В прошлый раз мы завершили разработку механизма, позволяющего подключать развернутые через Vagrant виртуальные машины к серверу Jenkins в качестве сборочных узлов. На борту у этих машин - платформа 1С и PosgreSQL ( с возможностью выбора их версий ). Теперь у нас есть основа для автоматизации различных процессов, связанных с платформой 1С, которую можно быстро развернуть на любом физическом сервере. И конечно одним из таких процессов является непрерывная интеграция и тестирование.
Для решения исходной задачи - построения завершённого CI-контура - осталось только разработать сами задачи-пайплайны, которые будут запускатсья посредством Jenkins. Но перед этим предлагаю немного погрузиться в теоретические вопросы, рассмотреть важные моменты создания пайплайнов Jenkins. Ведь разработка пайплайнов - это задача программирования. А программирование требует хотя бы минимальных знаний языка на котором пишется код. И понимания того, как работает исполняющая этот код среда.
Данная статья, как и все предыдущие, не обойдётся без коммитов в git-репозитории и кода, который при желании можно будет сразу опробовать на практике ;) В репозиторииях на Гитхаб и на Гитлаб появятся первые примеры пайплайнов Jenkins и две библиотеки с полезными методами, в том числе для работы с базами данных.
Синтаксис Groovy и Jenkinsfile
Ранее мы уже создавали простейшие задачи Jenkins, задавая их код непосредственно в окне браузера.
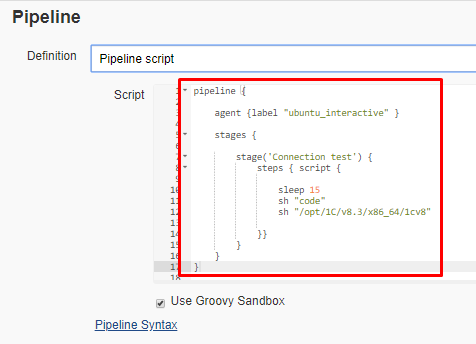
При выполнении таких задач исполняемый код загружается из xml-файла, хранящего настройки задачи:
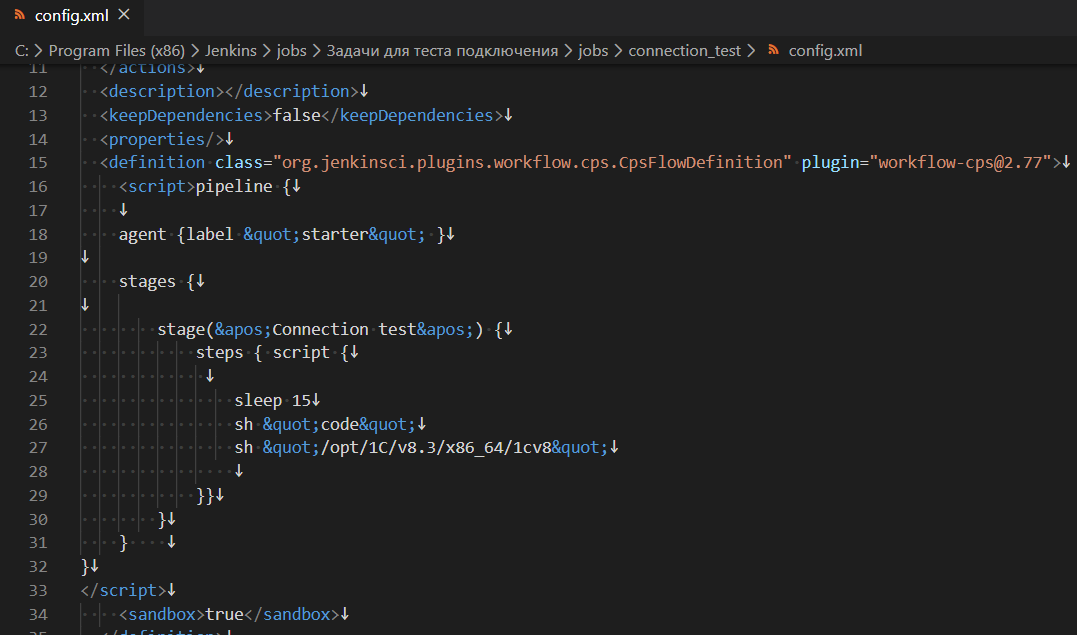
Но такой способ удобен только для очень небольших задач. Для задач большего объема применяется другой подход, который заключается в следующем:
- Код хранится в репозитории под версионным контролем git или другой VCS ( системы контроля версий )
- Путь к этому репозиторию указывается в настройках задачи, а вместе с ним указывается из какого файла внутри репозитория нужно извлекать исполняемый код
- Перед выполнением задачи Jenkins производит извлечение указанного файла из репозитория и читает исполняемый код пайплайна из этого файла, вместо того, чтобы брать его из xml-файла с настройками самой задачи.
Файлы, в которых хранится код пайплайнов, традиционно называются Jenkinsfile. Для их редактирования удобно использовать Visual Studio Code, так как в нем далее будет производиться редактирование не только кода пайплайнов, но и фича-фалов для сценарных тестов. В то же время то, что VSC стал самым распространенным инструментом для редактирования такого рода файлов не означает, что Вы не можете подобрать альтернативу по своему вкусу - здесь нет никаких ограничений ;)
В одном репозитории можно хранить множество Jenkinsfile, создавая по одному такому файлу для каждой задачи. Можно размещать такие файлы в одном каталоге, давая им разные имена, например по шаблону ИмяЗадачи.jenkinsfile. Или же можно поступить по другому и размещать их в разных каталогах, оставив традиционное имя Jenkinsfile ля всех файлов:
Код в Jenkinsfile пишется на языке Groovy. Этот язык является своего рода упрощением языка Java.
Поддержка динамической типизации, нетребовательность к квалификации разработчика и в то же время возможность использовать существующие библиотеки Java делают этот язык подходящим для использования в инструментах по автоматизации тестирования. Например он используется не только в Jenkins, но и в таком популярном инструменте, как SoapUI. Вряд ли этот язык следует изучать серьезно, так как он не используется в "большом программировании", но для написания пайплайнов этого и не требуется - достаточно понимать основные конструкции и принципы работы.
Собственно о таких причинах выбора Groovy как языка для пайплайнов Jenkins (близость к Java и при этом пригодная для работы начинающих разработчиков "безтиповая" скриптовость) можно услышать и от разработчиков самого Jenkins https://www.youtube.com/watch?v=LWeAc8wmnDI
В Jenkins применяется не чистый Groovy, а его подмножество с различными ограничениями и надстройками. Например можно создавать объекты, доступные в той JRE (Java-машине) которая у Вас установлена на сборочных узлах. Сам Jenkins тоже предоставляет дополнительные Java-классы, расширяя возможности своих Groovy-скриптов.
Но как из-за ограничений самого Jenkins так и из целей безопасности доступ ко многим возможностям Java ограничен. Не стоит надеяться, что абсолютно все удобства Java будут доступны из кода пайплайнов в Jenkins. Очень многие будут, но далеко не все ))
Свои ограничения вносит и необходимость передавать по сети значения переменных между сборочными узлами на различных компьютерах. Разные этапы одного пайплайна могут выполняться на разных компьютерах. Поэтому переменные, объявленные на уровне всего пайплайна и доступные в разных этапах, должны относиться либо к примитивным типам, либо к классам поддерживающим сериализацию и десериализацию.
Нам, как разработчикам на платформе 1С, это хорошо знакомо по разделению объектов на поддерживающие и неподдерживающие XDTO-сериализацию.
Разновидности пайплайнов
Базовая информация о синтаксисе и подходах к созданию пайплайнов приведена здесь: https://jenkins.io/doc/book/pipeline. Если Вы ещё не знакомы с этим синтаксисом, то прошу познакомиться с документацией или посмотреть несколько простейших видео на эту тему. Иначе всё, что написано далее может показаться обрывочной информацией.
По теме Jenkins есть целая россыпь видео на YouTube и торрентах для специалистов самого разного уровня подготовки как на Windows так и на Linux или MacOS. В частности хочу ещё раз порекомендовать следующий плейлист: https://www.youtube.com/playlist?list=PLmxB7JSpraiew9igtD89o33AaniUrmUzm. Ну а остальные легко найти самостоятельно.
Итак, есть два основных подхода к созданию пайплайнов. Первый из них - декларативный. Второй - скриптовый.
В декларативном синтаксисе объявляются вложенные конструкции - получается матрёшка. На верхнем уровне - пайплайн (Pipeline), который состоит из этапов (Stages) . Этапы состоят из шагов (Steps), шагами могут быть как отдельные операторы, вызовы функций, так и скрипты (Script) или нестандартные конструкции-обертки для кода, предоставляемые различными плагинами.
pipeline {
agent any
stages {
stage( ' Example ' ) {
steps {
echo ' Hello World ' // Это отдельный вызов функции
script { // Это скрипт
def browsers = [ ' chrome ' , ' firefox ' ]
for ( int i = 0 ; i < browsers.size(); ++i) {
echo " Testing the ${ browsers[i] } browser "
}
}
}
}
}
}
В скриптовом пайплайне немного меньше формальностей и больше возможностей. Но взамен во многих случаях он требует больше "ручного управления". Например при применении скриптового пайплайна не происходит автоматическая загрузка всего необходимого кода из git-репозитория на подчиненных узлах. В коде пайплайна необходимо явно прописывать, что и откуда мы загружаем и что именно исполняем.
Пример простейшего скриптового пайплайна из документации Jenkins:
node {
stage( ' Example ' ) { // Здесь весь код - это скрипт
if (env.BRANCH_NAME == ' master ' ) {
echo ' I only execute on the master branch '
} else {
echo ' I execute elsewhere '
}
}
}
Декларативный синтаксис появился позже и он часто оказывается проще для того, чтобы начать работать с пайплайнами. Можно встретить мнение, что декларативный пайплайн более продвинутый и пришел на замену скриптовому, однако это не так. Согласно документации по Jenkins, этот синтаксис придуман для упрощения работы с пайплайнами в случае простых процессов, а также для новичков и тех, кто не хочет глубоко погружаться в Groovy : https://jenkins.io/doc/book/pipeline/syntax
As it is a fully-featured programming environment, Scripted Pipeline offers a tremendous amount of flexibility and extensibility to Jenkins users. The Groovy learning-curve isn’t typically desirable for all members of a given team, so Declarative Pipeline was created to offer a simpler and more opinionated syntax for authoring Jenkins Pipeline.
Несмотря на то, что в сфере 1С тема CI часто воспринимается как сложная, на самом деле пайпланы для 1С получаются крайне простыми. Все сложности связаны в основном с API платформы 1С, отсутствием возможностей быстро и удобно выполнять операции с git и в стабилизацией сценарных тестов. На стороне же Jenkins почти не требуется знание сложных механизмов. В то же время избавление от ряда "ручных" операций не помешает. Поэтому выберем для наших задач декларативный пайплайн.
При этом можно легко превратить декларативный пайплайн в подобие скриптового. Достаточно все выполняемые операторы и вызовы функций обернуть в большие блоки script. Например следующим образом:
stage('Имя первого этапа) {
steps { script {
// Оператор 1
// Оператор 2
// ……………………….
}}
}
stage('Имя второго этапа') {
steps { script {
// Оператор 1
// Оператор 2
// ……………………….
}}
}
Это не вполне соответствует идее декларативного пайплайна, но при этом позволяет удобно сочетать преимущества обоих подходов. При такой записи также можно сэкономить на отступах в коде, так как нет смысла визуально разделять блоки steps и script.
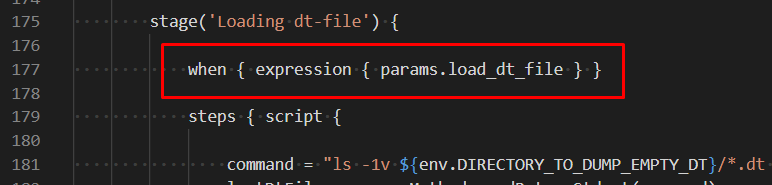
В декларативном пайплайне также легко можно задавать условия выполнения этапа сборки, что даёт возможность включать/отключать этапы выполнения не прибегая к громоздким условным операторам внутри блока steps. Например:
stage('Load test extension') {
// Это условие выполнения этапа. Если параметр задачи load_test_extention будет
// равен false, то Jenkins не будет выполнять этот этап и сразу перейдет к следующему
when { expression { params.load_test_extension } }
steps { script {
def statusCode = commonMethods.cmdReturnStatusCode([
baseDesignerCommandWithAuth,
"/LoadCfg \"./test_extension.cfe\" -Extension ${env.TEST_EXTENSION_NAME}"
])
Некоторые "декларативные" опции доступны не только для этапов, но и для пайплайна в целом. Например можно всего в одном месте указать timestamps():
pipeline {
options { timestamps() }
stages {
stage('Init environment') {
steps { script {
и тогда к выводу каждой команды в логах будет автоматически добавляться время её выполнения:
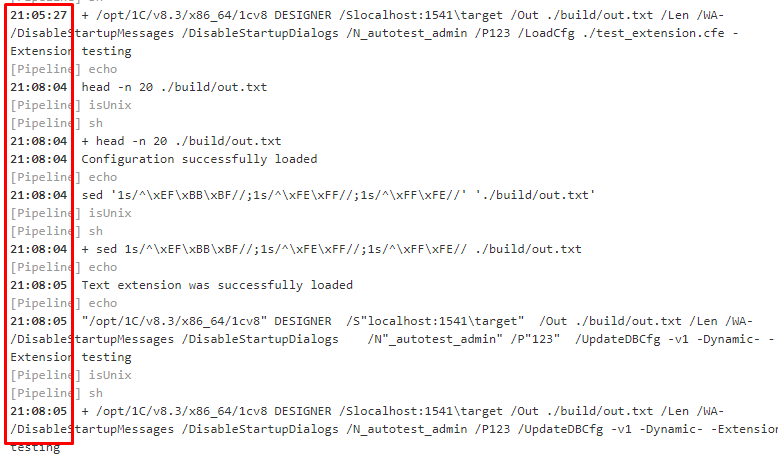
Элементы декларативного пайплайна
Итак, декларативный пайплайн, который мы будем применять, состоит из следующих элементов: сам пайплайн, этапы, шаги и операторы.
Блок pipeline описывает правила выполнения всей задачи в целом. По сути дела он и представляет собой задачу, за исключением настроек, хранящихся в xml-файле задачи и редактируемых как правило не через код, а через web-интерфейс Jenkins.
На уровне блока pipeline можно определять ряд общих свойств.
- Метки, которыми должен обладать сборочный узел, чтобы на него была назначена эта задача.
- Время хранения данных о прошедших сборках.
- Количество сборок, данные о которых нужно хранить.
- Необходимость выводить момент времени для каждого оператора в логах.
- и так далее.
Этапы - stages - это вехи пайплайна. Крупные логические блоки. Все элементы stage объединены в общий блок stages. Подозреваю что это сделано для упрощения парсинга текста Jenkinsfile, так как это не сильно упрощает чтение текста модуля и приводит к добавлению лишнего отступа в коде.
С точки зрения логической организации удобно разделять весь процесс сборки (пайплан) на эти блоки (этапы), чтобы можно было проще ими управлять и проще осуществлять поддержку ранее написанного кода. Например если в процессе сборки и тестирования выполняется загрузка конфигурации 1С, затем сценарное тестирование, затем дымовое тестирование, затем удаление протестированного cf-файла или его перенос в какое-то хранилище, то правильно будет разбить эти действия на отдельные этапы.
При этом в дополнение к логической организации кода мы получим удобное визуальное представление этапов выполнения с данными о затратах времени на каждый из этапов. И в случае ошибки сборки всегда будет ясно, на каком именно этапе она произошла:
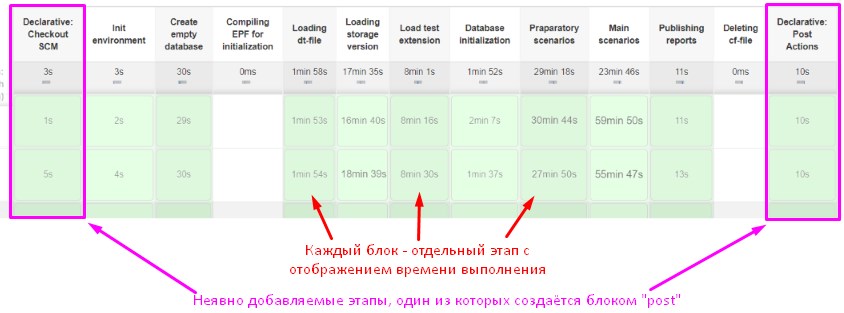
Если при этом исполняемый в задаче код загружается из git-репозитория, то в отображаемой таблице будет неявно добавлен специальный этап "Declarative: Checkout SCM" . И если в пайплайне есть специальный раздел "post", операторы которого всегда выполняются после всех прочих этапов, то видзуально добавится ещё один этап "Declarative: Post Actions". Отключить визуальное отображение этих "неявно" заданных этапов будет нельзя.
Впрочем никак нельзя отключить и отображение всех прочих этапов. Если этап не был выполнен согласно заданному в нём условию when { expression { логическое условие } } (см. пример выше) то визуальное отображение он всё равно получит. Это необходимо для корректного визуального выравнивания всех колонок в отображаемой статистике выполнения. Ведь при одном запуске пайплайна этап может быть пропущен. А при следующем запуске - уже выполнен и его надо будет как-то уместить в общей картинке.
Этапы не обязательно называть "по английски". Если при запуске Jenkins была включена поддержка UTF-8, то этапам можно давать названия на русском языке:
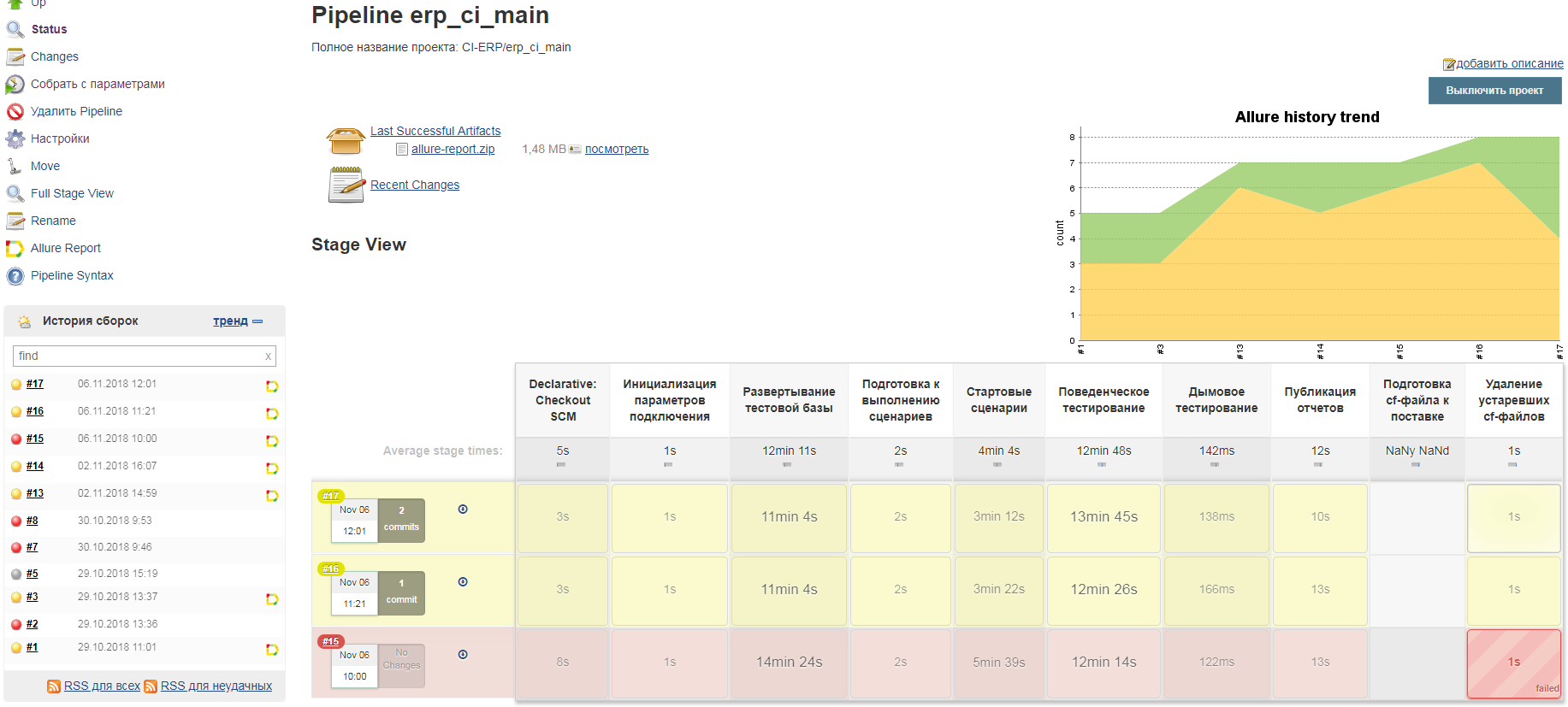
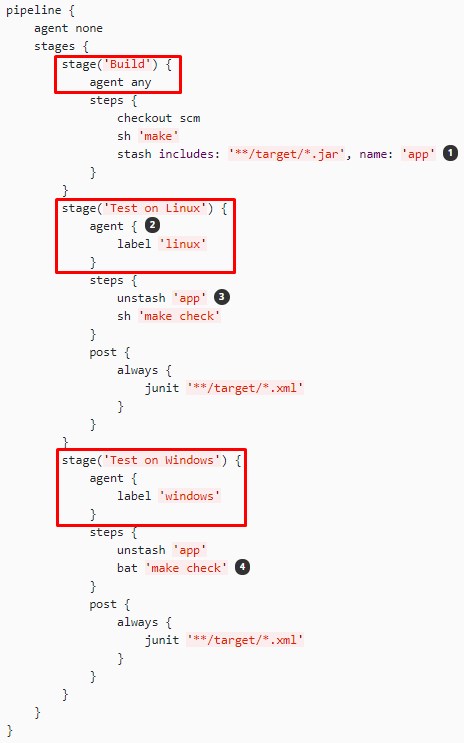
Каждый этап обладает не только именем, но и может быть назначен для исполнения на узел с определенной меткой. За счет этого можно организовать выполнение разных этапов на разных компьютерах. Вот пример из документации https://jenkins.io/doc/book/pipeline/jenkinsfile в котором демонстрируется как один из этапов назначить на узлы с операционной системой Linux а другой на узлы с операционной системой Windows:
Шаги - steps - в отличие от этапов элементы "подневольные". Они всегда выполняются в рамках своего этапа, и по умолчанию всегда последовательно. Каждый шаг - это отдельный оператор или вызов функции.
Для того чтобы организовать из шагов настоящий алгоритм, нужно включить их в специальный блок script. В этом случае можно будет помещать шаги в условные операторы и циклы.
Отдельные выполненные операторы также имеют не только текстовое представление в логах, но и визуальное представление. Если кликнуть мышкой по отдельному блоку (квадрату) с этапом сборки, то можно вызвать просмотр логов выполнения в графическом виде:

Данные о каждом операторе можно развернуть и увидеть какой строкой кода он был представлен. Хотя на практике при работе с объемными этапами, состоящими из множества вызовов функций и операторов, это совсем неудобно и как правило проще прочитать текстовые логи.

Переменные и операторы
Groovy позволяет объявлять как общие для всего скрипта переменные, так и переменные внутри отдельных блоков.
При этом переменные, объявленные для всего скрипта хранятся на мастер узле Jenkins на сервере. А переменные, объявленные внутри отдельных блоков создаются и хранятся на стороне подчиненных узлов. Дело в том, что отдельные этапы сборки (элементы блока Stages) могут выполняться на разных компьютерах, на разных подчиненных узлах, если их об этом "попросить" (указывать узел-компьютер на котором требуется выполнить этап сборки можно на уровне самого этапа). При этом переменные, объявленные для всего скрипта, должны быть доступны на всех машинах.
Здесь, как и в случае платформы 1С, вмешивается клиент-серверное взаимодействие. Переменные объявленные для всего скрипта должны относиться либо к примитивным типам, либо представлять собой Java-объекты, поддерживающие сериализацию/десериализацию, что необходимо для их передачи между разными машинами. В нашем случае в этих переменных будут храниться главным образом объекты класса String - строки. Поэтому проблем с сериализацией возникать не будет.
def baseDesignerCommand
def baseEnterpriseCommand
def baseDesignerCommandWithAuth
def baseEnterpriseCommandWithAuth
def baseEnterpriseCommandWithAuthRu
def timeoutBeforeDeleteTestDatabase
pipeline {
agent { label 'ubuntu_interactive' }
stages {
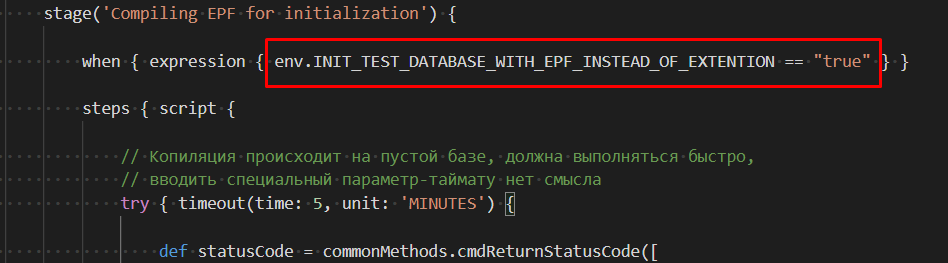
stage('Compiling EPF for initialization') {
steps { script {
def statusCode = commonMethods.cmdReturnStatusCode("текст команды")
commonMethods.cmdReturnStatusCode("tail -n 5 ${outFileName}")
def outputLine = commonMethods.getLastLineOfTextFileLowerCase(outFileName)
def success = (statusCode == 0) && outputLine.contains("import completed")
commonMethods.assertWithEcho(success, "EPF was not compiled", "EPF was successfully compiled")
}}
}
Объявляя переменную на уровне всего скрипта за пределами блока pipeline (в начале файла) обязательно использовать ключевое слово def . После этого она становится доступна для использования во всех блоках скрипта. Для переменных, создаваемых внутри отдельных блоков необходимости в этом нет. Переменная будет создана автоматически, когда ей впервые присваивается значение. Но здесь важно понимать, что если внутри блока первое обращение к переменной происходит без ключевого слова def, то создается "глобальная" переменная, которая будет доступна и из всех следующих блоков.
На практике возможность объявлять глобальные переменные в отдельных блоках очень неудобна и только ведёт к путанице. Поэтому лучше взять за правило выносить объявление таких переменных за блок pipeline в начало файла (как в примере кода выше) . Это простое правило позволит сэкономить много времени на поиске ошибок и отладке, которая в Jenkins является непростой задачей.
На скриншоте ниже в качестве демонстрации глобальная переменная создается внутри блока stage-steps-script:
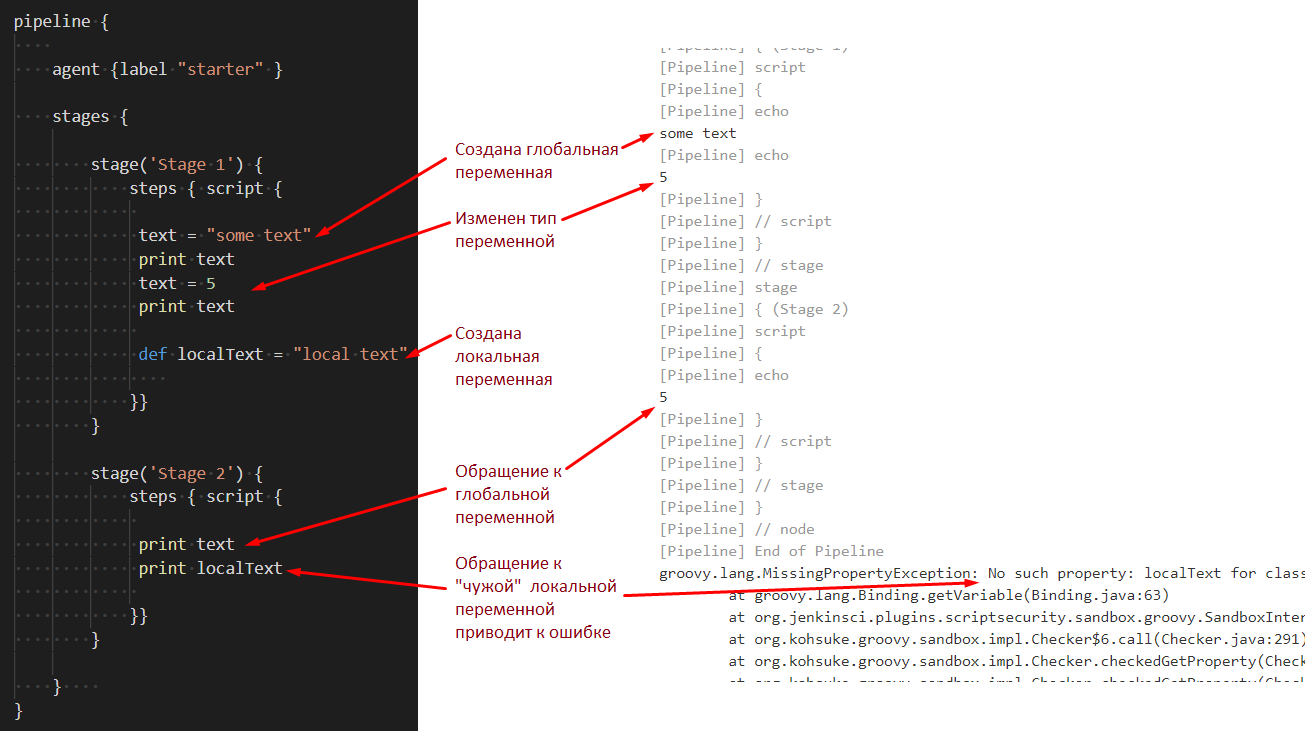
Тип переменной при создании указывать не обязательно. При этом даже если указать его, то затем тип можно изменить. Указание типа у переменной при ее создании в отдельном блоке приводит к созданию именно локальной переменной даже если не указывать слово def перед ней (запоминать такие детали ни к чему, это просто подробности для въедливых читателей):
В конце каждого оператора не ставится точка с запятой. С одной стороны это удобно. Новая строка - это новый оператор. В конце концов нет уже ни одного человека, который в здравом уме записывает несколько операторов в одной строке кода. По крайней мере хочется в это верить ;)
Но при записи логических операций и конкатенаций строк такой подход может ухудшать читаемость. Например мы не хотим записывать длинное условие в одной строке и хотим разнести его на несколько строк. В этом случае нельзя записать выражение как это принято в 1С (да и в ряде других языков):
// неправильно!!!
def success = (statusCode == 0)
&& (firstLineIsCorrect)
&& (lastLineIsCorrect)
Придется подсказать Jenkins , что оператор не заканчивается в строке, для чего нужно указать логические операции (или знаки +, -, *) в конце строки:
// правильно
def success = (statusCode == 0) &&
(firstLineIsCorrect) &&
(lastLineIsCorrect)
Создание и вызов функций
При создании функций также как и при объявлении переменных, можно как указывать типы параметров и возвращаемого значения, так и не делать этого:
def concatStringsFromArray(ArrayList command, boolean addSpaces = false) {
// ………………………….
return resultStr
}
def cmd(command) {
// ………………………….
}
Но в отличие от переменных, если указать тип входного параметра метода явно, то вызвать этот метод с параметром другого типа уже не получится.
Придерживаясь традиций предков и заветов природы, если программист может о чем-то не думать ради повышения надежности кода, то обычно без давления со стороны он об этом не думает ;)) Поэтому в примерах пайплайнов, втречаемых в сети, почти никогда не встречается типизация переменных и входящих параметров функций. О типах переменных и параметров, как и в коде на 1С, можно догадаться, прочитав код и поняв, что он делает )) В нашем репозитории эти нехорошие традиции также будут соблюдаться.
Объявляя метод, можно также указать значения по умолчанию для его параметров. В этом случае при вызове функции можно будет не указывать такие параметры.
def func( arg1, String arg2 , arg3 = "default value" ) {
print arg1
print arg2
print arg3
}
Вызывая функцию можно передавать значения параметров как в скобках, так и без скобок. Например для объявленной выше функции допустимы следующие вызовы:
func "val1", "val2" , "val3"
func("val1", "val2" , "val3")
func("val1", "val2")
Загрузка кода из репозиториев git
Весь код и данные, необходимые для выполнения пайплайнов, мы будем хранить в git-репозитории. Jenkins умеет загружать код напрямую из таких репозиториев. При этом в настройках задачи нужно указать, что код будет задаваться не в самой задаче, а браться из указанного файла из состава репозитория.
Для этого нужно зайти в настройки задачи в веб-интерфейсе Jenkins и изменить настройки:
- В поле "Definition" нужно выбрать "Pipeline script from SCM".
- Указать адрес репозитория. Это может быть общий каталог, доступный всем машинам по одному адресу, или репозиторий в облаке gitlab/github.
- Указать из какой ветки будет браться код в поле "Branches to build". Как правило имеет смысл разделять "рабочий" и "экспериментальный" код по разным веткам, поэтому на рабочем CI здесь обычно будет указана ветка "master" , а на экспериментальном ветка с другим именем, например "develop". В наших примерах такого разделения нет, поэтому можно указать ветку "master". Но на практике я бы не рекомендовал вести всю разработку в одной ветке.
- В поле "Script path" указать путь к Jenkinsfile относительно корня репозитория. Например, если Jenkinsfile находится в каталоге jenkinsfiles/main_build относительно корня репозитория, то необходимо указать путь к нему как jenkinsfiles/main_build/Jenkinsfile.
- Если репозиторий приватный или находится на корпоративном сервере, защищенном паролем, то для подключения к нему необходимо задать параметры аутентификации (Credentials). Если они еще не созданы, то добавить их можно прямо из этого поля. Вместо имени пользователя и пароля можно указать ssh-ключ доступа. Но на тонкостях аутентификации сейчас останавливаться не будем. В наших примерах используется открытый репозиторий, для которого аутентификация не нужна.
- Установить флаг "Lightweight checkout". Этот флаг очень важен, обязательно установите его. Если его не установить, то репозиторий будет целиком загружаться на мастер-ноду в каталог установки Jenkins. У нас мастер-нода находится на Windows , а каталог установки находится в C:\Program Files. Мало того что это увеличит время начала обработки файла, так еще и репозиторий окажется там, где он не нужен. Если же этот флаг установить, то Jenkins будет получать из репозитория только один файл с кодом пайплайна и сохранит его во временных файлах/оперативной памяти. Никаких лишних каталогов и репозиториев в C:\Program Files создаваться не будет.
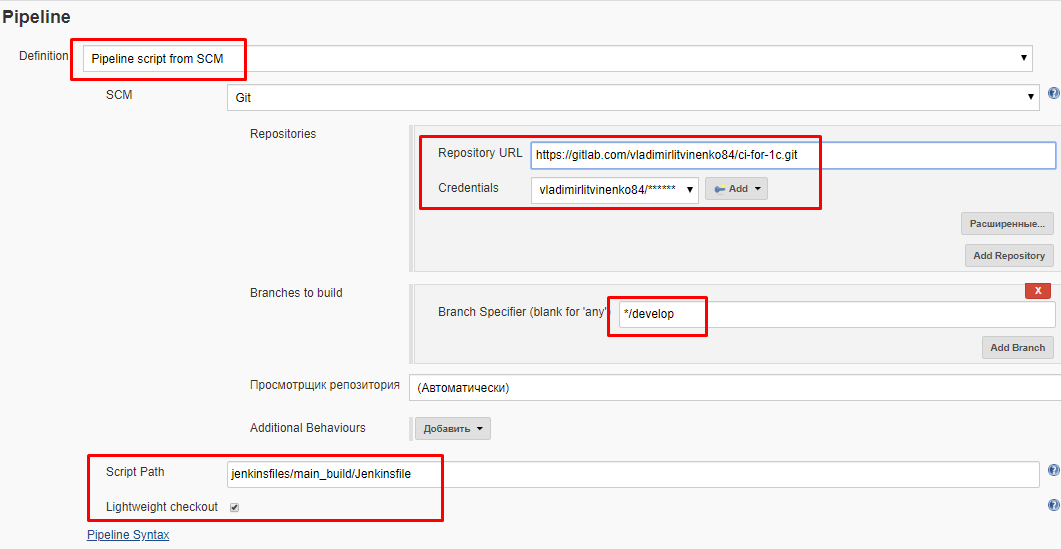
Выше приведён пример настроек для моего закрытого репозитория, который требует указания параметров авторизации - либо имени пользователя и пароля, либо ssh-ключа. Но для этой и последующих публикаций используется открытый репозиторий, поэтому параметры Credentials можно не указывать, а в качестве строки Repository URL можно указать адрес открытого репозитория на gitlab.com или github.com с которым мы сейчас работаем:
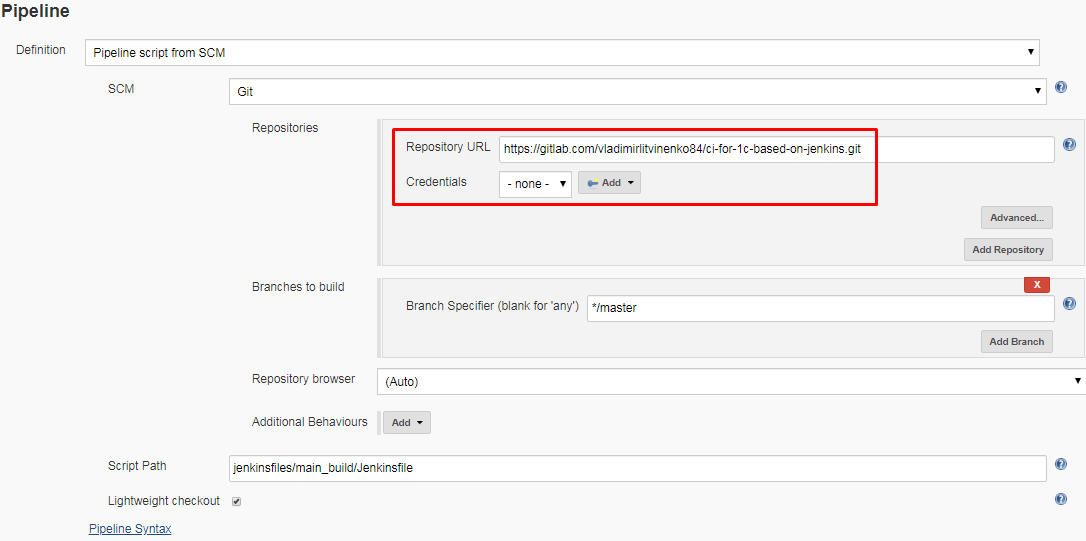
На подчиненном узле репозиторий будет извлекаться (загружаться с gitlab/github) в рабочий каталог задачи. При создании узла мы указывали у него в настройках корень удаленной файловой системы:
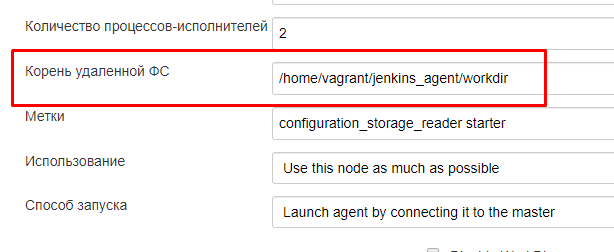
Рабочий каталог задачи представляет собой подкаталог workspace/имя_задачи, относительно этого каталога. Именно в него будет загружаться репозиторий и именно этот каталог будет становиться текущим при исполнении задачи. Если мы выполним команду pwd (вывод текущего каталога) в начале выполнения задачи, то в лог Jenkins будет выведен путь "Корень файловой системы узла/workspace/имя_задачи". Например "/home/vagrant/jenkins_agent/workdir/workspace/main_build" .
Рядом с ним также могут создаваться другие временные подкаталоги, в которые сохраняются служебные данные. Например в них сбрасываются пароли пользователей и ssh-ключи, сохраненные в Jenkins для подключения к сетевым ресурсам:
Перемещение кода пайплайна в репозиторий имеет не только плюсы, есть существенный минус.
Значительно усложняется отладка кода. Любое исправление в коде пайплайна требует сделать коммит в репозиторий и отправку его на git-сервер. Только после этого Jenkins сможет получить новую версию кода. Это приводит к следующим эффектам:
- Любое даже самое незначительное исправление в процессе отладки порождает лишний коммит в репозиторий. Таким ветка, в которой ведется разработка, замусоривается и в ней становится сложно ориентироваться.
- Часто можно внести изменение в код, но забыть сделать отправку на git-сервер. В этом случае запуск задачи с целью отладки окажется выполнен зря. Это может отнять много времени.
По этой причине
- Иногда в процессе отладки имеет смысл переключиться обратно на задание кода через веб-интерфейс задачи Jenkins, а не получение кода из git-репозитория. Это имеет смысл только в том случае, если меняется и отлаживается сам код пайплайна без других файлов в репозитории.
- Всегда имеет смысл выделить в репозитории отдельную ветку для разработки (ветку develop). А прежде чем переносить изменения в "боевую" ветку master делать объединение всех логически связанных коммитов в один - git rebase squash. Если вы начинающий разработчик CI-контура или работаете над CI в одиночку, то этого можно и не делать - научитесь или начнёте применять потом. Но если вы уже умеете работать с git и тем более работаете в команде, то это чуть-ли не обязательная практика, иначе в репозитории будет бардак.
Ранее мы уже создавали задачу connection_test и четыре другие задачи create_test_database_image, dump_storage_version_to_cf_file, starter_for_main_build и main_build. Теперь вынесем код этих задач в git-репозиторий:
- https://github.com/VladimirLitvinenko84/ci-for-1c-based-on-jenkins/tree/master/jenkinsfiles
- https://gitlab.com/vladimirlitvinenko84/ci-for-1c-based-on-jenkins/-/tree/master/jenkinsfiles
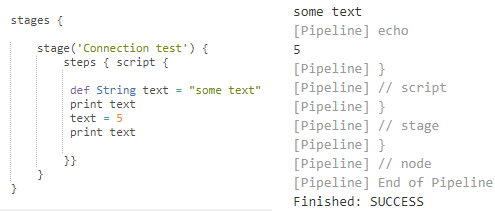
Создадим в нашем репозитории каталог jenkinsfiles в котором для каждой задачи будет создаваться отдельный подкаталог со своим собственным файлом Jenkinsfile. Код задачи connection_test предлагаю оставить без изменений (он нужен для сохранения актуальности прошлой публикации ), а в качестве кода для всех остальных задач задать такой простейший текст:
pipeline {
agent {label "ubuntu_interactive" }
stages {
stage('Connection test') {
steps { script {
print "I am alive!"
}}
}
}
}
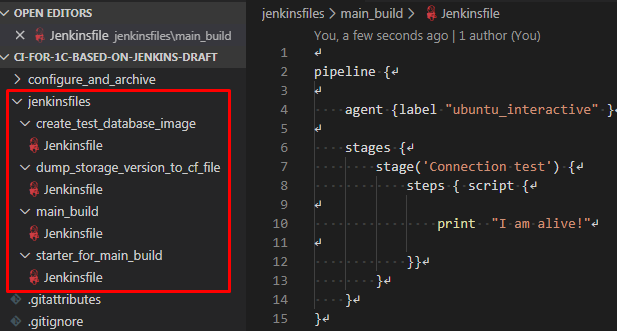
Выполним эту задачу и посмотрим какие сообщения Jenkins выводит в логи. При этом если предварительно удалить рабочие каталоги агента Jenkins в гостевой машине, то при получении изменений из репозиотрия (после того как код Jenkinsfile был получен на мастер-узле, но до того как началось выполнение первого этапа из Jenkinsfile) эти каталоги будут созданы автоматически:
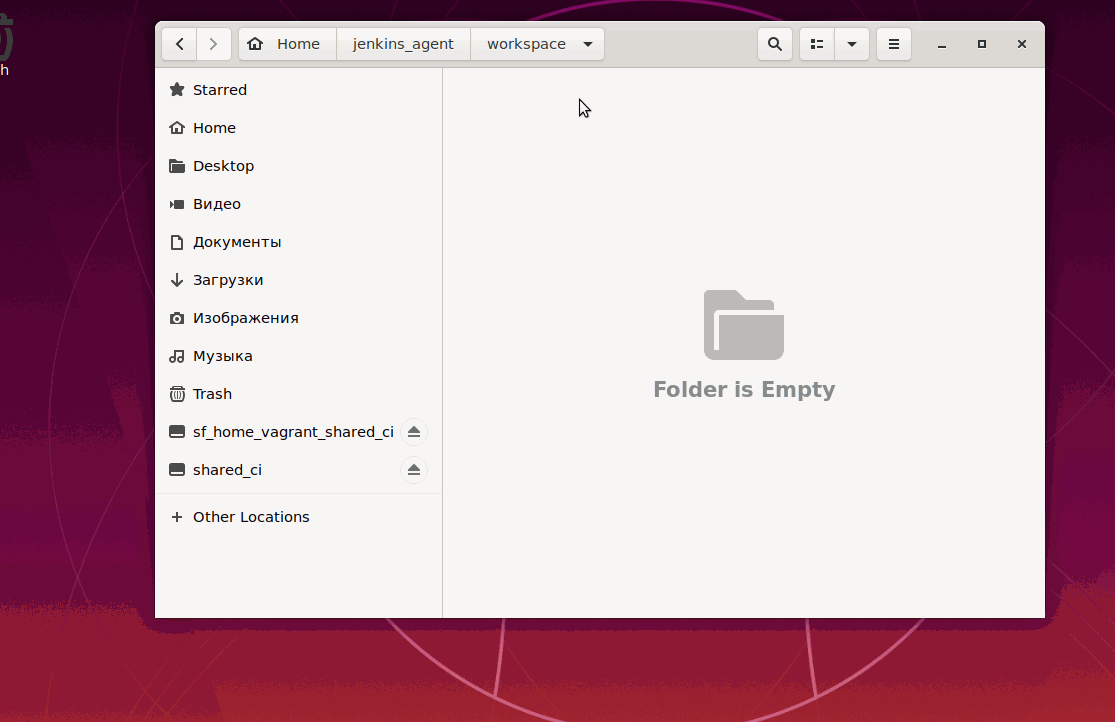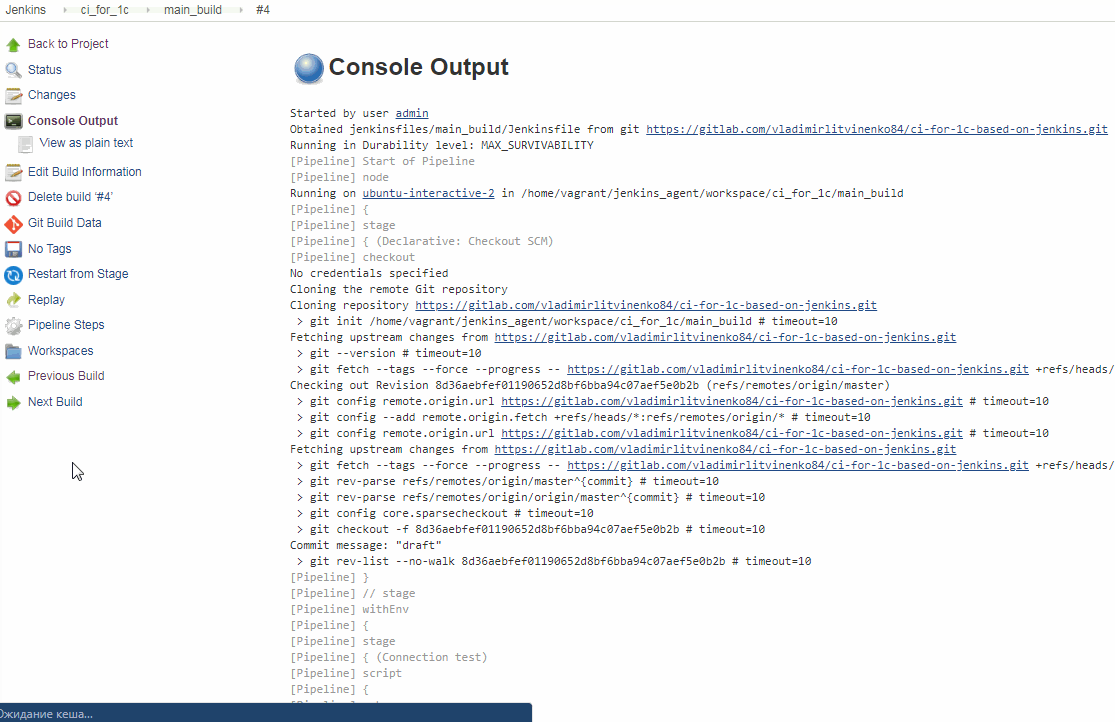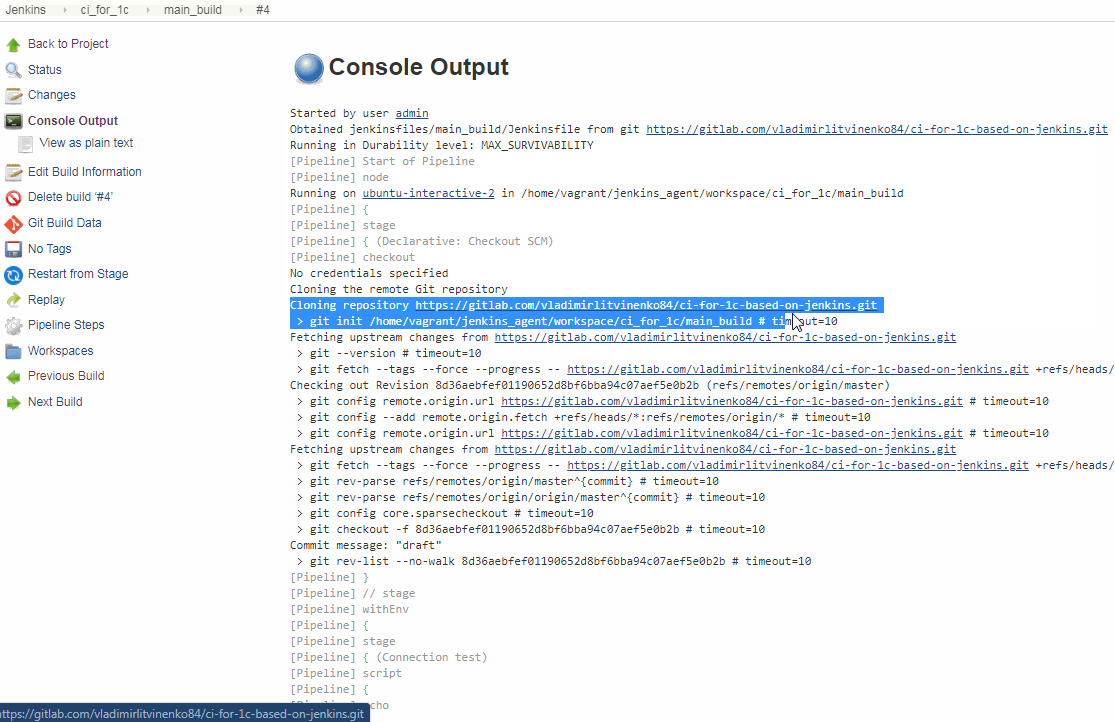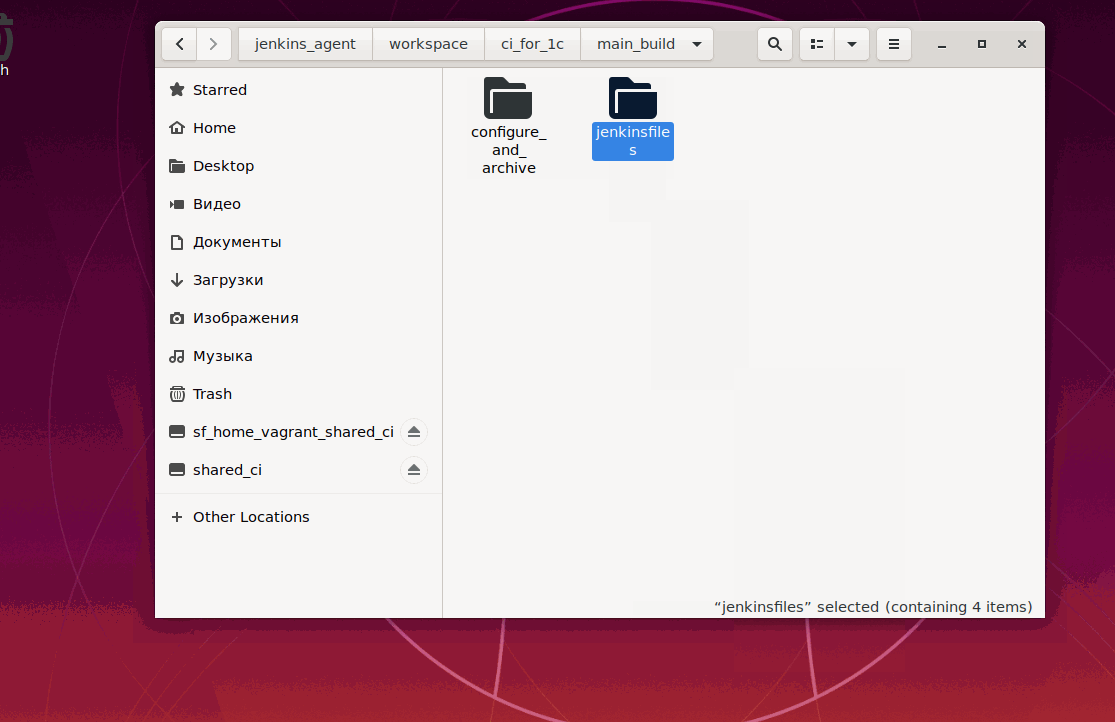
Лог вывода содержит текст
Obtained jenkinsfiles/main_build/Jenkinsfile from git https://gitlab.com/vladimirlitvinenko84/ci-for-1c-based-on-jenkins.git
еще до запуска выполнения на подчиненном узле. А уже после запуска в виртуальной машине происходит загрузка всего репозитория в рабочий каталог задачи:
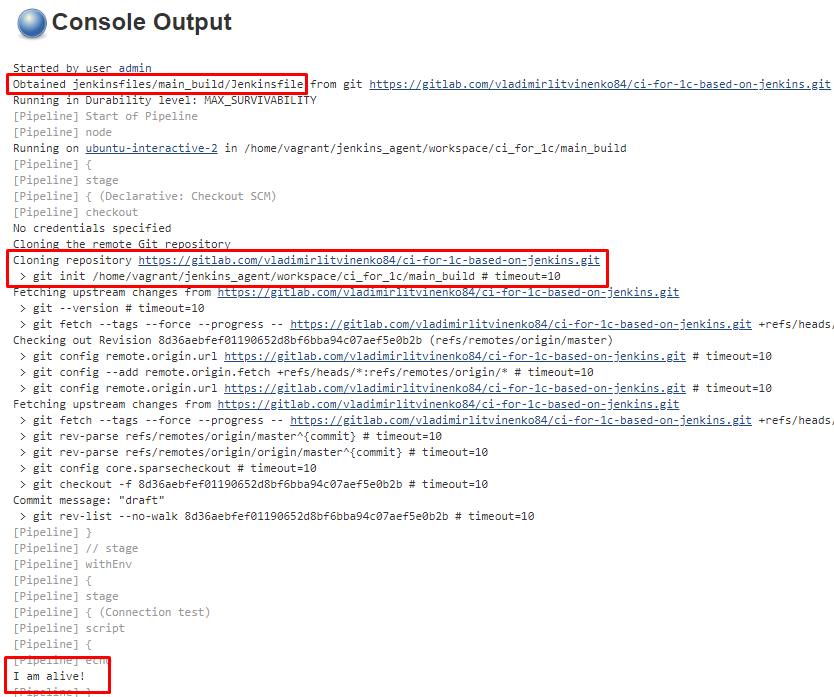
Подключение внешних модулей в cкриптах Groovy
Во всех пайплайнах нам потребуются методы общего назнчения и методы для работы с базами данных:
- объединить строки,
- выполнить команду с обработкой ее консольного вывода,
- прочитать файлы с логами платформы 1С
- создать базу данных,
- отключить сеансы 1С
- и так далее.
Дублировать эти методы в каждом Jenkinsfile было бы неправильно. Это привело бы не только у усложнению модификации этих методов, но и к многократному увеличению объема кода в каждом Jenkinsfile. И возможность сократить такое дублирование кода есть. Jenkins предоставляет два способа вынести общие методы в "общие модули" для их переиспользования в разных пайплайнах, и тем самым избежать дублирования кода.
Первый способ - это механизм Shared Libraries: https://jenkins.io/doc/book/pipeline/shared-libraries. В этом случае создается отдельный репозиторий и указывается в общих настройках сервера Jenkins. Репозиторий содержит код полноценных Groovy-классов, которые становятся доступны всем задачам, созданным на данном сервере Jenkins.
Этот способ не будет удобен для нас, так как
- Потребует создания ещё одного репозитория.
- Подходит для хранения универсальных библиотек, которые действительно имеет смысл делать общими для всех задач на сервере, а не какого-то одного набора задач.
Нарекания к этому способу есть и разработчиков на других платформах: https://habr.com/ru/company/jugru/blog/343754 (см. комментарии к публикации), поэтому иногда имеет смысл применять альтернативное решение.
Второй способ менее красив с технической точки зрения, но более прост при работе с небольшими проектами и на начальном этапе изучения Jenkins. Это просто загрузка одного модуля Groovy из другого и сохранение его в одной из переменных. После этого все методы загруженного модуля можно вызывать через точку от этой вспомогательной переменной.
Делается это так:
// Загружаем модули методом load, сохраняя их в переменных dbManage и commonMethods
dbManage = load "./jenkinsfiles/DBManage.groovy"
commonMethods = load "./jenkinsfiles/CommonMethods.groovy"
// Используем методы загруженных модулей
commonMethods.throwTimeoutException("Текст")
dbManage.publishDatabaseOnApache24(testDatabaseName)
У такого подхода есть ряд минусов:
- При загрузке необходимо указывать путь на диске к загружаемому модулю. Можно использовать путь относительно текущего каталога, но это всё равно менее удобно, чем указание имени класса при работе с Shared Libraries.
- Загруженный модуль - это не полноценный объект, не экземпляр класса, имеющий состояние . Переменные, в которых сохранен загруженный модуль, предоставляют полноценный доступ только к методам, но не к полям модуля-объекта. Здесь наиболее подходящая аналогия - общие модули в платформе 1С. Это сильно ограничивает возможности кэширования результатов обращения к методам модуля и хранения состояния. При необходимости состояние и кэшировать результаты вызовов приходится хранить в вызывающем Jenkinsfile.
В общем не стоит ждать от этого "скриптового" подхода слишком многого. Если Вы хотите более продвинутого использования - стоит изучить механизм Shared Libraries. В этом случае вам будут доступны полноценные объекты и при необходимости полноценное ООП.
Для того, чтобы метод load вернул объект-модуль, в самом загружаемом модуле обязательно в конце файла вне всех методов вернуть переменную this:
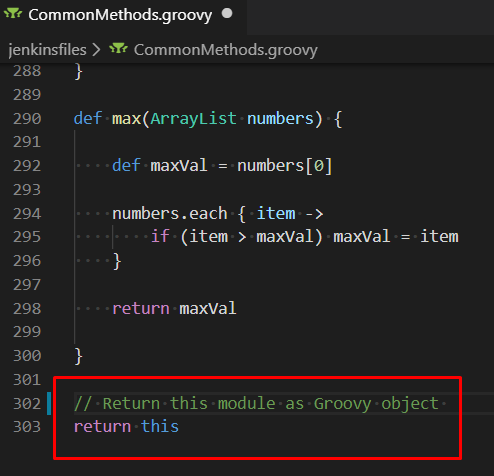
Хранение настроек выполнения задач
За время использования Jenkins я перебрал много способов хранения настроек и здесь предлагаю тот, который сейчас кажется самым удобным и экономит много сил как при разработке механизмов CI, так и при поиске ошибок, выявленных при автоматическом тестировании.
Все настройки удобно разделять на основе требований к оперативности их изменения в процессе эксплуатации рабочего CI-контура:
1) Настройки которые требуется изменять для оперативного поиска и исправления проблем на рабочем CI-контуре.
Как правило это флаги включающие или отключающие отдельные этапы. К этой же настройке можно отнести номер версии хранилища конфигураций 1С для загрузки в тестовую базу.
Такие настройки хорошо определять на уровне задачи в виде параметров самой задачи. Jenkins позволяет для каждой задачи создать параметры. Их создание и редактирование выполняется через web-интерфейс задачи. При этом для них можно задать значения по-умолчанию. Это позволит быстро запускать задачу, точечно меняя только отдельные настройки под текущие нужды. В остальных же случаях задача будет запускаться по расписанию или будучи вызванной из другой задачи со значениями по умолчанию.
-
2) Настройки, которые почти никогда не меняются на рабочем CI-контуре.
-
Как правило значения для этих настроек подбираются в ходе стабилизации работы CI. Меняться они могут часто, но только в процессе дальнейшей разработки механизмов. При этом после завершения разработки они надолго остаются неизменными на рабочем CI-контуре.
Такие настройки хорошо хранить прямо в репозитории в конфигурационных файлах. В процессе разработки их можно менять часто, делая после изменений отдельный коммит для того, чтобы эти изменения вступили в силу. Выше уже говорилось про необходимость создания отдельной ветки репозитория при таком подходе. Когда разработка и отладка завершены все сделанные изменения можно "сжать" в один коммит и отправить в основную ветку репозитория.
Для того, чтобы определить параметр выполнения задачи из интерфейса Jenkins нужно зайти на страницу задачи и установить флаг "Это - параметризованная сборка":
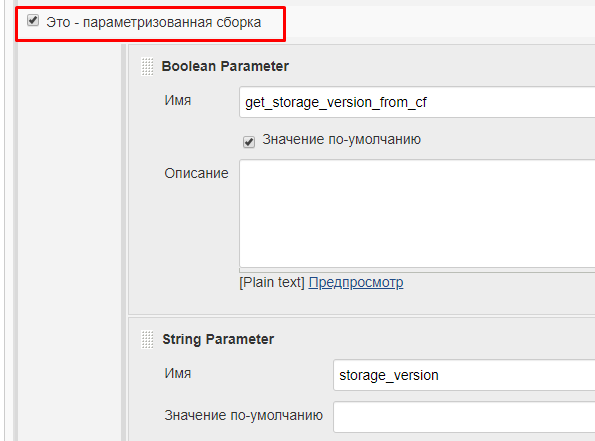
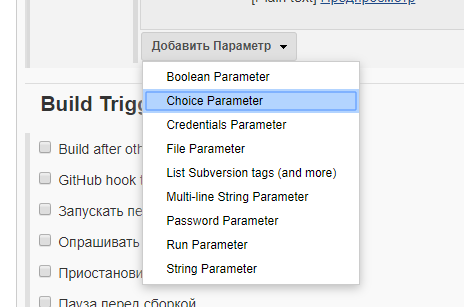
После этого можно добавить произвольное количество параметров, задав их тип и значения по умолчанию:
Теперь при запуске задачи перед тем как ее исполнить Jenkins будет предлагать задать параметры ее исполнения. Если значения по умолчанию устраивают, то достаточно будет нажать на кнопку "Собрать". Если же нужно поменять их перед выполнением задачи, то это можно сделать прямо на этой странице:
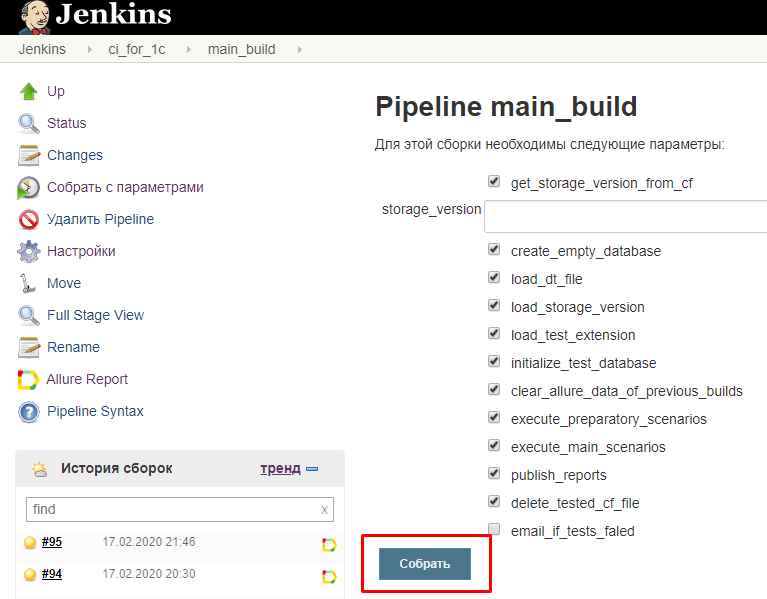
Имена параметров должны удовлетворять требованиям к идентификаторам, так как они становятся полями встроенного объекта params , к которому можно обращаться из кода в Jenkinsfile. Например это можно делать в условии выполнения этапа сборки:
Параметры, хранящиеся внутри репозитория, удобно транслировать уже не в параметры, а в переменные окружения.
Огромный плюс такого подхода заключается в том, что эти переменные окружения будут действовать не только в самом пайплайне, но и вызываемых из него командах. Например если из пайплайна нужно вызвать OneScript, то из исполняемого им скрипта на языке 1С будут доступны всё те же переменные окружения! Их не нужно будет передавать в OneScript в командной строке.
В свою очередь самый простой способ установить переменные окружения в Groovy - это выполнить команду вида
env.Имя_Переменной = "Значение переменной"
Через глобальный объект env Jenkins предоставляет доступ к переменным окружения как для чтения, так и для установки.
Установку значений можно выполнять в обычном Groovy-скрипте, загружаемом методом load, особенности которого рассмотрены выше. Это позволяет получить полностью платформонезависимый механизм установки значений переменных окружения, одинаково работающий и на Windows и на Linux. В Groovy скрипте можно использовать условные операторы и функции, что позволяет устанавливать настройки более гибко и сделать единый файл настроек, пригодный для использования и на Windows и на Linux и на рабочем сервере и на компьютере разработчика.
Например можно создать файл SetEnvironmentVars.groovy (по ссылке можно открыть полный листинг на GitHub) содержащий такой код:
def getJenkinsMaster() {
return env.BUILD_URL.split('/')[2].split(':')[0]
}
if (isUnix()) {
env.INSTALLATION_DIR_1C = "/opt/1C/v8.3/x86_64"
env.THICK_CLIENT_1C = env.INSTALLATION_DIR_1C + "/1cv8"
env.THICK_CLIENT_1C_FOR_STORAGE = env.THICK_CLIENT_1C
env.ONE_SCRIPT_PATH="/usr/bin/oscript"
} else {
env.PLATFORM_1C_VERSION = "8.3.15.1779"
env.PLATFORM_1C_VERSION_FOR_STORAGE = "8.3.14.1671"
env.INSTALLATION_DIR_1C = "C:/Program Files/1cv8"
env.ONE_SCRIPT_PATH="C:/Program Files (x86)/OneScript/oscript.exe"
env.THICK_CLIENT_1C = env.INSTALLATION_DIR_1C + "/" + env.PLATFORM_1C_VERSION + "/bin/1cv8.exe"
env.THICK_CLIENT_1C_FOR_STORAGE = env.INSTALLATION_DIR_1C + "/" + env.PLATFORM_1C_VERSION_FOR_STORAGE + "/bin/1cv8.exe"
}
// Здесь можно написать например if(env.HOSTNAME == "node1") { env.SQL_SERVER = "node2" }
env.SQL_SERVER = "localhost"
env.SQL_USER = "postgres"
env.SQL_PASSWORD = "vagrant"
Вызвав загрузку этого файла методом load мы получим переменные окружения THICK_CLIENT_1C и THICK_CLIENT_1C_FOR_STORAGE, содержащие путь к исполняемым файлам 1С в зависимости от операционной системы, на которой исполняется задача.
Можно сделать всего один такой файл для всех наших задач и производить загрузку настроек из этого файла в переменные окружения в каждом Jenkinsfile каждой отдельной задачи. Сделать это можно вызвав всю ту же функцию load, которая рассматривалась выше. При вызове этой функции с указанием пути к файлу с настройками, она инициирует выполнение всего кода модуля, находящегося вне методов. Таким образом все операторы, устанавливающие переменные окружения будут выполнены. При этом результат, возвращаемый методом load, можно даже не запоминать в переменной. Ведь всё, что нам нужно от этого файла - это установка переменных окружения, так как используем его как хранилище настроек, а не общих методов.
Таким образом в начале Jenkinsfile для каждой задачи у нас будет код следующего вида:
pipeline {
stages {
stage('Init environment') {
steps { script {
load "./jenkinsfiles/SetEnvironmentVars.groovy" // Загружаем переменные окружения (настойки)
dbManage = load "./jenkinsfiles/DBManage.groovy" // Загружаем "общий модуль"
commonMethods = load "./jenkinsfiles/CommonMethods.groovy"
Обратиться к прочитанным переменным окружения впоследствии можно в любой строке кода, в том числе в условиях выполнения этапов:
Общие методы для задач
Существует два основных подхода к разработке пайплайнов, независимо от того, какой CI-сервер Вы используете.
- Первый - использовать код пайплайнов только как механизм для вызова внешних скриптов (bat, bash, os и так далее). Таким образом сам пайплайн определяет только этапы работ и общий каркас, а всю основную работу делает скриптовый движок - PowerShell , OneScript, Python, командные файлы bash и т.д. Этот подход подходит тем, кто хочет просто быстро решить свою задачу оставаясь в рамках знакомого ему языка и используя механизмы CI сервера не как средства разработки, а как средства организации этапов сборки. В 1С этот подход очень распространен, благодаря популярности OneScript и редко встречаемого желания изучать языки, отличные от русского варианта языка 1С ;))
Этот подход позволяет быстрее начать разработку пайплайнов, но в то же время может привести к bat- / bash- подобным скриптам со сложными механизмами передачи параметров во внешние скрипты из вызывающего кода Groovy и сложно прослеживаемой логике работы пайплайнов.
- Второй - использовать возможности языка программирования, поддерживаемого самим CI-сервером. Например для Jenkins это Groovy, для Bamboo от Atlassian - это Java. Для TeamCity можно найти примеры кода на Kotlin.
Этот подход требует немного большего знакомства с механизмами CI-сервера. В то же время он позволяет получить более процедурный, алгоритмический подход к разработке пайплайнов. И скорее программировать логику, чем собирать её из различных внешних скриптов.
Также нужно учитывать, что наши узлы работают на Linux. Скорость нахождения и исправления специфичных для Linux ошибок в инструментах, заточенных под 1С, в гораздо ниже, чем ошибок, проявляющих себя в Windows (Это не простое заявление а результат наблюдения за механизмами, связанными с 1С на протяжении последних трех лет. Но наверное дальше ситуация будет улучшаться). Поэтому работая с механизмами самого CI сервера, который наоборот, пишется как правило сначала под Linux-системы, а потом тестируется под Windows, мы можем получить гораздо большую стабильность на Linux.
По совокупности этих аргументов предлагаю в наших пайплайнах Jenkisn использовать второй подход - через разработку процедур, которые можно хранить в "общих модулях" и использовать в разных пайплайнах. Кроме того, код этих процедур будет элементарен и надеюсь пригоден к дальнейшему сопровождению.
Общие для всех задач методы будут разделены на два внешних модуля - DBManage.groovy и CommonMethods.groovy. Полную реализацию методов, входящих в состав этих модулей, можно увидеть в репозитории. Здесь не имеет смысла приводить полный листинг модулей, но можно рассмотреть общий подход к их созданию.
В модуле CommonMethods.groovy разместим наиболее общие методы. К ним можно отнести методы, обеспечивающие одинаковое поведение в зависимости от операционной системы, чтобы в основных Jenkinsfile не приходилось анализировать на какой операционной системе происходит работа. Например методы, которые в зависимости от операционной системы возвращают префикс для команды экспорта переменной окружения, и путь к псевдофайлу пустого устройства (/dev/null на Linux и nul на Windows):
def exportEnvironmentVariablePrefix() {
if (isUnix())
return "export"
else
return "SET"
}
def getNullFile() {
if (isUnix())
return "/dev/null"
else
return "nul"
}
К другим методам, избавляющим от завсисомости основного кода от операционных систем относятся:
- cmdReturnStatusCodeAndStdout (command) - выполнить команду и вернуть код возврата и консольный вывод команды, даже если при выполнении команды произойдет ошибка, исключение не будет вызвано и метод вернёт результат.
- cmdReturnStatusCode (command) - выполнить команду и вернуть код возврата, если команда завершится с ошибкой, то исключения не будет и команда вернет результат.
- cmdReturnStdout (command) - выполнить команду и вернуть консольный вывод, если код возврата команды будет отличен от 0 то выполнение задачи будет прекращено с ошибкой.
- cmd (command) - выполнить команду и вернуть консольный вывод, если код возврата команды будет отличен от 0 то выполнение задачи будет прекращено с ошибкой.
- stdoutDependingOnOS() - получить стандартный поток вывода в зависимости от типа операционной системы.
- getTempDirecrotyDependingOnOS() - получить путь к каталогу временных файлов в зависимости от типа операционной системы.
Важным методом является метод чтения файлов UTF-8 без BOM символа. 1C всегда добавляет в начало своих логов символ BOM, а у Java бывают проблемы с чтением таких файлов. В Jenkins они особо выражены, из-за ограничений работы с объектами Java, предназначенными для обработки файлов.
Одним из самых простых способов корректно обработать такой файл с логами 1С в Jenkins является использование утилиты sed и получение от него консольного вывода через метод cmdReturnStdout.
def readFileWithoutBOM(fileName) {
def text = cmdReturnStdout("sed '1s/^\\xEF\\xBB\\xBF//;1s/^\\xFE\\xFF//;1s/^\\xFF\\xFE//' '${fileName}'")
return text
}
В этом же модуле (CommonMethods.groovy) находятся методы для получения системной информации и управления процессами:
- killProcessesByRegExp(regexp) - завершить процессы по заданной маске (по заданному регулярному выражению), сейчас метод предназначен только для Linux.
- hostname() - получить имя хоста.
В модуле DBManage.groovy разместим методы для управлением базами 1С и PostgreSQL. В дальнейшем этот модуль будет часто использоваться для развёртывания баз и настройки окружения для тестирования. Сейчас важно обратить внимание, что именно этот модуль заменяет для наших задач библиотеки OneScript. Если вы знакомы с функционалом этих библиотек, то работа методов этого модуля будет Вам сразу понятна.
Интересными также могут показаться возможности этого модуля по публикации баз 1С на сервере Apache. Например в нем есть метод для автоматической публикации базы 1С на веб-сервере с помощью утилиты webinst, входящей в поставку платформы 1С. Метод размещения default.vrd с настройками публикации SOAP и HTTP-сервисов в каталоге www-data. И другие подобные методы:
def publishDatabaseOnApache24(databaseName, user = null, password = null) {
def connectionString = "Srvr=${env.CLUSTER_1C_HOST}:${env.CLUSTER_1C_MANAGER_PORT};Ref=${databaseName};"
if (user != null)
command += "usr=\"${user}\";"
if (password != null)
command += "pwd=\"${password}\";"
commonMethods.cmdReturnStatusCode("rm -rf /var/www/${databaseName}/*")
def command = "sudo ${env.INSTALLATION_DIR_1C}/webinst -apache24 -wsdir ${databaseName}
-dir \"/var/www/${databaseName}\" -connStr \"${connectionString}\""
commonMethods.cmd(command)
}
def placeDefaultVrdToPublishDirectory(databaseName, pathToSourceDefaultVrdFile) {
def destinationFile = "/var/www/${databaseName}/default.vrd"
commonMethods.cmdReturnStatusCode("sudo rm -f ${destinationFile}")
commonMethods.cmd("sudo cp ${pathToSourceDefaultVrdFile} ${destinationFile}")
commonMethods.cmd("sudo chown usr1cv8:www-data ${destinationFile}")
}
Большая часть методов для управления базами 1С работает с привлечением утилиты RAS и RAC. Например метод, запрещающий выполнение регламентных заданий в заданной базе выглядит следующим образом:
def forbidScheduledJobsViaRas(rasHostnameOrIP, rasPort, clusterName,
databaseName, databaseUser = "", databasePassword = "") {
def clusterId = clusterIdentifierFromRAS(rasHostnameOrIP, rasPort, clusterName)
def databaseId = databaseIdentifierFromRAS(rasHostnameOrIP, rasPort, clusterId, databaseName)
def command = "${env.INSTALLATION_DIR_1C}/rac ${rasHostnameOrIP}:${rasPort} infobase --cluster ${clusterId} update
--infobase=${databaseId} --infobase-user=\"${databaseUser}\" --infobase-pwd=\"${databasePassword}\"
--scheduled-jobs-deny=on"
commonMethods.cmd(command)
}
От сервера RAS он получает идентификатор кластера и базы данных и затем выполняет команду запрещающую регламентные задания. Есть аналогичные методы для
- завершения сеансов,
- удаления и создания новой базы данных на PostgreSQL,
- получения номера последней версии хранилища 1С из отчета по хранилищу
- и так далее.
Таймауты операций и обработка ошибок
При работе с 1С многие операции могут "зависать" или прерываться из-за непредвиденного появления диалоговых окон.
Например, характерной ошибкой может быть сбой запуска внешней обработки инициализации базы. Если в процессе её исполнения произойдет ошибка, то команда завершения работы клиента 1С не будет выполнена:
- Мы хотим запустить внешнюю обработку в 1С вызвав режим ENTERPRISE с ключем \EXECUTE, но так чтобы после завершения операций обработка закрыла клиента 1С.
- В процессе работы обработки возникает исключение, появляется диалоговое окно с сообщением об ошибке. Обрабатывать все исключения будет не вполне корректным решением - это может скрыть существующую ошибку инициализации базы.
- Клиент 1С не завершает свою работу, а Jenkins продолжает его бесконечно ждать.
Если этом и множестве других подобных случаев не предпринять каких-то действий, то этап пайплайна, запускающий внешнюю обработку, не завершится никогда. Подключившись к виртуальной машине при этом можно будет увидеть зависшее окно с сообщением об ошибке.
Чтобы дать какой-то операции определенное время на исполнение и автоматически прервать её по истечению этого времени, надо воспользоваться плагином TimeoutStepExecution. Он входит в состав стандартных плагинов Jenkins и отдельно устанавливать его не нужно. Чтобы задействовать этот плагин достаточно обернуть операцию, длительность которой мы хотим ограничить, в следующее выражение:
try { timeout(time: env.TIMEOUT_FOR_CREATE_EMPTY_DT_STAGES.toInteger(), unit: 'MINUTES') {
// Выполнение длительной операции
}}
catch(FlowInterruptedException excp) { // Возник таймаут или операция была прервана вручную
if (commonMethods.isTimeoutException(excp))
commonMethods.throwTimeoutException("${STAGE_NAME}")
}
Время таймаута можно задавать константой или переменной. Например в приведенном примере время читается из переменной окружения TIMEOUT_FOR_CREATE_EMPTY_DT_STAGES.
Плагин выбрасывает исключение с типом FlowInterruptedException. Но проблема в том, что то же самое исключение возникает если выполнение задачи было прервано вручную (нажатием на крестик при выполнении задачи):
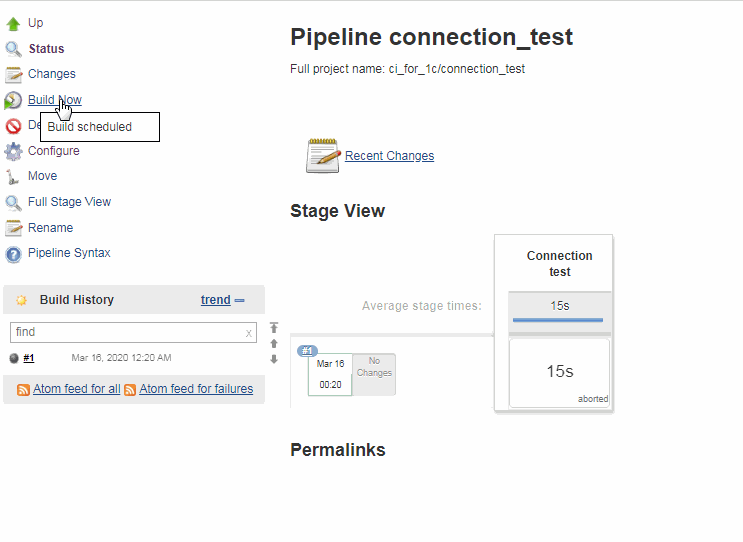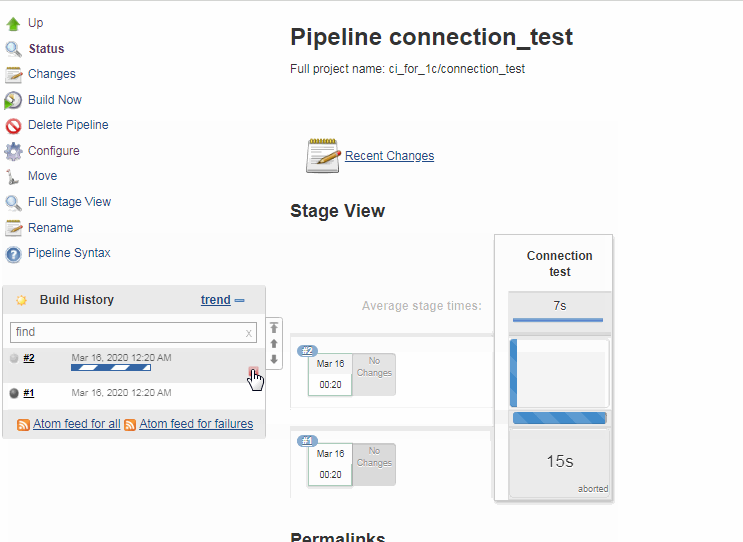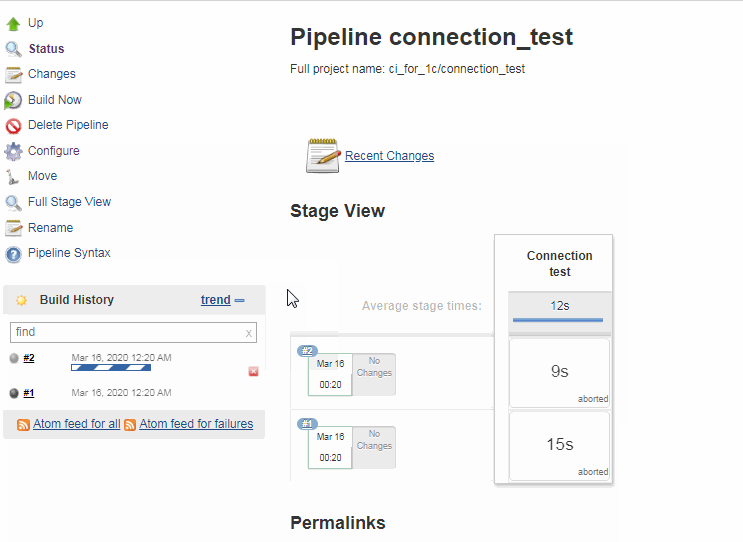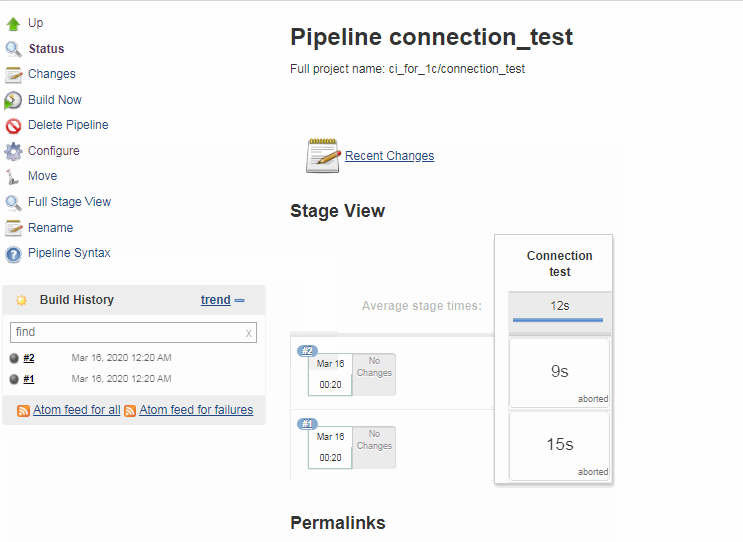
Нам необходимо отличать таймаут операции, являющийся ошибкой, от ручного прерывания. Если операция прервана пользователем, то это в целом нельзя считать ошибкой, а таймаут напротив нужно считать ошибкой и оповещать администратора системы. К сожалению сам плагин не даёт простой возможности отличить таймаут от прерывания пользователем.
Для решения этой задачи применим два вспомогательных метода из модуля CommonMethods. Один из них будет анализировать причины ошибки, ища в них признаки того, что ошибка вызвана плагином TimeoutStepExecution. Второй - выбрасывать исключение с текстом, который затем можно отправить на почту администратору системы:
def isTimeoutException(excp) {
result = false;
excp.causes.each { item ->
if ("${item}".contains("org.jenkinsci.plugins.workflow.steps.TimeoutStepExecution"))
result = true;
}
return result
}
def throwTimeoutException(stageName) {
error "TIMEOUT ON STAGE '${stageName}'"
}
Сама отправка оповещения может располагаться в специальном завершающем блоке пайплайна post. В этом блоке можно обработать успешное завершение, отмену или завершение с ошибкой. В нашем случае здесь размещается обработчик ошибки, который отправляет письмо на почту, заданную в настройках нашего репозитория:
post {
failure {
script {
commonMethods.emailJobStatus ("BUILD FAILED")
}
}
}
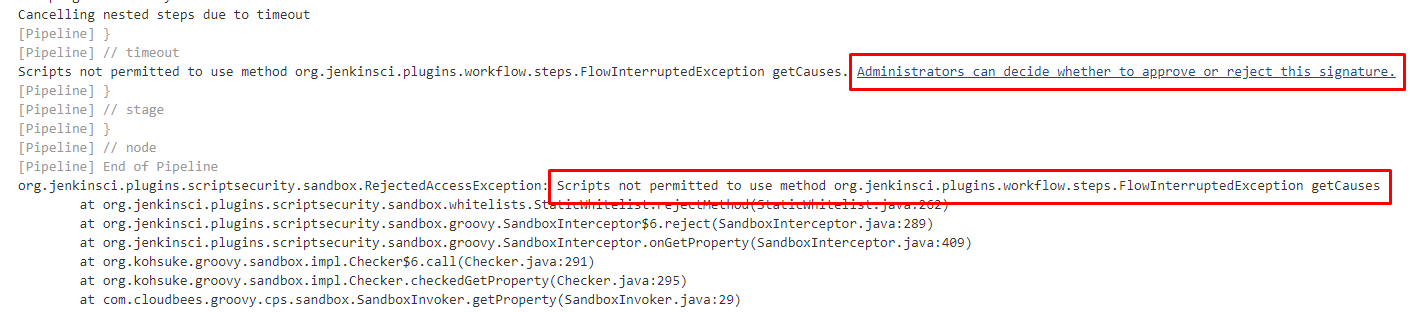
Однако это ещё не всё. В коде мы пытаемся выполнить итерацию по причинам возникновения исключения: excp.causes. Это одна из тех операций, которые с точки зрения Jenkins считаются небезопасными - мы заглядываем во внутренности объектов, и пытаемся узнать то, что знать нам "не положено" )) К сожалению, это единственный известный мне метод, позволяющий отличить таймаут от прерывания действий пользователем. Он работает и других примеров в сети я не нашёл.
Если сейчас установить таймаут для операции и дождаться связанного с ним исключения, то вместо корректной обработки таймаута мы получим ошибку. Вместе с сообщением об ошибке Jenkins предложит нам "точечно" разрешить исполнение небезопасного метода для этого пайплайна и даже выведет в логи выполнения задачи ссылку, пройдя по которой это можно сделать :
Ограничения, заложенные разработчиками Jenkins во многих случаях оправданы при работе в открытой небезопасной среде. Логи сборки могут быть открыты и введены в публичный доступ, и поэтому Jenkins при настройках по умолчанию пытается всячески ограничить пайплайн от вывода в них информации о внутреннем содержимом объектов. Однако очень часто ограничения могут показаться параноидальными. Дело в том что никаких стандартных "профилей безопасности" Jenkins не предоставляет и действует по принципу "всё запрещаю" или "всё разрешаю". Например неожиданно может оказаться, что проверить пуста ли строка через специально предназначенный для этого метод isEmpty() нельзя ;))
Наш CI-контур будет работать в изолированной среде, поэтому такие параноидальные настройки безопасности нам не нужны. И Jenkins предоставляет возможность их отключить. В первой части мы уже выполнили одну из необходимых для этого настроек - добавили параметр -Dpermissive-script-security.enabled=true при запуске главного Java-процесса Jenkins на хостовой машине. Эта настройка не работает сама по себе. Она включает плагин "Permissive Script Security", который необходимо установить.
Установку всех необходимых плагинов имеет смысл выполнять сразу на этапе первоначального конфигурирования Jenkins. Но ранее мы пропустили этот этап, чтобы не перегружать непонятной информацией предыдущие публикации. Поэтому выполним установку сейчас. Для этого нужно перейти в раздел управления плагинами:
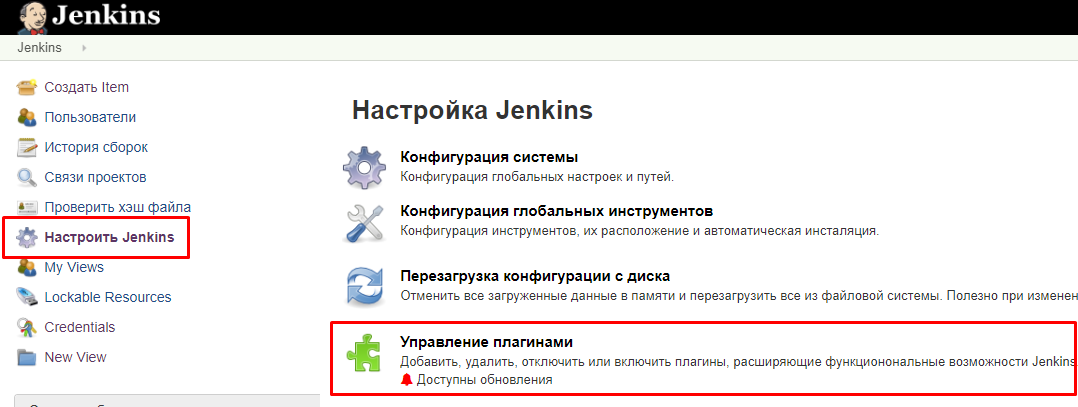
и найдя нужный плагин в списке доступных отметить его флажком.
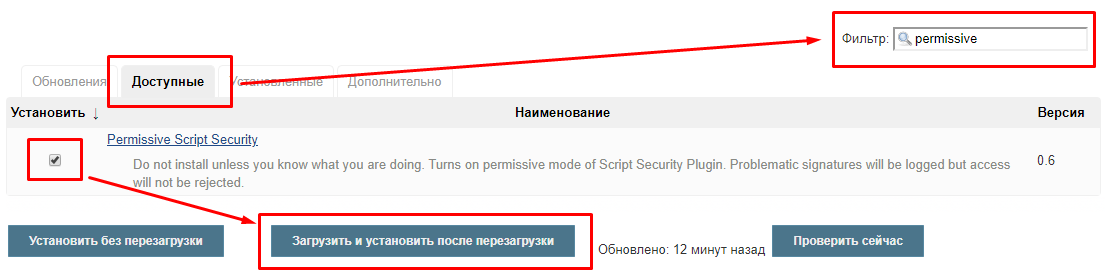
После чего нажать кнопку "Запустить и установить после перезагрузки". Этот плагин требует перезапуска процесса Jenkins на хостовой машине, так как он работает совместно с рассмотренным ранее параметром запуска службы Jenkins, применяемым при её запуске.
После перезапуска службы Jenkins обработка таймаута по прежнему будет приводить к предупреждению о выполнении небезопасного метода, но связанное с этим исключение больше не будет возникать и мы будем получать корректное сообщение, о том, что превышен таймаут операции:
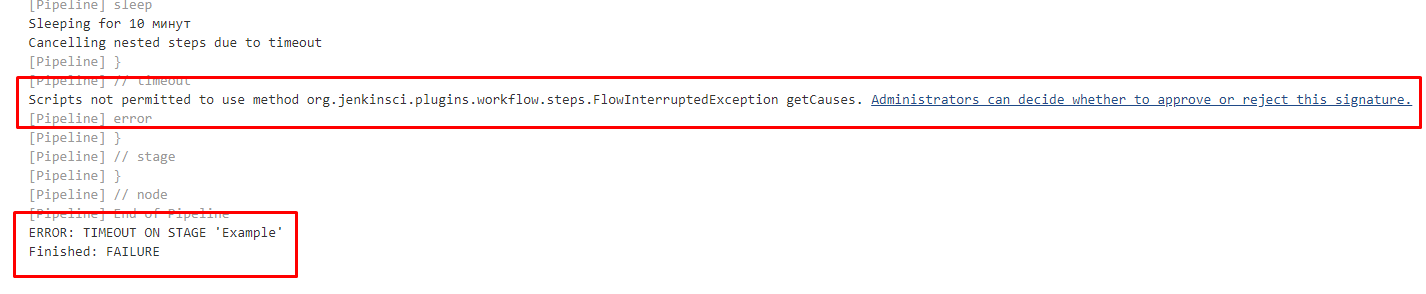
Что же, теперь репозиторий пополнен всем необходимым для решения более "прикладных" с точки зрения тестирования задач и можно приступить к наполнению его кодом, непосредственно решающим задачи тестирования.
Вступайте в нашу телеграмм-группу Инфостарт