Меня зовут Сергей Голованов. Я начинал как программист в отделе интеграции, затем стал ведущим программистом. Сейчас занимаюсь Research and Development (R&D) – изучаю передовые IT-технологии для их адаптации в экосистеме 1С и внедрения в нашей компании (проще говоря, «притаскиваю» интересные решения из большого мира IT в 1С).
Я расскажу о технологии, которую мы метафорично называем «Коровы» и которая помогает нам экономить дисковое пространство. Речь пойдет о Copy-on-write (копирование при записи), сокращенно COW (корова). В нашей компании этот сленг действительно очень прижился. Повсюду звучат фразы вроде «коровы, коровы, коровы» или «сделай мне корову». Даже роли для тестирования у нас носят название «пастухи», а серверы мы именуем «пастбищем». В рамках этого доклада я продолжу использовать данную парадигму, рассказывая о технологии, которую мы применяем.
Технология Copy-on-Write достаточно известная. Она неоднократно обсуждалась, однако в этой статье основное внимание уделено нашей реализации: что, как и почему мы внедрили. Перед этим разберем теорию «на пальцах» – даже непрофессионалам станут понятны принципы работы COW. Также будут представлены наши планы по развитию технологии.
Теория на пальцах копытах
Что такое кластеры? Эта картинка должна немного поднять настроение олдскульным специалистам. Помните дефрагментацию в Windows 95? Тогда было очень популярно запускать ее и наблюдать, как цветные квадратики бегают туда-сюда, все переливается и моргает. Сидишь, смотришь на это. Подходят коллеги: «Что делаешь?» – «Работаю, не мешай!» – «Как ты в этом разбираешься?».
Эти квадратики у специалистов по дискам называются кластерами. (В контексте 1С «кластер» означает группу серверов, но кластеры на диске – это другое). Термин появился с физического устройства магнитных дисков (HDD): они состоят из дорожек и секторов. На пересечении дорожки и сектора находится маленький блок – кластер. В нем хранится единица информации (часть файла). Кластер может либо хранить данные, либо быть пустым.
Обычная файловая система. На схеме есть белые квадратики Excel. Это кластеры. Сознательно грубо объясню принцип (знатоки, не кидайтесь тапками). Обычная файловая система делится на две зоны:
-
FAT (File Allocation Table) – таблица размещения файлов, где хранится информация о файлах;
-
Область данных. Здесь хранятся сами кластеры с содержимым файлов.

Чтение файлов. Представим, что нам нужно прочитать содержимое зеленого файла в обычной файловой системе. Для этого:
-
Идем в FAT.
-
По полному имени файла находим его запись (не может быть двух файлов с одинаковым полным именем – имя уникально адресует файл).
-
В записи, помимо атрибутов (права доступа, временные метки) берем список кластеров, принадлежащих этому файлу.
-
Последовательно считываем все кластеры файла из списка. Получаем содержимое.
Если нужно прочитать фиолетовый файл, действуем так же: идем в FAT, находим запись для фиолетового файла, получаем список его кластеров, считываем их.
Копирование файлов. Теперь представим, что необходимо скопировать зеленый файл в желтый. Как это происходит:
-
Операционная система обращается к FAT.
-
Находит запись зеленого файла.
-
Создает новую запись для желтого файла (копируя или обновляя атрибуты).
-
Последовательно считывает каждый кластер из списка зеленого файла.
-
Каждый прочитанный кластер записывается в любой свободный кластер.
-
Формируется новый список кластеров для желтого файла.
-
Этот список записывается в запись желтого файла в FAT.
Теперь мы можем прочитать содержимое желтого файла. Процесс понятен и прост. Однако наш пытливый программистский ум сразу заметит: после копирования кластеры желтого и зеленого файлов содержат абсолютно одинаковые данные. На диске физически хранятся две копии одних и тех же данных. Это логично, ведь мы скопировали файл. Но тем не менее, здесь явно есть пространство для оптимизации. Пытливые умы придумали файловые системы с механизмом «копирования при записи» (Copy-On-Write, COW).
Файловая система с коровами. Структура похожа: есть FAT и кластеры с данными. Но теперь, если мы хотим скопировать зеленый файл в желтый:
-
Файловая система заводит желтую запись в FAT (переносит или меняет атрибуты).
