







Официальный сайт эластика https://www.elastic.co/.
По ссылке https://www.elastic.co/downloads/ необходимо закачать и установить
1. elasticsearch
2. filebeat
3. kibana
Рассмотрим что для чего используется.
Elasticsearch это поисковый движок, он хранит данные.
Filebeat вычитывает файлы логов маркируя прочитанные и отправляет в elasticsearch.
Kibana это интерфейс к elasticsearch, который отображает данные и позволяет быстро находить нужные по отборам.
Запуск инструментов
Запуск filebeat
"D:\distrib\filebeat-7.0.0-windows-x86_64\filebeat.exe" -c "D:\distrib\filebeat-7.0.0-windows-x86_64\filebeat.yml" -path.home "D:\distrib\filebeat-7.0.0-windows-x86_64" -path.data "C:\ProgramData\filebeat" -path.logs "C:\ProgramData\filebeat\logs"
Проверка настроек filebeat
D:\distrib\filebeat-7.0.0-windows-x86_64\filebeat.exe test config -c D:\distrib\filebeat-7.0.0-windows-x86_64\filebeat.yml
Установка elasticsearch в виде сервиса
d:\distrib\elasticsearch-7.0.0\bin\elasticsearch-service.bat install
Запуск kibana выполняется файлом kibana.bat из папки bin корневого каталога.
Механизм работы:
Filebeat вычитывает файлы логов маркируя прочитанные и отправляет в elasticsearch с указанием в какой индекс ложить.
Если индекса нет он создается, если индекс есть в него добавляются новые записи.
Структура индекса создается по шаблону, который filebeat передает elasticsearch.
Сам шаблон filebeat берет из настроек fields.yml, так же можно указать свой шаблон.
Если в elasticsearch уже есть шаблон то по умолчанию он не обновляется (настройка setup.template.overwrite).
Для принудительного обновления шаблона необходимо выставить настройку setup.template.overwrite: true.
Так же можно самому создать шаблон напрямую в elasticsearch чтобы он подхватывался при создании индекса.
После создания индекса и шаблона необходимо задать правила парсинга сообщения ТЖ для разбора и заполнения полей индекса.
Настройка
Filebeat
Filebeat может обрабатывать каталоги и файлы.
Файлы читает построчно и гарантирует что прочитанное сообщение будет отправлено по крайней мере один раз и без потери данных.
Каждый файл обрабатывается отдельно.
Данные о прочитанных файлах хранятся в реестре.
По каждому файлу хранится уникальный идентификатор.
Это необходимо т.к. файл может быть переименован или перемещен.
Уникальные идентификаторы хранятся в реестре, поэтому возможен его рост при чтении большого количества файлов.
Более подробно описано в https://www.elastic.co/guide/en/beats/filebeat/7.0/how-filebeat-works.html.
# настраиваем сбор логов ТЖ
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
# Обращаем внимание на формат, \*\* будет смотреть в подкаталог, когда \* не будет
- d:\logs1С\*\*.log
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
# Имя индекса, если нет то создается новый
index: "onectj-%{+yyyy.MM.dd}"
# Разделим на индексы по типам сообщений
# Без разделения все будет ложиться в один индекс описанный выше
indices:
- index: "onectj-call-%{+yyyy.MM.dd}"
when.contains:
message: "SCALL"
- index: "onectj-conn-%{+yyyy.MM.dd}"
when.contains:
message: "conn"
timeout: 60
# Нас интересует преобразование логов при обработке в эластике
# для этого необходимо указать pipeline (https://www.elastic.co/guide/en/beats/filebeat/6.4/elasticsearch-output.html)
# который будет обрабатывать лог в эластике.
# В эластике необходимо настроить этот pipeline.
# Более подробно описано здесь
# https://www.elastic.co/guide/en/beats/filebeat/7.0/configuring-ingest-node.html
pipeline: "onectj_pipeline"
# загружать шаблон индекса в эластик, если шаблон есть он не перезаписывается
setup.template.enabled: true
# имя шаблона искомого в эластике для разбора индекса
setup.template.name: "onectj"
# паттерн шаблона
setup.template.pattern: "onectj-*"
#============================== Setup ILM =====================================
# Изменение имени индекса по умолчанию будет игнорироваться
# если включена ILM (управление жизненным циклом индекса).
# Можно либо доработать ILM либо отключить
# Более подробно описано здесь
# https://www.elastic.co/guide/en/beats/filebeat/7.0/ilm.html#setup-ilm-overwrite-option
# filebeat 7.0+
setup.ilm.enabled: false
#setup.lim.overwrite: true
Elasticsearch
Для его настройки используем kibana, точнее ее консоль.

Добавим шаблон по которому будет создаваться индекс.
PUT _template/onectj
{
"index_patterns": ["onectj-*"],
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
/*добавляем поля*/
"num_min": {
"type": "integer"
}
,"num_sec": {
"type": "integer"
}
,"ten_thousandth_second": {
"type": "integer"
}
,"duration": {
"type": "integer"
}
,"event1c": {
"type": "text"
}
,"level_event": {
"type": "text"
}
,"process_name": {
"type": "text"
}
,"usr": {
"type": "text"
}
,"context": {
"type": "text"
}
,"process1c": {
"type": "text"
}
,"ClientID_name": {
"type": "text"
}
,"ClientID": {
"type": "text"
}
,"computerName": {
"type": "text"
}
/*можно добавить группу полей*/
/*"onec": {
"properties": {
"num_min": {
"type": "long"
}
,"num_sec": {
"type": "long"
}
,"ten_thousandth_second": {
"type": "text"
}
,"duration": {
"type": "text"
}
}*/
}
}
}
}
Посмотреть существующий шаблон можно по команде
# получим шаблон индекса ТЖ
GET /_template/onectj
Чтобы просмотреть все шаблоны команда будет похожая
GET /_template/*
Для удаления шаблона используется команда
# удалим шаблон
DELETE _template/onectj*
Внимание!!!
Изменение шаблона делается по аналогии с добавлением.
Но если изменился тип поля то он обновится только в новом индексе либо при переиндексации существующего.
После создания шаблона определим правила разбора сообщения на поля индекса.
Внимание!!!
В индексе отображаются только заполненные поля.
Т.е. если поле есть в шаблоне, но не заполняется правилами оно не будет отображаться при просмотре индекса.
При создании правил допускается указание нескольких правил списком, при этом отработает первое подходящее.
# установим шаблон разбора сообщений ТЖ
PUT _ingest/pipeline/onectj_pipeline
{
"description" : "onec tj pipeline",
"processors": [
{
"grok": {
"field": "message",
"patterns": ["%{NUMBER:num_min}:%{BASE10NUM:num_sec}-%{WORD:duration},%{WORD:event1c},%{WORD:level_event}"]
}
},
{
"grok": {
"field": "message",
"patterns": [
"process=%{WORD:process1c}"
],
"on_failure": [
{
"set": {
"field": "process1c",
"value": ""
}
}
]
}
},
{
"grok": {
"field": "message",
"patterns": [
"Usr=%{WORD:usr}"
],
"on_failure": [
{
"set": {
"field": "usr",
"value": ""
}
}
]
}
},
{
"grok": {
"field": "message",
"patterns": [
"Context=%{WORD:context}"
],
"on_failure": [
{
"set": {
"field": "context",
"value": ""
}
}
]
}
}
]
}
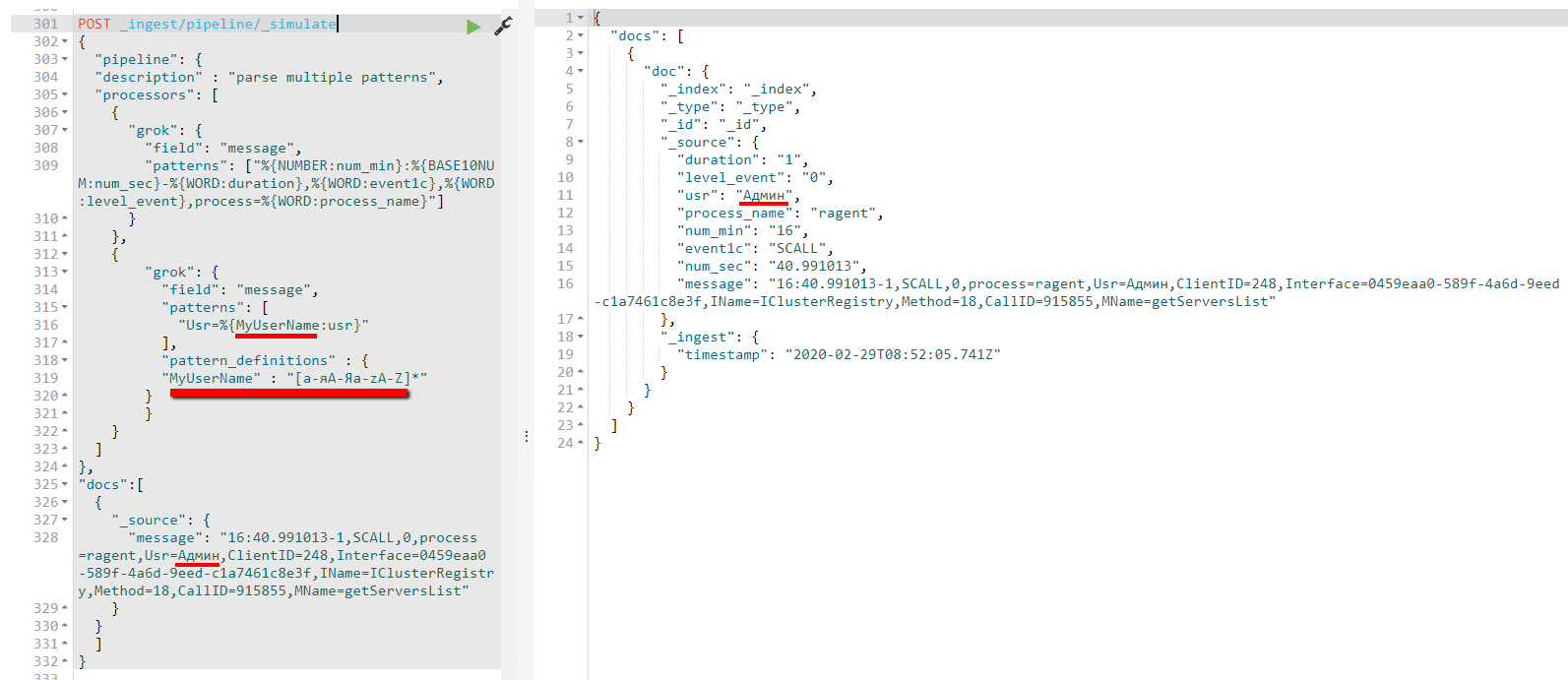
Отладить выражения для разбора можно следующим образом
# проверим шаблон разбора сообщений ТЖ
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description" : "parse multiple patterns",
"processors": [
{
"grok": {
"field": "message",
"patterns": ["%{NUMBER:num_min}:%{BASE10NUM:num_sec}-%{WORD:duration},%{WORD:event1c},%{WORD:level_event},process=%{WORD:process_name}"]
}
},
{
"grok": {
"field": "message",
"patterns": [
"process=(%{DATA:process},|%{GREEDYDATA:process})"
],
"on_failure": [
{
"set": {
"field": "process",
"value": ""
}
}
]
}
}
]
},
"docs":[
{
"_source": {
"message": "16:40.991013-1,SCALL,0,process=ragent,ClientID=248,Interface=0459eaa0-589f-4a6d-9eed-c1a7461c8e3f,IName=IClusterRegistry,Method=18,CallID=915855,MName=getServersList"
}
}
]
}
Kibana
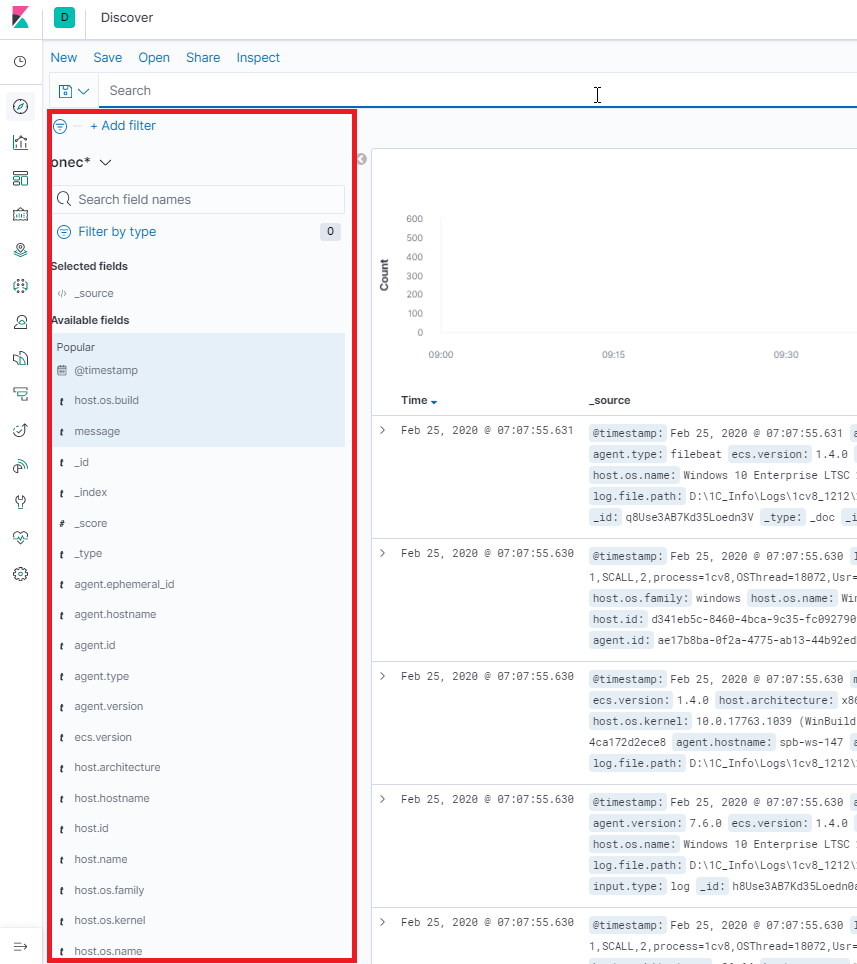
Для просмотра индексов в kibana необходимо создать паттерн их отображения.
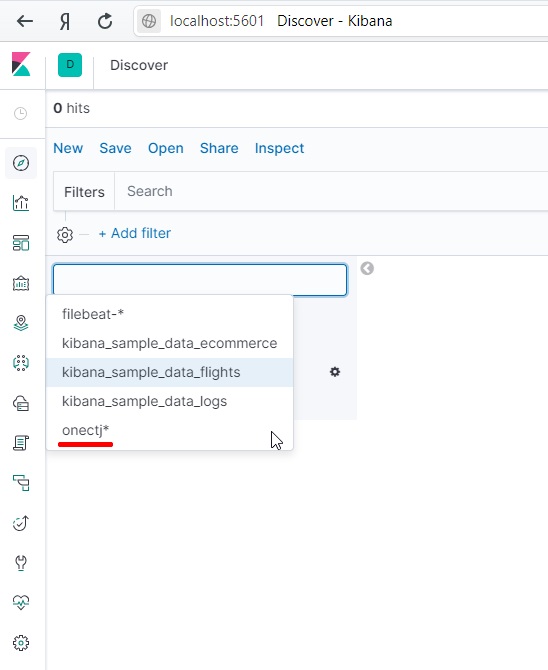
Для этого зайдем в паттерны индексов и создадим новый.
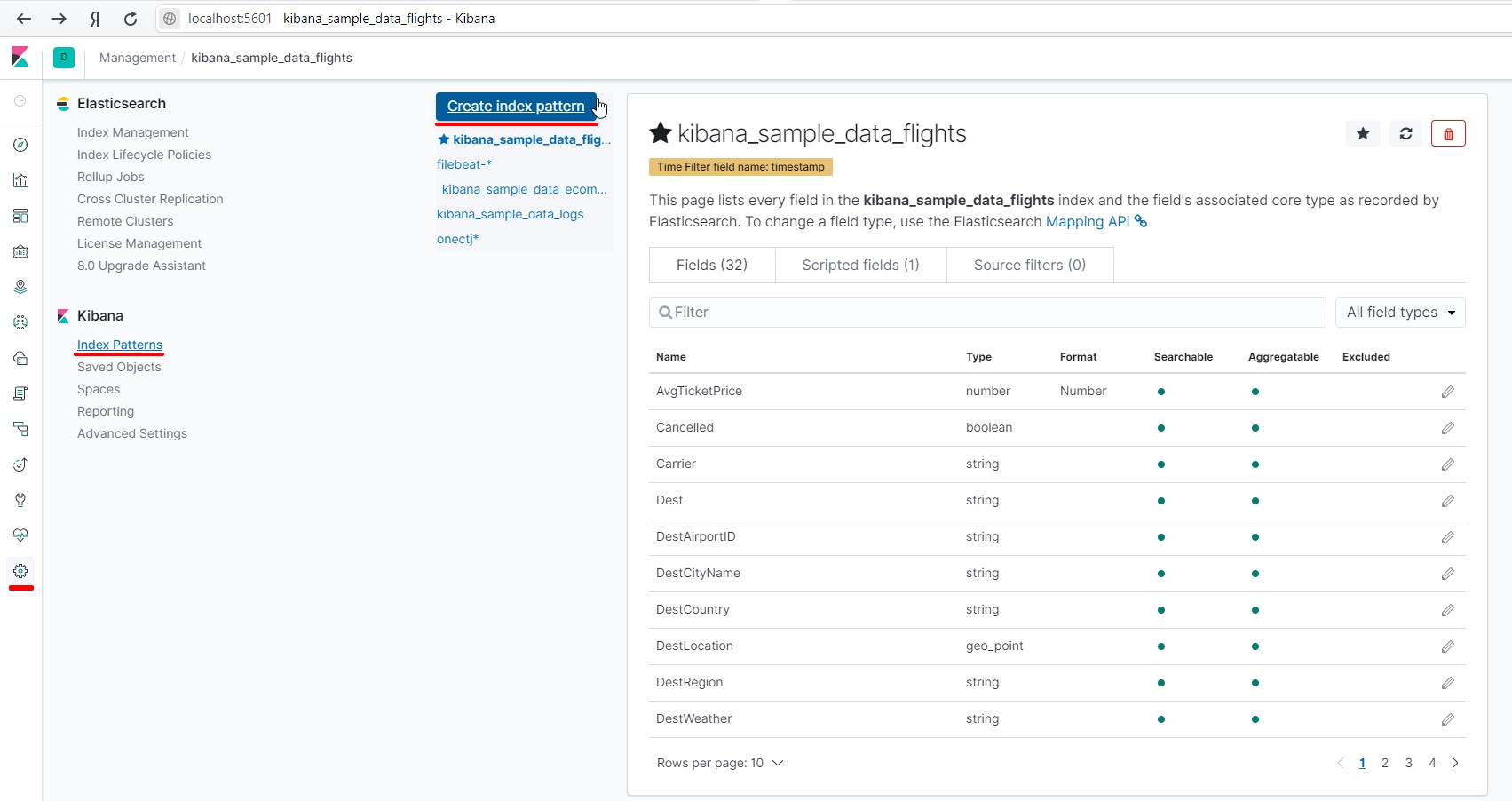
Укажем маску для группировки нескольких индексов.
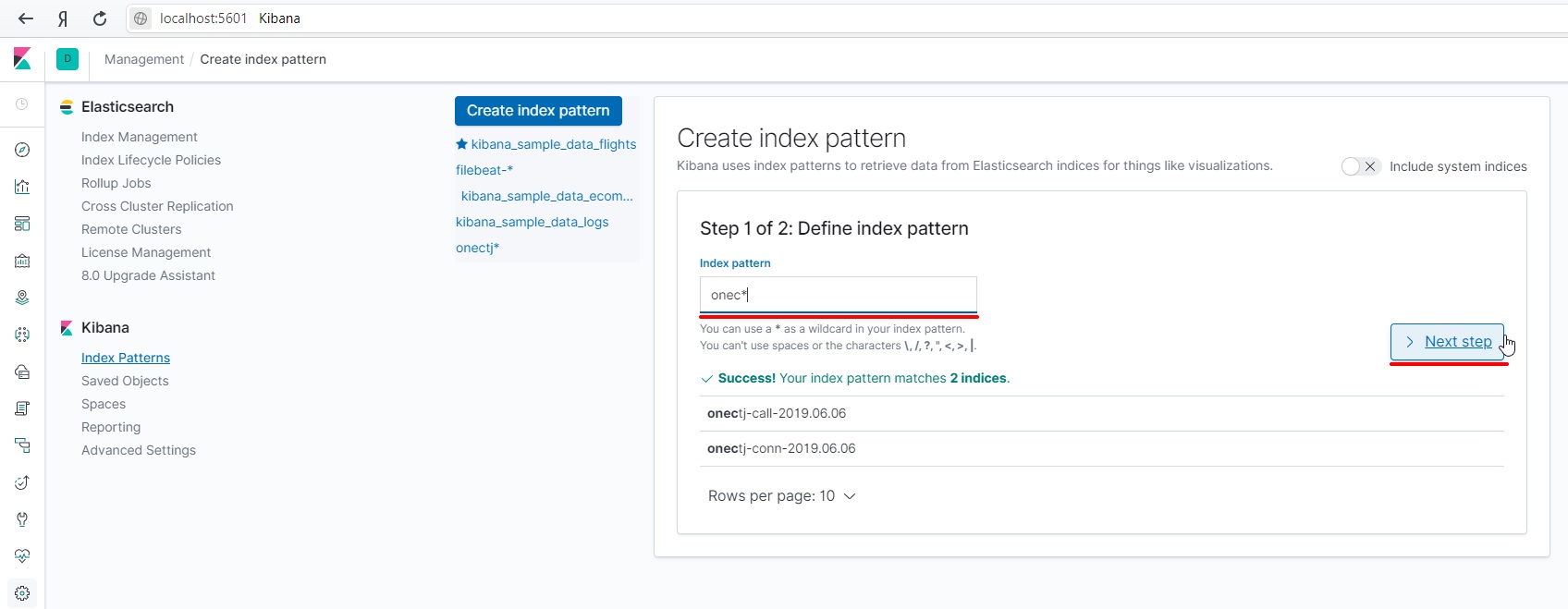
Выберем поле хранящее время события
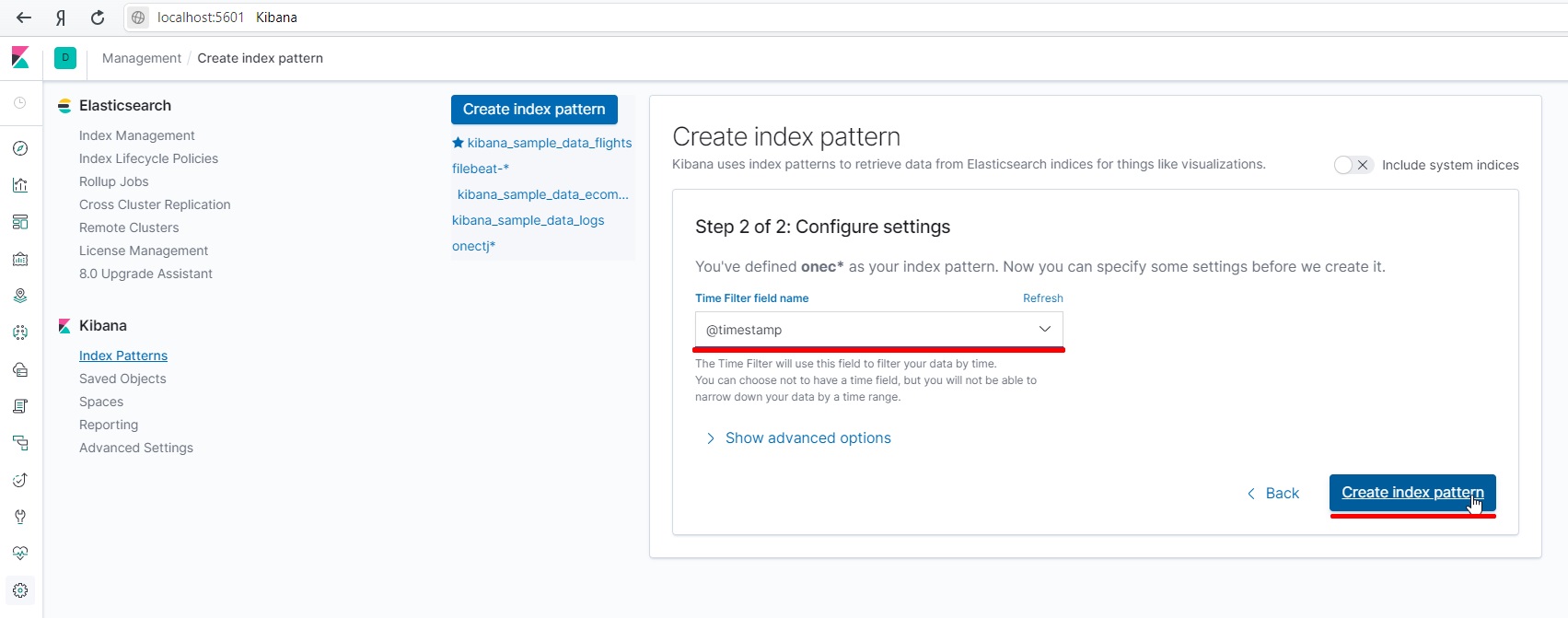
Создадим паттерн индекса.
Теперь выбрав этот паттерн можно будет просматривать индексы.

Отладка
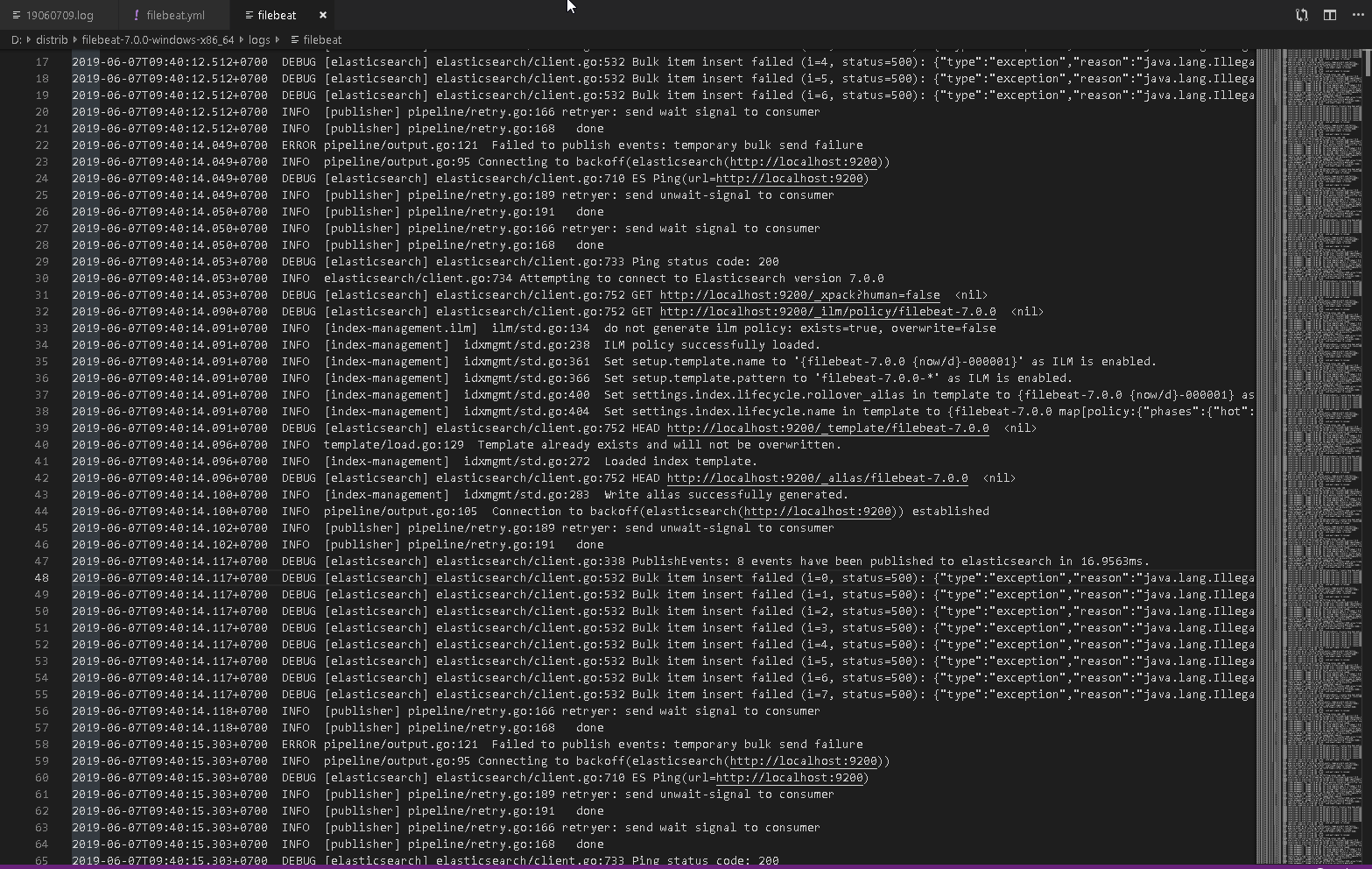
Для анализа проблем обработки в elasticsearch используем журнал filebeat.
#================================ Logging =====================================
# Sets log level. The default log level is info.
# Available log levels are: error, warning, info, debug
logging.level: debug
logging.to_files: true
logging.files:
path: "d:\\distrib\\filebeat-7.0.0-windows-x86_64\\logs"
name: filebeat
Указываем уровень регистрируемых ошибок, включаем журнал. При желании можно указать свой каталог логов.
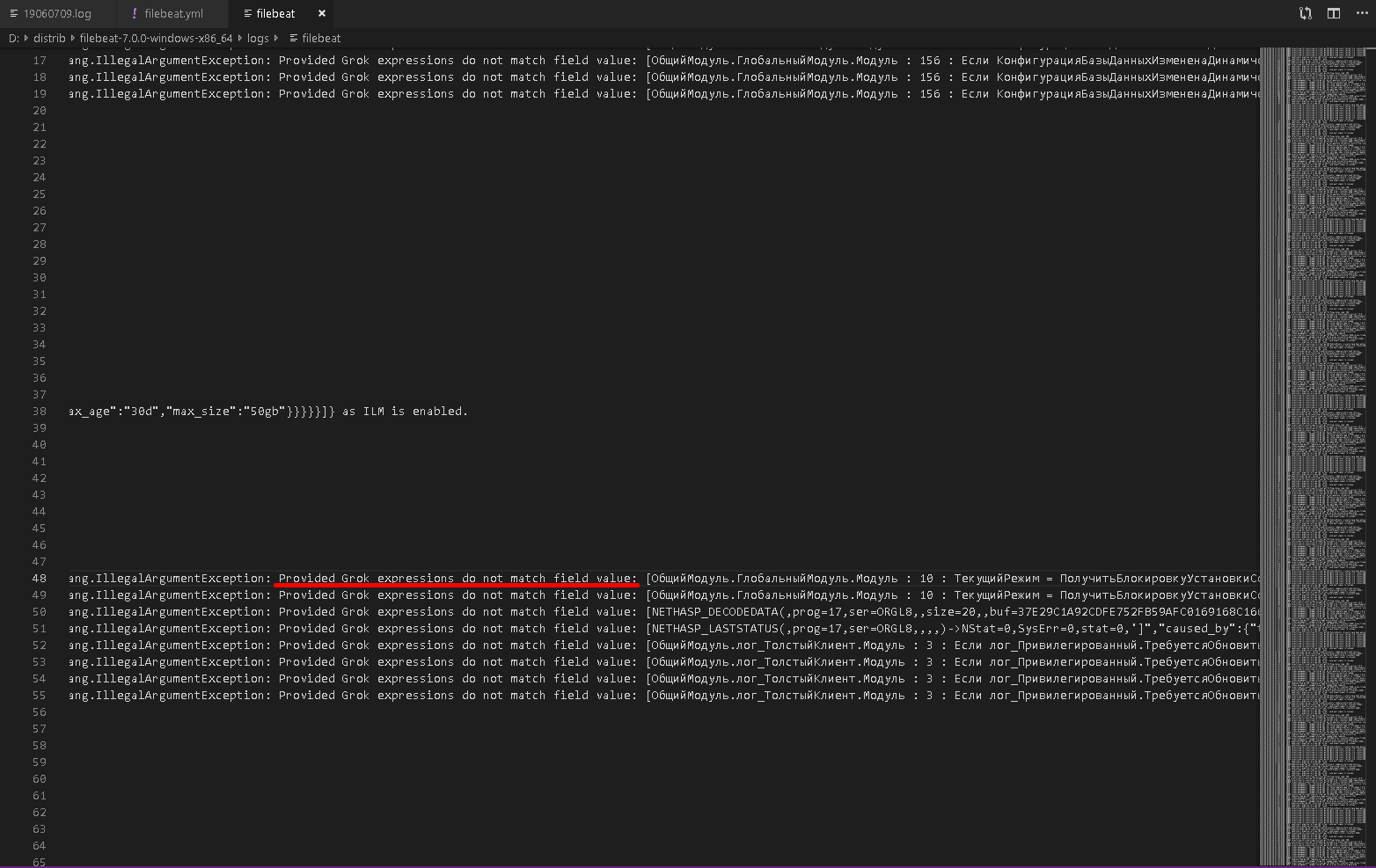
В случае ошибок они отобразятся в логах
Например
#2019-06-07T09:40:14.117+0700 DEBUG [elasticsearch] elasticsearch/client.go:532 Bulk item insert failed (i=0, status=500): {"type":"exception","reason":"java.lang.IllegalArgumentException: java.lang.IllegalArgumentException: Provided Grok expressions do not match field value: [ОбщийМодуль.ГлобальныйМодуль.Модуль : 10 : ТекущийРежим = ПолучитьБлокировкуУстановкиСоединений();']","caused_by":{"type":"illegal_argument_exception","reason":"java.lang.IllegalArgumentException: Provided Grok expressions do not match field value: [ОбщийМодуль.ГлобальныйМодуль.Модуль : 10 : ТекущийРежим = ПолучитьБлокировкуУстановкиСоединений();']","caused_by":{"type":"illegal_argument_exception","reason":"Provided Grok expressions do not match field value: [ОбщийМодуль.ГлобальныйМодуль.Модуль : 10 : ТекущийРежим = ПолучитьБлокировкуУстановкиСоединений();']"}},"header":{"processor_type":"grok"}}
Данная ошибка говорит об отсутствии в паттерне шаблона условия для разбора сообщения.
Сообщение не загрузилось.
Пример сообщений журнала.
Вступайте в нашу телеграмм-группу Инфостарт