





Предыдущие и будущие статьи:
- Часть 1. RabbitMQ
- Часть 2. Docker
- Часть 3. Журнал регистрации в ElasticSearch
- Часть 4. NoSQL (MongoDB, Redis)
- Часть 5. Обмен с 1С через HTTP-сервисы
- Часть 6. Докеризация, Начальная оркестрами, CD\CI
Видел на этом ресурсе, как некоторые выгружают журнал в файлы, потом специальной утилитой эти файлы парсят и помещают в ElasticSearch. Видел, как из таблицы СУБД с журналом регистрации выбирались записи для ElasticSearch. У меня есть своя идея. В этой статье мы воспользуемся функцией глобального контекста ВыгрузитьЖурналРегистрации(), а полученный XML-файл отправим в прослойку через HTTP-запрос методом POST. На стороне прослойки распарсим файл и передадим полученную структуру в ElasticSearch. В итоге посмотрим полученный результат в веб-интерфейсе Kibana
Для тестирования делаем обработку с отборами по датам для журнала и командой отправки.
Запускал все это дело в демо ERP на Платформе 8.3.16.1502
Для парсинга XML в прослойке я воспользовался пакетом "github.com/beevik/etree"
А для работы с ElasticSearch - пакетом "github.com/olivere/elastic"
В настройки прослойки вывел адреса ElasticSearch и имя индекса

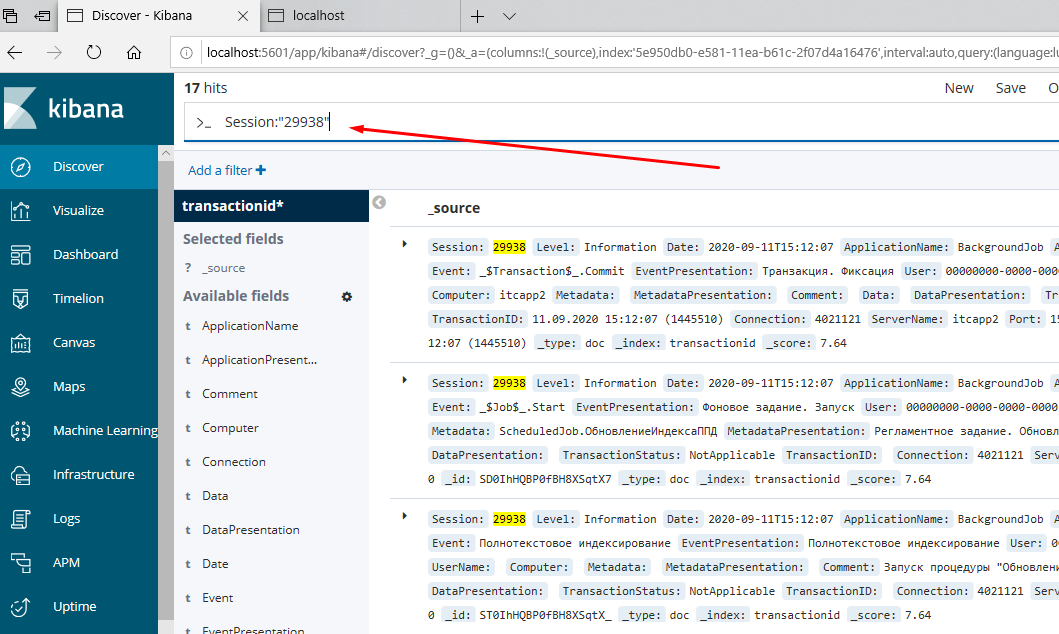
Видим, что данные пришли в ElasticSearch, накладываем какой-нибудь отбор
Исходники 1С обработки и прослойки на GitHub https://github.com/dmitry-msk777/Connector_1C_Enterprise
ОБНОВЛЕНИЕ 06.10.2020
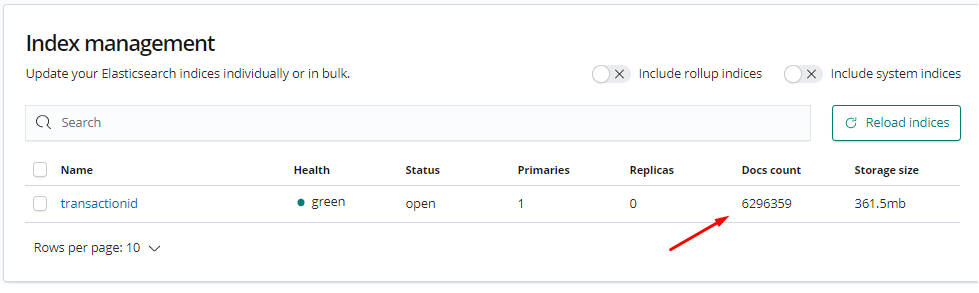
Протестировал загрузку на файле журнала 2GB - 2 000 000 записей, переписал алгорим парсинга XML под функцию xml.Unmarshal, а запись в ElasticSearch под bulk по 10 000 записей за раз.
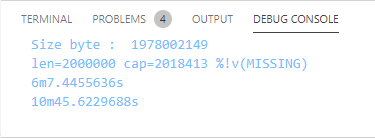
Производительность стала приемлемой на рабочем компьютере с 8GB и простеньким процессором: парсинг файла 6 минут, загрузка в Elastic 10 минут.
Обнаружил также проблему у функции глобального контекста ВыгрузитьЖурналРегистрации() если в параметр МаксимальноеКоличество задавать число меньшее 10 000, то он все равно будет всегда грузить 10 000. Узнал я это когда начал парсить выгружаемые файлы. В СП информации этой нет, в методической информации тоже нет. В начале я решил, что этот параметр не работает, когда вместо 50 записей, которые я хотел выгрузить, в XML оказалось 10 000
ОБНОВЛЕНИЕ 11.10.2020
Для файлов XML при отправке в прослойку добавлено zip-сжатие, это позволило например уменьшить файл с данными с 494MB до 32МБ

Также запись данных в прослойке разбита на потоки по числу процессоров, паралельность дает ускорение с увеличением числа записей.
Вступайте в нашу телеграмм-группу Инфостарт