-
Копирует список зеленых кластеров в запись желтого файла.
На этом все. Благодаря этому копирование на файловой системе с COW происходит мгновенно, потому что никакого копирования не происходит.
При этом мы можем:
-
Прочитать зеленый файлик: идем в FAT, находим запись, читаем список зеленых кластеров, вычитываем все содержимое.
-
Прочитать желтый файлик: берем его список кластеров (который скопировали из зеленого), вычитываем – и получаем то, что мы хотели.
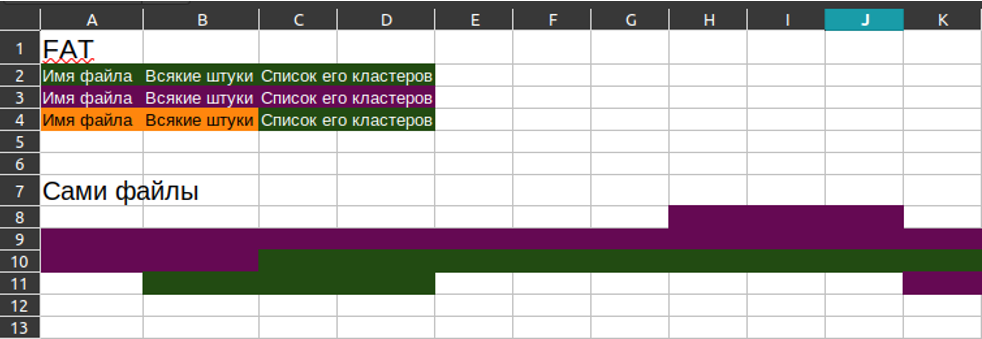
Запись в файл с использованием COW. Интересное начинается, когда мы хотим записать что-то, например, в зеленый файл:
-
Идем в FAT, читаем список кластеров зеленого файла.
-
Операционная система и файловая система определяют, какой именно кластер надо перезаписать (они не перезаписывают все сразу).
-
На обычной файловой системе целевой кластер просто перезаписывается на месте.
-
На системе с «коровами» (COW) существующий кластер не перезаписывается. Вместо этого система берет любой свободный (беленький) кластер, пишет туда новый и измененный, меняет ссылку на него в списке кластеров зеленого файла.
После этой операции мы снова можем пойти в FAT, прочитать зеленый файл и все его содержимое – мы увидим изменения. При этом ссылки на кластеры желтого файла остались прежними. Файлы расползлись, но только на изменения. На диске хранится только изменение между файлами: как снапшот (снимок состояния), только в виде маленького кластера.
Процесс получается быстрее. Мы не копируем кластеры, а пишем только изменения в них. Копирование реального файла происходит только при его записи. Именно так и появился термин «копирование при записи» (Copy-On-Write, COW). Вот и наши «коровы»!
Единственный нюанс: если после этого мы захотим перезаписать тот же кластер, но уже в желтом файле, система:
-
Найдет белый кластер.
-
Запишет в него новые данные.
-
Проверит, кому теперь принадлежит старый кластер. Пробежится по всем спискам кластеров и посмотрит, остались ли на него ссылки.
-
Если ссылок нет – пометит его как свободный (готовый к повторному использованию).
Это единственный небольшой оверхед (overhead, дополнительная операция). Но в целом файловая система с «коровами» не медленнее, чем обычная.
При этом мы получаем такие огромные преимущества, как:
-
Скорость копирования. Любой файл, независимо от размера, копируется мгновенно (создается лишь новая ссылка).
-
Экономия дискового пространства. При изменении файлов на диске хранится только разница одного файла относительно его предыдущего состояния или другого файла.
Получается сплошная прибыль места. Замедления работы не видно.
Исторический контекст. Технология CoW достаточно известна, причем достаточно давно. Я не претендую на исчерпывающий исторический анализ, но вот что я нашел:
-
2001 год. Компания Silicon Graphics выложила в open source свою файловую систему XFS, которая уже поддерживала легковесное копирование. Технология развивалась в компании и раньше – ей примерно 25 лет.
-
2005 год. Sun Microsystems создала ZFS, добавив к легковесному копированию свои «плюшки».
