Меня зовут Максим Сильванский, я являюсь архитектором 1С в компании Vi.Tech.

В последнее время мы всё чаще слышим о событийном подходе к интеграции, Kafka и RabbitMQ. И действительно, такой подход дает много преимуществ. Но важно понимать, что ваша архитектура и ландшафт 1С должны быть к этому готовы, в противном случае эти инструменты легко превращаются из решения в источник новых проблем и «бутылочное горлышко» всей системы.
Мой доклад – это своего рода компиляция опыта, советов и даже «граблей», которые мы собрали при построении нашей собственной подсистемы обмена. Сейчас эта система уже позволяет загружать более миллиона объектов в день, и объем постоянно растет. При этом мы уверены, что ограничений по масштабированию практически нет: решение гибкое, расширяемое и устойчивое.
Чтобы вы лучше представляли предпосылки, почему мы выбрали именно такой путь развития наших инструментов интеграции, начну с небольших вводных по нашему ИТ-ландшафту – тому, как мы понимаем архитектуру обменов, и как к ним подходим.
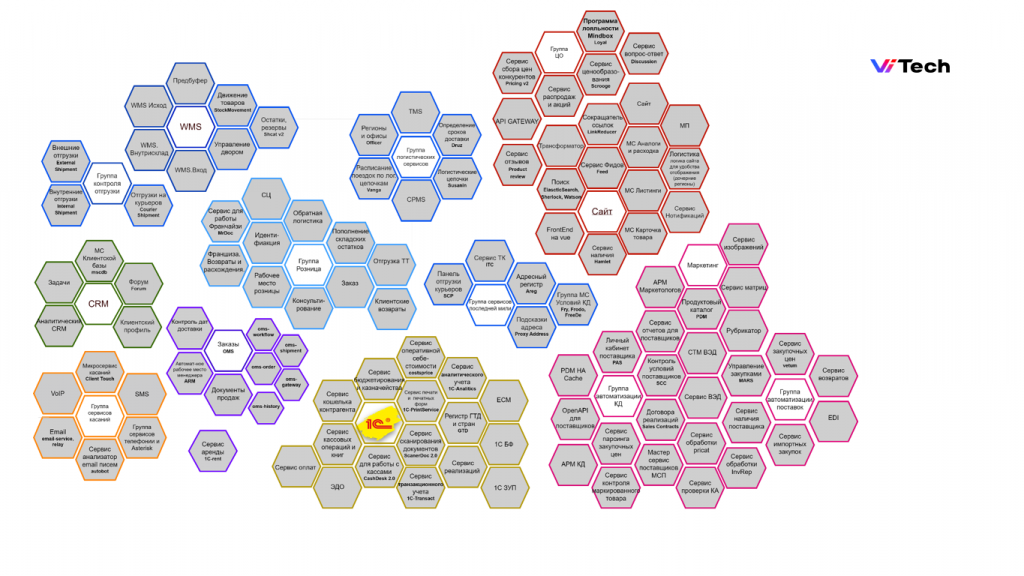
Vi.Tech – это дочерняя компания «ВсеИнструменты.ру».
-
Мы создаем ИТ-продукты для одного из крупнейших игроков на рынке e-commerce.
-
ИТ-штат компании в 2023 году – около 500 человек.
-
1С-отдел чуть поменьше – 22 человека.
На слайде вы можете видеть приблизительный ИТ-ландшафт нашей компании. 1С – это желтый блок снизу.
Каждый гекс на данном слайде – это отдельный сервис. Количество гексов-сервисов постоянно растет, и вместе с этим растет количество и объем обменов между ними.
До внедрения собственной подсистемы обмена у нас не было централизованного решения, позволяющего универсально управлять всем этим «зоопарком» разнородных интеграций – у нас были обмены по API, через COM, прямые подключения к базам данных и прочие варианты.
Осознав эту ситуацию, мы задались вопросом наподобие того, который часто задают на собеседованиях: «Где вы видите себя через 5 лет?» И поняли, что если ничего не менять, то через 5 лет мы видим себя в не очень хорошем месте.
Проблемы и цели подсистемы обмена

Мы решили очертить круг проблем и определить для себя подходы к их решению:
-
Главной проблемой для нас на тот момент была низкая скорость обмена и отсутствие контроля. Стандартные подходы к обмену в 1С редко обеспечивают высокую производительность. Да, их можно оптимизировать, но это трудоемко, негибко и сложно поддерживать. Поэтому первым требованием к новой подсистеме стала именно скорость.
-
Второй нашей проблемой стало масштабирование средств обмена. Представьте, что одномоментно по щелчку в вас полетело в 2-3 раза больше данных. Что с этим делать? Как не упасть? Нам было важно обеспечить быструю, легкую и удобную масштабируемость – не так, чтобы на увеличение мощности в 2-3 раза уходил целый месяц.
-
Третья проблема – падения обменов и восстановление консистентности данных. Обмены, особенно на COM, имеют свойство падать. Нам была важна отказоустойчивость, чтобы таких вопросов вообще не возникало.
-
Четвертая проблема – повторное получение сообщений или получение накопленных после простоя. Если система временно не читает сообщения (например, во время технологического окна или пересчета итогов), нужно обеспечить гарантию их доставки – возможность получить позже, причем в правильной последовательности, потому что есть обмены, для которых порядок доставки важен. Этот пул проблем мы озаглавили как гарантия и порядок доставки.
-
При стандартных подходах к обмену мы имели множество точек входа и большое количество повторных чтений – внешние системы приходили за одними и теми же данными, иногда даже вставали в блокировки, пытаясь читать одно и то же. Чтобы избежать этих проблем, нам нужна была легкая маршрутизация сообщений в обменах.
-
Еще одной проблемой была высокая стоимость добавления и изменения интеграций. Затраты на поддержку, создание, обслуживание, отладку обменов постоянно росли. Система переставала быть гибкой: из-за необходимости взаимодействия разных разработчиков и разных обменов издержки увеличивались как снежный ком. Этот пул проблем мы озаглавили как гибкость. Нужно было быстро создавать новые либо менять имеющиеся обмены.
-
И «вишенкой на торте» стало отсутствие контроля состояния интеграций и необходимость ручной подготовки мониторинга. Нужен был механизм, способный в автоматическом режиме отслеживать, все ли выгружается корректно, фиксировать ошибки и всплески активности, предсказывать момент, когда объем данных превысит возможности системы. На эти вопросы должен был ответить автоматический и самоактуализирующийся мониторинг.
Решение проблем с помощью Kafka

Существенную часть этих проблем (3 из 7) мы смогли решить с помощью Kafka. В число решенных вопросов вошли:
-
Отказоустойчивость. Мы развернули Kafka в “трёхЦОДовом” кластере с SLA 99,999% и просто забыли про то, что обмены могут падать.
-
Гарантия и порядок доставки. В Kafka есть параметр – offset, его еще называют смещением. Это порядковый номер каждого сообщения, известный и Kafka, и приложению. Благодаря ему мы в любой момент можем точно понять, какие сообщения прочитали. И откуда нам читать заново, если в обмене произошел сбой. При необходимости можно даже перечитать сообщения немного загодя, чтобы быть уверенными. Плюс Kafka хранит сообщения на ту глубину, на которую мы не готовы терять данные. Например, если мы даем себе время простоя 4 часа, Kafka должна хранить сообщение больше, чем на 4 часа.
-
Самый важный плюс, который мы получили при внедрении Kafka – это маршрутизация. Простой пример: мы являемся мастер-системой по банковским платежкам. Когда бухгалтер отражает в системе событие оплаты, сообщение об этом уходит в Kafka. А дальше нам все равно, сколько систем его читает – две или двадцать, и каким образом. Никаких дублирующих точек входа. Мы просто публикуем сообщение о событии и на этом наша ответственность заканчивается.
Какие вопросы Kafka не решила?
-
Масштабируемость.
-
Гибкость.
-
Система мониторинга.
Частично была решена скорость.
Но из-за того, что вместе с внедрением Kafka мы перешли на событийный подход к интеграции, мы получили дополнительные проблемы, о которых я говорил. Простой пример: заказы к нам приходят из внешней системы, где по каждому клику менеджера в заказе создаются сообщения в Kafka – объем данных даже вырос.
И в целом прирост производительности заключался не в ускорении, а в том, что Kafka обрабатывает сообщения равномерно и непрерывно 24/7, что делает обмен более стабильным относительно стандартных подходов.
Подготовка 1С к высоконагруженным обменам
На этих предпосылках мы переходим к основной теме доклада: как же все-таки подготовить 1С к высоконагруженным обменам, используя событийный подход и Kafka.
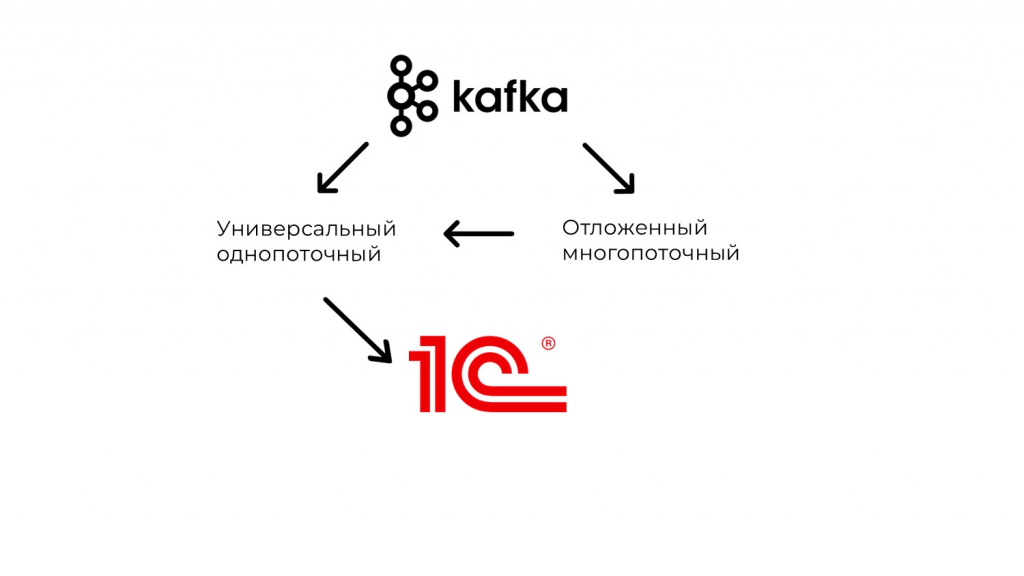
Первым делом мы разделили весь поток сообщений из Kafka на два типа:
-
универсальный однопоточный, который стал единой точкой входа всех обменов;
-
и отложенный многопоточный, в котором сообщения приходят в точку входа в обмен не сразу, а через какое-то время и уже будучи разделенными на потоки.
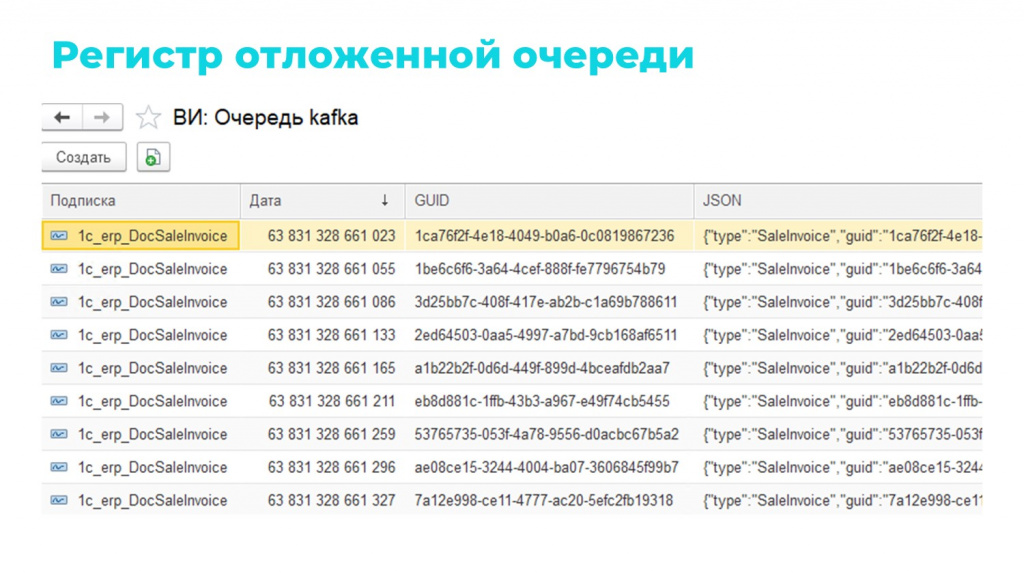
В отложенном многопоточном механизме основную роль играет отложенная очередь – простой регистр сведений, где для каждого сообщения хранится его подписка, уникальный идентификатор, дата и текст.
Сообщения, прежде чем отправиться в Kafka, без каких-либо проверок массово льются в этот регистр, а затем раскладываются по потокам с заданной для каждой подписки задержкой.
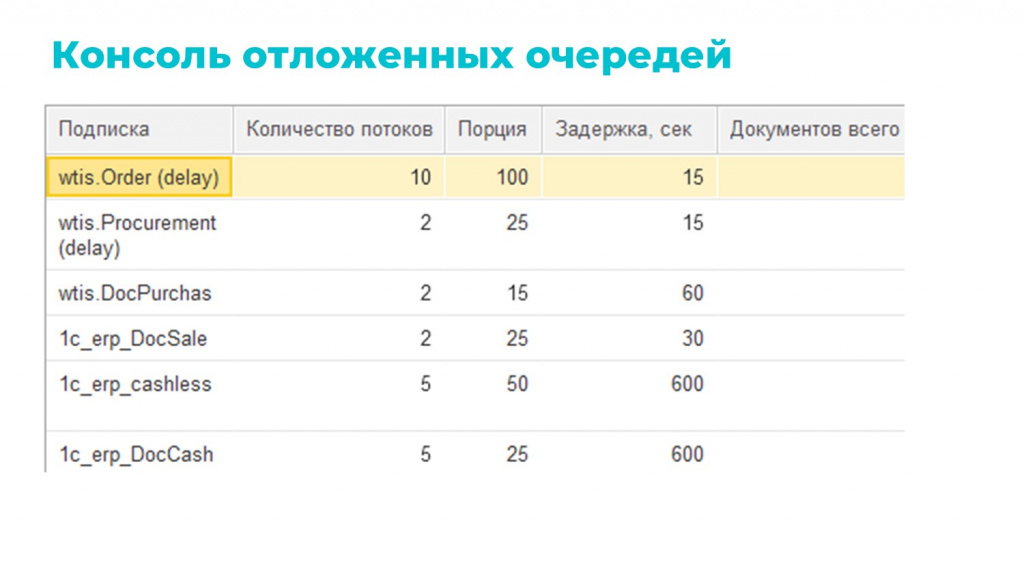
Настройки многопотока для конкретных подписок – количество потоков, размер порции, задержка (лаг) – мы вынесли в отдельную консоль. Это позволило нам гибко реагировать на всплески нагрузки и в целом на изменение конъюнктуры обмена.
Например, если данных вдруг стало лететь в 2–3 раза больше, мы можем просто увеличить количество потоков, изменить размер порций и уменьшить задержку. В итоге обмен не простаивает, данные обрабатываются, а у нас есть время разобраться, почему такое произошло – нормально это или ненормально.
Полезные советы для оптимизации использования событийного подхода
В ходе обкатки системы мы выделили 4 основных приема, которые значительно повысили производительность и стабильность.
-
Буферизация через замещение. Как я уже говорил, мы решили сначала загружать сообщения в регистр отложенной очереди, где при поступлении сообщения с тем же уникальным идентификатором, которое еще не было передано в рабочий поток, оно замещалось. Таким образом мы организовали своеобразную буферизацию, которая как раз решила проблему при работе менеджера с заказом – когда он накликал 20 изменений, а мы загружаем только последнее сохраненное состояние (то, что вписалось в лаг, в задержку). Понятно, что если все изменения в лаг не вписываются, мы загружаем заказ несколько раз, но это все равно меньше, чем количество кликов менеджера. Одно такое решение снизило объем входящих сообщений в 5-6 раз.
-
Проверка необходимости загрузки – похожее решение. Иногда дешевле проверить, изменился ли объект по ключевым реквизитам, чем обрабатывать его целиком. Пример: в CRM поменяли ответственного менеджера у контрагента, а для 1С это несущественно – если по ключевым реквизитам контрагент не изменился, мы не грузим это сообщение. Для очереди контрагентов это изменение позволило сократить объем обрабатываемых сообщений в 2-3 раза.
-
Непрерывное чтение и очередь ошибок – об этом я подробнее расскажу в следующем разделе.
-
Распределение потоков одним главным заданием и проверка существования сообщения – это тоже рассмотрим чуть позже.
Непрерывное чтение и очередь ошибок
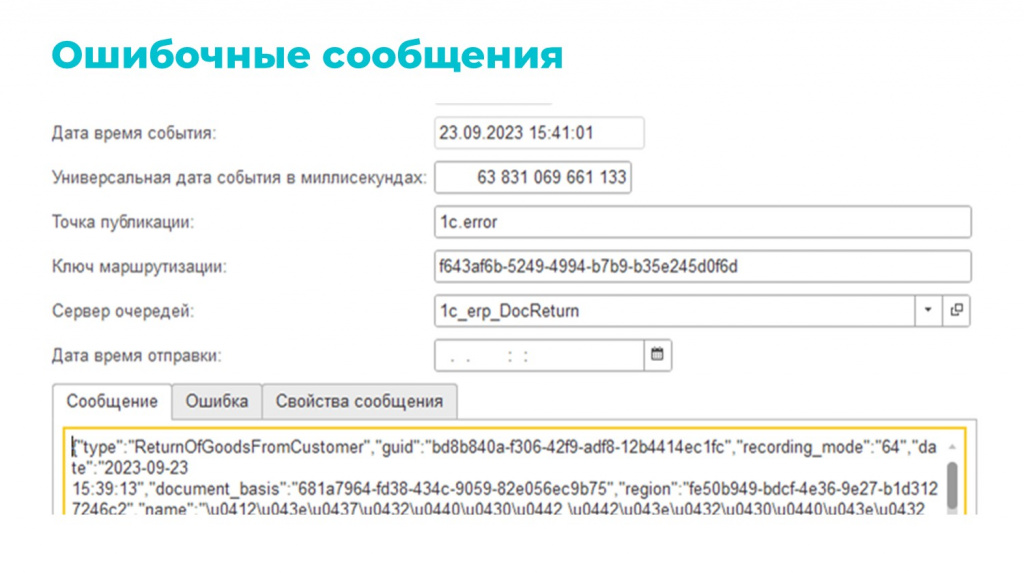
Типовой режим работы с очередью в Kafka – это чтение сообщений до ошибки. При возникновении ошибки чтение останавливается: сообщения начинают скапливаться, обмен отстает, а в техподдержку поступают жалобы – на вас, на обмен, на жизнь, на все.
Учитывая, что нас всего 22 человека, и все хотят спать по ночам, мы стали складывать ошибки в отдельный регистр ошибочных сообщений. При этом мы заметили, что около 80% случаев связаны с временным рассинхроном. Например: передается сообщение о заказе, а контрагент к этому моменту еще не загрузился. В итоге заказ падает в ошибку, но чуть позже контрагент появляется. Запустив регламент на повторные попытки обработки таких сообщений, мы добились того, что заказ догружался автоматически спустя небольшой промежуток времени.
Данное решение позволило избавиться от 80% ошибок. Оставшиеся 20% – это ошибки, которые будут всегда: кто-то накосячил, где-то неправильные данные, где-то что-то мы неправильно написали. Они будут всегда. И стопать из-за них чтение очереди не совсем корректно.
На наших объемах для каждой очереди осталось где-то 20-30 ошибок в месяц. Мы разбираем их постфактум, потому что они почти все требуют ручных изменений. Отправляем пользователям сообщение с пояснением, что нужно поправить. После исправлений данные догружаются без проблем.
Распределение потоков одним главным заданием и проверка существования сообщения
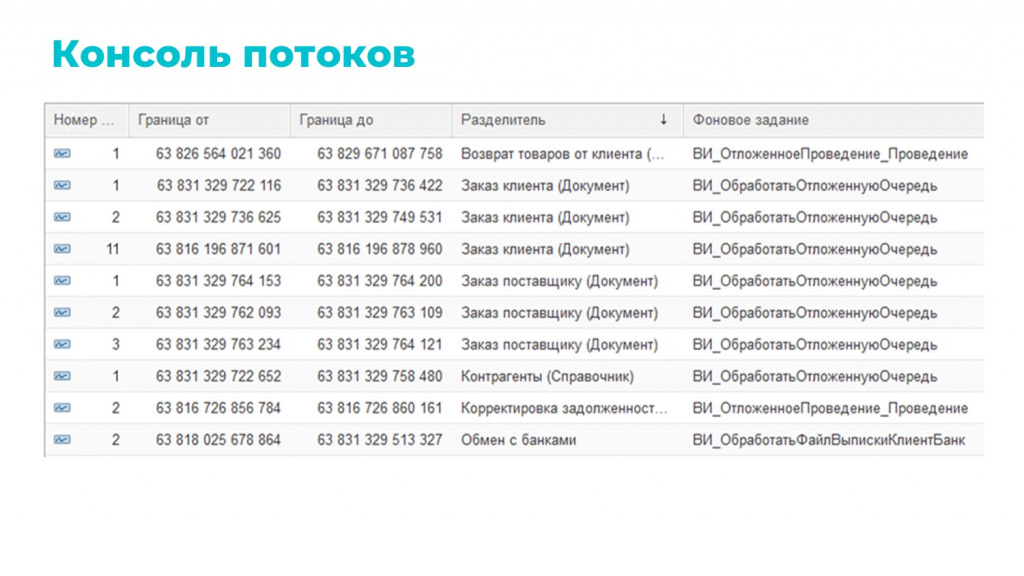
При работе в многопоточном режиме всегда есть риск дублей и блокировок. Чтобы подстраховаться, мы реализовали классическую схему:
-
Мастер-задание читает регистр и распределяет задачи между рабочими потоками.
-
Рабочие потоки не накладывают блокировок – единственная блокировка возникает на уровне мастер-задания в момент раздачи сообщений. Рабочие потоки просто передают данные.
Дополнительный лайфхак: если вспомнить, что сообщения могут заменяться более свежими версиями, рабочий поток дополнительно проверяет, не ждет ли новая версия сообщения своей очереди к обработке – тогда текущему потоку это сообщение обрабатывать не надо.
Правила обмена. Обработка входящих сообщений

Мы разобрались с входящим потоком обменов, научились гибко реагировать на возрастающую нагрузку и грамотно работать с ошибками, организовали буферизацию, проверяем, нужно ли грузить сообщение.
Переходим к обработке входящих сообщений.
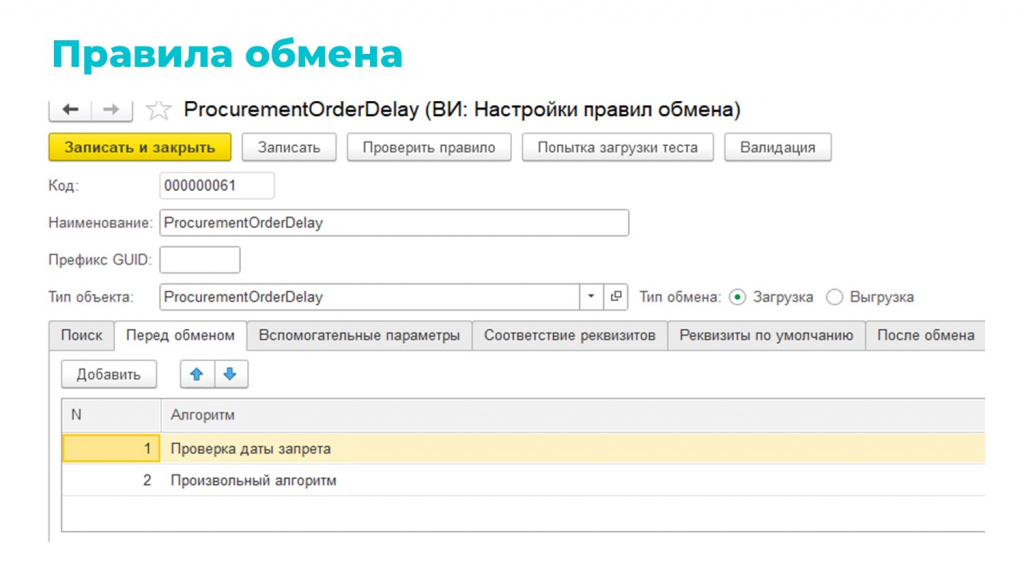
Для этой цели мы разработали систему настроек «Правила обмена». По сути, это доработанная идея «Конвертации данных», в которой есть два типа правил обмена – для загрузки и для выгрузки.
Вкладки здесь тоже имеют примерно такую же функциональность, как в «Конвертации». Например, для правила загрузки доступны вкладки:
-
«Поиск» – либо ищем, либо создаем, если не нашли.
-
«Перед обменом» – здесь мы можем указать алгоритмы для подготовительных действий и проверок.
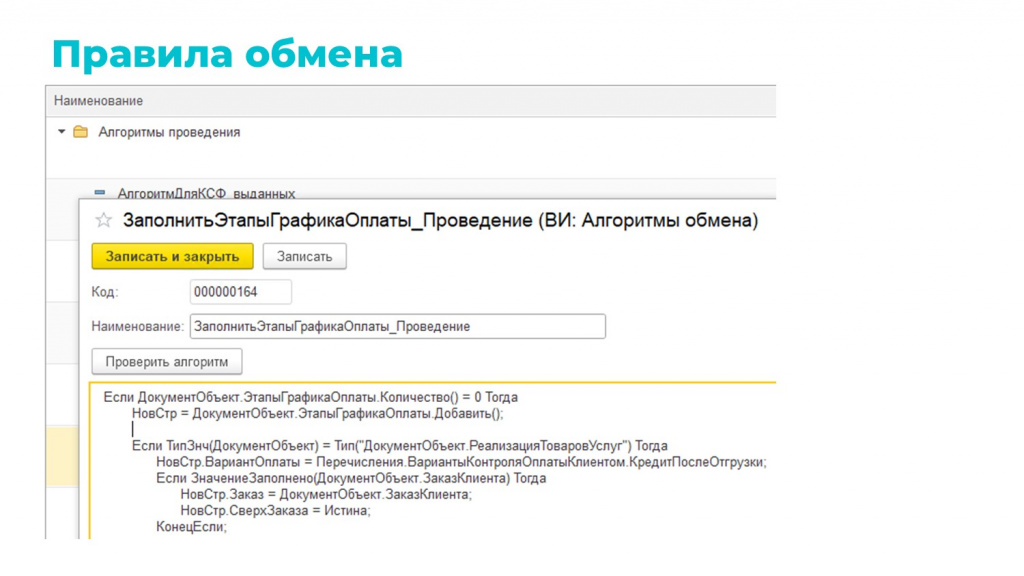
Алгоритмы, которые мы выбираем на вкладках «Перед обменом», «После обмена» и «После записи» – это основная логическая единица обмена. Они представляют собой просто строки кода, но для удобства каталогизации, переиспользования и выбора в правилах завернуты в справочник.
Когда правило обмена доходит до алгоритма, оно вытягивает из него эти строки кода и скармливает их методу «Выполнить()». Да, это не безопасно, но это супер универсально и супер удобно – на текущий момент дает больше профита, чем рисков.
Пробежимся по остальным вкладкам:
-
«Вспомогательные параметры» – переменные, которые доступны в контексте всего правила.
-
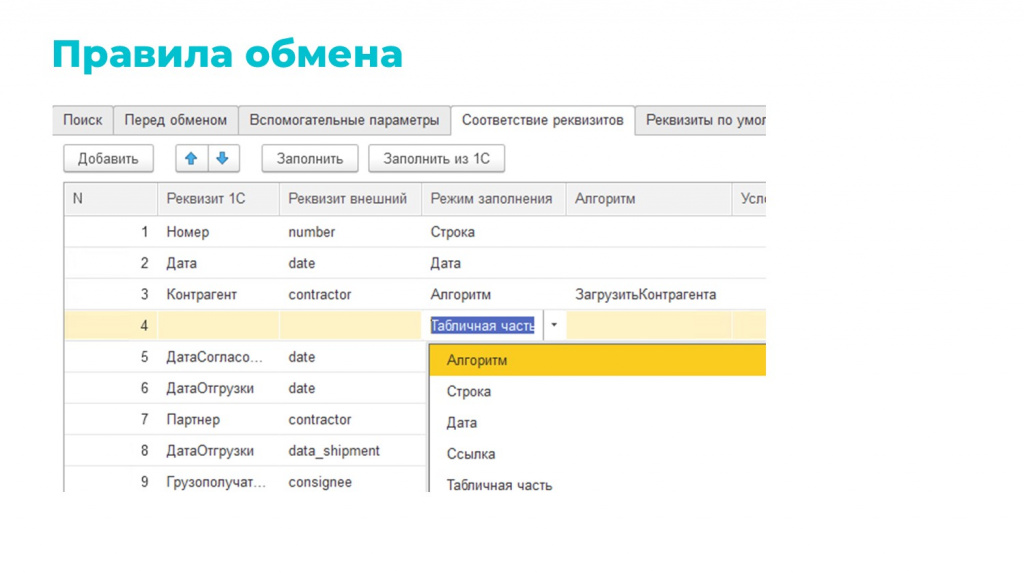
«Соответствие реквизитов» – то, как внешние реквизиты транслируются в реквизиты 1С.
-
Есть несколько режимов заполнения: «Строка» – это простое присвоение, «Дата» – это сериализация даты, «Алгоритм» – это то, что я ранее описывал.
-
Есть возможность работать с табличными частями. Там, естественно, все в цикле и ровно те же режимы заполнения.
-
-
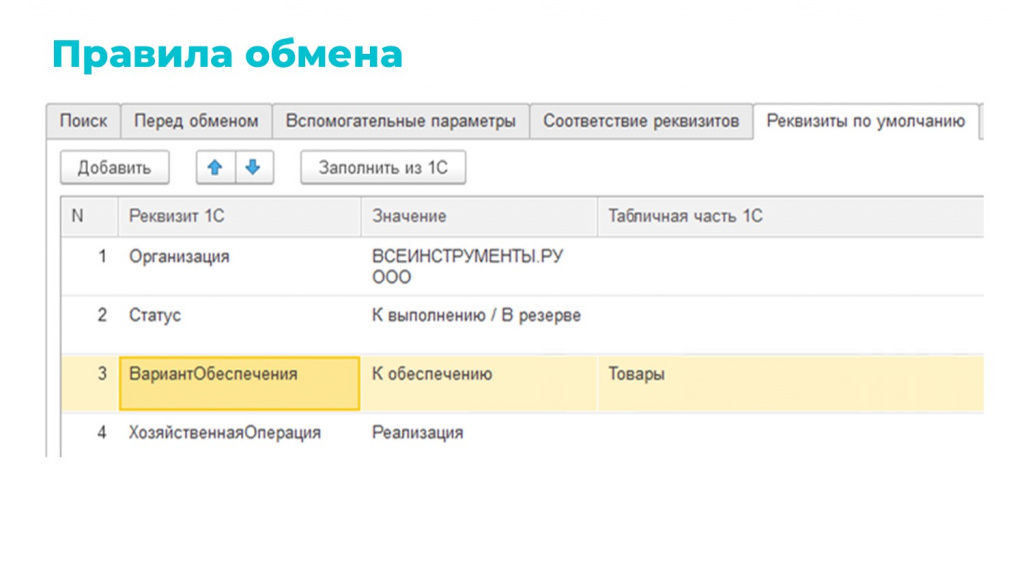
Моя любимая вкладка – «Реквизиты по умолчанию». Я как человек ленивый, не люблю, когда нужно искать значения реквизитов по коду, по наименованию либо писать для их установки алгоритм. На этой вкладке можно накликать значение из того, что у вас есть в базе. Например, можно выбрать конкретное значение организации, как на слайде. Это работает и для табличных частей – можно сразу проставить варианты обеспечения или единицы измерения и не писать для этого код.
-
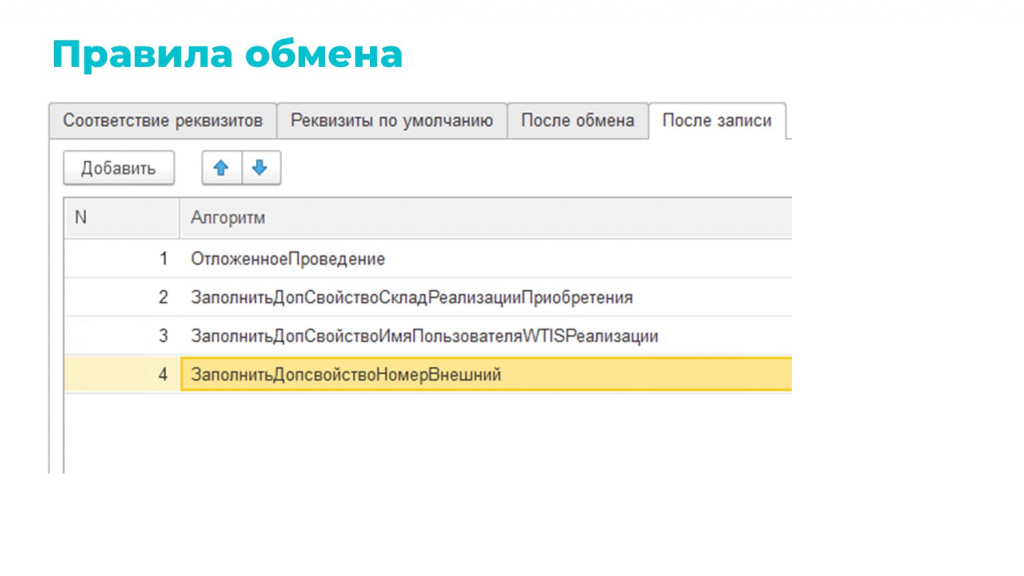
«После обмена» – доп. заполнения и доп. проверки после обработки, но до записи объекта
-
«После записи» – работа с уже записанным объектом (есть ссылка). Здесь можно вызвать разные алгоритмы по заполнению доп. свойств, по созданию дочерних объектов и пр.
-
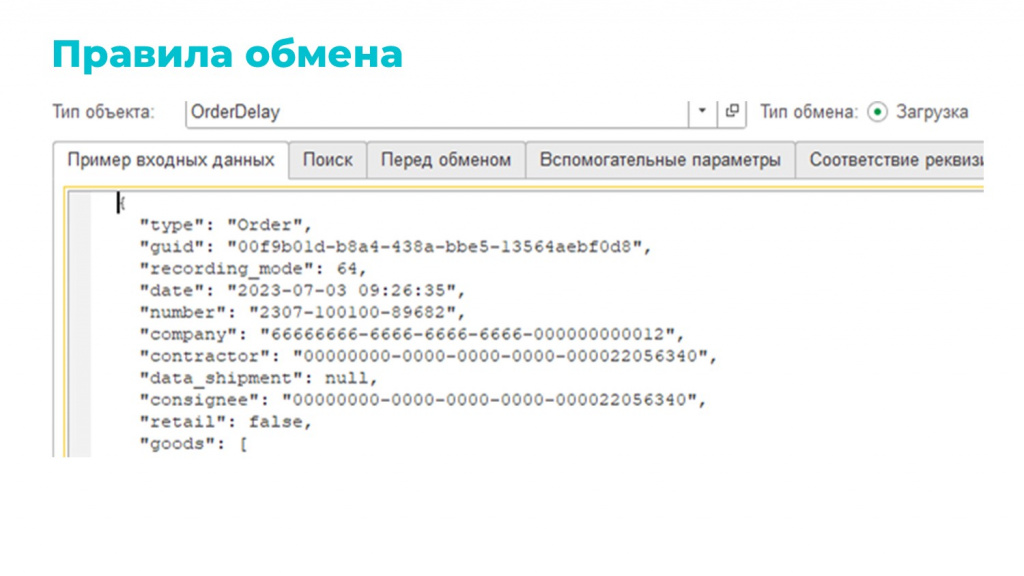
«Пример входных данных» – отладочная сервисная вкладка. Сюда можно вставить текст в формате JSON и прогнать через правило – это очень удобно для разработки или отладки.
-
Можно загружать в транзакции – тогда будет выведено уведомление, что обмен прошел успешно, но в базе никаких объектов создано не будет, все откатится как было.
-
Или можно загрузить как обычный обмен.
-
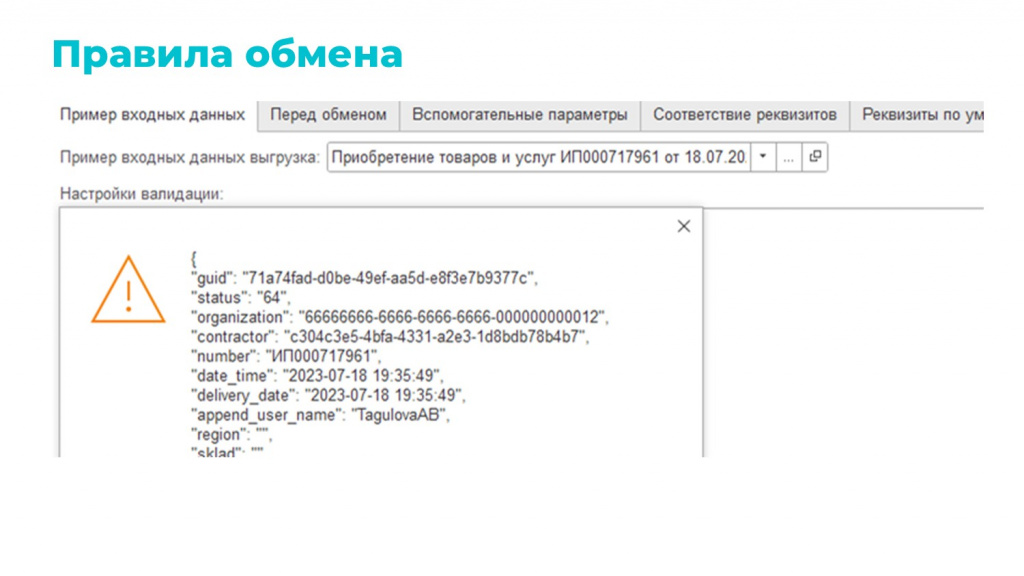
При выгрузке вкладок меньше, потому что выгрузка чуть проще – нужно просто сериализовать объект 1С в JSON.
-
На вкладке «Пример входных данных» у вас объект выгрузки. При успешной выгрузке выдается JSON, а в случае ошибки – ее описание.
-
И на остальных вкладках все наоборот – реквизиты 1С сериализуются в JSON.
Проведение и оптимизация

Мы научились гибко обрабатывать поток входящих сообщений и получили некий low-code инструмент для обработки входящих данных при обмене, которым могут пользоваться и аналитики, и программисты, может даже и руководители, как бы страшно мне от этого иногда ни было.
