





{kind=link}
Однажды передо мной встала задача выгрузить в гит многолетнюю историю версий хранилища - больше 3 тысяч версий. Решение в лоб - расчехляем старый добрый gitsync и натравливаем его на хранилище. Конфигурации уровня ERP скачиваются долго - и это большая проблема. Частично выгрузку можно ускорить, разделив выгрузку версий хранилища и обработку их для выгрузки в гит (как описано в моей статье Devops на коленке). Но все равно это очень долго.
Одно из возможных решений - распараллелить обработку версий хранилища, запустить выгрузку в разные ветки гита разных версий (например 1-1000, 1001-2000, 2001-3000 и тд), а потом сделать rebase силами git. Это тоже не очень быстрая операция. Параллельность обработки версий хранилища можно обеспечить вручную - запустив нужные команды в разных окошках консоли, а потом следить за их выполнением, не очень-то удобно.
А мы знаем, что с версии 1.6.0 в oscript появилась возможность использовать фоновые задания. Синтаксис работы с ними чуть отличается от 1С, но принцип схож - создаем массив с параметрами и вместе с именем выполняемой процедуры передаем его менеджеру фоновых заданий, затем можно ожидать завершения выполнения либо всех фоновых заданий, либо одного (оставлю ссылку на документацию, там все предельно понятно написано - Фоновое задание).
Попробую написать скрипт с фоновыми заданиями, который выгрузит версии хранилища в несколько потоков.
Скрипт многопоточной загрузки версий хранилища
Сформирую таблицу для управления потоками загрузки, в ее строчках будут лежать номера версий хранилища, также предусмотрим поля для хранения времени начала и окончания загрузки и статуса. В функцию заполнения таблицы передам начальный и конечный номер версии хранилища.
Функция ТаблицаВерсийДляЗагрузки(НачальныйНомер, КонечныйНомер)
ТаблицаВерсий = Новый ТаблицаЗначений;
ТаблицаВерсий.Колонки.Добавить("НомерВерсии");
ТаблицаВерсий.Колонки.Добавить("Статус");
ТаблицаВерсий.Колонки.Добавить("ДатаНачалаЗагрузки");
ТаблицаВерсий.Колонки.Добавить("ДатаЗавершенияЗагрузки");
Счетчик = НачальныйНомер;
Пока Счетчик <= КонечныйНомер Цикл
НоваяСтрока = ТаблицаВерсий.Добавить();
НоваяСтрока.НомерВерсии = Счетчик;
НоваяСтрока.Статус = "Не обработана";
Счетчик = Счетчик + 1;
КонецЦикла;
Возврат ТаблицаВерсий;
КонецФункции
Чуть не забыл, хранилище 1С под одним и тем же пользователем не может работать одновременно с несколькими базами - значит нам надо создать несколько пользователей в хранилище и передать в скрипт описание этих пользователей.
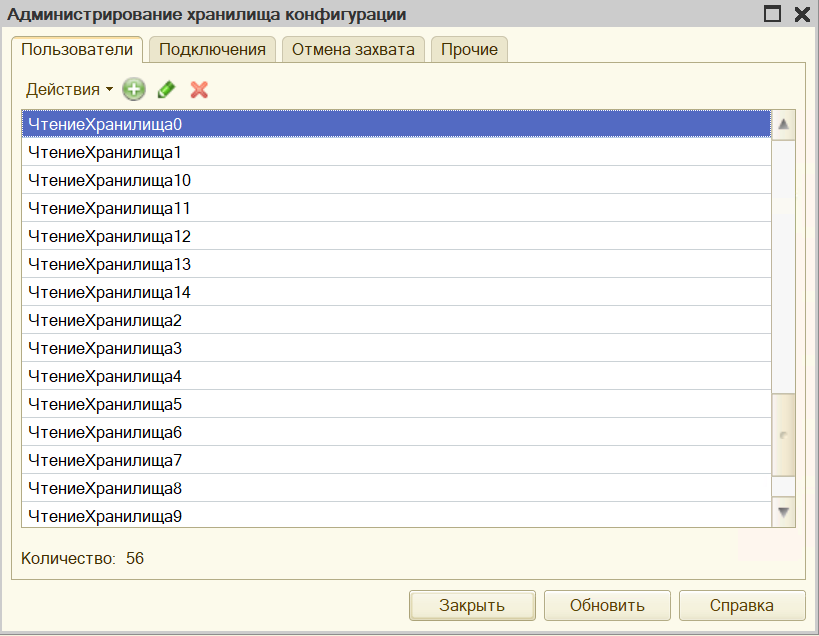
Здесь я создал пользователей без паролей и каких-либо прав с именем по шаблону "ЧтениеХранилищаНомер". В функции получения массива пользователей беру пользователя, начиная с нулевого (ну программист я, что поделаешь) и заканчивая нужным количеством (вынес количество пользователей хранилища в переменную - пригодится дальше, когда буду экспериментировать).
Функция МассивПользователейХранилища(КоличествоПользователейХранилища)
Результат = Новый Массив;
СчетчикПользователей = 0;
Пока СчетчикПользователей <= КоличествоПользователейХранилища Цикл
Результат.Добавить(СтрШаблон("%1%2", ИмяПользователяХранилища, СчетчикПользователей));
СчетчикПользователей = СчетчикПользователей + 1;
КонецЦикла;
Возврат Результат;
Конецфункции
Один поток - это один пользователь. При создании фонового задания буду исключать из массива пользователя, который в этом фоновом задании выгружает версию. При окончании фонового задания - верну его пользователя в массив для дальнейшего использования. И теперь все просто - обхожу циклом таблицу версий и создаю фоновое задание с выгрузкой. Когда доступные пользователи (потоки) кончаются, ожидаю завершения работы любого фонового, затем продолжаю обход таблицы.
ТаблицаВерсий = ТаблицаВерсийДляЗагрузки(1, 15);
МассивТекущихЗаданий = Новый Массив;
КоличествоПользователейХранилища = 8;
СвободныеПользователи = МассивПользователейХранилища(КоличествоПользователейХранилища);
Для Каждого СтрокаВерсии Из ТаблицаВерсий Цикл
Если МассивТекущихЗаданий.Количество() = КоличествоПользователейХранилища Тогда
ОжидатьВыполненияЛюбогоЗаданияЗагрузки(МассивТекущихЗаданий, ТаблицаВерсий, СвободныеПользователи);
КонецЕсли;
СтрокаВерсии.Статус = "Отправлена на загрузку";
СтрокаВерсии.ДатаНачалаЗагрузки = ТекущаяДата();
ДобавитьЗаданиеЗагрузки(СтрокаВерсии.НомерВерсии, МассивТекущихЗаданий, СвободныеПользователи);
КонецЦикла;
Добавление задания загрузки для лаконичности вынес в отдельную процедуру:
Процедура ДобавитьЗаданиеЗагрузки(НомерВерсии, МассивЗаданий, СвободныеПользователи)
МассивПараметров = Новый Массив;
МассивПараметров.Добавить(СвободныеПользователи[0]);
МассивПараметров.Добавить(НомерВерсии);
МассивЗаданий.Добавить(ФоновыеЗадания.Выполнить(ЭтотОбъект, "СохранитьВерсию", МассивПараметров));
СвободныеПользователи.Удалить(0);
КонецПроцедуры
Ну и приведу листинг процедуры СохранитьВерсию, это простое использование библиотеки v8storage.
Процедура СохранитьВерсию(Пользователь, НомерВерсии) Экспорт
ИмяФайлаКофигурации = СтрШаблон("%1\%2.cf", КаталогСохранения, НомерВерсии);
ВременноеИмяФайлаКофигурации = СтрШаблон("%1\%2.tmp", КаталогСохранения, НомерВерсии);
ХранилищеКонфигурации = Новый МенеджерХранилищаКонфигурации();
ХранилищеКонфигурации.УстановитьПутьКХранилищу(ПутьКХранилищу);
ХранилищеКонфигурации.УстановитьПараметрыАвторизации(Пользователь, "");
ХранилищеКонфигурации.СохранитьВерсиюКонфигурацииВФайл(НомерВерсии, ВременноеИмяФайлаКофигурации);
ПереместитьФайл(ВременноеИмяФайлаКофигурации, ИмяФайлаКофигурации);
КонецПроцедуры
В процедуре ОжидатьВыполненияЛюбогоЗаданияЗагрузки я ожидаю завершения любого фонового задания, возвращаю используемого там пользователя хранилища в пул свободных пользователей и дозаполняю таблицу версий - проставляю время завершения загрузки и ее результат.
Процедура ОжидатьВыполненияЛюбогоЗаданияЗагрузки(МассивТекущихЗаданий, ТаблицаВерсий, СвободныеПользователи)
ИндексЗавершившегося = ФоновыеЗадания.ОжидатьЛюбое(МассивТекущихЗаданий);
Задание = МассивТекущихЗаданий[ИндексЗавершившегося];
ПараметрыЗадания = Задание.Параметры;
Пользователь = ПараметрыЗадания[0];
СвободныеПользователи.Добавить(Пользователь);
НомерВерсии = ПараметрыЗадания[1];
Если ЗначениеЗаполнено(Задание.ИнформацияОбОшибке) Тогда
Загружена = "Ошибка";
Сообщить(Задание.ИнформацияОбОшибке.ПодробноеОписаниеОшибки());
Иначе
Загружена = "Загружена";
КонецЕсли;
НайденныеСтроки = ТаблицаВерсий.НайтиСтроки(Новый Структура("НомерВерсии", НомерВерсии));
Для Каждого СтрокаТаблицы Из НайденныеСтроки Цикл
СтрокаТаблицы.Статус = Загружена;
СтрокаТаблицы.ДатаЗавершенияЗагрузки = ТекущаяДата();
КонецЦикла;
МассивТекущихЗаданий.Удалить(ИндексЗавершившегося);
КонецПроцедуры
Полный текст скрипта вы можете найти на гитхабе RepoToCFBackgroundTask.
Запускаю его:
oscript .\toCF\RepoToCFBackgroundTask.os
Работает! Процесс oscript породил кучу процессов 1С. Вот скрин из ProcessExplorer от Sysinternals
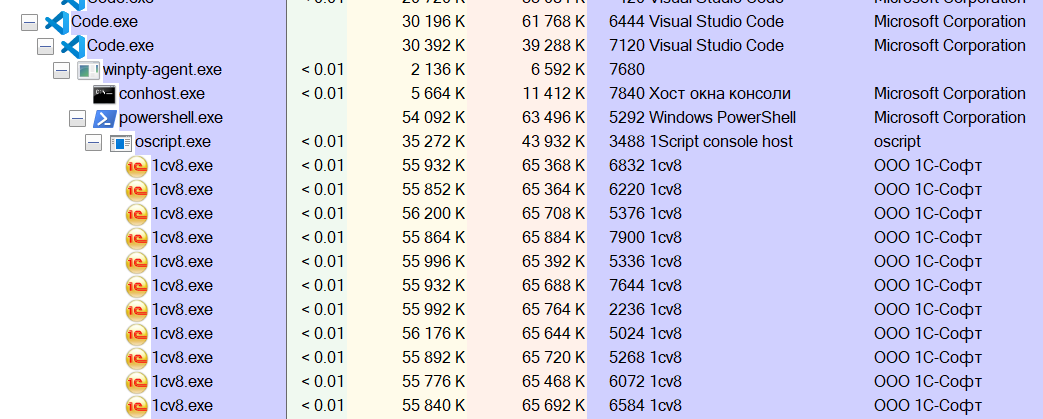
Да, в конце выполнения скрипта можно посмотреть отладкой таблицу значений ТаблицаВерсий, а можно вывести ее строки в консоль, чтобы посмотреть динамику загрузки.
Эксперименты с многопоточной загрузкой версий хранилища
Ну и теперь самое интересное - эксперименты!
Эксперименты проводил на отдельной виртуальной машине, не загруженной больше ничем. Хранилище находится рядом в локальной сети, подключение по TCP. Я скачивал первые 50 версий нашей основной рабочей конфигурации - ERP. На тот момент это была версия 2.4.5.83, размер CF - в районе 1.3 Гб.
Выгрузка одной версии занимает в среднем 5 минут. Я очищал каталог загрузки и запускал загрузку в n потоков, от 1 до 14, так три раза. Усредненное время загрузки вывел в таблицу. Прошу ознакомиться с моими результатами.
| Потоков | Общее время, минут | На 1 версию абсолютное, сек | На 1 версию в потоке, мин |
| 1 | 225,3 | 270,4 | 4,5 |
| 2 | 175,1 | 210,1 | 7,0 |
| 3 | 122,5 | 147,0 | 7,4 |
| 4 | 104,8 | 125,8 | 8,4 |
| 5 | 88,6 | 106,3 | 8,9 |
| 6 | 80,7 | 96,8 | 9,7 |
| 7 | 75,5 | 90,6 | 10,6 |
| 8 | 70,9 | 85,1 | 11,3 |
| 9 | 67,9 | 81,5 | 12,2 |
| 10 | 65,9 | 79,1 | 13,2 |
| 11 | 64,6 | 77,5 | 14,2 |
| 12 | 63,9 | 76,7 | 15,3 |
| 13 | 62,3 | 74,8 | 16,2 |
| 14 | 61,6 | 73,9 |
17,2 |
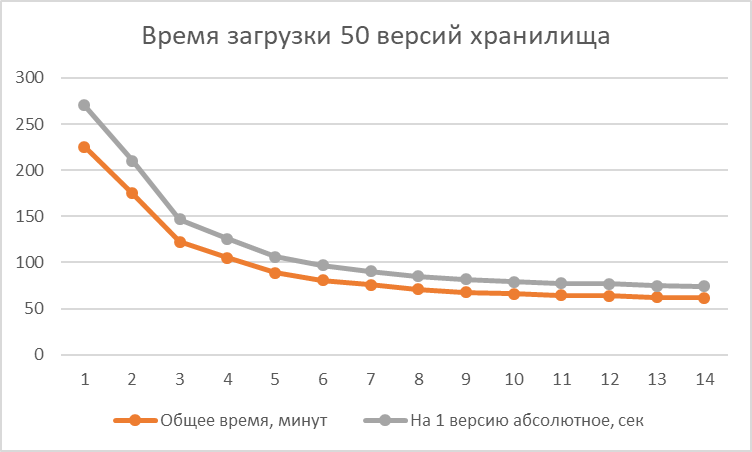
Если не хочется смотреть в таблицу и график, опишу результат словами - чуда не случилось. Если 50 версий в один поток загружаются чуть меньше 4 часов, то в 10 потоков они загружаются за чуть больше часа, а хотелось бы за 20 минут. Да, ускорение загрузки есть, но оно нелинейное. После 6-7 потоков уменьшение общего времени загрузки незначительно.
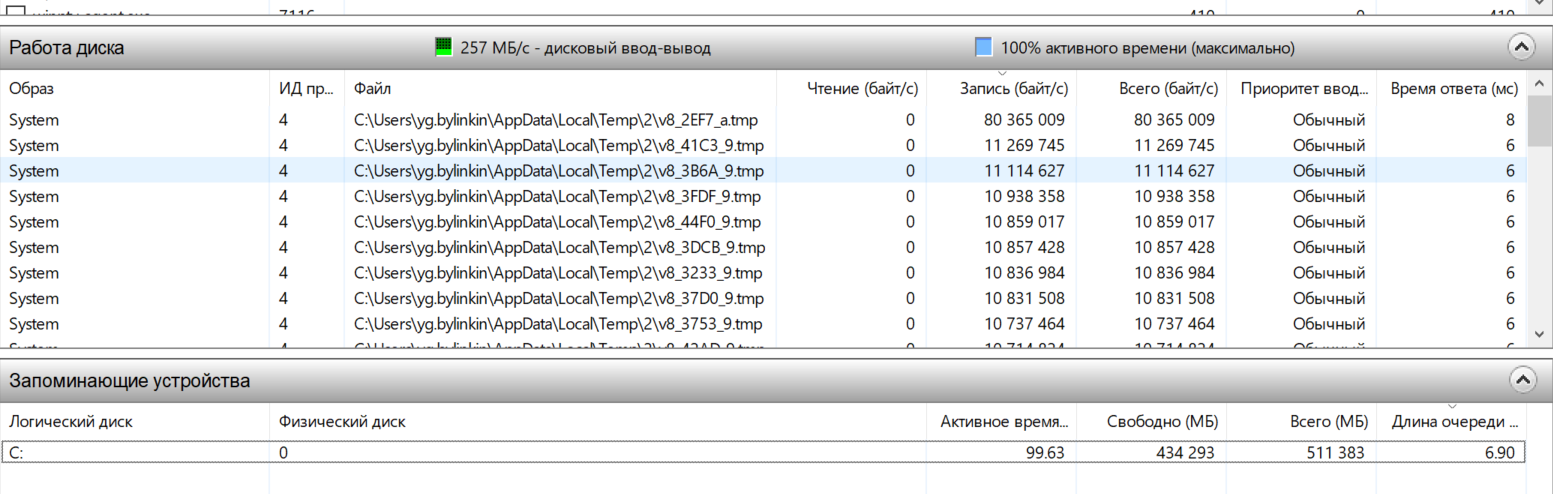
При повышении количества потоков начинается конкуренция за ресурсы компьютера, в первую очередь - жесткий диск. Посмотрите, какая жесткая просадка по диску (очередь диска огромная):
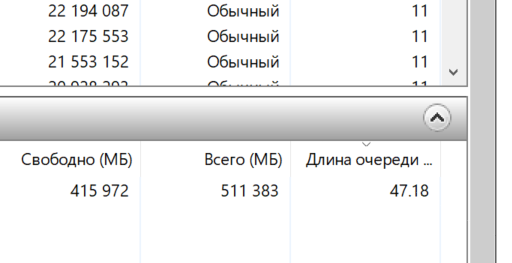
Что тут можно сделать? Поставить более быстрый диск, подсыпать еще ресурсов компьютеру, перенести хранилище еще ближе (да хоть на этот же компьютер). Возможности для улучшений еще есть.
Еще, приглашаю вас, мои читатели, воспользоваться этим скриптом и выложить в комментарии свои результаты.
В скрипте нужно указать свои данные - имя пользователя хранилища, путь к нему, место для складывания выгруженных cf. Интересно, что будет у вас.
Итоги
Я научился работать с фоновыми заданиями в oscript. Написал скрипт, позволяющий загружать версии хранилища в несколько потоков.
В итоге с перерывами в течение недели сделал выгрузку всей истории хранилища. Команда git rev-list --count HEAD в репо покажет сколько версий было выгружено:
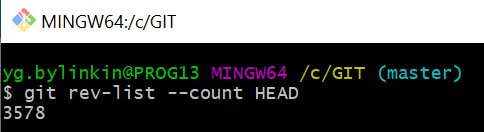
3578 версий.
Неплохо, да?
Вступайте в нашу телеграмм-группу Инфостарт