

{kind=link}
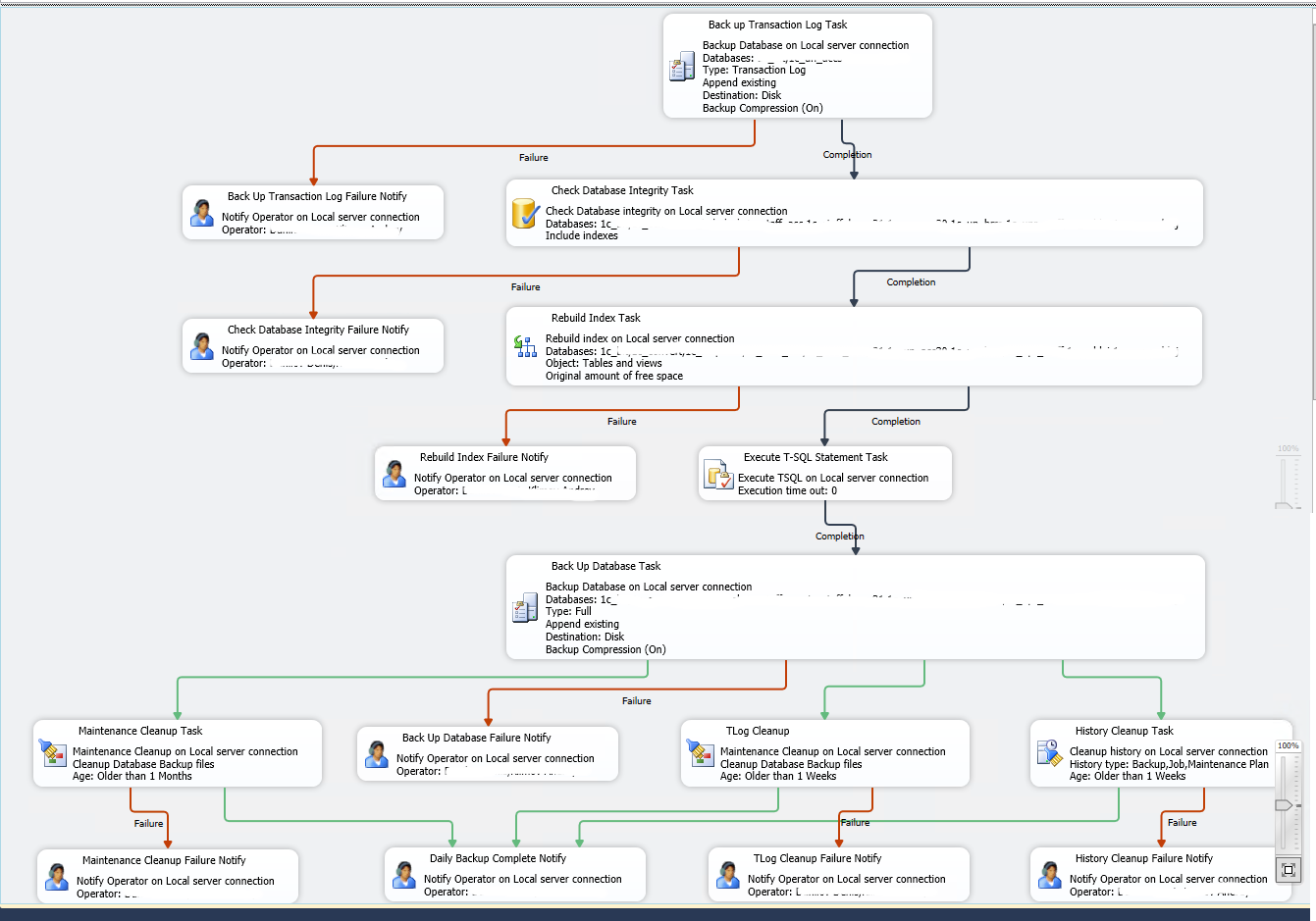
В архиве 2 скрипта. Оба реализуют стандартный комплект действий над списком баз:
- проверить целостность
- перестроить индекс
- очистить процедурный кэш
- [NEW] обрезать transaction log
- с архивировать
- удалить старые архивы
В случае ошибок - послать уведомление на почту администраторам
- serial.sql - выполняет комплект последовательно база за базой
- parallel.sql - пытается выполнить весь комплект параллельно
В результате на малой продуктовом сервере (8 virtual proc Xeon E5-2650v2 2.60 и SSD raid) c 15 базами общим объемом 50Gb получили:
- serial.sql - 13:51 минута
- parallel.sql - 4:22 минуты
Итого быстрее в 3 раза.
технически parallel.sql создает отдельные job для каждой базы и сразу их стартует.
Если кто подскажет идею, как сделать по другому - буду очень благодарен. Т.к. при таком режиме управлять количеством реально запущенных задач не получается.И какая там "параллельность выполнения" сказать тяжело.
[UPD.23/07/2019]
Дошли руки поправить скрипты:
- расширена обработка ошибок (не валимся если база в offline mode например)
- включена возможность бэкапа transaction log
на основном продуктовом сервер с тремя базами общим объемом 150 gb получили:
- serial.sql - 57 минут
- parallel.sql - 28 минут
Ускорение в 2 раза.
PS теперь надо сделать предварительную проверку дефрагментации индексов и делать rebuild/reorg только тем что нужно. Ну и некоторые таблицы вообще не трогать.
[ВАЖНО] Паралельный бэкап на тестовом сервере с 15K дисками и 30 базами объемом в 200Gb поставил сервер колом до окончания процесса. Поэтому на боевых серверах надо быть аккуратным. Во избежании
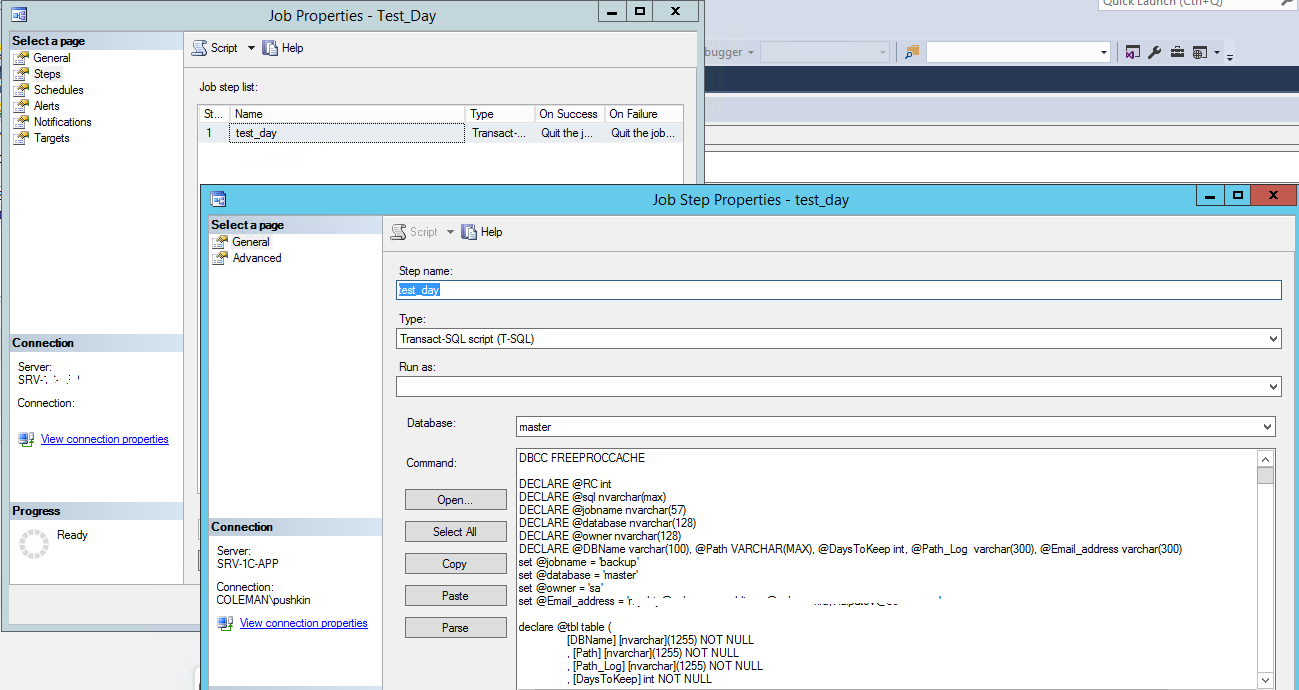
Подключение: 1 step в обычном job куда вводиться текст скрипта:

Вступайте в нашу телеграмм-группу Инфостарт