В докладе я расскажу:
-
как у нас было устроено тестирование до того, как мы начали применять Docker;
-
как мы в конце концов переехали на Docker;
-
ну и, собственно, где и как теперь можно запускать тесты.
Что такое Docker

Docker – это программное обеспечение, которое позволяет запускать приложения в контейнерах.
Контейнер – это изолированный процесс, в который вы упаковываете свое приложение со всеми зависимостями. Оно запускается и больше ничего на него повлиять извне не может.
Docker работает и на Windows, и на Linux.
Советую прочитать полезную статью на хабре, где очень хорошо рассказано, что же такое Docker. Называется «Понимая Docker».
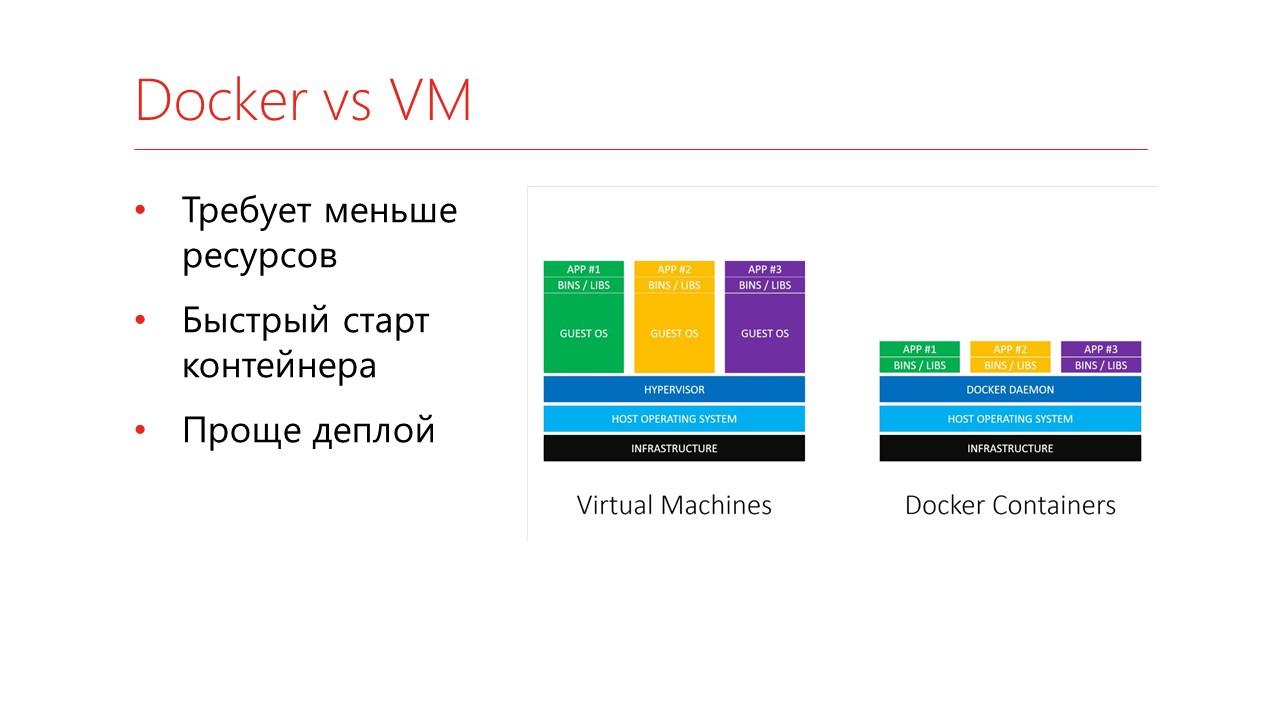
Docker очень похож на виртуальную машину, но от нее отличается.
На слайде показана классическая картинка сравнения Docker и виртуальной машины
-
У нас есть хост-система и на ней виртуализируется машина целиком. То есть она виртуализируется со всеми устройствами, жесткими дисками, процессами и гостевой операционной системой. Дальше будет наше приложение и библиотеки.
-
Docker же виртуализирует без гостевой машины – вместо этого он использует аппаратные возможности вашей машины.
Соответственно, какие мы получаем с него плюсы?
-
Он требует намного меньше ресурсов – вы дальше увидите картинку.
-
На нем очень быстро стартуют контейнеры по сравнению с виртуальной машиной.
-
И масштабировать такие контейнеры из-за этого проще.

Что нам даёт Docker с точки зрения тестирования?
-
Во-первых, это стабильное окружение. Когда вы собрали Docker-контейнер, вы его можете запускать сколько угодно раз, он будет выполняться одинаково.
-
Второе – благодаря тому, что он запускается достаточно быстро, его необязательно включить и долго держать, его можно запускать по запросу. То есть вы запустили, прогнали в нем тесты, контейнеры со всеми данными убили – все, чистить за ним не надо.
-
У Docker есть хорошая система взаимодействия между контейнерами, благодаря чему можно собирать матрешки из сервисов для тестирования.
-
И относительная простота администрирования – опять же, вы просто запустили контейнер, он сколько-то поработал, упал. И все, за ним следить-то и не надо.
Этапы применения тестирования

Я расскажу нашу историю – как у нас выглядело тестирование до того, как мы начали применять Docker, и через какие этапы мы прошли.
Этап 1. «А как это все устроено?»

Когда вы почитаете статьи в интернете, пообщаетесь с коллегами в чатах и узнаете, что 1С можно тестировать, а еще можно тестировать автоматически, а еще можно тестировать часто – вы, скорее всего:
-
поставите себе Jenkins на свою машину или на какой-нибудь сервер;
-
выберете какой-нибудь простой проект и запустите на нем тесты;
-
запускать, скорее всего, будете на одной машине – на своей или опять же на этом же сервере;
-
все окружение настроите руками – поставите нужную вам платформу, какие-то нужные вам дополнительные библиотеки;
-
ну и через какое-то время все это начнет работать как часы.
Что же происходит после этого этапа?
Этап 2. «Мы тоже так хотим»

Когда вы все это развернете, то, конечно же, захотите похвастаться перед коллегами: «Смотрите, как у меня все работает!»
-
Конечно же, они скорее всего захотят свои проекты потестировать. Ну или у вас там не один проект, вы еще какие-то другие проекты захотите запускать. Получается, вам вашу схему надо отмасштабировать.
-
Поскольку у вас, скорее всего, по-прежнему останется один сервер, а проектов будет много, у вас начнут появляться очереди на сборку. То есть вы запускаете задание, оно сколько-то выполняется, а за ним следующее-следующее-следующее, и т.д.
-
Чтобы разгрузить эти очереди, вы будете заводить несколько агентов на сборку – то есть машины, на которых вы будете выполнять задания. Мы пробовали разные схемы – поднимали виртуальные машины, брали просто несколько компьютеров, в частности, запускали прямо на компьютерах разработчиков. Последний более-менее рабочий вариант у нас был – мы завели мультилогон на одном из серверов и просто в нескольких сессиях запускали тесты. В общем, это не очень хорошая история, не советую на ней долго останавливаться.
-
Вам придется идти на какой-то компромисс по окружению, а поскольку вы уже будете запускаться не один, то вам надо договориться – какое же программное обеспечение у вас будет стоять, на каких платформах вы будете тестироваться.
-
Ну и начинать потихонечку добавлять метрики и мониторинг, чтобы вся эта ваша система не упала.
Этап 3. «Оптимизация»

Следующий этап, к которому мы перешли – оптимизация всего этого дела.
-
Мы поняли, что жить с одним сервером Windows – это очень долго, поскольку он очень любит ставить обновления, перезагружаться и поднимать обратно сессии. Мы завели набор виртуальных машин на Windows. Там были достаточно простые машины – по два гигабайта памяти и два процессора.
-
Настройка инфраструктуры через Ansible. Ansible – это такое программное обеспечение, которое позволяет описать вашу инфраструктуру декларативно. Вы можете заводить описания, какие вам пакеты надо поставить, в том числе можно описывать, какие платформы вы хотите поставить – какое дополнительное ПО вам надо, и оно раскатывается на все ваши машины. У нас был набор из шести-восьми машин, и они все идентичные.
-
Ну и не забываем, опять же, мониторить метрики – теперь нам надо было мониторить восемь машин вместо одной.
На этом этапе мы проработали достаточно долго – примерно полгода без каких-либо проблем. А потом, как обычно, что-то пошло не так.
Борьба за ресурсы

Появилось противостояние – Jenkins против Gitlab CI.
Пара проектов у нас собирается на Jenkins, а пара проектов – на GitLab CI, поскольку код у нас хранится в GitLab, а там, в принципе, тоже есть возможность организовать запуск тестов.
Во что же вылилось это противостояние?

Первое – это запуск тестов.
-
Поскольку запуск GitLab ничего не знает про запуск Jenkins, они периодически встречались на машинах. И начиналась такая веселая вещь, как борьба за порт тест-клиента – иногда GitLab перехватывал сеанс 1С, который запускался с Jenkins и наоборот.
-
Происходило пересечение скриншотов – когда у вас при возникновении ошибки делается скриншот окна, и вообще не факт, что вы там увидите то, что у вас происходило. Возможно, вы увидите чужой проект.
-
Постоянно не хватало места, потому что GitLab не очень хорошо за собой очищает данные. Об этом должен заботиться больше разработчик.
-
Такая боль, не сильно связанная с противостоянием, как доставка тестовых баз до восьми машин – когда у вас базы достаточно тяжелые, то быстро раскатить 10 Гб по восьми машинам – это такая еще задача.
-
Ну и достаточно интересная еще проблема – это внезапные обновления. Например, когда выходит новая версия фреймворка тестирования, я его ставлю на одну машину – у меня все работает, а когда раскатываю его на оставшиеся восемь – и у других проектов что-то идет не так. У меня был забавный случай, когда разработчик поставил новую версию платформы 8.3.17, чтобы протестировать работу приложения, и у меня отвалился тест. Причем он падал очень неадекватно, там была проверка наличия элемента на форме, и тест говорил, что элемента нет, а на скриншоте он есть. Как оказалось, был временный баг в платформе 8.3.17. Это поправили, но два часа я потратил на то, чтобы понять, что же там не так.

Вторая проблема, которая возникает из-за противостояния Jenkins и GitLab – это запись инструкций. Фреймворк тестирования Vanessa Automation позволяет писать очень хорошие понятные инструкции.
Но у нас это выглядело еще интереснее, поскольку накладывалась проблема с пересечением скриншотов – когда вы запускаете запись инструкции, у вас тесты проходят, вы ее публикуете, потом смотрите, а на скриншотах-то у вас другой проект совсем.
Решили с этим как-то бороться.
Подготовка образов Docker с 1С

Возник вопрос изоляции тестовых стендов. А за это вроде как должен отвечать Docker. Мы начали разбираться, как можно тестировать 1С в Docker.

Чтобы запустить в Docker какое-либо приложение, нужно создать так называемый образ, в который будет как раз упаковано наше приложение.
Как готовится образ с 1С внутри:
-
для этого нужно написать специальный файл – Dockerfile;
-
в нем вы описываете базовый образ, на основе которого у вас будет запущена виртуальная машина;
-
устанавливаете туда ваше приложение и все зависимости;
-
ну и мы дополнительно упаковываем всякие хотелки, чтобы потом их не доставлять.
По сути, вы поднимаете образ, а у вас там всё уже готовое.

Первая проблема – это выбор базового образа.
-
Самый классический вариант, который все всегда предлагают с точки зрения «собирать образ для 1С» – это взять Ubuntu, туда устанавливается Xserver и VNC, чтобы периодически заходить смотреть, что же там происходит. Мы такой образ собрали, но у нас что-то пошло не так. Очень часто окна не переключались – то есть тест проходит, а окно видно другое.
-
И мы нашли другой образ, называется Ubuntu_xfce_vnc. Там установлен xfce как рабочий стол Ubuntu, VNC и другое программное обеспечение, которое можно использовать. Например, там сразу же стоит Chrome – вы можете что-то потестировать с его помощью. И вот на базе такого образа мы собираем образ с 1С.
Как же его собрать?
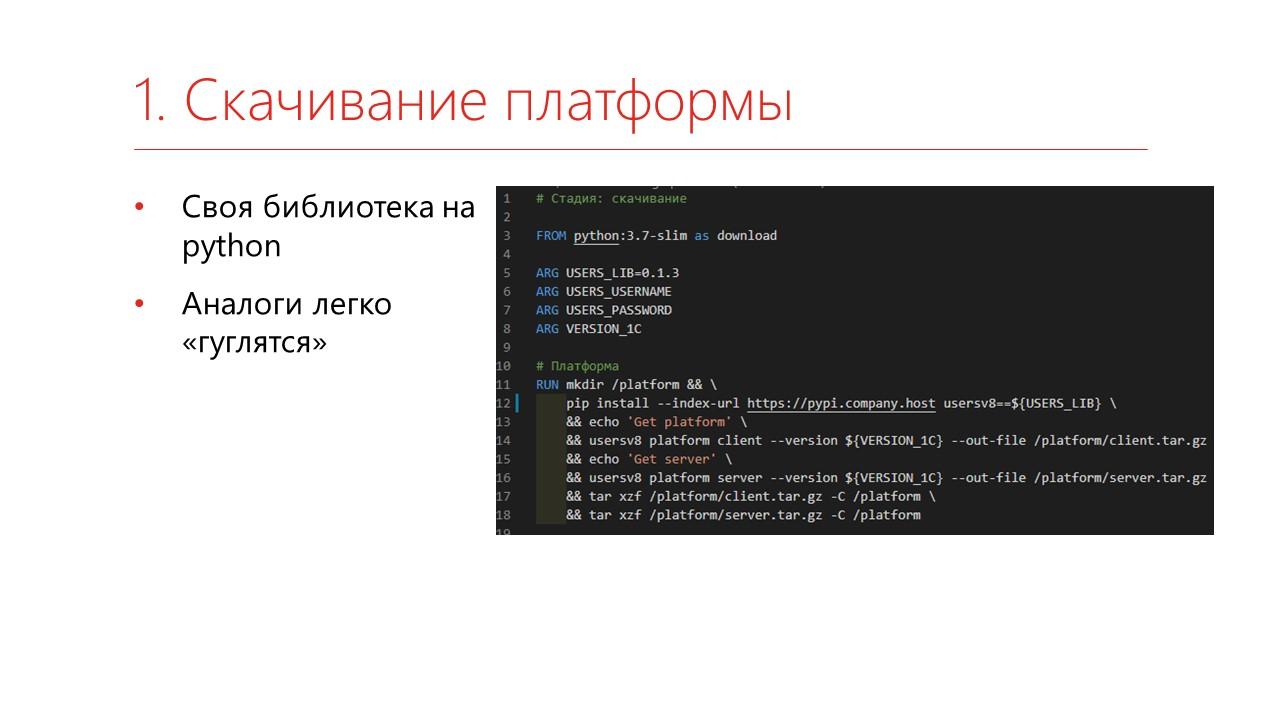
Сначала нужно скачать саму платформу и сервер с сайта 1С.
Мы скачиваем собственной библиотекой, написанной на Python – когда-нибудь мы ее обязательно опубликуем, но аналоги легко находятся. В конце доклада будут ссылки, где можно посмотреть другие варианты.
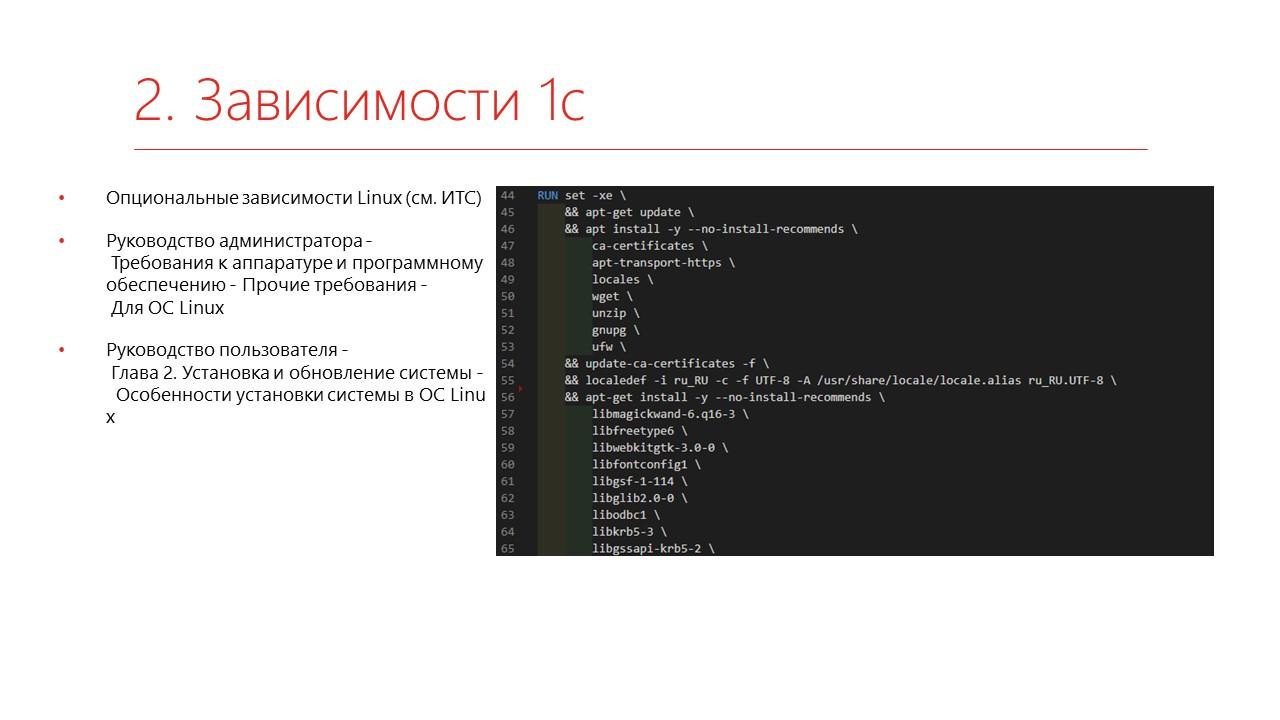
Дальше устанавливаем все необходимые зависимости. Их можно посмотреть на ИТС – кто ставил хоть раз 1С под Linux, тот, в принципе, знает, что там надо добавлять.
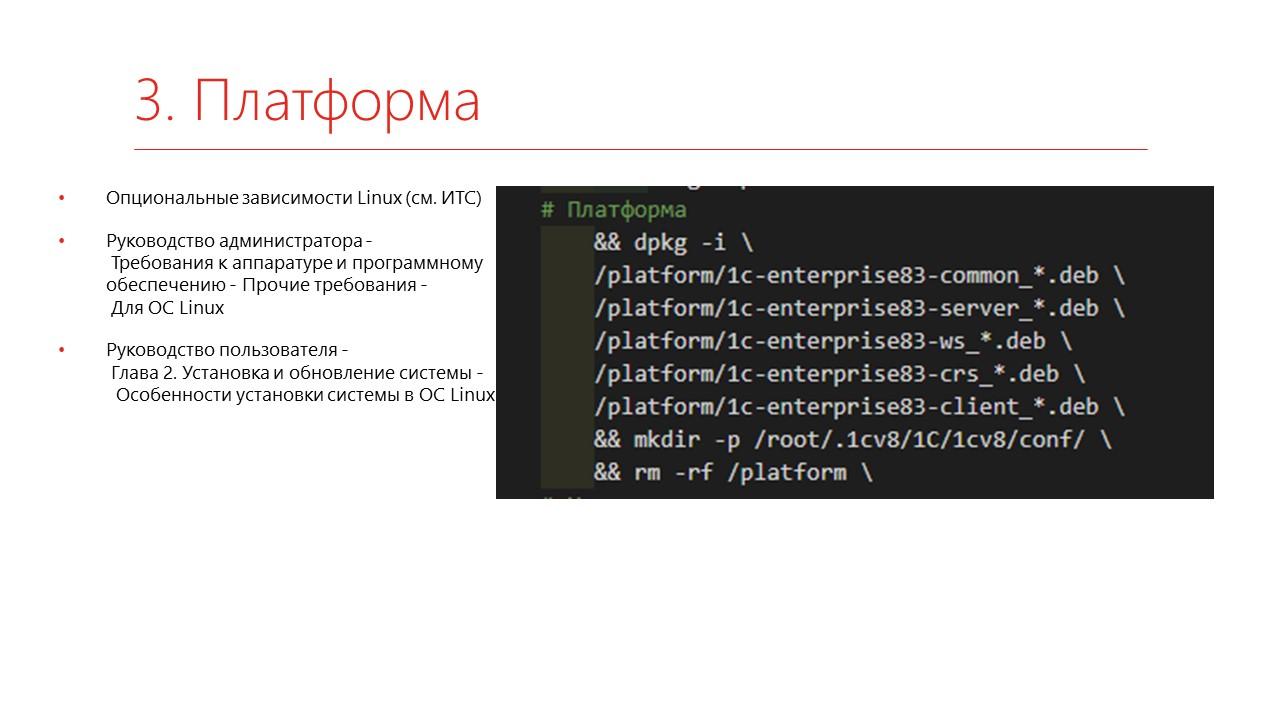
Следующим шагом ставим платформу – опять же, в статьях на ИТС можно посмотреть, как это устанавливается.

И доставляем прочие зависимости.
-
Мы ставим компоненту 1CWinCtrl – это очень хорошая компонента, которая позволяет управлять окнами и много чего дополнительно.
-
Ставим шрифты.
-
Мы используем приложение scrot, чтобы снимать скриншоты.
-
И еще надо обязательно поставить утилиту inetutil-ping, потому что в Ubuntu отсутствует ping. Если вы делаете паузу через ping, у вас приложение упадет.
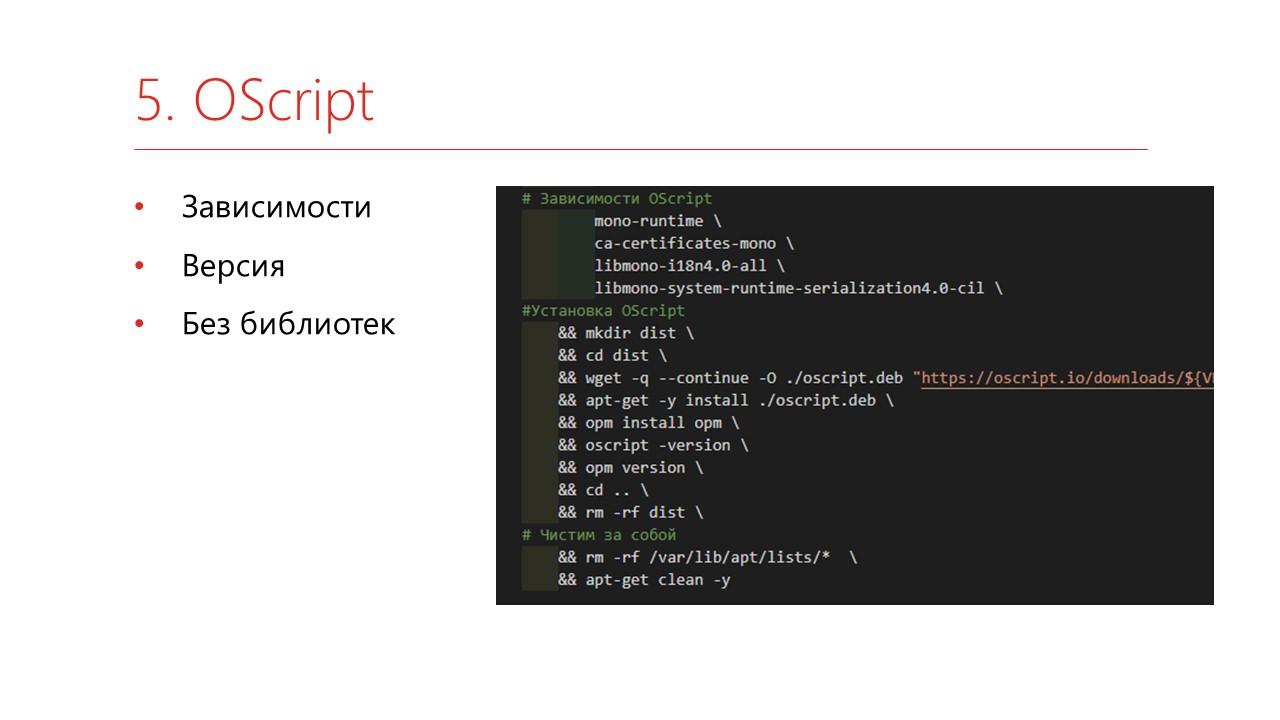
Дальше мы доставляем OneScript, чтобы всем этим управлять.
Единственное – мы договорились, что мы не ставим библиотеки. Благо, они ставятся очень быстро – каждый ставит, какие хочет, во время сборки.

И не забываем, конечно же, поставить лицензии. Сервис с лицензиями у вас должен стоять где-то отдельно и должен быть виден по сети.
После того как мы все это собрали и запустили, мы же помним, что мы поставили VNC – мы можем подключиться и наблюдать следующую картину.
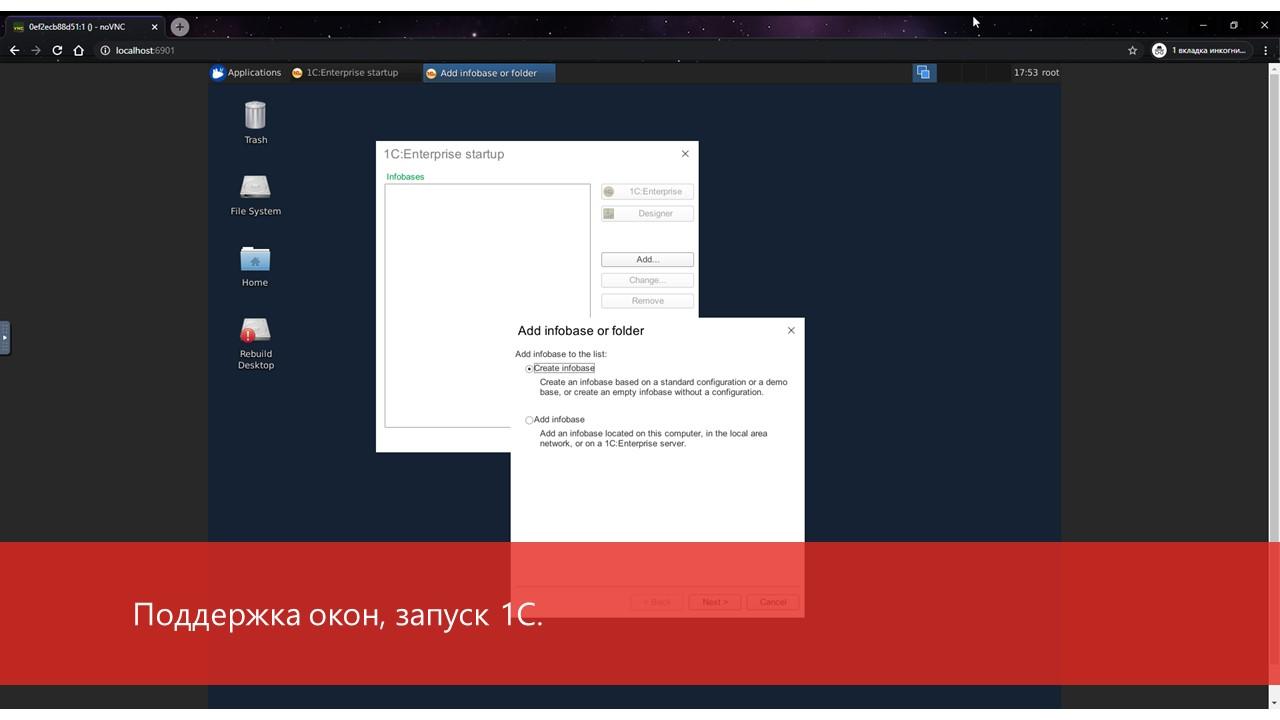
Вот так выглядит развернутый образ – здесь есть рабочий стол с поддержкой мультиокон, и вполне можно запускать 1С.

Сколько это занимает места? Вот примерные замеры памяти.
-
Просто запустить контейнер занимает 150 мегабайт.
-
На моей достаточно нагруженной машине он запускается за 4 секунды.
-
Если я запускаю в нем юнит-тесты, он начинает потреблять порядка 400 мегабайт.
-
А запуск UI-тестов на больших базах типа УТ11.4 или 1С:Документооборот выедает примерно 2-3 гигабайта.
Соответственно, на те виртуальные машины, которые мы брали в аренду – нужно было два гигабайта памяти. Выгода налицо.
Инфраструктура Docker

Когда мы с вами образ собрали, возникает вопрос – где все это запускать и хранить, как устроена инфраструктура.

Первое – этот образ надо где-то хранить, чтобы его можно было скачивать.
-
Как вариант, вы можете поднять собственный docker hub. Скачиваете официальный дистрибутив, поднимаете и он вам позволяет сохранять версии – образы будут доступны у вас в сети.
-
Второй вариант – это GitLab Registry. Если у вас исходный код хранится в GitLab, как у нас, то можете прямо в нем же хранить и образ. Тоже достаточно удобная система.
-
У нас используется Nexus – это более универсальная система. Кроме Docker-образов она позволяет хранить библиотеки питона, Node.JS-библиотеки. По сути, это такой агрегатор всех пакетных менеджеров.
Сборка образов с 1С

Теперь о том, как образы собирать. Конечно, можно каждый раз собирать образ руками, но хотелось бы это тоже автоматизировать. Тем более, что собирать можно и на GitLab CI, и на Jenkins.
По сути, надо выполнить четыре команды – это:
-
docker login – подключиться к вашему регистру;
-
docker build – собрать образ;
-
docker push – отправить его;
-
docker logout – не забыть отключиться.

На слайде показан пример файла gitlab-ci.yml, с помощью которого мы собираем образ:
-
В разделе before_script есть команда docker login – мы подключились.
-
Ниже, в разделе script – основная часть. Ветку master мы собираем с тегом версии платформы, которая нам нужна. А ветку develop мы собираем с тегом test, чтобы не испортить уже готовые образы.
-
Дальше мы собираем образ – командой docker build.
-
Отправляем его в наш docker registry – командой docker push.
-
И не забываем отсюда отсоединиться – командой docker logout.
Запуск тестирования на GitLab и Jenkins

При запуске этой сборки у нас опять возникает картинка – Jenkins против GitLab CI.

Сначала посмотрим GitLab, потому что он чуть проще.
На машине, где установлен Docker, вам нужно зарегистрировать GitLab runner – он запускает тесты в GitLab CI.
Дальше – в файле gitlab-ci.yml вы указываете:
-
образ, в котором хотите запускать тесты;
-
на каких компьютерах вы хотите их запускать;
-
GitLab сам скачивает последнюю версию образа, запускает контейнер, и потом все эти команды будут выполняться уже внутри контейнера.
То есть вам не надо сильно изучать Docker – вы просто пишете типовые команды.

Теперь как это устроено в Jenkins – он позволяет настроить более тонко, но и настраивать это дольше.
-
Первое, что вам надо – это запустить на вашем Docker-хосте Docker-daemon https://docs.docker.com/engine/reference/commandline/dockerd.
-
На Jenkins вам надо поставить Docker-plugin – это позволяет запустить Docker Cloud Provider.
-
Самая большая проблема – это то, что в ваших Docker-образах должна быть установлена Java и, собственно, агент Jenkins. По адресу https://github.com/jenkinsci/docker-inbound-agent есть официальный пример от Jenkins, как это добавить.
-
А дальше вы каждому такому образу присваиваете Label, который будет соответствовать Jenkins-агентам.
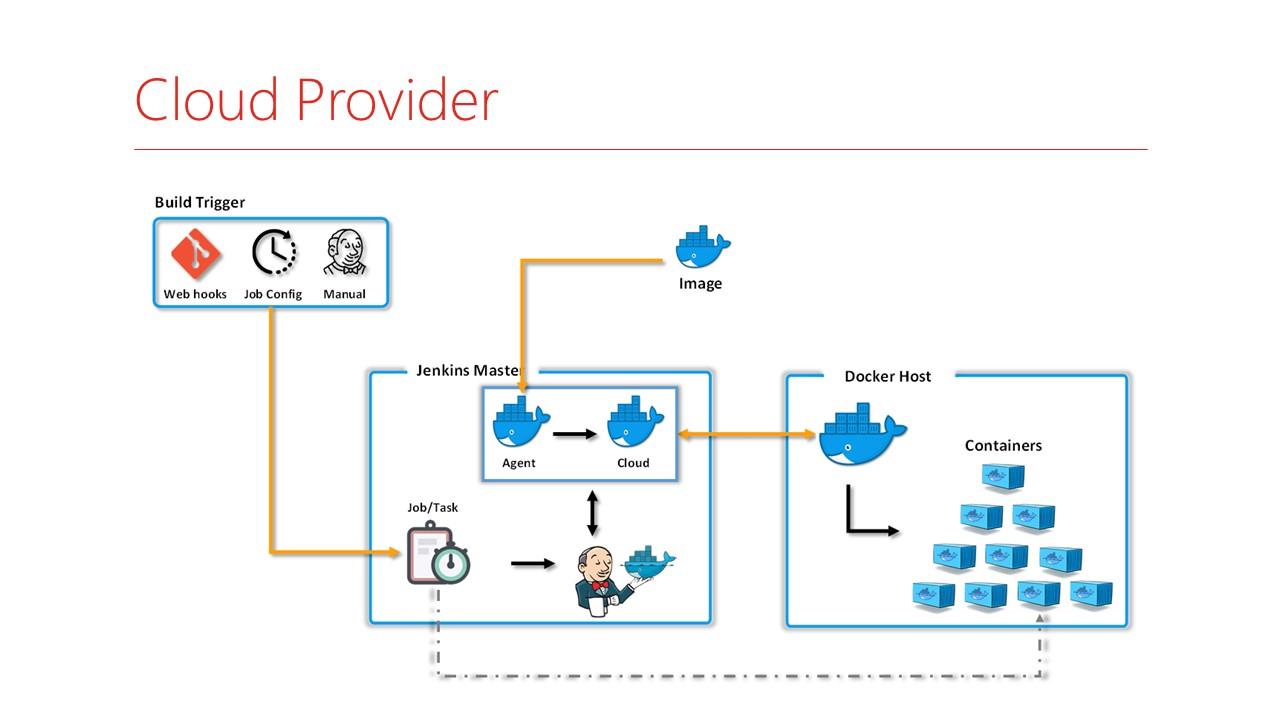
Как это выглядит на практике?
-
У вас на Jenkins по каким-то триггерам или при помещении кода, или по таймеру в очередь встает задание.
-
Jenkins смотрит, что это задание надо запускать на Cloud-провайдере каком-то, запрашивает возможность запустить эти данные – проверяет, хватает там сейчас памяти или нет.
-
Готовит специальный образ только под эту задачу, в него подключается и дальше запускает задачки внутри контейнера.
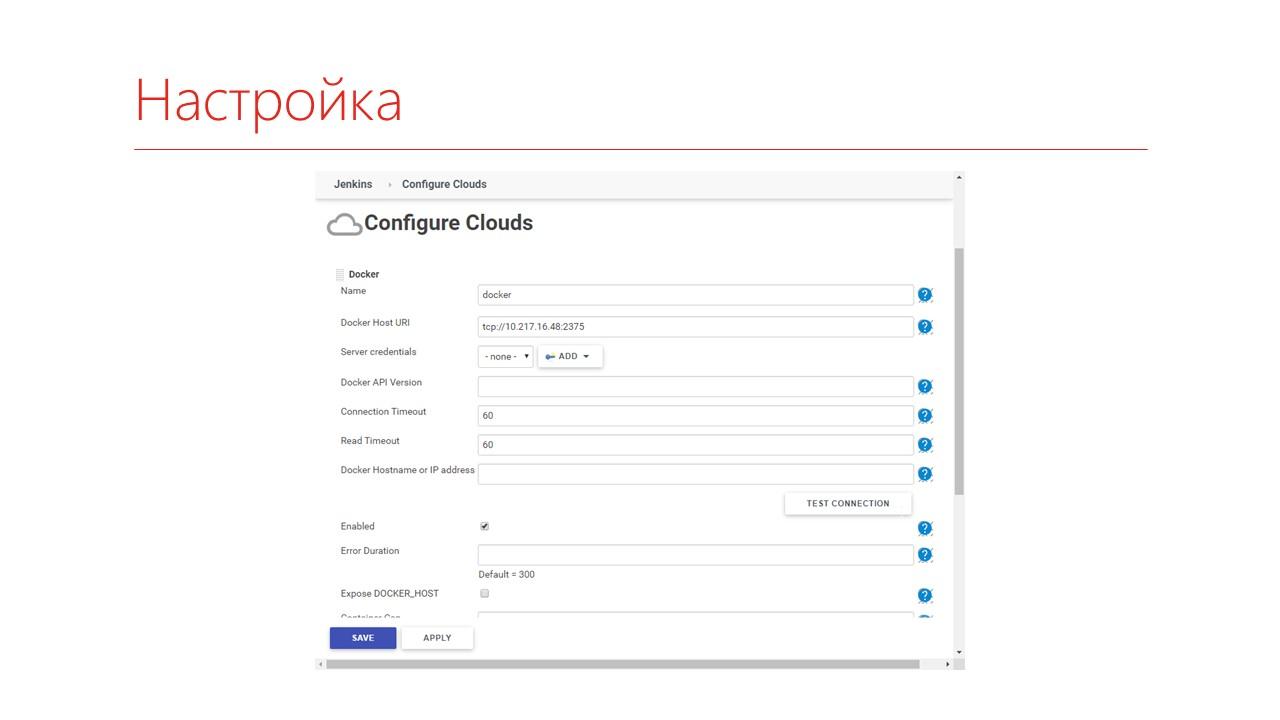
Как настраивается Cloud Provider?
Если вы запускаете тестирование просто на Docker, то вам надо указать IP-адрес вашего Docker-хоста и авторизацию, если есть.
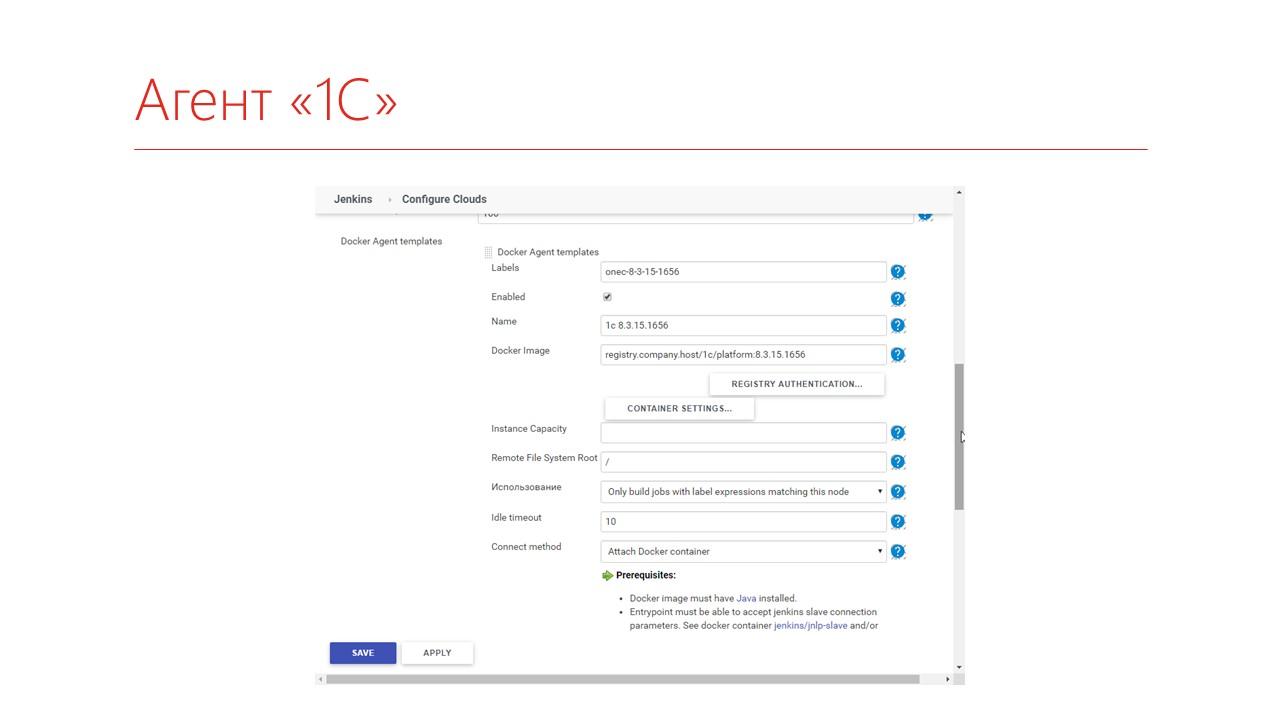
И дальше нужно описать, какие Docker-агенты вы будете запускать – на базе какого образа, назначить ему Label и, если нужно, дополнительные параметры.

Теперь в задаче Jenkins вы:
-
указываете Label контейнера;
-
если хотите больших настроек, можно указывать вручную образ и параметры запуска;
-
а дальше пишите типовой код на Jenkins, указывая путь к Jenkinsfile.

На слайде показано, как выглядит Jenkinsfile у нас.
Мы говорим, что хотим собираться на версии платформы 8.3.15, а дальше у нас обыкновенный код – мы подготавливаем папки, забираем наш репозиторий, ну и запускаем тесты. В частности, тут юниты.

Если хотим больше настроек, мы можем прямо указать, с какого Docker Registry скачивать, какую версию.
И тут через точку можно указывать кучу параметров – сколько памяти он будет занимать, как долго контейнер будет жить и т.д. и т.п.
Итоги перевода тестирования на Docker

Как в итоге получилось?
-
Мой образ – мои правила. Теперь каждая команда могла подготовить свой собственный образ с нужными ей библиотеками. И никто другой в него вмешиваться не сможет.
-
Можно выполнять операции параллельно – контейнер занимает мало места, и, например, конвертацию из формата EDT и CF мы теперь можем собирать параллельно. Раньше в один поток запускалось, потому что они как-то конфликтовали между собой даже на разных сеансах.
-
Уменьшили потребление памяти. Некоторые тесты занимают 400 мегабайт, благодаря чему, например, на той же машине в 2 гигабайта мы можем слить их в пять потоков вместо одного.
-
И теперь мониторить надо всего единственный наш сервер, на котором мы все запускаем, а не восемь виртуальных машин, которые были до этого.
-
Наконец, начали тестировать наши приложения под Linux. Это достаточно интересно – находятся неожиданные артефакты.
-
Ну и прокачка Hard-скиллов. Если раньше для работы с Docker-ом мы просто скачивали что-то с GitHub и запускали: «Не работает – ну и ладно», то теперь пришлось разобраться, как же он работает.

Из негативных итогов:
-
Памяти все равно мало. То есть у нас Docker-хост был на 8 гигабайт, и иногда на нем место заканчивается быстро – нужно выделять больше.
-
VNC так и не пригодилось, потому что там надо аккуратно порты пробрасывать, поскольку машина одна, а контейнеров много. И VNC мы так в итоге и не пользовались.
-
И мы не смогли запустить Docker-compose. Можно собрать «матрешку» из сервисов, которые вам нужны – например, если вы хотите монтировать внешнее API. Но такие «матрешки» мы запустить не смогли.
Kubernetes
В результате мы пришли к Kubernetes.
Kubernetes – это такое ПО, которое масштабирует запуск контейнеров.
Оно больше подходит для DevOps, но мы решили на нем запускать тесты.

