



Я думаю многие сталкивались с ситуацией, когда штрихкодов на объектах учета нет и не будет, а ТМЦ(продукцию, оборудование, документы и т.д.) учитывать нужно. При этом все понимают, что решение для автоматизации должно обладать повышенной надёжностью и главное скоростью. Никого не устроит если артикул будет сканироваться пару минут или если из 10 сканирований правильными будет только 7, да даже если из 100 будет правильным 99 – это тоже неприемлемый результат. Кто это будет исправлять потом? Такое решение только ради поиграться.
Алгоритмы распознавания текста (OCR) существуют уже очень давно и успешно применяются в разных областях. Например сканируются бумажные документы. Или книги. Если почитать такую отсканированную книгу (при условии что ее не редактировал редактор) то рано или поздно можно наткнуться на ошибки в распознавании. Такие ошибки я встречал в 100% отсканированных книг. Чисто практическим путем можно прийти к выводу что все эти алгоритмы не могут гарантировать 100% точность сканирования. Потому что нет внутренней верификации. В случае с текстом верификацией является словарь. Т.е. если сканируется слово «шоколад», даже если «о» смахивает на «0»(ноль) программа не выдаст «ш0к0лад» потому что она сверится со словарем.
А в случае сканирования номера или артикула – вообще нет никакой верификации! Нет никакой проверки целостности (как например в EAN-13) нет даже уверенности в том что блок текста захвачен полностью. Т.е. на таком алгоритме нельзя построить промышленную систему учета? Или всетаки можно?
Как работает решение для непрерывного захвата видеопотока можно посмотреть на приложенном видео – там где показана работа «демо» с бумаги и колеса. Суть в том что алгоритм непрерывно сканирует видеопоток, выделяет в нем блоки и распознает их. Далее по задумке Гугл пользователь должен тапнуть по нужному блоку и распознанный текст покажется на следующем экране (и далее с ним что то делать).
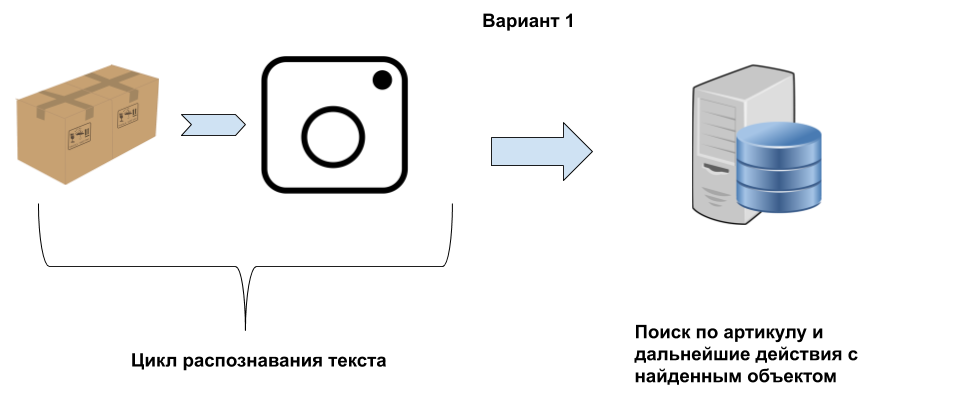
Если делать решение «в лоб» то сразу же получишь все вышеописанные проблемы. Тапнул на нужный блок, что то распозналось – передалось в систему. И далее варианты – если правильно распознался то все хорошо, если нет то логика будет неправильная. Т.е. это обычный вариант использования библиотеки как черного ящика который возвращает распознанный текст. Точно также используется библиотека распознавания штрихкодов. Но только она то работает, потому что штрих-коды на то и штрихкоды что строго стандартизированы и имеют встроенную верификацию.
Кстати, небольшое отступление о распознавании штрих-кодов камерой телефона. Многие относятся скептически, но библиотека ZXing от Zebra (не стоит путать с библиотекой от 1С) которая стоит в Simple UI показывает результаты, не уступающие оптическим сканерам. Конечно, телефон не заменит специальный дальнобойный лазерный сканер для работы с кара, но для обычных целей это 100%-эффективная замена ССD сканеру. 5 сканирований в минуту – легко!
В общем такой подход считаю неправильным и в вместо этого предлагаю другой.
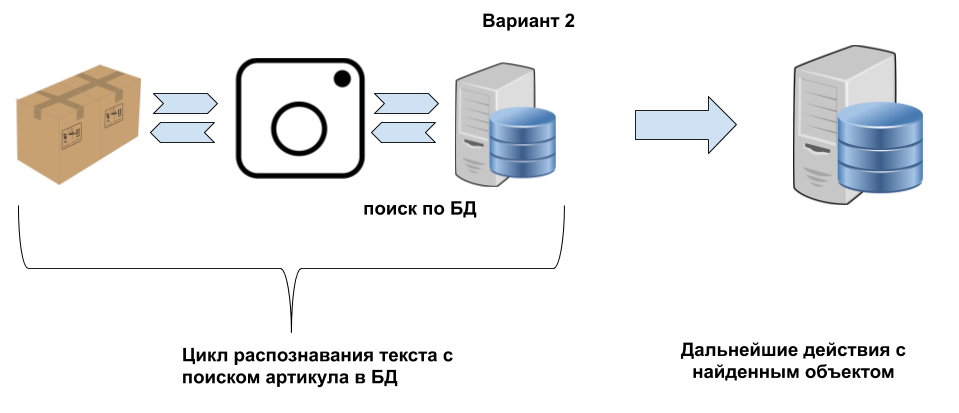
Суть подхода очень проста и заключается в глубокой интеграции в цикл сканирования видеопотока и верификации сканируемых идентификаторов (артикулов, номеров) в БД приложения. Работает это так. Допустим у нас есть база объектов для сканирования, например справочник Номенклатура с артикулами. Размер справочника не важен – хоть 100 тысяч объектов.
Если посмотреть на примеры в видео то там видно что видеопоток сканируется несколько раз в секунду – это бесконечный цикл, при этом постоянно выделяются блоки и блоки распознаются в текст. Так сказать появляются гипотезы. Так вот если в этот цикл встроить запрос к базе артикулов чтобы проверять эти «гипотезы» и прерывать цикл когда найдено 100% совпадение – это вот то что я и сделал. Я думаю это не провернуть с 1С (в смысле отсылки запроса, поиск в базе и возврат ответа) – скорость не та. Зато это отлично работает на прямых SELECT-ах к SQL на устройстве(в тесте у меня запрос к «документам» - таблице documents которая хранится в БД приложения Simple UI)
Т.е. этот метод работает только по существующим артикулам. Не возможна ситуация «Такого артикула нет в базе». Режим сканирования будет пытаться распознать пока не распознает и цикл не прервется. Работа такая же внешне как с распознаванием штрихкодов через камеру – распознал, цикл закончился.
Для теста я просто сделал открытие карточки найденного товара на экране. Распознал – карточка открылась. Это не часть конструктора, нельзя встроить в процессы – просто искусственный тест. Посмотрите видео, как это работает.

По результатам тестирования скорость при нормальной освещенности сопоставима со скоростью сканирования штрих кодов оптическим сканером. Каких то скрытых проблем не выявлено. Это конечно сильно зависит от состава и начертания текста, поверхностей, освещенности. Но согласитесь – шины довольно сложный объект?
Особенности библиотеки:
- Работает полностью OFFLINE хотя есть и онлайн режим. Специально выключал всю связь, Simple UI работала с настройкой Off-line
- Иногда телефон нагревается, когда долго ждешь
- Распознает только латиницу. Есть и другие языки кроме английского но кириллицу не распознает. Это можно частично обойти если делать замену похожих букв. Но понятноЮ не все буквы похожи
- Непонятен вопрос с лицензированием (об это далее)
Хоть распознавание и показало себя отлично я пока не встраиваю его в распространяемое решение Simple UI, но могу предоставить apk с встроенным распознаванием по запросу всем желающим. Причина в том, что я не понимаю как оно лицензируется. И судя по форумам не один я. У Гугла есть тарифы, они более чем божеские и можно было бы отдавать клиенту решение с его ключом чтобы он платил. Вот цены на online: https://cloud.google.com/vision/pricing Но! Конкретно та библиотека и модель работают OFFline, а нигде не указывал свой идентификатор Firebase и ничего не платил… Халява? Может дело в том что ML Kit имеет статус beta? Но я не представляю как они будут контролировать число сканирований (чего?) в месяц… В общем, пока этот вопрос выясняется.
Вступайте в нашу телеграмм-группу Инфостарт
