



Классическое для Android-разработки решение – хранить данные в SQLite обладает немалыми достоинствами и является стандартным подходом и именно поэтому это было реализовано в первую очередь. Однако основная миссия Simple UI (именно на это указывает слово simple) – максимально упростить процесс разработки и поддержки решений. А вот с этим у SQL есть проблемы. На помощь приходит NoSQL и то, как удачно его можно вписать в архитектуру с Переменными. Напомню, что вся работа с данными и командами в Simple UI происходит через стек переменных. Так вот теперь можно работать с хранимым данными просто как с переменными – не задумываясь о структуре и типизации, не зная SQL и без лишнего boilerplate кода и без необходимости парсить данные для синхронизации. Система такая простая что с ней справится даже ребенок. Я думаю это кардинально изменит ситуацию с оффлайн-разработкой на платформе и ускорит разработку offline- или offline-first-решений в разы!
В чем по моему мнению NoSQL подход выигрывает у SQL:
1.Не надо знать SQL SQL вроде язык простой, но по факту существует множество стандартов и особенностей в разных средах реализации. Например SQLite который используется в Android сильно отличается от T-SQL и в командах и в типизации
2.В SQL данные хранятся в таблицах, чтобы загрузить данных из сервера надо распарсить JSON, написать команды вставки/обновления в SQL-СУБД. А потом тоже самое проделать в обратном порядке чтобы послать данные на сервер. А в новой системе хранения вы просто помещаете JSON в СУБД командой put_ а потом достаете командой get_ Данные преобразовывать не надо.
3.Тоже самое относится к различным экранным объектам в JSON. Вам надо сделать JSON из данных таблиц СУБД чтобы отобразить его на форме Да, в SimpleUI сложные элементы экрана такие как таблица, список карточек и т.д. – хранятся в JSON их можно делать на сервере сразу и использовать как для отображения так и для хранения
4. Не надо думать как поддерживать консистентность при апдейтах, если все данные по объекту инкапсулированы в единый JSON. Когда речь идет об одной простой таблице обеспечение связанности и объем работ, который нужно сделать не так ощущается, но если это 3NF и данные документа хранятся в нескольких таблицах то вставлять/обновлять их также надо в нескольких таблицах, вот тут разница в простоте весьма ощутима.
5. Типизация в SQL сильная вещь, но что происходит когда структура данных меняется? Происходит много проблем, в то время как при JSON системе хранения каждый объект может быть со своей структурой. Пример – разные объекты ОС имеют разную структуру полей, причем даже не привязанную к видам ОС а просто могут быть индивидуальные поля.
6. Связь с внешними NoSQL СУБД (Mongo DB, CouchDB) с NoSQL – праздник, с SQL много много проблем. А зачем вообще нужны внешние NoSQL? Для того чтобы хранить файлы, картинки, видео а также сложные нетипизированные данные. Да, в SQL такой фокус не пройдет
7.Скорость записи Да, да – скорость записи в NoSQL базах выше
Но SQL обладает и преимуществами. На самом деле я не предлагаю полностью забыть про SQL – их можно использовать вместе, параллельно.
Какие преимущества есть у SQL:
1. Агрегатные функции удобнее в SQL Тут не поспоришь. Вычисление остатков товара в SQL удобнее, другое дело что например остатки товара на складе все таки правильно вычислять на сервере в 1С например, а не на локальном устройстве, так как нужно согласование с данными других участников процесса
2.WHERE и скорость поиска А тут можно поспорить. С помощью системы индексов висящих в памяти удалось сделать поиск таким же быстрым – это по сути поиск по заранее подготовленному массиву в ОЗУ «ключ-значение». Но если углубляться в частные случаи то where на текущий момент где то лучше.
Как с этим работать?
С этим работать очень просто. Все данные хранятся в СУБД по системе «ключ-значение» это могут быть простые данные(числа, строки и т.д.) или JSON-строки. Данные можно разбить по конфигурациям – под каждую конфигурацию своя СУБД, либо частично объединять либо не разбивать. Это регулируется с помощью поля «Имя базы noSQL» - его можно не заполнять вообще(все данные будут сыпаться в одну кучу).
Базовые команды
Вот все команды «базового уровня» которые есть на текущий момент. Их более чем достаточно для реализации всего того, что до этого реализовалось с sQLite.
1)Запись, чтение, удаление:
(put_ключ, переменная) - записать данные в СУБД в ключ
(get_ключ, переменная) - получить данные из СУБД из ключа в переменную. Если в обработчике есть команды get_, find_ и finindex_ система извлекает данные из СУБД в Переменные, после чего вызывает событие «_results» (как бы новый такт обработчика)
(del_ключ,) - удалить ключ
(getallkeys, переменная) - получить
2)Поиск и индексы:
(find_имяпеременной, имяполя=значение) - «условно медленный» поиск по объектам в СУБД. в «имяпеременной» возвращается JSON-массив найденных объектов. «имяполя» - имя поля в корне JSON объектов по кторому будет вестись поиск. Вид сравнение можно использовать «=»(точное сравнение) или «~»(вхождение подстроки). Значение - значение поиска.
(createindex_имяиндекса, имяполя) и (findindex_имяиндекса, имяполя=значение). Индексы - загруженные в память таблицы значение - ключ, по которым происходит более быстрый поиск. Т.е. если индекс задать заранее, поиск будет произвдиться очень быстро - ведь это поиск по массивы у памяти а не в СУБД. Поэтому где в начале, возможно при запуске конфигурации, следует создать нужные индексы командой createindex_. Далее использовать команду findindex_, где в качестве параметра поиска уже использовать имя ранее созданного индекса.
3)Очередь (аналог авторегистрации плана обмена в 1С)
Очередь используется для автоматической фиксации изменённых или добавленных объектов. Это используется например для синхронизации - всегда можно получить список ключей, измененных на устройстве, чтобы выгрузить в основную систему. Очередь пишется автоматически, но ее можно выключить например при загрузке данных из учетной системы командой («StopQueue»,»»)
_sys_queue - переменная-очередь, в которой всегда содержится список ключей объектов, разделенных через «;»
(removequeue,ключ) - удалить ключ из очереди (например, при успешной выгрузке)
Работа с переменными - еще более простой способ что то сохранить.
Можно просто записать все переменные или список переменных в СУБД, а потом извлечь. Т.е. собсвенно, вы работаете с просто переменными.
(puthasmap,списокпеременных) - записать дамп переменных в СУБД, списокпеременных - список имен переменных через «;»
(gethashmap,) - прочитать дамп переменных из СУБД в Переменные
Синхронизация с 1С

Одна из возможных схем синхронизации – передавать все через Переменные. Так как с переменными можно работать на сервере 1С в обработчике 1С то загрузка данных на устройство осуществляется в 1С, далее устройство работает с локальной СУБД с помощью скриптов Python а когда нужно загрузить в 1С это также происходит на стороне 1С. Для этого используется «Очередь» - аналог «Плана обмена» в 1С
Но! Это не единственный вариант решения. Можно просто слать/принимать JSON через REST API, брокер очередей или другим способом. Просто этот способ показался мне простым и более наглядным именно для реализации с 1С. Поэтому именно его я выбрал в качестве примера в демо базе.
В этом видео я хочу прокомментировать процесс разработки с новой системой хранения. Тут рассмотрено простое решение - Заказы поставщика из 1С выгружаются на устройство, далее происходит работа с Приемкой по заказам оффлайн, а потом факт загружается обратно в 1С. Такой пример есть для SQL реализации, сейчас это сделано на NoSQL.

Дерево технологий
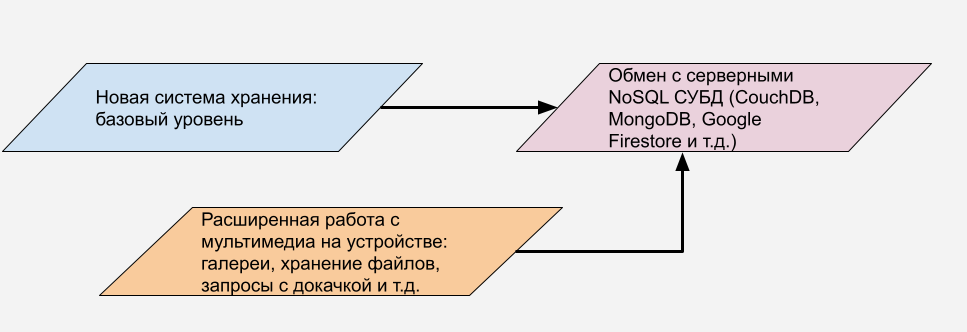
Такая система хранения открывает путь к другим замечательным возможностям - возможности совместной работы с серверными или «облачными» NoSQL СУБД такими как MongoDB Atlas, CouchDB, Couchbase практически бесшовно так как структура хранения объектов совпадает. Данные в таких СУБД хранятся как правило в JSON и все что надо – отправить уже готовый ваш JSON или принять без необходимости в преобразованиях.
Но зачем вообще нужны такие СУБД? Дело в том что в них удобно хранить неструктурированную информацию, а также большие файлы, картинки и прочее. С BLOB в SQL такая штука не проходит. Параллельно планируется доработка системы работы с мультимедиа, для совместной работы с NoSQL внутри устройства и синхронизации с другими СУБД.
Вместо заключения
Время покажет, но думаю теперь на оффлайн клиенты будет тратиться времени столько же сколько на онлайн и разрабатывать чисто он-лайн уже не будет иметь смысла. Вместо этого будет "offline first" - пишем базу и сразу отправляем на сервер в фоне либо пакетами по расписанию если есть возможность (если нет - копится в очереди, потом по возможности отправляется). Плюс какие то данные чисто всегда с сервера. Общемировая статистика по стекам разработки говорит о постоянном увеличении доли NoSQL как в серверном так и в мобильном сегменте.
Для меня очень ценно знать мнение сообщества разработчиков на Simple UI, поэтому буду крайне признателен за ваши комментарии по этой новой системе хранения - будете ли вы ее использовать, стоит ли ее развивать, что хотелось бы добавить? Или эта система не нужна, а для оффлайна достаточно SQLite?
Вступайте в нашу телеграмм-группу Инфостарт