-
2010 год. Появилась Btrfs (тоже появилась спецификация в open source).
Эти файловые системы работают в Linux. Технологии много лет, она надежно работает – почему бы нам ее не использовать?
Наши коровы
Все началось с того, что настало время коров. Оно настало, когда большие компании столкнулись с тем, что не могут купить новое железо. Поставщики внезапно ушли... И вот у тебя есть деньги, а ты не можешь купить новую СХД (систему хранения данных), жесткие диски. Соответственно, тут же возникает вопрос: как бы сэкономить имеющиеся ресурсы?
Наш архитектор Александр Спешилов написал статью «Использование Copy-on-Write на стендах разработки». Он позвонил мне (по его словам, потому что я «занимаюсь всякой R&Dой») и сказал: «Сережа, я тут статью написал. Пройдись по шагам, проверь работоспособность описанного. Если все корректно – опубликую на Хабре».

Мне выделили железо – полумертвый сервер, который было не жалко. Я буквально следовал инструкциям из статьи – там весь процесс описан достаточно подробно, и для XFS, и для Btrfs. На выходе получил рабочую, нормальную и вполне жизнеспособную «корову» (технологию Copy-on-Write). Она и стала у нас MVP (Minimum Viable Product) этой самой технологии.
Выбор файловой системы. Выбор был между XFS и Btrfs. Я остановился на Btrfs. Причины:
-
Красивое название. BTree FS – файловая система на основе B-деревьев (бинарных деревьев).
-
Функциональность. Помимо легковесных копий, есть много разных интересных штук.
Почему не XFS? XFS – выходец из корпоративной среды. Если вы ставите Microsoft SQL Server на XFS (а у нас все на MSSQL: продакшн, разработка, тесты), то чисто теоретически вы имеете право на поддержку Microsoft. Гарантия не теряется, можно использовать их поддержку. Насколько это актуально сейчас – большой вопрос. Они раза три уже уходили из России, потом возвращались и снова уходили...
Однако у XFS есть существенный минус. XFS был одним из пионеров подобных технологий, но он реализует не полноценный Copy-on-Write (CoW), а Delayed Allocation (отложенное размещение файлов). XFS работает на уровне файлов, но нам нужна работа с базами данных. Обычная база Microsoft SQL Server – это как минимум файл базы данных (.mdf) и файл журнала транзакций (.ldf). То есть два файла.
Копирование на XFS пофайлово происходит мгновенно, но все равно за какое-то время. Пока копируем второй файл (тоже мгновенно) – между этими копиями может вклиниться транзакция. Тогда данные расползутся: изменения улетят только в базу или только в журнал.
Для гарантированной целостности копии в XFS необходимо:
-
Переводить базу в offline-режим;
-
Выполнять копирование;
-
Возвращать базу в рабочее состояние.
Преимущества Btrfs. Btrfs работает с сабволумами (subvolumes, подтомами). Сколько бы файлов ни было на одном сабволуме, Btrfs создает снапшот (снимок) всего сабволума. Это не классический снапшот read-only (только для чтения), а полноценная, доступная для записи легковесная копия всех файлов в сабволуме. И это не требует остановки базы данных или перевода в offline-режим. Именно поэтому была выбрана Btrfs.
Практический старт. Oracle Linux – наш корпоративный стандарт. На него мы и поставили всю систему, установили Microsoft SQL Server. Я действовал буквально по шагам из статьи – там все подробно описано.
Нашли смельчаков – «людей, которых не жалко» – и предложили: «Вот новая технология, давайте попробуем. Проверим, можно ли вообще работать в 1С на таких базах». Отважные нашлись. Приходили и говорили: «Сделай мне корову». Я заходил по SSH, вручную писал команды типа sudo btrfs subvolume create. В итоге получался список скопированных файлов. Потом я шел в Microsoft SQL Server Management Studio, выполнял ATTACH DATABASE, указывал имена файлов – и база данных появлялась.
После этого шел в консоль кластера, указывал: «Вот там лежит SQL-база, опубликуй ее на этом app-сервере». Затем формировал строку подключения и отдавал человеку. Звучит долго, но на деле это гораздо быстрее, чем разворачивать наши стандартные разработческие базы.
Наша продакшн-база, сильно обрезанная и подготовленная для тестирования, весит 2 терабайта. Разворачивать 2 терабайта – это несколько часов. А тут люди подошли, «постояли над душой» – я отдал строку подключения, и все готово!
Стали пользоваться и говорить: «Да все нормально, разницы не видим. Зашли в 1С – все как раньше, ничего не изменилось». По теории так и должно было быть, но проверить нужно было. Слух о «коровах» пошел, и дело пошло в массы. Стало больше людей, приходили и просили: «Дайте мне корову, дайте мне корову!».
Развитие и автоматизация. В итоге сложились две вещи. Во-первых, мне надоело вручную писать команды. Во-вторых, у нас накопилась статистика по базам, созданным через «коров». Логический размер нашей «боевой» базы, которую мы раздавали – 2 терабайта. Но Btrfs умеет считать эксклюзивный размер – реальный физический объем.
Каков размер обычной разработческой базы: не средней, а именно рядовой? Стандартная задача: человек получил базу, зашел, чуть изменил конфигурацию, провел пару тестовых документов, что-то запустил – и задача завершена.
Оказалось, что обычный размер такой базы не 2 ТБ, а всего 80 МБ! Тут руки сами потянулись к шампанскому, захотелось бросать в воздух чепчики! Экономия места вышла колоссальная, да и технология показала себя хорошо.
Начальство резюмировало: «Все, запускаем в массы! Дайте людям инструмент для самостоятельного использования». Но нельзя же сказать пользователю: «Заходи в SSH, пиши sudo btrfs subvolume create...». Так не работает. Нужно, чтобы человек нажал кнопку – и «корова» готова. Значит, требуется интерфейс. А интерфейс в нашей экосистеме – это 1С.
Мы рассматривали вариант на winow (веб-сервер на OneScript), но выбрали родную платформу. У нас есть служебная база «Иван Суперскрипт». В этой базе люди управляют своими разработческими окружениями: создают снапшоты, работают с ними. Для «коров» мы сделали отдельный справочник – выглядит как самый обычный объект 1С.
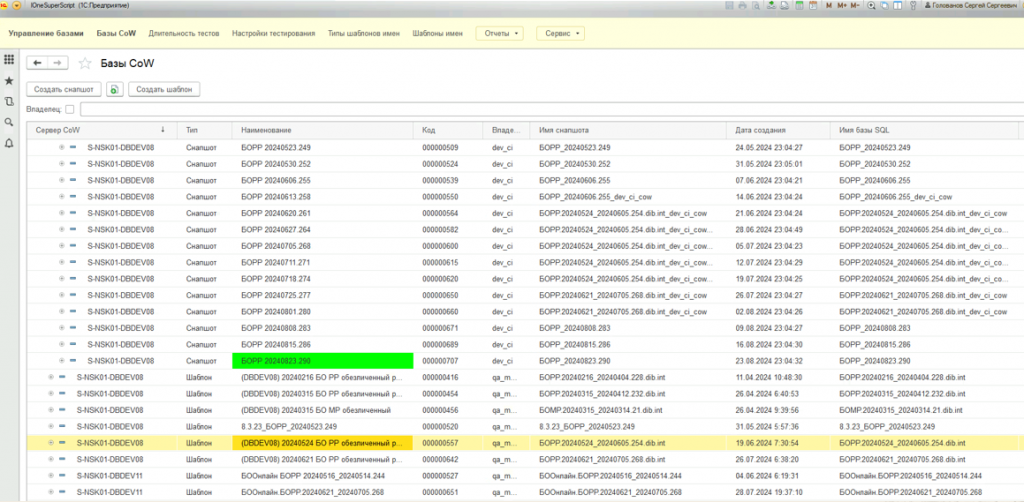
Интерфейс и работа с пользователями. Вот как это работает в интерфейсе: вы открываете справочник и выбираете любую строку. Вы видите сервер, имя снапшота, источник и имя SQL-базы. Выделяете строку, нажимаете «Создать снапшот», и открывается обычная форма справочника 1С.
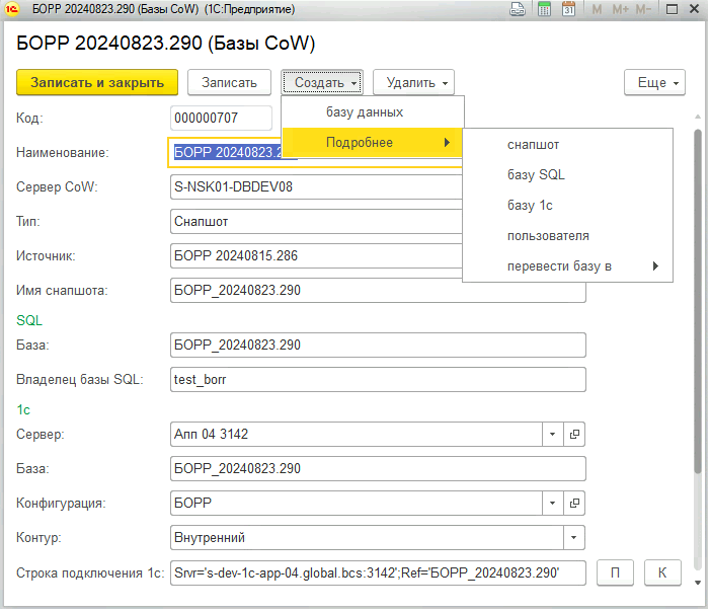
Все поля на месте. Пользователь нажимает «Записать и закрыть», и система спрашивает: «Создавать базу?» Пользователь отвечает «Да», и через 8-15 секунд (максимум!) все готово.
Причем львиная доля времени уходит на работу с app-сервером. Остальное происходит мгновенно. Пользователь получает двухтерабайтную базу, с которой можно сразу работать. Интерфейс привычный – 1С. У разработчиков не возникает проблем.
Права и структура хранения. Права разграничиваются через стандартные механизмы 1С. Субволумы логически разделены:
-
Шаблоны – это «здоровенные» 2-терабайтные исходники, которые хранятся в отдельном разделе.
-
Снапшоты – легковесные копии для пользователей, которые находятся в другом разделе.
На Btrfs можно строить деревья снапшотов: делать снимок от снапшота, от него еще один и так далее. Это открыло новые сценарии работы.
Пример живого сценария. Допустим, разработчик хочет запустить что-то «противоестественное» и боится сломать базу. Он:
-
Создает снапшот от своей текущей базы (8 секунд);
-
Тестирует рискованную операцию в копии и видит, что все сломалось;
-
Удаляет сломанный снапшот (мгновенно);
-
Создает новый снапшот (8 секунд), пробует другой вариант и снова ломает;
-
Повторяет, пока не найдет рабочее решение, и переносит его в основную базу.
Итог: скорость работы с огромными базами стала фантастической, а возможности – шире.
Управление через контекстное меню. В интерфейсе есть следующие действия:
-
«Создать базу данных» – автоматически создается снапшот, SQL-база и база 1С.
-
«Удалить» – каскадом удаляется база 1С, SQL-база и снапшот.
Можно выполнять шаги и по отдельности (например, для отладки).
Техническая реализация. Под капотом я не стал усложнять. Зачем? Уже есть рабочий механизм: SSH и Microsoft SQL Server Management Studio. Почему бы не использовать готовое?
На app-сервере, где опубликован «Иван Суперскрипт», мы выпустили пару SSH-ключей:
-
Секретный ключ разместили на серверах с «коровами»,
-
Публичный ключ оставили на app-сервере.
Теперь app-сервер может подключаться ко всем «коровьим» серверам по SSH без пароля (авторизация по сертификату) и выполнять команды вроде sudo btrfs subvolume create – все автоматически!
Средствами Linux легко настроить права: какие команды разрешены, что можно через sudo, а что нет. Система выглядит достаточно безопасной – я не вижу здесь рисков.
Как происходит магия после создания Subvolume:
-
Через ADO (ActiveX Data Objects) получаем список файлов нового субтома.
-
Идем в Microsoft SQL Server Management Studio и выполняем ATTACH DATABASE.
-
Через RAS/RAC (Remote Administration Server/Client, входящие в состав платформы 1C) публикуем базу на нужном сервере.
Все просто и понятно. Я перенес модуль управления кластером из БСП в «Иван Суперскрипт». Работает! Реализация незатейливая – если повторите эти шаги, получите такую же систему.
Почему наши «коровы» легли. Как я уже говорил, начиналось все с тестового сервера, «который было не жалко». Пока пользователей было 5-6 человек, все восторгались: «О, коровы! И мне дайте!». Но когда пришли 20 человек, а также начались ежемесячные обновления шаблонов (эти «здоровенные» 2ТБ базы с устаревшей конфигурацией), начались проблемы.
Представьте: утром 5-6 человек одновременно создали снапшоты от шаблона, накатили свежую конфигурацию и запустили реструктуризацию на 2 терабайта! Результат? «Корова сдохла». Сервер лег. Начался ропот: «Ваши коровы тормозят! Верните меня на обычный сервер!».
Стали искать решение в рамках имеющихся ресурсов. Вспомнили про наш CI-контур (о нем я рассказывал на прошлых конференциях). И вот что придумали:
По пятницам автоматика запускает спецзадание в «Иван Суперскрипт». Оно находит шаблон релиза (специально помеченный элемент справочника), создает от него снапшот, накатывает последнюю собранную конфигурацию и прогоняет полную реструктуризацию и обработчики обновления. На это есть двое суток (все выходные) – можно спокойно «лопатить» огромную базу.
Итог к понедельнику:
-
У разработчиков готова свежая «корова» с актуальным релизом.
-
Они создают свои базы за 8 секунд – без реструктуризации и нагрузки на сервер.
Если CI прошел успешно, этот снапшот становится новым шаблоном для следующих релизов.
Теперь можно быстро создавать базы для тестов и разработки от любого исторического релиза – без головной боли с масштабированием. Вот так мы приручили CI/CD для «коров»!
Планы развития. Мы создали задание по формированию релизов, но когда много людей сидит на полурабочем сервере, ему все равно плохо. Сейчас мы пришли к решению: сделать по своему «пастбищу» (отдельный сервер «коров») для каждой команды. То есть у каждой команды будет свой сервер, где она сможет спокойно управлять всем: загружать свои шаблоны, создавать снапшоты, и если не хватает места – самостоятельно разбираться, чтобы не мешать другим.
Мы хотим постепенно перевести все команды на эту технологию (процесс уже начался), потому что экономия места огромная: 80 мегабайт против 2 терабайт – это очень заметно. Конечно, если люди начинают перепроводить документы за все годы или пересоздавать индексы во всей базе, база начнет «расползаться», и ее размер увеличится. Но обычная база занимает немного.
Второй момент: изначально интерфейс был рассчитан на осознанных разработчиков. Мы давали принцип: «Инструмент как есть – хотите пилить, пилите!» Но пришлось добавить защиту от необдуманных действий. Например, если шаблон лежит на одном сервере «коров», нельзя разрешать выбирать другой сервер при создании снапшота – ведь на другом сервере этого шаблона может и не быть. Но пытливые программисты все равно пытаются что-то сломать, потом у них ничего не работает – приходится «закрывать» интерфейс, оформлять его красиво и безопасно.
Главное, ради чего все затевалось (сейчас идея в бэклоге, но скоро начнем работать), – это регресс (релизное тестирование). Он занимает очень много времени (10–16 часов) и состоит из нескольких этапов. Если на каком-то этапе что-то пошло не так, QA видят проблему только «через призму» всех последующих этапов, когда ошибка уже накопилась. С помощью «коров» мы сможем после каждого этапа регресса делать снапшоты базы. Тогда QA смогут зайти на ЛЮБОЙ этап независимо, проверить: «здесь хорошо, здесь хорошо, а вот здесь сломалось» и найти корень проблемы без влияния более поздних этапов регресса.
Технология отлично показала себя, и мы планируем перевести на нее всех. Хотя сейчас есть сопротивление: слышим «Ваши коровы тормозят!» и даже небольшой бунт. Но те команды, что уже перешли на свои серверы, – довольны, счастливы, у них все хорошо.
Напоследок: занимайтесь R&Dой! Это прикольно, интересно, дает дофамин, окситоцин и все остальные гормоны.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт