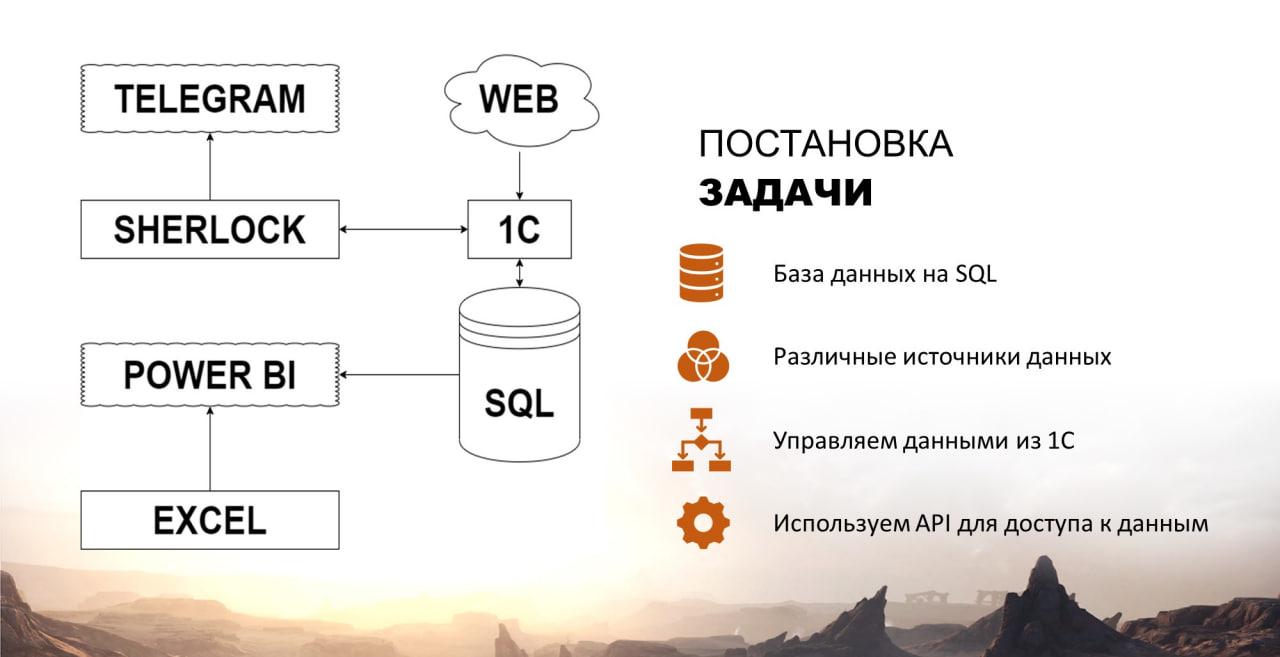
В своем докладе сегодня я хотел бы рассказать про то, как из базы 1С взаимодействовать с базой SQL. Рассказывать я буду на примере реального проекта – его схема представлена на экране.
-
В одной компании, которая занималась торговлей на рынке нефтепродуктов, был штат аналитиков, которые использовали для своих нужд Power BI – с его помощью они могли делать разные прогнозы, предоставлять отчеты руководству. Основным источником данных для Power BI были таблицы Excel.
-
Также в компании существовал Telegram-бот для клиентов, в котором они могли посмотреть какие-то новости про рынок нефтепродуктов. Например, посмотреть цену на бензин 95-й, маленько поплакать и сделать заказ.
-
Активно шел процесс перевода Telegram-бота на конструктор ботов Sherlock. Но, Sherlock не может сам обрабатывать введенные в него данные. Например, нужно было по первым буквам названия станции выдать варианты, возможные для выбора клиенту в боте – Sherlock сам это делать не мог, ему нужна была управляющая система.
-
В качестве управляющей системы была выбрана система 1С:Предприятие. Из нее планировалось настроить взаимодействие с Sherlock через API посредством HTTP-сервисов.
-
В свою очередь 1С должна была обращаться к различным веб-ресурсам за данными – например, на сайт биржи или на сайт РЖД, чтобы посчитать стоимость перевозки нефтепродуктов.
-
Данные скачивались с веб-ресурсов, и их нужно было где-то хранить. Конечно, можно было хранить и в самой базе 1С, но мы выбрали вариант хранить данные в отдельной базе SQL, в так называемом Storage, чтобы аналитики, которые пользуются Power BI, могли использовать эти данные для построения своих BI-моделей. В Power BI для этих целей есть встроенный коннектор к базе SQL.
Первые шаги. Подключаемся к базе SQL

Все это реализовать поручили мне. Но когда я подошел к этой задаче, я был похож на совсем маленького мальчика. Знаний было немного, но было очень любопытно. Глаза горели и было очень интересно.
Я предлагаю вместе проследить за ростом этого мальчика по ходу получения новых знаний по этой тематике.
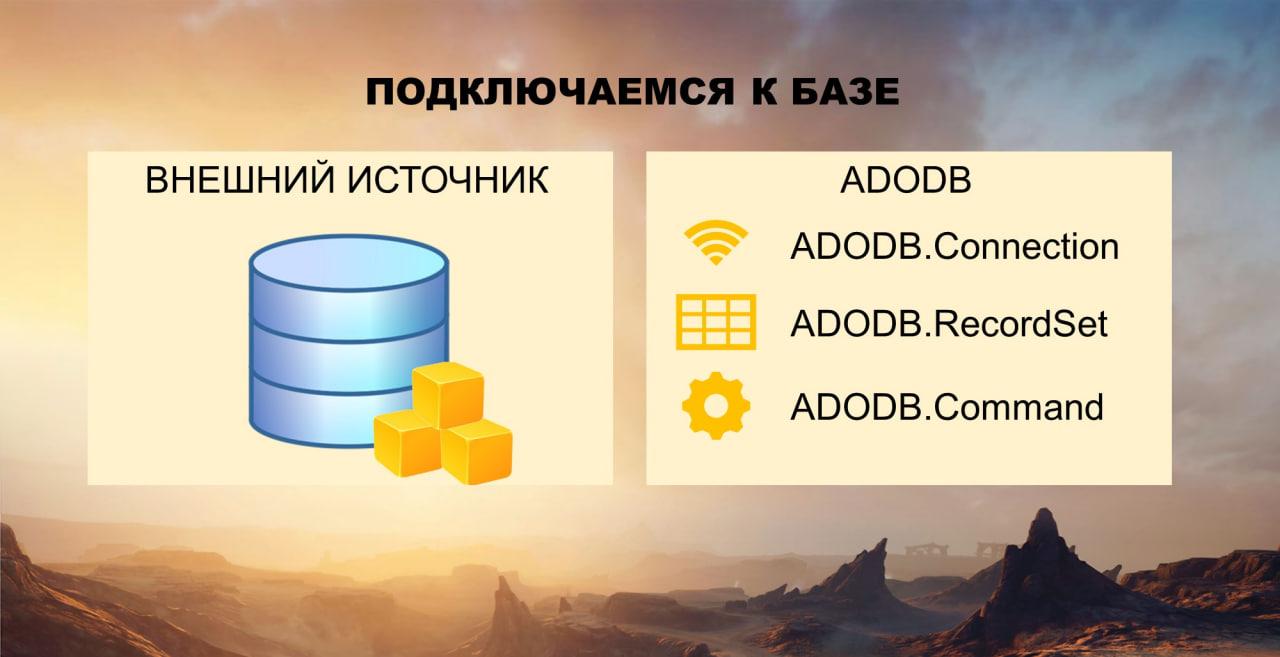
Первый вопрос был – какой выбрать путь взаимодействия с базой данной SQL.
Был вариант – использовать объект метаданных конфигурации 1С «Внешний источник». С его помощью можно настроить подключение к базе, прописать таблицы, с которыми мы планируем работать и потом использовать эти таблицы как объект конфигурации 1С. Достаточно удобный вариант. Я начал искать информацию об нем и в первой же статье на Инфостарте прочитал, что внешние источники нельзя использовать на запись, только на чтение. На самом деле, это неверно – с версии платформы 8.3.5 можно использовать и на запись. Но в тот момент меня эта информация сильно оттолкнула, и я начал искать дальше.
Второй вариант — это воспользоваться библиотекой от Microsoft ADODB. ADO расшифровывается как Active Data Objects – это библиотека, которая состоит из набора некоторых объектов.
-
Основным из них являются объект Connection, который отвечает за соединение с баз данных SQL (в принципе, с любой базой данных).
-
Второй объект – Command, который отвечает за выполнение запросов и выполнение команд.
-
И объект RecordSet, который отвечает за получение результата и его последующую обработку.
На официальном ресурсе Microsoft большое количество документации по всем объектам, которые входят в библиотеку ADODB, по всем их параметрам, методам – все подробно расписано. Если мы воспользуемся методом взаимодействия с SQL через ADODB, мы можем в качестве преимущества использовать все возможности на стороне SQL – дальше я расскажу как.
Поэтому я выбрал второй путь и начал двигаться дальше.

Как же нам подключиться к базе?
Для начала нам нужно подготовить строку подключения.
-
здесь мы указываем, что мы подключаемся к базе SQL;
-
указываем имя сервера;
-
имя пользователя;
-
пароль;
-
имя базы данных.
Затем создаем новый COMОбъект ADODB.Connection и подготовленную нашу строку передаем в качестве параметра в метод Open() объекта Connection.

Если у нас вдруг на сервере доменная авторизация, то имя пользователя и пароль нам уже не нужны – вместо этого мы указываем параметр TrustedConnection=Yes.
Выполняем запросы

Все, подключение к базе прошло успешно. Наш мальчик вырос и уже превратился в такого мальчугана с конфеткой.
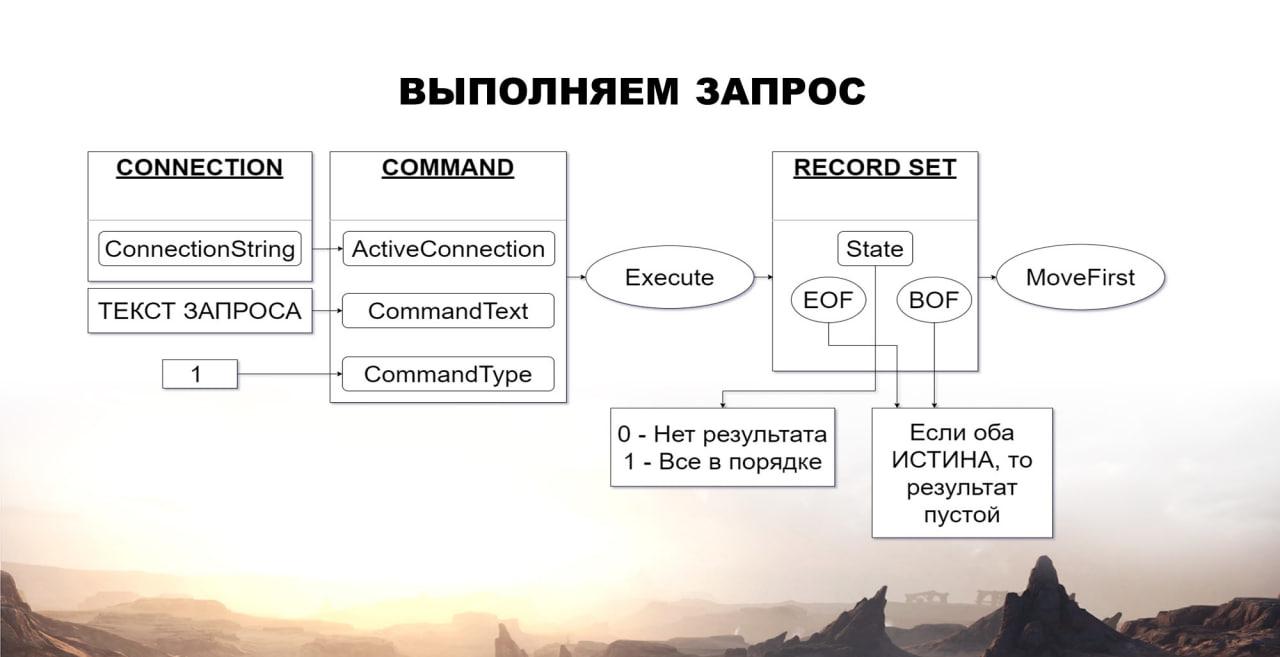
Дальше встает вопрос – а как же выполнять запросы к этой базе данных?
Для этого нам потребуется объект Command.
-
У него есть свойство ActiveConnection, куда мы записываем соединение, полученное на предыдущем этапе.
-
Дальше есть свойство CommandText, куда мы записываем текст запроса на языке SQL.
-
Есть свойство CommandType, куда мы записываем единичку – это будет означать, что мы собираемся выполнить запрос.
-
И дальше мы выполняем у объекта Command метод Execute, получая на выходе объект RecordSet.
RecordSet – это выборка данных по аналогии с 1С.
-
У RecordSet есть свойство State, которое содержит 1 или 0, показывая, выборка открыта или закрыта.
-
Выборка может быть закрыта (значение 0) в том случае, если мы выполнили запрос, который не возвращает результата – допустим, это добавление или изменение строки. Или, допустим, если у нас при выполнении запроса возникла какая-то ошибка.
-
Если у нас единичка, значит все в порядке, запрос выполнился.
-
-
Также у объекта RecordSet есть такие методы как EOF и BOF – они отвечают за текущую позицию выборки.
-
EOF возвращает истину, когда текущая позиция выборки за последней записью.
-
BOF возвращает истину, когда она у нас перед первой позицией в объекте. Если оба этих метода возвращают истину, значит мы получили пустой результат запроса.
-
-
И в конце я еще выполняю для объекта RecordSet метод MoveFirst() – таким образом я перемещаю указатель на первую запись выборки, потому что нигде на официальном ресурсе Microsoft не сказано, что после выполнения запроса указатель будет на первой записи выборки. Я находил в интернете информацию, что некоторые люди выполняют сначала метод MoveLast() – перемещают указатель на последнюю запись выборки, а потом выполняют MoveFirst(). Делают излишнее движение, чтобы количество записей выборки отображалось верно. Если этого не сделать, количество записей отображается неверно.

Как это выглядит в коде:
-
создаем новый COMОбъект ADODB.Command;
-
устанавливаем свойство ActiveConnection;
-
устанавливаем свойство CommonText текстом нашего запроса;
-
свойство CommonType ставим в единичку;
-
выполняем метод Execute() и на выходе получаем объект RecordSet;
-
проверяем, открыта ли выборка (если закрыта, выходим из процедуры с кодом возврата 1);
-
проверяем, запрос пустой или не пустой (если оба метода EOF и BOF возвращают истину, значит, запрос пустой, и мы выходим из процедуры с кодом возврата 2);
-
и в конце выполняем метод MoveFirst – перемещаем указатель на первую запись выборки.
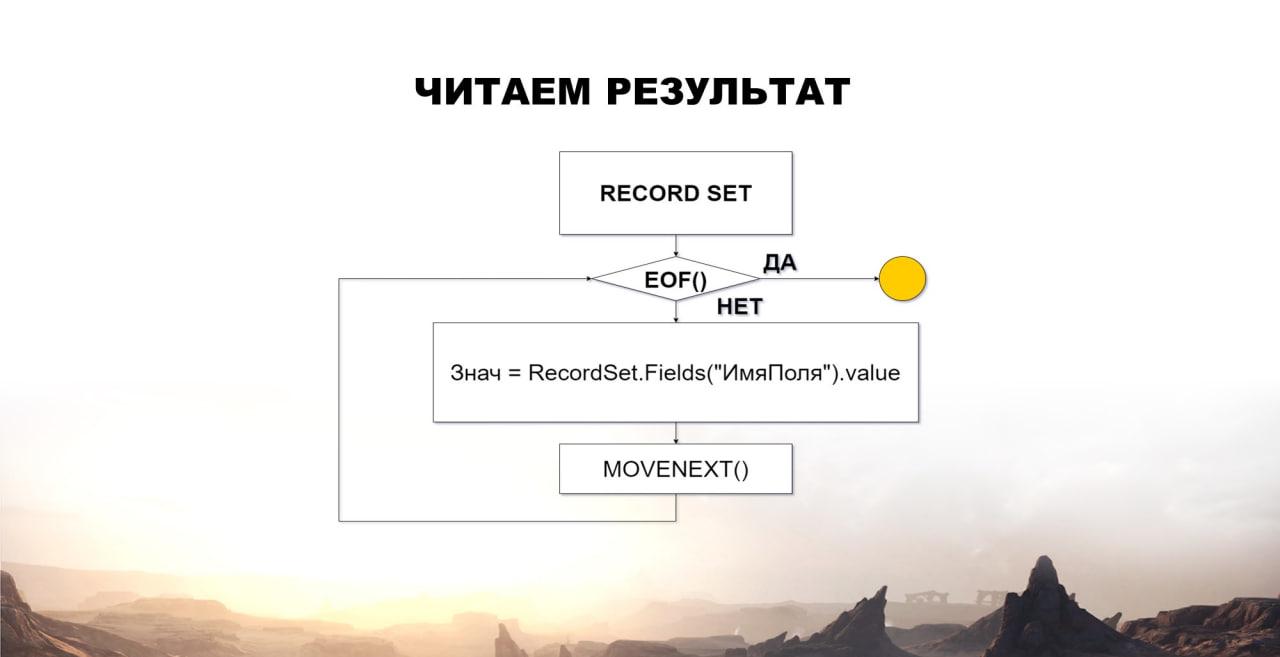
Дальше встает вопрос – как же нам этот результат прочитать:
-
у нас есть объект RecordSet – как я уже говорил, это выборка;
-
у нее есть метод EOF(), который показывает, в конце мы выборки или не в конце;
-
если не в конце, то у нас есть метод Fields("ИмяПоля"), в котором мы по имени поля можем получить необходимое нам поле, то есть столбец таблицы, и получить его результат;
-
дальше мы выполняем метод MoveNext – перемещаемся на следующую запись выборки;
-
если у нас это последняя запись, мы обработку результата прекращаем.
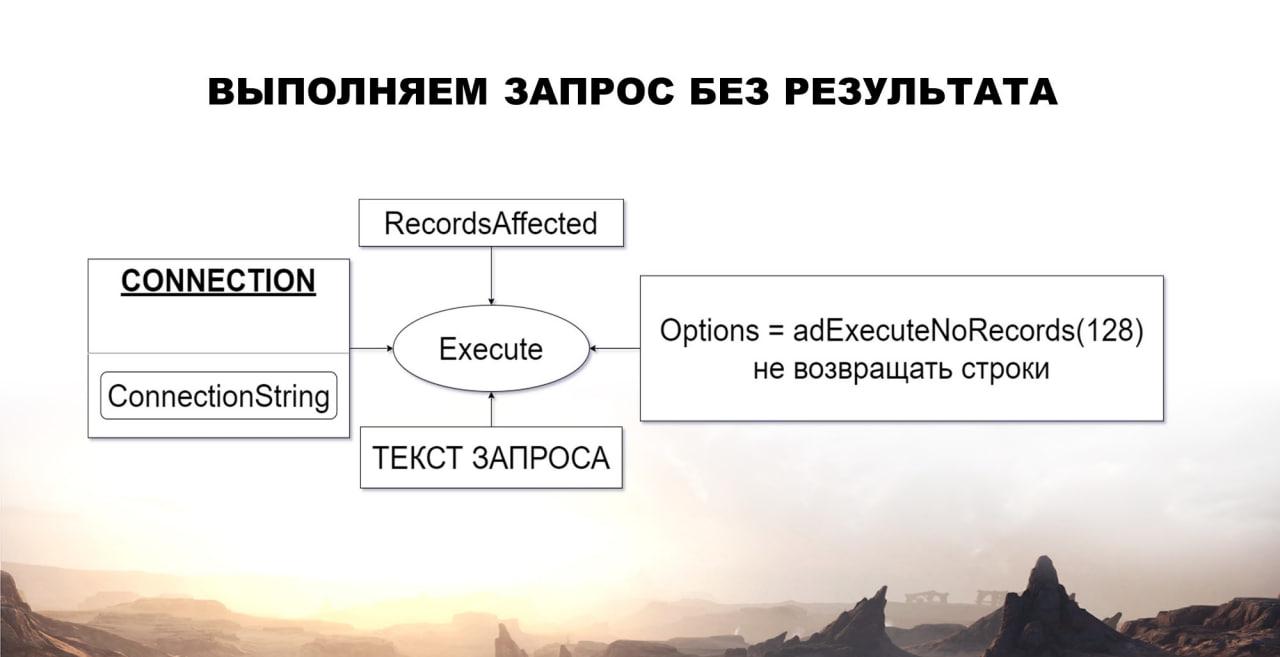
Дальше я решил разделить запрос без результата и с результатом. Потому что выборка у нас может быть закрыта, как в случае, когда у нас запрос без результата, так и в случае возникновения какой-то ошибки.
В этом случае я решил использовать объект Connection. У него тоже есть метод Execute(), у которого есть параметры.
-
Первый параметр – это текст запроса, тоже на языке SQL.
-
Второй параметр – это Options, где мы указываем 128. Это будет означать, что мы планируем выполнять запрос, который не возвращает результата.
-
И третий параметр RecordsAffected. Это скорее не параметр, который передается, а параметр, который возвращается. Он нам показывает количество записей, которое у нас затронется в результате запроса. То есть если мы, допустим, изменили запросом три строки, то в RecordsAffected у нас будет тройка.

Вот так это выглядит в ходе. Всего две строки, достаточно все просто.
Передаем параметры, вызываем хранимые процедуры

После того, как эти навыки были освоены, уже, можно сказать, начальная школа закончена, и мальчик уже дорос до студента.
Вспоминая свои студенческие годы, я учился в ОмГУ – в Омском государственном университете на математическом факультете. И у нас был такой предмет – численные методы. Чтобы его сдать, нужно было написать несколько программ для решения задач прикладной математики. Допустим, найти определитель матрицы.
Можно было пойти двумя путями. Путем легким — взять программу у предыдущего потока, под себя адаптировать и быстренько сдать. А можно было пойти как настоящему программисту и написать все с нуля самому.
Собственно говоря, я вторым путем и пошел. А программу нужно было писать на языке C++. Он очень тесно связан с объектно-ориентированным программированием. В итоге, пойдя сложным путем, вместо полгода я сдавал зачет два года. И на всю жизнь у меня в голове отложилось объектно-ориентированное программирование. И каждый раз, когда я подхожу к задаче, у меня сразу возникает мысль – а не применить ли мне здесь объектно-ориентированное программирование? Здесь тоже я об этом подумал.
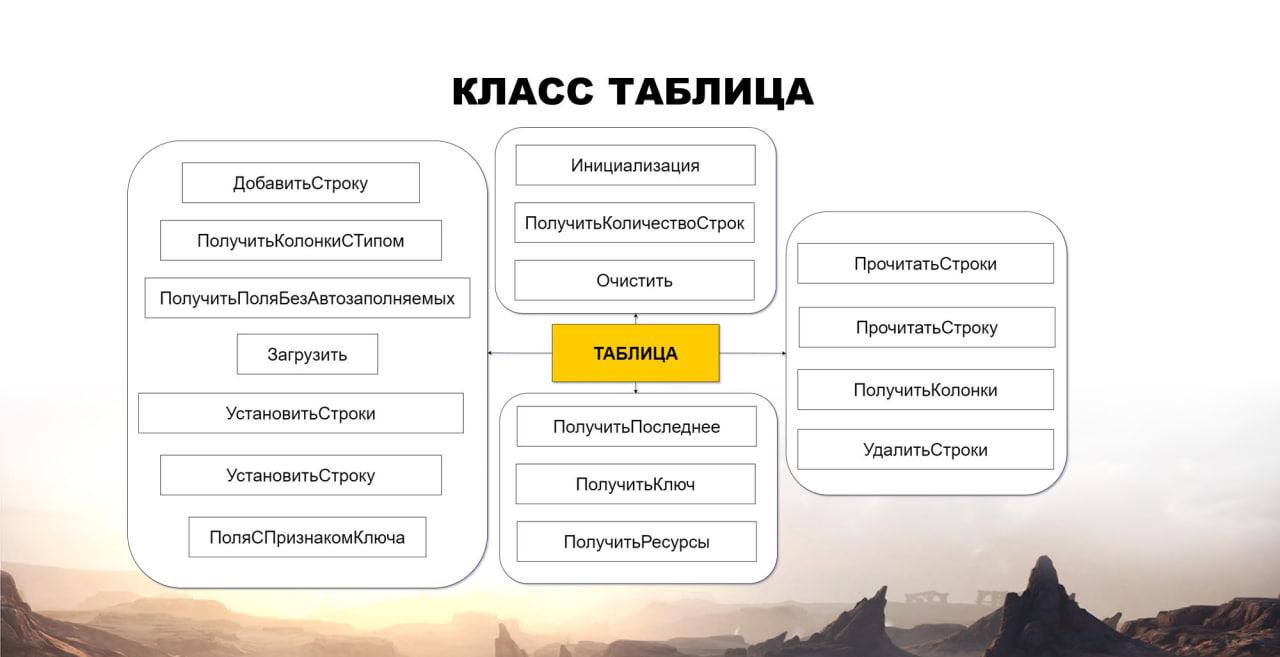
Я решил, что у меня есть таблица, и я буду с ней общаться как с объектом – уйду от языка SQL, буду работать с таблицей на языке 1С.
Я написал на 1С класс таблицы, написал методы, которые позволяют с ней взаимодействовать. Но оказалось, что этот путь ведет в никуда.
Потому что когда таблица одна, все хорошо – мы с ней работаем, добавляем данные, удаляем.
Но когда их уже несколько, их нужно как-то же совмещать, делать джойны. А здесь мы при использовании классов сильно теряем в производительности. Поэтому не повторяйте мою ошибку, идите сразу в сторону запросов.
Кстати, некоторые методы этого класса (ДобавитьСтроку, УдалитьСтроки, Очистить для таблицы) я потом все-таки использовал. Они оказались полезными.

Я вернулся к идее использовать запросы. Встал вопрос – как передать в эти запросы параметры.
Если с 1С все понятно – у нас есть метод «Установить параметр», то как же это сделать с SQL?
Все очень просто – можно использовать функцию ПараметрВSQL(), которая значение параметра переведет в текстовое представление. И мы потом это текстовое представление подсовываем в сам запрос.
Допустим, здесь у нас первый параметр – это 2,5, а второй – это дата, 5 января 2021 года.

Чтобы перевести число 2,5 в SQL, мы запятую заменяем на точку, а в дате меняем дату и месяц местами, потому что в SQL дата пишется наоборот.
Таким же путем я и пошел при добавлении новых данных в таблицу. Я просто переводил новые данные в текстовый формат и подсовывал в запрос. Потом запрос выполнялся, и они добавлялись в таблицу.
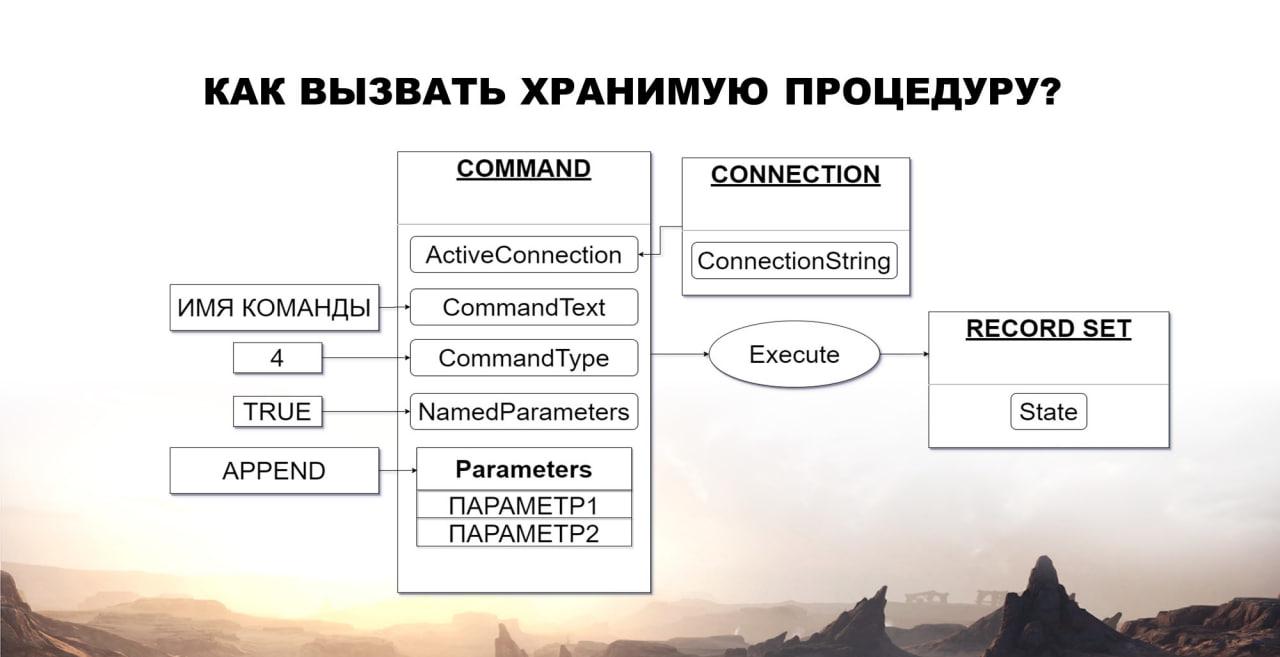
Теперь встал вопрос как воспользоваться преимуществами SQL – использовать временные таблицы, представления таблиц, различные индексы.
Для этого потребуется вызывать хранимые процедуры. Это также можно сделать с помощью объекта Command, у которого есть:
-
свойство ActiveConnection, куда мы устанавливаем наше соединение;
-
свойство CommonText, куда мы устанавливаем уже не имя запроса, а имя команды, которую собираемся выполнить;
-
свойство CommonType – здесь мы уже вместо единички устанавливаем четверку, это будет означать, что мы собираемся выполнить именно команду, а не запрос;
-
свойство NameParameters, туда мы устанавливаем True – оно будет означать, что параметры мы сопоставляем не по порядковому номеру, а именно по наименованию параметра;
-
и свойство Parameters – это таблица, куда мы с помощью метода Append() можем добавить все необходимые параметры для выполнения процедуры.
После этого мы выполняем для объекта Command метод Execute() и на выходе опять получаем объект RecordSet.

Как это выглядит в коде?
Мы создаем новый объект ADODB.Command, устанавливаем свойство ActiveConnection, и, допустим, хотим передать в него строковый параметр – пускай это будет город, откуда я приехал, Омск.
Чтобы этот параметр добавить, мы сначала должны его данные подготовить:
-
Помимо значения параметра нам понадобится имя параметра – допустим это Param1.
-
Дальше тип параметра. В данном случае это строка, поэтому мы здесь указываем 129 – кстати, я не нашел никакого другого способа для передачи дробного значения в качестве параметра, кроме как перевести его в строку. А если бы это было у нас целое число, мы могли бы указать для типа параметра – 3, и в качестве значения уже записывать само целое число.
-
И последнее, что нам понадобится, это размер параметра в байтах. Для строки, как мы знаем, это количество символов, потому что каждый символ занимает один байт.
После этого мы выполняем у объекта Command метод CreateParameter(), куда передаем все наши подготовленные данные в качестве параметров.
И затем с помощью метода Append() записываем полученный объект в свойство Parameters.
Продолжаем заполнять свойства объекта Commands:
-
устанавливаем в свойство CommandText имя хранимой процедуры,
-
в свойство CommandType устанавливаем четверку,
-
в свойство NamedParameters записываем True
-
и выполняем метод Execute().

Создать эту хранимую процедуру на стороне SQL мы можем с помощью инструкции CREATE PROCEDURE. При этом мы должны указать для нее то же имя, которое мы использовали при ее вызове на стороне 1С. И у этой процедуры должны быть прописаны параметры с теми же самыми наименованиями, которые мы использовали на стороне 1С.
Дальше у нас идет слово AS и после него – текст самого кода процедуры. В простейшем случае это может быть просто запрос – здесь это запрос из таблицы городов, в котором мы возвращаем наименование города и дату его основания.
В запросе мы можем в нужном нам месте использовать параметры, которые описаны при создании процедуры. Допустим, здесь у нас идет отбор по названию города.
Изучаем мир SQL. Временные таблицы, вызов хранимых процедур из запроса, волшебный MERGE

После того, как мы научились выполнять хранимые процедуры, перед нами открылся весь мир SQL со всеми его преимуществами. Давайте туда немного заглянем.

Первое, что мы можем здесь использовать – это временные таблицы.
Если в 1С у нас в запросе был оператор ПОМЕСТИТЬ, с помощью которого мы результат запроса помещали во временную таблицу, то на стороне SQL у нас есть слово INTO и обязательно нужно ставить решетку перед именем таблицы. Тогда результат поместится во временную таблицу, которая хранится на диске в базе TempDB.
На слайде показан простейший запрос с временной таблицей.

Чтобы из запроса SQL вызвать хранимую процедуру, нам опять понадобятся временная таблица – ее можно создать с помощью оператора CREATE TABLE.
Перед названием временной таблицы нужно обязательно поставить решетку и прописать все колонки с типом их значения.
Допустим, нам дополнительно понадобится переменная, которую мы хотим передать в эту процедуру в качестве параметра, поэтому объявляем переменную @date_current с типом DATETIME.
Для вызова процедуры нам нужно использовать оператор EXEC с названием этой процедуры, а все необходимые параметры с их значениями перечисляем через пробел и запятую.
И перед оператором EXEC мы пишем инструкцию INSERT с названием нашей временной таблицы – в нее будет записан результат выполнения процедуры.

Кроме того, на стороне SQL есть оператор MERGE – я его назвал «Волшебный MERGE». Это такая инструкция в запросе, которая делает сразу несколько вещей одновременно.
Допустим у нас есть компания, которая занимается продажей ноутбуков и принтеров.
Весь наш ассортимент хранится в базе в таблице PRODUCT. Мы продаем ноутбуки Asus и принтеры HP. Причем в наименовании Asus у нас первая буква большая, остальные маленькие.
И допустим у нас новое поступление – мы завезли ноутбуки Asus и ноутбуки HP. При этом ноутбуки Asus у нас уже были, а ноутбуки HP – это для нас новый продукт, нам нужно расширить нашу продуктовую линейку.
На выходе в нашей таблице PRODUCT должна добавиться третья строка с ноутбуком HP.
Причем, помимо добавления новой строки, мы хотим в тех строчках, которые есть, еще и какие-то данные обновить. Допустим, у нас производитель был указан неверно – первая буква большая, остальные маленькие. А мы хотим, чтобы все буквы в наименовании были большие.
Оператор MERGE нам позволяет все это сделать за один запрос.

Посмотрим, как это выглядит в тексте.
Здесь показана инструкция MERGE – мы через INTO указываем таблицу PRODUCT, с которой будем работать, и задаем для нее псевдоним T_DST.
Дальше мы указываем таблицу T_SRC, из которой будем брать данные или с которой будем производить сравнение – я здесь сразу прописал, как она заполняется данными.
Сравнивать эти две таблицы мы будем по полям с наименованием и с типом продукта.
Теперь пишем инструкцию, проверяющую совпадение по выбранным полям – WHEN MATCHED. В случае совпадения мы значение производителя (maker) оператором UPDATE SET заменяем значением из нашей новой таблицы T_SRC.
А если у нас не совпадение, WHEN NOT MATCHED THEN, тогда мы новую запись добавляем посредством инструкции INSERT.
Выполнение этого запроса за один раз решает сразу две задачи – мы обновляем текущие данные и добавляем необходимые новые.
Готовая подсистема для управления базой на SQL

После этого наш мальчик уже стал реально батя – он готов решить любой вопрос, который нужен для связки SQL и 1С. А что делает батя? Батя сам делает своих детей. И я тоже не стал исключением.
Я решил сделать свое небольшое детище – реализовать в 1С небольшую конфигурацию, которая позволяет:
-
во-первых собирать все методы для работы с базой SQL;
-
а во-вторых позволяет работать с базой SQL с помощью графического интерфейса – отображает все таблицы, которые там есть, и данные в этих таблицах.
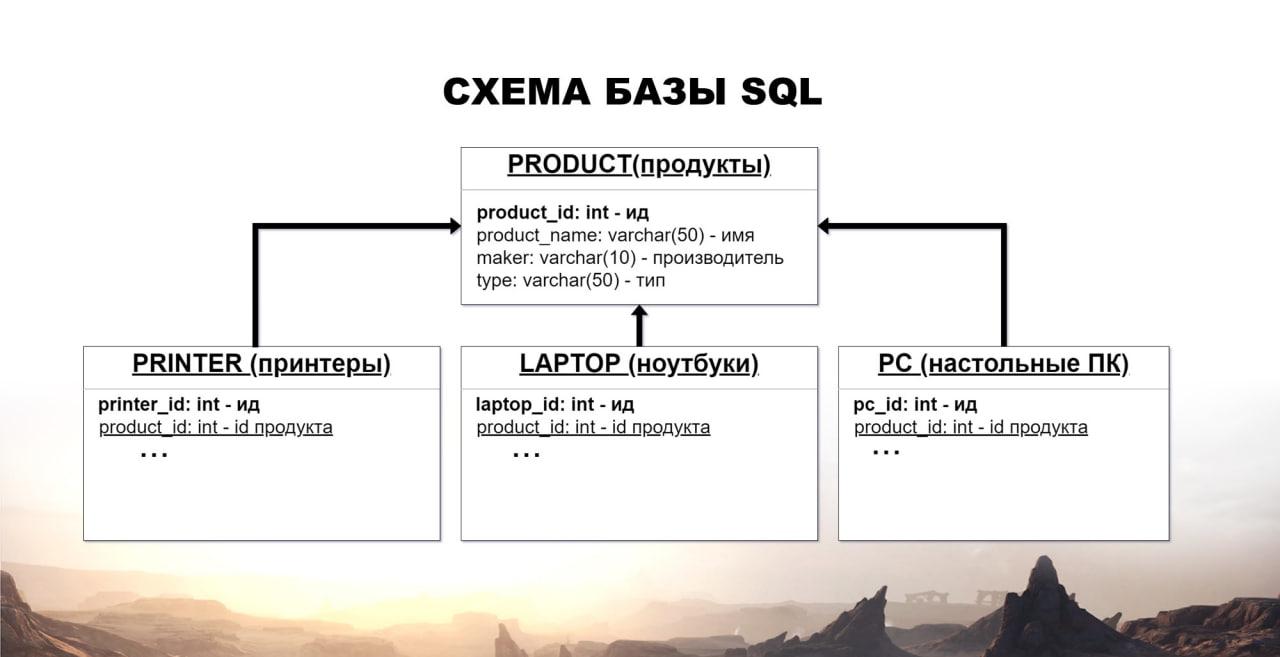
На примере я взял такую базу SQL, где у нас четыре таблицы:
-
есть продукты и эти продукты получаются от трех видов;
-
либо это принтеры;
-
либо ноутбуки;
-
либо настольные компьютеры.
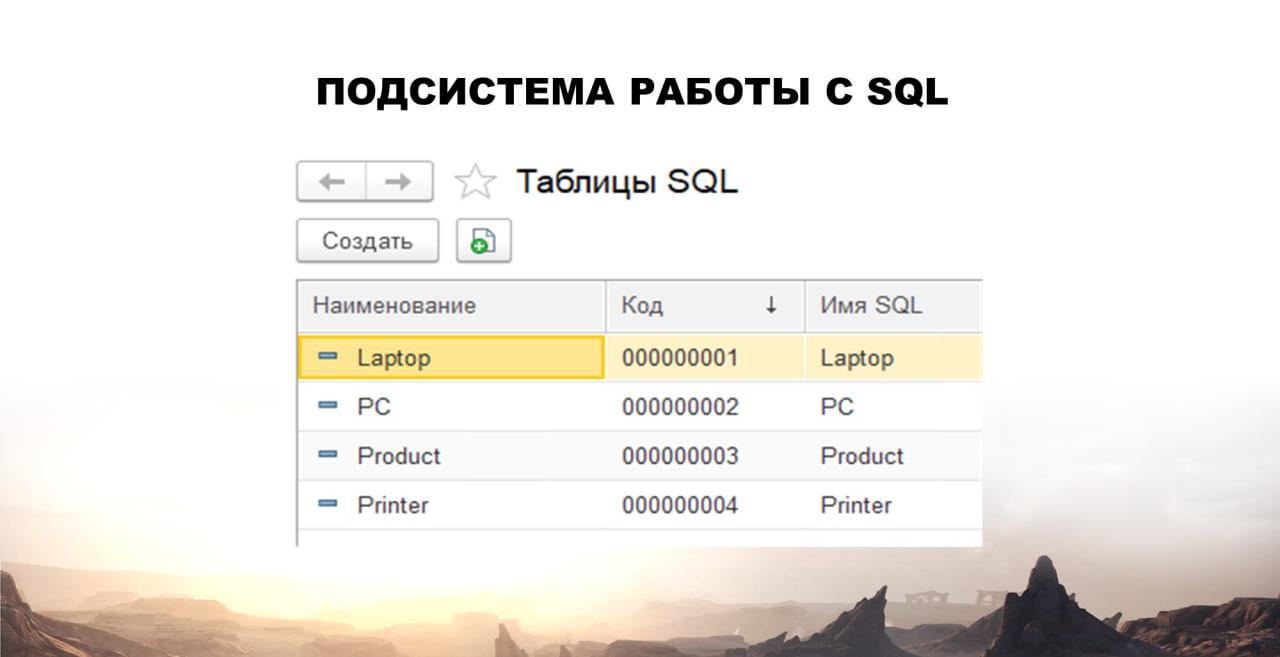
Загнал в свою подсистему, выполнил специальную обработку. У меня в справочнике таблиц появились четыре таблицы.
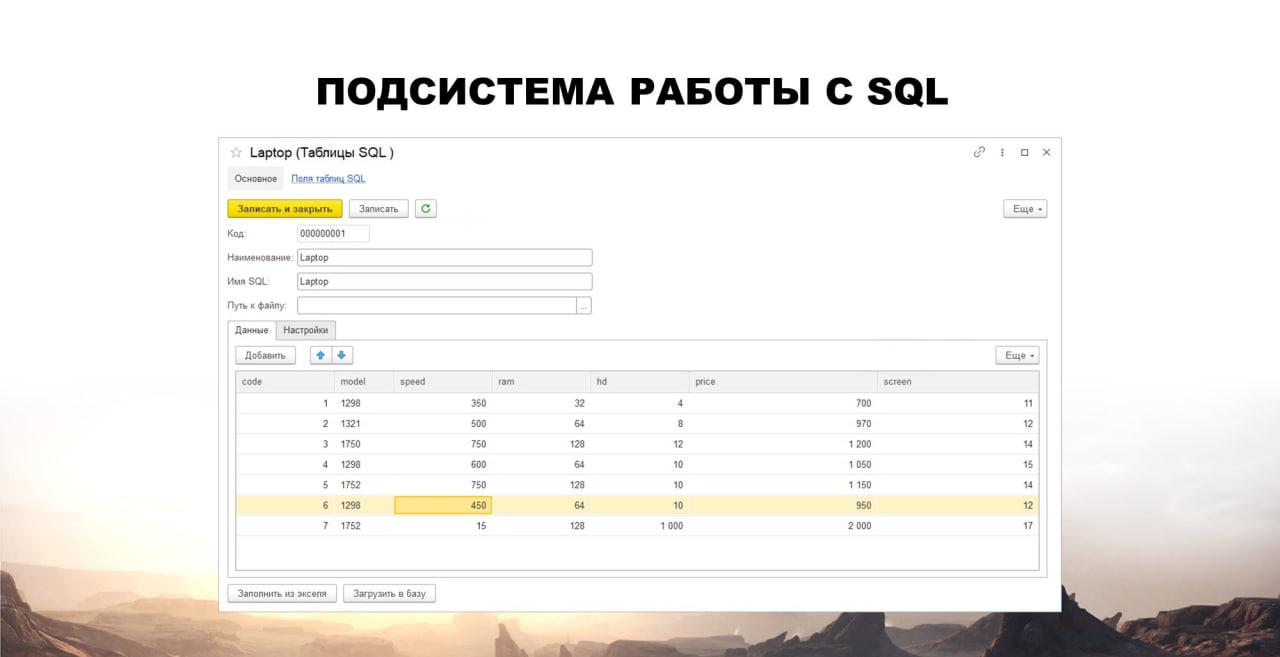
Дальше я могу любую таблицу открыть и увидеть:
-
какие там данные, какие колонки;
-
что-то поменять, если нужно;
-
сделать выгрузку в Excel;
-
загрузить из Excel полностью всю таблицу.
Все это можно сделать.
Эту подсистему можно скачать по ссылке.
Почему не 1С:Аналитика?
Вернемся к первоначальной задаче по проекту.
Когда я готовился к докладу, модератор поинтересовался, почему мы не захотели хранить все данные из облака в базе 1С, а вместо Power BI использовать 1С:Аналитику?
Что касается 1С:Аналитики – я когда посмотрел, что она из себя представляет, действительно на самом деле интересный, перспективный проект от фирмы 1С. Я считаю, что это такой широкий шаг вперед. Всем рекомендую ознакомиться, очень функциональное приложение для BI-аналитики.
Но в нашем случае причин, по которым мы не перешли на 1С:Аналитику, было несколько:
-
Первая причина заключается в том, что Power BI уже использовался. Пользователи уже умели с ним работать, привыкли к его интерфейсу. Все мы знаем, что переучивать пользователя на что-то новое – это себе дороже.
-
Второе – отказываться от Excel как от источника данных не планировалось. А 1С:Аналитика, к сожалению, пока не позволяет получать данные из Excel, она в качестве данных использует только данные из базы 1С, к которой она подсоединена.
-
И нужны были механизмы SQL, чтобы обеспечить максимальное быстродействие. Потому что был Telegram-бот, если пользователь ждал бы 30 секунд ответа на нажатие кнопки, он бы сразу это приложение удалил. Поэтому нужно было задействовать все механизмы SQL, чтобы максимально быстро получать ответ на запрос пользователя.
-
Четвертой причиной было то, что когда я с этим проектом начинал работать, 1С:Аналитики еще в принципе не было.
Вопросы лицензирования

Следующий вопрос – про лицензирование.
Все мы знаем, что нельзя обращаться к данным информационной базы 1С напрямую. За это бьют по рукам, ругают. Там нельзя индексы создавать, туда нельзя лезть.
И на официальном ресурсе 1С написано, что это связано в первую очередь с необходимостью стабильной работы системы. То есть если мы залезем, что-то руками поменяем, это может привести к плачевным последствиям.
Так вот здесь речь только про ту базу SQL, которая связана с конфигурацией 1С. Если мы работаем со сторонней базой, мы здесь никаких ограничений лицензионного соглашения не нарушаем. Наша совесть чиста.
Я рассказал пример использования связки 1С и SQL на реальном проекте. Берите на вооружение пример подсистемы – он выложен по ссылке. Кому понравилось, используйте.
Вопросы
Вы здесь реализовали только работу с MS SQL, а с другими базами данных, например, с PostgreSQL? Там совсем другой язык.
Здесь нам именно объект ADODB.Connection позволяет подсоединиться не только к базе данных SQL, но и к другой базе, например, на Oracle. Единственное, что те запросы, где я рассказывал на SQL, они могут не так работать.
Я тоже проходил этот этап в своей программе, но с PostgreSQL у нас так и не получилось нормально работать с такими же запросами.
Проблема в том, что диалект SQL разный? ADODB работает, просто диалекты разные. У ADODB под капотом T-SQL приближенный, поэтому он ломается, конечно.
А не было необходимости передавать данные типа MEMO, либо BLOB?
С таким типом данным мы не работали. Я смотрел в сторону типа данных, как раз таки схожий с blob, но потом отказался, потому что не потребовалось для проекта.
Через ADO возникает проблема при передаче такого типа данных.
Я столкнулся с проблемой передачи данных типа float – с плавающей запятой. Нашел только вариант передачи через текстовое представление.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт