Я думаю, ни у кого не возникает проблем при использовании микроволновки. Поставил, нажал две кнопки, и все работает. Никому же в голову не приходит паять дома на коленке какой-нибудь магнетрон, чтобы разогреть себе еду. Несмотря на то, что устройство сложное, вся сложность упакована в простой интерфейс.
Но когда дело касается анализа производительности, многие почему-то только тем и занимаются, что паяют каждый свою микроволновку на коленке. Один сделает такую, другой – другую.
В этом случае высокая квалификация требуется даже для того, чтобы собрать данные: распарсить технологический журнал, собрать данные из Extended Events, из логов, еще откуда-то. На это уходит масса времени. И потом еще уходит масса времени на то, чтобы эти данные как-то агрегировать, проанализировать и на остаток времени уже подумать, что со всем этим делать.
Вы, конечно, можете сказать, что есть специальные инструменты от 1С и других поставщиков. Но у каждого из них тоже есть ряд своих проблем. Расскажу, с какими столкнулся я.
Проблемы

Первая проблема – это низкая точность.
Основная причина, почему мне пришлось написать свой инструмент для анализа производительности (не то чтобы я горел желанием, но так получилось) – я веду курсы для людей, которые хотят научиться ускорять и оптимизировать 1С.
Я специально руками воспроизвожу какие-то проблемы, потом их анализирую, показываю, героически их решаю.
Так получилось, что я проблему воспроизвожу, а инструменты мне ее не показывают. Я знаю, что проблема есть, а инструмент говорит: «У тебя все хорошо в системе, расслабься!»
Другого выхода не было. Мне пришлось сделать что-то свое и разобраться, почему некоторые инструменты какие-то проблемы не показывают. В этом докладе я покажу, почему так может быть.
Вторая проблема – это предположения вместо точных ответов.
Когда инструмент говорит: «У вас есть жертвы блокировки и 10-20 возможных виновников. Разберись, кто из них виноват». И ты тратишь дополнительное время, чтобы понять, кто же из них на самом деле виновник. Это тоже отнимает лишнее время.
Третья проблема – необходимость доступа в интернет.
Некоторым инструментам требуется иметь доступ в интернет, чтобы выгрузить и проанализировать данные с сервера 1С. Такой доступ не всегда просто организовать. Может быть, кто-то имел «удовольствие» общаться со службой безопасности – этот разговор не всегда приятный. Много компаний не могут себе это позволить, потому что слишком большие сложности с доступом в интернет и прочим.
Четвертая проблема – недостаток данных.
Часто не хватает данных в одном месте. Приходится куда-то бегать: часть здесь посмотрел, часть – там, часть – в одних логах, часть – в других. На все это уходит время, и это вызывает лишние сложности.
Поэтому, в частности из-за первого пункта, я решил написать что-то свое. Небольшое, маленькое и простое, чтобы можно было быстро поставить и какие-то вещи сразу увидеть.
Покажу, что получилось. Расскажу, с какими проблемами я сталкивался на этом пути. И объясню, почему иногда анализ технологического журнала – это все равно не гарантия того, что вы увидите все проблемы.
Запросы
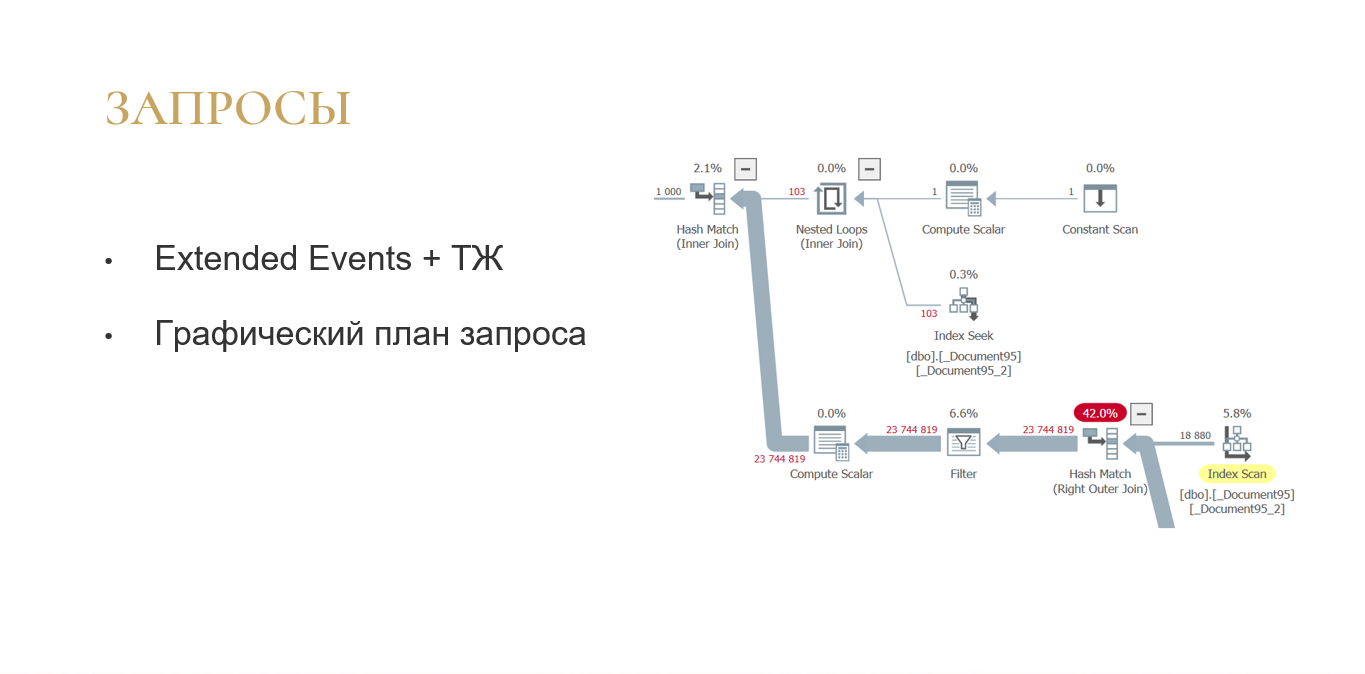
Первое, что было сделано – это анализ медленных запросов. Схема была такая: собираем расширенные события для MS SQL, соединяем с данными ТЖ и получаем плюшки.
Мы сразу можем видеть графический план запроса: не нужно из технологического журнала тянуть текстовый план, который не очень удобно анализировать.
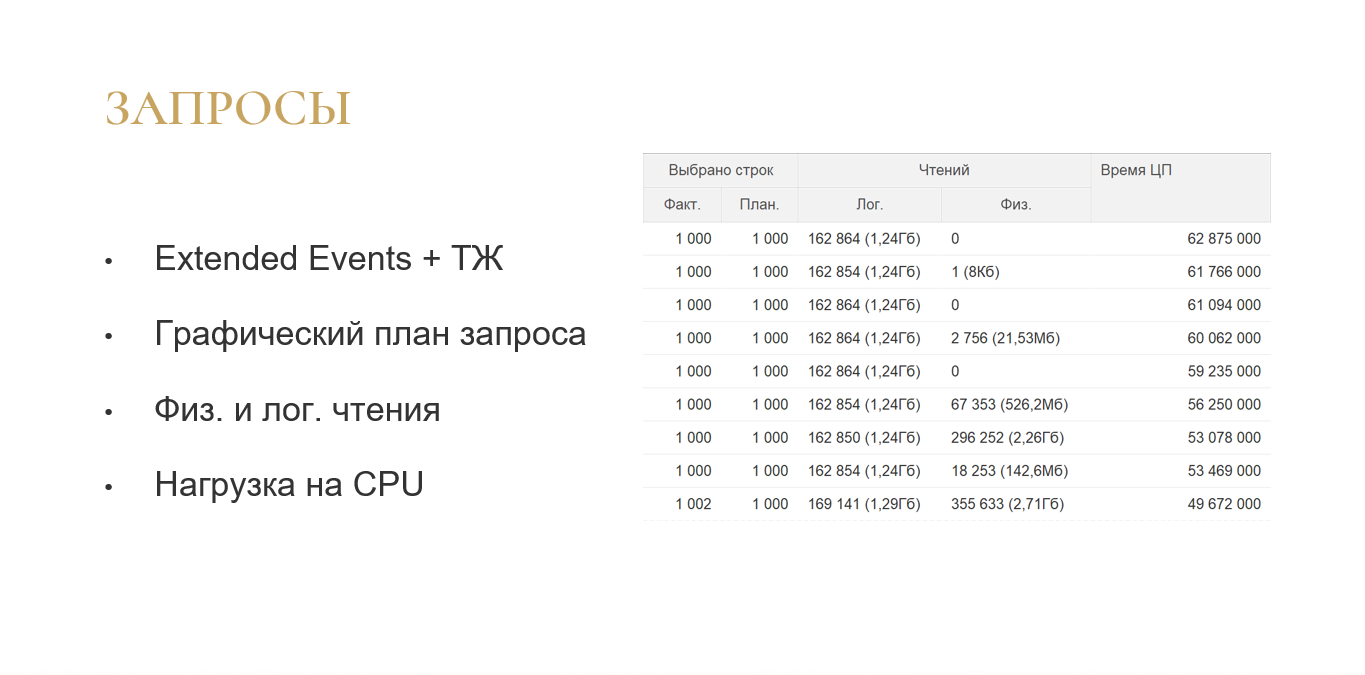
Сразу видим физические и логические чтения. Понятно, сколько данных прочитал запрос при выполнении именно с диска, сколько он взял из памяти. Этих данных нет в технологическом журнале, их нет в профайлере, их можно получить только из Extended Events (из расширенных событий).
Еще сразу видна нагрузка на CPU.

Сразу можно увидеть запрос в терминах метаданных 1С.
С запросами все довольно просто – вы такой анализ тоже легко сможете написать, это не займет много времени.
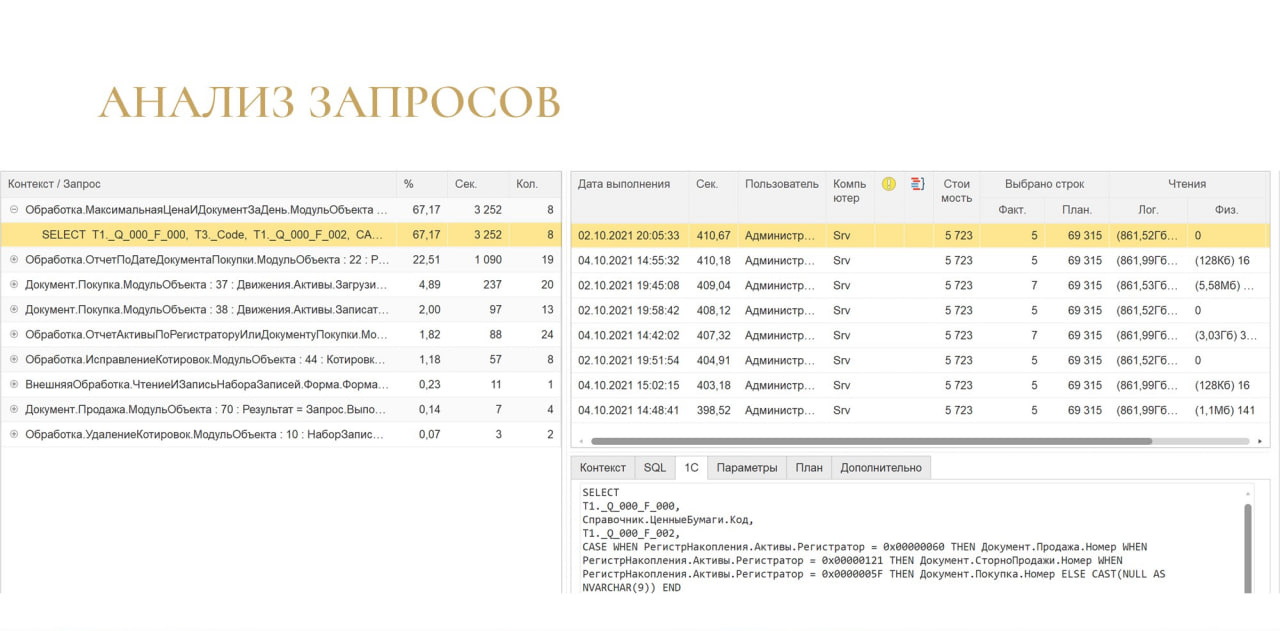
В итоге получилась вот такая картина:
-
слева вы можете видеть запросы с группировкой по контексту;
-
справа – это детали выполнения этого запроса, притом детали сразу со стоимостью плана и остальными штуками;
-
внизу идет дополнительная информация.
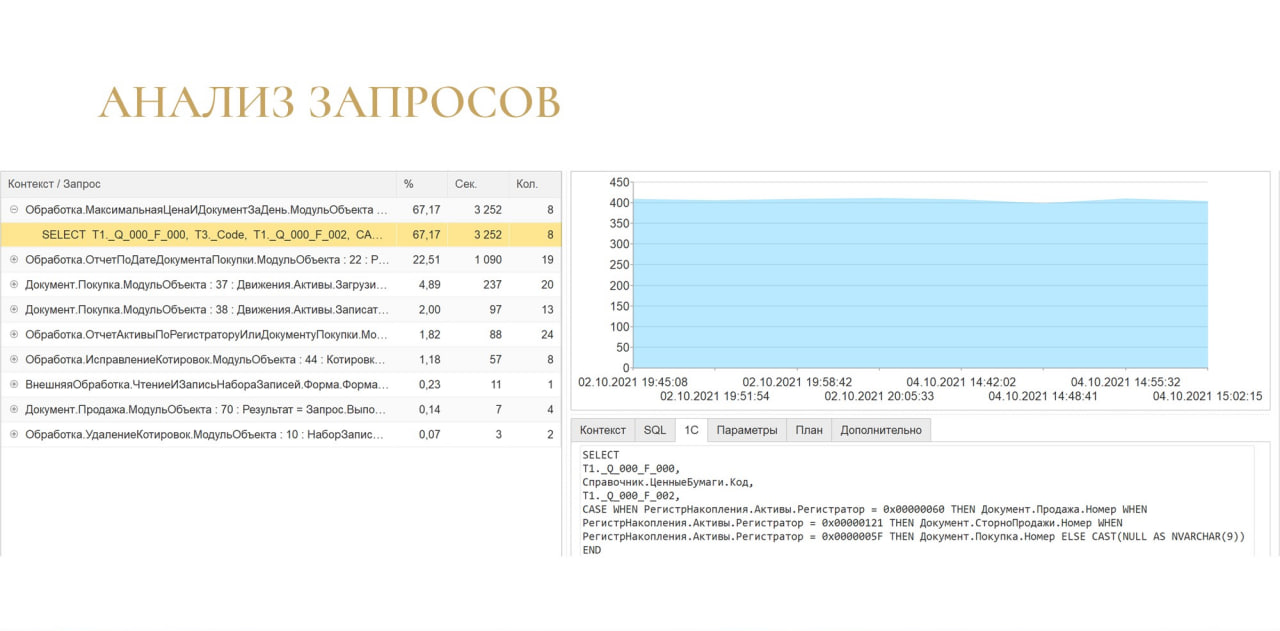
Кстати, здесь можно увидеть, насколько стабильно выполнялся запрос. На изображении показано, что запрос стабильно выполнялся 400 секунд.
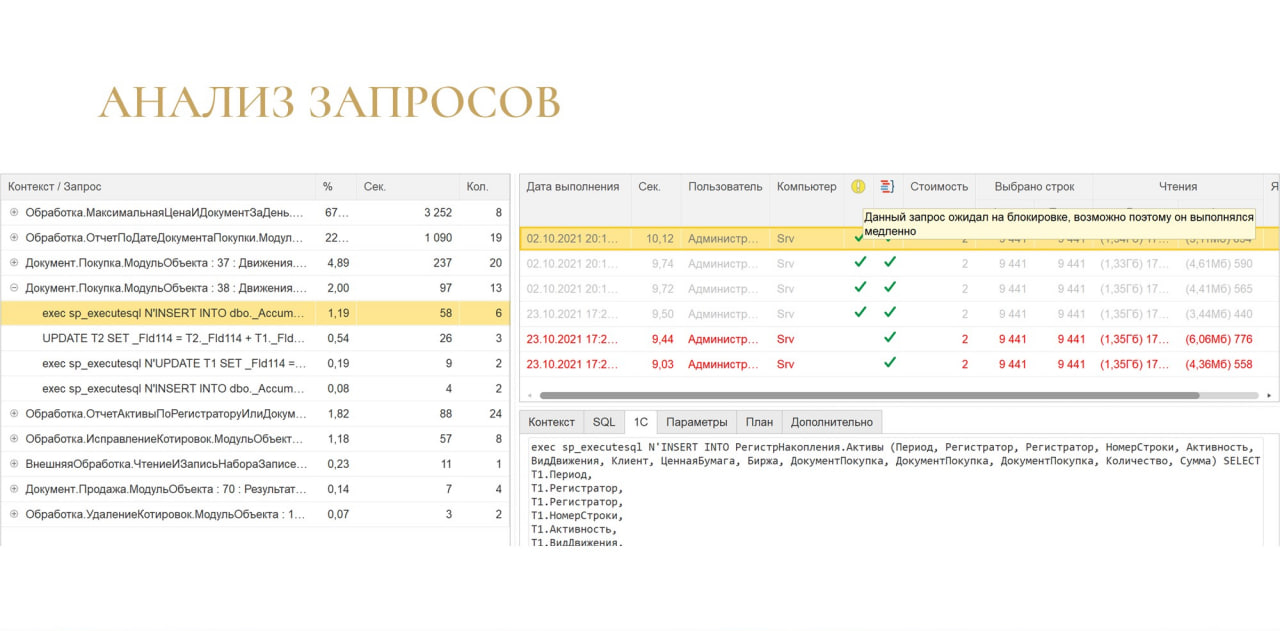
Есть столбец с желтым кругом, который показывает, что запрос был выполнен медленно не потому, что он сам по себе плохой, а потому что он ждал на блокировке.
Так как система собирает и блокировки, и запросы, она как бы говорит: «Не трать время на анализ самого запроса, он ждал на блокировке! Иди и занимайся блокировками, а не этим запросом!»
Анализ блокировок

Самое интересное – это анализ блокировок. Здесь было много интересных неожиданностей.
Изначально схема была такая же – я думал, что соберу Extended Events, сопоставлю с данными ТЖ и буду это все анализировать.

Думал, что анализ ожиданий на блокировках будет самой сложной частью. Оказалось, что проблемы были вообще в другой плоскости.
-
Первая проблема – это долгий парсинг логов, потому что для анализа блокировок объем логов получается очень большим.
-
При этом 1С очень медленно работает с текстом – использовать 1С для парсинга так себе идея. Конечно, я изначально это знал, но думал как-то с этой ситуацией справиться.
-
Если у вас управляемый режим, нет смысла ловить в логах запросы с SELECT, потому что SELECT работает на уровне изоляции READ_COMMITTED_SNAPSHOT и данные не блокирует.
-
Это сильно снижает объем логов, поскольку собирать лишнее смысла нет.

Для исключения операций SELECT мы не можем использовать not like – такого условия в технологическом журнале нет. Зато можно использовать условие like и собрать все логи, содержащие операторы UPDATE, DELETE и INSERT.

Но этого недостаточно, потому что объем логов даже с учетом этих фильтров все равно получался довольно большим. Была придумана следующая схема парсинга.
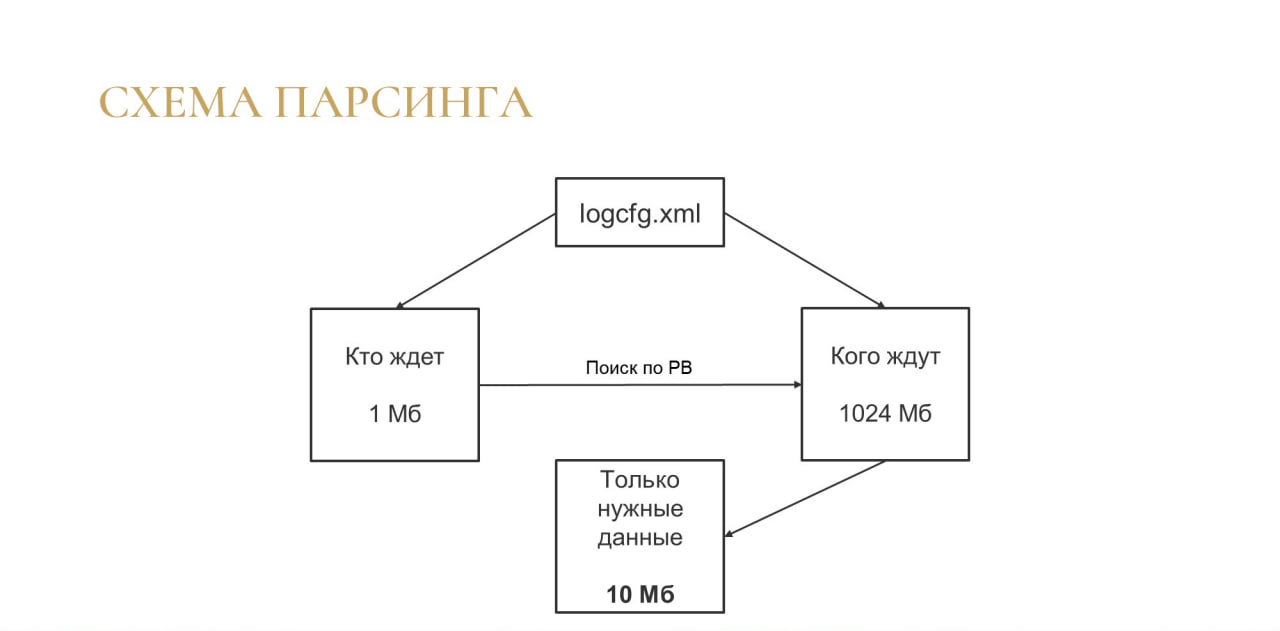
Во многих инструментах мы собираем большие логи, а потом парсим их чем-то внешним. Но мне хотелось, чтобы это был один инструмент, содержащий все необходимое, чтобы не нужно было делать какие-то дополнительные инсталляции. При этом нужно было учитывать, что 1С, как я уже говорил, очень плохо парсит большие объемы.
Поэтому логи поделились на две части:
-
В первый каталог я записываю только жертв блокировок – делаю фильтр в технологическом журнале по свойству WaitConnections и записываю только тех, кто ждет. Объем логов там получается небольшой – может быть, какие-то десятки мегабайт, потому что жертв блокировок за один час не так много.
-
И отдельно я записываю тех, кого ждут – потенциальных виновников. Там уже могут быть гигабайты логов, в зависимости от вашей нагрузки.
Но мне не нужно читать все эти гигабайты, потому что я читаю только жертв. Я смотрю, кто у них был виновником, автоматически составляю регулярное выражение и по этой регулярке ищу потенциальных виновников – не только по номеру соединения, но и через дополнительные фильтры.
И на выходе я получаю готовый файл на несколько десятков (максимум – сотен) мегабайт, который содержит только нужные мне данные.
Мне не нужна внешняя система, чтобы все туда затаскивать и там все это парсить, а потом вычленять нужное. Сразу же из логов я получаю нужные мне данные.
Эти несколько десятков мегабайт я могу распарсить даже в 1С – это не вызывает существенной нагрузки.
Поскольку мне не нужно все это загружать в память, такая схема очень экономна по памяти, а утилита, которую я использую для регулярных выражений, занимает очень мало памяти.
Что я использую

Для парсинга регулярок я использую такую классную вещь как Ripgrep. Может быть, вы уже о нем слышали.
-
Он гораздо быстрее, чем обычный Grep, работает феноменально быстро.
-
Еще эта утилита мультиплатформенна: можете установить ее и на Linux, и на Windows.
-
Самый главный плюс – она бесплатна.
-
Вы можете скачать ее с GitHub https://github.com/BurntSushi/ripgrep.
Вы можете использовать эту утилиту на каких-то своих проектах. Если вы используете обычный Grep, попробуйте Ripgrep, я думаю, вы будете приятно удивлены.

Вторые «грабли» – это многострочные события. Я думаю, что все, кто когда-то пытался парсить технологический журнал, сталкивались с проблемой их анализа.
Например, запросы, как правило, пишутся в несколько строк, контекст – это тоже несколько строк. Написать какой-то алгоритм для распарсивания всего этого, конечно, можно, но он будет не самым тривиальным. Это тоже снижает скорость анализа.
Можно написать регулярку, которая будет делать парсинг многострочных строк, но она очень требовательна к памяти и работает гораздо медленнее, чем регулярка для одной строки.

Для обработки многострочных строк я написал простую утилитку на C++, которая заменяет перенос строк на вертикальную черту «|».
В итоге технологический журнал принимает вид, как на слайде. В нем одно событие – это одна строчка.
Если вдруг по какой-то причине вам это тоже нужно, по ссылке вы можете ее бесплатно скачать и тоже пользоваться.
Просто указываете:
Straighten.exe <ПутьКФайлуЛога>
И на выходе получается файл с таким же именем, только с добавлением *out.log, где для всех событий будут уже прямые строчки. Оригинальный файл остается неизменным, создается копия файла с уже прямыми строчками, парсить который гораздо удобнее и быстрее.
Утилита тоже работает довольно быстро – какие-то секунды. Она больше ограничена возможностями вашего диска, чем самим софтом.
Кто виновник?
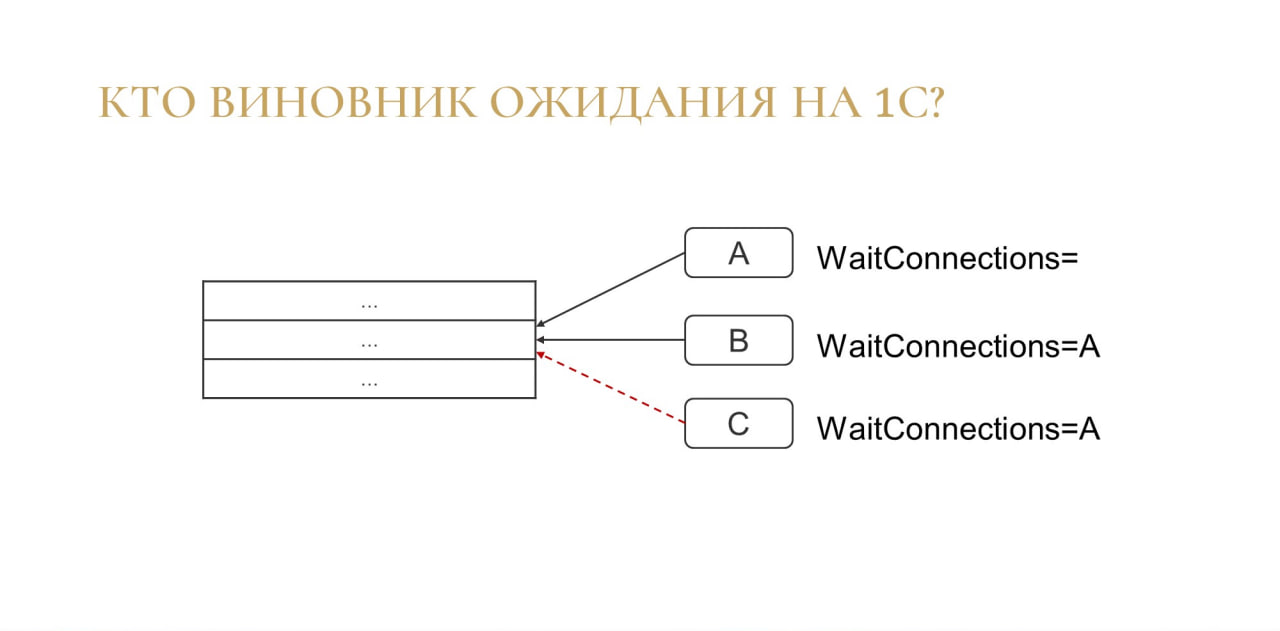
Теперь давайте разберемся, почему некоторые инструменты не полностью показывают ситуацию в вашей базе?
-
Допустим, есть какая-то таблица и какое-то соединение A заблокировало какую-то строчку. WaitConnections – это свойство с номером соединения, которое ждало транзакцию. Если транзакция A никого не ждала, WaitConnections будет пустой.
-
И, допустим, есть какое-то соединение B, которое тоже хочет заблокировать эту строчку. WaitConnections для B будет равен А (WaitConnections=A), потому что А заблокировало эту строчку, а B ее ждет. Все логично, все понятно. Для B виновником является A.
-
Но часто происходит ситуация, когда есть еще транзакция C, и она тоже хочет заблокировать эту строчку. Оказывается, виновником для транзакции C будет A, хотя должны бы быть и A, и B, потому что они обе были виновниками.
Проблема в том, что A может длиться полсекунды и исчезнуть, а B может висеть потом и 15 секунд, и 20 и т.д. но мы в каком-нибудь нашем инструменте можем увидеть, что виновником было соединение A. В итоге мы пойдем по неверному пути, потому что A на самом деле в этой ситуации виновником не являлось.
Получается, что по-нормальному мы эту проблему проанализировать не сможем, потому что здесь нужно показывать нескольких виновников. А в больших базах такие ситуации происходят часто.
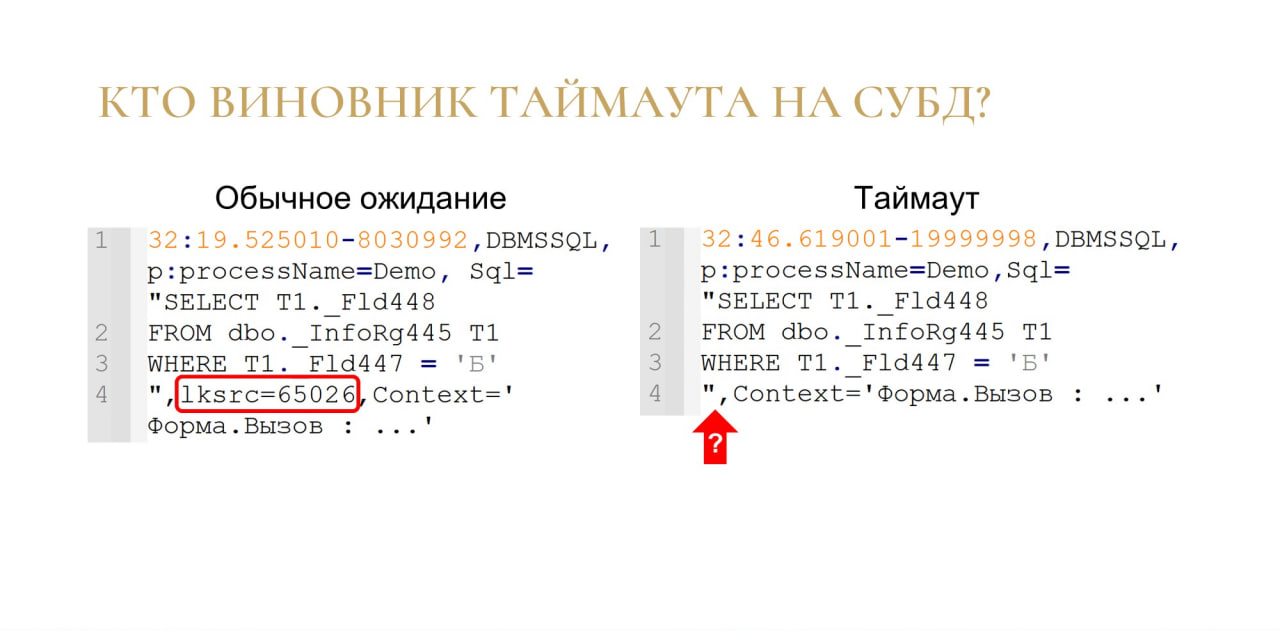
Следующая ситуация. Это мне вообще вынесло мозг в свое время, очень много моих нервных клеток было потрачено.
-
Слева на слайде фрагмент технологического журнала во время обычного ожидания на блокировке СУБД. В этом случае у события появляется свойство lksrc, где указывается номер виновника. Для ожидания все хорошо работает, мы можем проанализировать, сколько секунд длилось ожидание, и по какой причине оно возникло.
-
Но когда случается таймаут, событие в технологическом журнале может выглядеть так, как показано справа. Видите разницу?
Для обычного ожидания номер виновника пишется всегда, а для таймаута у каких-то клиентов свойство lksrc почти всегда пишется, у каких-то клиентов – почти никогда не пишется, в каких-то случаях было 60 на 40 и т.д. Я не увидел вообще никакой зависимости, просто понял, что на это свойство нельзя полагаться, потому что оно нестабильное – может быть, а может и не быть.
И сложность в том, что таймауты – это намного большая проблема, чем обычное ожидание, а без свойства с номером виновника мы не можем его проанализировать по-нормальному.

В итоге было найдено следующее решение.
-
Регламентным заданием я постоянно отправлял прямой запрос к СУБД и получал сведения о том, кто кого ждет.
-
Данные записывались в регистр.
-
Это решало проблему, но было очень неудобно.
-
Но потом произошло кое-что интересное… Как только я написал этот механизм, через несколько месяцев я заметил, что свойство lksrc стало добавляться в 100% случаев. Какая-то магия.
Снова было потрачено много нервных клеток, прежде чем я понял, в чем дело.
Теперь перейду к разгадке.

Оказывается, если в технологическом журнале включена определенная настройка, запись в любой базе (вообще в любой базе кластера) вызывает служебный запрос:
SELECT spid, blocked FROM master.dbo.sysprocesses WITH(NOLOCK)
WHERE blocked > 0 AND lastwaittype LIKE ‘LCK_%’
Этим запросом платформа получает информацию об ожиданиях на СУБД. Из этого запроса она берет информацию, которую пишет в свойство lksrc.
Фишка в том, что пока был таймаут 20 секунд и никто ничего ни в одной из баз кластера не записал, этот запрос не выполняется, и lksrc не пишется, потому что таймаут воспринимается как ошибка, а не как завершенный запрос.
Этой информации я почему-то нигде не встретил, пришлось разбираться самому.
Решение оказалось простым: если просто каждые сколько-то секунд что-нибудь небольшое записывать в любую базу кластера, мы можем быть на 100% уверены, что это запрос будет выполнен. Все свойства для таймаутов будут заполнены, и мы все таймауты сможем проанализировать.
Иначе у вас нет 100% гарантии, что вы все свои таймауты сможете корректно проанализировать. Да, вы увидите, что они у вас есть. Но без этого свойства у вас не получится разобраться, кто там был виновником.
Что получилось
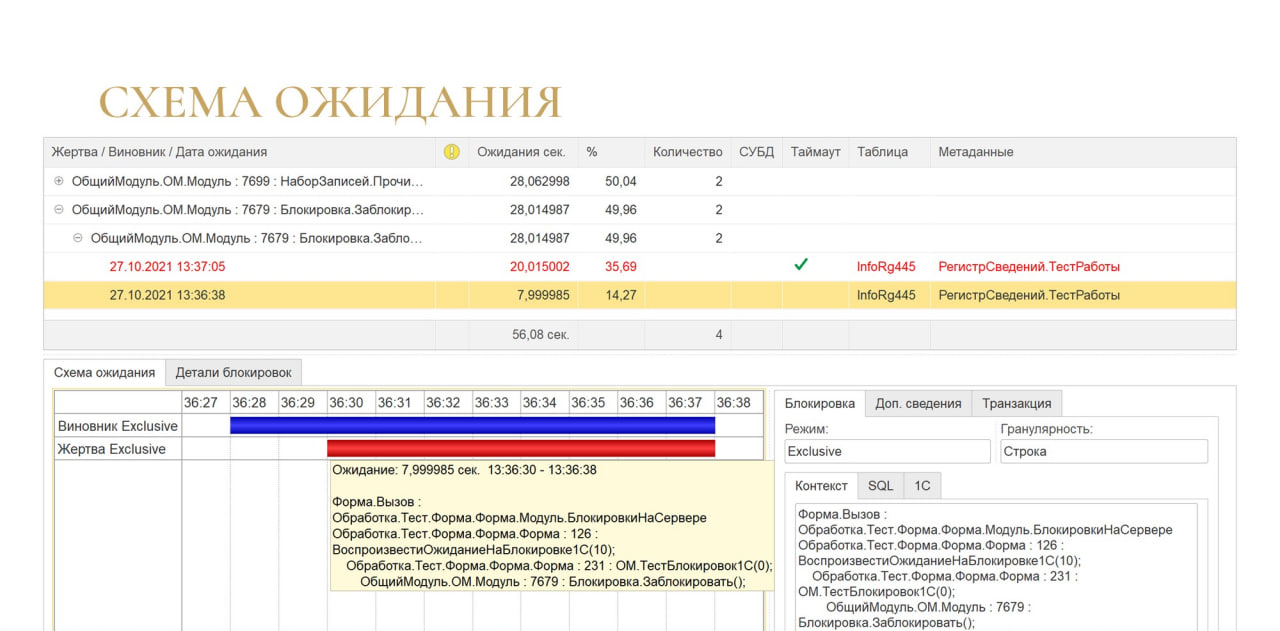
Для анализа таймаутов хотелось сделать какой-нибудь простой и наглядный инструмент, и получилось вот такое иерархическое дерево:
-
в верхней группировке отображаются контексты жертвы;
-
ниже – контексты виновника;
-
и в качестве детальных записей – события; если был таймаут, строка события помечается красным шрифтом.
Но самое интересное – это схема ожидания. Выглядит очень наглядно. Ты сразу понимаешь сколько у тебя длился виновник, сколько длилась жертва, и что там вообще происходило.
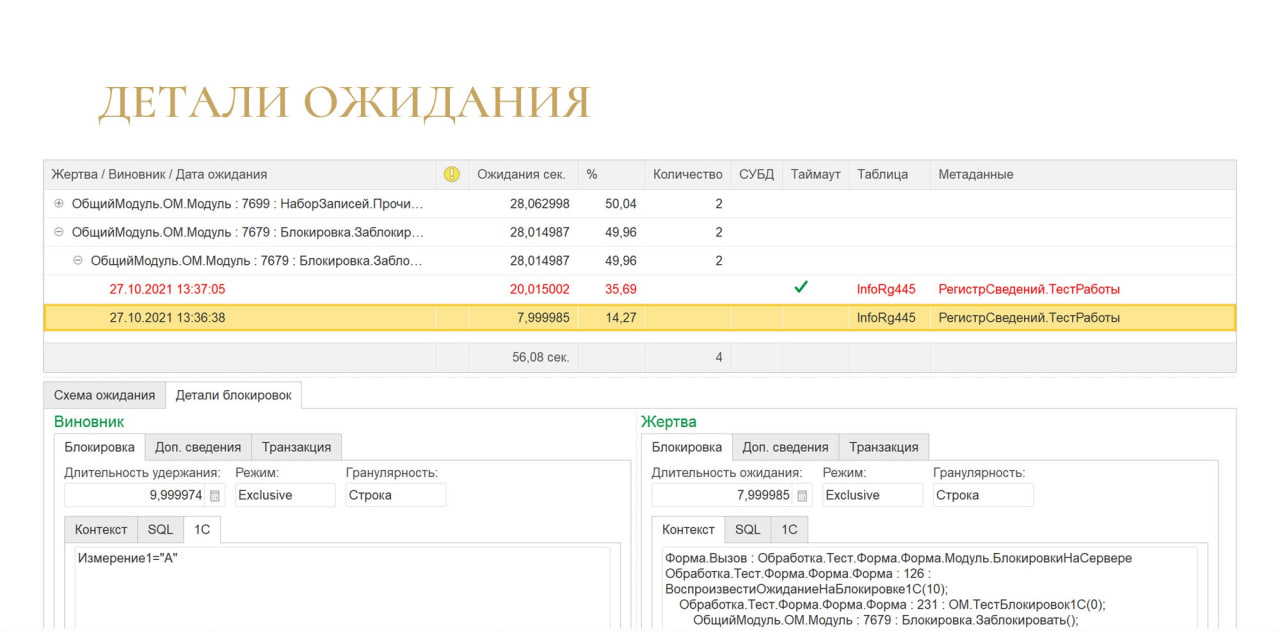
Если нужно погрузиться в детали, есть закладка «Детали блокировки», где можно получить более подробную информацию, в том числе и по транзакциям: когда транзакция началась, когда она закончилась, сколько длилась.
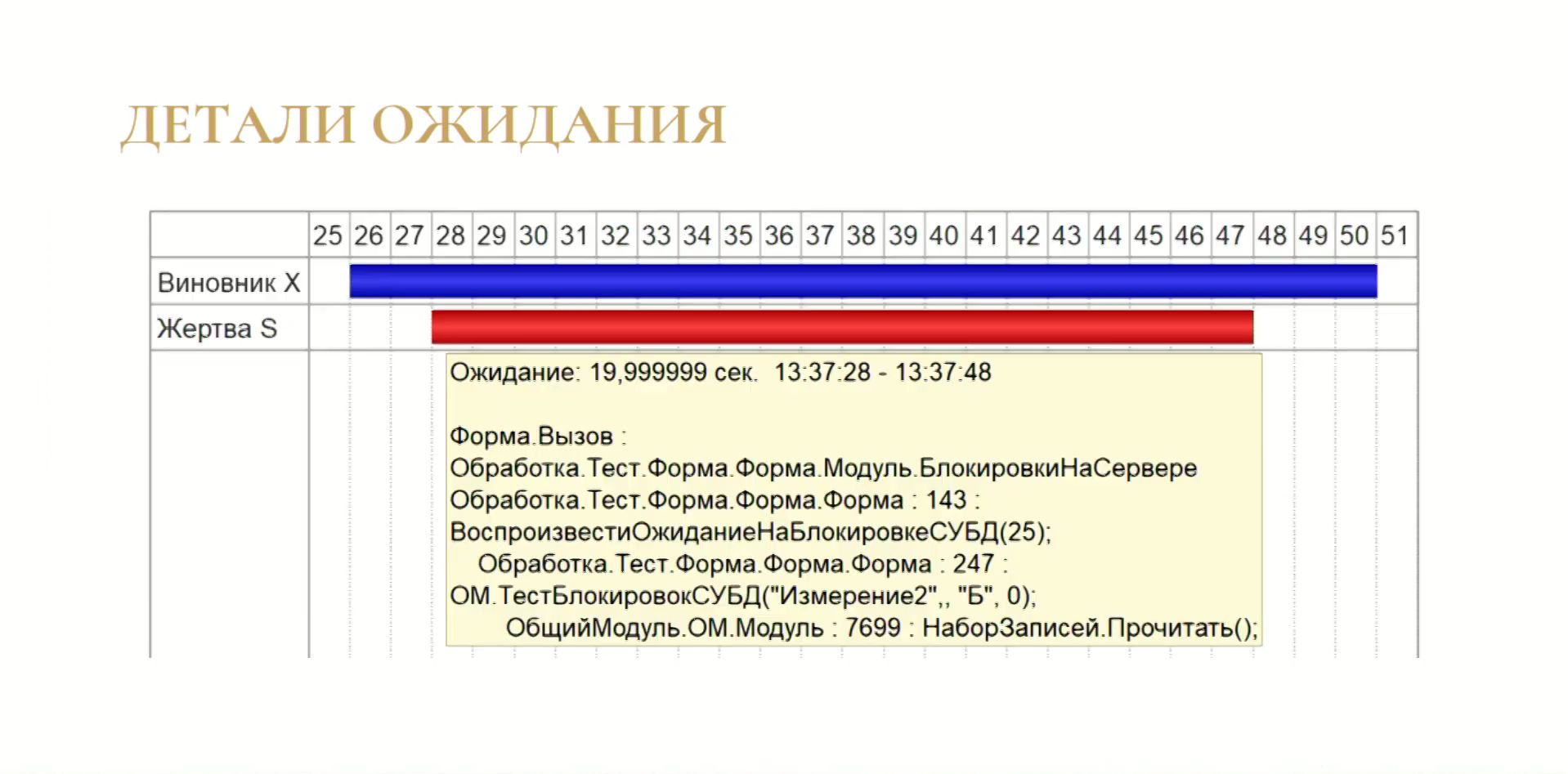
Если время транзакции отличается от времени установки блокировки, на графике это тоже видно.
Вот так выглядит таймаут – как он происходит в жизни, так он и выглядит. У нас долго длился виновник, жертва ждала и не дождалась.
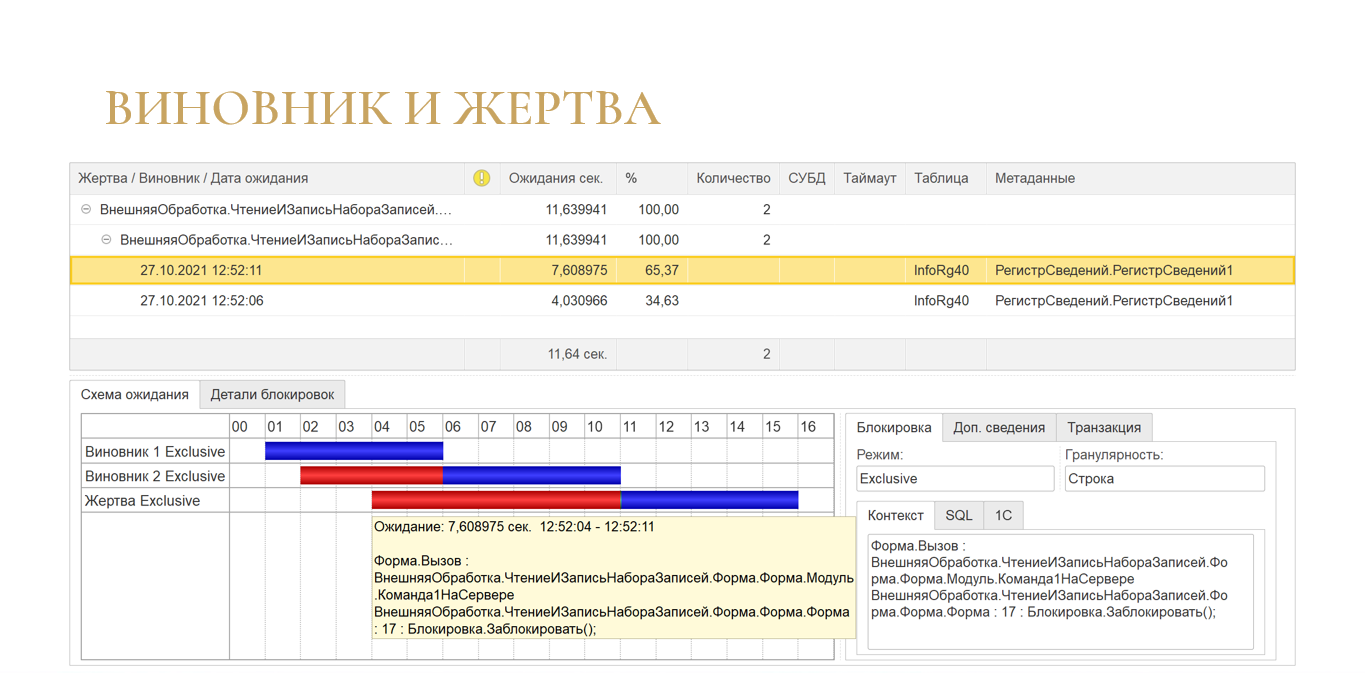
А вот так выглядит ситуация, когда у нас есть цепочка ожиданий. Здесь мы видим, что виновник на самом деле был не один.
Когда вы видите на каком-то объекте много таких ситуаций, это значит, что за него идет высокая конкуренция. Именно с него желательно начинать оптимизацию, потому что там не просто виновник и жертва, а куча сеансов, которые хотят заблокировать именно этот объект. Здесь все это можно проанализировать поэтапно.
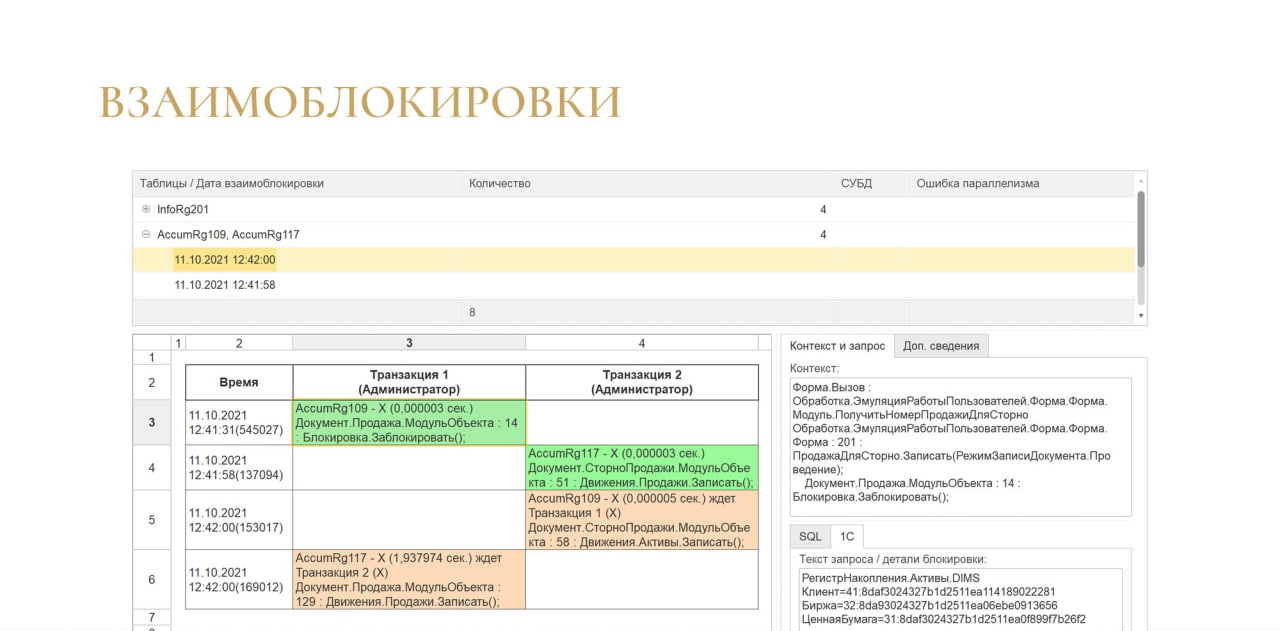
И, естественно, есть анализ дедлоков.
Здесь ничего интересного нет, за исключением визуализации дедлока из анализа параллелизма. Считается, что этот дедлок довольно редкий, потому что есть рекомендация от 1С устанавливать параметр параллельности max degree of parallelism (MAXDOP) в значение «1» и т.д.
Но как только начинаешь ловить все дедлоки в базе, почему-то оказывается, что он не так уж и редко встречается.
Здесь тоже показывается, что запрос распараллеливается и впадает в дедлок с указанием контекста и т.д.
Недостатки

Естественно, есть и недостатки:
-
Так как инструмент писался в первую очередь для себя и для целей обучения, я его старался сделать максимально простым, поэтому пока он работает только на Windows – сервер 1С у вас должен быть установлен именно на Windows.
-
Все эти «красивости» с графическим планом, с количеством логических и физических чтений, с блокировками СУБД и дедлоками доступны только для MS SQL 2012 года и выше. Если у вас другая СУБД, то вы тоже можете использовать этот инструмент, но там уже не будет графического плана, а там будет текст из технологического журнала, там будут только блокировки и дедлоки 1С, информации из СУБД там уже не будет.
-
И платформа 1С требуется 8.3.12 и выше. Это связано уже с интерфейсом. В принципе, можно установить и на 8.3.6, но интерфейс немного «поедет».

Если вам это интересно, можете скачать этот инструмент по ссылке, доступна бесплатная версия. Выпрямитель текста многострочных событий там тоже есть.
Мне будет очень интересно узнать ваше мнение и получить обратную связь о том, что можно добавить или улучшить.
Заключение

В качестве заключения скажу следующее:
-
Парсинг может быть быстрым даже на 1С, просто нужно подойти к этому немного иначе.
-
Строки ТЖ могут быть прямыми – можно использовать специальные утилиты, все это выпрямить, и работать с ними будет гораздо удобнее.
-
Анализ может быть легким.
-
Инструменты для анализа могут быть простыми, несмотря на всю свою внутреннюю сложность. Такими же простыми, как ваша микроволновка.
Вопросы и ответы
Вопрос про чудеса с виновником. Все-таки в любую базу в кластере?
Да, в любую.
Создаем служебную базу с одной табличкой и туда что-нибудь записываем раз в две секунды?
Нет, раз в две секунды – это слишком часто. Раз в 10 секунд.
Именно в кластере? И она все базы отправит?
Может быть даже на сервере, я это не тестировал. Но в кластере 1С будет точно работать.
Как была решена проблема с цепочками блокировок? Если виновник – транзакция A уже закончилась, но в логах именно A, как выявить, что виновник все-таки B? Какой алгоритм стыковки?
На регулярках это сделать не получится. Нужен алгоритм, который ищет пересечение периодов на одном и том же пространстве блокировок.
У него точность почти 100%, потому что он анализирует еще и значения измерений – сначала периоды, потом пространства, потом значения измерений.
Если есть совпадение по значениям измерений, значит, это точно виновник. Поэтому я не делаю предположений, я говорю – вот у вас жертва, вот виновник, разбирайтесь.
Как анализируются ожидания на блокировках из СУБД? Про Extended Events я понял, но оттуда нужно данные как-то забирать. Если не прямыми запросами, то как это происходит?
Из Extended Events? Прямыми запросами. Просто в настройках базы устанавливается логин и пароль подключения к СУБД, там автоматом создаются расширенные события, и автоматом оттуда подтягиваются данные.
А расширенные события, потому что у них много возможностей. Microsoft рекомендует их использовать, они оказывают гораздо меньшую нагрузку, и вообще это очень удобная штука.
Получается, что если нам злобные безопасники не дадут доступ к базе, мы это не сможем сделать. Но мы можем достать блокировки из технологического журнала. 1С-ка тащит же СУБД-шные блокировки к себе в технологический журнал?
Тащит, но у меня большая часть данных получается именно из СУБД, чтобы сократить объем технологического журнала.
И чтобы не парсить?
Да. И там просто совмещаются. Потому что части данных нет в технологическом журнале. Например, нет информации о гранулярности, нет информации о том, какой тип блокировки (эксклюзивная, Shared и т.д.).
Это все можно получить только из СУБД, иначе никак. А если безопасники не разрешают… Гораздо проще с ними об этом договориться, чем договориться о выгрузке данных куда-то в интернет.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт