Меня зовут Владимир Кирбаба. Я ведущий инженер в «T-банке». Занимаюсь администрированием кластеров приложений на платформе 1С:Предприятие, автоматизацией процессов разработки и поддержкой интеграционных сервисов.
Эта статья о том, как руководствуясь принципами CI/CD, мы используем конвейеры на платформе GitLab для повышения эффективности и надежности доставки программного обеспечения.
Мы автоматизируем процессы в рамках нескольких проектов, над которыми работают более чем три команды разработки. Наш спринт длится всего одну неделю, и по его завершению мы выпускаем новый релиз. Именно поэтому для нас критически важны надежные инструменты тестирования и доставки программного продукта до конечных потребителей.
Платформа GitLab позволила нам достичь значительных результатов в решении этих задач. Далее я расскажу, как мы ее используем. Но сначала – краткое введение для тех, кто еще не знаком с GitLab.
Основные компоненты GitLab
GitLab – это платформа для управления Git-репозиториями, которая предоставляет широкий набор возможностей для разработки, контроля версий, управления проектами и обеспечения безопасности программного обеспечения.
Она включает множество компонентов, которые охватывают весь цикл разработки программного обеспечения. Среди ключевых можно выделить:
-
Систему контроля версий git,
-
Инструменты контроля доступа,
-
Bug tracking для фиксации и систематизации ошибок,
-
Механизмы управления Feature request, позволяющие организовать взаимодействие между пользователями и разработчиками,
-
Средства Task management для эффективного управления проектами,
-
Wiki для ведения документации в рамках проекта,
-
И, конечно, GitLab CI/CD – большую компоненту для автоматизации процессов сборки, тестирования и доставки приложений.
CI/CD – это метод непрерывной разработки программных продуктов, который предполагает постоянное создание, тестирование и развертывание кода в различных средах.
Использование GitLab CI/CD начинается с момента внесения изменений в код – будь то модификация существующей логики или добавление нового функционала. Разработчики работают в отдельных ветках локальных репозиториев, тестируют свои изменения, фиксируют их и отправляют в удаленный репозиторий.
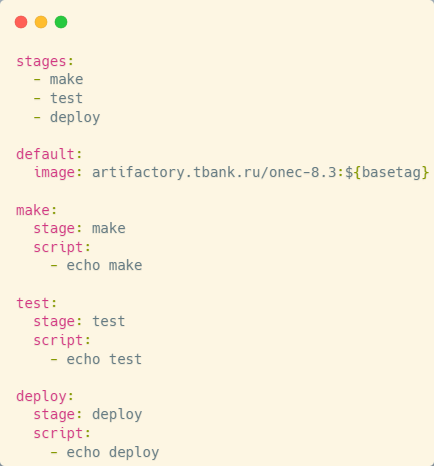
Автоматизация процессов начинается с того, что GitLab CI/CD управляется конфигурационным файлом, который вместе с проектом находится в одном репозитории. Все, что вы напишете в конфигурационном файле – это и есть ваш конвейер или pipeline (пайплайн).
Структура пайплайна: этапы и задания
Пайплайн состоит из этапов (stages) и заданий (jobs).
-
Этапы задают порядок выполнения операций: сначала сборка, затем тестирование, после чего – развертывание в целевые среды.
-
Задания определяют конкретные действия, которые выполняются на каждом этапе.
Например, на этапе сборки мы формируем основную конфигурацию, конфигурацию расширения, а также внешние отчеты и обработки. На следующем этапе все это тестируется, а затем – развертывается на информационных базах для конечных пользователей.
Сами пайплайны могут запускаться различными событиями, начиная с нажатия на кнопку, заканчивая срабатыванием по расписанию. Самый удобный способ – автоматическое срабатывание конвейера при коммите в ветку или при коммите в request.
Выполнение заданий: роль раннеров и окружений
Задания в наших конвейерах выполняются с помощью агентов GitLab, которые называются раннерами. Агент или раннер – это приложение, взаимодействующее с платформой GitLab и отвечающее за выполнение задач конвейеров.
Как правило, задание выполняется на том устройстве, где установлен раннер. При этом вам доступна поддержка различных операционных систем. Но одновременно с этим вы можете выполнять задания конвейера в Docker-контейнерах, в платформе Kubernetes или даже в автоматически разворачиваемых облачных инстансах.
Примеры использования раннеров и Docker-образов
Приведу несколько примеров. Если установить GitLab Runner на Windows-сервере, выполнение заданий можно настроить, например, в оболочке PowerShell. Если же раннер развернут на Unix-подобной системе, можно указать выполнение заданий в Docker-контейнере.
Мы используем кластеры Kubernetes для выполнения команд заданий. Указываем расположение Docker-образа, который будет использован для создания контейнеров в этих кластерах. После этого раннер клонирует репозиторий в программное окружение развернутого образа, и начнет последовательно выполнять команды заданий для достижения результата.
Особо хочу подчеркнуть преимущество использования Docker-образов – это изоляция процессов. Все конвейеры выполняются в изолированных средах, тем самым мы достигаем прозрачности процессов и понимаем, что они друг на друга не влияют при масштабировании конвейеров.
Состав Docker-образа для CI/CD

На картинке я выделил ключевые компоненты, входящие в состав образа:
-
Утилиты для управления удаленным компьютером: ssh\ и ssh-pass\,
-
Утилита unzip\ для работы с архивами,
-
Screen\ – утилита для создания виртуальных терминалов в режиме сессии,
-
Xorg\ – реализация оконной системы, необходимая для запуска графических приложений в Unix-средах,
-
Openbox\ – оконный менеджер для оконной системы (которую мы установили),
-
Xvfb\ (виртуальный дисплейный сервер) позволяет выполнять графические операции в оперативной памяти без необходимости вывода на физический экран,
-
И, наконец, мы ставим серверную часть платформы 1С:Предприятие для работы с ней.
Этап сборки: работа с 1С и автономным сервером
Теперь рассмотрим реализацию классических этапов пайплайна: Make, Test и Install. На этапе сборки мы формируем основную конфигурацию, конфигурацию расширения, а также внешние отчеты и обработки. Потом смотрим, как это используется на тестовой среде и разворачивается у пользователей.
Сборка в нашем случае выполняется с помощью утилиты управления автономным сервером 1С, которая позволяет работать с файловыми информационными базами.
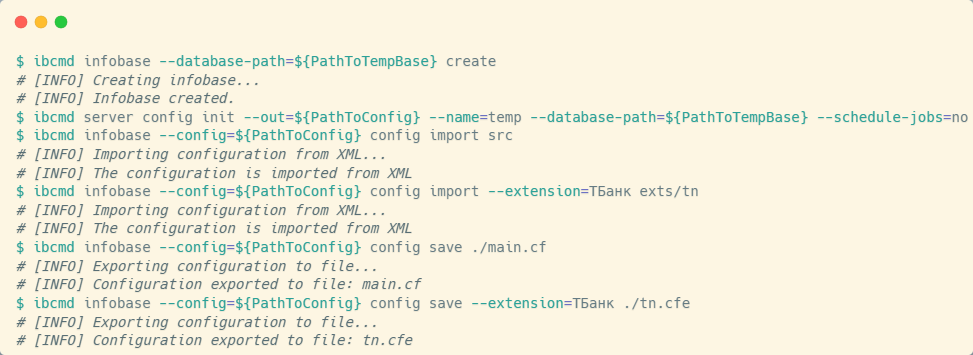
Для создания новой файловой базы необходимо вызвать утилиту управления автономным сервером с ключом infobase create, указав каталог, в котором она будет создана. Для удобства дальнейшей работы рекомендуется использовать конфигурационный файл сервера, который создается при запуске с опцией server config init и передачей всех необходимых параметров для работы с базой.
После этого будем использовать файл конфигурации сервера для выполнения таких команд, как загрузка основной конфигурации в рабочую (config import) и конфигурации расширения в нашу файловую базу.
После выполнения команд config import мы получаем файловую базу с измененной рабочей конфигурацией. Этого достаточно для последующей выгрузки конфигурации в файлы. С помощью команд config save мы сохраняем как основную конфигурацию, так и конфигурацию расширения.
На этом этапе все выглядит достаточно просто. Однако с внешними отчетами и обработками ситуация сложнее.
Сложности сборки внешних отчетов и обработок
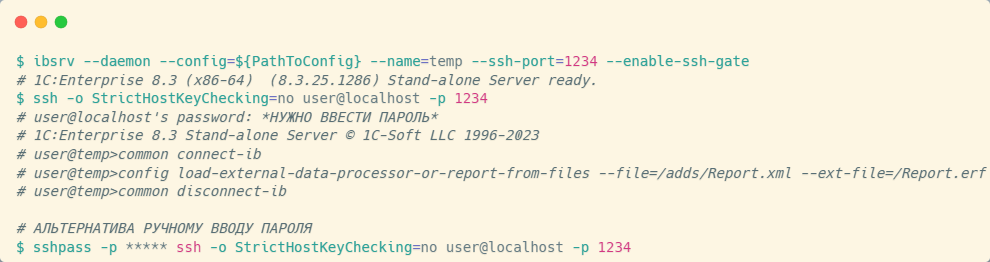
Проблема в том, что для сборки внешних отчетов и обработок с помощью конфигуратора требуется лицензия. Альтернативный способ – использование автономного сервера 1С, но для этого его нужно запустить с опцией enable-ssh-gate для разблокировки возможности подключения к автономному серверу по SSH.
Дело в том, что при таком подключении автономный сервер начинает работать как конфигуратор в режиме агента, у которого существует свой довольно большой набор команд. Нас интересует команда сборки внешних отчетов и обработок.
При подключении любым SSH-клиентом к автономному серверу – в моем примере используется простой SSH – необходимо пройти аутентификацию.
Если файловая база пустая, подключение происходит без запроса пароля. Если же в базе уже есть пользователи, автономный сервер запросит пароль.
После успешного подключения к серверу первой командой необходимо подключиться к информационной базе. Для этого используется команда common connect-ib. Затем можно приступать к сборке внешних отчетов и обработок из файлов.
Как особенность можно выделить то, что значения ключей этой команды должны быть указаны в виде относительных путей – относительных по отношению к каталогу данных пользователя. При запуске автономного сервера указывается множество параметров. Некоторые из них имеют значение по умолчанию. Один из них – это UserData, указывающий на каталог, который будет использоваться как каталог данных пользователя.
Соответственно, перед началом сборки нужно убедиться, что исходные файлы находятся в этом каталоге или что вы задали каталог данных пользователя в то место, где у вас исходники. Сборка довольно простая, если знать особенность расположения файлов.
После завершения работы с базой можно отключиться с помощью команды common disconnect-ib. Однако отключиться от SSH-сессии, установленной с автономным сервером, так легко не получится: для этого надо использовать специальный SIGINT-сигнал (Ctrl+C). Архитектура конвейеров в GitLab CI не позволяет нам легко послать такой сигнал – это приведет к разрушению всего конвейера.

Далее хочу показать, как мы решаем две задачи:
-
Передачу пароля пользователя для подключения к автономному серверу без взаимодействия с клавиатурой,
-
Отключение автономного сервера без разваливания конвейера.
Здесь мы используем утилиту ssh-pass, которой передаем пароль и команду подключения к автономному серверу. Таким образом ssh-pass берет на себя процесс аутентификации, позволяя автоматизировать установку SSH-соединения.
Для решения второй задачи – безопасного управления сессией – мы применяем утилиту screen. Screen позволяет создавать новые виртуальные терминалы в режиме сессии: мы открываем новый терминал, передаем туда команду установки соединения – и соединение есть, но в другом терминале.
Для того, чтобы выполнять команды в другом терминале, мы используем опцию staff утилиты screen, которая принимает команды из стандартного потока ввода и выводит их на экран любого терминала. Чтобы подтвердить команду к выполнению, нужно нажать Enter.
В моем примере я предлагаю дополнять стандартный поток ввода символом перевода строки – для этого я использую команду echo и возможность указания символов через кодировку.
Такими простыми шагами мы смогли все собрать, не блокируя работу интерфейса в конвейере.
Этап тестирования: создание тестового стенда
На следующем этапе полученные файлы конфигурации, расширения и внешних обработок необходимо протестировать. Ключевой задачей становится создание полноценного тестового стенда.

Мы придерживаемся соглашения: тестовые данные, пользователей с актуальными ролевыми моделями и настройки баз, которые будут соответствовать настройкам продакшена, мы воссоздаем в специальных тестовых стендах, расположенных на отдельных хостах, вне контура Kubernetes. Эти хосты недоступны для прямого выполнения команд со стороны раннеров.
Мы создаем новый файл конфигурации сервера и используем его для того, чтобы реплицировать клиент-серверную базу, которая находится отдельно, в файловую базу внутрь окружения контейнера. Таким образом, мы получаем файловую базу с данными для тестирования.

После этого применяем имеющиеся файлы основной конфигурации и расширения к нашей файловой базе и обновим ее. В результате у нас формируется полноценный тестовый стенд, включающий как тестовые данные, так и новые доработки.
Инструменты тестирования: Vanessa Automation и JAX Unit

Мы активно используем такие инструменты автоматизированного тестирования, как Vanessa Automation и YAxUnit. Это замечательные инструменты, которые работают с информационными базами в режиме предприятия и для своей работы требуют лишь конфигурационный файл с настройками тестов.
Чтобы запустить тестирование, мы поднимаем автономный сервер 1С в режиме службы и запускаем режим предприятия. Однако в Docker-контейнере отсутствует графическое окружение, а некоторые инструменты (включая Vanessa) требуют его для корректной работы. Для решения этой проблемы мы используем виртуальный дисплейный сервер Xvfb. Утилита xvfb-run упрощает выполнение команд в такой среде: с ключом -a она одновременно запускает виртуальный графический сервер и передает команду на выполнение в его среду.
Важный нюанс: Vanessa Automation для тестирования будет пытаться создать новый сеанс работы с информационной базой в режиме testclient, и у нее не получится это сделать, потому что она будет пытаться это сделать без использования графического сервера. Однако этот момент легко обойти.
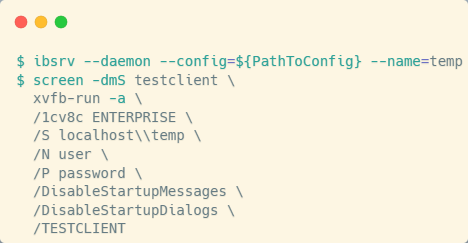
Перед запуском самой Vanessa с ключом testmanager необходимо вручную запустить сеанс работы с информационной базой с ключом testclient. Здесь я еще раз обернул запуск виртуального графического сервера с сеансом работы с базой в уже известный нам screen. Не блокируя сеанс в виртуальном терминале, поднимаем виртуальный графический сервер и выполняем там подключение к базе.

С YAxUnit ситуация проще: достаточно поднять автономный сервер, указав ему работать с нашей файловой базой, и запустить сам инструмент тестирования в режиме предприятия. Дополнительных обходных манипуляций не требуется.
По завершении тестирования формируются отчеты, которые мы консолидируем в единое хранилище и отправляем в нашу тестовую платформу – мы используем Allure TestOps. У вас может использоваться другое решение – это не принципиально.
Также мы минимально дополняем карточку request, отмечая статус: прошли ли тесты успешно или обнаружены ошибки.
Управление развертыванием: правила и ресурсные группы
Не каждый конвейер должен завершаться заданием обновления. Платформа GitLab позволяет очень тонко настраивать конвейеры для того, чтобы отражать наши пожелания и соответствовать ожиданиям.

При создании задания конвейера вы можете управлять запуском задания через правило с условиями. Можно представить, что мы будем обновлять информационные базы только при коммите в ветку master. Или, наоборот, что мы откажемся от тестирования ветки master, поскольку все предыдущие коммиты были протестированы.
Так как мы не ставим раннеры на сервера приложений кластеров платформы 1С:Предприятие, складывается ситуация, когда несколько раннеров могут конкурировать за доступ к информационной базе в попытке ее обновить. Поэтому здесь можно и нужно использовать ресурсные группы.
Указание ресурсной группы гарантирует, что задание является взаимоисключающим для всех конвейеров одного и того же проекта. Таким образом, несколько заданий, использующих одну ресурсную группу, запущенные одновременно, выстроятся в последовательную очередь и последовательно выполнятся.
На рисунке выше задание deploy использует ресурсную группу production. Это гарантирует, что никаких коллизий в процессе обновления информационных баз не будет.
Дополнительные процессы: анализ кода и документация
В своих конвейерах мы используем не только классические этапы – сборку, тестирование и развертывание. Также мы подвергаем нашу кодовую базу анализу и автоматизируем задачи создания документации.
Для анализа качества кода мы, как и многие, используем SonarQube – платформу с открытым исходным кодом, предназначенную для анализа, отслеживания изменений и контроля качества кодовой базы.
SonarQube использует готовые инструменты для проведения анализа кодовой базы. В проектах на 1С особенно полезны плагины, разработанные сообществом:
-
1C BSL Community Plugin,
-
Community Branch Plugin, который разблокирует работу с реквестами и ветками.
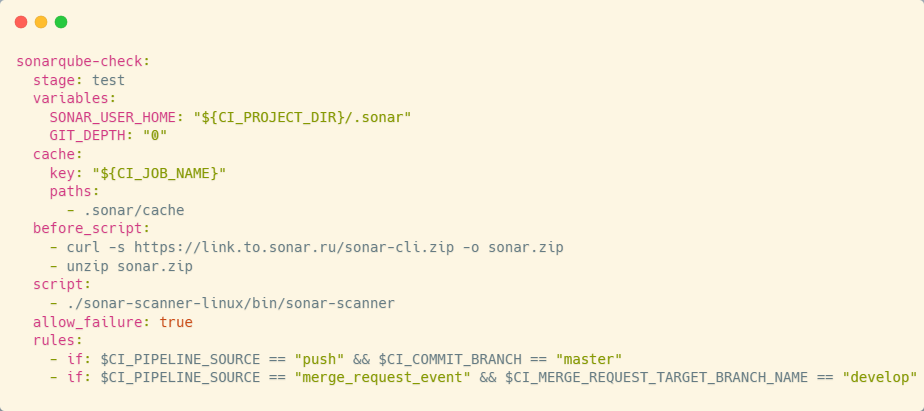
Реализация проста – мы не изобретали ничего нового. Мы скопировали задания проверки реквестов с сайта вендора. Для его работы потребуется определить несколько переменных окружения:
-
Адрес сервера SonarQube,
-
Токен доступа,
-
Путь к файлу настроек проекта.
После того, как переменные определены, вызывается утилита SonarScanner, которая выполняет анализ и отправляет результаты на сервер. SonarScanner доступен в различных форматах – в том числе как Docker-контейнер, где он уже существует, либо вы можете скачать его по прямой ссылке, как я привожу в примере: использую curl, затем путь к Sonar, разархивировал и запустил. И использовал правило, что не все должно подвергаться проверкам – только коммиты в master и реквесты в dev.
Автоматизация документации: Release Notes и changelog
Мы также автоматизировали формирование Release Notes (релиз-нот) – документа, описывающего изменения в новой версии по сравнению с предыдущей.

В GitLab существует удобный инструмент для этого, который способен собрать реквесты в определенную ветку и на основании этих реквестов в ветку создать список, что было сделано. Но для работы с этим списком нужно подготовиться. Так, я предлагаю задание, которое проверяет заголовок реквеста на соответствие определенному шаблону. В качестве шаблона мы используем пространство в Jira и номер задачи. Если заголовок реквеста не соответствует шаблону, конверт для него не выполняется – надо переделывать.

После того, как мы добились того, что все реквесты соответствуют шаблону, мы подготавливаем сообщение к merge-комиту, который произойдет после слития реквеста. Разработчики не любят писать хорошие сообщения к своим реквестам, поэтому здесь мы все берем на себя.
Сообщение включает:
-
Заголовок реквеста,
-
Описание изменений,
-
Информацию о том, кто, что и куда слил,
-
И главное – в конце указываем ключевое слово changelog с тремя вариантами развития событий added/changed/removed. Эти значения будут использованы для группировки заголовков всех реквестов на три группы: «Что добавлено», «Что изменено», «Что удалено».
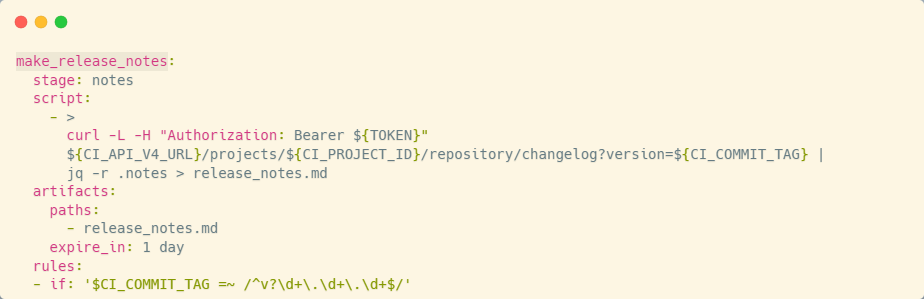
Подготовительный этап завершен. Теперь, чтобы сгенерировать список изменений по проекту, необходимо обратиться к GitLab API, к его API по changelog и передать параметр версии. Значение параметра должно соответствовать формату версии – несколько чисел, разделенных точкой, например, 0.0.1.
Само значение передается через тег – мы сами его формируем и пушим в репозиторий, после чего отрабатывает задание, смотрит, что тег есть, тег соответствует шаблону и обращается к GitLab API с использованием этого тега. В результате получаем файл с изменениями новой версии.
В завершение хочу поделиться материалами, которые использовал при подготовке этой статьи. Также хочу поблагодарить сообщество, которое развивало DevOps-инструменты.
-
Vanessa-automation: https://github.com/Pr-Mex/vanessa-automation
-
Документация по Gitlab: https://docs.gitlab.com/
-
Руководство администратора платформы 1С:Предприятие: https://its.1c.ru/db/v8324doc#browse:13:-1:4
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт