataFlow.
Когда аналитик или архитектор разрабатывает DataFlow, он показывает потоки данных – как данные переходят из одной системы в другую. Или иллюстрирует взаимодействие между таблицами витрин данных.
Обратите внимание, что на представленном на слайде DataFlow есть четыре промежуточных шага, где пользователь может выгружать отчеты и делать манипуляции с данными.
Причем не все точки изменения данных попадают в финальную отчетность. И потом, если полученная финансовая отчетность не совпадает с тем, что должно быть, у нас подключается целый большой департамент финансистов. Они начинают обрабатывать данные и судорожно пытаются понять, а в чем же проблема – откуда дубликаты, почему у нас не сходятся данные по номенклатуре, почему справочники у нас не работают.
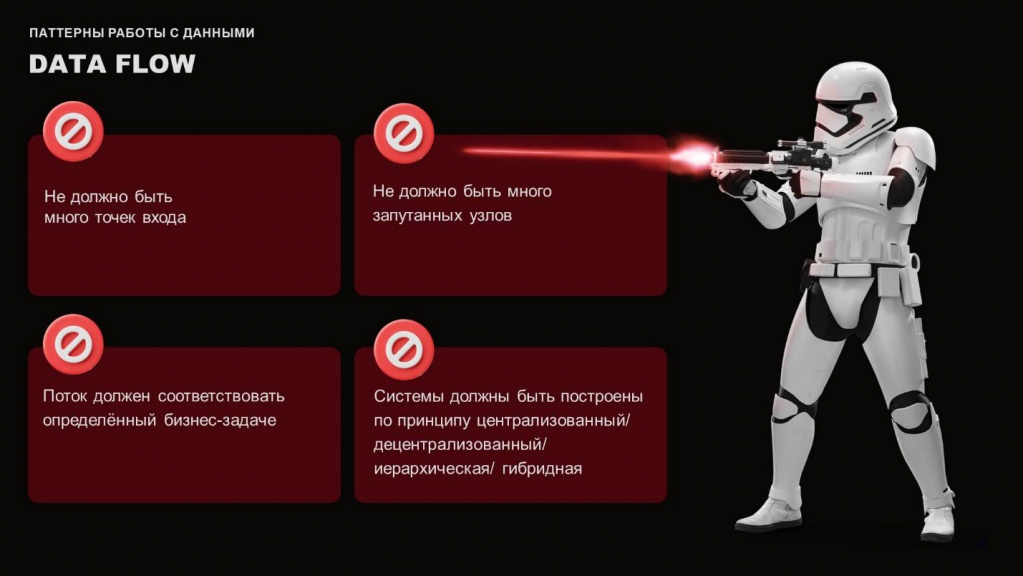
Поэтому при построении потока данных DataFlow, вы должны задаться следующими вопросами:
-
откуда данные идут;
-
куда идут;
-
какие промежуточные узлы у вас есть;
-
сколько точек входа, где пользователи могут зайти и что-то сделать.
И дальше важно учитывать четыре основных параметра:
-
Не должно быть много точек входа. Например, у вас есть одна веб-форма, через нее пользователи вводят какую-то информацию. Если у вас будет множество разных веб-форм, куда будут пользователи что-то вводить, и вы потом не будете их актуализировать и постоянно управлять ими, пользователи будут вводить уже какие-то непонятные вещи. Грубо говоря, вы разработали это десять лет назад, на текущий момент это совсем нерелевантно, но пользователи туда что-то вносят.
-
Поток данных должен быть всегда согласован с бизнес-процессом – это вообще база.
-
Не должно быть множества запутанных узлов.
-
Система должна быть построена по определенному принципу – централизованная, децентрализованная, иерархическая, гибридная.
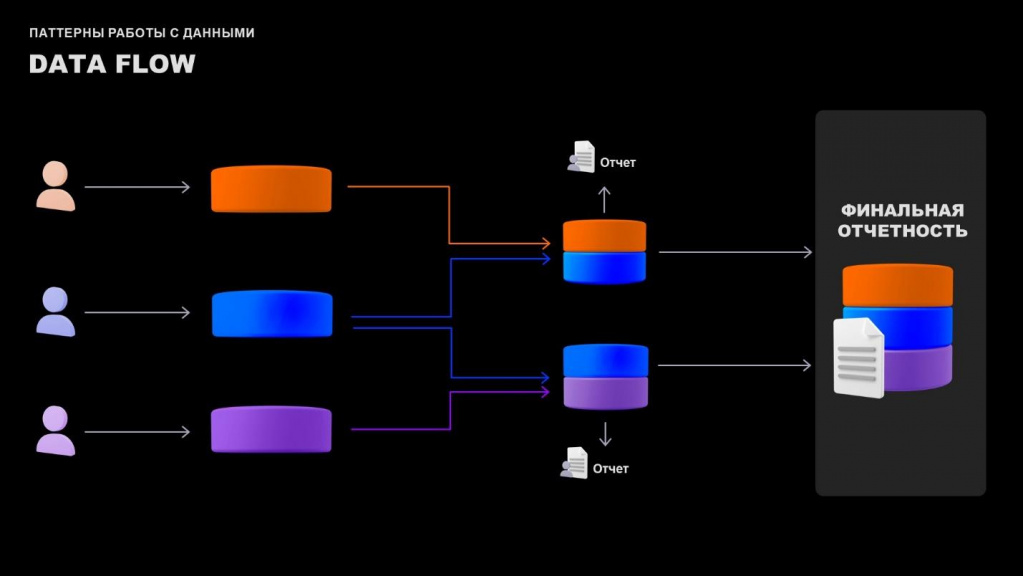
Здесь показан исправленный – адекватный данный поток данных DataFlow, где на промежуточных узлах мы уже не позволяем пользователям изменять основную информацию, которая потом пойдет в итоговое хранилище и будет использоваться для финальной отчетности.
В любом случае, это абстракция, но эта абстракция помогает найти ошибки потенциальной архитектуры.

На что еще стоит обратить внимание при работе с данными?
-
На наименование таблиц и баз данных – сразу договориться об этом внутри той команды разработки, в которой вы работаете. Иначе со временем, когда вы будете создавать какую-то сложную систему, у вас будут большие проблемы.
-
Опять же, это базовые артефакты – архитектурная схема данных и интеграционная спецификация.
-
Задуматься о качестве данных, которые у вас будут. Если вы не обращаете внимание на качество данных, вы сделаете непонятно что – у вас будут дубли, отчетность будет распадаться, в ней будут какие-то расхождения. На это очень важно обращать внимание.
-
Определение видов данных – для характерных типов данных стоит применять характерные паттерны их обработки.
Связь с ML

Теперь поговорим о машинном обучении, ML.
Во всех современных компаниях используются инструменты, связанные с машинным обучением. Все больше и больше компаний внедряют чтение QR-кодов, чтение штрих-кодов, анализ посетителей с занесением информации в базу данных и т.д.
Попробуем понять, при чем тут мы – аналитики, разработчики, руководители отделов.
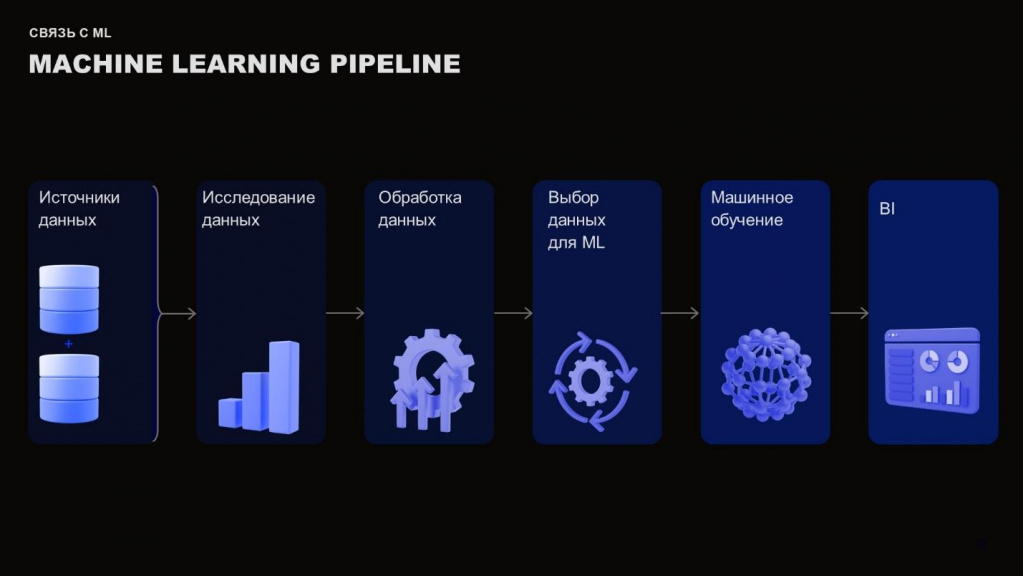
Посмотрим на конвейер машинного обучения. Чаще всего этот конвейер для нас – черный ящик, но в его исследовании мы играем большую роль, что потом может очень хорошо или очень плохо сказаться на бизнесе.
-
У нас есть источники данных.
-
В дальнейшем происходит их исследование, предпроцессинг и обработка – нам надо привести данные к такому виду, чтобы наша модель машинного обучения могла все это обработать.
-
И дальше мы могли бы сделать какой-нибудь красивый дашборд и похвастаться тем, что можем это визуализировать.

И тут у любого дата-сайентиста и machine learning инженера возникает большая проблема – что делать с данными? Вы мне данные дали, а модели данных нет. А данные вообще непонятные, непонятна их природа. Откуда в них столько выбросов?
Разведочный анализ данных занимает очень большую часть времени. Порой он занимает больше времени, чем само обучение моделей, а это очень плохо.
Грубо говоря, мы приходим к бизнесу, просим дать модель данных. Если у бизнеса ничего нет, и никто не понимает, как это делать, мы будем просто сидеть и исследовать.
А хотелось бы сразу начать получать какие-то результаты, но для этого нам нужно понимать, с какими данными мы работаем, и как минимум убирать оттуда непонятные вещи. Сейчас мы к этому вернемся.

Если опять вернуться к конвейеру machine learning, стоит обратить внимание на связь сырых данных со структурой DWH.
Чаще всего, любого человека, который работает непосредственно с базой данных 1С, не интересует, что там находится. Но когда вы дополнительно делаете DWH, где хранятся данные в нужном формате для пользователей или для определенного заказчика, вам нужно это все понимать.
Соответственно, как только у вас появляются сырые данные, аналитику нужно произвести препроцессинг. И если аналитик не уделил нужное время на препроцессинг, предварительную очистку данных и разведочный анализ, при использовании этих данных в дальнейшем для продакшена будет множество проблем. И боли, о которых я вначале говорил, чаще всего связаны с этим.

На этапе препроцессинга нужно обработать сырые данные – обратить внимание на дубли и пропуски.
Под дублями я имею в виду регистровые дубли, семантические или дубли по регулярному выражению:
-
Регистровые – это дубли, которые отличаются регистром букв. Где-то написано с большой буквы, а где-то – с маленькой.
-
Семантические – например, кто-то указывает г. Москва для кого-то это Московская область. Соответственно, в вашем справочнике и то, и другое должно быть определено под одним типом объекта.
-
По регулярному выражению. У вас после указания Москвы может быть точка или запятая или точка с запятой. И всё это на самом деле одна и та же Москва.
Пропуски. Есть два вида пропусков, но они опасны для любой аналитики.
-
Если у вас в системе встречается пропуск вида NaN, дальше ваши средние и медианные показатели будут работать очень-очень плохо, потому что NaN любой системой воспринимается, как будто это какое-то непонятное число. Числовой вид, но пустой. На средний показатель он повлияет, и ваш средний показатель будет жутко изменяться.
-
А None – это чаще всего либо ошибка разработчика, либо изначально неправильная постановка.

Применим эффект подорожника.
-
Чтобы убрать регистровые дубли, мы должны сразу договориться о том, что у нас будет однорегистровая запись. Это крайне желательно, либо у вас четко выделенный формат, который будет дальше обрабатывать данные по регулярному выражению.
-
Семантические дубли – тут, кроме справочников и их актуализации ничего не поможет.
-
По регулярному выражению – сразу, как у вас только появляется какая-нибудь веб-форма, либо вы данные откуда-то забираете, ваша программа должна первостепенно эти данные обработать и убрать оттуда лишние символы.
-
Пропуски. Кроме анализа тут ничего не поможет, но в случае None требуется еще и проверка кода. Чаще всего, это ошибка разработчика.
Плохие и лучшие практики

Хорошие и плохие практики.
Я делал большой обзорный доклад о том, сколько компания может потерять денег, если не будет обращать внимание на данные. И второй доклад – о том, как аналитику работать с данными.
Кто эти аналитики
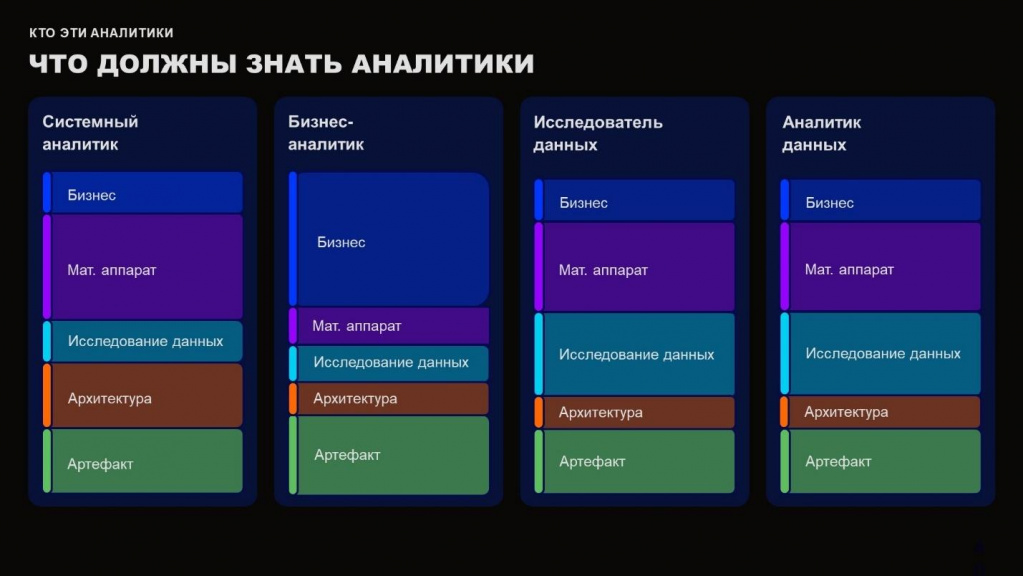
Напомню, что аналитики должны быть full-stack – все виды аналитиков ориентированы на работу с одними и теми же понятиями, но в разных пропорциях.
Соответственно, мы надеваем шляпу и подстраиваемся под каждую компанию.

Какие основные рекомендации могут быть:
-
Для любых данных требуется строить модель.
-
Если у вас более 6-10 моделей данных, описывайте их в едином реестре, иначе они просто теряются – положили их на локальный диск и забыли.
-
Данные должны быть всегда определены по типу, чтобы вы потом могли под них подстраивать те или иные паттерны работы.
-
Как только у вас становится больше одной информационной системы, между ними устраивается взаимодействие, пожалуйста, отрисовываем DataFlow.
-
Как только речь у вас заходит об интеграции между системами – готовьте интеграционные артефакты, модели данных, архитектуру, DataFlow.

Вроде бы все, да? А нет.

Представьте себе кейс: данные баз 1С из множества филиалов (10-20) складываются непонятно куда, а потом мы из этого делаем аналитику. Причем аналитика написана на каком-то древнем УПП. Как тут вообще начинать действовать? Что делать, чтобы выжить в это непонятном ландшафте?
Пошаговый план для аналитика

Я выделил несколько шагов, которые базово должны проводиться любым аналитиком при работе с данными.
-
Во-первых, аналитик должен провести исследование: изучить предметную область, провести предметный анализ – исследовать саму природы этих данных и предварительно сделать выводы.
-
После этого он начинает все это документировать. Сначала создает специальные артефакты, которые характерны для вашей компании или для вашего заказчика. После чего он делает основные артефакты. Они порой могут дублировать друг друга, но это необходимость. Конечно, излишняя документация – это плохо, но основная документация обязательно должна быть, иначе мы с вами сделаем непонятно что и забудем про это. Что мы будем делать, если у нас из команды пять человек уйдет? Как новый сотрудник вникнет, если у нас нет ни одного артефакта? Да никак.
-
Третьим шагом обычно идет разработка.
-
Потом мы начинаем проводить тестирование – конечно, это ни в коем случае не полный спектр, но там может и функциональное, и нагрузочное, и регрессионное, в зависимости от типа вашей разработки.
-
И далее у нас идет вывод – мы защищаем наше решение перед отделом информационной безопасности. Показываем, что у нас все хорошо, мы ни в коем случае не нарушаем ни один закон. Если мы работаем с европейскими странами или с другими рынками, то конечно же, мы должны подстраиваться под ISO стандарты или под что-то еще характерное для данного региона.

Где хранить архитектурные схемы и модели данных:
-
Обычно для этого создают небольшие базы.
-
Либо это хранится в SharePoint.
-
Либо создается несколько вкладок в Excel.
-
Либо, если у вас очень много моделей данных, их можно хранить в Access.
-
Мы, например, храним это все на Confluence. И нам этого хватает. А у нас сейчас порядка 150 графовых витрин.

Пора бы окончить речь мою.
Вопросы
Чем отличаются между собой документ архитектуры, интеграционная спецификация и DataFlow?
Когда мы описываем общую архитектуру, мы указываем, какие у нас есть системы, что они из себя представляют, в каком они окружении находятся. Находятся ли они в OpenShift или в Kubernetes и т.д. мы там не расписываем все детально, иначе это будет нечитаемо, и только под микроскопом мы что-то сможем найти.
Когда мы расписываем интеграционную спецификацию, мы детально показываем, какие информационные системы у нас как взаимодействуют друг с другом.
А когда мы расписываем DataFlow, мы показываем, как сами данные идут – детализируем до уровня данных. Указываем, какие типы данных мы используем в базах данных – будь то DWH или любое другое хранилище.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.