
Меня зовут Виталий Бусыгин. Я руководитель направления эксплуатации систем 1С в Почтатехе.
Почтатех – цифровая дочка Почты России, которая занимается разработкой и поддержкой абсолютно всех цифровых продуктов почты, которых уже на данный момент более ста. Некоторые из них вы, скорее всего, знаете – это портал pochta.ru и приложение.
Совместная аудитория портала и приложения уже превышает 20 миллионов человек.
Почтатех – это не только 1С. Это большой стек, разнообразные технологии. Суммарное количество сотрудников в Почтатехе – уже более полутора тысяч человек.

Сегодня мы поговорим о том, какие в Почте России ставятся задачи мониторинга, каким образом эти задачи решаются, и о некоторых инструментах, которые помогают нам в мониторинге и в процессе эксплуатации.
Контур эксплуатируемых систем и задачи мониторинга

Экосистема 1С в «Почте России».
Укрупненно, у нас эксплуатируются 10 информационных систем.
-
17 баз – централизованные, поскольку почтовые отделения территориально распределены и работают в 17 централизованных информационных базах.
-
Пять баз из них мы можем назвать высоконагруженными – в них одновременно работают более тысячи активных пользователей.
-
Три информационных системы территориально распределенные – в них более 80 филиалов (узлов) от Калининграда и до Камчатки.
-
Платформа 1С 8.3 – от 8.3.10 до 8.3.21.
-
MS SQL Server 2016.
-
PostgreSQL 10 и 11 версии от 1С, а 13, 14, 15 на данный момент проходят тестирование.
На 2024 г. в эксплуатации PG 12, 14, 15 от 1С.

Пул задач мониторинга и эксплуатации можно поделить на две большие группы:
-
Снизить простой системы при возникновении внештатных ситуаций.
-
Предупредить появление этих внештатных ситуаций, чтобы уменьшить их количество.

Мониторинг в нашей компании разделен на три больших блока.
-
Мониторинг инфраструктуры.
Сюда относится самый нижний уровень – это сеть и виртуализация. -
Мониторинг оборудования.
Все, что касается операционной системы, в т.ч. производительность, работа любого дополнительного ПО. -
Мониторинг производительности, стабильности и функционирования 1С, в том числе бизнес-логики, про которую мы тоже поговорим.
Задачи службы эксплуатации

Одна из поставленных задач – контроль доступности информационных баз:
-
Есть пользователи, которые работают в базе по своему рабочему времени – условно, они подключаются с Дальнего Востока, а в Москве в это время ночь.
-
Есть службы, которые консолидируют данные, например, для аналитики.
Исходя из этих требований - база должна быть доступна круглосуточно – о любых проблемах нужно узнавать оперативно.
Инструментом для реализации данной задачи был выбран ЦКК – «Центр контроля качества» из «Корпоративного инструментального пакета».
Почему ЦКК? Потому что это все-таки 1С. Там большая часть задач уже решена «из коробки» – например, данная задача там решена контрольной процедурой «Контроль подключений». А если потребуется доработка – решается собственными силами.
Но у 1С есть особенность – графики, которые строятся в 1С, непрезентабельные, и их не очень удобно выводить в веб. Всю визуализацию мы перенесли в Grafana.

Итак, база работает, доступна – это мы уже мониторим.
В определенный момент начинает сыпаться много обращений с жалобами, что что-то работает не так. Пользователи массово жалуются – начинается эскалация наверх.
Анализируем проблему – снизилась производительность системы. Нужно придумать как контролировать производительность, чтобы предупредить подобные ситуации и обеспечить требуемый уровень производительности системы.
Для мониторинга использовали контрольную процедуру «Контроль производительности» в ЦКК и визуализацию в Grafana.
В ЦКК есть оповещения по снижению производительности APDEX, но они нам не совсем подошли, страдает оперативность – APDEX требуется предрассчитать, и только потом можно отправлять информацию по отклонениям.
Мы разработали свою небольшую подсистему, которая оперативно рассчитывает снижение APDEX за последние 15 минут. Доработан блок обнаружения инцидентов, который позволяет механизм гибко настраивать.
APDEX контролируется:
-
за последние 15 минут в целом;
-
по определенным важным пользователям.
(у них может быть другая картина производительности, нежели во всей базе)
Рассылка оповещений о снижении происходит штатными средствами ЦКК.
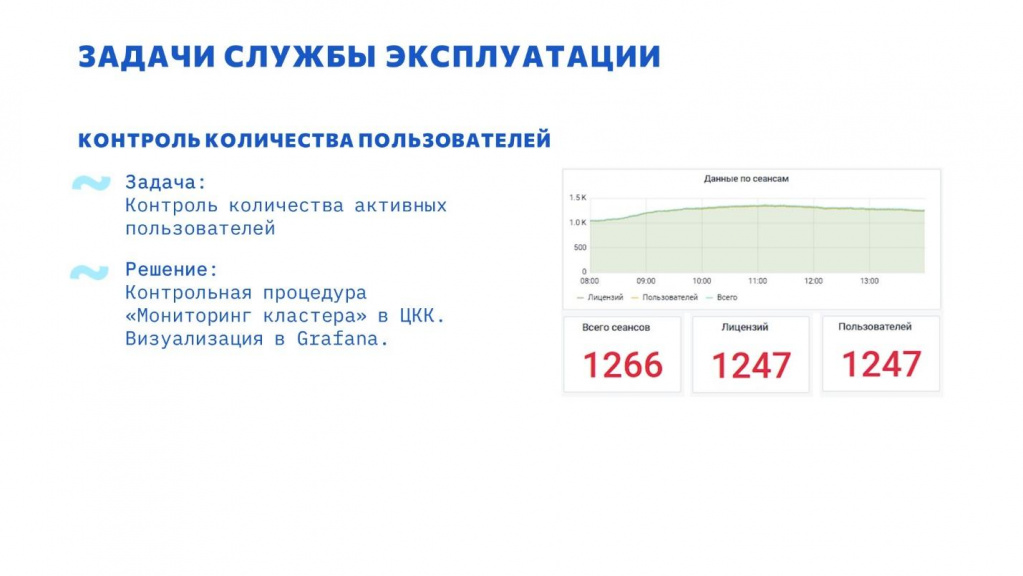
Базы растут, количество пользователей увеличивается.
С этим связаны две ключевых проблемы.
-
Лицензии могут закончиться.
-
Оборудование может оказаться перегружено, т.к. подбирается под определенное количество пользователей так, чтобы максимальная нагрузка на него не превышала 80% от возможной, а базовая была не выше 60%.
Решение – отслеживать количество одновременно работающих пользователей. Для этого использовалась контрольная процедура «Мониторинг кластера» в ЦКК.
