Исходные данные
Вкратце о EDI: это передача документов между организациями в виде структурированных файлов. Подробнее написано здесь. Активнее всего в России EDI используется при взаимодействии проводольственных сетей (Магнит, Ашан, ...) и их поставщиков. Они обмениваются заказами, подтверждениями, счетами и прочими рабочими сообщениями для поставки товаров. Вот этим всем мы и занимаемся.
Наша команда разрабатывает модуль интеграции EDI для 1С. По ссылке доступна демо-база со встроенным модулем. Также есть короткое видео о том, как оно все работает. За термином “модуль интеграции” скрывается обычная внешняя обработка.
Изначально обработка должна была выполнять 4 действия:
-
По существующим в системе документам формировать сообщения (файлы определенного формата).
-
Отправлять эти сообщения по каким-то каналам связи.
-
Получать по этим же каналам новые сообщения.
-
Из принятых сообщений создавать новые документы в 1С.
Эти требования были реализованы силами одного человека, команда не требовалась. Затем модуль был представлен клиентам в виде бета-версии, и тут произошло первое столкновение с российскими особенностями EDI.
Проблемы предметной области
Почти в каждом IT-проекте встречаются совершенно очевидные предположения, которые разбиваются о суровую реальность. Мне очень нравится пример с именами.
Чем же нас порадовал российский EDI?
-
Покупатель может прислать заказ, а потом отменить его следующим сообщением.
-
Поставщик в это время может уже успеть отправить машину с товаром.
-
Покупатель может прислать один и тот же заказ 30 раз. Абсолютно одинаковый.
-
Покупатель может прислать заказ с одним и тем же номером несколько раз с разными данными. В первом заказе 200 куриных тушек, во втором - 150. Сколько куриц убивать в итоге? А если 200 уже полегло, и тут прилетает заказ на 150?
-
Уведомления о приемке товара очень часто НЕ СОДЕРЖАТ идентификатор отгрузки. Т.е. покупатель сообщает, что не досчитался 5 бутылок доброго виски при приемке машины, но не говорит, по какой накладной.
-
Один покупатель может заказать 60 коробок вина по 20 бутылок в каждой. Другой может заказать 60 бутылок по 20 в коробке. При этом сообщения могут выглядеть одинаково. А у поставщика вообще учет в литрах. Хорошо, это не курицы, но сколько же вина привезти?
-
Покупатель может прислать заказ на товар, который у поставщика хранится на разных складах (например, замороженная курица и охлажденная). Поставщик в этом случае иногда физически не может закинуть весь товар в один документ.
-
Сообщений может быть ОЧЕНЬ много. По 300 заказов в день одному поставщику от одной сети - не редкость. Обрабатывать их поштучно при таком объеме уже нереально. А теперь давайте добавим сюда предыдущий пункт с делением заказов.
-
Если поставщик забыл что-то указать в сообщении, его машину с товаром могут развернуть обратно прямо возле магазина. Список требований к сообщениям меняется чуть ли не каждый день.
-
У покупателей постоянно меняются точки доставки и юр.лица. Например, торговая сеть X5 открывает/закрывает магазины несколько раз в неделю. Поставщик должен обладать актуальной информацией о том, куда везти товар. А модуль должен как-то предоставлять эти данные.
-
Заполнить товары документа по сообщению очень просто? Получаем в сообщении код товара, находим по нему номенклатуру и закидываем в документ? Не торопитесь. Один и тот же товар покупателя (“Булочки в ассортименте”) может быть заведен у поставщика разными позициями (“Булочки с маком”, “Булочки с повидлом” и т.д.). Или наоборот.
И далее в том же духе.
Проблемы кода
Изначально весь код обработки был хорошо структурирован, а проблем командной разработки не существовало по причине отсутствия команды. Но в ходе развития каждая из описанных выше ситуаций требовала решения, причем, как обычно для разработки на 1С, срочного. Постепенно набрали команду (в том числе меня).
За плечами у нас были франчи, ИТ-отделы компаний разных масштабов, фриланс. Каждый работал в одиночку, как это обычно и бывает с 1С-никами.
И понеслось.
Когда-то стройный код стал обрастать костылями. Методы - непонятными параметрами, о назначении которых мы стали забывать. Тексты запросов становились все запутаннее, они собирались динамически в зависимости от десятков условий, закопанных где-то глубоко. Отладка усложнялась, а количество багов стало плавно, но уверенно расти. Как и их сложность: порой одна ошибка обходилась нам в несколько человекочасов только на ее локализацию. А исправление иногда только усложняло исходный алгоритм.
Общее владение кодом падало.
Параллельно мы развивали версию для конфигураций на управляемых формах. Ее код мы частично скопировали из обработки на ОФ, но дальше развивали независимо. Изменения базовой функциональности (например, работы с API сервиса) приходилось вручную переносить из одной обработки в другую и адаптировать.
Кроме того, у нас иногда появлялись клиенты с полностью самописными конфигурациями. Адаптировать модуль под такие разработки было тяжело: один из разработчиков полностью уходил в эту задачу на 2-3 для, потом еще в течение недели (или больше) занимались отладкой получившегося Франкенштейна. Последующее обновление обработки становилось неоправданно тяжелым. А развитие продукта, естественно, буксовало из-за этого.
В общем, мы столкнулись с тем, с чем ранее не имели дела: с разработкой тиражного продукта (и со всей ответственностью, вытекающей из этого), а также с необходимостью работы в команде.
Средства командной разработки от 1С нам не подошли. “Хранилище Конфигурации” решает другую задачу: оно в буквальном смысле хранит конфигурацию. И все. Ветвление и объединение веток, режим “blame” и возможность построчного комментирования кода отсутствуют. Да, в последних версиях 8.3 разработчики платформы дали возможность разложить конфигурации на исходники в виде текстовых файлов, которые уже можно хранить в современных системах контроля версий. И скомпилировать конфигурацию из этих исходников, разумеется. Нас эти возможности очень радуют, но воспользоваться мы ими не можем. Причина проста - нам приходится поддерживать версию для 8.2.
Итого, мы имели около 85 тысяч строк кода в 2 разных обработках, длинные запутанные методы, проблемы с объединением наработок. Тяжелее всего было объединять изменения двух разработчиков в рамках одной функции.
Как выживать?
Я не открою здесь Америку, многое давным-давно описано в учебниках ООП. Можно почитать Фаулера. Если вы, как и я, не знаете Java, то пойдет эта статья. Но 1С8 - не совсем ООП, и мы долгое время писали по принципу “лишь бы работало” (и работало, конечно, до поры до времени).
На Инфостарте тоже лежит несколько статей с хорошими советами (пример, пример, еще пример), рекомендую к прочтению и осознанию. Опишу наш собственный опыт.
Технические решения
-
Рефакторинг - наше всё
В продуктах подобного масштаба читабельность и структурированность кода становится не эстетическим удовольствием перфекциониста, а необходимым условием выживания проекта вообще. Лучше потратить лишний час на структурирование и подбор говорящих за себя имен методов/переменных, чем заставить своего коллегу потом убить 2 дня на поиск ошибки, оторвав его от текущих задач на развитие.
А еще в сложном, запутанном коде часто водятся баги. Прозрачный и лаконичный код они почему-то не любят.
Например, встречаются такие нагромождения:
"Если ...
<170 строк чего-то>
ИначеЕсли...
<250 строк чего-то>
…(в том же духе)
КонецЕсли" (несколько экранов спустя).
И где-то там еще есть вложенные “Если”. Эти конструкции работают ровно до тех пор, пока в них не придется что-либо поменять (например, исправить ошибку, которая там наверняка встретится). Три-четыре уровня вложенности "Если" попахивают неприятностями. Пять-шесть уровней практически гарантируют баги. Больше всего времени при исправлении ошибок нами было убито именно на то, чтобы понять, да как же, черт возьми, попасть в эту ветку. Начали раскладывать такие нагромождения в линейные конструкции вроде
Если ДальшеДелатьНечего Тогда
Возврат
КонецЕсли;
И жить стало легче.
Наткнувшись на особо древние костыли, назначение которых уже никто особо не помнит, мы их просто вычищаем, стараясь сделать код красивым изнутри. Потом смотрим, что от этого сломалось, и стараемся сделать код красивым и там тоже. Если совсем без костылей обойтись пока не удается, мы их выделяем, заливаем красной краской и обставляем дорожными конусами, чтобы вернуться впоследствии.
Рефакторинг проводим время от времени, без какого-либо плана, по настроению. А настроение обычно возникает на фоне необходимости добавления какой-либо фичи, затрагивающей запутанные участки кода.
-
Чем меньше кода, тем лучше
Не в ущерб читабельности, здесь важно вовремя остановиться. Одинаковые или просто похожие куски кода мы стали объединять в новые методы или в циклы. Это типичный прием рефакторинга, но мы пошли чуть дальше.
Мы начали избавляться от функциональности, от которой в принципе можно было избавиться (имелась альтернатива). Это было довольно болезненно: взять и выбросить десятки тысяч строк кода, написанных когда-то совместными усилиями. Скрежет наших зубов раздавался по всему этажу. Самые значимые примеры:
- Забросили развитие модуля для УФ, в который до этого вложили кучу сил, и стали вписывать управляемые формы в модуль для ОФ, сэкономив десятки тысяч строк кода.
- Прекратили поддержку хранения данных в типовых объектах системы (справочник “Хранилище дополнительной информации” + регистр сведений “Значения свойств объектов” на конфигурациях вроде УТ). Сейчас все данные модуля (сообщения, настройки,...) хранятся непосредственно в текущей базе данных - для этого в базу добавляется 3 справочника и 3 регистра сведений. Альтернативой “Типовым объектам” стало хранение данных модуля “снаружи” текущей БД. Т.е. модуль разворачивает вспомогательную базу с почти такой же конфигурацией, и работает с ней через COM-соединение. За счет близкой структуры данных мы здорово сэкономили на коде и текстах запросов.
-
Написали с нуля новый интерфейс главного окна (и шесть раз переписали движок почти полностью). В последнем варианте удалось сделать построение списков документов максимально гибким, скоростным и универсальным. При этом кода стало меньше.
Кроме того, многие участки кода удалось вообще преобразовать в макеты. Это часть запросов, названия типов документов/справочников в разных типовых конфигурациях, списки настроек, XSD-схемы некоторых файлов и т.д.
Полтора года назад у нас было 2 обработки и 85 000 строк кода в сумме. Сейчас одна обработка и 70 000 строк кода. Разумеется, эти полтора года мы не только уничтожали код, но и писали много нового.
-
Декомпозиция методов
Это тоже часть рефакторинга, но о ней я расскажу чуть подробнее.
Чем меньше разных действий выполняет метод, тем он читабельнее. Например, если в одной процедуре/функции встречается чтение файла с FTP и заполнение какого-либо документа, логичнее разбить его на два разных метода. Методу, который парсит XML, незачем знать, как устроена текущая конфигурация. Еще есть управляемые формы, где интерактивные действия недоступны на сервере.
Это аналог старых добрых классов в ООП и немного закос под mvc.
Мы стали делить длинные портянки кода на логические блоки, и средний размер одного метода упал с 40 до 30 строк кода. Стало гораздо проще объединять код разных веток перед релизом. Вероятность конфликтов свелась к минимуму, а их разрешение упростилось в разы.
Да, у нас еще остаются портянки строк на 300. Придет время - и их по возможности раскидаем.
-
Автоматизированное тестирование
Мы внедрили 2 системы тестов: сценарные тесты и юнит-тесты на основе xUnitFor1c. Каждый коммит в системе контроля версий подхватывается скриптом и автоматически отправляется на тестирование в нескольких типовых конфигурациях 1С. Релиз не выпускаем до тех пор, пока все тесты не позеленеют, и пока тестировщики не скажут "ок", разумеется. (Да, у нас есть тестировщики, нет, они не программисты).
Первый вариант тестирования (сценарный) выявляет наибольшее количество ошибок. Он похож на этот, только для обычных форм. Для этого нам пришлось встроить в сам код модуля точки входа для скриптов тестирования.
Второй не столько ловит ошибки (да, мы еще ленимся писать новые тесты, типичная проблема), сколько заставляет писать новый код с тем расчетом, чтобы его можно было прогнать через юнит-тесты. То есть его действие пока больше психологическое, но оно помогает более грамотно структурировать код. А значит, избегать появления ошибок еще на этапе разработки.
Стараемся придерживаться такого правила: если в релизной версии более 1-2 раз регистрируются ошибки, возникающие в одном и том же методе, то покрываем этот метод тестами. Чаще всего сначала его приходится потрошить и расчленять подвергать рефакторингу.
-
Система контроля версий
Изначально использовали SVN с клиентом от Tortoise. Использовали его для блокировки предрелизной версии в момент заливки изменений и для хранения истории коммитов и релизов.
Затем на коленке собрали собственную систему контроля версий на 1С. Выглядит примерно так:
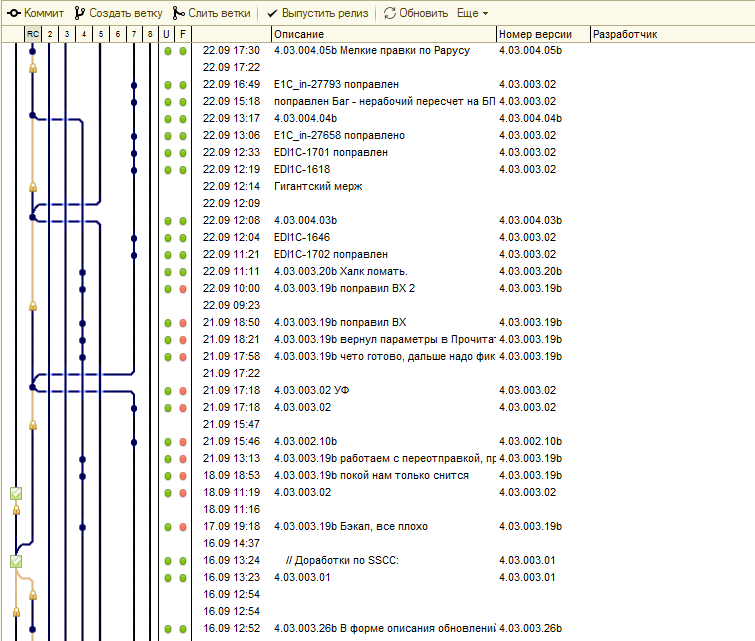
Автотесты интегрированы с этой системой и зеленеют/краснеют прямо на коммитах. Столбец с зелеными кружками и заголовком “U” - юнит-тесты. Столбец правее с заголовком “F” - интеграционные тесты.
Иногда встречаются такие цепочки коммитов:

Сюда же встроен V8Reader с возможностью сравнить 2 произвольных коммита без открытия конфигуратора. Получается очень удобно.
Здесь же автоматизированы действия при выпуске релиза: формирование RSS, закрытие задач в трекере, расчет контрольной суммы файла и т.д.
Почитав статьи про современные системы контроля версий (раз, два), захотели перейти на связку Git+Precommit1c с компиляцией обработки из исходников. Увы, в платформе 8.x есть не очевидная особенность: при сохранении файла внешней обработки некоторые формы (не управляемые) хаотично перекодируются, выдавая совершенно другой файл, даже если вы просто пробел в коде добавили. Мы пытались как-то обмануть платформу, чтобы можно было объединять изменения разных веток и компилировать исходники обратно во внешнюю обработку. В конце концов пришлось смириться с реальностью и оставить эти попытки. Однако используем Git+Precommit1c для “ленивого” Code Review: каждый участник команды получает уведомления о новых коммитах и может оставить комментарии к любой строке изменившегося кода. В precommit1c внесли изменения:
-
После декомпиляции удаляем файлы обычных форм, чтобы не засорять коммиты.
-
Из управляемых форм вытаскиваем код отдельно.
-
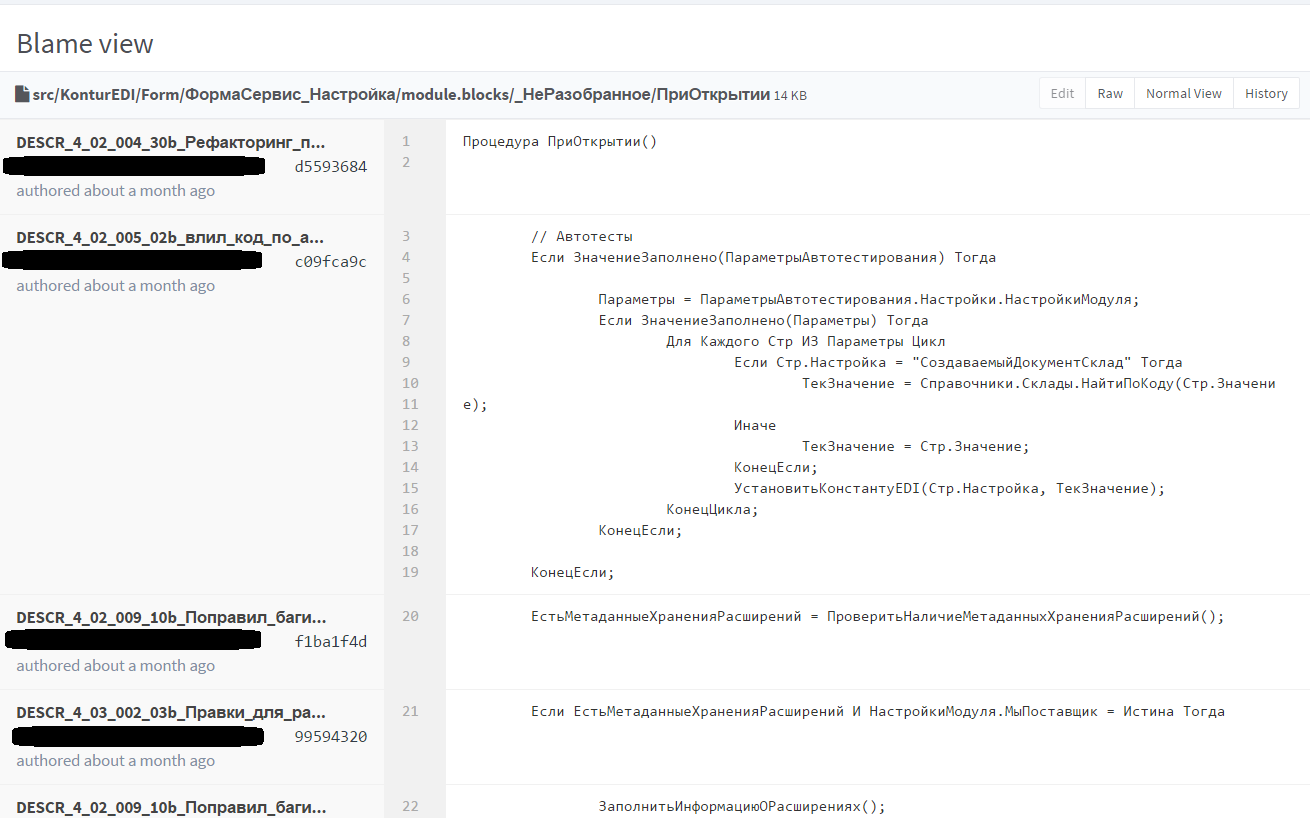
Каждый метод записывается отдельным файлом. Это сильно облегчает и Code Review, и просмотр в режиме Blame.
Кто не знает, режим Blame в Git отвечает на вопрос:

Но делает это более корректно:
-
Работа в нестандартных конфигурациях
Периодически возникавшая необходимость адаптировать модуль под нетиповую конфигурацию очередного крупного клиента заставила нас задуматься о каком-то инструменте, который позволит выполнять эту работу хотя бы с минимальными усилиями. Мы же программисты, самые ленивые люди в мире. Тем более что для 7.7 такой инструмент уже был готов: у нашего основного разработчика на этой платформе черный пояс по магии.
Изначально модуль 8.х разрабатывался на УТ 10.3. Весь код был пронизан конструкциями вида Заказ = Реализация.Сделка, например.
Мы стали постепенно, от релиза к релизу, абстрагироваться от привязки к конкретной конфигурации (снова немного mvc), загоняя поиск связанных документов в промежуточные функции и параметризуя названия справочников, документов, их реквизитов.
Был период, когда мы целенаправленно брали вне очереди задачи на настройку модуля в самописных конфигурациях и смотрели, в какие участки кода приходится вносить правки. Начинали с простого: с замены конструкций “Заказ = Реализация.Сделка” на функции-обертки: “Заказ = ПолучитьЗаказ (Реализация)”. В итоге получился довольно мощный инструмент, основная идея которого, надеюсь, будет понятна. Большую часть описания конфигураций удалось оформить декларативно (макеты, тексты запросов, без кода).
Получилось примерно так:
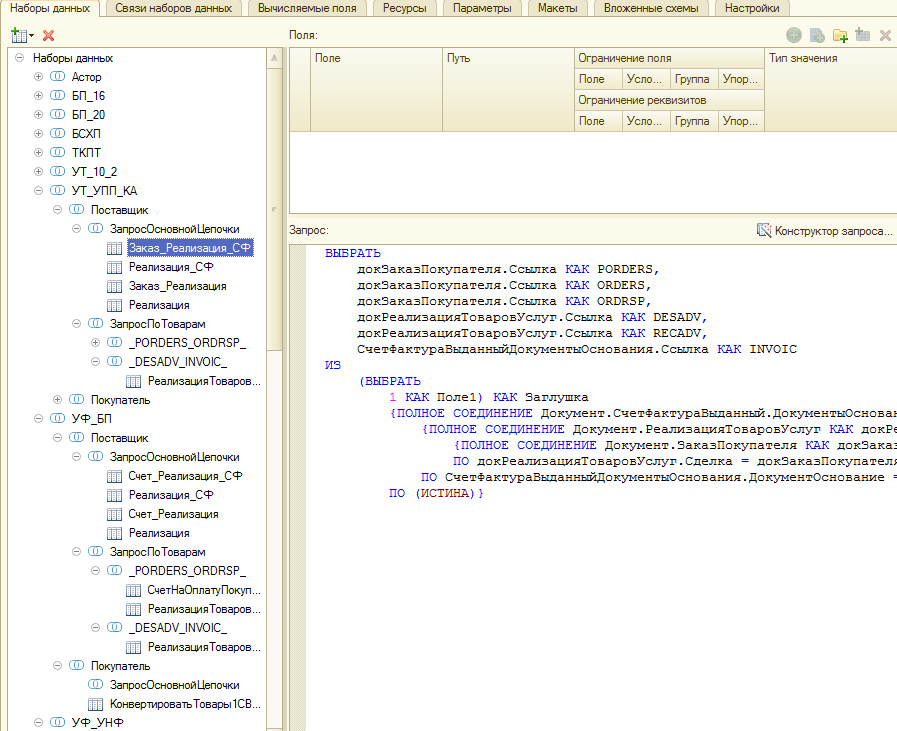
(Данные запросы разбираются на части и собираются заново в нужном виде. И не говорите, что СКД для этого не предназначена. Знаю, согласен.)
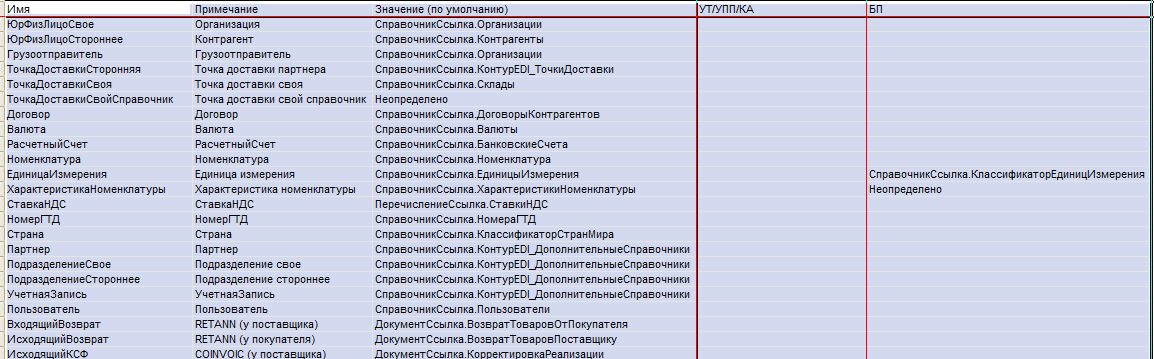
Для заполнения документов по сообщениям и наоборот хотим сделать двухсторонний маппинг полей “Сообщение - Документ”. Посмотрим, насколько это возможно, а пока пользуемся простой функцией-оберткой для доступа к реквизитам документов. Длина кода - 80 строк.
Эти вещи позволили нам легко выполнять 90% работы по кастомизации обработки.
После этого провели боевой тест на полностью самописной конфигурации, вот фрагмент метаданных для наглядности :

Модуль взлетел быстро, большую часть изменений удалось вынести “сбоку”, что дает возможность с минимальной болью обновляться в будущем.
Так мы очень сильно разгрузили себя от однообразной работы по кастомизации модуля под конфигурации заказчиков и получили возможность больше времени уделять продуктовым задачам.
И еще один побочный эффект от проделанной работы: стало гораздо проще влить в модуль логику работы с 3 основными конфигурациями на управляемых формах.
Организационные решения
Очень простой и мощный инструмент. При масштабных изменениях в коде автор кидает клич, желающие изучают diff и дают свои замечания.
Практический эффект: на этом этапе мы действительно иногда находим ошибки в коде, неоптимальные действия, нечитабельные места. Психологический эффект: зная, что твой код будет придирчиво изучать коллега, стараешься писать как можно качественнее и яснее. Плюс повышаем общее владение кодом: напомню, это 70 000 строк.
Пример “ленивого” Code Review:
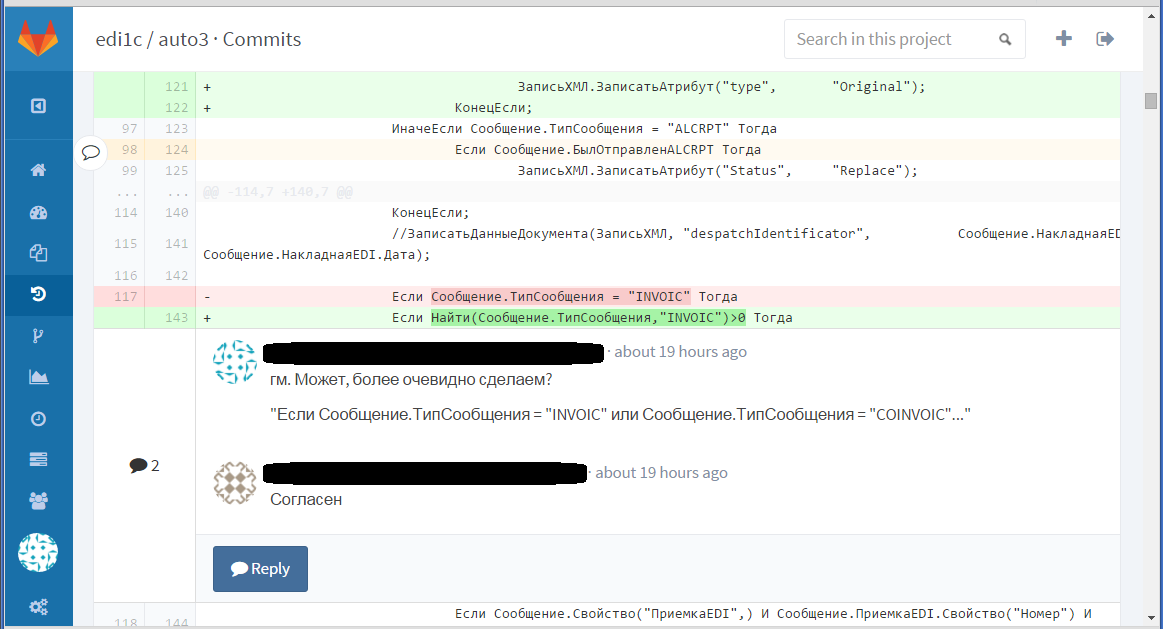
Это часть технологии “SCRUM”. Каждый день в 15:45 встаем возле доски и двигаем листочки с задачами, рассказывая друг другу, что сделали и что собираемся делать. Это здорово помогает быть в курсе того, куда вообще двигается продукт, и заодно позволяет избегать проблем с объединением кода.
-
Циклы разработки
Изначально мы выпускали релизы по такой схеме:
-
Добавили новую фичу
-
Отправили в продакшн.
Сейчас действуем так:
- Набираем задач на ближайшую неделю
- Разрабатываем и тестируем в своих ветках
- Проводим Code Review всех крупных изменений
- Сливаем в предрелизную ветку, она же версия для тестирования
- Тестировщики говорят свое "фи", исправляем баги
- Когда тестировщики говорят "ок", готовим описание релиза для rss, выпускаем релиз (обычно это 2-3 недели от начала итерации, бывает и больше).
- Критичные баги в случае их появления лечим в промежуточных релизах, дублируя фикс в предрелизную ветку.
Получается около 3-4 недель на итерацию. Если перед релизом есть ощущение, что что-то не так, значит, что-то действительно не так. Откладываем релиз и ищем причины неприятных ощущений, интуиция иногда спасает.
-
Работа с багами.
Представьте, что перед вами большая очередь задач на разработку, вы увлеченно кодите, и тут к вам прибегают 2 пользователя. У одного при открытии какого-то документа аварийно завершается работа системы. У второго - в каком-то окне вылетает непонятное сообщение об ошибке, которое можно закрыть и спокойно продолжить работу. Когда вы приступите к исправлению первого бага? А второго?
Критичные/блокирующие баги исправляются везде и всегда в первую очередь. А мелкие, позволяющие продолжить работу, обычно копятся. Психологически очень тяжело заставить себя потратить час на исправление одной ошибки из известных 46, чтобы их осталось 45.
Однажды мы ввели “день багов”. Это один день в неделю, когда все, преодолев собственное сопротивление, откладывают в сторону все новые фичи и занимаются исключительно исправлением таких вот мелких ошибок. Сейчас их осталось 13, это самые редкие или неуловимые.
-
Подбор задач из очереди
Были времена, когда мы лихорадочно пытались закрыть как можно больше задач за минимальное время — сказывался опыт работы во франчах и ИТ отделах компаний.
В действительности же самое циничное, что может сделать разработчик с заказчиком, - просто реализовать все его требования без их анализа. Ну а цинизм 80 уровня - реализовать их именно в той постановке, которую дал заказчик.
При работе фрилансом я сталкивался с тем, что клиент настаивал на придуманном им неоптимальном способе решения задачи. Если не удавалось его переубедить, в действие вступал простой алгоритм:
-
Делаю, что попросили.
-
Получаю оплату.
-
…
-
Клиент просит "сделать обратно". Делаю.
-
Получаю оплату.
Так вот, в тиражном продукте такой способ не подходит. Поток входящих задач всегда гораздо больше, чем способна переварить разработка. Со временем очередь задач выросла настолько, что нам пришлось привыкнуть к мысли: многие из этих хотелок мы будем делать только тогда, когда более важные закончатся. То есть никогда. Совсем. Было очень грустно это понимать, поскольку за каждой задачей обычно стоит какой-то клиент, которому без нее, возможно, будет плохо. Такова обратная сторона “массовости” продукта.
Зато у нас сформировалось собственное видение стратегии развития модуля. Именно стратегии, а не беспорядочного исполнения желаний. И при отборе задач в очередную итерацию мы определяем их по таким критериям:
-
Потенциальная польза от выполнения задачи.
-
Соответствие ее общей стратегии развития.
-
Целесообразность выполнения ее именно в эту итерацию (например, задача требует предварительного рефакторинга, который запланирован в следующую итерацию).
-
Наличие схожих задач, выполнение которых затрагивает общую функциональность, и которые целесообразно решать совместно.
Это дало интересный эффект: некоторые задачи мы стали выполнять еще до того, как они к нам поступали от отдела внедрения или от клиентов. Забавно на вопрос “ребята, нужна такая-то возможность, ее долго делать?” отвечать “мы 15 минут назад ее в релиз включили, скачивай”.
Что сейчас?
Не скажу, что год-два назад мы прямо ощущали какой-то большой дискомфорт. Нет, мы занимались разработкой в привычном для 1С-ника режиме (ну, вы понимаете, в каком именно). Более того, казалось, что по-другому и не бывает. Это как с курением: пока куришь, не понимаешь что что-то не так. Понимаешь только тогда, когда уже бросил.
Сейчас нам стало гораздо спокойнее выпускать новые релизы. Легче объединять код. Легче его поддерживать, мы больше не боимся через год-два полностью погрязнуть в разборе багов. Мы развиваем модуль по своей стратегии, и нам это нравится. Получаем удовольствие от красиво написанного кода и морщимся, наткнувшись на свои же костыли многомесячной давности. Продолжаем набивать шишки и расти. Наверное, так и выглядит командная разработка в других средах за пределами 1С.