
Меня зовут Александр Пузаков, более 10 лет я занимаюсь разработкой на платформе 1С, последние 4 года работаю в компании «Магнит».
Я расскажу о принципах SOLID применительно к 1С.
-
Сначала опишу, что вообще такое принципы SOLID
-
Расскажу, чем принципы SOLID будут полезны 1С-никам.
-
Разберем каждый из пяти принципов – я дам определения, пояснения и много примеров кода:
-
Красным крестиком будут отмечены негативные примеры кода, противоречащие принципам SOLID,
-
Зеленой галочкой будет отмечен код, соответствующий принципам SOLID.
-

Рассказывать буду на примере кода вот этих двух красавцев.
-
Федор – классный парень, но ничего не знает о принципах SOLID.
-
Харитон Иванович – старый воин, давно работает разработчиком, хорошо знает и применяет принципы SOLID, знает толк в хорошем коде.
SOLID – принципы дизайна (проектирования)

SOLID – это акроним. Название образовано из первых букв пяти принципов. Сами принципы хорошо дополняют друг друга.
Еще есть такое слово – solid. Оно переводится на русский как «надежный, прочный». То есть эти принципы сделают ваш код надежнее или по задумке должны сделать.

Автор принципов SOLID – Роберт Мартин, также известный под псевдонимом «Дядюшка Боб». Если кого заинтересует эта тема, я советую почитать книгу «Чистая архитектура». Про принципы SOLID там относительно немного, зато есть и другая полезная информация.

Теперь про проблему, которую решат принципы SOLID в 1С.
В каждой конфигурации есть какой-то большой и важный механизм. Например, это может быть расчет зарплаты, расчет себестоимости, какая-то сложная интеграция со сторонней системой и т.д.
Такой механизм состоит из тысяч или десятков тысяч строк кода. Работать с ним тяжело, изучать его долго. Но из-за его важности к нему ведет множество задач.

Если такой механизм хорошенько отшлифовать принципами SOLID, он уже не будет таким большим и монолитным – можно будет удобно и безопасно работать с отдельными его частями, игнорируя все остальное.

Соблюдение принципов SOLID приносит пользу:
-
Код станет проще и понятнее.
-
Кодовая база будет меньше засоряться.
-
Легче писать модульные тесты – код становится к ним более дружелюбным.
-
Код станет более гибким и адаптивным – уменьшатся трудозатраты на доработки.
-
И новым людям будет легче входить в проект – чтобы начать выполнять задачи, им потребуется получить меньше знаний о внутренней кухне проекта.
SRP принцип единственной ответственности

Итак, начнем рассматривать принципы SOLID.
Первый принцип – это SRP (Single responsibility principle), принцип единственной ответственности. Этот принцип – очень важный и отлично применяемый в 1С. Другие применяются в 1С с натяжкой, а этот – хорошо заходит, поэтому про него расскажу побольше.
Принцип единственной ответственности звучит следующим образом: модуль должен иметь только одну причину для изменения.
Тут надо прояснить, что такое модуль и что такое причина изменения.
-
В 1С модуль – это модуль объекта, модуль формы, общий модуль и так далее. А с точки зрения SOLID модуль – это структура поменьше. Допустим, в модуле объекта метаданных «Документ» будет модуль проведения, модуль заполнения на основании, модуль печати и так далее. А при большом количестве кода декомпозиция будет еще сильнее – допустим, модуль проведения по взаиморасчетам, модуль проведения по бухучету и так далее.
-
Причина для изменения может быть организационной или технической. Главная организационная причина изменений – это люди, потому что разные категории пользователей хотят изменения в разное время и по разным причинам.
Давайте разберем все это на примерах.

Стоит задача – провести документ «Реализация» по двум оборотным регистрам накопления.
-
регистр «Продажи» – создан для нужд отдела продаж.
-
регистр «Обороты бюджетов» – заведен для отдела бюджетирования.
Нужно добавить в обработку проведения формирование движений по этим регистрам.

На слайде показано решение задачи, как ее сделал Федор.
В 1С принято данные для движений собирать запросами – так же сделал и Федор.
-
Он написал пакетный запрос, который собирает данные документа и формирует из них таблицы, удобные для записи в регистры накопления.
-
Выгрузил результаты пакетов запроса в таблицы значений.
-
И загрузил данные из таблиц в движения регистров.
Обратите внимание, этот код отмечен крестиком, потому что в одном коде и в одном запросе объединены две ответственности – он отвечает сразу за два отдела.

Рассмотрим ближайшее будущее – к чему это может привести.
Поступила задача из отдела бюджетирования: нужно видеть в регистре сумму без НДС – при том, что в самом документе сумма содержится с НДС.
Федор немного поторопился и внес изменения не туда – теперь сумма без НДС ушла в оба регистра:
-
в регистр «Обороты бюджетов», как и задумывалось;
-
и в регистр «Продажи» – получается, неумышленно сломали логику движений по регистру продаж. Выяснится это не сразу.
Вот к чему приводит объединение ответственности.

А вот так решил задачу Харитон Иванович.
У него код, формирующий движения по разным регистрам, инкапсулирован в разные методы. И работая с движениями по определенному регистру, весь остальной код никак не затрагивается – его уже не сломать.

Принцип единственной ответственности проецируется и на метаданные. Потому что иногда – а местами даже часто – один объект метаданных начинает отвечать за потребности большого количества пользователей.
В данном случае Федор тоже сначала хотел не заводить два отдельных регистра накопления, а думал запихать все в один. Слава богу, что одумался.
Работать с таким регистром потенциально намного сложнее.
-
Тут уже будут и какие-то хитрые отборы по измерениям.
-
Если у нас сумма одна общая, будет сложнее извлечь сумму НДС: либо добавляем новый ресурс «СуммаБезНДС» и редактируем много кода и много запросов; либо в существующих запросах на лету выделяем сумму НДС. Один вариант не лучше другого.
Когда объединили разные ответственности друг с другом, появилось много лишней работы.

На слайде – иллюстрация принципа единственной ответственности схематически.
Слева – модуль с двумя объединенными ответственностями; а справа – тот же код, только разделенный.
-
Модуль с двумя ответственностями:
-
визуально больше, потому что в нем содержится больше кода, разработчик будет работать с большей кодовой базой;
-
к этому модулю опускается большее количество задач от разных отделов – эти задачи где-то будут между собой пересекаться, конфликтовать;
-
возможно, с модулем будут работать разные разработчики, один другому будет наступать на пятки.
-
-
А когда эти модули разделены между собой, сразу же многие проблемы исключаются:
-
разработчик работает с меньшей кодовой базой;
-
не происходит непредвиденных поломок чужого кода.
-
OCP принцип открытости-закрытости

Следующий принцип – OCP (Open Closed Principle), принцип открытости-закрытости.
Принцип OCP звучит следующим образом: модуль должен быть открыт для расширения, но закрыт для изменения.
Мотивация этого принципа – стараться не изменять существующий код, который уже написан, отлажен и работает. Потому что можно что-то сломать.
Чтобы достичь такой защищенной открытости, нужно предусмотреть возможность расширения поведения в коде без его редактирования.
Слово «расширение» здесь ассоциируется с механизмом платформенных расширений, но это немного не то, хотя платформенные расширения позволяют изменять поведение, не изменяя существующий типовой код.

Снова разберем на примере. Тот же документ, что и в предыдущем примере, только добавляются движения еще по одному регистру – «Запасы». Теперь уже для отдела бухгалтерии.

Федор в своем стиле – у него пакетный большой запрос, и он в этом запросе просто добавляет новый пакет, формирующий движения для нового регистра.
Принцип единственной ответственности здесь еще более ухудшился, при этом еще Федор влез в существующий запрос, отредактировал его и мог его потенциально сломать.

А у Харитона Ивановича новые движения добавляются независимо от существующего кода.
Изменения старого кода минимальны – в процедуру инициализации движений добавляется только одна новая строчка, а так вставляется новая функция. Это безопасно и соответствует принципу открытости-закрытости.

На слайде – графическая иллюстрация принципа открытости-закрытости.
Разработчик должен предусмотреть в модуле механизм – точку расширения, через которую будет расширяться поведение в коде.
В будущем через эту точку расширения будет подключаться дополнительный код, при этом старый код не трогается.
Как этого достичь – это отдельная большая и сложная тема, но следующие принципы немного проливают на это свет.
LSP принцип подстановки Барбары Лисков

Следующий принцип – LSP (Liskov Substitution Principle), принцип подстановки Барбары Лисков.
Определение принципа LSP сложное, но оно про взаимозаменяемость типов: чтобы поведение в коде удобно и легко расширялось, должна быть возможность заменить один тип на другой.
Это примерно то же самое, что розетка для электроприборов. Спасибо инженерам, они все продумали: мы один электроприбор вытаскиваем, другой включаем. Представьте, что было бы, если бы электроприборы были вмонтированы в стену и подключались к электропроводке напрямую – для их переключения сразу много лишних действий, много сил, много трудозатрат.

Уточним, что такое тип с точки зрения SOLID.
Это не совсем то, что мы привыкли воспринимать. Да, у нас есть системные типы, прикладные типы, но тип – это понятие пошире. Например, на слайде:
-
Слева два разных типа «Структура». Они не взаимозаменяемы, у них разный набор ключей.
-
Справа – тип «ДокументОбъект». Это очень сложный тип, у него уже много кода и свое сложное поведение.
-
Следующий тип – таблица, полученная выгрузкой из запроса. Здесь запрос будет тоже неотделимой частью типа.
Важный вывод этого принципа в том, что код нужно рассматривать как часть типа.

Важное условие: чтобы типы были взаимозаменяемые, должен быть хорошо придуман и спроектирован контракт типа. Причем мы в 1С используем контракты, хотя и не называем их так.
Первый пример контракта – палитра свойств. У реквизита «Цена» заданы:
-
тип;
-
длина;
-
неотрицательное;
-
минимальное значение;
-
и проверка заполнения.
Набор этих правил образует контракт.
Другой пример контракта, но уже в коде – функция на входе получает параметр «СтруктураДанных», рассчитывая, что это будет коллекция значений с определенным набором свойств.
То, каким должен быть этот набор свойств, как именно эти свойства должны называются, должны ли они быть числовыми – тоже будет контракт функции.

Когда контракты плохо спроектированы и не выдерживаются, возникают некоторые проблемы.
Первое следствие нарушения контракта – это возникающие ошибки.
Например, в коде, представленном на слайде, Федор нарушил контракт функции. Он передал коллекцию значений неподходящей структуре – обратите внимание, у коллекции значений «СтрокаТаблицы» нет колонки «ПроцентНДС», это приведет к ошибке.
Здесь, конечно, проблема не кажется проблемой – ошибка сразу объявится и ее легко исправить. Но если ошибка спрячется где-нибудь в недрах логических условий и будет проявляться раз в месяц, отловить ее будет сложно.

Второе следствие нарушения контракта – засорение модуля сервисными механизмами
Здесь показан обработчик подписки на событие, который срабатывает для некоторых документов. У всех документов есть реквизит «Контрагент», а у документа «ТребованиеНакладная» такого реквизита нет. Из-за этого Федор нарисовал костыль – сервисный механизм, который каким-то хитрым способом опосредованно получает контрагента.
Здесь контракт либо не соблюден, либо плохо спроектирован. Скорее всего, просто не соблюден. В результате такие сервисные механизмы засоряют кодовую базу.

А у Харитона Ивановича с контрактами все хорошо, он принцип подстановки Барбары Лисков знает и соблюдает.
Он заранее позаботился о тех, кто будет пользоваться его кодом:
-
создал шаблон, который содержит все необходимые поля и заполняет их значениями по умолчанию;
-
задокументировал все условия в проверках – добавил для них комментарии в самом начале.
Здесь принцип подстановки Барбары Лисков соблюден.
ISP принцип разделения интерфейсов

Следующий принцип – ISP (Interface Segregation Principle), принцип разделения интерфейсов. Он звучит так: маленькие узкоспециализированные интерфейсы лучше, чем большие и универсальные. Клиенты не должны вынужденно зависеть от методов, которыми не пользуются.
У нас во встроенном языке 1С нет интерфейсов, тем не менее, этот принцип вполне применим к 1С, поскольку нацелен на удобство повторного использования кода.
Философия принципа ISP в том, что не нужно создавать большие универсальные методы – они усложняют переиспользование кода.

Понятие интерфейса нам тоже немного знакомо. Проваливаясь в некоторый модуль, мы видим «#Область ПрограммныйИнтерфейс». Сигнатуры методов, перечисленные в этой области, (сигнатура – это название метода и его параметры) – это и будет интерфейсом.

Рассмотрим, к каким проблемам приводят слишком сложные и универсальные интерфейсы.
Федор привык писать большие методы, которые делают все и сразу. Из-за этого его код в будущем сложно переиспользовать. Его метод делает три больших действия:
-
читает данные из файла;
-
конвертирует – заполняет данными некоторые объекты;
-
и записывает эти объекты в базу.
Если в будущем Федору или кому-то из его коллег понадобится только часть этой логики – например, заполнение объекта – он или кто-то другой не сможет использовать его готовый метод. Он не подходит для переиспользования. Полетят копипасты кода со всеми ошибками, которые были в этом коде.

Харитон Иванович знает о принципе разделения интерфейсов, поэтому старается отделять действия между собой. У него методы более компактные, более узкоспециализированные – делают определенные действия, и он старается поддерживать между ними слабую связь.
В коде Харитона Ивановича методы переиспользовать гораздо проще.
DIP принцип инверсии зависимостей

Последний принцип – это DIP (Dependency Inversion Principle), принцип инверсии зависимостей.
Сформулирован принцип DIP довольно сложно и непонятно:
Высокоуровневые модули не должны зависеть от низкоуровневых модулей. Модули обоих видов должны зависеть от абстракций. Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракции.
Но если кратко, то код, который реализует высокоуровневую политику (бизнес-логику), не должен зависеть от низкоуровневого кода, отвечающего за работу с базами данных, с интерфейсом и так далее. Сейчас поясню подробнее.

Что вообще такое зависимость – в частности, в коде? На слайде два простых метода – метод «Рассчитать» вызывает метод «СложитьДваЧисла».
-
Метод «Рассчитать» зависит от метода «СложитьДваЧисла», он знает об этом методе.
-
А метод «СложитьДваЧисла» ничего не знает о методе «Рассчитать», он от него не зависит, как и от любого вызывающего кода.
То есть стрелка зависимости будет направлена от метода «Рассчитать» вниз к методу «СложитьДваЧисла». Это пример зависимости.

Теперь самое сложное – что такое бизнес-логика и почему она должна отделяться?
Бизнес-логика – это то, что существует вне зависимости от системы. Например, есть расчет процентов для графика платежей по кредиту. Такой расчет процентов существует в объективном мире, и он не зависит от того, с помощью какой системы он автоматизирован – он может вестись в 1С, в Блокноте, в Excel, а может и не вестись вообще. Это и есть высокоуровневая политика.
-
Реализовывать эту бизнес-логику в системе 1С будет код, который рассчитывает проценты и ведет график платежей. Этот код получается на самом верху – ближе всего к бизнес-логике внешнего мира.
-
Код будет записывать значения в базу данных, или в файл, или отправлять на HTTP-сервис – неважно.
-
Также код будет отображать какие-то данные в интерфейсе или еще что-то.
Все, что обслуживает бизнес-логику – это все низкоуровневые детали, бизнес-логика о них ничего не должна знать. Запись базу данных – низкоуровневая деталь, отображение на форме – тоже низкоуровневая деталь.
Здесь, конечно, вызывает диссонанс, почему интерфейс – это низкоуровневая деталь. Но интерфейс действительно лежит близко к аппаратной части. За интерфейсом дальше уже отработка кликов мыши, клавиатуры, операционная система, драйвера – совсем низкоуровневые вещи. Поэтому интерфейс находится тоже внизу.

Разберем на примере, как инвертировать зависимости.
Задача: загрузить файл JSON в регистр «Цены». Стандартная задача, с которой часто встречаются 1С-ники.

Вот как сделал Федор – у него один метод читает данные из JSON, разбирает его и тут же регистрирует цены, записывает их в регистр сведений.
В данном случае код регистрации цен – это бизнес-логика, высокоуровневый код. А чтение из файла – низкоуровневый код.
Но здесь бизнес-логика знает о низкоуровневой операции и зависит от нее – стрелочка направлена от бизнес-логики к низкоуровневому чтению из файла.
Да, тут есть еще работа с базой данных, запись в регистр сведений, но она выполняется через стабильную и безопасную объектную модель, поэтому нормально, что она присутствует в бизнес-логике.

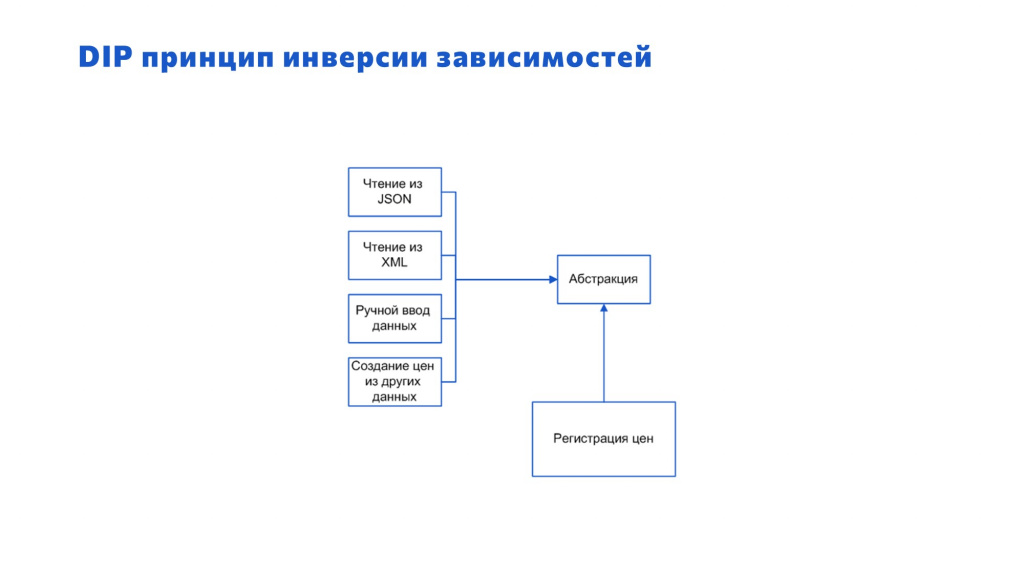
А вот как поступает Харитон Иванович.
Он создает промежуточную абстракцию в виде таблицы значений. Сначала он в эту таблицу значений считывает все данные из файла, и потом уже готовую таблицу значений с данными передает в отдельный метод. У него бизнес-логика инкапсулирована в одном методе, а чтение из файла – уже в другом.
Обратите внимание на схему. Здесь чтение из файла работает с абстракцией. И бизнес-логика тоже работает с абстракцией. Обе сущности зависят от абстракции – их стрелки зависимости направлены к абстракции. Это примерно и есть принцип инверсии зависимости.
Кто знаком с ООП, может кинуть в меня шапкой, потому что в ООП абстракциями все-таки служат интерфейсы и абстрактные классы – такие объекты, которые еще обладают кодом. Но у нас это реализовать сложно, и во многих случаях такой абстракции уже достаточно. Таким образом, принцип инверсии зависимости можно и нужно применять в 1С.
Кто-то может спросить: «Зачем раздувать код и добавлять выгрузку данных в таблицу значений? Что это дает?»
Такой подход имеет далеко идущие перспективы. В будущем к этому коду можно будет подключать и другие низкоуровневые реализации – сегодня у нас чтение из JSON, а завтра мы добавим чтение из файла XML, который прилетает из какого-нибудь веб-сервиса.
Этот XML также будет распаковываться, конвертироваться и записываться в готовую таблицу значений, которая будет передана в тот же самый код, реализующий бизнес-логику.
При этом сам код ничего не будет знать о том, откуда и в каком формате эти данные прилетели – он просто работает с готовой таблицей значений и не зависит от низкоуровневых операций.
Вопросы и ответы
Вы говорили про разделение кода по нуждам разных отделов. Вроде наоборот – стараются делать некий общий 1С с едиными метаданными, а тут: «Давайте разделим – отдел бухгалтерии хочет одно, отдел бюджетирования и продаж хочет другое и так далее».
Разделение по разным группам пользователей – это сильная движущая сила. Чем больше у системы пользователей, тем насущнее принцип единственной ответственности.
Например, в ERP-системе на несколько тысяч пользователей будет департамент бюджетирования на 500 человек, департамент бухгалтерского и налогового счета, где тоже 500 человек, другие департаменты. Это будут отдельные государства со своими хотелками, со своими разными большими запросами.
Их очень желательно отделить. Да, формально они друг с другом взаимодействуют, у них общие справочники и все такое. Но объединение используемых ими регистров и отчетов в одну кучу создает множество проблем.
Заинтересовал принцип единой ответственности. Как он балансирует с вопросами производительности высоконагруженных систем? Меня смутило, что мы считываем одни и те же данные несколько раз.
Вы имеете в виду, что два запроса обращаются к одним и тем же табличкам? Благодаря кластерному индексу отбор по ссылке совершается моментально, никакой проблемы с производительностью нет, все нормально работает. В примере с пакетным мегазапросом тоже есть некоторые накладные расходы на создание временных таблиц. По сути, одно и то же.
Даже если и есть какая-то потеря времени, она очень незначительная, и она нивелируется теми плюсами, которые сулит принцип единственной ответственности.
Мы чуть-чуть может жертвуем некоторой производительностью, чуть-чуть жертвуем местом на диске, когда разделяем регистры между собой, а взамен этого получаем удобство и простоту разработки и сопровождения.
Мы же можем эту выборку данных закинуть во временную таблицу – запроектировать контракт выборки данных, а потом уже использовать его для формирования движений. Это же не так, что мы берем один принцип и только его используем. Они отлично комбинируются.
Да, боевой код будет, конечно, сложнее. Там будут и какие-то общие временные таблицы.
А можно какой-то небольшой вывод? Вы призываете писать мелкие методы, тогда все будет хорошо?
Писать мелкие методы – это хорошая рекомендация. Даже не зная SOLID, она дает серьезный эффект, с таким кодом потом проще работать.
Но если говорить о глобальном выводе – я считаю, что принципы SOLID можно и нужно использовать в 1С.
Когда в системе большое количество пользователей, и всем нужны доработки, разработчики легко и часто сталкиваются лбами, потому что им нужно делить общие объекты.
У нас в «Магните» тысячи бизнес-пользователей в базах. У нас куча аналитиков, куча процессов и групп пользователей. Ранее, когда наша комплексная система была с большими кодами, ее сопровождать и дорабатывать было очень тяжело – мы месяцами ждали очереди для того, чтобы доработать объекты.
Когда мы стали разделять код и метаданные в соответствии с принципами SOLID, мы смогли оперативно дорабатывать объекты сразу для нескольких групп пользователей. Это большой плюс для сопровождения и внедрения доработок.
В докладе делается большой упор на использование принципов SOLID именно при написании кода. Но в классическом ООП речь идет о самих объектах, классах и, например, наследовании. Здесь я услышал, что у вас формируется некое наследование за счет механизма контрактов типов данных. При этом вы переводите понятие типа на другой уровень – это не типы объектов самой 1С, а некоторые абстрактные типы в рамках вашей разработки. А как применять эти принципы в рамках объектов метаданных самой конфигурации?
В ООП все делается через классы. Классы – это и данные, и код. Плюс эти данные и код еще можно куда-то передавать, по-разному вызывать.
А в 1С – процедурный язык, и нет возможности к таким механизмам прибегать. Но все равно многие принципы будут номинально использоваться на договоренности, на вере. Разработчик посчитал, что этот код и эти данные вместе с собой связаны, как-то вместе их рядышком сгруппировал, поставил – это и будет у нас, грубо говоря, класс.
Еще есть такая непопулярная возможность, которая почему-то не используется – у нас обработки и отчеты можно использовать как классы. Можно создать обработку, куда-то ее передавать, дергать ее методы, и она во многих отношениях будет работать так же, как класс в ООП.
Конечно, обработка слишком тяжеловесна по сравнению с классом в ООП, но, если кто-то есть, кто хочет попробовать ООП и ее приемы, можно использовать обработки. Даже больше, некоторые паттерны проектирования могут быть реализованы в 1С, в том числе с помощью обработок. Даже в полной мере.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.


Вступайте в нашу телеграмм-группу Инфостарт