Меня зовут Андрей Крапивин, и я люблю тесты.
У меня есть необычное хобби: когда я устаю от работы, я начинаю писать на чем-то другом. В какой-то момент я решил снова попробовать себя в GameDev – с него я начинал учить программирование. Пару дней выбирал, что лучше – Unity или Unreal. Но поскольку на Unreal у меня уже был опыт, решил попробовать Unity. В итоге провел две недели, просматривая видео о том, как тестируют игры, но так ничего и не начал писать. На самом деле, автоматизированное тестирование игр – это очень интересная тема, прямо захватывает дух.
Чтобы вам было интересно, все картинки у меня в презентации сгенерированы нейросетью, которой я описывал разные мемы. Можете попробовать угадать, где какой исходный мем был.
Пирамида тестирования
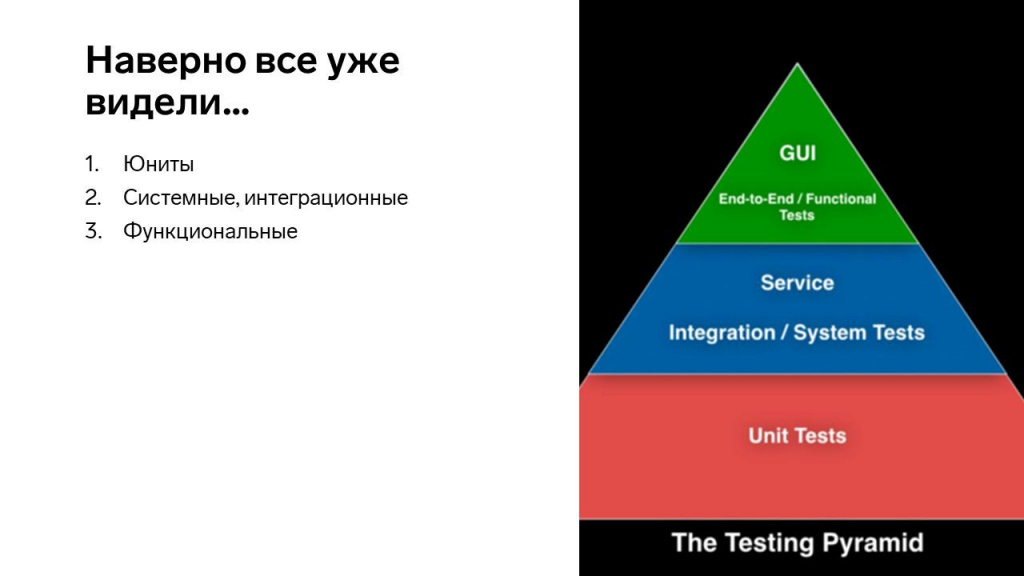
На слайде – так называемая пирамида тестирования, которая говорит, что:
-
код должен опираться на большое количество юнит-тестов;
-
дальше должны идти системные и интеграционные тесты;
-
и последний уровень – это функциональные тесты.

Юнит-тесты – это как иглоукалывание. Вы берете какой-то кусочек кода и тыкаете в него иголкой. Если все хорошо – значит он работает. Если стало больно – значит надо что-то поправить.
-
Юнит-тесты быстрые – ткнули и пошли дальше.
-
Они проверяют точечно.
-
А еще их почему-то иногда называют дешевыми, но, чтобы написать хороший юнит-тест, нужно такую архитектуру построить, что дешевым это не назовешь.

Следующий уровень – это интеграционные тесты. Это когда мы проверили отдельные кусочки кода, а теперь проверяем, как они между собой подружились.
-
Эта категория тестов – уверенный середнячок. Они не сильно быстрые, но и не часами длятся.
-
Сюда же можно отнести те тесты, которые мы пишем на Vanessa: они быстро работают, и с ними код можно быстро поправить.

Самый верхний уровень – это системные тесты, тесты на уровне взаимодействия двух систем. Нам сначала надо подготовить систему №1, потом систему №2 и проверить, что у нас ничего не сломалось. Таких тестов обычно очень мало:
-
Это самые сложные тесты с точки зрения подготовки.
-
И они самые дорогие – они могут длиться долго, их долго подготавливать.
Дальше мы будем говорить только про юниты. В конце будет понятно, почему.
Предыстория применения тестов в отдельно взятом продукте

На конкретном примере одного проекта расскажу, как у нас развивались тесты:
-
6 лет назад, когда я устраивался на работу, у меня в резюме была красивая гордая строчка: «Владею навыками автоматизированного тестирования 1С». Тогда это был хайп, и я надеялся, что это поможет мне устроиться на работу. Мне это помогло устроиться на работу.
-
После того как я прошел собеседование и трудоустроился, мне говорят: «Ты же написал, что умеешь тестировать 1С? Бери код и пиши к нему тесты». Хорошо, я взял Vanessa-behavior, начал писать тесты, но, поскольку я еще не понимал, как нужно проверять результаты, мои тесты сравнивали результат с реальными данными. Сами тесты были хорошие, они показывали ошибки, правда, падали примерно раз в неделю, когда данные менялись. Но, поскольку самих тестов было еще немного – я их быстро правил, и все было нормально.
-
Время шло, я изучал теорию тестирования, осваивал новые инструменты, перешел на xUnit. Это уже были более быстрые тесты – когда я переписал тесты с Vanessa-behavior на xUnit, их выполнение ускорилось раза в четыре. Поставил Jenkins – тесты стали выполняются автоматически по триггеру или расписанию.
-
Дальше я научился мокированию данных. Теперь я не завишу от реальных данных, тесты падают раз в месяц вместо раза в неделю.
-
Прошел курс по тест-дизайну – это был внутренний курс, который обычно проходят только тестировщики. Более того, я стал единственным разработчиком, которого на этот курс взяли. Мне написали: «Давай мы на тебе протестируем?» и после этого не взяли ни одного разработчика. Надеюсь, это не из-за меня.
-
Время идет, появляется еще много всего нового – мы учимся тестировать в Docker, запускаем тестирование на Kubernetes, в GitLab и так далее. Но самое интересное, что баги все равно есть. В той функциональности, которую я начал покрывать тестами еще 5-6 лет назад и построил за это время столько всего нового, все равно есть баги.
Вопрос – кто виноват? Есть варианты?
Виноваты тесты

В том, что баги до сих пор остались, разработчики не виноваты – мы их и так заставили писать тесты. В этом виноваты сами тесты – видимо, они оказались плохие. А почему?
-
Потому что у них сложная логика – надо вспомнить, как они замокированы и так далее.
-
Сценариев тестирования много – функциональность разрослась с 40 до 300-400 тестов. Есть тесты грамматики и т.д.
-
И все это надо поддерживать.

В какой-то момент я подумал, что это напоминает отговорки о причинах, почему обычный код не работает.

Я задался простым вопросом: «Кто пишет тесты для тестов – не на фреймворк, который тестирует, а на сами тесты? Как понять, что то, что я написал, это хорошо?»
Как проверить сами тесты, если учесть, что все есть код?
-
Юниты – это вообще в чистом виде код.
-
Фича-файлы, которые мы пишем – это тоже, по сути, код.
Но прежде, чем я расскажу, как писать тесты для тестов, давайте поймем, что мы будем тестировать.
Как понять, что тесты – хорошие?

Для оценки качества теста есть три классических метрики.

Обычно начинают с покрытия кода. Причем снять покрытие в 1С – это отдельная история, но мы сейчас этот вопрос опустим.
Обратите внимание на слайд:
-
здесь слева – кусок кода;
-
а справа – тест на него.
Этот тест даст 100% покрытие. Но можно ли доверять такому покрытию? Нет, слепо доверять ему не стоит.

Нужно смотреть чуть дальше – оценивать, какой код мы покрываем, какие у него входящие параметры, учитываются ли в тесте возможные значения этих параметров.
Как вы думаете, сколько тестов нужно написать для этого кода? Минимальное количество – три:
-
надо взять какое-то число в интервале;
-
какое-то – мимо интервала;
-
и так называемое «граничное состояние».
Но на самом деле можно включить фантазию и запихать сюда: строку; булево; просто очень большое число; или, наоборот, маленькое дробное. На эти две строчки кода можно написать очень много тестов – вдруг это критически важно?
И последняя метрика – покрытие требований. Эта метрика достаточно сложная для подсчета: нужно понять, что написанные нами тесты покрывают все сценарии, которые исходно были в фиче.
Тесты для тестов
Переходим к тестам для тестов. Возьмем две аксиомы.

Первая аксиома: большинство ошибок, которые вносят профессиональные разработчики – синтаксические. Где-то запятую забыли поставить, метод по-другому назвали, вместо плюса поставили минус. Вроде все хорошо, запускаем отладку: «Поле объекта не обнаружено». Мы допускаем такие ошибки в спешке или по невнимательности, когда уже восьмой час код пишем.

Вторая аксиома – мелкие ошибки могут каскадно вызывать падение системы. Здесь мы минус забыли, там точку поставили, а по итогу база зависла.

На этом и основана идея в тестировании тестов.
-
Мы берем наш идеально работающий код и портим его – начинаем генерировать мелкие ошибки, меняем логические и арифметические операции, еще что-нибудь делаем.
-
И в этот момент запускаем все тесты, какие у нас есть.

Самое главное – тесты должны упасть. Если тест не упал, когда вы явно допустили ошибку – тут уже явно что-то не так.

Это изменение кода называется мутантом. А количество упавших тестов можно легко посчитать – этим мы и занимаемся.
-
Если все тесты упали, считается, что мутанта мы убили.
-
Если тесты упали не все, мутант считается выжившим – мы считаем, сколько у нас выжило, делим на общее количество мутантов, получаем метрику MSI (Mutation Score Indicator) – это и есть процентная оценка качества наших тестов.
Библиотека Mutagen

Чтобы легко реализовать мутационное тестирование для ваших проектов на 1С или OneScript, представляю вам библиотеку Mutagen. Она была нашим внутренним проектом, но я ее в последний момент переписал, и теперь она доступна в OpenSource – прикладываю ссылку на GitHub.
-
Библиотека Mutagen основана на библиотеке osparser, которая умеет парсить язык 1С, строить синтаксическое дерево и выполнять в нем замены.
-
Библиотека Mutagen поддерживает файлы bsl/os. Если у вас на GitHub есть проект с кодом на OneScript и тестами к нему, вы можете настроить себе мутационное тестирование в GitHub Actions и оценить, насколько ваши тесты хорошие.
-
Сам код библиотеки Mutagen тестируется этими же мутантами.
-
В библиотеке уже доступно некоторое количество базовых мутантов – о них я немного сейчас расскажу.

Первый доступный мутант – замена операций. Это когда у вас в коде должен быть плюс, а вы поставили минус. Она заходит к вам в код и делает всякие пакости:
-
Меняет «+» на «*», «-» на «/».
-
Меняет операции сравнения в логических выражениях, в том числе «>=» и «<=» по кругу меняет.
-
Меняет логические выражения – «Истина» поменяет на «Ложь» и наоборот.

Второй доступный мутант – это немного магии:
-
Например, всеми любимые магические числа. Если вы любите в коде оставлять 86400, она найдет такое число и добавит к нему 100 – а вы по результатам тестов посмотрите, что будет.
-
Находит магические строки, добавляет к ним какие-то свои символы.

Есть специфические проверки.
-
Это прерывание циклов – у вас есть цикл, вы в нем пишете «Прервать», а она поменяет слово «Прервать» на «Продолжить».
-
Меняет логические выражения – если вы написали большое, длинное, красивое логическое выражение, она его полностью сотрет и напишет «Ложь» в этот момент.
-
И внезапный выход – просто в начало функции добавляет «Возврат».
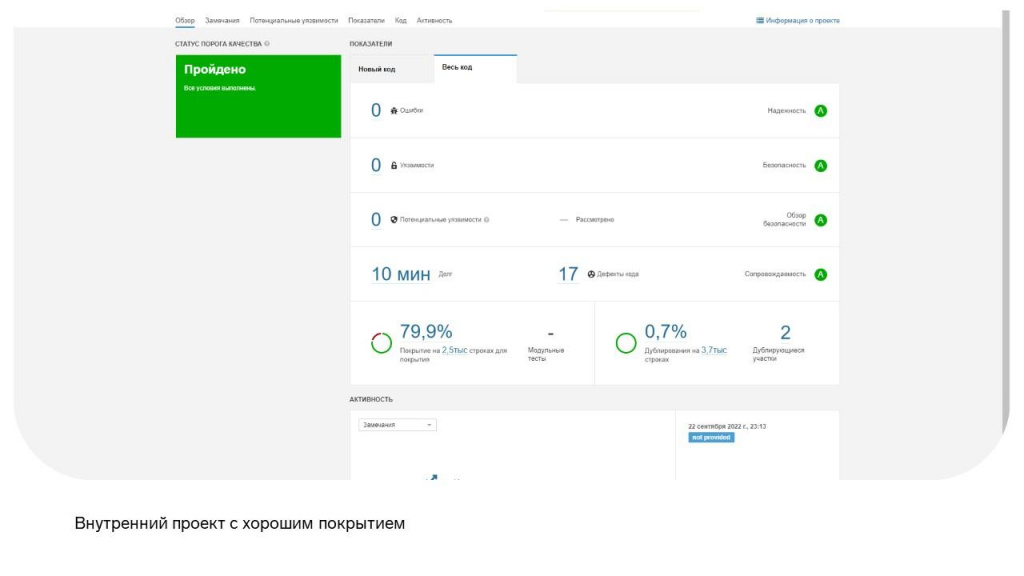
На слайде наш небольшой внутренний проект – расширение, которое достаточно легко собирать и накатывать на конфигурацию:
-
У него хорошее покрытие – 79%.
-
Отличное качество кода – нужно всего 10 минут на исправление всех замечаний.
-
Он маленький – в нем всего 2500 строк кода.
Поскольку я знаю, как с ним работать, я на нем мутации и проверял.
Этапы запуска мутаций
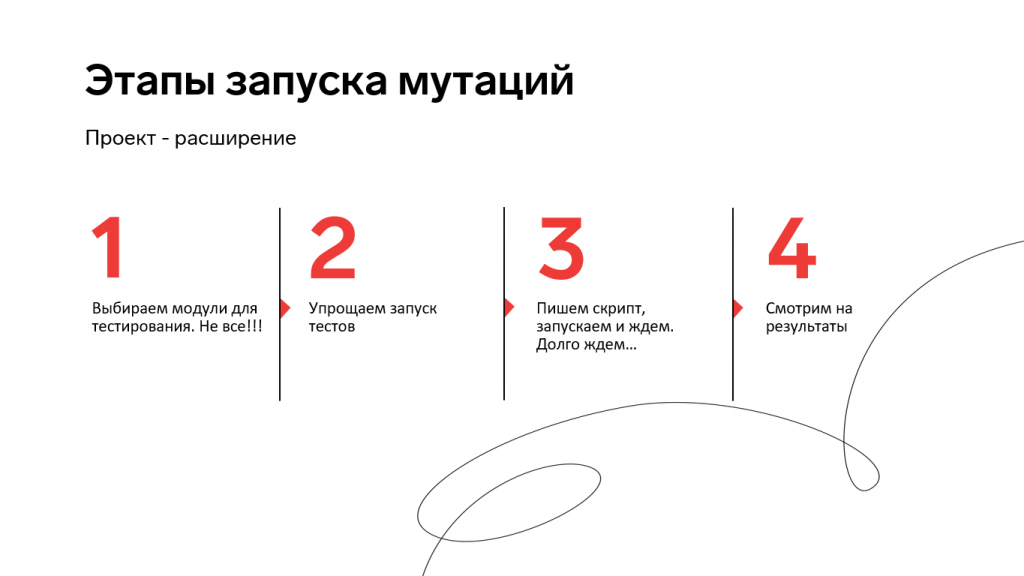
Процесс мутационного тестирования для этого расширения выглядит следующим образом:
-
Мы берем некоторый модуль из расширения.
-
Генерируем на нем мутации – они складываются в отдельный файлик с новым модулем.
-
Собираем из измененных файлов расширение и накатываем на базу.
-
Запускаем все тесты и смотрим на результаты.
Выглядит это все просто, но чтобы это реализовать, нужно написать хорошую функцию для запуска тестов.

Можно было бы использовать для запуска тестов vrunner, но нам было важно упаковать все шаги в отдельный скрипт, поэтому мы использовали Python.
Этот скрипт делает очень простую вещь:
-
подготавливает исходники расширения и загружает их в базу;
-
запускает базу и создает нужные данные;
-
собирает тесты из исходников и запускает их;
-
пишет – удачно они прошли или нет;
-
и в конце готовит отчет в формате JUnit.
В таком виде тест можно запустить одной строчкой – просто выполняем функцию test, и тесты пошли.

На слайде описан порядок запуска этого скрипта.
Как вы думаете, сколько времени заняло его выполнение?
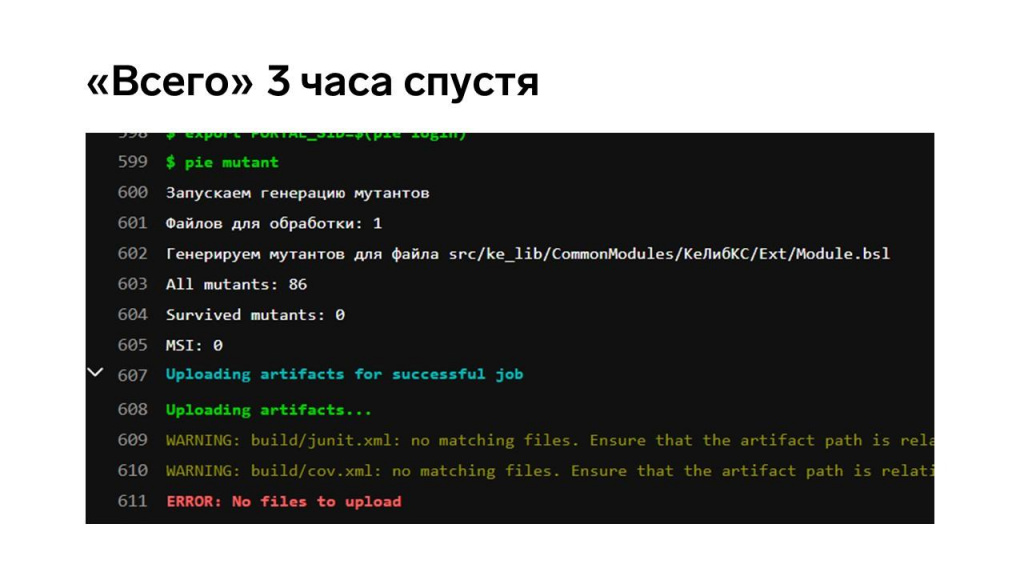
Выполнение скрипта заняло три часа, и это даже не на всем модуле – нам пришлось его специально разделить, потому что выполнялось реально очень долго.
Но все мутанты были побиты – мы убедились, что этому модулю в расширении можно доверять, тестами он покрыт хорошо.
Проблемы
Теперь давайте поговорим, какие у нас проблемы появляются при мутационном тестировании.

Первая очевидная проблема – это очень долго, потому что:
-
кода у нас много, и он нам дает много мутаций;
-
платформа достаточно медленно работает с загрузкой и выгрузкой, чтобы это все собрать и запустить.
Как же это можно оптимизировать?
-
Во-первых, научиться быстро падать. У нас тесты выполняются все, поэтому это было так долго. По факту нам нужен первый упавший тест, и все, можно закрывать.
-
Можно распараллелить выполнение – вынести отдельные потоки в докер и так далее, варианты есть.
-
И аккуратно выбирать модули – не надо брать модули, в которые один тест заходит где-то посередине и все, больше в нем ничего не делается. Мутационным тестированием нужно проверять корневой, суперважный для вас модуль, на который написано много тестов.

Результаты анализировать тяжело, потому что мутантов будет много. И если мы узнали, что какая-то ситуация тестами не обрабатывается, нам нужно:
-
Загрузить измененные мутантами исходники в конфигурацию.
-
Запустить тесты и понять, почему они не падают.
-
Найти тест, который должен падать.
-
И поменять – или логику, или тест.
И зачем оно надо, если так долго?
Нужно ли ждать три часа, при том, что даже саму себя библиотека тестирует порядка 40 минут, хотя она на OneScript.

На самом деле – да, надо, если вы правильно выбрали, что хотите проверять. Если это ваш корневой модуль, на котором завязана вся бизнес-логика или еще что-то, то лучше потратить лишние сутки и быть уверенным, что там точно ничего не сломается, чем потом лечить баги с прода. Это дорогого стоит.
Вопросы и ответы
Правильно ли я понимаю, что нет смысла менять мутантами код, который не очень часто запускается или на него вообще нет тестов?
Да, если на нем нет тестов, он очевидно выживет, потому что ничем не будет проверен.
«Упал тест» – имеется в виду, что тест сообщил о неуспехе, или мы получили необрабатываемую ошибку?
Это же юниты. Юниты так и падают – они выкидывают исключения: или это проверка результата, или это ошибка в программе. В любом случае тест падает в тот момент, когда ловит исключения. Юниты так устроены.
При мутации меняется один участок в коде? Или сколько строк кода, столько и мутантов?
Мутантов может быть больше, чем строк кода – например, в строке кода может быть четыре плюса, это сгенерирует четыре мутанта на одну строку, каждый плюс поменяется на минус или знак умножения.
Мутанты – это точечные изменения, которые проверяют корректность точечных юнит-тестов. Они меняют конкретные символы выражения – например, «плюс» на «минус» или «больше» на «меньше». Если мы поменяем целиком модуль, это нам ничего не даст. Да, тест упадет, но мы не узнаем, насколько корректно он упал.
Какой участок выбирается для изменения? Один тест рождает много разных мутаций во всех местах, где можно заменить?
Тесты-то зачем менять? Меняется исходный файл. Сам запуск библиотеки Mutagen рождает некоторое количество мутаций на один файл.
У приложения Mutagen есть команда run, принимающая в качестве настройки JSON-файл, где настраивается путь к изменяемому модулю и тесты, которые нужно запустить для проверки мутаций – можно запускать все, а можно часть.
Стандартно инструменты, которые анализируют результат выполнения тестов, ожидают ошибки в тесте. А в вашей ситуации вы, наоборот, проверяете наличие зеленых тестов. В этой ситуации зеленые тесты – это беда, они все должны быть красные. При помощи какого инструмента вы быстро находите зеленые тесты?
Любой тест запускается скриптом. Тест может запускать vrunner – он смотрит на код возврата. И наша библиотека на Python тоже смотрит код возврата.
Зеленые тесты – код возврата 0, красные тесты – код возврата 1. Проверяется этот код и принимается решение. Этого достаточно. Библиотека напишет, какой мутант выжил, его можно будет найти в каталоге измененных исходников и посмотреть, какой код получился.
Я правильно понимаю, что проверить конфигурацию целиком нереально? Можно только какой-то один общий модуль туда загнать, и все?
Надо проверять самое критичное – то, что мы полностью закрыли автотестами. Вряд ли самый важный наш кусок кода будет большим – там не миллион строк будет.
Почему? Если это какая-то фронтовая информационная система, на ней куча операций, которые должны быть по максимуму проверены тестами. Если оператор не сможет продавать, а кладовщик не сможет отгружать, бизнес встанет.
Здесь же вопрос в том, что на это должно быть хорошее тестовое покрытие – причем не по строкам кода, а по параметрам и по всем сценариям. Если покрытие у вас хорошее, и это у вас критически важный кусок кода, тогда вы его берете и мутируете. Не нужно брать целиком конфигурацию.
Я для интереса делал мутационное тестирование для своего Python-овского pet-проекта на полторы тысячи строк. У Python есть своя библиотека мутирования – она намного мощнее, чем эта. Она из полутора тысяч строк кода делает порядка полутора миллионов мутантов. Естественно, он тестирует это примерно часа 4. И это Python, который вроде быстрый.
А если мы говорим про 1С, то нужно выбрать что-то такое действительно для себя важное, и прогнать это через мутатест.
Насколько объемные модули вы у себя проверяете?
Не очень большие куски кода – буквально строк 10-20. У меня сейчас 100 таких модулей.
Вы проводите мутационное тестирование на регулярной основе?
Да, запускаем тесты каждую ночь, чтобы инфраструктура не простаивала. За нее же заплачено.
Допустим, у нас есть модуль, покрытый тестами. Мы решили проверить его мутационным тестированием, нашли каких-то мутантов, исправили тесты. После этого, как я понимаю, если мы не вносим никакие изменения в модуль, его не имеет смысла проверять этим инструментом второй раз? В следующий раз его стоит применить только когда у нас что-то там изменилось?
Или изменился набор тестов, или появились какие-то доработки в самом модуле.
Еще может быть вариант, что разработчик самой библиотеки Mutagen добавил новые виды мутантов – хорошо бы ими тоже проверить, может быть, они найдут что-то полезное.
Мне кажется, надо тесты запускать как можно чаще – не рассчитывать на то, что ничего не изменилось. На GitHub у меня на всякий случай каждую ночь проверяет – даже если ничего не меняется.
Получается, что это сервисный инструмент для проверки именно тестов?
Да, это тесты для тестов. Но тесты же используются не просто так, они код проверяют. Мы просто проверяем, что наши тесты действительно проверяют наш код, а не что-то непонятное.
Когда впервые начинаешь писать юнит-тесты, стиль разработки начинает меняться – и функции поменьше, и компактнее все становится. А после мутантов что-нибудь подобное произошло?
Основное изменение в написании, что кода, что тестов, произошло, когда я прошел обучение по тест-дизайну. Мне после этого стало понятнее, как нужно правильно писать код и тесты. А Mutagen – это просто дополнительный инструмент, который мне наутро скажет, где я ошибся в проектировании теста.
Можно ли ограничить участок, где будет производиться мутирование кода, до функции? Есть ли возможность это где-то настроить?
Когда он строит мутантов: он берет весь модуль и строит из него AST-дерево. Там нет возможности настроить, докуда он будет опускаться, он просто берет весь модуль целиком. Он просто идет по веткам, и если находит там логическую операцию, применяет мутанта на логическую операцию.
Получается, что этот инструмент применяется на уровне модуля?
Да. Нет смысла его чем-то ограничивать, иначе мы пропустим ошибки.
Вы сказали, что мутационное тестирование у вас применимо к инструменту xUnit. А можно ли его использовать для сценарного тестирования?
Если сравнивать скорость выполнения на Vanessa или на xUnit, Vanessa проиграет. А поскольку я уже знал, что это будет долго, то взял для демонстрации xUnit.
Но по идее, модуль можно тестировать еще и сценарным тестированием?
В мутационном тестировании речь идет про модули. А писать большие сценарии, которые зайдут в каждую строчку и в каждую функцию – тяжело. Правильнее тестировать модуль. Для этого и есть модульное тестирование.
Как вы находите в себе силы искать эти ошибки? Не боитесь совсем в перфекционизм скатиться?
Когда ты выпускаешь релиз, и в нем уверен, а тебе буквально через три часа прилетает с техподдержки, что что-то сломалось, силы как-то находятся – техподдержка поможет.
Я в докладе рассказывал, что первые тесты для этого продукта я написал семь лет назад. Они оказались нестабильными, я начал их переписывать и продолжаю до сих пор. Прошло семь лет, и ко мне до сих пор с прода приходят репорты об ошибках в тех местах, на которые я написал тесты семь лет назад.
Одна из аксиом тестирования заключается в том, что никакие тесты не найдут все ошибки. Можно использовать статический анализ SonarQube, применять все методики тестирования, включая мутаген – все равно не найдут. Пользователь все равно наступит на эту мину. Тесты и проверки качества кода просто уменьшают вероятность этого события.
Здесь скорее не перфекционизм, а отношение к работе. Мы же программисты, нас мотивирует не только материальная жизнь, но и то, что происходит в нашей системе. Если там происходит что-то хорошее – у нас эйфория и состояние потока. В этом потоке нас несет осваивать что-то новое, мы используем всякие методики тестирования – TDD, мутаген и так далее.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.
Вступайте в нашу телеграмм-группу Инфостарт