Система, которая показана на слайде, была изначально рассчитана под 800 активных пользователей. И когда количество пользователей подобралось к 1000, появились проблемы производительности. Мы узнали о проблеме заранее и проработали ее – провели нагрузочное тестирование на увеличенное количество пользователей, оптимизировали выявленные узкие места.
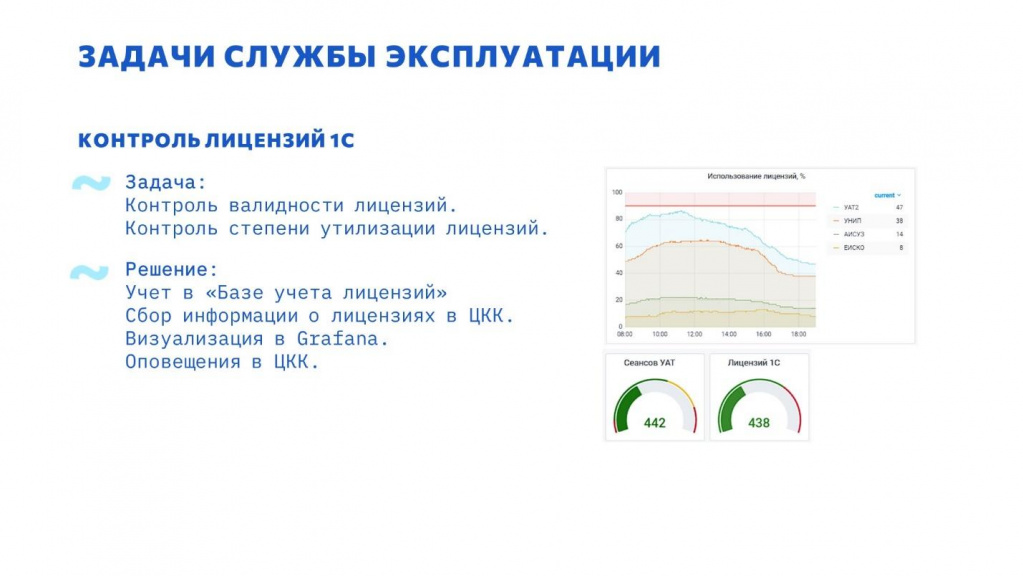
Проблемы с лицензиями не исчерпываются тем, что они заканчиваются. Лицензия может стать невалидной.
Так как все в виртуализации, могут меняться диски, процессоры, виртуальная машина переезжает на другой хост. Как следствие, лицензия “слетает”.
В ЦКК из коробки есть возможность сбора данных лицензий. Этот механизм мы активно используем, но нам он подошел не полностью.
Для реализации всех наших потребностей был разработан инструмент «База учета лицензий». К нему мы еще вернемся.
На 2024 г. полностью отказались от сбора лицензий через агента КИП из-за некоторых проблем в его работе, разработали собственные скрипты.
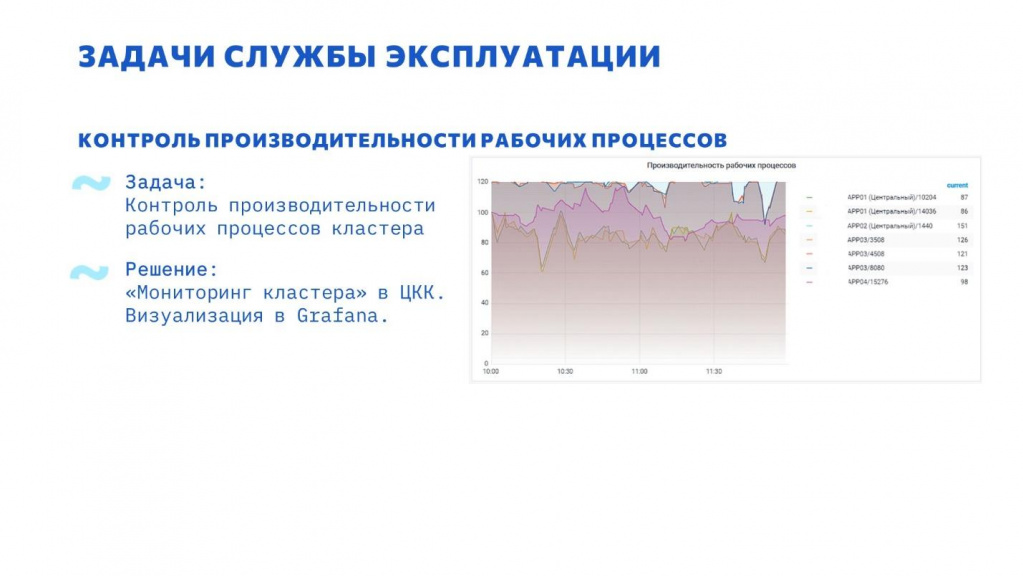
Один из интересных случаев. Столкнулись с проблемой деградации производительности рабочего процесса, когда в результате роста потребления памяти производительность рабочего процесса значительно падает.
Кроме проблемы деградации производительности при наборе памяти, о которой известно, мы столкнулись еще и с аналогичной проблемой при освобождении памяти.
По результатам приняли решение контролировать производительность рабочих процессов. Для этого пришлось немного доработать процедуру контроля производительности рабочих процессов в ЦКК – по умолчанию производительность не собиралась.
В платформе 8.3.20 эту проблему уже решили, после обновления она больше не воспроизводится.

Для расследования проблем стабильности и производительности требуются логи ТЖ, журналы регистрации, собранные счетчики производительности и APDEX.
Баз много, они территориально распределены, за всеми базами и всеми настройками не уследишь – бывает, что базу могут перевести куда-то на другой кластер и даже на другой сервер. Публикация остается прежняя, выгрузки APDEX остаются – визуально и фактическа база работает корректно. Но когда возникает какая-то проблемная ситуация, выясняется, что нет данных для анализа.
Для решения проблем, связанных с изменением расположения баз, был реализован механизм контроля строк соединения в ЦКК. В случае изменения у базы строки соединения создается инцидент в ЦКК и приходит оповещение всем заинтересованным.

Одна из основных задач техэксперта – расследование проблем производительности. Как уже говорили, для этого минимально требуются логи ТЖ, ЖР и счетчики производительности.
Серверов у нас уже больше тысячи и требуется собирать информацию со всех. Чтобы все это как-то автоматизировать, был разработан скрипт, который собирает все эти счетчики и журналы в единое хранилище.
Скрипт на PowerShell для windows, 1С:Исполнитель для linux. Возможности:
-
Первые версии скрипта копировали данные Perflog, ТЖ, ЖР.
-
Данные передаются по протоколу HTTPS – требование информационной безопасности.
-
Актуализация и контроль настроек ТЖ.
При помощи скрипта можно добавлять и модифицировать секции ТЖ. Если настройки сбора ТЖ отличаются от шаблона, скрипт создает инцидент в ЦКК. -
Сбор данных о лицензиях.
-
Актуализация сборщиков счетчиков.
-
Контроль за работой скрипта, удаление устаревших логов, настройки хранения логов реализованы в ЦКК.

Для удобного и быстрого анализа логов был выбран ElasticSearch:
-
ТЖ;
-
Журнал регистрации;
-
логи СУБД.
Для получения консолидированных данных из ElasticSearch и 1С используется небольшая обработка 1С.
В примере на одной временной линии можно наблюдать:
-
событие CALL;
-
внутри этого CALL был DBPOSTGRS;
-
обновление динамического списка.
Таким образом можно увидеть, какие события вошли в обновление динамического списка.
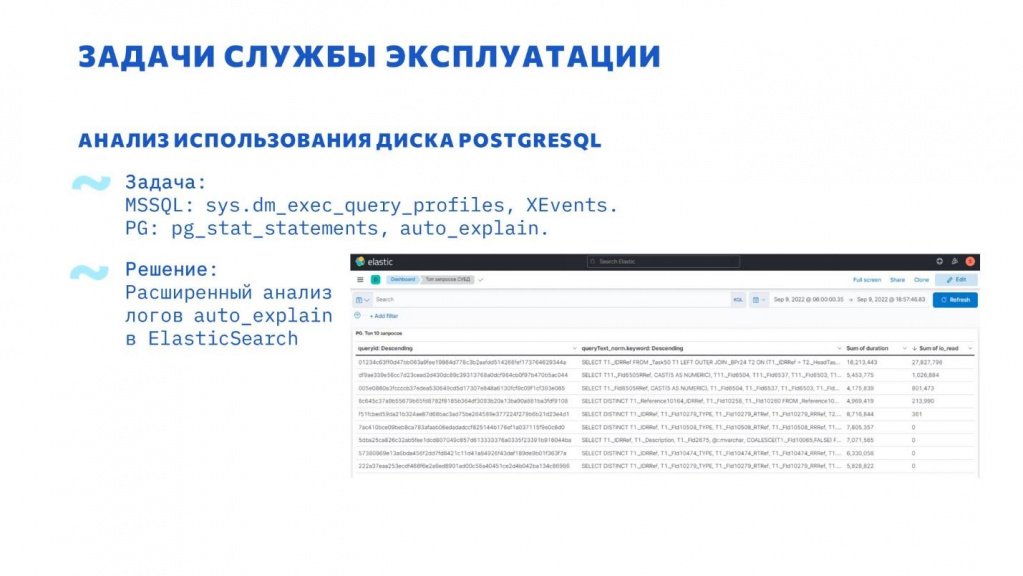
Другой интересной проблемой эксплуатации 1С+PostgreSQL стала высокая загрузка дисковой подсистемы.
В MS SQL исследовать эту проблему просто – достаточно настроить Extended Events.
В PostgreSQL есть инструмент pg_stat_statements. Но возникла проблема с именованием временных таблиц, они часто не совпадают, в итоге получаются запросы отличающиеся только именами временных таблиц. Когда в системе большое количество пользователей и активно используются временные таблицы, pg_stat_statements быстро вытесняется. Базовое значение установлено 5000, мы его поэтапно увеличили до 500 тысяч записей, и пока остановились.
На 2024 г. данные pg_stat_statements+pg_stat_kcache раз в час агрегируются, нормализуются и грузятся в ElasticSearch. После этого статистика pg_stat_statements и pg_stat_kcache очищается.
Следующим шагом стало использование auto_explain. Auto_explain – это расширение PostgreSQL для получения фактических планов запросов. Мы настроили получение планов запросов длительностью более 3 секунд.
При передаче в ElasticSearch запрос нормализуется, по нормализованному запросу вычисляется хэш. По этому хэшу дальше можно получить контекст и сгруппировать по нему.
В результате в одном месте можно по запросу посмотреть его статистику выполнения, фактический план и данные из ТЖ.
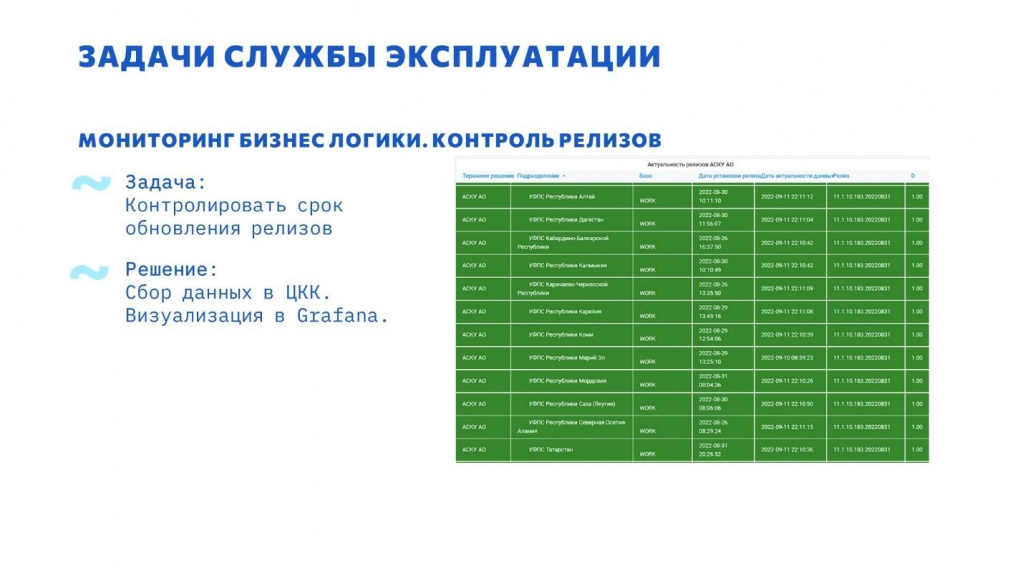
Процесс мониторинга не ограничивается показателями производительности ИС, он также может включать в себя метрики бизнес-логики.
К примеру, у нас есть три распределенных ИС, более 80 баз каждая. И в каждой требуется контролировать версию релиза и своевременность обновления.
Для этого был реализован собственный механизм в ЦКК с выводом в Grafana.

Невидимая, но важная часть работы системы – интеграции.
Если система в целом работает корректно, но останавливается один из обменов, этого можно не заметить своевременно. Последствия могут быть как незначительные, так и довольно серьезные. Для предотвращения подобных проблем был разработан механизм контроля обменов.
Вся логическая и функциональная часть механизма, определяющая, корректно работает обмен или нет, находится на стороне самой информационной системы.
В ЦКК передаются следующие данные об обменах:
-
успешно ли прошел последний обмен;
-
дата последнего успешного обмена;
-
сколько данных загружено;
-
транспорт обмена;
-
иные важные данные об обмене;
-
Получатели оповещений и параметры оповещения;
ЦКК обрабатывает эти данные и на их основании оповещает получателей о проблемах.
Инструменты. ЦКК
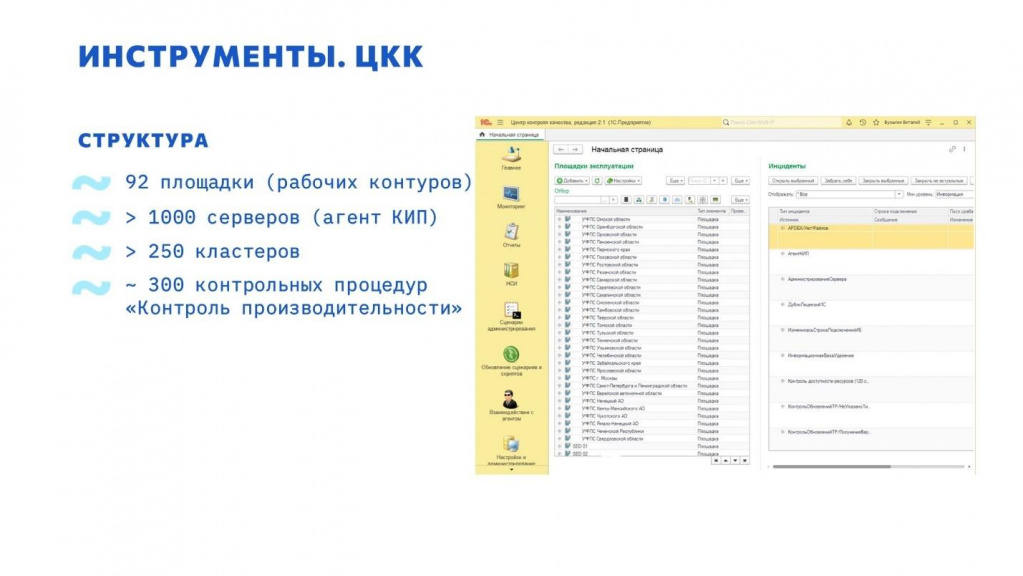
В результате реализации поставленных задач мониторинга мы имеем большую и высоконагруженную базу ЦКК, в которой суммарно контролируется:
-
92 площадки в разбивке по территориальным и по информационным системам;
-
более тысячи серверов – каждый сервер сообщает свои данные при помощи «Агента КИП» раз в 10-30 секунд;
-
более 250 кластеров, из которых раз в минуту примерно собираются данные по сеансам;
-
и около 300 контрольных процедур «Контроль производительности».
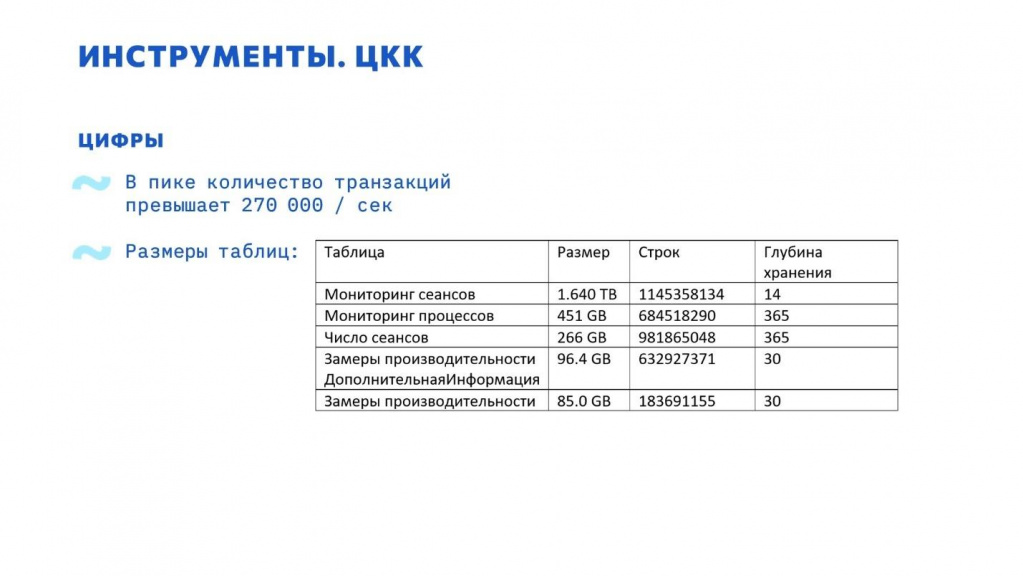
Количество транзакций в моменте превышает 300 тысяч в секунду.
Статистика по таблицам:
-
Размер таблицы мониторинг сеансов сейчас составляет почти 2 терабайта – данные сеансов по всем нашим базам за 2 недели.
На 2024 год объем данным уменьшен до 600 Гб за счет снижения частоты опроса.
-
Таблица мониторинга процессов – статистика по рабочим процессам.
-
Три первых таблицы «Мониторинг сеансов», «Мониторинг процессов» и «Число сеансов» используются в одной процедуре мониторинга.
-
Замеры производительности – APDEX.
На 2024 г. в процессе перевода в ClickHouse.

База ЦКК получилась очень большая, очень нагруженная. В связи с этим возникло несколько проблем:
-
Мы столкнулись с тем, что данные поступают очень быстро, в несколько потоков, а удаляются в один поток – мы не успевали удалять и распараллелили удаление по дням. Каждый день теперь удаляется в отдельном потоке.
-
Примерно такая же проблема возникла с разбором буфера. Сначала все данные поступают в буфер, а потом отдельно разбираются, но в буфер данные поступали в десятки потоков, а разбирались в один.
Узнавали мы об этих проблемах, только когда уже было поздно – данные не загружаются, ЦКК лежит. Ты подключаешься, смотришь, а там данных – на неделю вперед разбирать можно. -
Основная таблица по мониторингу сеансов почти 2 терабайта, и с запросами к ней надо быть очень аккуратным. Проанализировав все запросы, плюс запросы, которые делает Grafana, мы немного изменили структуру регистра – поменяли там пару полей, исключили лишние индексы и один индекс добавили. Теперь проблем с запросами к этой таблице у нас нет.
-
Иногда возникает другая проблема. Статистика по этой таблице не всегда успевает обновиться. И в этом случае планировщик запроса выбирает решение просканировать таблицу. А как мы будем сканировать таблицу 2 терабайта? Естественно он пытается включить параллелизм, но в нашем случае использование параллелизма скорее вредно. Лучше пускай этот запрос работает один, но медленно, чем все остальные не работают совсем.
-
Все эти проблемы нам указали на то, что нужно мониторить и саму систему мониторинга. Как результат был разработан дашборд, на котором были собраны все жизненно важные для ЦКК параметры.
На 2024 г. ЦКК практически не требует контроля
Инструменты. Grafana, БУБ, БУВОО и БУЛ

Grafana – это всего лишь визуализатор того, что уже чем-то собрано. Но очень удобный и гибкий визуализатор. Она умеет брать данные из разных источников и выводить их в удобном виде.

У нас огромное количество разработчиков и подрядчиков, и количество тестовых баз в определенный момент стало превышать тысячу.
Большое количество времени занимала работа с этими тестовыми базами. Для автоматизации этих работ разработан инструмент - база управления тестовыми базами, БУБ.
-
Около трех тысяч тестовых баз.
-
В тестовой среде сейчас производится более тысячи операций работы с тестовыми базами в день.
-
Количество восстановлений из бэкапов в день – более 200. Причем можно восстанавливать базу как планово, по регламенту, так и по запросу.
-
Реализована ролевая модель.
-
Интеграция с Active Directory.
-
Поддерживает работу с Linux и Windows.
-
Поддерживает MS SQL и PostgreSQL (ограниченно).

В определенный момент возникла задача контролировать внешние отчеты и обработки, которые запускают пользователи в базах. Был разработан инструмент «База учета внешних отчетов и обработок» – рабочее название БУВОО.
Сейчас мы в этой базе собирается информация по внешним обработкам. А в будущем планируем научить ее эти обработки доставлять – т.е. ими еще и управлять можно будет.

БУЛ – база учета лицензий.
База учета лицензий хранит данные по учету программных, аппаратных и иных лицензий (к примеру, отраслевых).
БУЛ автоматизирует процесс получения дополнительных PIN-кодов, процесс активации лицензий. БУЛ полностью интегрирована с ЦКК – информацию о фактической утилизации она получает из ЦКК.
Итог
Мониторинг позволяет решать очень много проблем до того, как они появятся – надеюсь, наш опыт кому-то поможет.
Вопросы
Вы сказали, что ЦКК не успевает разбирать из буфера. Скорость разбора – это прямо ахиллесова пята ЦКК, там все плохо. Что вы сделали, чтобы решить эту проблему?
При отставании более чем на час в сутки у нас автоматически подключаются дополнительные потоки.
А бизнес логику не пробовали мониторить? Например, в системе есть цепочка процессов – от заказа покупателя до заказа поставщику. И если цепочка рвется, возникает проблема. Можно было бы мониторить количество заказов или прослеживать какую-то взаимосвязь – проактивно видеть, что возникает резкий спад формирования заказов, значит, будет простой поставок или еще что-то такое.
У нас есть подобная задача – в базе Документооборота мониторится количество документов на согласование.
Я не вижу проблемы реализовать для этой цели в ЦКК что-то наподобие имеющегося у нас механизма контроля обменов. Там есть для этого гибкие инструменты. Плюс всю логику можно описать на нашем родном языке, мы все при необходимости сможем доработать.
Какая система у вас мониторит систему мониторинга?
У нас две ЦКК, первая контролирует все базы, а вторая контролирует первую ЦКК. И они друг друга перекрестно мониторят. Не подводило пока.
А почему бы просто не разделить все базы на два пула – один пул мониторит одна ЦКК, второй – вторая ЦКК и друг на друга они тоже смотрят? Вы же сможете снизить нагрузку в два раза.
Тогда мы лишим себя уникальной возможности расследовать все проблемы в одной базе.
Обратил внимание, что присутствует большое разнообразие платформ, СУБД и так далее. Вопрос по платформам – они действительно все одновременно поддерживаются? И по какой причине?
Хотелось бы, чтобы везде была одна платформа и самая новая. Но, к сожалению, процесс обновления платформы – это не так просто. В нем задействованы и функциональные специалисты, и аналитики, и методологи, которые должны проконтролировать, что все нормально будет. Там нужно провести полное функциональное сценарное тестирование и хорошее нагрузочное тестирование.
Мы не можем просто перевести – если мы прыгнем, не зная, какая там глубина, мы, может быть, утонем, а может быть, ударимся. Лучше подстраховаться.
Но постепенно у нас все переводится – база, которая была на 8.3.10, сейчас уже переехала на 8.3.21.
А какая основная платформа сейчас у вас используется? Самая нагруженная и стабильная.
Самая нагруженная сейчас 8.3.12. Но она не самая стабильная, к сожалению.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт