
{kind=link}
Чем только не парсят технологический журнал 1С. Есть и решения от 1С, есть и множество самописных конфигураций, обработок и скриптов на самых разных языках.
Подтолкнула меня к экспериментам статья Go. Разбор лога технологического журнала. Достойная альтернатива perl'у
В ней рассматривается вариант парсера написанного на языке Go вместо аналогичного решения на Perl. Я не знаю ни Go, ни Perl. И, хотя, разобраться в них для меня особого труда не составляет, т.к. я знаю достаточно языков, что бы понять и использовать еще два, не слишком хочется тратить на это время.
Тем более, что я недавно опубликовал демонстратор языка программирования Перфолента и время мне позарез необходимо на его отладку и развитие.
Итак, поехали… Для начала, мне очень понравилась картинка в указанной статье, демонстрирующая многопоточную обработку файлов ТЖ (здесь и далее ТЖ равно «технологический журнал») и я решил, что и на Перфоленте попробую сделать похожую структуру программы. Затем, сделал вывод, что мне не хочется изобретать и использовать массу параметров командной строки. Проще сделать копию программы для другого отбора и обработки строк, ведь исходный код всегда под рукой. Постепенно накопятся все необходимые мне варианты.
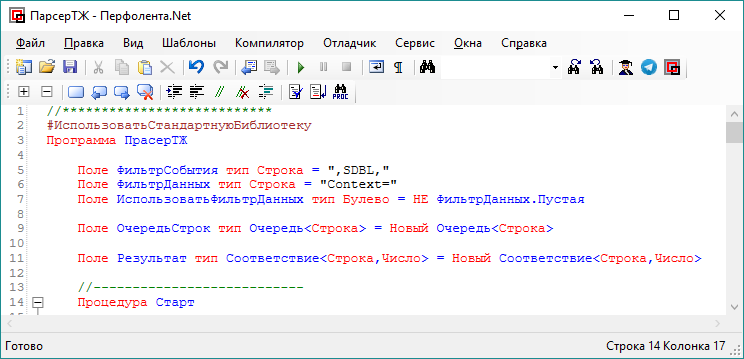
Начало программы стандартное, нажимаем меню Шаблоны\Программа и получаем начальный шаблон, где необходимо ввести имя программы:
//***************************
#ИспользоватьСтандартнуюБиблиотеку
Программа ПарсерТЖ
//---------------------------
Процедура Старт
КонецПроцедуры
КонецПрограммы
Теперь в процедуре Старт начинаем писать код. Нам необходимо обработать все файлы логов ТЖ находящиеся в папке программы. При необходимости, можно указать и другой каталог. Обрабатывать файлы будем в многопоточном цикле ДляКаждого, который использует все имеющиеся ядра процессора.
//выбираем все лог файлы из текущей папки
//загрузим все ядра процессора
Рез=ПараллельныеДействия.ДляКаждого<Файл>(
ФС.ВыбратьФайлы(ЭтаПрограмма.Каталог,"*.log"),
ПолучитьДелегат(,ОбработатьФайл,"ДействиеПроц<Файл>"))
В указанном фрагменте кода для программистов 1С может быть не понятным оператор ПолучитьДелегат, который просто возвращает ссылку на процедуру с одним параметром, в которой и будет обрабатываться каждый файл.
Синтаксис оператора ПолучитьДелегат такой:
ПолучитьДелегат( Объект , ИмяМетода, "ТипДелегата")
В нашем случае параметр Объект не обязателен, т.к. метод расположен в этом же модуле Программа. Тип делегата выбираем из имеющихся в стандартной библиотеке, главное, что бы совпадало число и тип параметров. Параметр ТипДелегата в данном случае тоже можно опустить, компилятор поймет и так ПолучитьДелегат(,ОбработатьФайл), но я решил написать в примере полный синтаксис, есть случаи, когда этот параметр обязателен.
Напишем эту процедуру чуть ниже процедуры Старт:
//---------------------------
Процедура ОбработатьФайл(Ф тип Файл)
Ив = Новый ИнтервалВремени
Чт = Новый ЧтениеТекста(Ф)
Пт = Новый ПостроительТекста
Кво=0
Цикл
Стр=Чт.ПрочитатьСтроку
ПрерватьЕсли Стр Это Неопределено
//началом строки события считаем шаблон ^\d\d:\d\d\.\d+
//однако проверка только разделителей вполне надёжна и достаточна
Если Сред(Стр,3,1)=":" И Сред(Стр,6,1)="."
Если Пт.Количество <> 0
Кво++
ОтборСтрок(Пт.ВСтроку)
КонецЕсли
Пт.Очистить
КонецЕсли
Пт.Добавить(Стр)
КонецЦикла
Если Пт.Количество <> 0
Кво++
ОтборСтрок(Пт.ВСтроку)
КонецЕсли
Чт.Закрыть
ВыводСтроки "Обработали файл: "+Ф+" Количество строк = "+Кво+" Время, сек: "+Ив.ВсегоСекунд
КонецПроцедуры
Готово… Теперь наши файлы обрабатываются и для каждой строки вызывают процедуру ОтборСтрок(ТекущаяСтрока). Объект ПостроительТекста используем для ускорения конкатенации строк. Объект ИнтервалВремени используем для измерения времени обработки файла. Строки приходится склеивать потому, что в файле ТЖ могут быть многострочные фрагменты в определении одного события. Формально, в ТЖ события заканчиваются символами ВКПС, а многострочные строки разделяются символом ПС, но, к сожалению, для объекта ЧтениеТекста это одно и то же.
Теперь нам надо написать процедуру ОтборСтрок, в которой мы применим правила первого отбора. Почему я решил делать отбор в 2 этапа? Потому, что если файл лога у нас будет только один, или их будет меньше, чем ядер процессора, то процессор мы полностью не загрузим. Сложная обработка строки будет тормозить работу. А если быстро отобрать строки только по имени события, например «SDBL», то дальнейший отбор мы сможем вести многопоточно, вне зависимости от числа файлов.
Процедура получилась простая:
//---------------------------
//В этой процедуре отберем только интересующий нас вид строк
Процедура ОтборСтрок(Стр тип Строка)
Если Найти(Стр,ФильтрСобытия)=0
Возврат
КонецЕсли
Если ИспользоватьФильтрДанных И Найти(Стр,ФильтрДанных)=0
Возврат
КонецЕсли
ОчередьСтрок.Добавить(Стр)
КонецПроцедуры
Как видно, мы используем в виде накопителя отобранных строк некий объект ОчередьСтрок, а так же еще несколько имен: ФильтрСобытия, ФильтрДанных, ИспользоватьФильтрДанных. Это всё поля, которые мы определили в модуле Программа:
Программа ПрасерТЖ
Поле ФильтрСобытия тип Строка = ",SDBL,"
Поле ФильтрДанных тип Строка = "Context="
Поле ИспользоватьФильтрДанных тип Булево = НЕ ФильтрДанных.Пустая
Поле ОчередьСтрок тип Очередь<Строка> = Новый Очередь<Строка>
В Перфоленте у объектов есть Поля, которые похожи на переменные модуля 1С, но все же это не переменные, переменные в Перфоленте «живут» только в методах.
Объект ОчередьСтрок используется одновременно несколькими потоками, добавляющими в него отобранные строки. Если бы это была обычная коллекция, то могли бы возникнуть проблемы. Многопоточность опасна, если разные потоки одновременно обращаются к одним и тем же данным. Однако, в Перфоленте многие коллекции обобщенного типа, в том числе и Очередь<>, являются потокобезопасными и поэтому ни какая дополнительная синхронизация нам не потребуется.
На данном этапе у нас уже есть коллекция отобранных строк для события SDBL. Запустим их многопоточную обработку и посчитаем суммарное время работы для каждого контекста выполнения.
//обработаем все найденные строки
Рез=ПараллельныеДействия.ДляКаждого<Строка>(
ОчередьСтрок,
ПолучитьДелегат(,ОбработатьСтроку,"ДействиеПроц<Строка>"))
Ничего нового по сравнению с обработкой файлов в этом фрагменте кода нет, разве что тип Файл сменился типом Строка.
Напишем процедуру окончательной обработки строки лога:
//---------------------------
//Получим из строки интересующие нас данные
Процедура ОбработатьСтроку(Стр тип Строка)
//получим длительность события
Длительность = Число(Стр.Сред("-",","))
//получим контекст
//Контекст = Стр.Сред("Context='","'")
//а можно воспользоваться и регулярным выражением
Контекст = ""
Рег = Новый РегулярноеВыражение("(?<=Context=').*?(?=')")
Если Рег.Совпадает(Стр)
Контекст=Рег.НайтиСовпадения(Стр)[0].Значение
КонецЕсли
//нам все же понадобится блокировка, т.к. несколько потоков могут одновременно попытаться увеличить значение по одному и тому же контексту
Блокировка ОчередьСтрок
//сложим время одинаковых контекстов
Было = Результат.Получить(Контекст)
Результат.Вставить(Контекст, Было+Длительность)
КонецБлокировки
КонецПроцедуры
Как мне кажется, этот код будет понятен всем программистам 1С. Отбор фрагментов строки можно осуществлять двумя способами, обычными функциями работы со строками и регулярными выражениями. Кому что больше нравится.
Результат в этот раз мы собираем в коллекцию типа Соответствие<Строка,Число>. Выглядит немного необычно для программистов 1С, но не для программистов C#. В данном случае, мы просто указываем, что ключ соответствия будет иметь тип Строка, а значение будет иметь тип Число. Другие типы в этой коллекции сохранить нельзя. Можно ли использовать обычное Соответствие? Можно, но скорость его работы будет меньше и понадобятся блокировки, т.к. обычное Соответствие не является потокобезопасным.
Поле Результат тип Соответствие<Строка,Число> = Новый Соответствие<Строка,Число>
Осталось обработать результат. А давайте сохраним его в файл Эксель и откроем.
//обработаем результат, например, создадим табличку
Док=Новый ТабличныйДокумент
НомСтр=1;
Для КлючЗнач Из Результат
//берем только длительные события
ПродолжитьЕсли КлючЗнач.Значение<400000
Док.УстановитьЗначениеЯчейки(НомСтр , 1,КлючЗнач.Значение)
Док.УстановитьЗначениеЯчейки(НомСтр++, 2,КлючЗнач.Ключ)
КонецЦикла
//сохраним и откроем в Экселе
Док.Записать(ЭтаПрограмма.Каталог+"ТабличныйДокумент.xlsx")
ЗапуститьПриложение(ЭтаПрограмма.Каталог+"ТабличныйДокумент.xlsx")
Я тут в цикле дополнительно ограничил количество строк, отобрал только те, длительность которых была не меньше 400000 миллионных долей секунды. Просто меня интересуют самые медленные.
А что со скоростью?
Вполне сопоставимо со скоростью программы на Go, у меня даже быстрее получилось, но не факт, что на любом компьютере будет так же. Тестовый файл размером 5,7 ГБ, около 10 млн. строк, пережевался за 5 минут.
А что с потреблением памяти и допустимым размером файлов лога?
Во время обработки файла размером 5,7 ГБ максимальное потребление памяти программой составило 1,2 ГБ. Файлы больше указанного размера я не проверял, но скорее всего проблем не будет.
Как мне кажется, любой программист 1С сможет самостоятельно доработать этот пример, добавив необходимые отборы, сортировки и группировки.
Вступайте в нашу телеграмм-группу Инфостарт