







{kind=link}
Про саму технологию CDC отлично написано в статье.
В данной публикации мы развернем Debezium и Kafka в докере, настроим подключение и получим наши первые данные.
Немного теории:
Debezium — это платформа для захвата изменений в базе данных (CDC, Change Data Capture), которая позволяет отслеживать все изменения в данных и передавать их в другие системы в реальном времени.
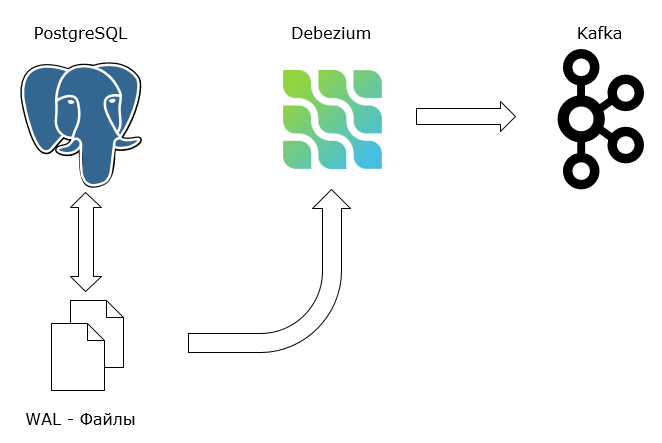
В связке с PostgreSQL и Kafka Debezium работает следующим образом:
1. PostgreSQL: Лог репликации
Debezium использует лог репликации PostgreSQL, чтобы отслеживать изменения в базе данных. PostgreSQL поддерживает механизмы логирования всех операций с данными (INSERT, UPDATE, DELETE) в виде так называемых WAL (Write-Ahead Logs). Эти логи содержат последовательность изменений, которые происходят в базе данных.
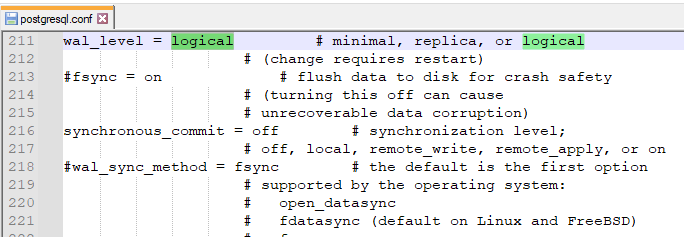
Когда мы включаем в PostgreSQL "wal_level = logical " и подключаем Debezium, то он читает эти логи и отслеживает изменения. Debezium не вносит изменения в базу данных , а просто читает, что было добавлено, изменено или удалено.
2. Debezium: Коннектор для PostgreSQL
Debezium предоставляет коннектор для PostgreSQL, который подключается к этой базе данных и начинает читать WAL. Коннектор работает как агент, который «слушает» изменения. При каждом изменении данных (например, новая запись, обновление или удаление) Debezium преобразует это изменение в событие.
3. Kafka: Передача событий
После того как Debezium считывает изменения, оно передает эти события в Kafka — систему передачи сообщений. А Kafka собирает, сохраняет и передает данные между различными системами, не только 1С.
Debezium отправляет события изменения данных в виде сообщений в определенные топики Kafka. Например, если мы изменяем запись в таблице с Номенклатурой, то событие с информацией об этом изменении будет отправлено в топик, который может называться что-то вроде buhbase.nomenclature. Каждое событие может содержать информацию о том:
- Что это было за изменение (вставка, обновление, удаление).
- Какие данные изменились (старые и новые значения).
Общий поток выглядит так:
- PostgreSQL пишет изменения в WAL.
- Debezium читает эти изменения и преобразует их в события.
- Kafka получает эти события в виде сообщений и распределяет их по топикам.
- Потребители Kafka могут использовать эти события для разных нужд, как, например, обновление данных, обработка или репликация.
Таким образом, Debezium + PostgreSQL + Kafka позволяет в реальном времени отслеживать все изменения в базе данных и использовать эти данные для различных интеграций и потоковой обработки.
Для начала работы у вас должен быть установлен Docker.
Содержимое файла Docker compose:
version: '5.0'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
hostname: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- 2181:2181
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- 29092:29092
hostname: kafka
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
kconnect:
image: debezium/connect:latest
ports:
- 8083:8083
environment:
CONFIG_STORAGE_TOPIC: my_connect_configs
OFFSET_STORAGE_TOPIC: my_connect_offsets
STATUS_STORAGE_TOPIC: my_connect_statuses
BOOTSTRAP_SERVERS: kafka:29092
links:
- zookeeper
depends_on:
- kafka
- zookeeper
Сохраним содержимое в файл docker-compose.yml.
В командной строке перейдем в папку с файлом и запустим команду: docker-compose up -d
Должны увидеть подобную картину:
А в приложении Doker запущенные наши контейнеры:

Для нормального соединения к контейнерам по имени, я еще пропишу в файл C:\Windows\System32\drivers\etc\hosts соответствие имении и IP адреса.
![]()
С помощью программы Offset explorer подключимся к Kafka и проверим, что брокер работает.
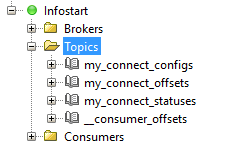
Более того, мы видим топики, созданные Debezium.
Теперь настроим связь между Debezium и PostgreSQL. В базе 1С у меня есть таблица _reference47, будем подключать её.
![]()
Управление Debezium производится с помощью REST - интерфейса, далее я буду использовать Postman.
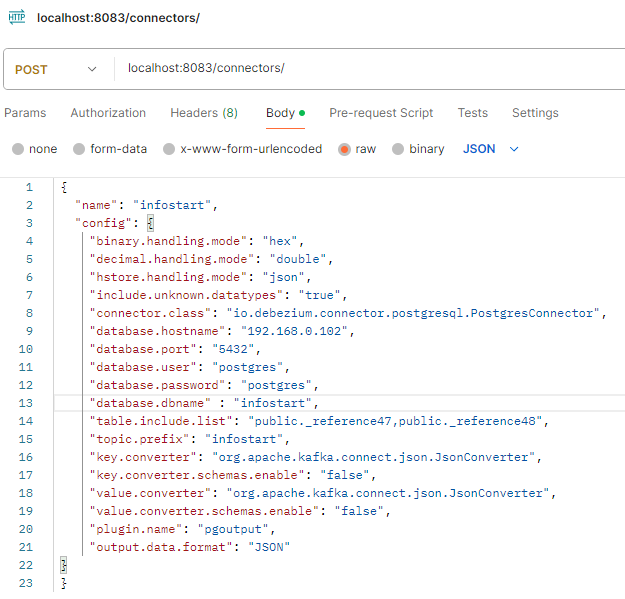
Запустим наш запрос, после этого мы можем проверить, что коннектор добавился с помощью GET запроса.
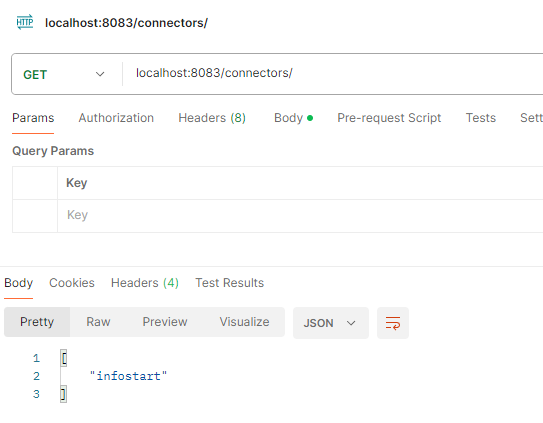
Добавим информацию в нашем справочнике и посмотрим, что у нас появилось в Kafka.
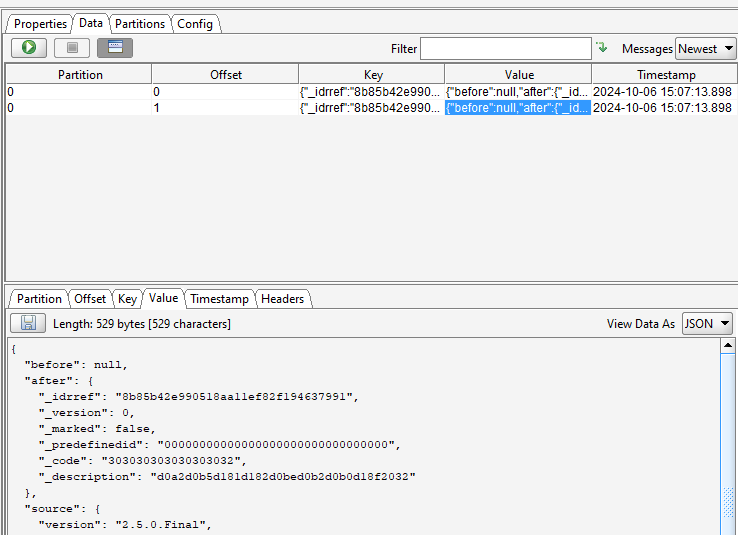
Таким образом мы настроили самый базовый сценарий CDC.
Вступайте в нашу телеграмм-группу Инфостарт