












Вводные условия
Сразу оговорюсь, что вариантов решения предложенной задачи может быть как минимум не меньше, чем число коллег, которые захотят их представить в виде комментариев после статьи.
Еще здесь затронуто несколько холиварных моментов, которые также могут вызвать определенную реакцию сообщества.
Призываю, конечно же, делиться своими соображениями по всем заинтересовавшим вас моментам. Но делать это аргументированно, без пустого "пффф...кто же так делает..." и другой подобной риторики.
Итак... Промышленное предприятие среднего размера. ИТ-отдел занимается самостоятельным внедрением и поддержкой различных решений преимущественно на платформе 1С. Есть определенный "зоопарк" задач, ведется последовательный перенос части этих задач в рамки единой конфигурации.
Вот она - доработанная типовая конфигурация, стоящая на поддержке вендора, с включенной возможностью изменений. Конфигурация (ERP, конечно же) и одно (а, может быть, и не одно, но, надеюсь, у вас не слишком много) расширение, его дополняющее. В конфигурации и расширении ведется периодическая доработка действующего (боевого) функционала и исправление обнаруживаемых ошибок.
В основной конфигурации добавляются реквизиты к существующим объектам или добавляются новые объекты метаданных. Логика для "собственных" объектов метаданных может программироваться в основной конфигурации. Логика для объектов поставщика преимущественно переносится в расширение для облегчения процесса обновления на новые релизы вендора.
Для основной конфигурации и расширения созданы хранилища конфигурации, которые регулируют процесс доработки и помогают переносить наработки в боевую базу.
В боевой базе используется только часть функционала типовой конфигурации - один или несколько контуров учета или разделов операционного управления. Именно эти контуры и разделы доработаны в расширении и основной конфигурации.
Остальные контуры учета и разделы управления автоматизированы в других информационных системах (или не автоматизированы вообще) и идет последовательный, минимизированный по стрессу для пользователей, разработчиков и сотрудников сопровождения, процесс их автоматизации в рамках рассматриваемой типовой конфигурации.
В процессах доработки, внедрения и сопровождения участвуют только сотрудники ИТ-отдела организации: до 7-ти разработчиков, до 5-ти сотрудников сопровождения (они же консультанты, методологи и тестировщики). При этом, та же команда сопровождает все другие используемые информационные системы организации, кроме технологических. Стандартный "заводской" набор.
Контуры автоматизации разработки, тестирования и развертывания (CI/CD) не используются - масштаб не тот, относительно больших конфигураций "с нуля" не разрабатывается. Есть набор "дымовых" тестов, помогающий при обновлениях и все.
Подходит очередь автоматизации нового контура учета и возникает дилемма.
Требуется одновременно:
- достаточно интенсивно дорабатывать конфигурацию и расширение в рамках внедрения нового функционала;
- дорабатывать боевую часть функционала (отложенные при прошлых внедрениях моменты) и исправлять там ошибки.
Если делать все в рамках существующих хранилищ, то вероятность того, что в боевую базу попадет "сырой", не протестированный функционал, пересекающийся в каких-то моментах с боевым, и, потенциально, порождающий неожиданные коллизии и ошибки, достаточно велика. Особенно, если боевая база подключена к хранилищам.
Проблемы Git'а и EDT при доработке типовых конфигураций
Само собой, первое что приходит здесь на ум - Git с его ветками. Действительно, решение в мире 1С современное, модное и, на первый взгляд, вполне подходящее под сложившуюся ситуацию.
Но конфигуратор, наиболее привычная среда разработки для пока подавляющего большинства разработчиков 1С, не может работать с Git'ом.
Git, вернее достаточно большое число его клиентов, может работать с отдельно взятыми файлами, в которые сейчас можно выгрузить конфигурацию и/или расширение.
Но, в случае использования такого подхода, процесс разработки грозит стать достаточно сложным и долгим. Выгрузка/загрузка в файлы конфигураций уровня ERP занимает очень продолжительное время. Кроме того, разработчикам придется учиться очень тщательно контролировать работу с Git'ом через файловую систему или учиться работать с большим количеством нового инструментария. И я не уверен, что не возникнет еще одной проблемы, которая описывается чуть ниже.
Напрашивается вроде бы очевидное решение - EDT.
Среда разработки, пусть и относительно новая, но вполне годная для достаточно быстрого освоения разработчиками, с большим количеством "плюшек", которых лишен старый добрый конфигуратор. Сейчас уже поддерживаются самые свежие релизы платформы. Работа с Git'ом поддерживается без лишних "танцев с бубном". Есть возможности расширения функционала с помощью плагинов. И прочая, и прочая...
Остаются, конечно, вопросы с производительностью машин разработчиков, но это вопрос при необходимости решаемый.
К сожалению, в случае доработки типовых конфигураций, EDT никуда не годится.
Если бы речь шла только о расширении, то, возможно, проблем бы никаких не возникло.
Но дорабатывается, хотя и ограниченно, и сама основная конфигурация. А это значит, что ее также придется выгружать в проект EDT и загружать назад в конфигурацию для целей разработки и тестирования.
Помимо немалых затрат времени есть еще один, причем, на мой взгляд, самый значительный фактор, который мешает подобному использованию EDT.
Эта среда разработки обязательно "поломает" вашу конфигурацию (которая находится на поддержке, и которую еще нужно периодически обновлять, напомню), привнеся в нее большое число ненужных и странных артефактов в виде отличий разных свойств объектов метаданных, форм и их элементов от первоначального состояния.
Для эксперимента можно взять любую типовую конфигурацию с включенной возможностью изменений. В EDT сделать проект, загрузив в него эту конфигурацию. После чего, не внося никаких изменений в сам проект EDT, выгрузить его в другую, совершенно пустую конфигурацию. После этого попробуйте сравнить в конфигураторе первоначальную конфигурацию и файл cf, сохраненный из второй конфигурации. Ожидая увидеть их полную идентичность, вы получите примерно вот это:

Все эти изменения не носят фатального характера и не влияют на работоспособность функционала (скорее всего :-)). Но они очень сильно повлияют на скорость обновления типовой конфигурации, выступая в качестве сильного "фонового шума" в общем списке отличий нового релиза от старого, в котором обычно требуется вычленить дважды измененные свойства (изменения в новом релизе и привнесенные вами) для их успешной модификации и слияния.
EDT можно прекрасно использовать для разработки новых конфигураций и/или расширений. Но в случае необходимости модификации конфигураций, находящихся на поддержке, - увольте...
Разветвленная разработка в конфигураторе
На самом деле, для решения этой задачи можно обойтись штатными средствами 1С. Причем так, как рекомендуется это делать на ИТС.
Коллега sinichenko_alex в статье "Технология разветвленной разработки конфигураций 1С" очень доходчиво и подробно поясняет что и как делать. Я не хотел бы все описывать повторно. Кому будет действительно интересно - прочтите указанную статью.
Применительно же к нашим вводным условиям и через призму рекомендаций ИТС выглядеть все должно примерно так:
- Перед разветвлением разработки желательно обновить боевую базу до последнего релиза. В процессе разветвленной разработки до слияния веток делать это нежелательно, поскольку может значительно затрудниться сам процесс слияния. А одновременно обновить и боевую базу и базу ветки не получится, поскольку в конфигурации поставщика базы ветки должна сидеть боевая конфигурация на момент разветвления.
- В определенный момент из основного хранилища (Хранилище № 1) конфигурации получаем файл поставки, на основании которого создаем центральную базу нашей новой ветки (см. статью). В последнем помещении в хранилище № 1 ставим метку, которая будет показывать нам точку разветвления. Просто для себя, на всякий случай. Особого смысла в ней нет, поскольку в конфигурации поставщика нашей ветки сидит как раз последнее состояние этого хранилища на момент разветвления.
- В этот же момент из хранилища расширения боевой базы (Хранилище № 2) получаем файл cfe, на основании которого делаем расширение в центральной базе новой ветки. Опять же, в хранилище-родителе (№ 2) помечаем меткой точку разветвления. Вот здесь это сделать уже обязательно! А еще неплохо бы сохранить этот самый исходный cfe-файл. Почему - поясню позже.
- Из центральной базы новой ветки создаем новые хранилища основной конфигурации (Хранилище № 3) и расширения (Хранилище № 4)
- В этих хранилищах (3 и 4) ведем разработку в рамках автоматизации нового контура учета.
- Параллельно в хранилищах 1 и 2 дорабатываем и исправляем ошибки боевого функционала.
- По завершении разработки и тестирования в рамках автоматизации нового контура учета обновляем основную конфигурацию ветки (Хранилище № 3) с помощью нового файла поставки, полученного из боевой конфигурации (Хранилище № 1). Как это делать подробно описано все в той же статье.
В итоге получим в хранилище № 3 все изменения боевой базы и функционал нового контура учета.
- Обновляем расширение в конфигурации ветки (хранилище № 4) с помощью исходного файла cfe, полученного в момент разветвления, и нового файла cfe, полученного из расширения боевой базы на текущий момент (хранилище № 2). Как именно это сделать проще - опишу чуть ниже.
- Тщательно тестируем "слитые" конфигурации в базе ветки.
- Обновляем основную конфигурацию и расширение в боевой базе с помощью обычного "Сравнить, объединить...", используя cf и cfe-файлы, полученные из базы ветки после пункта 9. Фиксируем изменения в хранилищах № 1 и 2. Ликвидируем базу ветки вместе с хранилищами 3 и 4.
Слияние веток расширения
Теперь вернемся к пункту 8. Дело в том, что расширения не обладают функционалом основной конфигурации в плане создания, хранения и использования при обновлениях конфигурации поставщика. В лучшем случае, в конфигураторе можно использовать сравнение/объединение для расширений.
Но при таком подходе очень легко затереть те изменения, которые были внесены в расширение в Хранилище № 2 изменениями, внесенными в Хранилище № 4.
Для качественного слияния двух веток нужна общая отправная точка - начало новой ветки из пункта 3. Чтобы сравнением с ней двух файлов cfe в настоящий момент (Хранилище № 2 и Хранилище № 4) найти тонкие места в виде дважды измененных свойств и уделить им максимальное внимание при слиянии веток.
В конфигураторе нет инструмента, способного использовать трехстороннее сравнение расширений. Но зато он есть все в том же EDT.
Я, опять же, не рекомендую использовать EDT для непосредственного объединения и последующей загрузки результата в расширение базы. Причина та же - EDT привносит свои изменения в неожиданных местах, хотя для расширения это уже не будет так критично, как для основной конфигурации.
Вот для локализации тех самых, тонких, дважды измененных мест и получения текста слитых модулей в этих самых местах EDT очень пригодится!
Итак, как же действовать:
- Получаем актуальные файлы cfe из хранилищ № 2 и 4.
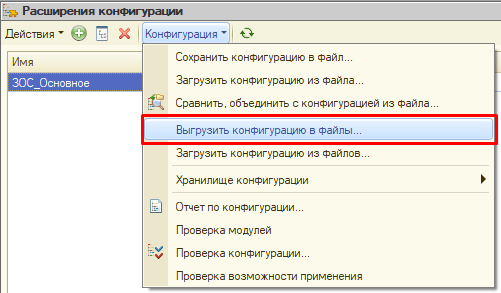
- Получаем нашу "отправную точку" - файл cfe перед разветвлением - из помеченного нашей меткой в предыдущей главе помещения в хранилище № 2 (если, конечно, вы не сохранили его еще тогда, при разветвлении):
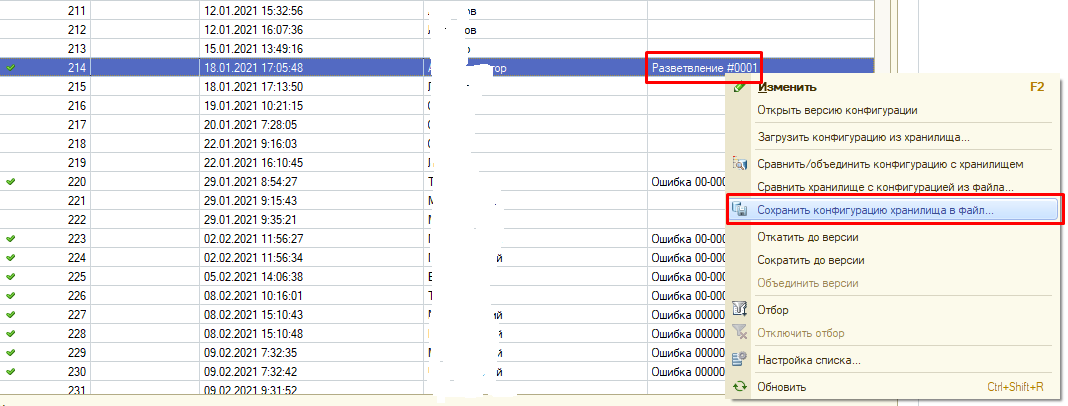
- Берем любую базу (которую вы, например, использовали для разработки) отключаем ее расширение от хранилища. После чего последовательно загружаем в расширение наши три файла и выгружаем каждый раз расширение в файлы в разные папки - "начало ветки", "боевая" и "ветка":

Наша цель - получить три папки с файлами для загрузки их в проекты EDT
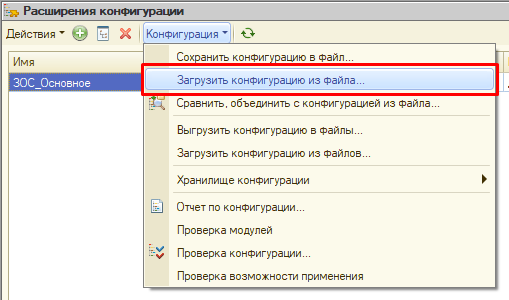
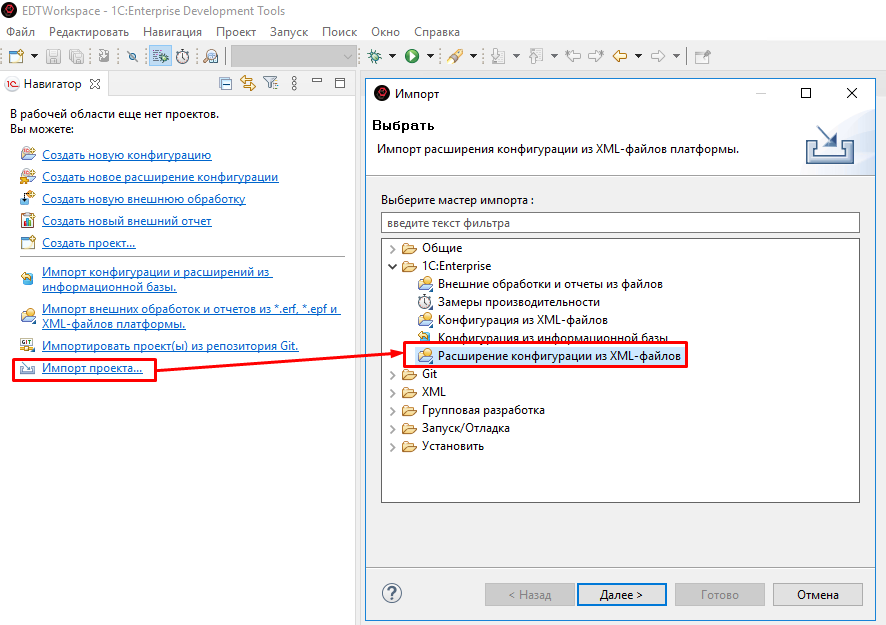
- Открываем EDT, создаем три новых проекта расширений из наших папок в одной рабочей области, указывая соответствующие наименования проектов. Проекты расширений в EDT могут существовать и без родительских проектов.
Так как объемы расширений обычно значительно меньше больших конфигураций (если, конечно, следить за ними и не допускать огульного массового расширения ненужных объектов), то проекты создаются достаточно быстро:

- Теперь осталось воспользоваться тем самым трехсторонним сравнением/объединением, ради которого все и затевалось. Выбирать главный источник для сравнения/объединения следует исходя из соображений наибольшего числа изменений в нем с момента разветвления. Для нашего случая - это проект "ветки":

- В итоге получим примерно следующую картину:
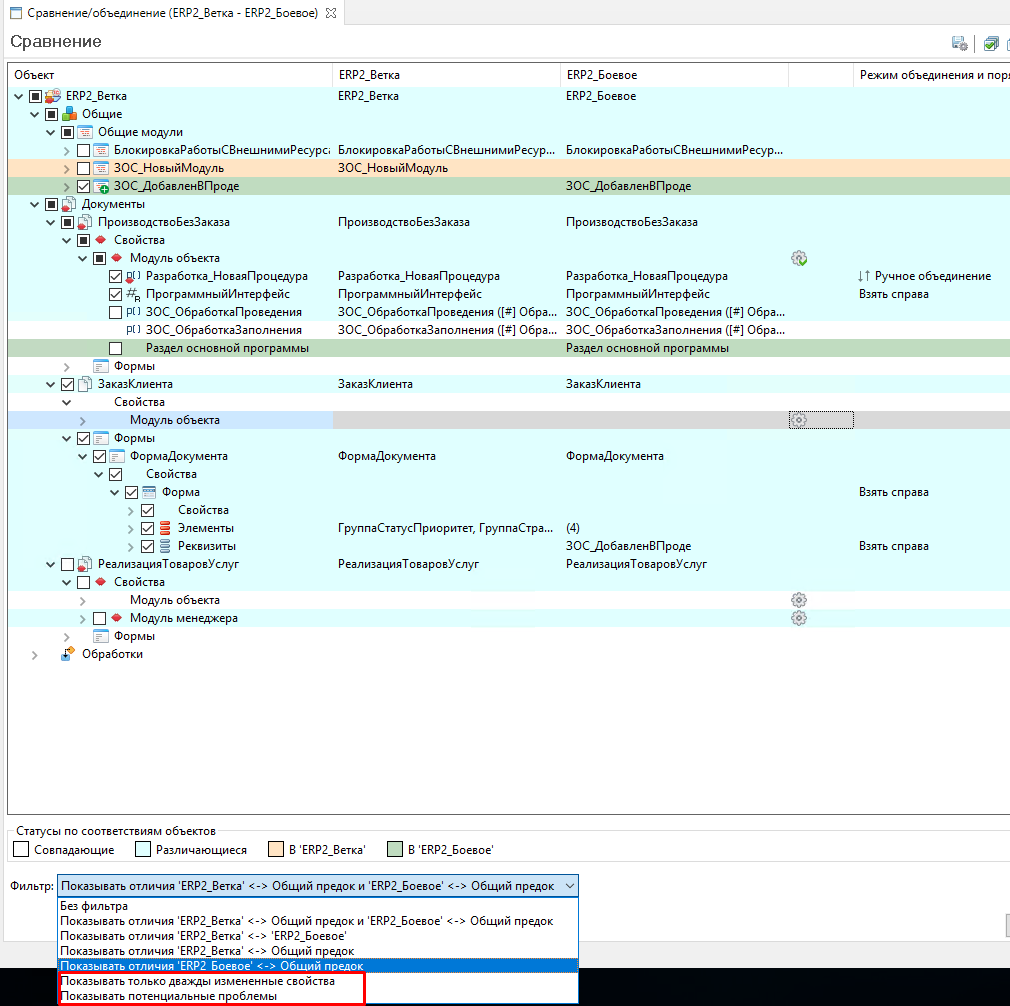
- То есть, EDT самостоятельно отметила нам объекты, которые безусловно должны быть перенесены в общее расширение. Кроме того, с помощью фильтра внизу формы сравнения можно ограничить список различий до тех объектов, объединение которых вызвало у EDT затруднение. Это как раз наши дважды измененные объекты - и в хранилище № 2, и в хранилище № 4.
Их объединение EDT предлагает провести нам вручную:
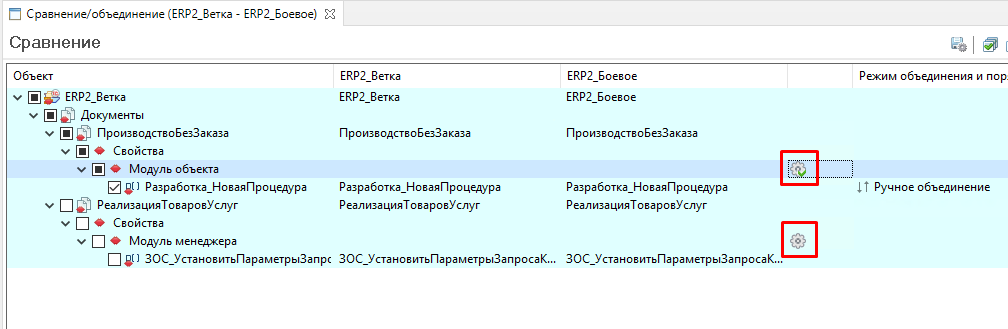
При этом предлагается использовать вполне удобный инструмент трехстороннего объединения текста модулей:
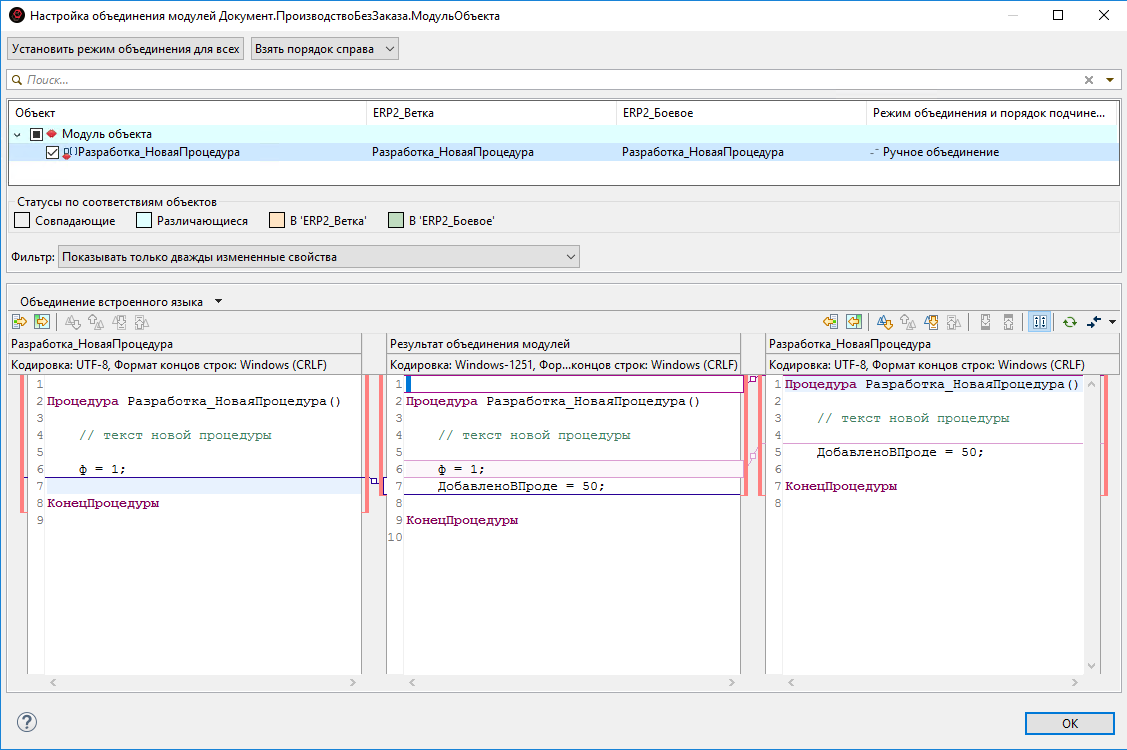
- Как я уже говорил, у нас не стоит цели получить результат объединения в проекте EDT. Нам это надо сделать в конфигураторе, а EDT нам нужен в качестве "подсказки".
Поэтому открываем конфигуратор, загружаем в конфигурацию расширения тот файл cfe, который мы получили из ветки (хранилище № 4). Запускаем сравнение/объединение расширения с файлом cfe, который мы получили из боевой базы (хранилище № 2).
Снимаем все флажки и аккуратно расставляем их в соответствии с тем, как установила нам их EDT (два монитора очень помогут!). А также аккуратно повторяем все манипуляции по ручному слиянию дважды измененных объектов:
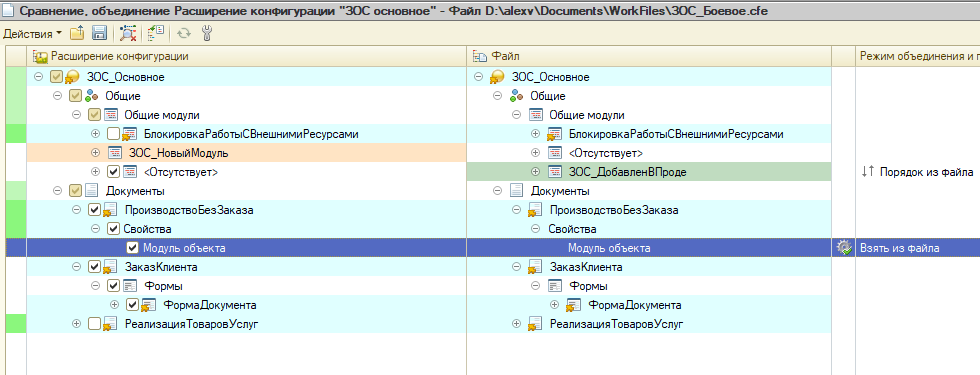
Ах, если бы можно было бы из EDT сохранить настройки объединения, а в конфигураторе применить их... Но увы, эти настройки объединения конфигуратор не понимает.
- Собственно, все. Результат объединения сохраняем в cfe, сравниваем/объединяем с ним расширение в боевой базе, помещаем все изменения в хранилище.
Послесловие
Конечно, предложенный вариант разработки не идеален и допускает определенные проблемы.
Например, разработчики могут путаться между базами и хранилищами боевой конфигурации и ветки разработки. Особенно, если нет выделенной команды для разработки ветки и одни и те же разработчики и участвуют в разработке нового функционала, и исправляют ошибки в боевом. А в условиях небольшого ИТ-отдела так обычно и бывает...
Но пока это единственный вариант, который после недолгого обсуждения был нами принят на вооружение.
Если спросите, а какие еще были, то отвечу: например, вариант с отдельным расширением для новой ветки. Но плодить несколько расширений не очень хотелось, да и доработки основной конфигурации в рамках нового функционала полностью исключить вряд ли бы получилось...
Главное, не пытаться в таком ключе разрабатывать несколько веток одновременно, тогда точно запутаемся все. Ну, да это не про наши ресурсы :-)
Всем спасибо за внимание! Особенно тем, кто осилил сей опус до конца!
Другие мои публикации, возможно, достойные вашего внимания:
- [БЕСПЛАТНО] "Откат" данных без транзакций. Расширение для легкого возврата к "исходному" или выбранному состоянию после любых изменений данных
- Быстрое формирование наборов данных Объект схемы СКД
- Комплексный контроль остатков. Для одного или сразу нескольких логически связанных регистров накопления. Универсальное решение уровня данных для контроля не только складских остатков
- Подсистема "Диспетчеризация обслуживания". Предварительная запись, планирование, регистрация и анализ этапов обслуживания или производства для любых конфигураций на платформе 8.3.6+ с использованием планировщика
- Даты запрета изменения по пользователям в режиме "Общая дата" для БП 3, ЗУП 3 и других конфигураций на УФ, использующих БСП
Вступайте в нашу телеграмм-группу Инфостарт