Зачем?
-
Во-первых, у нас уже был готовый корпоративный кластер Kubernetes с большим количеством памяти.
-
Во-вторых, Kubernetes может запускать тесты в Docker-Compose. Там не совсем Docker-Compose, но я дальше покажу, как это выглядит.
-
Ну и просто попробовать, что это такое, и перенести туда пару своих сервисов, которые сейчас крутились на наших машинах.
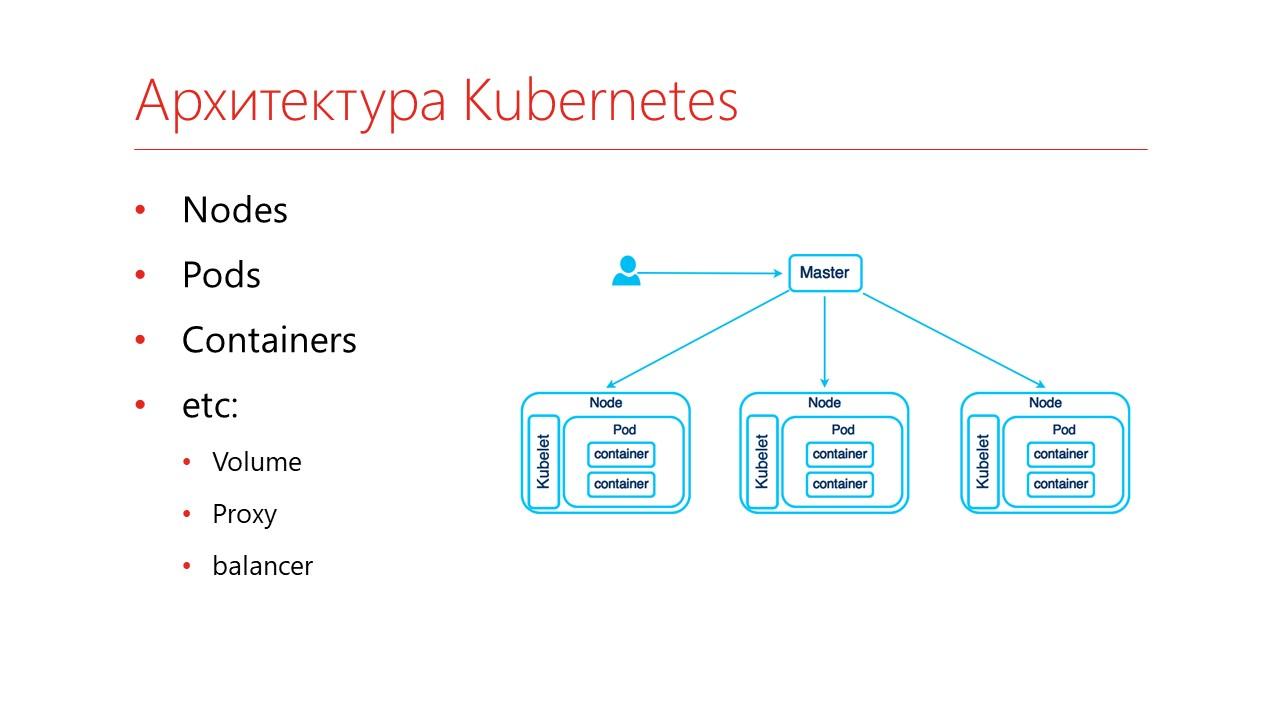
Как выглядит кластер Kubernetes?
-
Во-первых, это кластер, в нем существует несколько компьютеров, которые объединены одним Master-узлом. Эти компьютеры называются ноды – Nodes.
-
На нодах запускаются так называемые поды – Pods. Pod – это очень похоже на контейнер, только интересность в том, что он сам состоит из контейнеров. То есть тут изоляция двойная – сначала Pod изолируется от всего остального, что есть на компьютере, а внутри него еще есть изолированные контейнеры.
-
И вот как раз в контейнерах можно запускать свои дополнительные сервисы.
-
Ну и дополнительно – это хранение данных (подключение Volume), проксирование запросов и балансировка нагрузки.
Как это настраивается? Я покажу, как это настраивается на Jenkins, потому что на GitLab ничего не меняется – вы точно так же регистрируете на нем docker-runner и просто пишете, в каком образе вам запустить тесты.
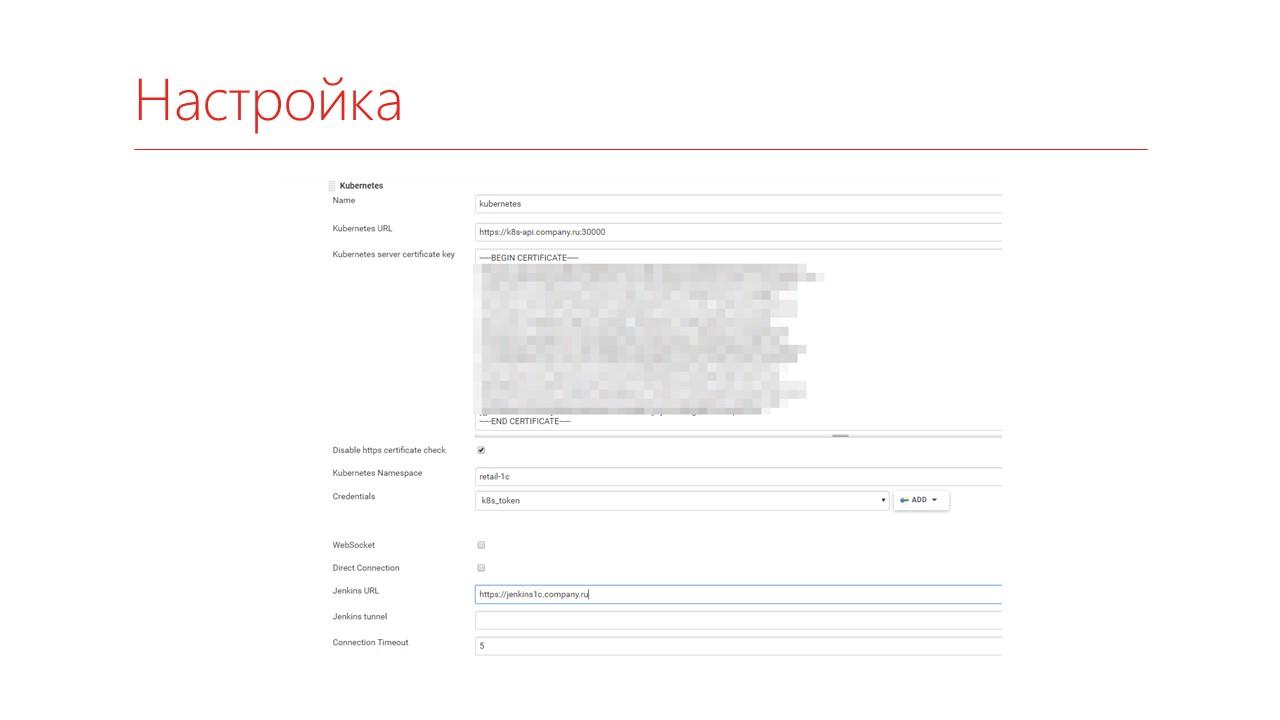
Чтобы зарегистрировать Jenkins, вам потребуется получить сертификат для подключения и выделить себе какой-то кусок этого кластера.
Все это можно получить у своих DevOps-инженеров или, если вы сами будете это себе настраивать, то по мере установки эти данные вам будут предоставлены.
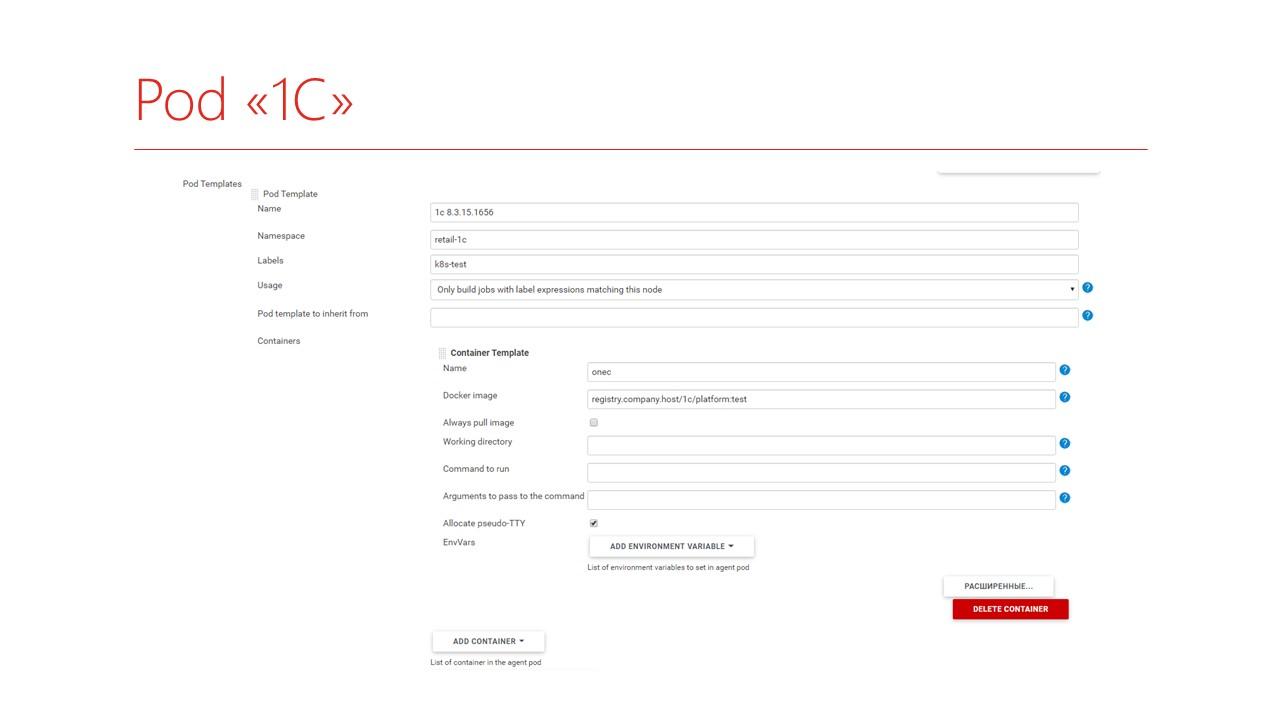
Дальше можно описать, собственно, Pod, в котором вы будете запускать 1С.
Соответственно, вы задаете:
-
имя вашего пода;
-
в какой части Kubernetes он будет запускаться;
-
присваиваете ему какой-то Label;
-
и дальше пишете, из каких контейнеров он будет состоять. В частности, он будет состоять из контейнера 1С такой-то платформы – здесь, видимо, тестовая.
Что интересно – когда вы работаете с Kubernetes, вам уже не надо ставить Java в ваш контейнер, что очень хорошо, и не надо регистрировать агента Jenkins внутри контейнера. Вы собираете типовой контейнер с 1С. А контейнер с Jenkins будет автоматически добавляться при обращении к новому Pod.

Запуск состоит из таких этапов:
-
вы описываете Pod;
-
описывайте, какие контейнеры будете выполнять;
-
и пишите используемые действия.

Выглядит это вот так.
-
нам нужна нода с таким-то лейблом;
-
персонально под текущей запуск в этой ноде поднимается контейнер с нужной платформой;
-
дальше мы обращаемся к контейнеру 1С;
-
и внутри него готовим папки, получаем наш исходный код и запускаем тесты.
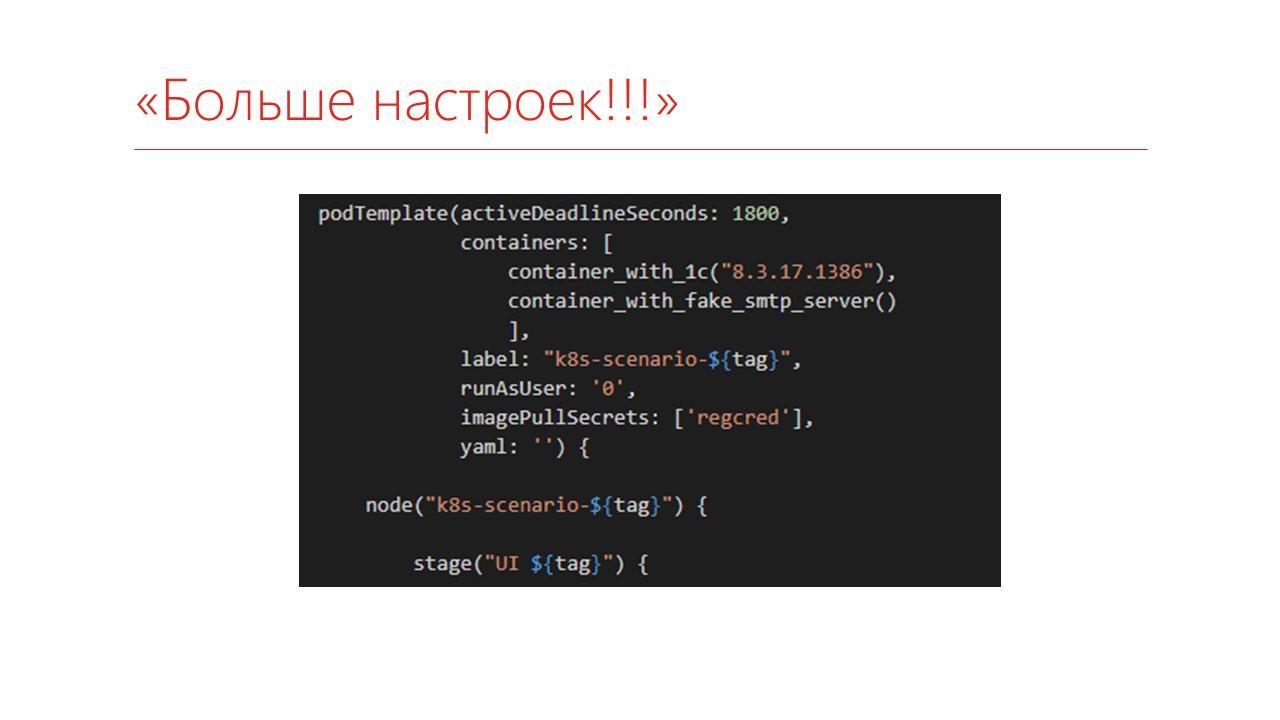
Если мы захотим больше настроек, то Pod можно описывать прямо в коде:
Говорим, что нам нужен будет такой-то Pod, состоящий из двух контейнеров – с платформой и с Fake SMTP Server. Fake SMTP Server – это очень удобный сервер, который позволяет тестировать отправку почты.
Благодаря тому, что они упаковываются в Pod, у них взаимодействие будет только сетевое, причем адрес у них у обоих будет localhost.
Вот так интересно это работает.
Ну а дальше запуск тестов, как это было показано.

Можно указать еще больше настроек – здесь указывается, сколько нам надо потреблять ресурсов, чтобы более корректно выбирать ноду.
Итоги перехода на Kubernetes

Итоги этого этапа.
-
Теперь за контейнерами не нужно следить, потому что в случае падения Jenkins сам умудряется за собой все почистить.
-
Можно собирать тестовое окружение из нескольких сервисов, как я уже показал, причем внутри эти контейнеры могут быть на совсем разных архитектурах. Там наш контейнер собран на Ubuntu, а Fake_smtp, по-моему, собирается на Centos.
-
Еще мы прокачали наши Hard skills и перевели наши три внутренних сервиса в Kubernetes.
Особенности Docker

Итак, что же сделать, чтобы со всем этим работать?
-
Во-первых, поймите, что Docker – это не страшно, это не какая-то магия, его вполне можно поставить к себе на компьютер и попробовать с ним работать. Это достаточно удобно, особенно если вы хотите попробовать какой-нибудь сервис. Например, вы хотите внедрить в код-ревью. Мне нравится Upsource – это достаточно удобный сервис для код-ревью. Вместо того, чтобы ставить на какой-то машине, вы можете скачать официальный образ, развернуть его у себя, попробовать с ним поработать и убрать, если он вам не подойдет.
-
Запуск тестов фактически не отличается – код, который использовался для запуска теста в Jenkins, перекочевал как каковой с Windows-машин на Linux-машины. Единственное, на что нужно обращать внимание – это регистр, потому что Linux регистрозависимый, какие слеши вы используйте в путях, и будьте аккуратнее с правами доступа на уровень файловой системы.
-
Kubernetes – это тоже в принципе не страшно. Можете поставить себе minikube. Он работает и под Windows в том числе. Это такой кластер на одну вашу машину. Вы можете легко позапускать в нем какие-то данные.
Полезные ссылки
Официальная документация по Docker и Kubernetes:
Чтобы не бояться, советую пройти практику на сайте katacoda.com. Там бесплатные курсы, причем они достаточно интересно построены – вы просто руками набиваете нужную вам команду и видите, как они исполняются:
Пара готовых образов для 1С:
И видео, из которого черпали вдохновение:
Вопросы
-
Скажите, как вы тестируете обычный интерфейс?
-
Обычный интерфейс – это, конечно, сложный вопрос. У нас к его тестированию было два подхода. Один вариант тестирования мы сделали через оповещения – расставили в коде очень много меток оповещений. При запуске обработка тестирования просто выполняет команды, и, по сути, она делает то же самое, что делает тест-менеджер по HTTP, только через типовое оповещение. Поскольку менеджер тестирования в обычных формах не работает, там идет оповещение с ключом, чтобы не вызывать лишнего, и параметром – какую кнопку нажать. И через команду «Выполнить» этот код выполняется.
-
У вас тестируется и обычный, и управляемый интерфейс? Или в основном все на управляемых формах?
-
Больше на управляемых формах. Даже более того, мы перешли к тому, что мы пишем на управляемом интерфейсе, закрываем его тестами, и на обычный интерфейс переносим этот кодпрактически копипастом. То есть мы его пишем специальными обертками, которые позволяют переносить его на обычный интерфейс.
-
Как быть с тестированием специфичных для Windows возможностей – с теми же самыми COM-объектами?
-
Такие агенты оставить на Windows. Разделить тестирование. У нас есть часть вещей, которые тестируются на Linux – это большинство, потому что это теперь быстро и меньше ресурсов. А та часть возможностей, которая использует COM-объекты или, например, у нас часто используется ИзвлечениеТекста – она уходит на Windows-машины. У нас просто Windows-машин меньше теперь
-
Получается так, что в самом Docker-контейнере запускается, по сути, только клиент, а база данных находится где-то в другом месте, и Docker подключается к ней. Или разворачивается файловая база?
-
В основном у нас используются файловые базы, и есть один узел, который тестирует серверные базы. Поскольку это все в одной сети, Docker видит серверные базы, и поскольку тестирование серверных баз производится на конкретном узле, так можно делать. Если мы запускаем тестирование параллельно, то это, в основном, файловые базы. Причем сейчас мы пришли к тому, чтобы файловую базу прямо в контейнер помещать, потому что контейнеры и так тяжелые получаются – 1С достаточно тяжеловесная. И если туда догнать еще один гигабайт, то уже не так страшно. А поднимать контейнер с готовой базой намного быстрее, чем ее откуда-то скачивать каждый раз.
-
Можно ли замонтировать в контейнер каталог с файловой базой?
-
Можно. Но, опять же, если мы уходим на Kubernetes, там монтировать сложно.
-
Как у вас автоматизирован код-ревью?
-
А что можно автоматизировать в части код-ревью? У нас принято, что мы не заливаем напрямую в ветку – ни в master, ни в develop. Все это запускается через так называемые Merge-request. Если на GitHub – то через Pull-request. К репозиторию с помощью типовых возможностей веб-хуков подключен Upsource, где создается проект, в который приглашаются люди. Как только они просматривают, что все ОК, дают свое добро, Merge-request можно закрывать. Что тут автоматизировать? Это помогает только в части организации, чтобы код-ревью быстрее проходило.
-
Есть ли у вас SonarQube?
-
Да, SonarQube есть. Но он же не код-ревью проводит, он просто на ошибки быстрее указывает.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Ekaterinburg.Online.

Вступайте в нашу телеграмм-группу Инфостарт