Анастасия: Меня зовут Анастасия Андриянова. Мы с Леонидом Паутовым отвечаем за тестирование конфигурации 1С:ERP. Расскажем, как организован этот процесс в нашем отделе и в целом в фирме «1С».
Начнем с основ. Мир внедрения и мир разработки – это два разных мира. Если на внедрении все понятно – есть конкретная организация и конкретные пользователи, то при тестировании типовой конфигурации есть множество разных вариантов – разные функциональные опции, разные настройки в учетной политике. И мы сейчас с Леонидом попытаемся совместно рассказать об этой непростой задаче – промышленном тестировании конфигураций в компании-разработчике, фирме «1С».

Анастасия: Я работаю в фирме «1С» с 2006 года. Начинала в отделе качества. И вот уже 12 лет я работаю под руководством Алексея Моничева – занимаюсь вопросами качества конфигураций ERP\КА\УТ и отвечаю за сроки выпуска их релизов.

Леонид: Меня зовут Леонид Паутов, я тимлид группы качества в отделе 1С:ERP. Много лет занимаюсь вопросами повышения качества 1С:ERP и других конфигураций. И еще я автор фреймворка для тестов – Vanessa Automation.

Леонид: В ходе доклада мы хотим поделиться опытом – рассказать, какой путь мы прошли, и к чему пришли в данный момент:
-
Погрузим вас в наше закулисье – покажем, как мы разрабатываем и тестируем 1С:ERP.
-
Расскажем, что делать, если у вас мало железа для тестов, и как его найти без особых затрат.
-
Стоит ли дружить с Git и docker.
-
Нужно ли хранить код и тесты «в одной корзине».
-
И может ли 500 ванесс спеть хором?
Доклад будет интересен и тем, кто только интересуется темой тестирования, и тем, кто уже глубоко в этой теме – для таких продвинутых слушателей на слайдах будет специальная иконка. И, конечно, доклад должен быть интересен тем, кто хочет узнать, что же происходит у нас внутри «1С».

Анастасия: Начнем с самого начала. Конфигурация 1С:ERP вышла больше 11 лет назад – расскажу, что у нас было, и к чему мы сейчас пришли.
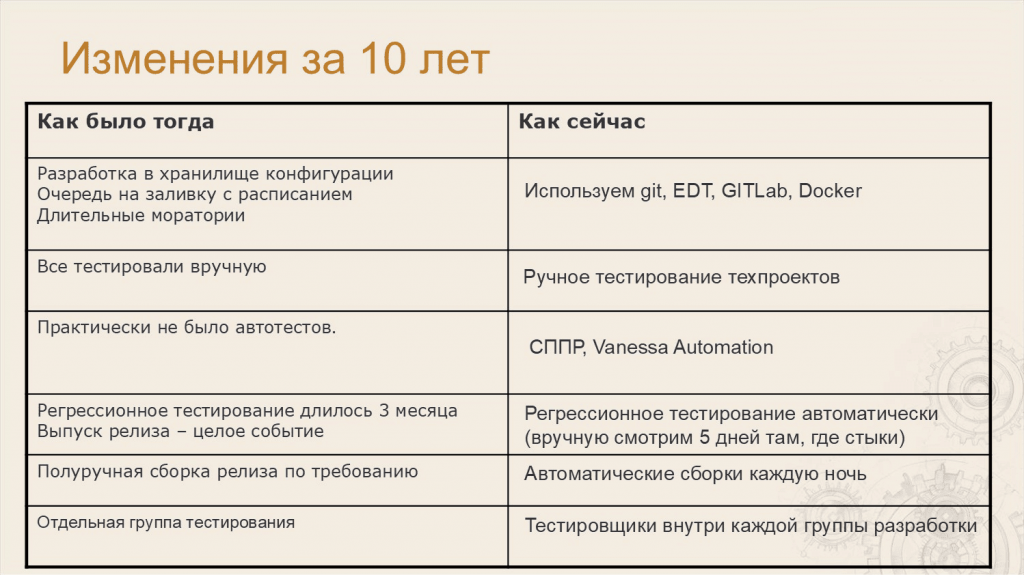
Анастасия: Как мы работали 10 лет назад:
-
10 лет назад мы вели разработку в хранилищах конфигурации. У нас была очередь на заливку – я ходила по группе разработки с блокнотиком и записывала: «Вы заливаетесь в четверг, вы – в пятницу» и так далее.
-
Всё тестировали вручную.
-
Автотесты были, но их было очень мало – можно считать, что их не было.
-
Регрессионное тестирование – это была целая история. Тестировщики с разработчиками садились на три месяца и с нуля тестировали все бизнес-процессы вручную по списку: «Завести организацию», потом «Завести сотрудников» и так далее. Все сценарии мы тестировали вручную с нуля.
-
Сборка была полуручная – это тоже отдельная история. У нас был специальный компьютер-билдер, куда вся фирма «1С» приходила собирать свои конфигурации – БП, ERP и так далее. Это тоже была интересная история – там подкладывали специальные батники и т.д.
-
И была отдельная группа тестирования – нам тогда казалось, что так работать эффективнее.
Как мы работаем сейчас:
-
Мы используем современные технологии – Git, EDT, GitLab, Docker. Далее подробно об этом расскажем.
-
У нас все еще есть ручное тестирование – мы от него не ушли, техпроекты мы тестируем вручную.
-
У нас очень много автотестов. Мы используем Vanessa Automation в связке с СППР. СППР – это тоже наш продукт, его разработали в нашем отделе. Мы постоянно дорабатываем его и используем для наших целей.
-
Регрессионное тестирование у нас тоже на автотестах. Но при выпуске такого продукта страшно доверять все роботам, поэтому закладываем себе еще 5 дополнительных дней, чтобы проверить все стыки вручную.
-
Сборки у нас каждую ночь – без учета человека.
-
И тестировщиков мы распределили внутри каждой группы разработки. Это позволило тестировщикам раньше включаться в проект – свои сценарии тестирования они пишут уже на этапе проектирования.
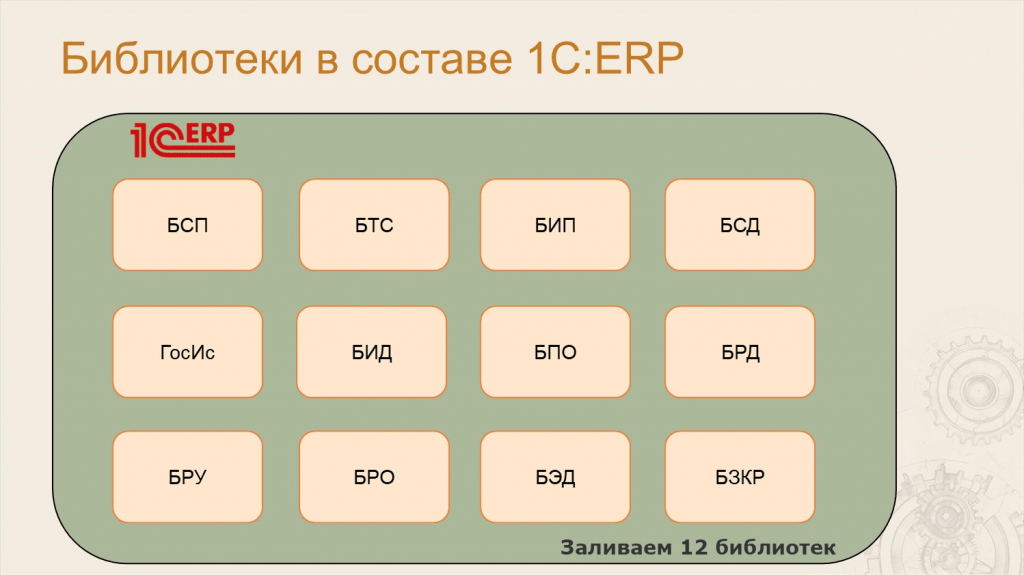
Анастасия: Немного о составе ERP.
В нашу конфигурацию входит не только код, который писали разработчики ERP, мы заливаем еще 12 библиотек. Их в основном тестируют сами разработчики библиотек. Мы тестируем только некоторые.

Анастасия: Разработку мы ведем с помощью технических проектов – это наш внутренний жаргон, терминология СППР. А в общепринятой терминологии технический проект – это большой фича-бранч.
На экране представлен шаблон для работы с техпроектом, у него 6 этапов:
-
открытие проекта;
-
проектирование;
-
разработка;
-
тестирование;
-
помещение изменений в ветку версии;
-
прочие работы по проекту.
В каждом этапе есть предустановленные задачи – они помогают нам разрабатывать и тестировать техпроект последовательно, ничего не забывая. Не откатываться назад и не терять время.
Помимо веток технических проектов у нас есть:
-
релизные ветки – оттуда мы выпускаем релиз;
-
и багфиксовые ветки – для исправления ошибок.
Ни одна ошибка не заливается сразу в релизную ветку, она сначала заливается в багфиксовую ветку группы, потом тестируется и уже после тестирования заливается в основную ветку.
А про особенности архитектуры тестирования расскажет Леонид.
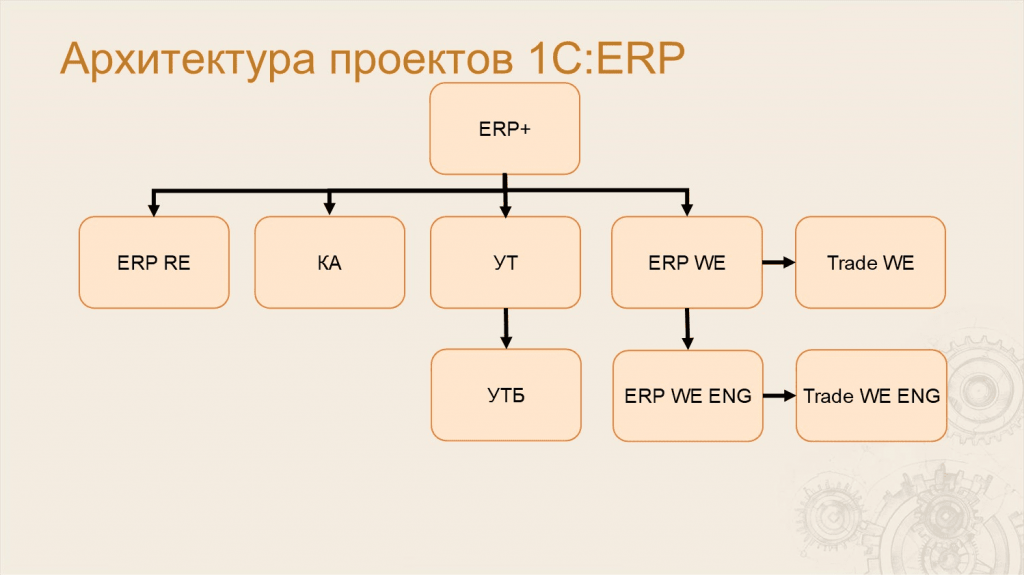
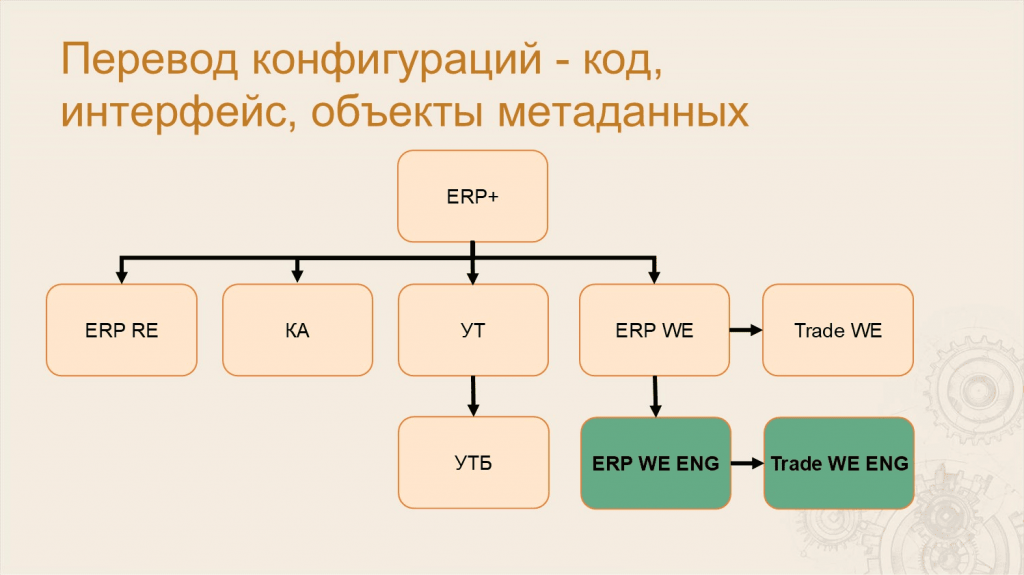
Леонид: Многие уже знают, что из кодовой базы 1С ERP выпускаются и другие продукты. Они как бы из нее вырезаются – такие, как «Комплексная автоматизация», «Управление торговлей». Поэтому корректно говорить про архитектуру группы проектов.
-
Ключевым проектом в этой группе является ERP+. Название ERP+ означает, что в этом проекте есть все метаданные от ERP и еще немного – например, там есть специфические планы обмена, которые есть только в «Управлении торговлей», но нет в самой ERP.
-
Дальше из этого проекта с помощью механизмов вырезки мы получаем другие проекты. Первый и главный из них – это ERP RE, что расшифровывается как ERP Russian Edition. Это та самая ERP с сайта релизов, которую внедряют партнеры – этот продукт вы все знаете как ERP.
-
Также из ERP мы вырезаем «Комплексную автоматизацию» и «Управление торговлей».
-
Из «Управления торговлей» мы вырезаем «Управление торговлей базовую».
-
Еще из ERP+ мы создаем ERP World Edition – это конфигурация для международного рынка, в которой нет специфики российского учета. Там нет НДС, счет-фактур и подобного.
-
Дальше с помощью механизмов перевода мы создаем ERP WE на английском – там переведены код, метаданные и интерфейс.
-
И еще есть две конфигурации – «Управление торговлей» для международного рынка и ее переведенный вариант.
Таким образом, когда мы хотим протестировать ERP, нам на самом деле надо протестировать все эти девять проектов.
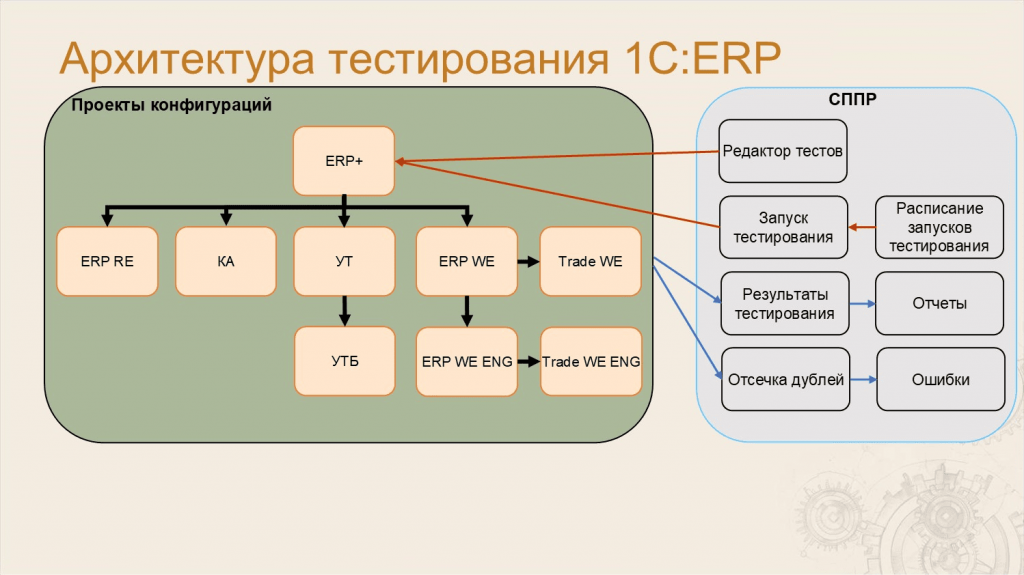
Леонид: Очевидно, что разработкой и тестированием проектов 1С:ERP нужно как-то управлять – для этого мы используем СППР.
Расскажу, как мы используем СППР с точки зрения тестирования.
-
В СППР находится редактор тестов, он же редактор сценариев. Сами сценарии находятся в репозитории Git, а в СППР мы их именно редактируем.
-
Кроме этого, в СППР находится расписание запусков сессий тестирования. Именно СППР определяет то, в каком объеме и как именно будет протестирована конкретная ветка. СППР создает запуск тестирования, который и будет тестировать конкретный техпроект.
-
Потом в СППР приезжают результаты тестирования, которые можно посмотреть в виде отчетов – поговорим об этом позже.
-
И, конечно же, автотесты будут регистрировать ошибки, которые будут приходить в СППР сразу с ответственными за метаданные, разделенные по объектам, подсистемам и так далее. СППР делает отсечку дублей и после этого ошибку отправляет ответственному, который должен с этой ошибкой разбираться.
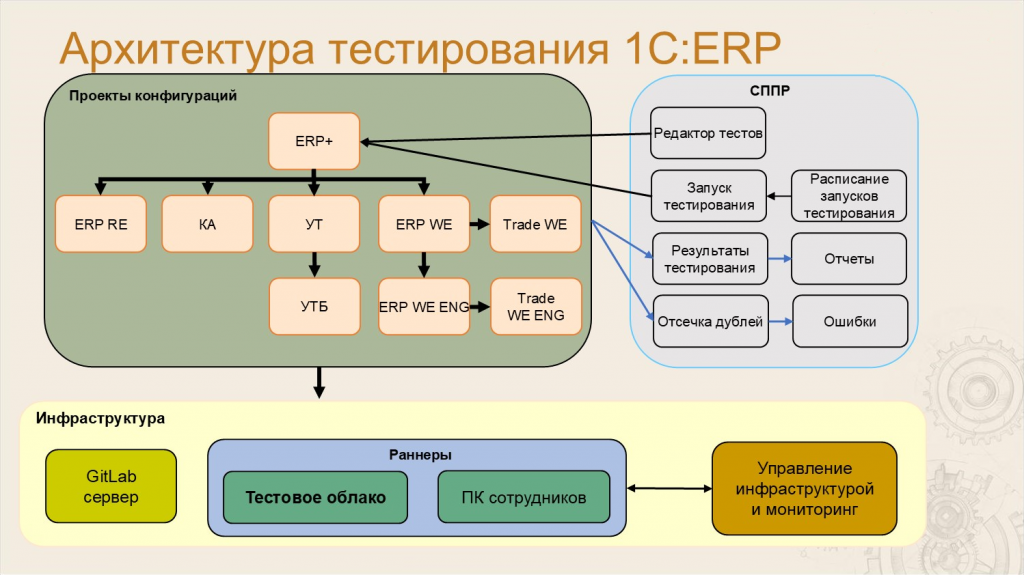
Леонид: Чтобы все это работало, нужна инфраструктура.
-
Ключевым объектом инфраструктуры у нас является GitLab-сервер – наше хранилище репозиториев Git, и, конечно же, Continuous Integration сервер.
-
Для всего этого нужно железо. Основную часть железа нам поставляет тестовое облако, которое находится внутри фирмы «1С». И еще часть железа мы берем от компьютеров сотрудников. Про это расскажу подробнее потом.
-
Ну и, конечно же, у нас есть сервисы для управления и для мониторинга инфраструктуры.

Леонид: Поговорим про тестовое облако. Оно нам дает определенные мощности, из которых мы потом создаем нужные нам виртуальные машины.
Наше облако создано на базе OpenStack. На экране приведены реальные данные, которые мы используем на данный момент:
-
у нас 1200 ядер процессора;
-
2,4 терабайта оперативной памяти;
-
11 терабайт быстрых SSD дисков;
-
15 терабайт обычных дисков;
-
всего получилось 120 виртуальных машин.
Мы используем подход «Инфраструктура как код» – все машины создаются автоматически скриптами и полностью настраиваются. Мы для этого используем Ansible и механизм оркестрации OpenStack.
Во время тестирования мы поняли, что железа всегда мало. И в нашем тестовом облаке есть классная фича – если у другого отдела есть ресурсы, которые он временно не использует, мы можем забрать их себе. Например, мы можем забрать себе неиспользуемую оперативную память, которая была выделена для другого отдела, и подключить ее к определенной виртуальной машине. Это дает примерно плюс 25% к текущей мощности облака.
И есть горизонтальное и вертикальное масштабирование – мы можем создать много разных машин и менять параметры этих машин так, как нам надо.

Леонид: На скриншоте показан типичный пайплайн создания виртуальной машины – это реальный скриншот из нашего GitLab CI. Все этапы создания и настройки полностью автоматизированы – после создания тестируется правильность настроек и готовность машины к работе.

Леонид: Немного технической информации. У нас довольно сложная инфраструктура и много типов виртуальных машин – некоторые самые основные типы я привел на слайде.
Основная идея нашего конвейера – собрать файл конфигурации, сделать на его основе тестовые базы и прогнать тысячи тестов.
Синими скобками на слайде выделены машины, которые мы используем на подготовительной стадии.
-
Docker-checkout – это машины, которые нужны для того, чтобы получить данные из репозитория. У нас в репозитории лежит горячий кэш – он довольно большой.
-
Docker-edt – это специальные виртуальные машины с EDT, которая собирает cf-файл, делает перевод, вырезку конфигурации и так далее. Там чуть более мощные машины.
-
И основные наши рабочие лошадки – это машины docker. Их у нас 50 штук, они шестипоточные. И они нам дают примерно 300 потоков тестирования, чтобы мы могли одновременно тестировать в параллельных потоках 300 ERP.
Все docker-контейнеры работают в Linux на Ubuntu 20.
Еще есть несколько Windows-хостов, они выполняют специфические задачи.

Леонид: Как я уже говорил, железа всегда мало, его всегда не хватает.
Однажды мы столкнулись с тем, что тестовое облако перестало успевать нам выдавать ресурсы. Оно не успевало расширяться настолько быстро, как нам это было нужно.
Мы посмотрели – у нас отдел большой, простаивают сотни достаточно мощных компьютеров и ничего не делают. И решили на них тоже запускать тесты ERP.

Леонид: Сказано – сделано:
-
поставили Docker Desktop;
-
поставили службу GitLab runner;
-
обмазали все это скриптами;
-
эмпирически вычислили, что нам для запуска дополнительного потока нужно 64 гигабайта памяти;
-
и дополнительный SSD-диск, чтобы все это не конфликтовало с тем, что делают разработчики, тестировщики или другие сотрудники.
С помощью этих машин мы собираем всяческие метрики.
В результате мы к 300 потокам тестирования, которые нам давало облако, получили еще +200 потоков тестирования от машин разработчиков – это достаточно много.
Само собой, эти потоки тестирования мы получаем только ночью, когда машина разработчика или другого сотрудника простаивает. И еще в выходные.
Сейчас мы уже подключили все машины и начали присматриваться к сотовым телефонам. Шутка, конечно.
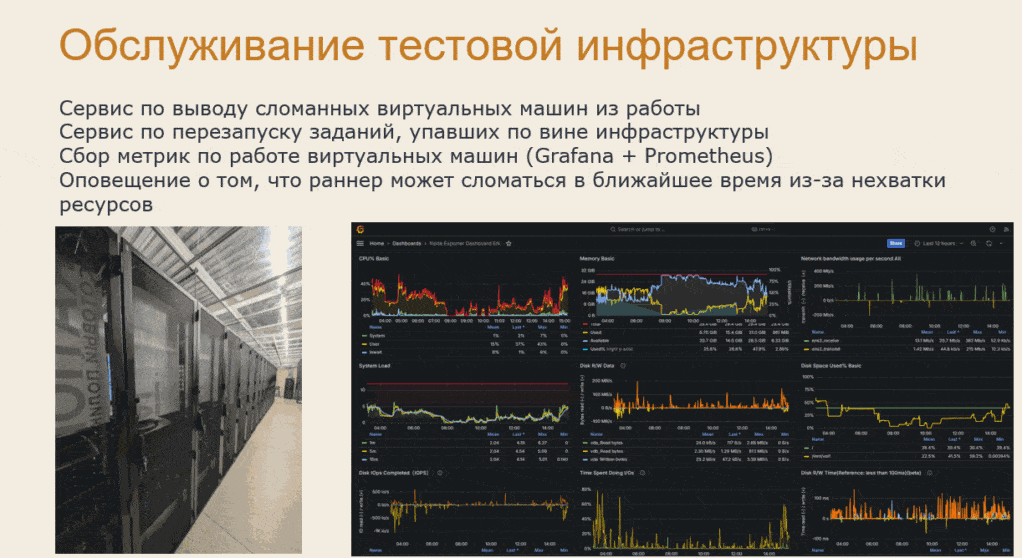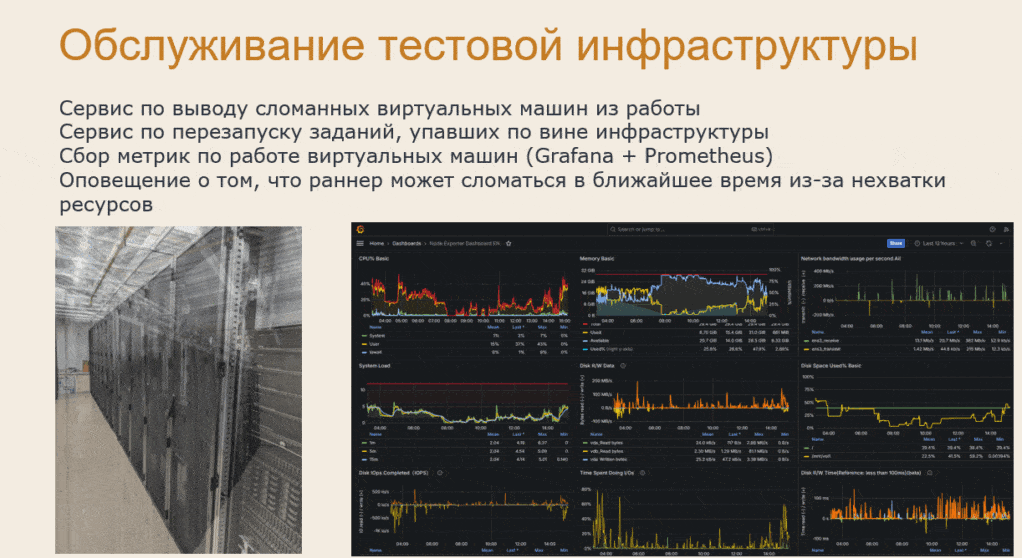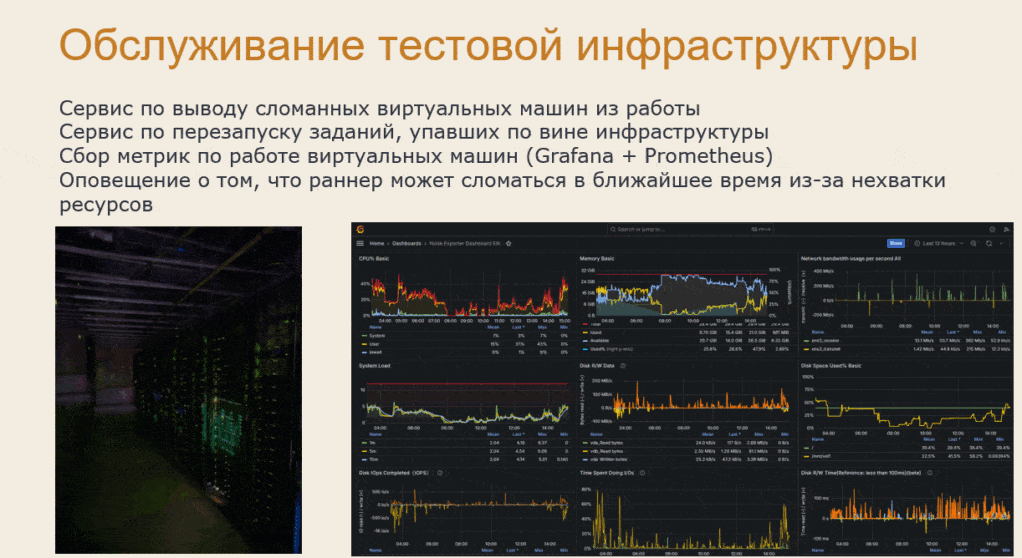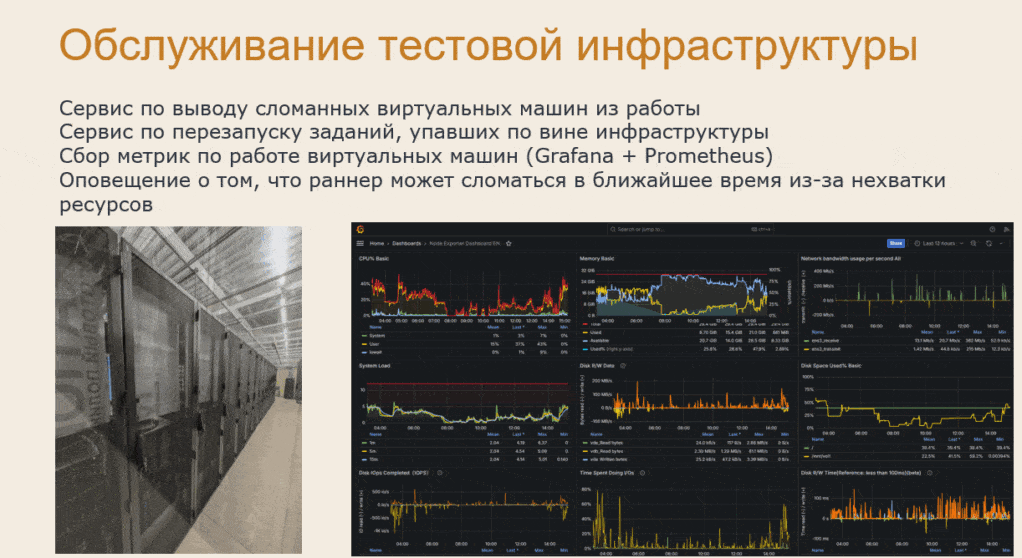
Леонид: Но совсем не шутка обслуживать такую тестовую инфраструктуру.
Обслуживание сотен виртуальных машин требует автоматизированных сервисов. Может случиться такое, что виртуальная машина вышла из строя, например, кончилось место на диске или произошел другой сбой. Такая машина очень быстро может «перемолоть», т.е. сделать красными много заданий, и кто-то должен среагировать и вывести её из пула.
Для этого у нас существует сервис, который находит такие машины и снимает с них теги, чтобы они перестали выполнять задания. А потом другие сервисы перезапускают задания, которые эта машина успела «сломать».
Кстати, на представленной анимации – реальные фотографии серверной нашего тестового облака.
Для расследования проблем мы используем классическую связку Grafana + Prometheus.
-
Grafana – это инструмент для визуализации, мониторинга, демонстрации и анализа данных.
-
Prometheus – это система, предназначенная для сбора и анализа данных о работоспособности IT-оборудования.
Также у нас работает система алертинга, которая присылает оповещение о том, что на машине скоро могут закончиться ресурсы (место на диске), и она выйдет из строя.
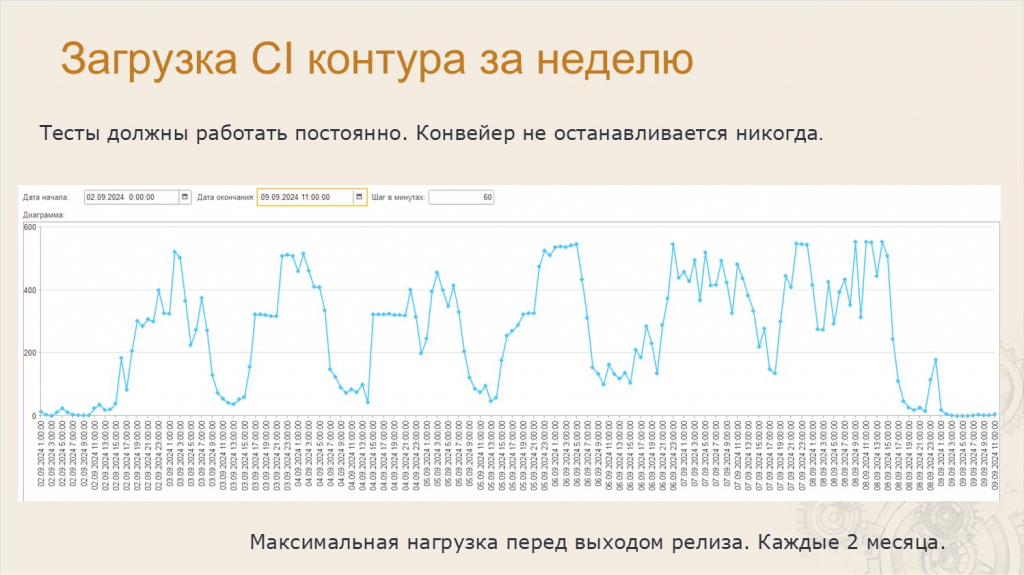
Анастасия: Помните, в самом начале Леонид обещал вам рассказать про 500 ванесс, которые поют хором?
CI у нас не останавливается никогда – он всегда работает, всегда загружен.
На слайде – график загрузки контура CI за неделю.
На графике хорошо видны всплески нагрузки – это загрузка контура CI ночью. Днем разработчики коммитят, пишут код, а в 20:00 запускаются их персональные компьютеры, и мы видим всплески – это работа ночью.
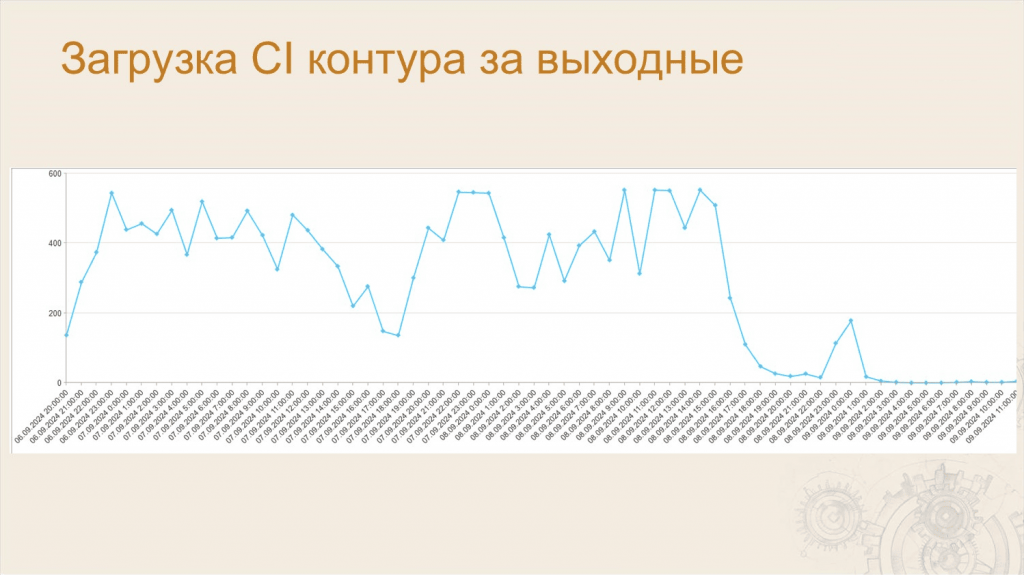
Анастасия: Так как за одну ночь мы не успеваем протестировать все ветки, часть веток тестируются в выходные. В это время нагрузка на CI максимально большая – тесты запускаются практически постоянно.
На слайде можно видеть, что максимальное значение параллельных потоков тестирования – где-то 550. Это те самые 550 ванесс, которые у нас поют хором.
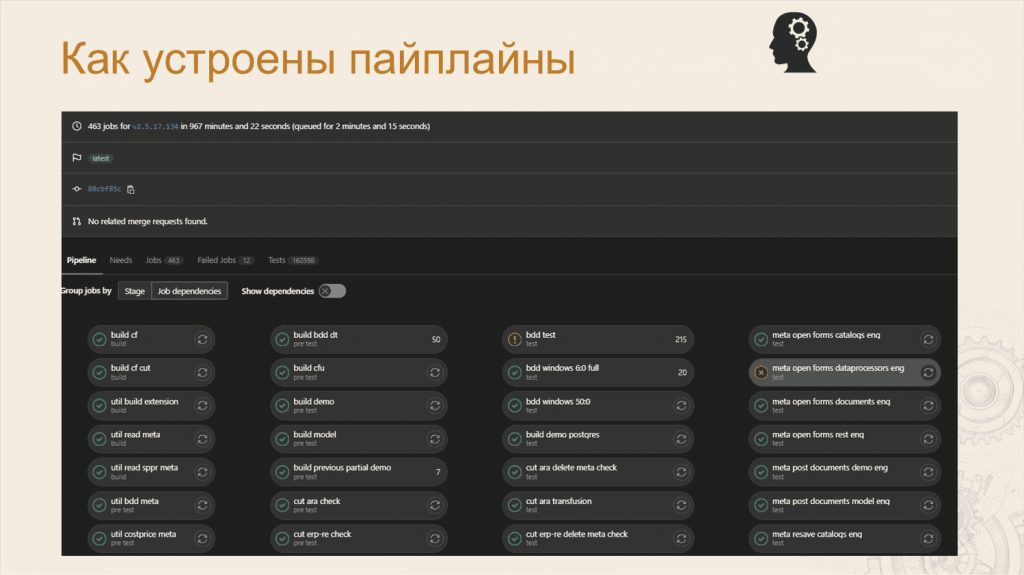
Леонид: Дальше я хочу показать, как у нас устроены пайплайны.
Если кто не знает, пайплайн – это конвейер или последовательность действий. Обычно пайплайн состоит из заданий, а задания часто делят на стадии.
На слайде – скриншот нашего реального пайплайна, который тестировал ветку 2.5.17 основного проекта ERP. В этом пайплайне 463 задания: каждый из овальчиков – это либо тест, либо группа тестов.
Но данный скриншот не дает полной картины для понимания состава пайплайна, поэтому мы сделали небольшую анимацию.
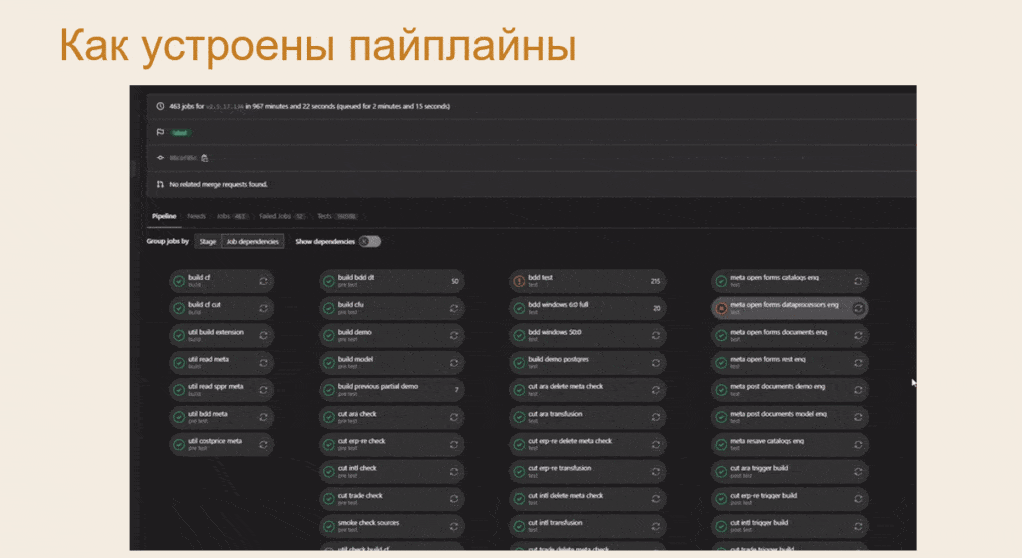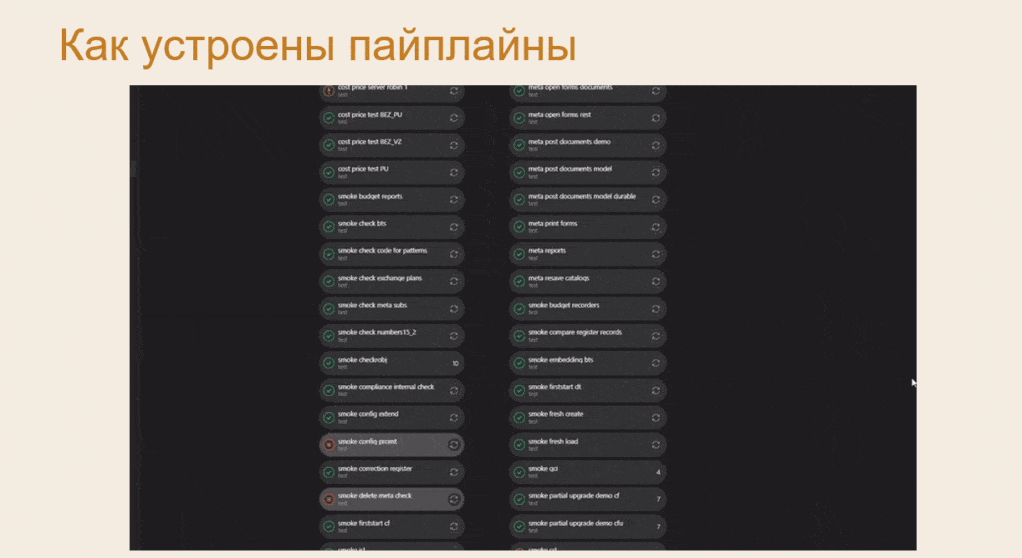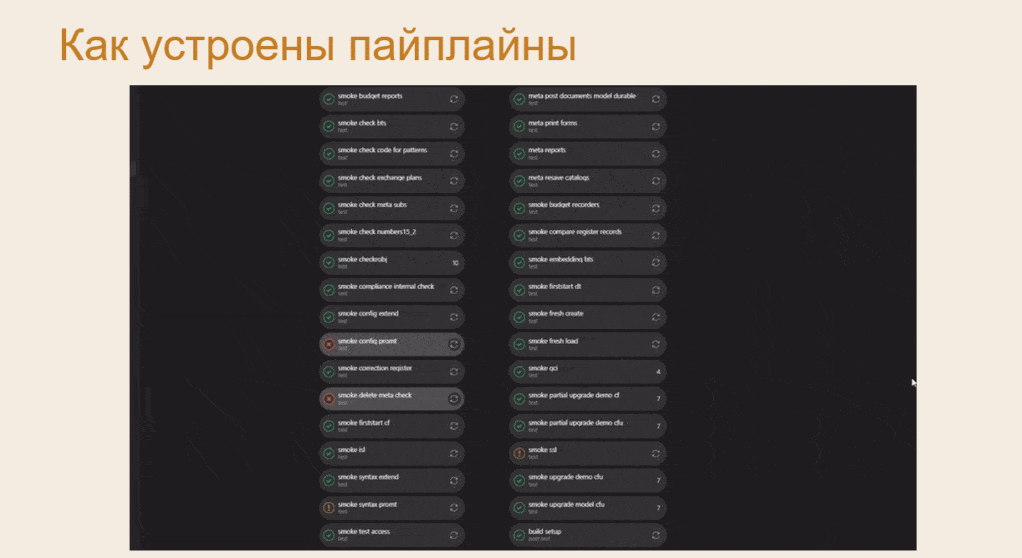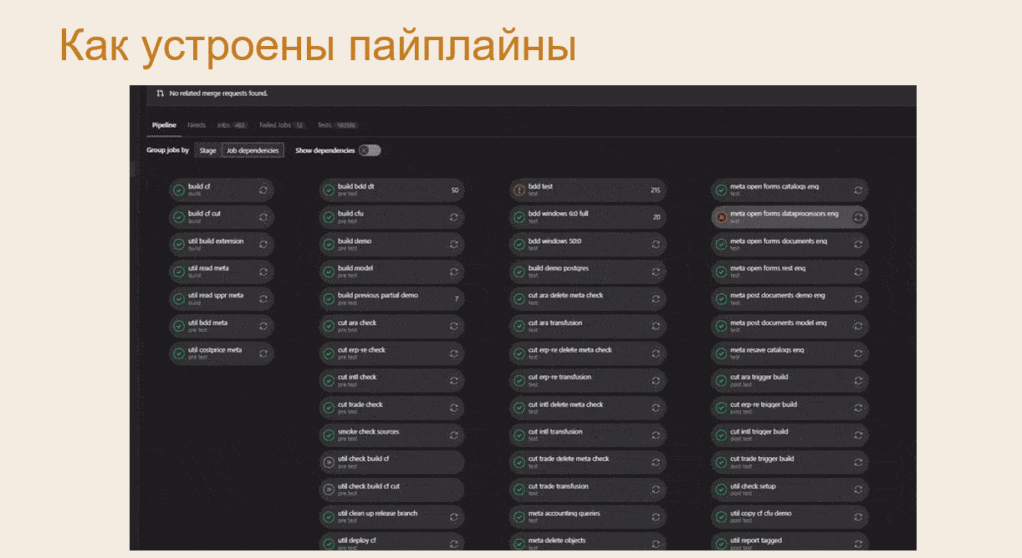
Леонид: Вот так в реальности выглядит пайплайн с полным набором тестов для одной ветки ERP.
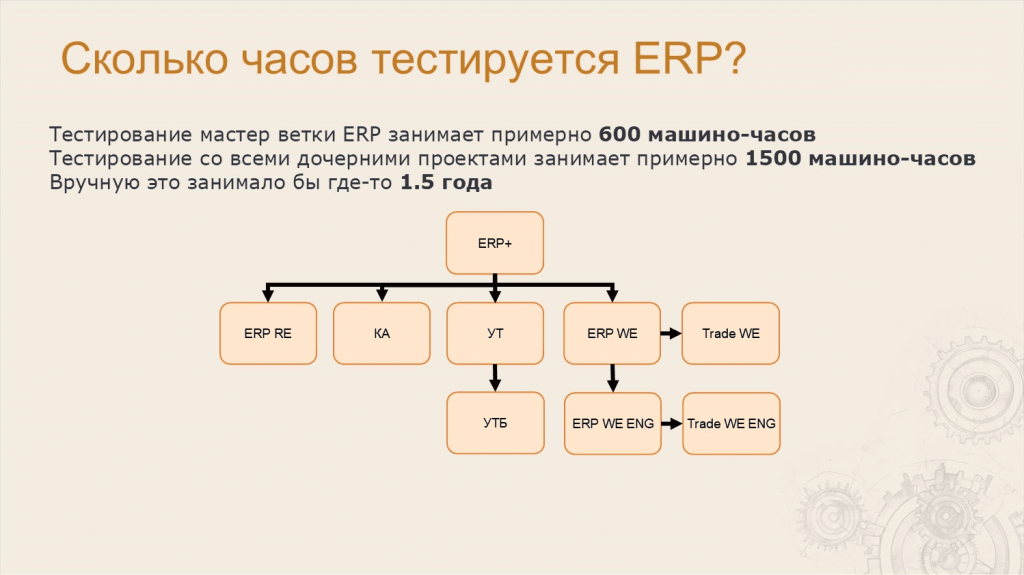
Леонид: А как вы думаете, сколько часов тестируется ERP?
Тестирование мастер-ветки занимает примерно 600 машино-часов. А тестирование со всеми дочерними проектами – я напомню, что проектов у нас 9 – примерно 1500 машино-часов.
Мы прикинули, что если бы это один человек тестировал вручную, это занимало бы где-то полтора человеко-года.

Леонид: За сутки при полной нагрузке тестовая инфраструктура у нас выполняет 12000 машино-часов. Обычно такое происходит в самый нагруженный день – это суббота.
А за неделю полная нагрузка на инфраструктуру – где-то 65000 машино-часов. Это очень много человеко-лет, мы даже не стали считать, сколько это.
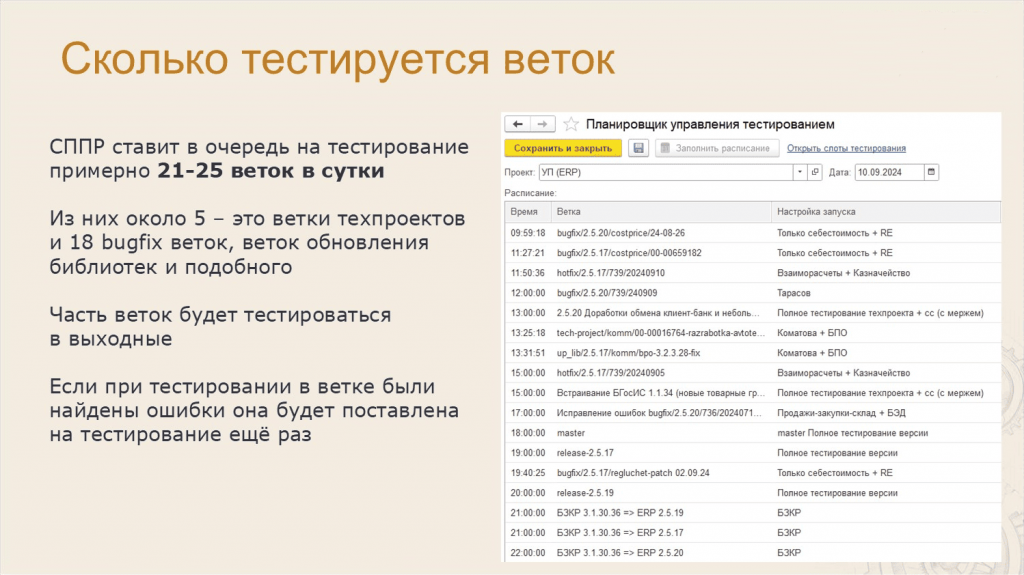
Анастасия: Зато мы можем посчитать количество веток, которые находятся у нас в тестировании.
У нас в работе ежедневно используется около 120 веток, но CI пропускает только 21-25 веток в сутки. Поэтому многие ветки становятся на тестирование в выходные.
Для управления всем этим потоком у нас в СППР есть планировщик управления тестированием.
У каждой ветки есть приоритет тестирования, настройки запуска, и на основе приоритета тестирования ветки попадают в расписание планировщика. Если какую-то ветку нужно продвинуть, релиз-менеджер ставит ее тестироваться вручную.
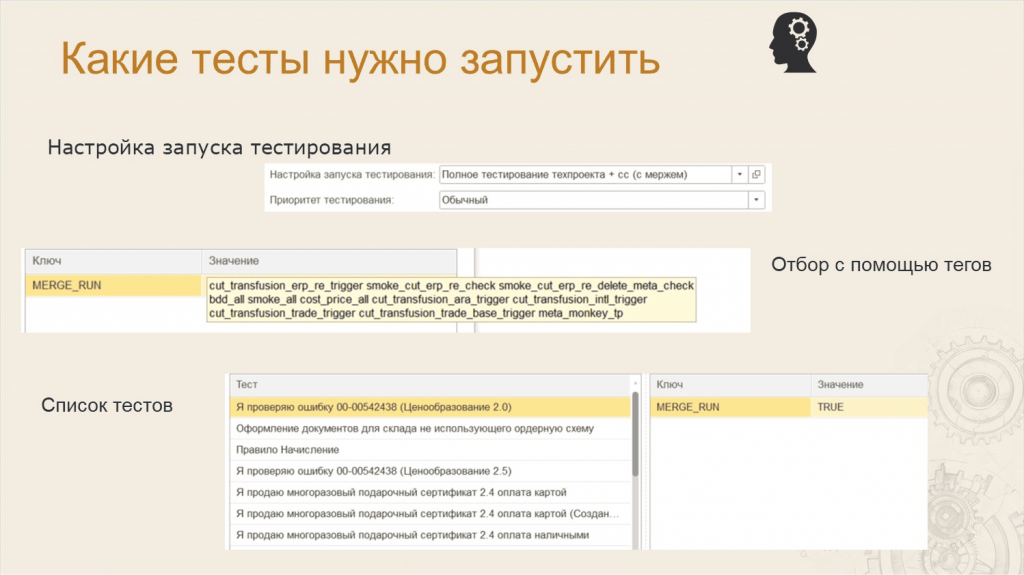
Анастасия: С помощью настройки запуска тестирования мы можем указать для конкретной ветки в СППР состав тестов, которые должны быть запущены:
-
На ветках техпроектов и релизов мы обязательно прогоняем полные тесты.
-
А на багфиксовых ветках нам полные тесты не нужны, поэтому мы можем управлять составом тестов:
-
либо с помощью тегов;
-
либо через список тестов;
-
либо комбинацией – список тестов и теги.
-
Внизу на слайде показан список тестов, установленный в настройках запуска тестирования для конкретной ветки.

Леонид: Мы используем разные типы тестов – классические дымовые тесты, сценарные тесты и тесты «цепочек» документов:
-
Дымовые тесты – это автоматические тесты на открытие всех форм, проведение/запись документов и так далее.
-
Сценарные тесты – это тесты эмулирующие действия пользователя.
-
Ну а тесты «цепочек» – это немного модернизированные сценарные тесты для проверки движений. О них я расскажу подробнее позже.

Леонид: В качестве дымовых тестов мы используем внешние обработки для автотестирования, которые перечислены на слайде.
Важно, что эти тесты доступны на сайте релизов 1С в разделе ERP – все, кто имеет доступ к релизам нашей конфигурации, могут их скачать.
Эти обработки включают как классические смоук-тесты – такие, как открытие форм, так и специфические – например, проверка закрытия месяца.
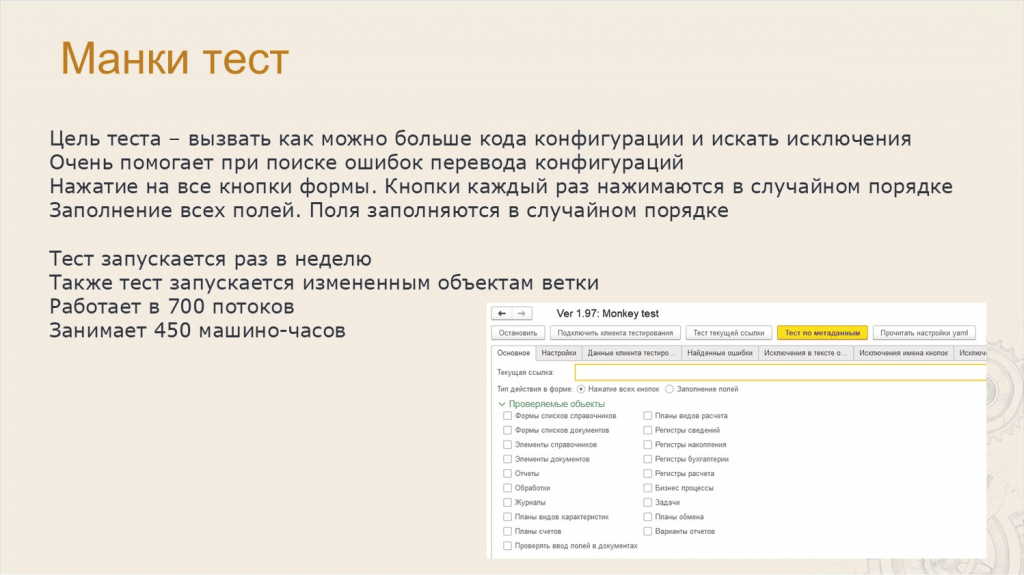
Леонид: Один из специфических тестов, которые мы используем – это манки тест (MonkeyTest.epf).
Когда мы реализовывали проект по переводу одной из конфигураций, мы столкнулись с тем, что ошибки перевода вызывают исключения в коде: «Поле объекта не обнаружено», «Ошибка при выполнении запроса» и так далее.
В результате мы решили сделать тест, который выполняет весь код ERP по максимуму – открывает все формы, нажимает все кнопки и заполняет все поля случайным образом.
Сказано – сделано! Сделали тест, и он стал находить нам эти ошибки.
А потом решили запускать этот тест и на всех остальных проектах, чтобы находить все возможные исключения.
Тест потребляет достаточно много ресурсов, и если его запустить на ERP, он отработает примерно за 450 машино-часов при выполнении в 700 потоков.
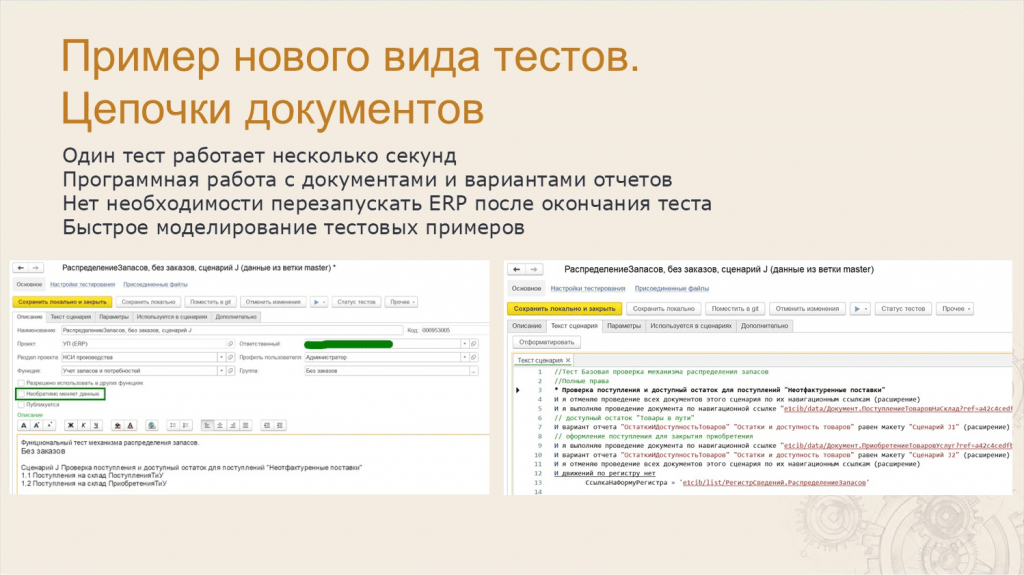
Леонид: Еще один вид тестов – тесты «цепочек» документов.
Мы столкнулись с проблемой, что сценарные тесты не очень подходят для моделирования движений, потому что там используется UI – форма должна открыться, прокешироваться, потом нужно дождаться, пока все закроется и так далее. А нам, чтобы проверять движения документов в сценарных тестах, нужно моделировать сотни примеров.
Но и в чисто программный API мы тоже уйти не можем, потому что некоторые действия – заполнение для документа каких-нибудь категорий – через внешний API недоступны. Это доступно только в интерфейсе.
Решили сделать гибридный вариант – специальные сценарные тесты для моделирования «цепочек» документов и проверки их движений.
Мы доработали СППР и добавили в карточку сценария флажок «Необратимо меняет данные» – его видно на левом скриншоте на слайде. Если этот флажок снять, обычный сценарий тестирования превращается в цепочку – такие сценарии выполняются подряд без перезапуска ERP.
Создали несколько специальных шагов, которые программно проводят и распроводят документы на стороне клиента тестирования с помощью расширения VAExtension и так же программно работают с отчетом.
Идея в том, что есть база, где куча заранее подготовленных распроведенных документов, тест быстро их проводит, проверяет отчеты и распроводит.
Эта цепочка отрабатывает за несколько секунд, не нужно перезапускать ERP – эти примеры реально можно моделировать сотнями, это все работает очень быстро.

Леонид: Отдельный мир – это мир 1С:Фреша.
Наверняка вы знаете, что ERP и «Комплексная автоматизация» доступны в режиме сервиса, развернутого по технологии 1C:Fresh – это классический SaaS (Software as a service), когда программа находится в облаке.
Для нас это отдельный мир, потому что там специфические требования – нам нужно проверять, что в ERP корректно создаются области, корректно проходит миграция из «коробки» во фреш и обратно и т.д.
Для работы в режиме 1С:Фреш мы написали специальный сценарный тест, который в реальном менеджере сервиса, в компоненте облака, нажимает на кнопки, создает конфигурацию, обновляет ее, делает все эти миграции. Для нас это обычный сценарный тест, но для этого пришлось поднимать специальный заранее настроенный стенд.

Леонид: Тест закрытия месяца (CheckMonthClose.epf) – это тоже отдельный мир, его тоже нельзя реализовать на обычных сценарных тестах.
-
У нас есть специальные эталонные базы, в которых наколочено много разных правильных эталонных примеров.
-
Тест перерасчитывает движения документов по финансовым регистрам.
-
Проверяет расчет себестоимости, проводки, НДС, взаиморасчеты и так далее.
-
Выполняет закрытие месяца – перезакрывает сразу много месяцев.
-
Потом он сравнивает текущие движения по регистрам с эталонными движениями и регистрирует расхождения в СППР.
-
А дальше ответственный за этим смотрит и решает, что с этим делать – это ошибка или плановое поведение.
Причем сам код теста встроен в ERP, и его может использовать любой желающий – внешняя обработка тестирования просто вызывает его методы.
На слайде – пример расхождений, которые регистрируются по итогам выполнения этого теста в СППР.
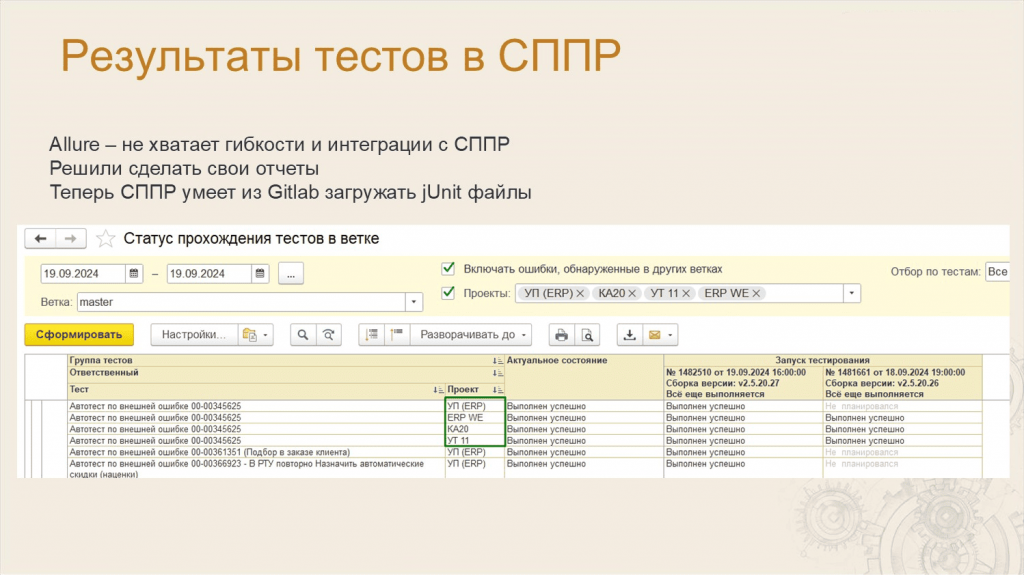
Леонид: Когда все сессии тестирования выполнились, нам нужно где-то посмотреть результат отчетов.
На раннем этапе, когда мы развивали нашу систему, мы, как и многие, использовали Allure – прямо на GitLab через GitHub Pages прикладывали ссылки на Allure-отчеты.
Потом мы поняли, что в Allure очень не хватает гибкости – нам нужны хитрые отборы и группировки, такие как в системе компоновки данных.
Поэтому решили пойти другим путем – мы научили СППР загружать данные напрямую с GitLab CI, прямо из артефактов считывать данные JUnit-файла. И все – результаты складываются в специальный регистр сведений, из которого можно строить отчеты.
Такая реализация очень важна, потому что у нас тестируется одновременно 9 проектов, а тест при этом работает один и тот же – он может в ERP пройти, а в «Комплексной автоматизации» упасть. И нам это нужно видеть – при том, что фактически это одна сборка, где собираются сразу 9 проектов.
На слайде как раз видно, как один тест отработал в разных конфигурациях.

Леонид: Нас иногда спрашивают – сколько у нашей команды всего сценарных тестов. Настя, напомни?
Анастасия: Наверное, вопрос не очень корректный, потому что тесты бывают и большие, и маленькие, состоящие из одного шага или как цепочки документов.
Высокоуровневых сценариев у нас примерно 2200, с подсценариями – 6300.
Но мне кажется, что важнее количество шагов – элементарных действий, которые делают наши тесты. Например, ввести в поле какой-то текст, нажать на кнопку, перейти. И тут, внимание, количество элементарных действий пользователя, которые делают наши тесты при тестировании одной ветки – 2 миллиона.

Анастасия: А еще часто задают вопрос – как правильно организовать хранение тестов и кода конфигурации? Где хранить исходный код конфигурации, а где – тесты?
Вначале мы пробовали работать в режиме, когда код и тесты лежат отдельно, потому что репозиторий ERP и сам по себе очень большой. Но это приводило к ошибкам и ложным срабатываниям тестов.
Поэтому сейчас мы все храним в одном репозитории – у нас там находятся и тесты, и настройки, и исходный код конфигурации.
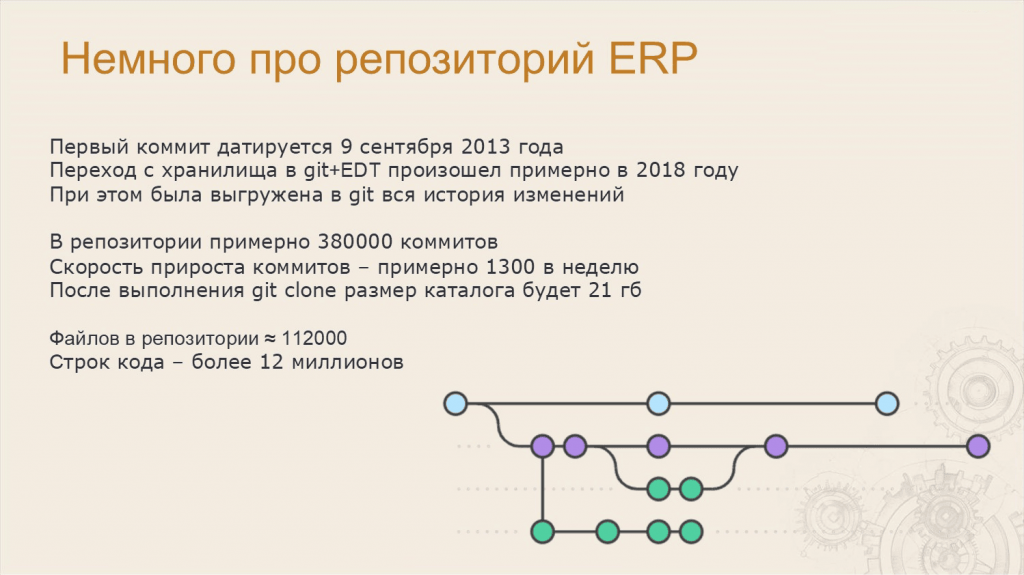
Леонид: Первый коммит в проект 1С:ERP датируется 9 сентября 2013 года.
Переход от хранилища к работе в формате Git+EDT мы сделали в 2018 году. При этом вся история была сконвертирована, и в Git-репозитории все коммиты из хранилища есть.
Сейчас в репозитории примерно 380 тысяч коммитов, а скорость прироста – где-то 1300 коммитов в неделю.
Если попытаться клонировать этот репозиторий к себе, получится каталог размером в 21 гигабайт – таков наш репозиторий, таковы наши реалии. Там где-то 112 тысяч файлов и примерно 12 миллионов строк кода.
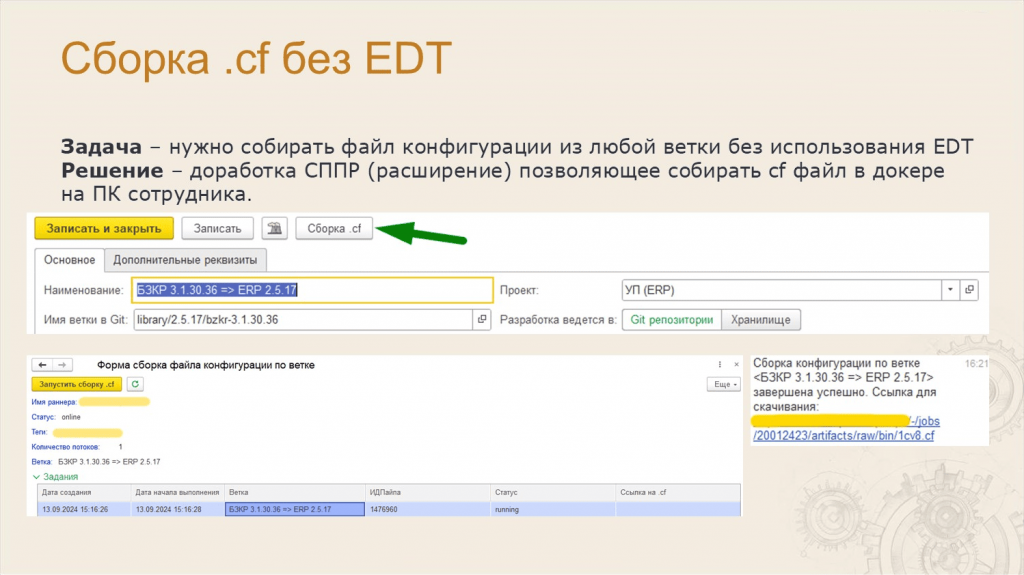
Леонид: Мы периодически сталкиваемся с задачами, которые находятся на стыке разработки и тестирования.
Мы при разработке используем EDT, но не у всех сотрудников он установлен – например, аналитикам и тестировщикам EDT может быть не нужен. Но у всех постоянно возникает необходимость собрать cf-файл из ветки определенного техпроекта, а таких веток у нас много.
Мы решили сделать быстрый механизм сборки – сделали расширение в СППР, чтобы можно было собирать cf-файл из любой ветки без использования EDT.
Но если у нас 100 сотрудников одновременно нажмет на кнопку «Сборка .cf», тестовая инфраструктура сформирует большую очередь, и конфигурация будет собираться довольно долго.
Поэтому файл конфигурации собирается у сотрудника на компьютере, при этом сама сборка происходит в докере с установленным EDT, но сам EDT на ПК действительно ставить не нужно.
Помните, я говорил о том, что мы используем компьютеры сотрудников, чтобы на них запускать тесты? Тут мы переиспользуем эту технологию, так как докер уже установлен на компьютер сотрудника, и он может принимать джобы.
Сотрудник нажимает кнопку «Сборка .cf», и где-то через час ему приходит оповещение в Системе взаимодействия – вот ваша ссылочка, скачайте, пожалуйста, собранный файл конфигурации.
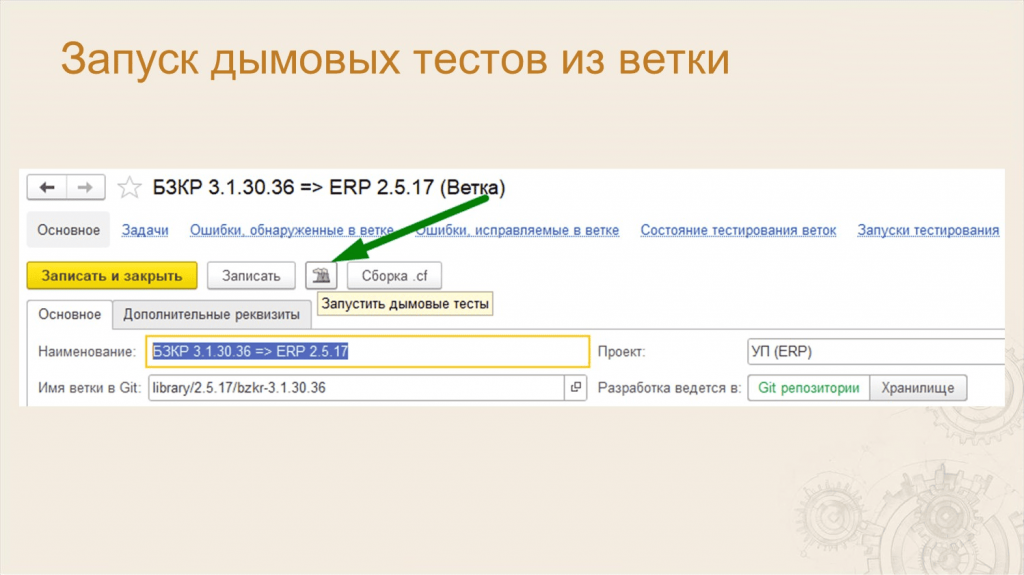
Леонид: Также мы столкнулись с тем, что разработчики хотят запускать тестирование предварительно, пока ветка ещё находится в стадии разработки. Тем более, что некоторые ветки могут содержать очень серьезные доработки, которые разрабатываются несколько месяцев.
Я предложил им использовать интерфейс GitLab CI, который позволяет запускать произвольные наборы тестов на любых ветках, но сотрудники попросили упростить задачу до одной кнопки.
Мы сделали кнопку в СППР, и теперь кто угодно может запустить дымовые тесты в любой момент времени.
Фактически там просто через стандартный API запускается пайплайн, куда передаются ключи для отбора по дымовым тестам.

Леонид: Отдельная грань качества – это то, как команды умеют согласовывать между собой изменения.
У нас проект большой, команд много. Есть вертикальные подсистемы – это когда за подсистему отвечает одна команда. И есть горизонтальные подсистемы, которые проходят через всю ERP.
С изменениями в горизонтальных подсистемах постоянно возникали проблемы. Потому что вы можете поправить любой файл – залезть в любое метаданное, и коллега без Git этого не увидит.
Нужен был механизм для согласования изменений объектов метаданных.
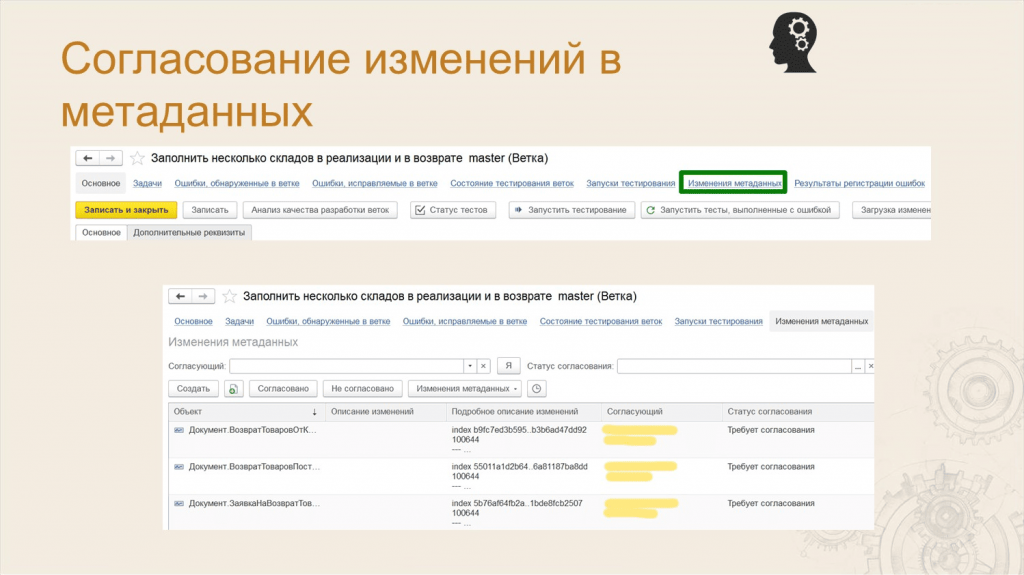
Леонид: Мы реализовали такой механизм – в справочнике «Ветки» есть гиперссылка «Изменения метаданных», по которой открывается список изменений.
СППР по регламентному заданию обращается в CI-сервер и подтягивает все изменения по ветке.
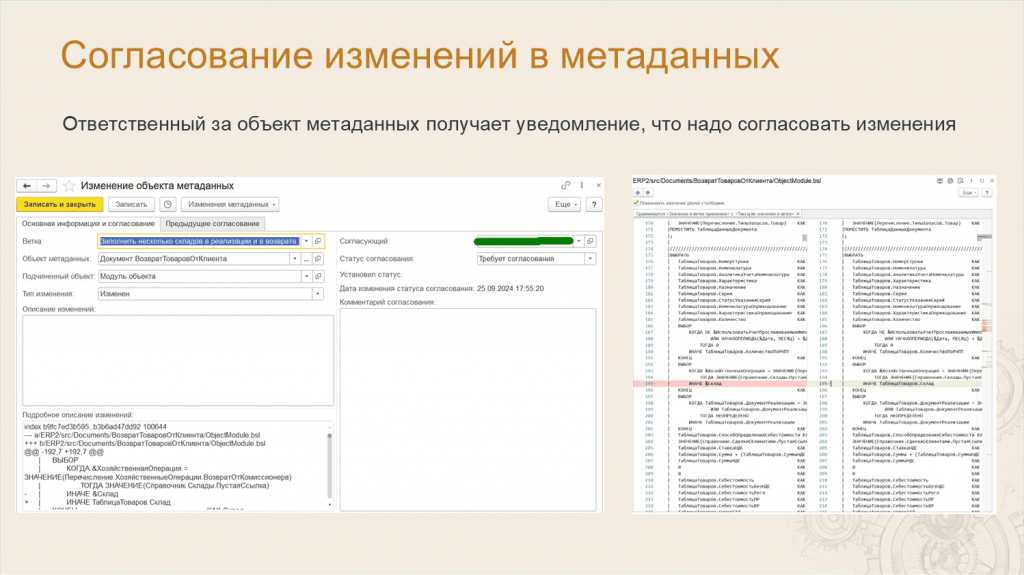
Леонид: Ответственный за объект метаданных получает в Системе взаимодействия оповещение, что в его объект пытаются внести изменения. И дальше можно либо согласовать эти изменения, либо откатить их, начать какое-то обсуждение.
Таким образом решается проблема, что одна команда разработки может изменить объекты другой команды без согласования с ними.
Это тоже важный параметр качества разработки, т.к. если этого не делать, будут накапливаться проблемы несогласованных изменений.
Также СППР научился показывать двустороннее сравнение – можно прямо в СППР посмотреть, что именно изменили.
Леонид: Запуск тестов на дочерних проектах – это отдельный мир.
У нас 9 проектов и, например, «Заказ покупателя» есть и в ERP, и в «Комплексной автоматизации», и в «Управлении торговлей». Было бы странно написать тест для ERP, а потом еще раз дублировать его для всех дочерних конфигураций проекта.
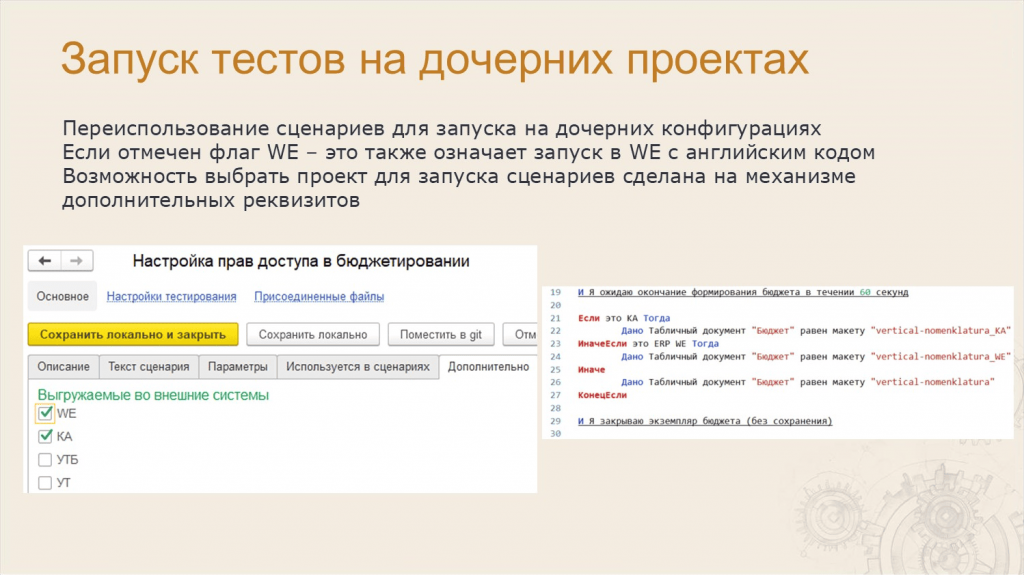
Поэтому мы сделали в СППР доработку – в карточке сценария можно расставить галочки, для каких еще конфигураций должен запускаться этот тест.
Но один и тот же объект может вести себя в конфигурациях немного по-разному – например, он в ERP такой же, как и в «Комплексной», но чуть-чуть отличается. Не будем же мы писать на это два сценария.
Мы добавили несколько специальных шагов, которые позволяют проверить контекст запуска теста: если мы находимся в «Комплексной», делай так, если в ERP WE – так, а в остальных случаях – так.
Такие шаги показаны на правом скриншоте. С их помощью один сценарий может запускаться на всех дочерних конфигурациях проекта.
Леонид: Немного про перевод. Я уже говорил, что у нас есть конфигурации, которые переводятся на английский язык – переводится код, метаданные и интерфейсы.
Причем перевод кода для программного продукта – это вообще довольно редкая ситуация в мировой практике, поэтому мы сейчас поговорим именно про конфигурации ERP WE ENG и Trade WE ENG, которые выделены на слайде зеленым.
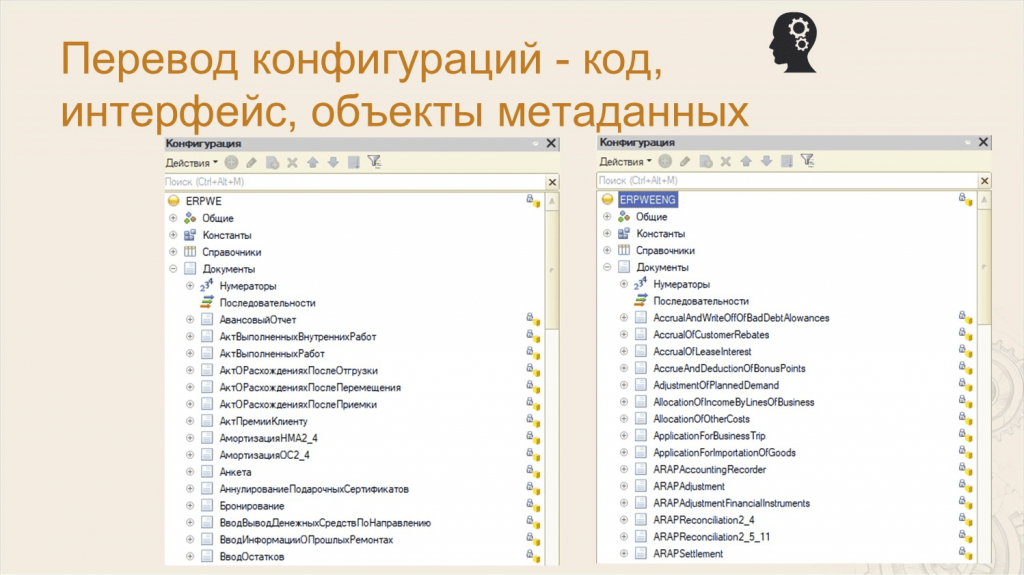
Леонид: На слайде пример того, как переводятся метаданные для ERP WE: слева список метаданных на русском, а справа – переведенный вариант. Переводится код, имена объектов метаданных и интерфейс.

Леонид: Для перевода мы используем 1С:Language Tool, который встраивается в EDT. Про это есть отдельные доклады, я не буду про это подробно рассказывать.
Но у нас возникла задача адаптации существующих тестов под английские имена метаданных.
Например, есть тесты, которые работают в ERP WE на русском, и их нужно запустить в ERP WE на английском, и никто не будет писать их с нуля два раза. Но там же метаданные переведены, и тест будет падать. Поэтому надо переводить тесты.
Написали инструмент для автоматического перевода, но чтобы в сценарии было как можно меньше изменений, сделали такой ход: конфигурация переведена на английский, но мы запускаем ее в русском интерфейсе. В этом случае нам достаточно перевести только параметры шагов, которые обращаются к имени объекта метаданных. Это видно в анимации на слайде.
Получилось, что перевод для сценария нужен, но точечный. И в результате сценарии остались похожими – практически один и тот же тест работает и на ERP в русском коде, и в ERP в английском коде.
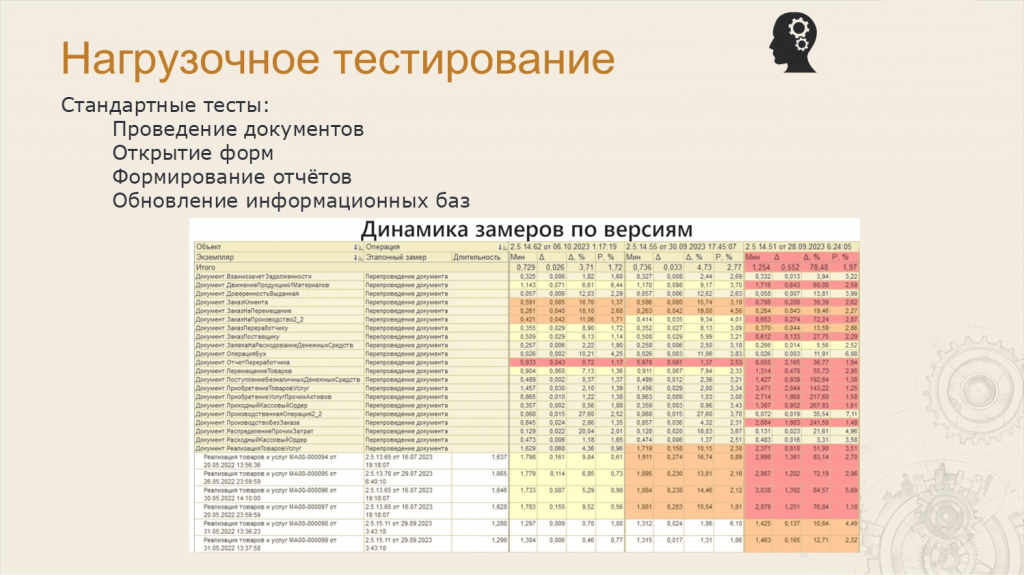
Леонид: Нагрузочное тестирование – это вообще отдельный мир. Про это можно делать прям большие доклады. Я вкратце расскажу, как это у нас работает.
Есть отдельный железный стенд, который не использует виртуализацию – специально для того, чтобы делать чистые замеры. На этом стенде раз в неделю замеряется работа ключевых операций, таких как:
-
проведение документов;
-
открытие форм;
-
формирование отчетов;
-
обработчики обновления информационных баз.
Нам важно понять, привели ли последние доработки к деградации скорости работы конфигурации.
После снятия замеров по каждой версии продукта мы сравниваем их в отчете, который показан на слайде – по цвету видно, где большие расхождения, где маленькие. И дальше уже принимается решение, что с этим делать.
Вообще по нагрузочному тестированию у нас целая система отчетности, я здесь показываю только маленький кусочек.
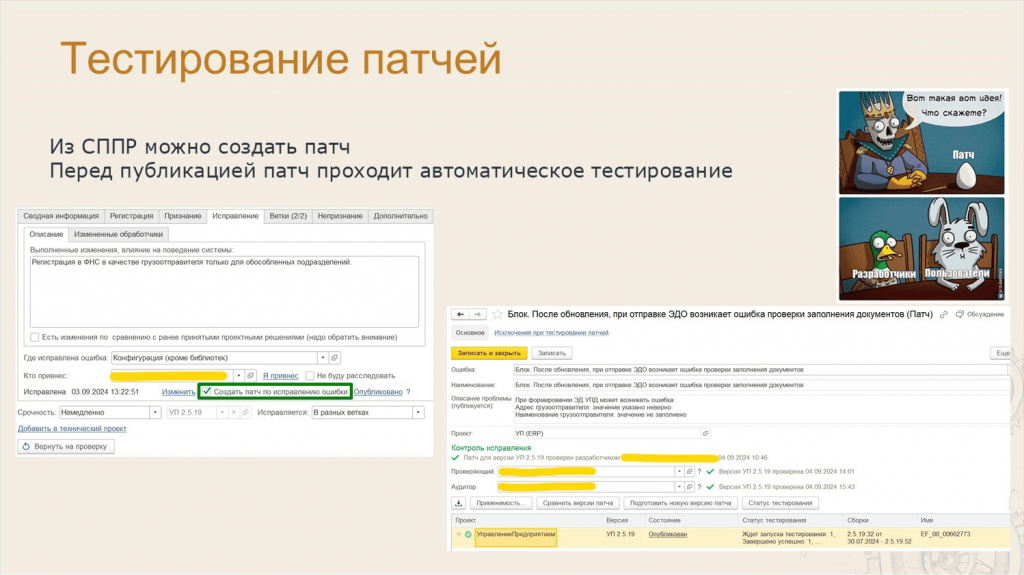
Леонид: Тестирование патчей. Думаю, все знают, что если в конфигурации нашли ошибку, надо либо ждать обновления на следующую версию релиза, либо ставить себе патч.
Патч – это, по сути, расширение. Само собой, нам нужно проверять, как это расширение сформировалось, и как оно работает.
В СППР прямо в форме ошибки есть флаг «Сформировать патч по исправлению ошибки» – при установке этого флага СППР лезет в Git, находит коммит исправления и автоматически формирует патч через механизм БСП.
Но дальше же патч надо проверить – точно ли он все исправляет, а не ломает? Для этого тоже запускается сессия тестирования уже с накаткой этого патча. Таким образом мы проверяем, что патч реально работает.

Леонид: Мы периодически слышим от партнеров и разработчиков вопрос: «Вы хорошо рассказываете, а можете поделиться вашими технологиями?».
Давайте напомню, как мы делимся технологиями с партнерами и разработчиками:
-
СППР. Конфигурацию СППР разрабатывает наша группа, в том числе, я. Мы сами им пользуемся и поставляем его наружу. Несколько слайдов назад я вам показывал механизм для согласования изменений в объектах метаданных. Мы сделали его для себя, но это абсолютно типовая функциональность, которую могут использовать все, кто имеет доступ к скачиванию последних релизов СППР.
-
Дымовые тесты. Мы их тоже выкладываем наружу – вы можете скачать наши тесты на сайте релизов в разделе ERP.
-
Фреймворк тестирования. Мы используем абсолютно типовой фреймворк тестирования Vanessa Automation. Там нет никаких кастомизаций, специальных сборок – все как есть. Тоже можно скачать с GitHub.
-
А тесты? Периодически нас просят: «Дайте ваши тесты!» И тут интересная ситуация. Мы вообще «за» и хотели бы ими делиться. Несколько раз проводили эксперименты – передавали партнерам тесты. Причем передавали не сразу все 2000 сценариев, а штук 200 для начала. И каждый раз это заканчивалось неудачно. По опыту эксплуатации мы поняли, что нам нужно не только тесты передать, но и всю обвязку, чтобы эти тесты могли запуститься: скрипты, инфраструктуру и специалистов, которые умеют этим пользоваться. И тут возникают основные проблемы. Надеюсь, мы их когда-нибудь решим, но пока ситуация такая.

Леонид: Причем у нас есть не только автотесты, еще и ручное тестирование осталось.
Анастасия: Да, мы не все доверяем роботам – что-то тестируем вручную. Прежде всего мы тестируем вручную наши техпроекты – большие фиче-бранчи.
На этапе проектирования техпроекта мы создаем план тестирования, используя шаблон, который показан на слайде.
Шаблон содержит подсказки, на что обратить внимание при тестировании, и через плюсики подсказки можно развернуть до конкретных инструкций. Он позволяет нам не забыть проверить фичу под разными функциональными опциями, их комбинациями, группами доступа и так далее.
Самое важное, что нужно сделать – это описать план сценария: что нужно создать, что проверить и т.д. Итоговый план сценария в будущем можно использовать как план автотеста.

Анастасия: Регрессионное тестирование также требует проверки вручную. На это мы выделяем 5 дней – чтобы проверить стыки и точно выпустить качественную конфигурацию.
Для регрессионного тестирования мы тоже используем шаблон с разделами, о которых нужно не забыть.

Анастасия: И помимо автотестирования и ручного тестирования мы еще предпринимаем организационные меры, чтобы наше качество улучшилось.
Например, мы для каждого техпроекта стали добавлять задачу «Подтвердить качество реализации проекта у разработчиков и тестировщиков».
Все разработчики и тестировщики, которые участвуют в проекте, просто пофамильно отмечают: «Подтверждаю».
Казалось бы, пустячок, но люди не ставят эту пометку бездумно – прежде чем поставить, они могут еще раз залезть и проверить, все ли там правильно работает.

Анастасия: ERP и КА у нас могут использоваться в сервисе 1С:Фреш.
Когда релиз уже готов, все наши внутренние проверки сделаны, мы заливаем новый релиз на 30% областей 1С:Фреш и мониторим обращения от пользователей об ошибках.
Если в течение суток сообщений об ошибках нет, на следующую ночь мы заливаем обновление на оставшиеся 70% областей 1С:Фреш. И если за следующие сутки сообщений об ошибках не будет, мы выкладываем новую версию на сайт релизов.
Но если приходит ошибка, самые опытные сотрудники, включая руководителей разработки, собираются, обсуждают, в чем может быть проблема, как пропустили, и быстро-быстро делают патч. У нас рекорд исправления ошибки в 1С:Фреш – 2-3 часа.

Анастасия: Мы делаем тестирование нашего продукта не ради крутости или технологий – мы это делаем, прежде всего, для качества ERP.
-
Главный показатель качества для нас – это минимизация внешних ошибок. Потому что внешние ошибки – это первое, с чем сталкивается пользователь.
-
Дальше – массовость обращений на линию консультаций. Если по одной ошибке нам прислали обращение несколько пользователей, значит, это плохая ошибка.
-
Мы пробовали еще и другие методы оценки нашей конфигурации, но поняли, что самый подходящий показатель – это оценка, которую нам ставят партнеры на семинарах в «Космосе» весной и осенью. В 2024 году нам поставили оценку 4,5.
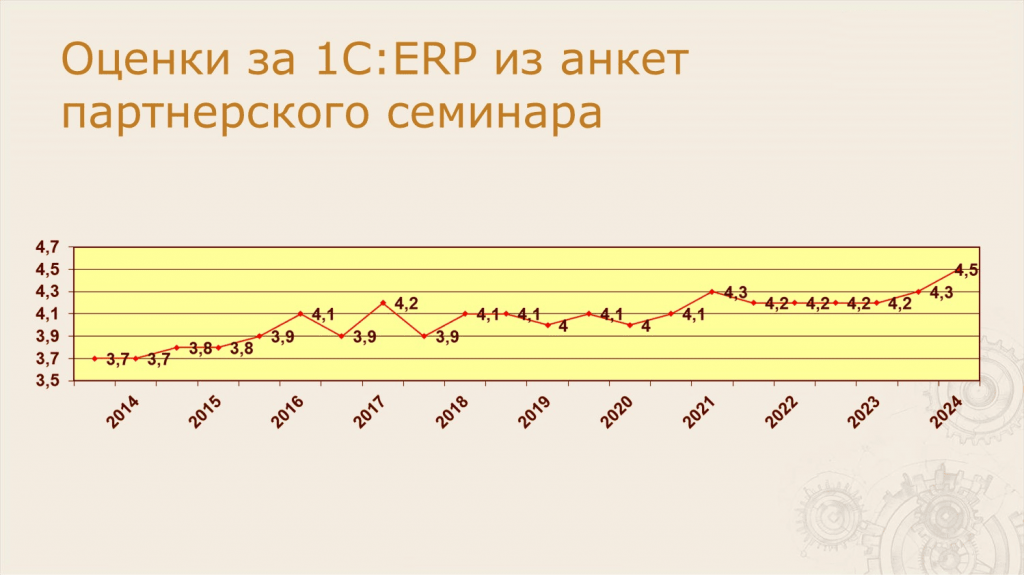
Анастасия: Я специально выписала все оценки, чтобы вы посмотрели наш рост:
-
Первые пять лет нам не удавалось получить даже 4 – это был период, когда мы все тестировали вручную. Хорошо, что хоть 3,7 получали.
-
Когда у нас стало развиваться автотестирование, мы получили четверку.
-
И теперь оценка конфигурации от партнеров выросла до 4.5.
Спасибо большое всем, кто видит наши старания и понимает, что качество действительно растет.
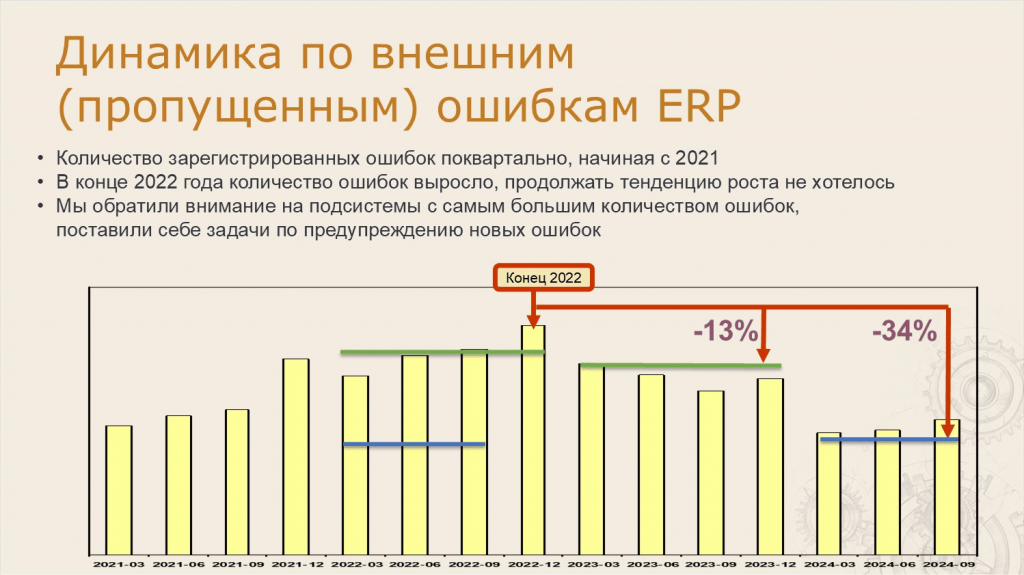
Анастасия: Это же и подтверждают и наши внутренние данные.
На слайде – динамика по внешним (пропущенным) ошибкам поквартально с 2021 года.
Вы видите, что сначала количество ошибок росло. Но в конце 2022 года мы достигли пика, поняли, что больше не хотим продолжать тенденцию роста, и предприняли ряд мер, чтобы улучшить качество ERP.
В 2023 году к нам пришло ошибок на 13% меньше по сравнению с 2022 годом. А если смотреть данные по 3 квартал 2024 года, то улучшение уже на 34%.

10 лет назад нам казалось нереальным иметь автоматические сборки и автотестирование.
Как вы думаете, что будет через 10 лет? Наверное, искусственный интеллект будет сам писать код и тестировать, а пользователю достаточно будет только подумать о декларации, чтобы она по воздуху прилетела в налоговую?
Поживем – увидим.
Вопросы и ответы
Можете ли вы поделиться ли Ansible-скриптами, которые разворачивают инфраструктуру?
Пока нет. На данный момент это наши внутренние репозитории.
Почему у вас докер EDT – отдельный?
Это вопрос инфраструктуры и эффективного использования ресурсов.
Если смотреть по машино-часам, которые уходят на подготовительную стадию и на тестирование, там соотношение: 1/6 – на подготовку и 5/6 – на само тестирование. И если все ноды делать одинаковыми, чтобы они работали и с EDT, и с тестами, получается неэффективно, потому что сборка cf на EDT требует больше оперативной памяти, чем один поток обычного тестирования ERP.
А второй момент – для EDT нужен репозиторий, те самые 20 гигабайт. Он их клонирует примерно час. И вы сразу получаете расход по диску 20 гигабайт. Плюс еще тестовая база ERP весит где-то пару гигабайт.
Соответственно, чтобы научить каждую машину работать с любым заданием, нужно очень много ресурсов. Поэтому эффективнее их делить – небольшую часть мы выделяем на подготовительную стадию, а остальное – на тестирование.
Вы говорите, что для тестирования используются компьютеры разработчиков. А как определить, что машина вообще находится в сети и на ней можно тестировать? Какой-то общекоммунальный Prometheus стучится в локальные машины разработчиков?
На каждый компьютер ставится служба Node Exporter – с ее помощью мы понимаем, что происходит с этой машиной, что у нее с ресурсами. Если машина почему-то сломалась, мы должны ее вывести из пула.
А кто в 1С пишет тесты?
Каждая команда решает сама. У нас есть команды разных размеров – и маленькие, и большие.
В некоторых командах есть выделенные тестировщики, и они однозначно пишут тесты. А дальше команда сама решает – подключать разработчиков или нет.
А есть команды, где нет тестировщиков. Например, в БСП вообще все тесты пишут.
Вы приводили пример, что что-то тестируете вручную, а что-то – автоматически. До какого процента покрытия вы дошли сейчас – сколько процентов бизнес-процессов тестируется автоматом, сколько вручную?
Общий подход – все критичное покрываем автотестами. Плюс все ошибки покрываем автотестами.
А процент покрытия именно по бизнес-процессам определить сложно. Предложите методику, мы посчитаем.
Мы думали, как это оценивать – команды рисовали модель в эксельке с функциями, она получилась огромная. ERP же огромная. Там если какая-нибудь функциональная опция переключается, то все по-другому работает.
Там реально много функций. Мы даже для небольшого блока расписывали – огромная экселька получилась. А потом ее нужно еще и актуализировать, ERP же меняется постоянно. И здесь возникает проблема – у этой истории очень большая стоимость поддержки. Мы не придумали, как это быстро делать.
А чтобы посчитать то, что вы хотите, сначала нужно получить такую модель.
Тестируете ли вы интеграции?
Если вы про универсальные обмены через EnterpriseData – да, конечно.
Сколько человек участвует в создании теста? Задействуете ли вы по бизнес-процессу аналитика или консультанта, чтобы он накидал какой-то тест-лист, передал его тестировщику, а он по нему уже фичу написал?
Когда мы тестируем техпроекты, у нас остается база и план сценария для ручного тестирования. И потом либо этот же тестировщик сам пишет тесты, либо он передает автотестировщику, который просто накидывает эти шаги.
Насколько я знаю, в Vanessa Automation для дымового теста нужно каждый раз формировать тест по новым метаданным. А у вас при добавлении нового объекта, нужно ли перегенерировать дымовой тест? Или он на лету подхватит новый объект?
Тесты, которые мы используем для ERP, автоматически подхватят все новые изменения.
Вы можете настроить исключения для объекта, если хотите. Но если вы его не исключите, то и манки тест будет в нем все кнопки нажимать, и дымовые тесты будут пытаться в нем печатные формы печатать, и так далее.
На сколько пользователей запускается нагрузочный тест, который вы показывали?
Там эмулируется много пользователей, несколько тысяч.
А как вы запускаете несколько тысяч пользователей в Ванессе?
Стенд нагрузочного тестирования у нас не на Ванессе, он ближе к Тест-центру, там Ванесса вообще не используется.
Как обстоят дела с модульными тестами для ERP? В докладе ничего при юнит-тесты не было.
Мы считаем, что это правильное направление, туда надо развиваться, но у нас этот процесс пока не поехал. Мы частично компенсируем это специфическими тестами, которые просто кодом что-то вызывают.
То есть сами тесты кодом у нас есть, но в чистом виде юнитов сейчас нет. А тема правильная. Приветствуем.
Я так понял, что изначально разработка ERP ведется на русском языке, а потом с помощью определенных инструментов вы переводите код и метаданные для редакции World Edition. Тестируете ли вы результат перевода?
ERP World Edition вырезается из ERP+, а она тестируется тестами в полном объеме. Потом она переводится, и тот же набор тестов запускается еще и на переведенной версии.
Вопрос именно о результате перевода. Дело в том, что мы сталкиваемся с ситуацией, что не всегда все термины переведены корректно.
Мы переводим не сами – высылаем словарь для перевода в специальный отдел, который этим занимается, а нам обратно приходит переведенный словарь.
Я не знаю, кто конкретно там переводит – может быть, и искусственный интеллект. Но в отделе работают люди – они эксперты, им виднее, как правильно переводить.
Были ли планы отказаться от этой схемы и сразу начать разработку на английском языке?
Пока таких планов нет.
У меня вопрос по системе вырезки конечных версий из большой ERP+ через систему префиксов. Что за инструменты это делают? Они есть в доступе? Или это вообще часть СППР?
Про это даже есть подробная статья на Хабре.
Если вкратце, в конфигурации есть подсистемы: «Управление торговлей», «Комплексная автоматизация» и так далее. И вы включаете каждый объект в ту или иную подсистему.
А дальше через пакетную команду MergeCfg на вход подается XML, которая говорит: возьми конфигурацию и по этим правилам из нее что-то убери или добавь. И получается другая конфигурация. Эта пакетная команда – часть платформы.
А еще в коде расставлены теги, с помощью которых вырезаются куски кода – это отдельный механизм.
А в СППР просто заведено куча проектов и оттуда все управляется. Правила XML лежат в репозитории, а саму вырезку выполняют задания в пайплайне.
Можно ли использовать СППР для разработки расширений?
У нас нет такой задачи. Мы только патчи в СППР делаем. И вообще все отделы в «1С» делают патчи в СППР.
А отдельные расширения, как проект с родительской конфигурацией – наверное как-то можно. Вроде люди используют.
Вы показывали систему согласования изменений в объектах метаданных. Можно ли ее использовать для хранилищ? Или там в качестве исходников можно брать только EDT или файлы выгрузки из конфигуратора?
Этот механизм поддерживает оба формата – можно использовать и для хранилищ, и для формата EDT.
Вы сказали, что используете для тестирования типовую версию Vanessa Automation, которая доступна всем пользователям. А генератор дымовых тестов вы тоже из нее используете?
Так исторически сложилось, что дымовые тесты были написаны до того, как появился генератор в Vanesa Automation. Поэтому нет, конкретно этот генератор не используется.
Есть ли какие-то планы по доработке этого генератора? Потому что он сейчас фактически не поддерживает функциональность БСП – не использует подключаемые команды, ввод на основании через него нельзя протестировать, и там еще куча ограничений.
Прямо сейчас готовых планов по доработке этого генератора нет, но все можно обсудить.
Как у вас обстоят дела с актуализацией тестов? Насколько много времени на это уходит? Что вы делаете для того, чтобы это время сократить?
У нас все ошибки при тестировании регистрируются в СППР. И там есть поле, где возникла ошибка – если ошибка возникла в тесте, она сразу исправляется. Ошибки в тестах бывает очень часто.
Мы постоянно актуализируем тесты – разработчики тестов где-то 30% своего времени тратят на актуализацию автотестов.
Были ли какие-то идеи как это автоматизировать, чтобы оно само актуализировалось?
На актуализацию тестов действительно тратится много времени и приходится даже выбирать – написать тест или проверить вручную, чтобы не тратить время на постоянную актуализацию.
Мы даже проводили анализ на ломкость тестов – в СППР же есть статистика, и можно проверить, какие тесты ломались чаще всего.
Дальше уже можно провести анализ – тест ломается потому, что функциональность постоянно развивается, либо его просто написали плохо, и он нестабилен.
Вы говорите, что тестирование у вас происходит в основном на Linux. Но разве можно потестировать на Linux и быть уверенным, что потом у пользователей на Windows все будет нормально? Не стоит ли еще дополнительно на Windows потом протестировать?
Мы тестируем на Linux, потому что в докере на Linux получается более эффективная нагрузка на железо.
Но как раз для того, чтобы предотвратить то, о чем вы говорите, у нас сбоку есть блок специальных машин, которые с небольшим отставанием по round-robin проверяют эти потоки еще и на Windows.
Мы не собираемся полностью уходить на Linux, потому что не хотим оторваться от реальности. Поэтому да, Windows-тестирование в определенном объеме у нас тоже есть, чтобы быть уверенным, что это работает.
У нас также есть и отдельное тестирование для файловых версий и клиент-серверного варианта на PostgreSQL и MS SQL. Со всем этим тоже приходится работать. Для этого есть отдельные стенды.
Вы готовите эталонные базы вручную заранее, или они наполняются перед тестами автоматически?
У нас более 50 эталонных баз для сценарных тестов. Причем каждая команда сама решает, сколько ей создать эталонных баз.
Тут проблема в том, что некоторые функциональные опции нельзя включить и выключить. Их нужно включить навсегда, а потом набить эталонные данные. И откатить это уже невозможно – такая функциональность. Поэтому приходится создавать для этого отдельные базы.
Конечно, мы стараемся минимизировать количество эталонных баз. У нас есть отдельные базы для закрытия месяца, есть две типовые базы для дымовых тестов.
Мы используем базы, где эталонные данные подготовлены заранее – обновляем их на новую версию ERP и тестируем.
А если кто-то создает новый объект метаданных и к нему нужно добавить какие-то данные, это происходит вручную?
Да. Но у группы регламентированного учета есть даже специальный механизм для актуализации эталонных баз.
Они тестируют свои техпроекты, набивают туда данные, и когда все протестировали, переносят эти объекты с помощью обработки в свою основную эталонную базу. Получается, что им не нужно набивать эталонную базу каждый раз с нуля.
Я у себя на проектах использую утилиту для измерения покрытия кода тестами Coverage41C. Она написана на Java, там используются библиотеки из EDT и так далее. Есть ли у фирмы «1С» планы по развитию метрики покрытия generic coverage?
Сейчас готовых механизмов для анализа покрытия кода в платформе нет. Но можно строить метрику покрытия кода тестами на основе данных из автоматически собранных pff-файлов, файлов замеров производительности.
Мы бы тоже хотели, чтобы в платформе было более изящное встроенное решение, но пока ничего, кроме уже упомянутого, в платформе нет.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART.

Вступайте в нашу телеграмм-группу Инфостарт