












Наше стремление дополнять и улучшать каждый аспект бизнеса и жизни с помощью данных требует изменения парадигмы в том, как мы управляем данными в объеме. В то время как технологические достижения последнего десятилетия позволили решить проблему большого объема данных и вычислений для их обработки, они не смогли решить проблему объема в других измерениях: изменение в ландшафте данных, увеличение числа источников данных, разнообразие вариантов использования данных и пользователей и скорость реагирования на изменения. Подход сети данных (Data Mesh) учитывает эти аспекты, и основывается на четырех принципах:
- децентрализованное владение данными и архитектура, ориентированная на домен,
- данные как продукт,
- инфраструктура данных самообслуживания как платформа
- федеративное управление вычислениями
Каждый принцип определяет новый логический взгляд на техническую архитектуру и организационную структуру.
Оригинальная статья "Переход от монолитного Data Lake к распределённой Data Mesh" (оригинал) (перевод), которую я рекомендую вам прочитать, прежде чем продолжить чтение это статьи, она посвящена сегодняшним болевым точкам архитектурных и организационных проблем при организации управляемых данных, использования данных для конкуренции или использования данных в масштабе для повышения ценности. В ней предложена альтернативная перспектива, которая с тех пор привлекла внимание многих организаций и дала надежду на иное будущее. В то время как оригинальная статья описывает подход, она оставляет много деталей дизайна и реализации для вашего воображения. У меня нет намерения быть слишком предписывающий в этой статье и подавлять воображение и творческий подход к реализации сети данных. Однако я думаю, что необходимо прояснить архитектурные аспекты сети данных в качестве ступеньки для продвижения парадигмы вперед.
Эта статья написана с намерением в дальнейшем ей продолжить. В ней будет кратко изложен подход к сети данных, перечисляя его основополагающие принципы и логическую архитектуру высокого уровня, которой руководствуются принципы. Создание логической модели высокого уровня является необходимой основой, прежде чем я погружусь в подробную архитектуру основных компонентов сети данных в будущих статьях. Следовательно, если вы ищете рецепт для точных инструментов и рецептов для сетей данных, эта статья может вас разочаровать. Если вы ищете простую и технологически независимую модель, которая устанавливает общий язык, то продолжаем.
Большой разрыв в данных
Что мы на самом деле подразумеваем под данными? Ответ зависит от того, кого вы спрашиваете. Сегодняшний ландшафт делится на оперативные данные (operational data) и аналитические данные (analytical data). Оперативные данные хранятся в базах данных за бизнес-способностями, обслуживаемыми микросервисами, они имеют транзакционный характер, сохраняют текущее состояние и удовлетворяют потребности приложений, работающих в бизнесе. Аналитические данные - это временное и агрегированное представление фактов бизнеса с течением времени, часто моделируемое для получения ретроспективной или перспективной информации; на них обучают ML модели (машинного обучения) или используют в аналитических отчетах.
Современное состояние технологий, архитектуры и организационного дизайна отражает расхождение этих двух плоскостей данных - двух уровней существования, интегрированных, но отдельных. Это расхождение привело к хрупкой архитектуре. Постоянные сбои в заданиях ETL (Extract, Transform, Load) (извлечение, преобразование, загрузка) и постоянно растущая сложность лабиринта конвейеров данных - это знакомое зрелище для многих, кто пытается соединить эти две плоскости, передавая данные из плоскости операционных данных в аналитическую плоскость и обратно в операционную плоскость.
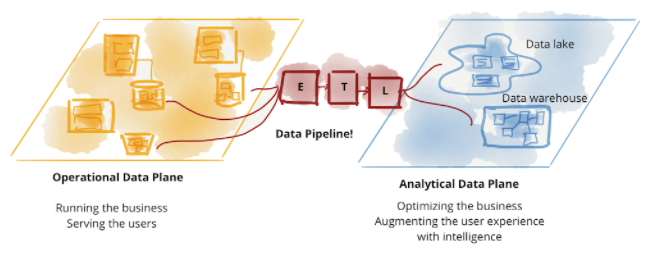
Сама аналитическая плоскость данных разделилась на две основные архитектуры и технологические стеки: озеро данных (data lake) и хранилище данных (data warehouse, DWH) (ссылка); с озером данных, поддерживающим шаблоны доступа к научным данным, и хранилищем данных, поддерживающим шаблоны доступа к аналитическим и бизнес-аналитическим отчетам. В этом разговоре я отложу в сторону танец между двумя технологическими стеками: хранилище данных, пытающееся внедрить рабочие процессы обработки данных, и озеро данных, пытающееся обслуживать аналитиков данных и бизнес-аналитику. В оригинальной статье о сети данных рассматриваются проблемы существующей архитектуры плоскости аналитических данных.
Дальнейшее разделение аналитических данных - хранилище данных:
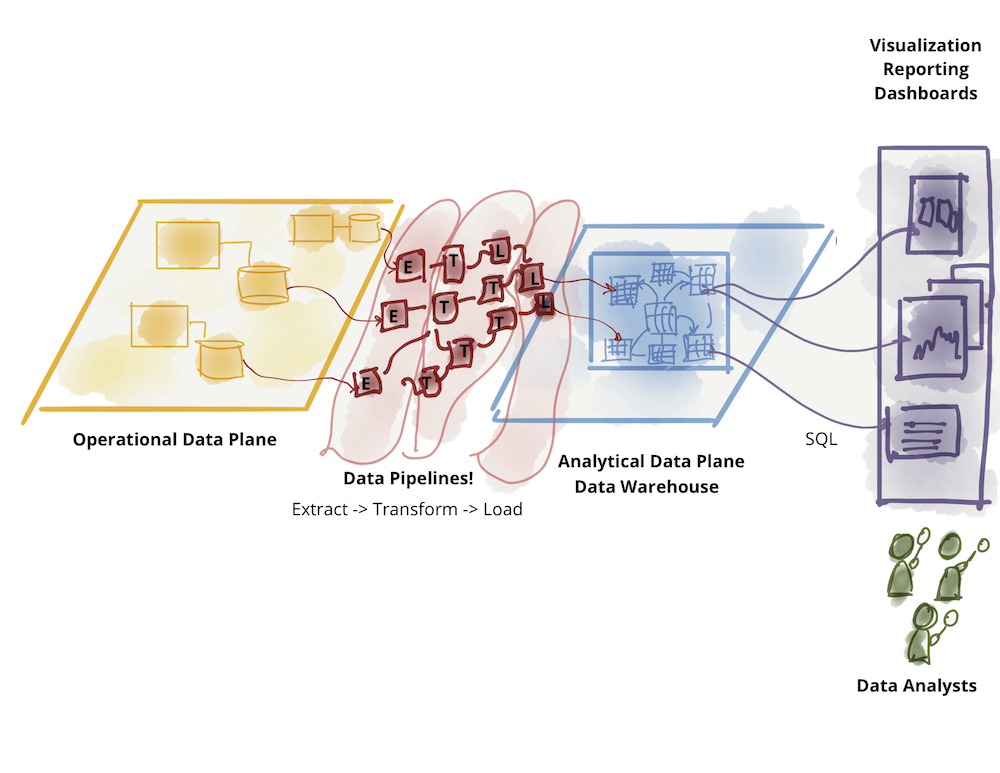
Дальнейшее разделение аналитических данных - озеро данных:

Модель сети данных признает и уважает различия между этими двумя плоскостями: природу и топологию данных, различные варианты использования, индивидуальные особенности потребителей данных и, в конечном счете, их различные схемы доступа. Однако она пытается соединить эти две плоскости в рамках другой структуры - перевернутой модели и топологии, основанной на доменах, а не на стеке технологий, с акцентом на плоскости аналитических данных. Различия в современных доступных технологиях управления двумя архетипами данных не должны приводить к разделению организации, команд и людей, работающих над ними. На мой взгляд, технологии и топологии операционных и транзакционных данных являются относительно зрелыми и в значительной степени зависят от архитектуры микросервисов; данные скрыты внутри каждого микросервиса, управляются и доступны через API-интерфейсы микросервиса. Да, есть возможности для инноваций, чтобы действительно создать многооблачные решения для операционных баз данных, но с точки зрения архитектуры это отвечает потребностям бизнеса. Однако именно управление и доступ к аналитическим данным остаются точкой трения при увеличении объема. Именно здесь фокусируется сеть данных.
Я действительно верю, что в какой-то момент в будущем наши технологии будут развиваться, чтобы еще больше сблизить эти два варианта работы с данными, но пока я предлагаю разделить их проблемы.
Основные принципы и логическая архитектура модели сети данных
Цель модели сети данных состоит в том, чтобы создать основу для получения ценности из аналитических и исторических данных в масштабе, применяемом к постоянному изменению ландшафта данных, распространению как источников данных, так и потребителей, разнообразию преобразований и обработки, которые требуются в случаях использования, скорости реагирования на изменения. Для достижения этой цели я предлагаю, чтобы было четыре основополагающих принципа, которые воплощает любая реализация сети данных для обеспечения потребностей масштабирования, обеспечивая при этом гарантии качества и целостности, необходимые для использования данных: 1) децентрализованное владение данными и архитектура, ориентированная на домен, 2) данные как продукт, 3) инфраструктура данных самообслуживания как платформа и 4) федеративное управление вычислениями.
Хотя я и ожидаю, что практика, технологии и реализация этих принципов будут меняться и совершенствоваться с течением времени, но эти принципы остаются неизменными.
Я намеренна чтобы эти четыре принципа были в совокупности необходимыми и достаточными; чтобы обеспечивали масштабирование и устойчивость при одновременном решении проблем, связанных с блокированием несовместимых данных или увеличением стоимости эксплуатации. Давайте углубимся в каждый принцип, а затем разработаем концептуальную архитектуру, которая его поддерживает.
Владение доменом (Domain Ownership)
Сеть данных, по сути, основана на децентрализации и распределении ответственности между людьми, которые находятся ближе всего к данным, чтобы поддерживать непрерывные изменения и масштабируемость. Вопрос в том, как нам разложить и децентрализовать компоненты экосистемы данных и их права собственности. Компоненты здесь состоят из аналитических данных, их метаданных и вычислений, необходимых для их обслуживания.
Сеть данных следует за границами организационных подразделений в качестве оси декомпозиции. Наши организации сегодня подразделяются на основе их бизнес-областей. Такая декомпозиция локализует влияние непрерывных изменений и эволюции, по большей части, в ограниченном контексте предметной области. Следовательно, создание ограниченного контекста бизнес-домена является хорошим кандидатом для распределения владения данными.
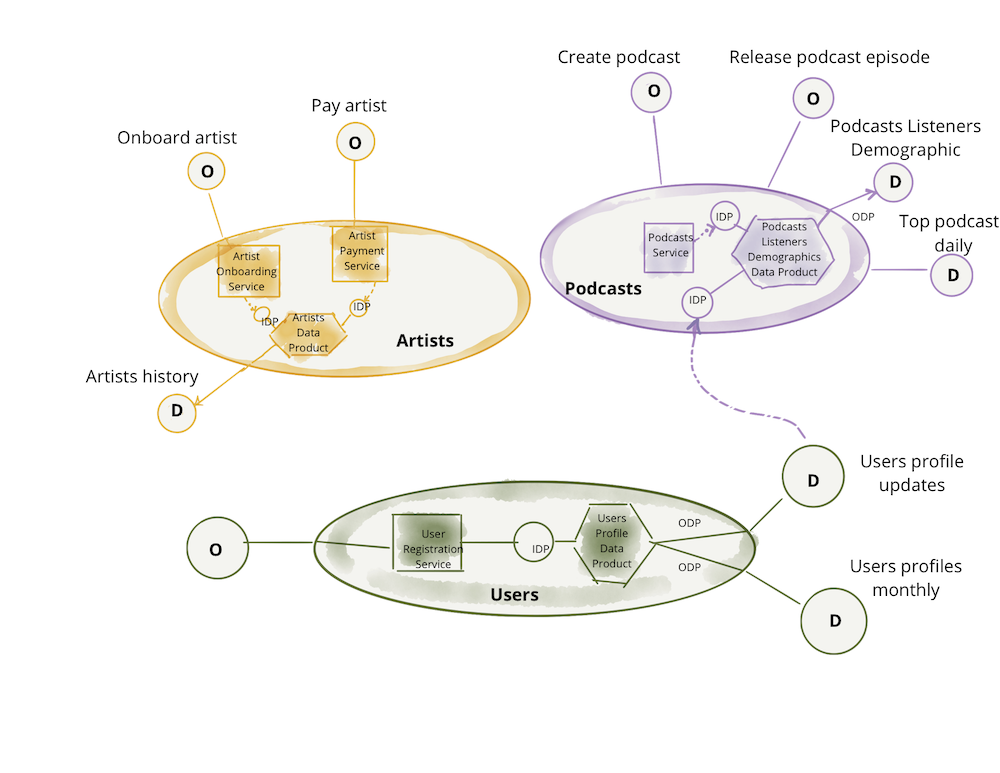
В этой статье я продолжу использовать тот же вариант использования, что и в оригинальной статье, "цифровая медиа-компания". Можно представить, что медиакомпания разделяет свою деятельность, следовательно, системы и команды, которые поддерживают эту деятельность, на основе таких доменов, как "подкасты", команды и системы, которые управляют публикацией подкастов и их размещением; "художники", команды и системы, которые управляют включением и оплатой артистов, и так далее. Модель сети данных утверждает, что владение и обслуживание аналитических данных должны соответствовать этим областям. Например, команды, которые управляют "подкастами", предоставляя API для выпуска подкастов, а также должны отвечать за предоставление исторических данных, которые представляют "выпущенные подкасты" с течением времени, связанными с другими фактами, такими как "аудитория" с течением времени. Для более глубокого понимания этого принципа см. раздел Декомпозиция и владение данными, ориентированными на домен (ссылка en).
Логическая архитектура: доменно-ориентированные данные и вычисления
Чтобы способствовать такой декомпозиции, нам необходимо смоделировать архитектуру, которая упорядочивает аналитические данные по доменам. В этой архитектуре интерфейс домена с остальной частью организации включает не только операционные возможности, но и доступ к аналитическим данным, которые обслуживает домен. Например, домен "подкасты" предоставляет операционные API для "создания нового эпизода подкаста", а также конечную точку аналитических данных для извлечения "всех данных эпизодов подкастов за последние <n> месяцев". Это означает, что архитектура должна устранять любые противоречия или стыковки, чтобы домены могли обслуживать свои аналитические данные и выпускать код для вычисления данных, независимо от других доменов. Для масштабирования архитектура должна поддерживать автономность групп домена в отношении выпуска и развертывания их операционных или аналитических систем данных.
Следующий пример демонстрирует принцип владения данными, ориентированными на домен. Диаграммы являются только логическими представлениями и являются иллюстрациями. Они не должны быть полными.
Каждый домен может предоставлять один или несколько операционных API, а также одну или несколько конечных точек доступа к аналитическим данным.

Естественно, каждый домен может иметь зависимости от точек доступа к операционных и аналитических данных других доменов. В следующем примере домен "подкасты" использует аналитические данные "обновлений пользователей" из домена "пользователи", чтобы он мог представить демографическую картину слушателей подкастов с помощью своего набора данных "Демография слушателей подкастов".

Примечание: В этом примере я использовала императивный язык для доступа к оперативным данным или возможностям, таким как "Платные исполнители". Это делается просто для того, чтобы подчеркнуть разницу между намерением получить доступ к оперативным данным и аналитическим данным. Я признаю, что на практике операционные API реализуются с помощью более декларативного интерфейса, такого как доступ к ресурсу RESTful или запросу GraphQL.
Данные как продукт
Одной из проблем существующих архитектур аналитических данных является высокая сложность и стоимость поиска, понимания, доверия и, в конечном счете, использования качественных данных. Если не решить эту проблему, она только усугубится с помощью модели сети данных, поскольку увеличивается число мест и команд, предоставляющих данные - домены. Это было бы следствием нашего первого принципа децентрализации. Принцип "Данные как продукт" предназначен для решения проблемы качества данных и устаревших хранилищ данных; или, как называет это Gartner, темные данные - “информационные активы, которые организации собирают, обрабатывают и хранят в ходе обычной деловой деятельности, но, как правило, не используют для других целей”. Аналитические данные, предоставляемые доменами, должны рассматриваться как продукт, а потребители этих данных должны рассматриваться как клиенты - счастливые и довольные клиенты.
В оригинальной статье перечисляется список возможностей, включая возможность обнаружения, безопасность, возможность исследования, понятность, надежность и т.д., которые должна поддерживать реализация модели сети данных, чтобы данные домена считались продуктом. В ней также подробно описываются такие роли, которые должны вводится в организации, такие как владелец продукта данных домена, ответственный за объективные показатели, обеспечивающие доставку данных в виде продукта. Эти показатели включают качество данных, сокращение времени обработки данных и в целом удовлетворенность пользователей данными. Владелец продукта данных домена должен иметь глубокое представление о том, кто такие пользователи данных, как они используют данные и каковы методы, с помощью которых им удобно использовать данные. Такое глубокое знание пользователей данных приводит к разработке интерфейсов продуктов обработки данных, отвечающих их потребностям. На самом деле, для большинства продуктов обработки данных в сети существует несколько обычных ролей с их уникальными инструментами и ожиданиями, аналитики данных (data analysts) и специалисты по обработке данных (data scientist). Все продукты обработки данных могут разрабатывать стандартизированные интерфейсы для их поддержки. Диалог между пользователями данных и владельцами продуктов является необходимым элементом для создания интерфейсов продуктов данных.
Каждый домен будет включать роли разработчиков продуктов данных (data product developer roles), ответственных за создание и обслуживание продуктов данных домена. Разработчики продуктов для обработки данных будут работать вместе с другими разработчиками в домене. Каждая команда домена может обслуживать один или несколько продуктов обработки данных. Также возможно сформировать новые команды для обслуживания продуктов обработки данных, которые естественным образом не вписываются в существующую операционную область.
Примечание: это перевернутая модель ответственности по сравнению с прошлыми парадигмами. Ответственность за качество данных смещается вверх по течению как можно ближе к источнику данных.
Логическая архитектура: продукт данных как архитектурный квант
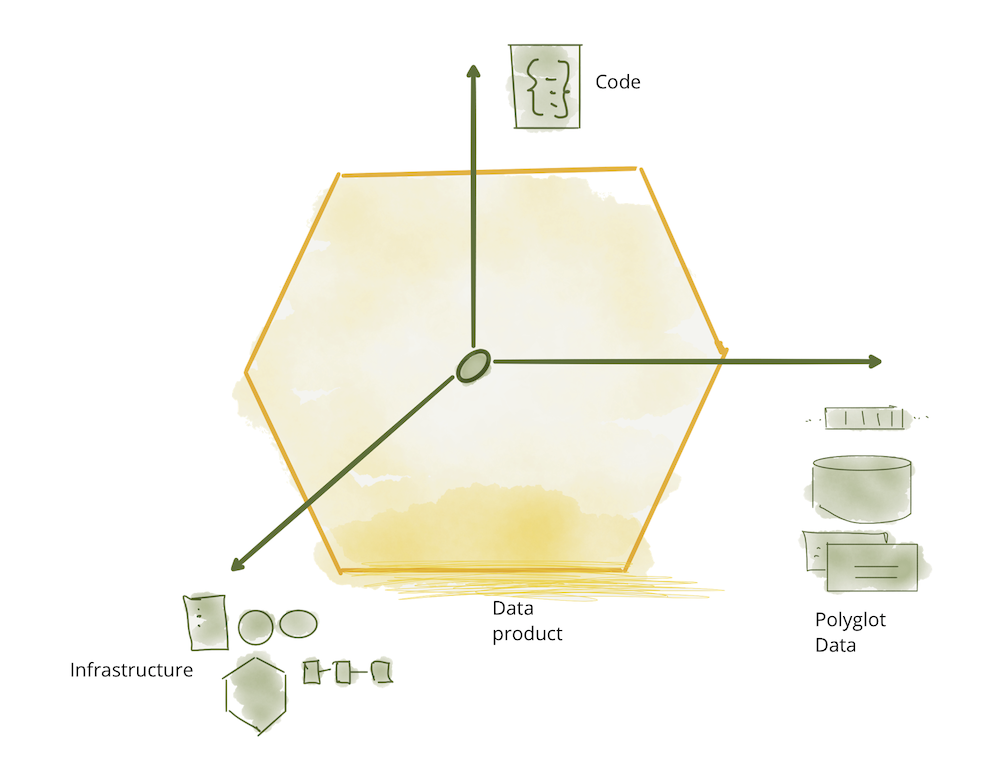
Архитектурно, для поддержки данных как продукта, который домены могут автономно обслуживать или потреблять, модель сети данных вводит концепцию продукта данных в качестве своего архитектурного кванта. Архитектурный квант, как его определяет Эволюционная архитектура, является наименьшей единицей архитектуры, которая может быть независимо развернута с высокой функциональной связностью и включает в себя все структурные элементы, необходимые для ее функционирования.
Продукт данных - это узел в сети, который инкапсулирует три структурных компонента, необходимых для его функционирования, обеспечивая доступ к аналитическим данным домена в виде продукта.
- Код: он включает в себя
- (а) код для конвейеров данных, отвечающих за потребление, преобразование и обслуживание восходящих данных - данных, полученных из операционной системы домена или восходящего продукта данных;
- (б) код для API, которые обеспечивают доступ к данным, семантической и синтаксической схеме, метрикам наблюдаемости и другим метаданным;
- (в) код для обеспечения соблюдения таких характеристик, как политики контроля доступа, соответствие, происхождение и т.д.
- Данные и метаданные: это то, для чего мы все здесь собрались, базовые аналитические и исторические данные в многоязычной форме. В зависимости от характера данных домена и его моделей потребления данные могут быть представлены в виде событий, пакетных файлов, реляционных таблиц, графиков и т.д., сохраняя при этом ту же семантику. Для использования данных существует соответствующий набор метаданных, включая документацию по вычислениям данных, семантическую и синтаксическую декларацию, показатели качества и т.д. Метаданные, которые являются неотъемлемыми для данных, например его семантическое определение и метаданные, которые передают характеристики, используемые управлением вычислениями для реализации ожидаемого поведения, например, политики контроля доступа.
- Инфраструктура: Компонент инфраструктуры позволяет создавать, развертывать и запускать код продукта данных, а также обеспечивать хранение и доступ к большим данным и метаданным.
Следующий пример основан на предыдущем разделе, демонстрируя продукт данных как архитектурный квант. Схема включает только образец содержимого и не предназначена для того, чтобы быть полной или включать все детали проектирования и реализации. Хотя это все еще логическое представление, оно приближается к физической реализации.
Обозначения: домен, его (аналитический) продукт данных и операционная система

Информационные продукты, обслуживающие аналитические данные, ориентированные на предметную область:
Примечание: Модель сети данных отличается от прошлых парадигм, в которых конвейеры (код) управляются как независимые компоненты от создаваемых ими данных; и часто инфраструктура, такая как экземпляр хранилища или учетная запись хранения озера данных (data lake), используется совместно многими наборами данных. Продукт данных представляет собой совокупность всех компонентов - кода, данных и инфраструктуры - с детализацией ограниченного контекста домена.
Платформа данных самообслуживания
Как вы можете себе представить, для создания, развертывания, выполнения, мониторинга и доступа к скромному шестиугольнику - продукту данных - существует изрядная часть инфраструктуры, которую необходимо подготовить и запустить; навыки, необходимые для обеспечения этой инфраструктуры, являются специализированными, и их будет трудно воспроизвести в каждом домене. Самое главное, что единственный способ, которым команды могут автономно владеть своими продуктами данных, - это иметь доступ к высокоуровневой абстракции инфраструктуры, которая устраняет сложности и трудности, связанные с предоставлением и управлением жизненным циклом продуктов данных. Это требует нового принципа - самостоятельной инфраструктуры данных в качестве платформы для обеспечения автономии домена.
Платформу данных можно рассматривать как расширение платформы доставки, которая уже существует для запуска и мониторинга сервисов. Однако базовый технологический стек для работы с продуктами обработки данных сегодня сильно отличается от платформы доставки сервисов. Это просто связано с расхождением стеков технологий больших данных с операционными платформами. Например, команды домена могут развертывать свои службы в виде контейнеров Docker, а платформа доставки использует Kubernetes для их согласования; Однако соседний продукт обработки данных может запускать свой код конвейера в качестве заданий Spark в кластере Databricks. Это требует подготовки и подключения двух совершенно разных наборов инфраструктуры, которые до создания сети данных не требовали такого уровня совместимости и взаимосвязанности. Я лично надеюсь, что мы увидим сближение операционной инфраструктуры и инфраструктуры данных там, где это имеет смысл. Например, возможно, запустить Spark в той же системе оркестровки, например, Kubernetes.
На самом деле, чтобы сделать разработку продуктов для анализа данных доступной для разработчиков широкого профиля, для существующего профиля разработчиков, который есть в доменах, платформа самообслуживания должна предоставить новую категорию инструментов и интерфейсов дополненную упрощенным вариантом поставки. Платформа данных с самообслуживанием должна создавать инструменты, которые поддерживают рабочий процесс разработчика продукта данных домена по созданию, обслуживанию и запуску продуктов данных с менее специализированными знаниями, которые предполагают существующие технологии; инфраструктура самообслуживания должна включать возможности для снижения текущих затрат и специализации, необходимых для создания продуктов обработки данных. Первоначальная запись включает в себя список возможностей, предоставляемых платформой данных самообслуживания, включая доступ к масштабируемому хранилищу данных на многих языках, схеме продуктов данных, объявлению и согласованию конвейера данных, происхождению продуктов данных, вычислениям и местоположению данных и т.д.
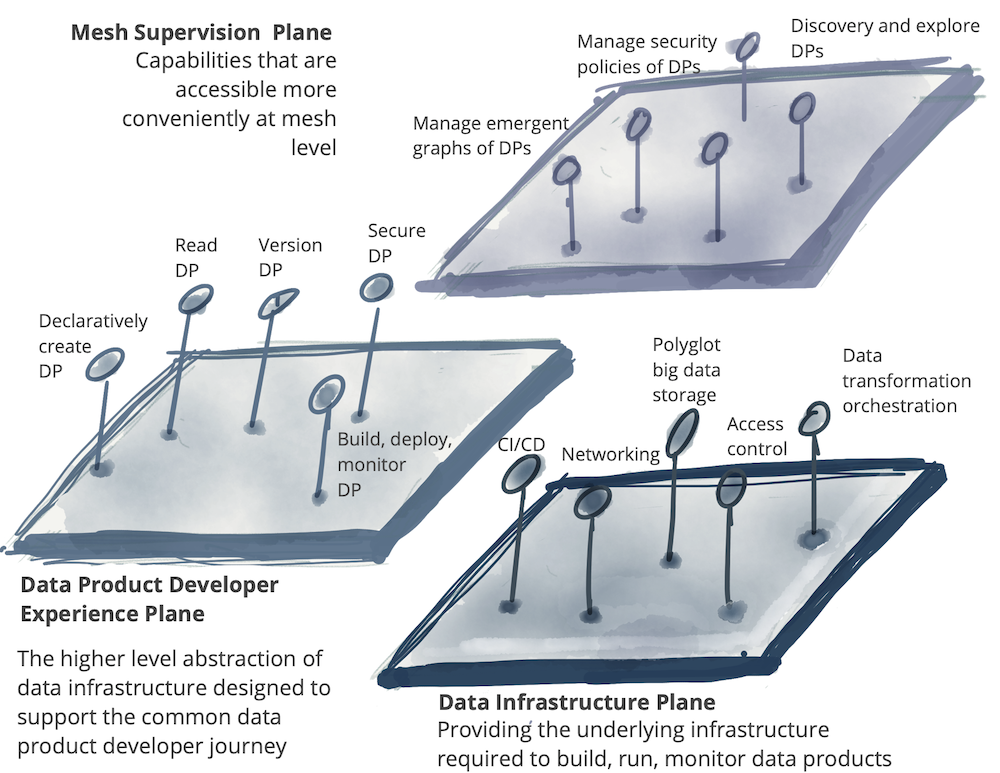
Логическая архитектура: многоплоскостная платформа данных
Возможности платформы самообслуживания подразделяются на несколько категорий или плоскостей, как это называется в модели. Примечание: Плоскость представляет уровень существования - интегрированный, но отдельный. Аналогично физическим планам и планам сознания, или планам управления и передачи данных в сетях. Плоскость не является ни слоем, ни подразумевает сильную иерархическую модель доступа.
Обозначение: Плоскость платформы, которая предоставляет ряд связанных возможностей через интерфейсы самообслуживания

Платформа самообслуживания может иметь несколько плоскостей, каждая из которых обслуживает разные профили пользователей. В следующем примере перечислены три различные плоскости платформы данных:
Уровень подготовки инфраструктуры данных: поддерживает подготовку базовой инфраструктуры, необходимой для запуска компонентов продукта данных и сетки продуктов. Это включает в себя предоставление распределенного хранилища файлов, учетных записей хранения, системы управления доступом, согласование для запуска внутреннего кода продуктов данных, предоставление механизма распределенных запросов на графике продуктов данных и т.д. Я бы ожидал, что либо другие плоскости платформы данных, либо только продвинутые разработчики продуктов для обработки данных напрямую используют этот интерфейс. Это довольно низкоуровневый уровень управления жизненным циклом инфраструктуры данных.
Уровень опыта разработчика продукта данных: это основной интерфейс, который использует типичный разработчик продукта данных. Этот интерфейс абстрагирует многие сложности, связанные с поддержкой рабочего процесса разработчика продукта данных. Он обеспечивает более высокий уровень абстракции, чем "уровень подготовки". Он использует простые декларативные интерфейсы для управления жизненным циклом продукта данных. Он автоматически реализует сквозные задачи, которые определены как набор стандартов и глобальных конвенций, применяемых ко всем продуктам данных и их интерфейсам.
Плоскость наблюдения за сетью данных: существует набор возможностей, которые лучше всего предоставляются на уровне сети - график подключенных продуктов данных - во всем мире. Хотя реализация каждого из этих интерфейсов может зависеть от возможностей отдельных продуктов обработки данных, удобнее предоставлять эти возможности на уровне сети. Например, возможность находить продукты данных для конкретного случая использования, это лучше всего обеспечивается поиском или просмотром сети продуктов данных; или сопоставление нескольких продуктов данных для создания понимания более высокого порядка лучше всего обеспечивается путем выполнения семантического запроса данных, который может работать с несколькими продуктами данных в сетке.
Следующая модель является лишь иллюстративной и не претендует на полноту. Хотя иерархия планов желательна, ниже не подразумевается строгого наслоения.
Несколько плоскостей платформы данных самообслуживания, *DP означает продукт данных
Федеративное управление вычислениями
Как вы можете видеть, модель сети данных соответствует архитектуре распределенной системы; набор независимых продуктов данных с независимым жизненным циклом, созданных и развернутых независимыми командами. Однако в большинстве случаев использования для получения ценности в формах наборов данных более высокого порядка, аналитических данных или машинного обучения, необходимо чтобы эти независимые продукты данных взаимодействовали, чтобы иметь возможность сопоставлять их, создавать объединения, находить пересечения, создавать другие схемы или оперировать над ними в масштабе. Для того чтобы любая из этих операций была возможной, реализация сети данных требует модели управления, которая включает децентрализацию и независимость домена, совместимость посредством глобальной стандартизации, динамическую топологию и, что наиболее важно, автоматизированное выполнение решений платформой. Я называю это федеративным управлением вычислениями. Модель принятия решений, возглавляемая федерацией владельцев продуктов данных домена и владельцев продуктов платформы данных, с автономией и полномочиями по принятию решений на уровне домена, при создании и соблюдении набора глобальных правил - правил, применяемых ко всем продуктам данных и их интерфейсам - для обеспечения здоровой и совместимой экосистемы. Перед группой стоит сложная задача: поддержание равновесия между централизацией и децентрализацией; какие решения необходимо локализовать в каждом домене и какие решения следует принимать глобально для всех доменов. В конечном счете глобальные решения преследуют одну цель - обеспечение совместимости и усиление сетевого эффекта за счет обнаружения и компоновки продуктов данных.
Приоритеты управления в сетке данных отличаются от традиционного управления системами управления аналитическими данными. В то время как они оба в конечном счете стремятся извлечь выгоду из данных, традиционное управление данными пытается достичь этого за счет централизации процесса принятия решений и создания глобального канонического представления данных с минимальной поддержкой изменений. Сетки данных, напротив, объединяют управление вычислениями, охватывая изменения и различные интерпретирующие контексты.
Помещение системы в смирительную рубашку постоянства может привести к развитию хрупкости.
- Кроуфорд Стэнли Холлинг, Эколог
Логическая архитектура: вычислительные политики, встроенные в сеть
Вспомогательная организационная структура, модель стимулирования и архитектура необходимы для функционирования модели федеративного управления: для принятия глобальных решений и стандартов взаимодействия при уважении к автономии локальных доменов и эффективной реализации глобальной политики.
Обозначения: федеративная модель управления вычислениями
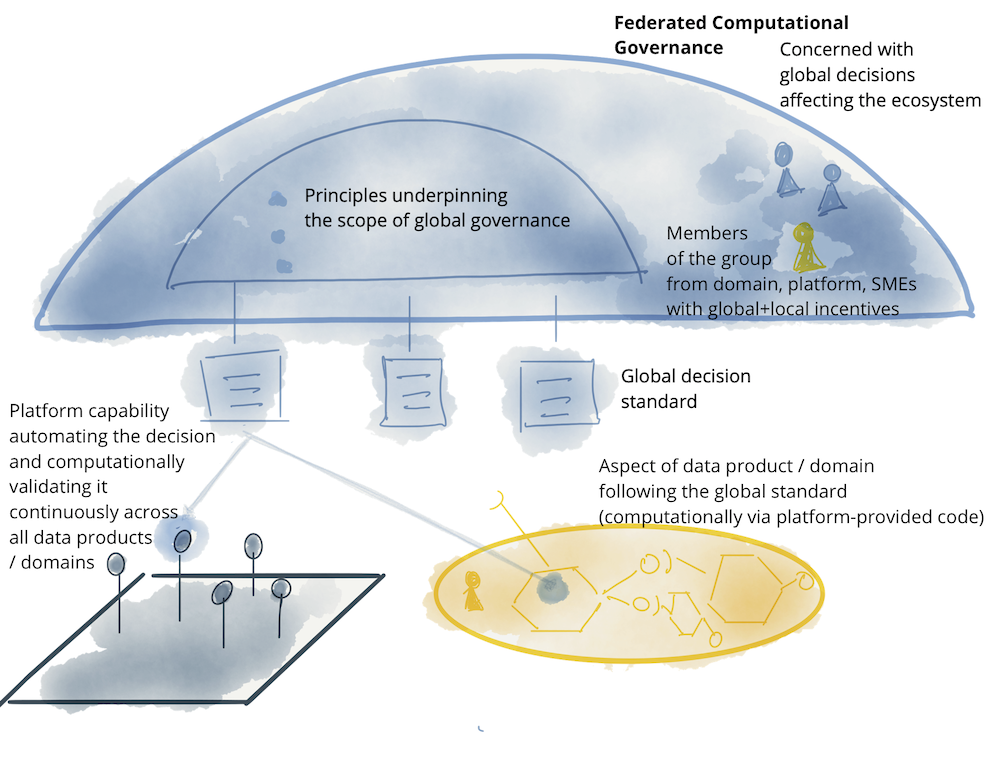
Как упоминалось ранее, достижение баланса между тем, что должно быть стандартизировано глобально, внедрено и внедрено платформой для всех доменов и их продуктов данных, и тем, что должно быть оставлено на усмотрение доменов, является искусством. Например, модель данных домена - это проблема, которая должна быть локализована в домене, который наиболее хорошо с ней знаком. Например, определение семантики и синтаксиса модели данных "аудитория подкастов" должно быть предоставлено команде "домен подкастов". Однако, в отличие от этого, решение о том, как идентифицировать "слушателя подкаста", является глобальной проблемой. Слушатель подкаста - это член группы "пользователей" - ее контекст, ограниченный восходящим потоком, - который может пересекать границы доменов и быть найден в других доменах, таких как "потоки воспроизведения пользователей". Единая идентификация позволяет сопоставлять информацию о "пользователях", которые являются одновременно "слушателями подкастов" и "слушателями стримов".
Ниже приведен пример из элементов, участвующих в модели управления сетью данных. Это не исчерпывающий пример, а лишь демонстрация проблем, актуальных на глобальном уровне.
Пример элементов объединенного управления вычислениями: команды, стимулы, автоматизированная реализация и глобально стандартизированные аспекты сетки данных

Многие методы управления предшествующие модели сети данных, такие как централизованная функция, больше не применимы к парадигме сети данных. Например, прежний акцент на сертификации "золотых наборов данных" - наборов данных, прошедших централизованный процесс контроля качества и сертификации и отмеченных как заслуживающие доверия - в качестве центральной функции управления больше не актуален. Это было связано с тем фактом, что в предыдущих парадигмах управления данными данные - в любом качестве и формате - извлекались из баз данных операционной области и централизованно хранились на складе или в озере, что теперь требует централизованной команды для применения к ним процессов очистки, согласования и шифрования; часто под опекой группы централизованного управления. Сеть данных полностью децентрализует эту проблему. Набор данных домена становится продуктом данных только после того, как он локально, в пределах домена, проходит процесс обеспечения качества в соответствии с ожидаемыми показателями качества продукта данных и правилами глобальной стандартизации. Владельцы продуктов данных домена лучше всего могут решить, как измерить качество данных своего домена, зная в первую очередь детали операций домена, производящих данные. Несмотря на такое локализованное принятие решений и автономию, они должны соответствовать моделированию качества и спецификации SLO (Service Level Objectives, Цели уровня обслуживания) на основе глобального стандарта, определенного командой глобального федеративного управления и автоматизированного платформой.
В следующей таблице показан контраст между централизованной (озеро данных, хранилище данных) моделью управления данными и сетью данных.
| Аспекты управления до сети данных | Аспекты управления сети данных |
|---|---|
| Централизованная команда | Федеративная команда |
| Ответственный за качество данных | Ответственный за определение того, как моделировать то, что составляет качество |
| Ответственный за безопасность данных | Отвечает за определение аспектов безопасности данных, т. е. уровней чувствительности данных платформы, которые будут автоматически встроены и отслеживаться |
| Ответственный за соблюдение правил | Отвечает за определение нормативных требований к платформе для автоматического встраивания и мониторинга |
| Централизованное хранение данных | Федеративное хранение данных по доменам |
| Ответственный за глобальное каноническое моделирование данных | Отвечает за моделирование полисемий (многозначность, многовариантность) - элементов данных, которые пересекают границы нескольких доменов |
| Команда независима от доменов | Команда состоит из представителей доменов |
| Стремление к четко определенной статической структуре данных | Стремление обеспечить эффективную работу сети, охватывающее постоянно меняющуюся и динамическую топологию |
| Централизованная технология, используемая монолитным озером/хранилищем | Технологии платформы самообслуживания, используемые каждым доменом |
| Измерение успешности на основе количества или объема управляемых данных (таблиц) | Измерение успешности на основе сетевого эффекта - соединений, представляющих потребление данных в сети |
| Ручной процесс с вмешательством человека | Автоматизированные процессы, реализуемые платформой |
| Предотвращение ошибок | Обнаружение ошибок и восстановление с помощью автоматизированной обработки платформы |
Краткое изложение принципов и логическая архитектура высокого уровня
Давайте сведем все это воедино, мы обсудили четыре принципа, лежащих в основе сетки данных:
| Децентрализованное владение данными и архитектура, ориентированные на домен | Чтобы экосистема, создающая и потребляющая данные, могла масштабироваться по мере увеличения числа источников данных, числа вариантов использования и разнообразия моделей доступа к данным просто увеличивая автономные узлы в сети. |
| Данные как продукт | Чтобы пользователи данных могли легко находить, понимать и безопасно использовать высококачественные данные с приятным опытом; данные, которые распределены по многим доменам. |
| Инфраструктура данных самообслуживания как платформа | Чтобы команды домена могли создавать и использовать продукты данных автономно, используя абстракции платформы, скрывая сложность создания, выполнения и поддержки безопасных и совместимых продуктов данных. |
| Федеративное управление вычислениями | Чтобы пользователи данных могли получать выгоду от агрегирования и корреляции независимых продуктов данных, сеть ведет себя как экосистема, следуя глобальным стандартам взаимодействия; стандартам, которые вычислительно интегрированы в платформу. |
Эти принципы управляют логической архитектурной моделью, которая, хотя и сближает аналитические данные и оперативные данные в одной и той же области, учитывает лежащие в их основе технические различия. Такие различия включают в себя, где могут размещаться аналитические данные, различные компьютерные технологии для обработки операционных и аналитических услуг, различные способы запроса и доступа к данным и т.д.
Логическая архитектура подхода к сети данных:
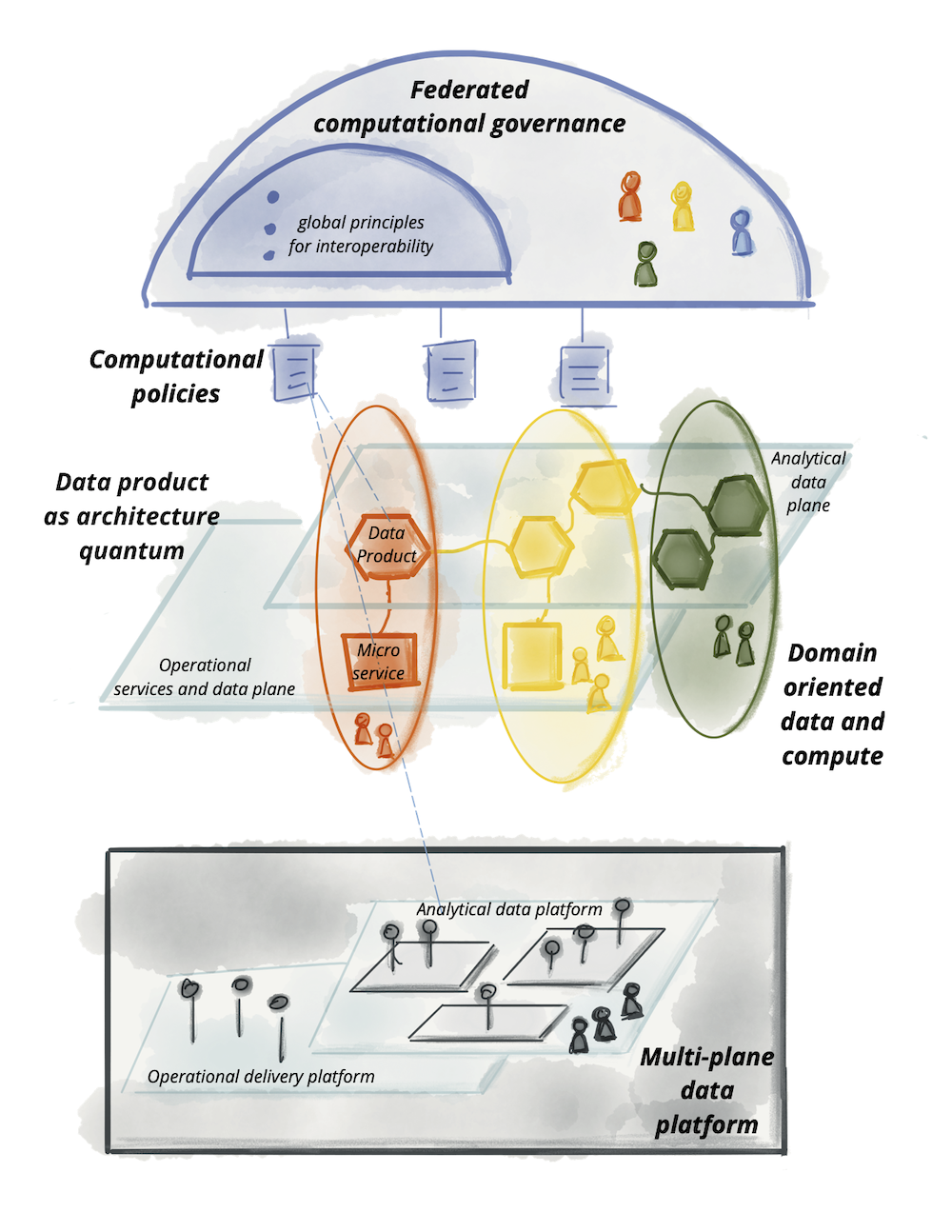
Я надеюсь, что к этому моменту мы уже выработали общий язык и логическую ментальную модель, которую мы сможем коллективно использовать для детализации схемы компонентов сетки, таких как продукт данных, платформа и необходимые стандартизации.
Переведено с использованием Яндекс.Переводчик.