







Коллеги, любите ли вы Технологический Журнал Платформы 1С так, как люблю его я? Нет, я серьезно. Согласитесь, бесценный инструмент! Написано о нем уже немало и, казалось бы, добавить нечего. Рассказаны и показаны все способы работы с Техжурналом. Но я всё-таки попробую продемонстрировать еще один способ анализа.
Задача
Для примера предлагаю считать что мы анализируем длительную транзакцию при проведении документа. Уже собраны события DBMSSQL, содержащие все запросы, выполнявшиеся в рамках одного сеанса и одного серверного вызова. Найдено начало транзакции (Sql='... BEGIN TRANSACTION'), конец транзакции (Sql=COMMIT TRANSACTION). Всё лишнее, выполнявшееся до начала и после окончания интересующей транзакции, отброшено. Имеем несколько тысяч записей. Нужно понять, есть ли какие-то длительные запросы, которые можно оптимизировать. Или множество одинаковых запросов, говорящих о том, что выполняются в цикле. Или большие паузы между запросами, что может говорить о длительной передаче параметров или результата запроса, а также ожиданиях управляемых блокировок или выполнении кода 1С.
Самый первый взгляд на наличие длительных событий я обычно бросаю в Notepad++, выделив событие цветом (просто щелкнув на нем или присвоив стиль). Какое-то представление этот метод дает, но, согласитесь, он не очень-то информативен. Длительность, отличающаяся на порядок, будет на одну цифру длиннее. Заметить это глазами при пролистывании простыни текста, конечно можно, но достаточно сложно. Особенно с учетом 15-миллисекундных «всплесков» (о них чуть ниже, под спойлером).
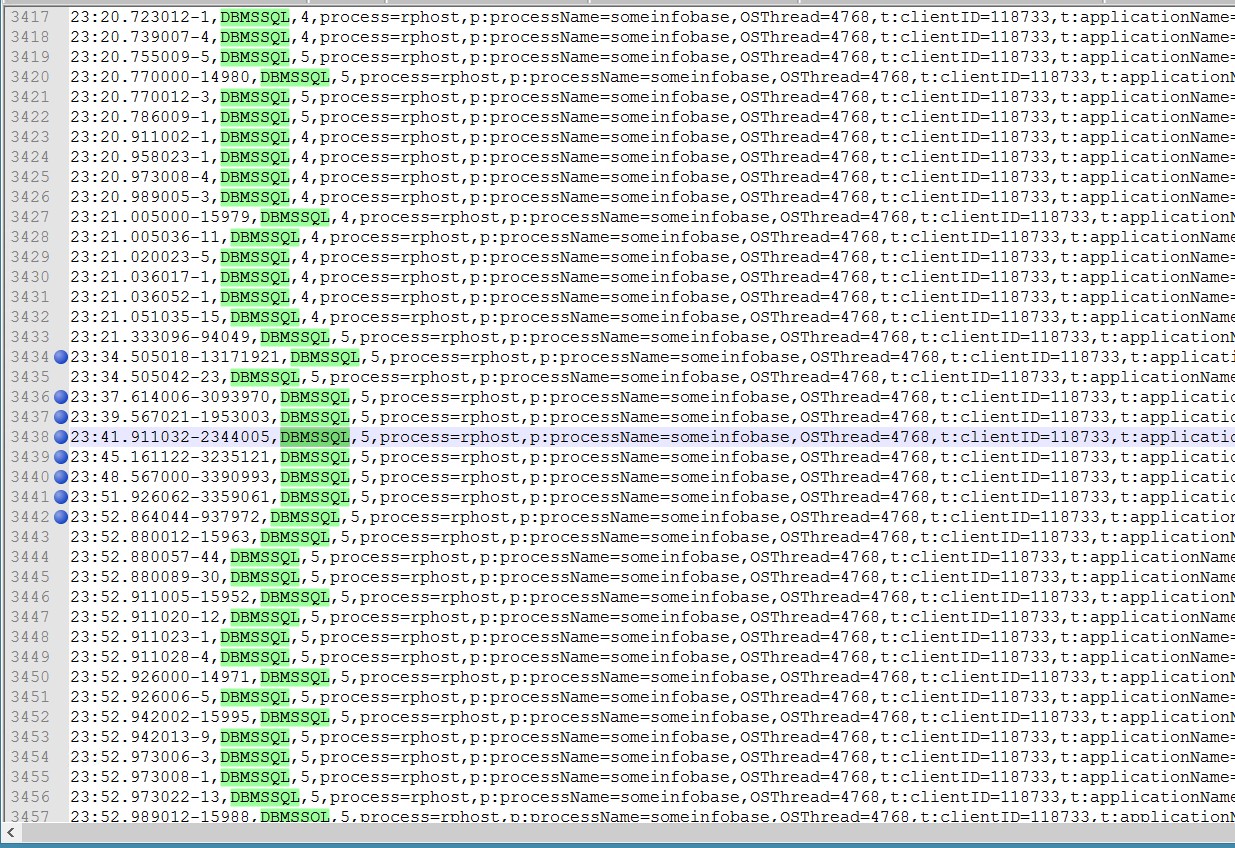
"Всплески" длительности, которые можно наблюдать в технологическом журнале для событий, обычно выполняющихся единицы или десятки микросекунд, всегда приблизительно равны 15-ти миллисекундам. Они могут быть чуть-чуть короче или чуть-чуть дольше, как видно на скриншоте выше, но всегда находятся в рамках 14-16 мс.
На самом деле эти события не выполняются дольше других. 15 миллисекунд - это дискретность используемого для технологического журнала счетчика времени в операционной системе Windows.
Механизм получения отметки времени для технологического журнала базируется на системном счетчике времени, значение которого изменяется с интервалом примерно 15 миллисекунд, и обеспечивает возрастающую последовательность отметок увеличением каждой следующей отметки времени на одну микросекунду от предыдущей.
На Linux используется другой метод (clock_gettime).
Источник: Партнерский форум
Я уже слышу, как некоторые из читателей хотят напомнить мне о том, что для подобных задач прогрессивные 1С-ники используют утилиты BASH, скрипты на Perl и прочие инструменты для обработки текстовых данных. Не сомневайтесь - всё это используется в полной мере. Но всё же обнаруженные таким образом длительные события не дают достаточно четкого понимания ситуации. Например, при такой выборке не видно окружения этих запросов, не видно собраны ли они в одном месте или разбросаны по коду, не видно пауз между запросами.
Пример получения из ТЖ списка событий, длительность которых превышает... Нет, не секунд и не микросекунд, а количество разрядов (цифр) в строке длительности. В примере - минимум 7 знаков, что соответствует длительности более 1 секунды.
cat КакойТоОбщийФайлСКучейСобытий.txt | \
grep -E -a "[0-9]{7,}," \
> СобытияДольшеСекунды.txt
Каждый раз при анализе Техжурнала, меня посещала мысль: "Вот бы было здорово, если бы можно было визуально проанализировать последовательность событий ТЖ, так же как это доступно веб-разработчикам в браузерах". Но чего нет, того нет. Разработчики Платформы такого инструмента не предлагают. И о сторонних разработках в этом направлении я ничего не слышал.

Тем не менее, желание иметь такой инструмент обострялось у меня каждый раз, когда нужно было, например, проанализировать длительную транзакцию, выявить в ней аномально длительные запросы. А может быть вовсе и не запросы? Может быть это длительное получение результата запроса? Может быть это длительная передача параметров в запрос? Может быть это длительное ожидание установки управляемой блокировки? Может быть это выполнение какого-то кода сервером приложений в промежутке между запросами? То есть меня интересовало не только длительность самих событий (например запросов), но и время пауз между окончанием одного и началом следующего события.
Периодически я обдумывал как можно было бы реализовать такую "хотелку" и пробовал различные варианты.
Среди попыток было и построение графика с помощью Excel, и реализация с помощью диаграмм 1С. Но всё что пробовал, не устраивало качеством результата. Проблема в том, что событий в анализируемом периоде, составляющем всего лишь несколько секунд, обычно очень много – по несколько тысяч. Графики, сформированные испробованными способами, были либо нечитаемыми, либо просто не формировались из-за большого объема данных.
Браться за создание полноценного приложения, отрисовывающего всё так, как я представлял себе, не было ни желания, ни возможности. Хотелось получить график вот прямо такой же (или почти) как в Chrome. И не затратить при этом больших усилий.
Реализация
В процессе поисков решения выяснилось, что в браузерах есть возможность сохранить полученные данные трассировки для последующего анализа, в HAR-файл (HTTP Archive).
А если можно выгрузить, значит должна быть и возможность чем-то открывать эти файлы. Приложений (или онлайн-сервисов) для просмотра таких файлов нашлось не очень много, но они есть. И, что самое главное, они удовлетворяли моим пожеланиям.
Ура! Решение, можно сказать, найдено! Получается, что можно трансформировать необходимые записи Техжурнала в формат HAR, и уже этот файл загрузить в какую-либо программу просмотра, или визуализатор (viewer).
Осталось дело за малым – понять как именно нужно сформировать HAR-файл.
Описание формата нашлось здесь. Следует заметить, что формат не был утвержден консорциумом W3C, и носит неофициальный характер, о чем на странице описания формата свидетельствует предупреждающее сообщение. Более того, само описание формата является не полным. Но для наших целей всё это не имеет существенного значения. Главное, что есть от чего отталкиваться и с чем экспериментировать.
Также, нашлась и XSD-схема формата, с которой можно было работать.
Очень кратко, формат основан на json и представляет собой описание событий http-сессии в текстовом виде. Набор параметров событий вполне подходит для задачи отображения событий Техжурнала.
Так как формат не является утвержденным, различные визуализаторы могут работать с ним по-разному. Один и тот же файл может прекрасно открываться одной программой и сыпать кучей ошибок в другой.
В качестве инструмента для проведения своих опытов я выбрал расширение для Chrome "HTTP Archive Viewer". Для себя я счел удобным то, что окно расширения открывается отдельно от браузера, его можно расширить на весь экран, а также можно для этого веб-приложения создать ярлык как для обычного приложения. Весь код выполняется на клиентской стороне (javascript), без обмена с веб-сервером. Кроме того, существует возможность встраивания этого инструмента в свои решения (ссылки на документацию в конце статьи).
На странице веб-приложения chrome://apps жмем правой кнопкой мыши на нужном приложении и выбираем "Создать ярлык..."

Теперь можно формировать свой файл. Принцип работы описывается буквально четырьмя пунктами:
• Для каждой строки события вычисляем время начала события;
• из XSD-схемы (которую всё-таки пришлось немного доработать) создаем XDTO пакет;
• заполняем его разобранными данными Техжурнала;
• выводим в json-формате.
Предварительно из текста удалены все "лишние" данные, находящиеся между именем события и текстом запроса или функцией. Этого можно не делать, но так визуальное отображение событий будет более информативным.

Отдельного комментария здесь заслуживает, пожалуй, лишь опция "Сортировать по началу". В технологический журнал события записываются в порядке их завершения. При выборе этой опции сортировки, вывод будет сделан в порядке начала выполнения событий.
Полученный json-текст копируем (или выгружаем-загружаем через файл) в HTTP Archive Viewer

Жмем "Load"...иииии... УРА! получилось!
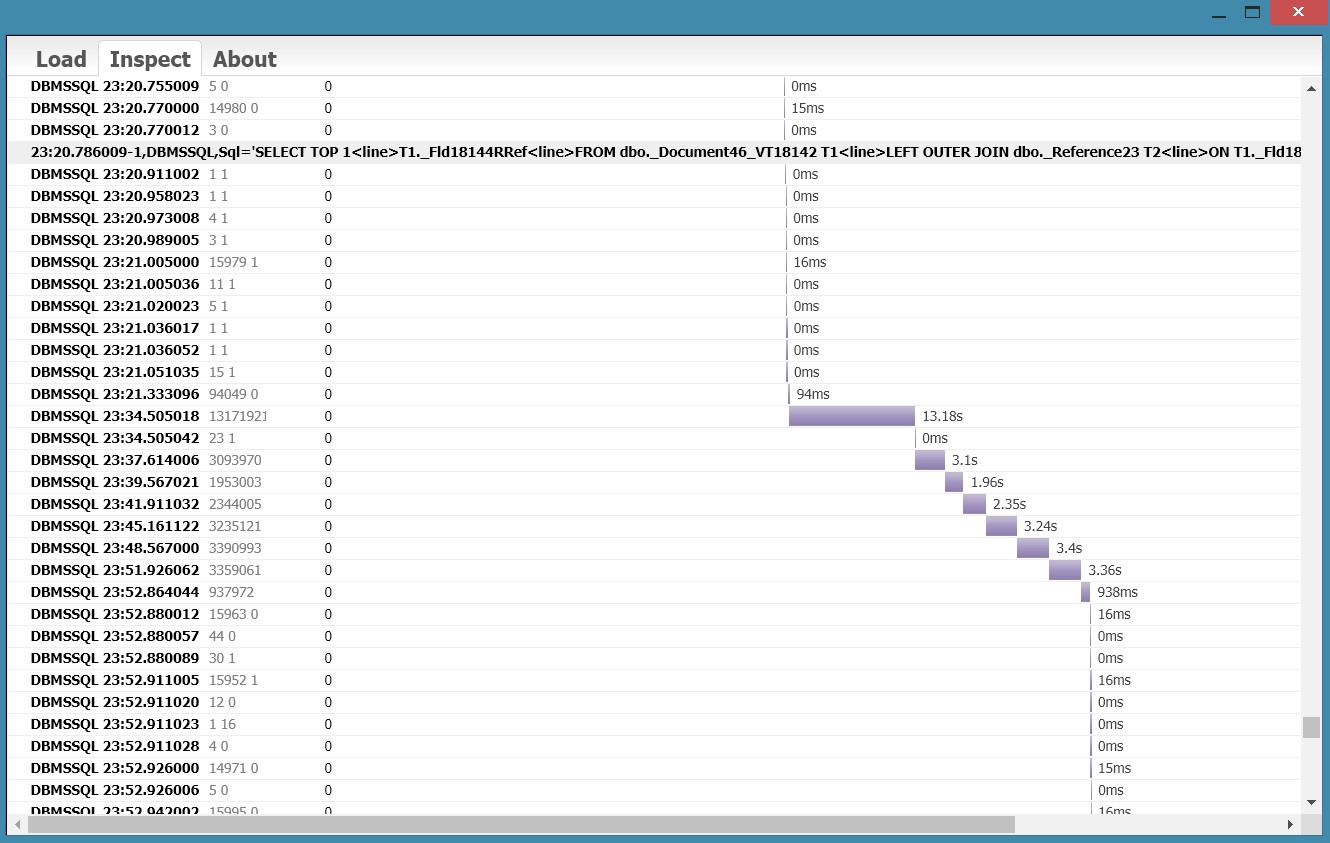
Для дальнейшего анализа, события, которые вызывают особый интерес можно найти в файле ТЖ по подстроке "время-длительность".
Как использовать
События ТЖ должны быть склеены в одну строку. Любым способом. Я делаю это bash-командами.
Пример конвейера bash-команд для поиска событий в архивированных файлах Техжурнала, с выводом каждого события одной строкой.
Значения OSThread, SessionID взяты из ранее найденного события длительной транзакции "SDBL,… ,Func=Transaction,Func=CommitTransaction".
Отбор по OSThread применен для того, чтобы собрать запросы, выполнявшиеся в рамках одного серверного вызова.
find /cygdrive/d/TechLogs*/ -regex ".*_DBMS_20201222_08.*\.zip" -print0 | \
xargs -0 -i -n 1 unzip -p {} '*/rphost*/*.log' 2>err.txt | \
awk -vORS= '{if(match($0, "[0-9][0-9]\:[0-9][0-9]\.[0-9]+\-")) print "\n"$0; else print "<line>"$0;}' | \
grep -a ",DBMSSQL,.*OSThread=4768,.*SessionID=284752," \
> long_transaction_querries.txt
Как уже писал выше, для компактности и улучшения отображения событий, лишнюю информацию из строк можно удалить.
Минимальный набор данных из каждой строки ТЖ – начало строки, содержащее время и длительность, до имени события.
Можно отсортировать события по началу выполнения (в ТЖ они записаны в порядке окончания выполнения). Это может быть полезным, если выборка сделана не по одному типу события, а по нескольким. Например, события SDBL и DBMSSQL. В ТЖ событие SDBL, обрамляющее всю транзакцию, будет отображено последним, хотя началось первым.
Можно дополнить каждую строку события вычисленным значением времени начала, пометив соответствующую опцию.
Примеры
Пример длительных запросов в транзакции уже был приведен выше. В каких еще случаях может помочь подобная визуализация?
Пример множества (несколько тысяч) одинаковых запросов, выполняемых за микросекунды - явное свидетельство выполнения в цикле. Если просто сложить время выполнения этих запросов, скажем, с помощью bash-команды awk, получим совсем немного - миллисекунды. И ошибочно решим, что они не составляют большой проблемы. Но ведь эти запросы сначала компилируются, передаются в СУБД, для них получается план запроса, после выполнения возвращается результат, производится какая-то работа сервером приложений. За счет всего этого набегает совсем не мало времени. Если пролистать к началу и к концу этого блока запросов, можно убедиться что цикл выполнялся десятки секунд!
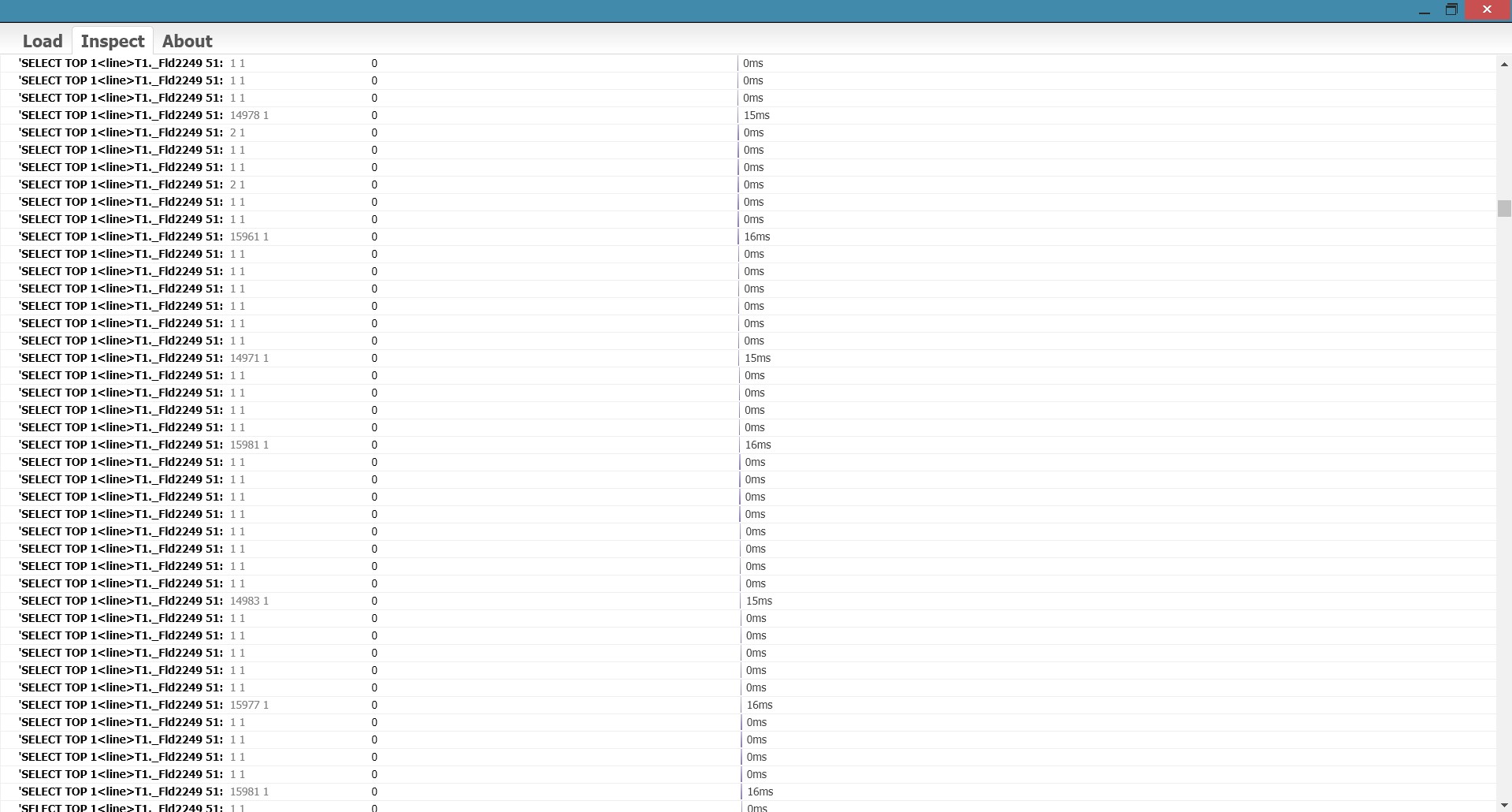
Пример паузы между запросами - повод посмотреть на управляемые блокировки, а также обратить более пристальное внимание на параметры и/или результат смежных запросов.
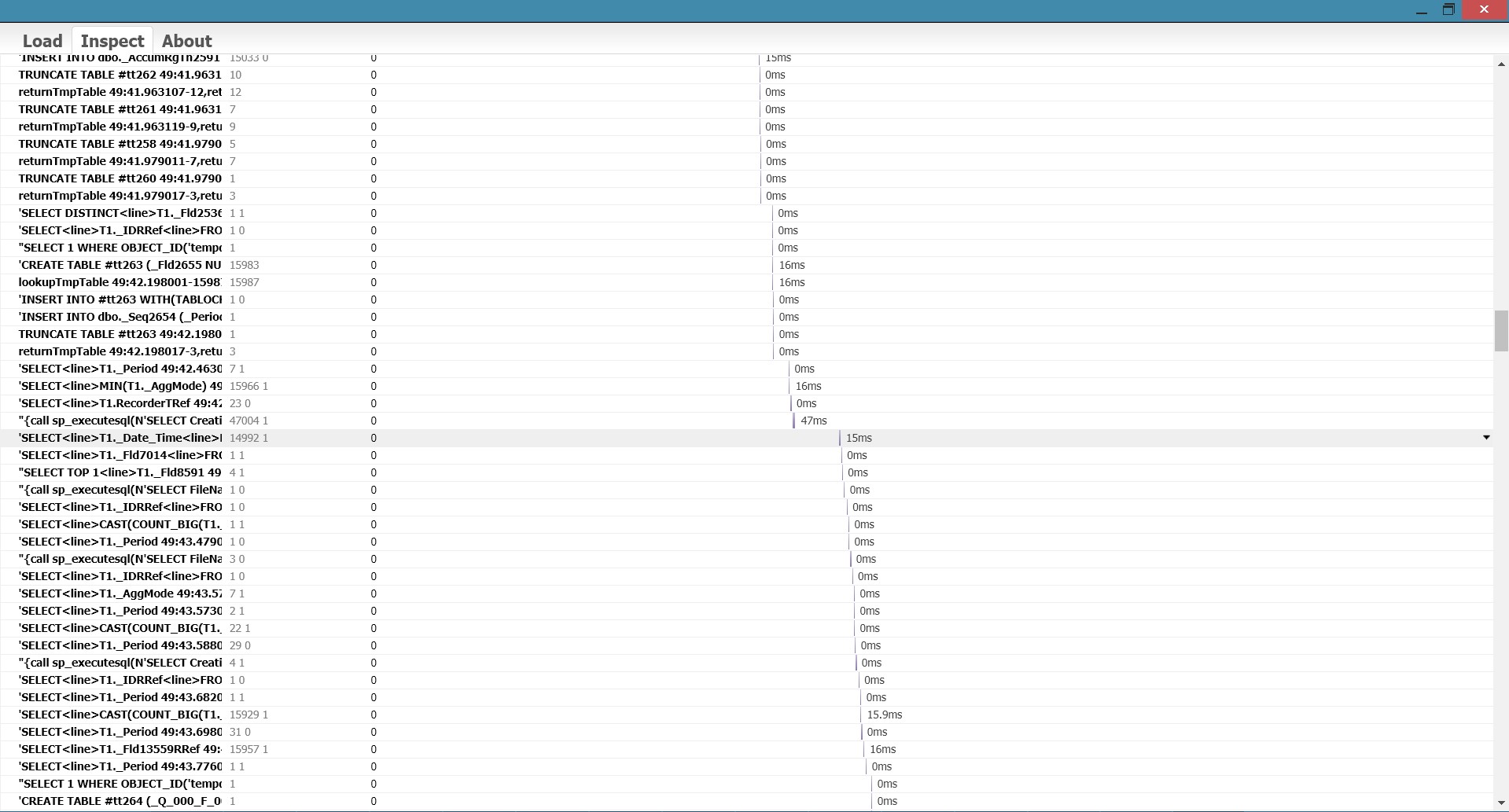
Также, можно загрузить разнородные события, например SDBL, DBMSSQL, TLOCK и другие, с целью посмотреть в какой последовательности они выполняются. Думаю, что пытливый ум найдет и другие применения предложенному визуальному анализу.
Маленький бонус
Все, кто работает с Техжурналом, конечно же знают, что в записи события на первом месте всегда указано время окончания события. Следом идет длительность. А вот фиксировать время начала события разработчики Платформы сочли излишним. Ведь его можно получить путем вычитания длительности из времени окончания.
При анализе проблем производительности довольно часто возникает необходимость понять в какое именно время началось событие. Для событий, которые начинаются и заканчиваются в рамках одной секунды, произвести нужные вычисления не составляет большого труда. Но если событие длится больше нескольких секунд, такие вычисления отнимают значительное время.
С целью вычисления времени начала события была сделана обработка. По сути, именно на её базе и реализована выгрузка в HAR-формат.

На скриншоте приведено событие выполнения запроса отчета, работавшего более 5 часов и явившегося причиной блокировки обновления статистики, которое, в свою очередь блокировало выполнение других запросов всё это время. Но это уже совсем другая история...
Заключение
Статья не преследует цели "раскрыть тему" или предоставить готовую инструкцию по анализу ТЖ. Это скорее описание еще одного варианта, представленное в виде прототипа. Тем не менее, прототип вполне работоспособный и регулярно используется мною в реальной работе по расследованию проблем производительности и оптимизации систем на Платформе 1С.
Приложенный файл обработки протестирован на версиях Платформы 8.3.14, 8.3.16
Ссылки
Описание формата:
https://w3c.github.io/web-performance/specs/HAR/Overview.html#sec-har-object-types-entry
XSD-схема:
http://www.softwareishard.com/har/schema/HTTPArchiveV12.xsd
Еще описание спецификации:
http://www.softwareishard.com/blog/har-12-spec/
Инструменты:
http://www.softwareishard.com/blog/har-adopters/
Embedding HAR Viewer
https://github.com/janodvarko/harviewer/wiki/Customization#har-preview-embedding
HAR Viewer API:
https://github.com/janodvarko/harviewer/wiki/API
Другие статьи автора
PID процесса в сборщиках PerfMon
Способы проверки доступности TCP-портов
Загрузка-выгрузка файлов по RDP с докачкой
Массовое изменение режима поддержки объектов конфигурации
GitSync 3.0. Шпаргалка по использованию
Проброс IP-адреса клиента в http-сервис 1С. Реализация для IIS
Автономный сервер. Часть 1 - новый вариант сервера
Автономный сервер. Часть 2 - утилита управления
Вступайте в нашу телеграмм-группу Инфостарт