Меня зовут Владимир Ловцов. Представлю вам небольшой мастер-класс «Ликвидация безграмотности в работе с данными». Буду рад поделиться информацией по данной тематике.
Данные в компаниях

У меня было совместное исследование с коллегами из университета о том, как компании растут, расцветают, и когда они умирают. Причем заходить в данную проблематику я начал после того, как встретился с огромным валом проблем в так называемых мастер-данных – это важнейшие данные для отчетности.
В одной крупной FMCG-компании я столкнулся с тем, что данные там не ахти, но на каждом уровне отчетности это маскируется. И в конечном варианте отчетности от первозданных данных ничего не остается – мы видим совершенно другие вещи. Но руководители этого чаще всего не понимают.
Также я замечал, что если компания не обращает внимания на свою ИТ-стратегию на самых первых этапах развития, то, когда бизнес начинает приносить прибыль (у него появляются «звезды» с точки зрения маркетинга или как называемые «коровы», которые генерируют основную прибыль), в компании начинает появляться зоопарк программного обеспечения – всевозможнейшие базы данных, системы. Если это вовремя не остановить, в какой-то момент компания начинает просить о помощи: «Помогите нам с нашим ландшафтом, у нас шесть баз данных – Oracle, MS SQL, PostgreSQL». Вы спрашиваете: «А зачем вам так много? У вас работает тысяча человек, вам должно быть достаточно единого хранилища» – «Нет, у нас каждый департамент имеет свою базу данных, и мы сами ее строим». – «А у вас слоевая структура есть?» – «Нет, нету. Как смогли, так и построили».
Чем дольше компания затягивает с принятием концепции по работе с данными – тем тяжелее ей входить в это русло. На графике можно заметить, что прибыль начинает понемногу расти. Но одновременно с появлением зоопарка систем начинают стремительно расти затраты на внедрение управления данными. Если компания не задумается о данных вовремя – на этапах роста, расцвета, стабильности – то принятие политик по управлению данными в дальнейшем становится очень дорогим решением и чаще всего проваливается.
Да и вообще преобразование учета в компании – миграция или закупка аудита от крупного консалтинга из «большой четверки» – не приводит к успеху. Компания закупает какое-то решение по управлению данными и надеется, что придет «большая четверка», проведет им аудит, и у них все наладится. Но никто в компании этим заниматься не хочет.
Кто-нибудь из руководителей говорит: «Нам надо сделать политику по управлению данными. Я слышал про Data Mining, нам надо войти в это русло». Но никаких преобразований в компании не происходит. Сотрудники – аналитики, разработчики, администраторы, ИТ-лиды и средний менеджерский состав – не знают об этом и не умеют этим управлять. Все это становится просто сливом бюджета.
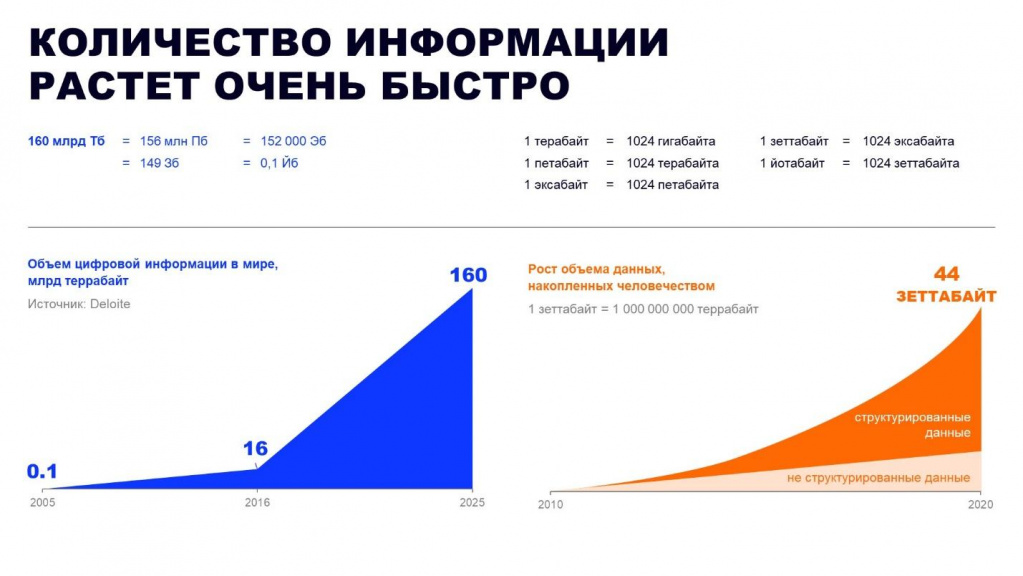
Наши данные постоянно растут – вы это, наверное, и так знаете. Они колоссальнейшие – я сталкивался с петабайтовыми хранилищами.
Работать с ними сейчас очень сложно, потому что растут именно неструктурированные данные – а именно звук, изображения, видеозаписи, всевозможнейшие логи нестандартных видов (JSON и тому подобные). С этим нужно уметь работать.
Многие компании не задумываются о том:
-
какие данные у них есть сейчас;
-
какие данные им важны для дальнейшего роста и развития;
-
что не все данные нужно хранить – например, некоторые данные могут стать потенциальным риском. Если данные вам не важны, лучше от них вовремя избавляться или как-то их аккуратно прятать, чтобы к ним никто лишний не залез.
Из-за этого образуются всевозможные сливы.
Компании нужно вовремя заботиться о том:
-
какие данные она хранит;
-
в каком виде она их хранит;
-
где именно она хранит;
-
какой уровень безопасности для этих данных требуется.
Если мы об этом вовремя не позаботимся, есть большой риск, что эти данные мы потеряем.
К тому же к нам всегда могут прийти аудиторы или представители контролирующих органов и запросить данные за какой-то период времени. А мы должны правильно их предоставить.
Что такое данные

Базовое понятие данных – это совокупность единиц и нулей. В зависимости от того, как эти единицы с нулями представлены, данные могут быть совсем разными. Главное, чтобы нам было удобно с ними работать и представлять их в нужном нам виде.

Как вы считаете, всегда ли данные приносят информацию? Имеют ли данные свой жизненный цикл? Умирают ли они когда-нибудь?
Очень важно понимать, что, когда мы начинаем работать с данными, это всегда просто какой-то массив непонятно чего. Для данных, которые имеют для нас смысл, может быть три классических типа:
-
мастер-данные – важные для бизнеса;
-
НСИ (нормативно-справочная информация) – то, что обычно не меняется;
-
и метаданные;
У данных может быть три агрегатных состояния:
-
Если у данных нет метаданных – описания, откуда они, и что из себя представляют – они сразу же становятся мертвыми.
-
Чтобы получить из данных информацию, ее нужно извлечь. Но для этого нам нужно понимать, зачем мы эти данные храним, для какой цели. Если мы можем извлечь из данных информацию и понимаем, что через год мы эту информацию тоже еще сможем извлечь, то данные у нас полезные. Это важно.
-
Если дальше мы можем уложить эту информацию в какую-то отчетность или в описание каких-то докладов для руководства, мы должны эту информацию преобразовать в знания.
Итого: из данных мы извлекаем информацию, и, систематизируя эту информацию, мы получаем знания. Если руководитель прочитал ваш отчет и понял, что вы хотели ему донести, то весь путь данных прошел корректно – все агрегатные состояния по данным пройдены.
Какие данные нужны

Поговорим о жизненном цикле данных.
Данные всегда имеют дату годности. Грубо говоря, данные о продажах детского пюре за 1993 год сейчас уже далеко неважны – даже для компаний из сектора FMCG, хотя по идее они на этом работают. Сейчас уже совершенно другие стратегии, по-другому измеряются метрики продаж, поэтому эти данные нам будут уже бесполезными – они могут быть полезны только в случае, если кто-нибудь захочет сделать сводку за последние сто лет. Но для бизнеса это чаще всего неважно. Бизнес должен понимать, зачем ему тот или иной отчет, зачем ему те или иные данные. Если данные у нас хранятся просто так, чтобы когда-нибудь сделать красивую, но бесполезную отчетность – оно никому не надо, на это не нужно тратить деньги.
Нужно сразу же определять, какой период времени данные должны храниться в компании. Обычно мы храним данные 5-10-15 лет – в зависимости от того, какой у них уровень критичности и для кого они нужны.
Если ваш бизнес может периодически сдавать по этим данным отчетность в какие-то органы, там может и до 15 лет доходить. Но обычно срок хранения данных – 5 лет.
Данные в бизнесе разделяются на три основных вида:
-
непосредственно мастер-данные;
-
метаданные
-
и НСИ.
Для данных в ИТ появляется дополнительное разделение данных:
-
структурированные;
-
полуструктурированные;
-
и неструктурированные.
Подписи БА, АД и СА на слайде – это те роли, которые обычно взаимодействуют с этими данными:
-
БА – это бизнес-аналитик,
-
АД – аналитик данных,
-
СА – системный аналитик.
Чаще всего непосредственно с данными работают именно аналитики – они предоставляют необходимую для руководства отчетность, причем уже в предобработанном виде. Поэтому именно аналитику важно уметь работать с данными и правильно их предоставлять.
Но руководителю важно понимать, как данные преобразуются и какой их путь. Чтобы он понимал, что данные, пройдя путь преобразования, не изменились колоссально и не изменили свою природу.
Данные в бизнесе – здесь под видами данных подразумеваются:
-
Мастер-данные – это основные данные, которые идут от продаж и важны для бизнеса, там все основные показатели.
-
Метаданные – это данные, которые описывают все остальные данные.
-
НСИ – нормативная справочная информация. Это информация, которая обычно не меняется и на которую во всех компаниях чаще всего забивают – никто не хочет работать со справочниками.
Например, если у нас есть несколько филиалов, каждый из которых работает с одним и тем же списком контрагентов, при попытке синхронизировать все продажи по филиалам, мы можем обнаружить, что информация по контрагентам нигде не сходится, потому что каким-то странным образом в каждом филиале все ведется по-своему. А потом мы еще захотим отправлять эту отчетность инвесторам.
Все руководители думают, что у нас все хорошо, мы закупили всевозможнейшие решения, у нас вся компания работает на 1С. Но никто не задумывается о том, что надо управлять данными – применять MDM-решения. У нас же есть аналитик – он поколупается, что-нибудь найдет, сопоставит. Что сложного-то?
Тут чаще всего возникает очень много проблем, которые потом уходят в очень большие круглые суммы – далеко не шесть знаков.
Данные в ИТ. Когда мы говорим про ИТ-шные данные – это то, с чем непосредственно работают разработчики, системные аналитики. Сюда относятся:
-
Структурированные данные – хорошо, что они имеют хотя бы какую-то структуру.
-
Полуструктурированные данные – данные, имеющие минимальную разметку. Например, это какие-то JSON, XML – данные, в которых есть хотя бы элементарная разметка.
-
Неструктурированные – это изображения, звук. Мы уже порой не понимаем, как правильно работать с этими данными – для них нужно применять специальные алгоритмы и методы.
Если у вас в компании мертвым пластом лежит куча неструктурированной информации, чаще всего компания и через 5 лет также к ним не притронется, но вы будете тратить очень большие суммы денег на то, чтобы это содержать. Поэтому всегда смотрите, зачем вы всю эту информацию храните, для чего она вам нужна.
Если вы не хотите стать Яндексом или провайдером по данным, за деньги предоставлять данные за 10 лет – не надо хранить. Не нужно иметь колоссальный объем ресурсов во всевозможнейших облаках, ЦОДах – чаще всего это бесполезно. А я с этим встречался.
Решение о том, что данные должны иметь такой-то жизненный цикл, принимается на уровне топ-менеджмента. В соответствии с этим должны появиться какая-то стратегия и политика управления – это обязательно. Если вы принимаете решение отказаться от хранения данных на уровне команды, то это нужно много-много эскалировать – доказать, что вам бессмысленно это хранить.
У меня был проект, где я должен был исправить проблему с данными в холдинге. Там как раз были проблемы с данными на нижнем уровне. На верхнем уровне понимали, что от этих проблем нужно избавиться, но не знали, как это сделать. Они думали, что достаточно будет сказать об этом руководителям департаментов, они установят для данных какой-то жизненный цикл и объяснят сотрудникам политику управления данными. Но никто этим занимался вообще. Глобально все отчитывались: «У нас все хорошо», но при полном аудите всего холдинга было понятно, что никто этим не управляет.
Если вам придется реализовать такой же проект, покажите руководству, сколько денег уходит на хранение этих данных и работу с ними, какие в этом еще есть потенциальные финансовые риски. Я показывал в денежном эквиваленте – сколько вы сейчас тратите, а сколько вы будете тратить чуть позже. От скольких дополнительных людей, которых мы нанимаем на аутсорс в определенный период времени для сдачи налоговой отчетности, мы можем избавиться, от каких систем мы можем избавиться, от каких проблем мы избавляемся, и какие потенциальные риски мы отключаем.
Паттерны работы с данными
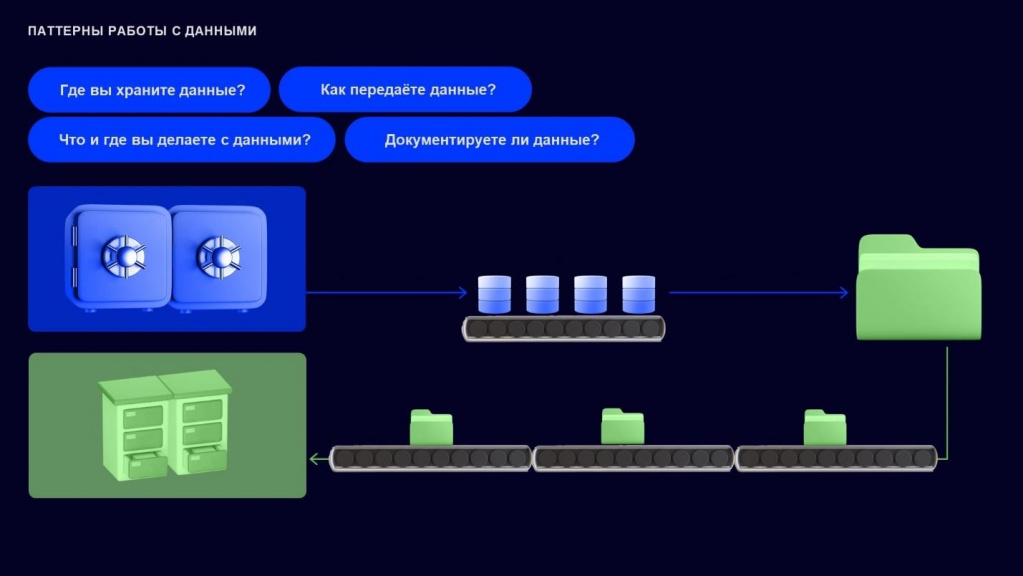
Паттерны работы с данными подразумевают решение четырех главных вопросов:
-
как мы с данными работаем;
-
как мы их храним;
-
как мы передаем;
-
как мы их документируем
Расскажу, какие чаще всего проблемы существуют, на каких этапах.

Когда мы говорим, что мы где-то храним данные, чаще всего это:
-
либо какая-нибудь база данных;
-
либо накопитель;
-
либо локальный каталог;
-
либо облачное хранилище.
Чтобы мы могли работать с любым из этих ресурсов, нам всегда нужна модель данных, которая описывает: какие есть атрибуты, что они собой представляют, для чего нужны.
Особенно модель данных нужна, когда мы производим какую-нибудь миграцию и описываем, как эти данные должны трансформироваться из системы в систему. Имея модель, мы всегда можем восстановить путь данных, не нанимая людей, которые будут исследовать наш ландшафт и пытаться этот путь восстановить, чтобы поработать с этими данными.
Если у нас нет описи данных, модели данных – каких-то метаданных, которые описывают наши текущие данные – то эти данные мертвые. Очень часто так бывает. Либо нам приходится платить деньги каким-то аналитикам данных, чтобы они разобрались с этими данными. А еще в компаниях любят говорить: «Нам дата-сайентист поможет – скажет, что нам с этим делать». Никогда. Вы потратите сотни тысяч рублей или даже долларов на то, чтобы нанять кого-то, чтобы он вам за короткий период времени поправил данные. Чаще всего это просто слив бюджета.
Чтобы правильно работать с данными, нужно начинать их описывать.

Как мы передаем данные из системы в систему:
-
Для 1С характерен файловый обмен в том или ином виде – многие любят передавать между системами XML или JSON.
-
Реже обмен происходит через брокеры. Если сообщений достаточно много, и нам нужно применять шины данных, мы заходим в Kafka, Artemis, в RabbitMQ. Или какие-то данные нам нужны здесь и сейчас в режиме реального времени, мы применяем Apache Flink.
-
А когда данных немного – применяем API-сервисы.
На что нам следует всегда обращать внимание? Любые передачи данных должны оформляться моделью данных. А для более сложных обменов дополнительно нужны DataFlow, архитектура и интеграционная спецификация.
-
DataFlow – это схема наших потоков. Она описывает, как наши данные из системы в систему идут, что они собой представляют на каждом этапе.
-
А в интеграционной спецификации мы расписываем: в какой топик мы пишем, какие у нас могут быть сертификаты, как мы это все подключаем – через токен или по-другому. Это все должно быть четко прописано в интеграционной спецификации.
Если всего этого нет, и вы сдаете проект по передаче данных из одной системы в другую – ерунда получится. Тот, кто у вас заказал, будет потом на вас долго плеваться и всем говорить, какой у него отвратительный был поставщик услуги.
Я сталкивался с ситуацией, когда бизнес заказал проект обмена у одного из вендоров, и тот предоставил вроде бы готовое решение, но это полнейшее легаси – черный-черный ящик, где не описано вообще ничего. Ни одна передача не описана. Нет ни модели данных, ни DataFlow. Чтобы как-то работать с этим черным ящиком, приходилось полностью разбирать все это легаси и постоянно пилить там микросервисы, чтобы хотя бы частично перевести на современную архитектуру. Потратили много денег, чтобы просто с этим начать работать.

Дальше – о том, как мы работаем с данными, и какие здесь появляются роли.
-
Классически с данными работают: архитектор, аналитик и кто-нибудь из ИБ – если у вас они есть в компании.
-
Работая с данными, мы их создаем, удаляем, обновляем, изменяем.
-
Что касается систем, в которых мы работаем с данными – они могут быть разными. В 1С чаще всего нужно работать с данными напрямую – мы загружаем данные в базу, и там уже работаем непосредственно. В Oracle, Hadoop, ArangoDB, Access, Excel – инструменты по работе с данными есть, можно применять любые алгоритмы и методы.
Важно, что если у вас в компании данных реально много, и вам хотелось бы, чтобы они начали вам приносить прибыль, вам нужно создавать дополнительные роли:
-
Владелец данных – это тот, кто эти данные хранит, создает и за них отвечает. Чаще всего, владелец данных – это руководитель бизнеса или департамента.
-
Распорядитель данных – тот, кто может этими данными распоряжаться, понимает, какая у них природа, специфика, для чего они предназначены, какой у них жизненный цикл, можно ли их применять для тех или иных кейсов (например, можно ли эти данные использовать в том или ином отчете). Если ваша система генерирует множество данных, распорядителей у нее может быть много – они принимают частные решения, помогают аналитикам и разработчикам, а также дополнительно согласуют любое решение с владельцем данных.
-
И еще для данных всегда нужен архитектор. Причем это чаще всего не Solution-архитектор или архитектор системы, это прямо архитектор данных, который должен понимать, что данные собой представляют, как эти данные трансформируются, откуда и куда они идут, чтобы была хоть какая-нибудь стратегия по работе с данными. Если для работы с данными нет стратегии и про архитектора данных мы забываем, у нас получается какая-то мешанина. В каждом отделе, в каждом департаменте, принимают свои собственные решения. И получается какая-то грязь, которую потом будет сложно разгрести. Чаще всего не разгребают, и она остается в том виде, в котором есть, и приносит нам потом только колоссальнейшие убытки.
Когда у нас появляются роли владелец и распорядитель данных (или так называемый дата-стюард), у нас появляется офис по работе с данными. Нужно это применять или не нужно, зависит от того, насколько большая у вас компания. Если у вас в компании тысяча человек или более, желательно, чтобы появилось несколько таких ролей. Желательно, чтобы это были конкретные позиции, которые full-time с этим работают.
Когда-то для одной из компаний я проверял, сколько времени на исправление данных тратят разные виды аналитиков: системный аналитик, аналитик данных и бизнес-аналитик. Можно ли превратить это время в деньги, и сколько денег у нас уходит, если он занимается не отчетностью (своей основной обязанностью), а корректировкой данных. Убытки получились колоссальные.
Если у вас 100 аналитиков, и каждый из них регулярно исправляет данные, лучше взять на эту задачу три отдельные позиции: владелец данных (CDO), распорядитель данных (Data Steward) и архитектор данных. Они будут управлять данными, доносить до руководства стратегию по работе с данными и постоянно держать все уровни вертикали и горизонтали в курсе дел.
Модель данных

Мы наконец дошли до так называемой модели данных.
Нам всегда важно понимать:
-
какие у нас есть атрибуты;
-
как они переходят из системы в систему;
-
какие данные у нас есть в начале (AS IS);
-
какие у нас данные будут в конце (TO BE);
-
как эти данные трансформируются;
-
и что эти данные собой представляют.
Для работы с данными нужен какой-то инструмент. В большинстве случаев аналитики строят отчеты в Excel – данные туда выгружаются, и аналитики там что-то правят, но при этом ни в одной из исходных систем никакая актуализация справочников не производится.
Чтобы полноценно работать с данными, нужна какая-то система – чаще всего, это база данных, куда сливаются данные из других систем. Но если мы не понимаем, как устроено хранилище 1С, мы сливаем все данные в нужную нам базу и дальше уже начинаем с этим работать. Например, у меня для этого была отдельная база на PostgreSQL, куда разработчики настроили для меня выгрузку, и я там уже дальше анализировал.
Если у нас есть модель данных, по которой производится миграция из одной системы в другую, мы можем ей воспользоваться:
-
Мы понимаем, из какой системы в какую целевую систему мы это все сливаем – нам известна схема-источник в целевая схема.
-
Мы понимаем, как эти данные трансформируются.
-
И у нас есть примеры данных.
Через несколько месяцев работы вы или кто-нибудь другой будете разбираться с вашим кодом, и сможете спокойно вспомнить – что разрабатывали, и как это делали.
Если потом ваша компания будет нанимать каких-нибудь ML-инженеров или захочет перейти на что-то новенькое – например, внедрить AI-технологии – важно, чтобы ваши данные были качественными:
-
чтобы все ИНН были проставлены;
-
если это продажи, чтобы не было пропусков;
-
чтобы данные были адекватными в самом базовом понимании.
DataFlow
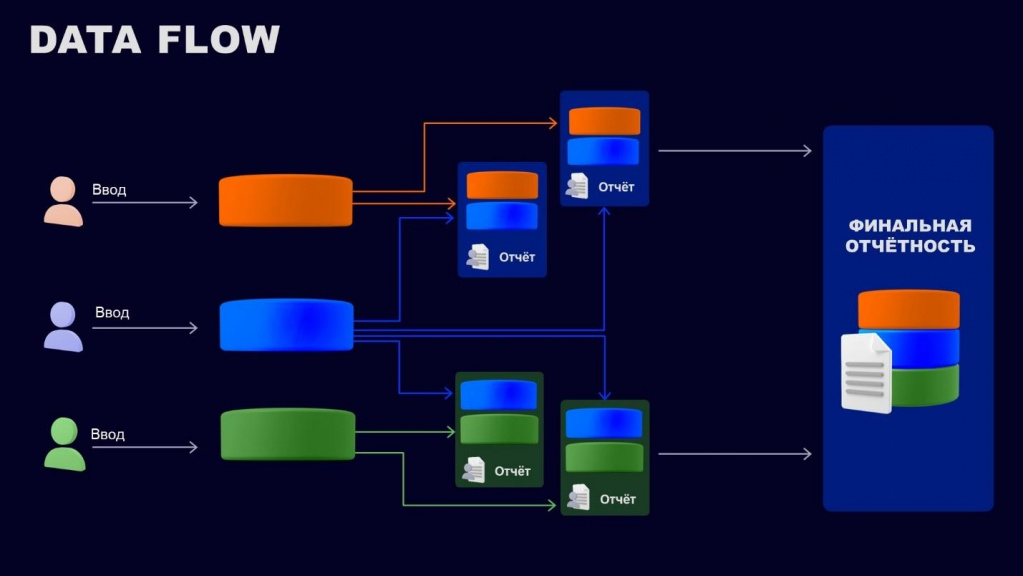
Расскажу, что такое DataFlow.
Предположим, что наши данные мигрируют из системы в систему.
В каждой системе могут быть:
-
точки входа, где данные создаются либо изменяются;
-
дополнительные точки преобразования, где данные агрегируются с другими источниками, или, возможно, там появляются новые пользователи, которые данные добавляют или изменяют.
Потом наши данные каким-то образом сходятся в единую систему. Или расходятся – в зависимости от того, какая архитектура была принята у вас в компании.
Важно, что в финальной отчетности мы начинаем пытаться сопоставить данные из разных систем. Но, если на каждой ступени агрегации данных появляются дополнительные точки входа, в 99% случаев мы эти данные не сопоставим. Чтобы сопоставить эти данные, нам потребуется очень много ресурсов и денег.

На что тут надо обращать внимание?
-
Не должно быть много точек входа – если у вас в каждом филиале менеджеры заводят своих клиентов, а потом эти клиенты мигрируют в общую аналитическую систему – важно, чтобы на промежуточных этапах точек входа не было.
-
Каждый поток данных должен соответствовать определенной бизнес-задаче. Айтишники не должны создавать потоки, как они видят – только потому, что им это кажется правильным. Надо понимать, что у бизнеса для каждого потока есть какое-то назначение. Если вы создаете форму, данные с которой потом передаются в общую аналитическую базу, она должна быть реально продиктована потребностью бизнеса.
-
Промежуточных узлов между начальной и конечной точкой не должно быть много. Если их много, стараемся их сделать максимально правильно – на них не должно быть дополнительных точек входа. Должны быть только точка входа в начале и точка входа в конце. Если у вас запутанная система, отчетность на каждом промежуточном звене никогда не будет соответствовать конечной системе. Например, каждый филиал может вести тех же юрлиц совершенно по-своему – у них есть свои уникальные реквизиты, которые потом не будут сводиться в итоговой системе.
-
И, конечно, архитектура системы должна быть выстроена по какому-то принципу. Она может быть централизованной – если у вас есть система, куда все сходится. Или она может быть децентрализованной, и тогда каждый отчет в разных системах у вас будет строиться совершенно по-разному. Либо система может быть построена по какому-то гибридному принципу, который характерен для вашей компании. Чаще всего все говорят, что у нас гибридная система, и не задумываются, что она собой представляет. Просто там архитектор не посидел никогда, и все придумывают, что она гибридная.
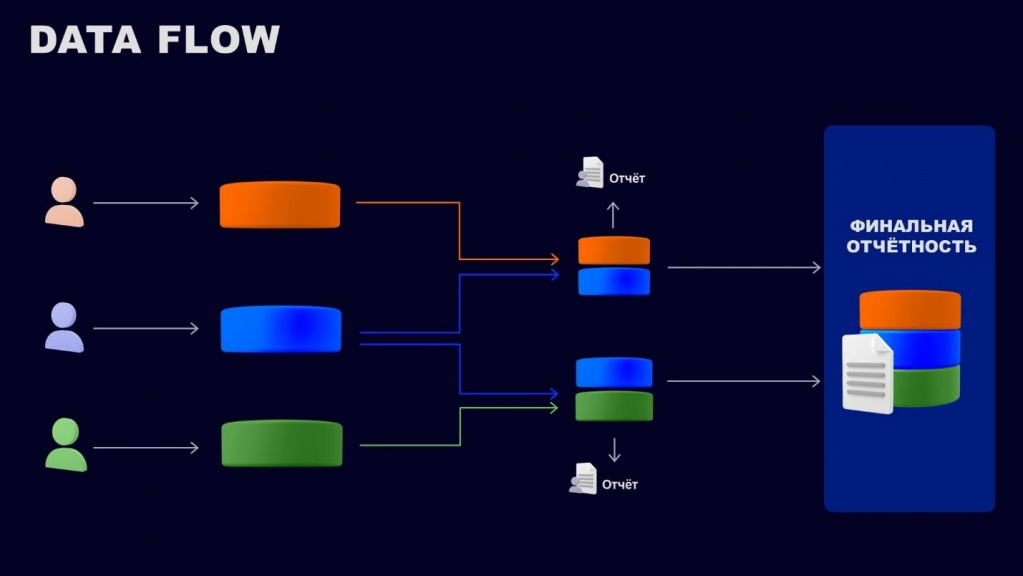
Здесь на слайде - исправленная схема DataFlow.
-
Здесь есть несколько точек входа.
-
Есть промежуточные точки для агрегации и преобразования, где несколько систем сливаются, и там появляются промежуточные отчеты.
-
И есть итоговая система, куда все данные сливаются, и из которой мы можем выгрузить финальный отчет.
Тут является хорошим знаком то, что на агрегационных и промежуточных этапах преобразования данных нет точек входа. Это значит, что наши данные не изменятся в обход автоматических правил. И отчеты, которые мы выгрузим на каждом этапе, можно будет сопоставить с финальной отчетностью – в отличие от первоначальной истории, когда у нас было много запутанных узлов.
Зона внимания

На что следует обращать внимание, когда мы работаем вообще с данными:
-
У нас должен быть регламент на наименование таблиц – например, мы называем таблицы латинскими буквами только через нижний регистр и через нижнее подчеркивание. Приняли правило, и по всей компании стараемся применять один и тот же алгоритм.
-
Отдельный регламент для наименований баз данных – например, базы данных вы называете уже в верхнем регистре.
-
Далее на каждое преобразование, на каждую таблицу, на каждый справочник, который вы разрабатываете, вы всегда пишете модель данных – чтобы все всегда понимали, что этот объект собой представляет.
-
Любое изменение вы должны версионировать, чтобы потом можно было с легкостью сопоставить – что там изменилось. А то разработчик вам что-то заоптимизировал, а в результате оказалось, что все обвалилось, и часть шагов пропала, например. Как вернуть все назад? Разработчики бэкапа не делали, вернуть уже не получится. А еще бывает такое, что каким-нибудь отчетом пользуются раз в год или раз в два года. Ты что-нибудь изменишь, и через два года к тебе приходят и говорят: «Нам надо, чтобы вы все это восстановили». А восстановить уже невозможно.
-
Спецификация интеграции – любая интеграция должна быть описана, в спецификации должно быть прописано, что это за интеграция, что она собой представляет, какие в ней поля за что отвечает, и почему именно эта интеграция.
-
Качество данных – вы должны принимать решение, можете ли вы эти данные использовать. Это больше касается аналитиков, которые будут обрабатывать данные, чтобы не было дубликатов и пропусков.
-
И определение видов данных – то, с чем вы работаете. Если вы работаете с НСИ, вы понимаете, что эта информация не меняется, и вам достаточно с этим работать раз в какой-то короткий промежуток времени. Если это будут мастер-данные, тут вам надо будет принимать ad-hoc и быстро взаимодействовать с этим.
Работа с данными и структура DWH
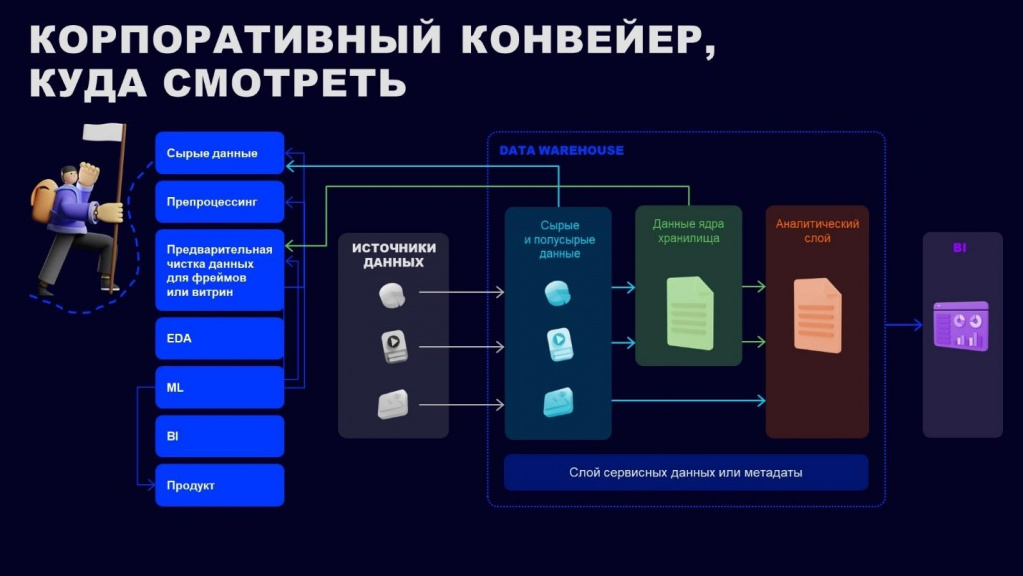
Немного расскажу о том, как сейчас строят конвейеры по данным. Я не утверждаю, что это прямо must have, но тут есть некоторые структуры, которые важно учесть.
Почему важно обращать внимание на данные, когда вы строите какой-то отчет или делаете какие-то преобразования у вас в системах? Потому что потом, когда компания захочет перестроиться, данным потребуется:
-
чистка для фреймов или витрин
-
препроцессинг,
-
всевозможные виды анализов, которые характерны для машинного обучения.
Если вы хотите настроить свою систему так, чтобы отчетность в ней формировалась автоматически, данные должны быть хорошо предобработаны. Плюс у вас должны быть для них реализованы DataFlow и модель данных, чтобы понимать, в каком виде вы представляете данные.
В какой-то момент у нас компания начинает трансформироваться, и начинают внедряться какие-нибудь хранилища DWH. При этом нас не устраивает ни одно из текущих рыночных решений (например, они либо дорогие, либо не подходят для нас), мы решаем, что у нас достаточно экспертизы по разработке, и начинаем делать свое собственное хранилище.
Хранилище DWH чаще всего устроено следующим образом.
-
У нас есть какие-то сырые данные – те данные, которые мы в исходном виде закачали к себе в базу.
-
На втором этапе мы преобразуем сырые данные в данные ядра хранилища, чтобы они имели реляционную форму – добавляем ключ для связи ключ-значение и атрибутный состав.
-
И на этапе третьего преобразования – так называемого аналитического слоя – эти данные уже готовы для бизнеса. Вы можете отдать их руководителю и не краснеть уже за них.
Чтобы все это правильно выстроить, нужно всегда обращать внимание на качество данных – у вас данные должны быть предварительно очищены. Не должно быть кучи дублей, и не должны появляться значения NaN и None, как бывает в некоторых выгрузках. Пропуски NaN и None воспринимаются системой как числовые значения и могут влиять на то, что ваша отчетность будет некорректной.
Хочу еще сказать про BI. Для работы с BI важно иметь в DWH аналитический слой, где хранятся уже трансформированные данные в нужном нам виде. Если вместо этого мы сразу тянем данные в BI из разных систем без нужной нам трансформации и предварительной проверки данных, у нас может возникнуть следующая ситуация. Например, мы сделали дашборд, он некоторый период времени работает, а потом может «поехать», потому что у нас нет дополнительного слоя.
Объясняю. В источник пришли какие-то непонятные данные от поставщика и наши данные все полетели – дашборд сразу упал. Такое может быть.
Когда я работал с сервисом, которому нужны были данные практически в реальном времени, там требовалось обязательное применение нескольких слоев – это позволяло исключить ситуацию некорректной работы дашборда в ненужный период времени. Представьте, заходит там руководитель бизнеса или руководитель продаж – смотрит, а у него дашборды все полетели. Чтобы такого не было, требуется применять дополнительную слоевую архитектуру, и только на это настраивать BI-решение.
Любое BI-решение, которое мы делаем, нужно для бизнеса – бизнес там видит красоту, которая ему требуется.
А сервисная поддержка (то, что находится на части ИТ) мониторит состояние данных, поступающее в BI – полетел ли ELT-процесс, обрушилась ли какая-то миграция и т.д. И применяет решения, чтобы эту ситуацию исключить. Потому что, если бизнес видит, что в отчетах полетела хотя бы одна метрика или кружочек у него неправильно отображается – там такая тревога, такой уровень эскалации начинается, что потом все ИТ трясет еще несколько дней.
К каждой системе применяется свой уровень критичности. Если у нас разные процессы имеют разные уровни критичности, на основе конкретного слоя метаданных, настраивается дополнительная система мониторинга. И если какой-то из индикаторов обвалился или сигнализирует, что обвалилась миграция и сообщения из Kafka больше не читаются, вы бегом заводите инцидент, на это моментально реагирует служба поддержки, все это исправляет, и бизнес даже не успеет этого прочувствовать.
Это важно, если вы представляете отчетность для ЦБ или каких-то дополнительных регулирующих органов, в вашей системе обязательно должен быть сервисный слой. В ИТ-системах она обязательно должна существовать – без этого не пройдет.
Тут именно про грамотное построение вообще архитектуры. Если архитектура построена грамотно, такой проблемы не будет.
Дубли и пропуски

В интегрируемых системах могут быть дубли из-за того, что существующие справочники каждым человеком обновлялись совершенно по-разному: кто-то написал Москва с большой буквы, где-то – с маленькой буквы, а кто-то вообще под Москвой подразумевал Московскую область. Получается несколько вариантов развития событий.
Возникает вопрос: по какому признаку группировать эти данные при формировании отчетности?
Чтобы дублей не было, надо сразу же применять правила работы с НСИ и управление справочниками – без разницы, какая у вас система, в ней всегда должно быть управление справочниками.
Дубли бывают трех видов
-
Регистровые дубли. Если вы уже применяете стратегию и пишете все в нижнем регистре – пишите все в нижнем регистре.
-
Семантические. Если речь о дублях в классических справочниках тех же самых городов или улиц, используйте общероссийские справочники, я там ни разу не замечал проблем.
-
Дубли по регулярному выражению. Если у вас есть справочник, который заполняют разные аналитики или вообще обычные пользователи, потом от этого справочника пляшет вся ваша отчетность. Например, кто-нибудь ввел Москва с пробелом, Москва со звездочкой или вообще с каким-нибудь непонятным символом, и все у вас полетело.
Дубли – это самая частая боль, с которой мы встречаемся, но которую почему-то очень сложно исправлять в компаниях.
Далее – по поводу пропусков. Пропуски бывают двух видов – NaN или None.
-
NaN – это пропуск числового типа, который связан с тем, что в системе что-то не просчиталось. Скорее всего, какая-то выгрузка была некорректной – аналитику с разработчиком нужно это посмотреть и проанализировать.
-
None – тут сложнее. Это, чаще всего, проблема чисто разработческая, миграционная – где-то трансформация прошла неправильно. Непонятно, к какому типу данных этот пропуск отнести – это может быть число, дата, что угодно.

Как исправить эти проблемы:
-
Чтобы избавиться от дублей разных регистров, вводим однорегистровую запись либо подключаемся к классификаторам – бывают российские и международные классификаторы.
-
Актуализируем справочники либо запрещаем множество точек входа в справочники – за справочник всегда должен кто-то отвечать.
-
И чистим данные на входе – любая форма, которая будет транслировать информацию в справочник, должна иметь предварительную чистку. Если у вас справочник адресов, можно проверять по регулярному выражению либо сверять с сервисом DaData, что данные улицы, города и дома попадают в систему только в нормализованном типе, а в ненормализованном вы запрещаете.
И рекомендации по пропускам я уже сказал.
Заключительные рекомендации

Несколько советов напоследок:
-
Для любых данных составляйте модели.
-
Если моделей данных больше десяти штук, ведите по ним какой-то небольшой реестр, чтобы потом у вас ничего не обвалилось. Для реестра можно использовать SharePoint, Excel, Access – каждый из этих вариантов жизнеспособен.
-
Как только у вас становится много информационных систем, нужно рисовать DataFlow, чтобы не забывать, с чем вы работаете.
-
Внедряйте политику управления данными.
-
И для всех интеграций обязательно составляйте спецификацию и архитектуру
Вопросы
Вы рассказывали, что попросили разработчиков обеспечить вас сервисами, которые скачивают мастер-данные в некую вашу базу. Что из себя представляет ваша база данных? Она уже как-то логически структурирована? В ней есть какие-то свои метаданные? Или вы просто получаете копию исходной базы данных и уже в своей копии как-то причёсываете данные? Кто проектировал эту базу данных?
Я сам её проектировал чисто под себя – я у этой базы был единственным пользователем. Это PostgreSQL, я её поставил на локальной машине.
Мне настроили выгрузку данных в XML из разных систем – мне туда падали контрагенты, номенклатура, единицы измерения. И еще я туда забирал немного данных по продажам. Но в основном там было всё, что связано с НСИ.
Через парсер это все загружалось ко мне. Чтобы все это уложить, производилась небольшая трансформация данных – самописный ETL через Python.
После чего я делал всевозможные отчёты по состоянию данных.
У нас порядка 20 систем, в каждой из которых НСИ при начале эксплуатации заводили, кто как подумал. А сейчас они хотят получить из этого какой-то аналитический слой для руководства. В результате при каждой интеграции мы делаем сопоставление вручную – это очень трудозатратно и тяжело поддерживать. Потоки данных у нас некрупные, но слишком разноплановые. Из-за необходимости сопоставления данных у нас поток уходит чуть ли не кольцом – сначала в одну систему, потом во вторую и в третью. При этом в одной из систем эти данные могут еще и поменять. Как развязывать этот клубок?
Я это делал следующим образом:
-
Посмотрел, какие есть системы, и за что отвечает каждая система.
-
Расписал базовый поток DataFlow и сопоставил его с бизнес-процессами, которые к этому завязаны. Все клубки, которые есть, по максимуму расписал и рассмотрел, какие бизнес-процессы тут существуют.
-
Потом рассмотрел, что уже давным-давно умерло – есть ли в процессе дополнительные связи и передачи информации, которые уже стали неактуальными. Проходил по всем и смотрел – актуально или неактуально, интеграция еще жива или не жива, нужна ли она кому-нибудь или не нужна.
-
Сделал общую исходную архитектуру и пошел с ней к руководству со словами: «У нас есть столько-то потоков данных. Если мы те или иные интеграции не используем, отрубаем их? Зачем нам эти непонятные связи? Если эти связи нам нужны, они реально используются, мы их оставляем. Если мы можем перестроить какие-то потоки на адекватный целевой вид – чтобы это было не закольцованно по несколько раз – мы эти процессы выстраиваем правильно, чтобы у нас было меньше проблем».
-
Исходя из этого, я предложил целевую архитектуру и попросил, чтобы мне помогли надавить на бизнес, чтобы они отказались от тех или иных решений. В результате мы смогли провести небольшую трансформацию – убрали лишние потоки данных и избавились от каких-то ненужных данных – они перестали заводиться.
-
Потом мы закрутили гайки на формах – прицепили всевозможные регулярные выражения, сверку по актуальным кодам НСИ, чтобы все было адекватно.
-
После чего посмотрели, на каких промежуточных узлах у нас происходит еще какая-то трансформация. Посмотрели, нужна ли нам трансформация на этих узлах либо там достаточно просто выгрузить. Если трансформация не нужна, мы ее переставили на начало пути либо на конец потока. Так мы очистили практически все промежуточные пути.
Получается, что я обошелся без глобальной замены всей архитектуры. Мы ее правили, но глобально не меняли, потому что у бизнеса было четкое понимание, что он хочет работать только на 1С решениях.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART Анализ & Управление в ИТ-проектах.