Но на этом процесс не заканчивается – все документы, которые мы загрузили и обработали, нужно провести.

Проведение, как правило – самая ресурсоемкая операция во всей транзакции обмена. Для нас было логично вынести ее в отдельный процесс. В итоге мы ее полностью изолировали и получилось, что за обменом мы следим отдельно, и за проведением тоже отдельно.
Внимательные читатели могли заметить, что слайд называется «Отложенная обработка» и есть вид обработки. На самом деле в какой-то момент нам так понравилось проведение, что мы добавили:
-
распроведение;
-
проведение и распроведение без даты запрета;
-
техническое проведение с повышенным приоритетом;
-
постобработки (например, для заказов), которые вообще не связаны с проведением.
Как и в многопоточности, здесь есть настройки: «Количество потоков», «Порция», которые можно менять на лету. Если случился резкий всплеск нагрузки или массовое перепроведение – просто увеличиваем параметры и система обрабатывает данные быстрее без значительного отставания.
Также здесь есть «Алгоритмы» – очень удобная возможность что-то сделать: либо до проведения, либо после.
Полезные советы для оптимизации проведения
Для обработки и проведения мы также выделили основные моменты, которые, возможно, будут полезны:
-
«Правила обмена» можно использовать не только для обмена Kafka и не только для обмена вообще. Например, у нас в совокупности с многопотоком происходит создание сотен тысяч счетов-фактур, и это очень удобно делать именно через правила обмена, хоть они так и называются.
-
Еще один лайфхак. Отложенное проведение можно использовать для оптимизации. Представьте – к вам приходит руководитель или заказчик и говорит: «Платежки в ERP проводятся пять секунд, а мне нужно, чтобы проводились за секунду». Можно оптимизировать код, но это долго и дорого. Мы пошли иначе: заменили стандартное проведение на отложенное. Для пользователя все выглядит так: он нажал «Провести и закрыть» и документ закрылся мгновенно, а проведение выполняется в фоне.
-
Всегда нужно помнить, что бесконтрольное увеличение потоков проведения не всегда дает положительный результат. Вы можете получить обратную ситуацию – чем больше потоков, тем меньше объектов успевает обработаться из-за ожиданий на блокировках. А узнать об этом можно только из анализа технологического журнала. Причем иногда при увеличении числа потоков обмена даже в ТЖ никаких проблем не видно и ресурсы вроде есть, но начинается деградация rphost – все операции в два раза медленнее. Не говоря уже про то, что могут происходить падения rphost, возникать неоптимальные траты ресурсов и так далее.
-
Мы долго пытались «лечить» эти проблемы оптимизацией – тратили на это много времени, но практически безрезультатно. Тогда мы пошли простым путем – просто изолировали фоновые задания на другие рабочие сервера. На одном из решений у нас сейчас, например, три рабочих сервера обслуживают клиентов и кластер, а пять работают только под фоновые задания. В результате клиенты никогда не чувствуют падение rphost, деградации и так далее – у них тихая, спокойная гавань. На серверах с фоновыми заданиями бывает разное, мы с этим разбираемся, но главное, что это не затрагивает пользователей, и у нас больше времени на реакцию.
Мониторинг

Мы научились ловить весь входящий поток сообщений, обрабатывать его и даже проводить. Теперь это нужно было полирнуть мониторингом.
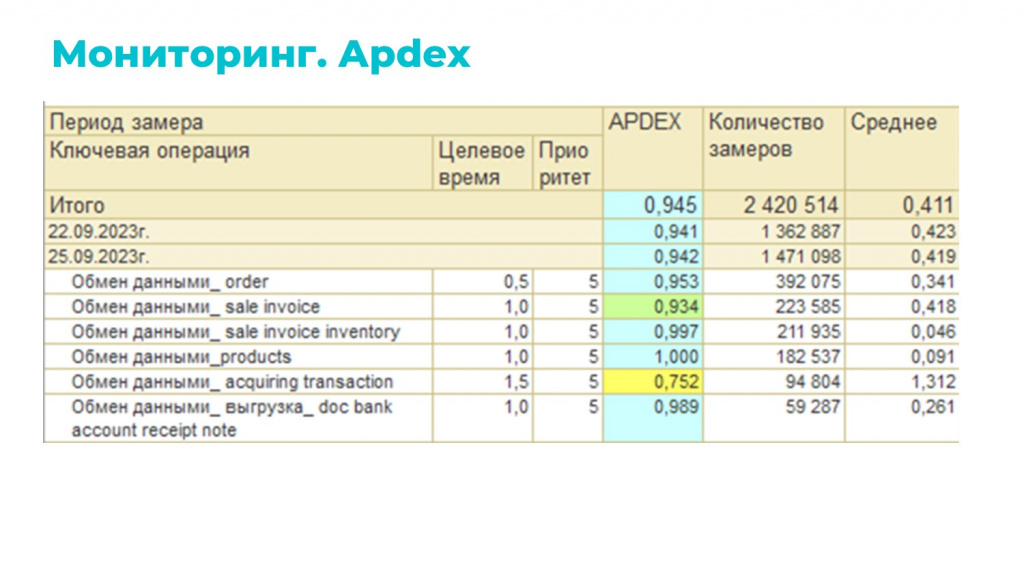
Мониторинг у нас построен на двух подходах: APDEX и Grafana.
APDEX. Есть единая универсальная точка входа, куда встроен замер. Программно добавляем типы операций и всегда имеем актуальный мониторинг. Если кто-то добавил новый обмен, я могу об этом даже не знать, но он автоматически отразится в этом мониторинге.
Выглядит примерно так, как на слайде. Используется в основном для подсчета количества операций и контроля скорости.
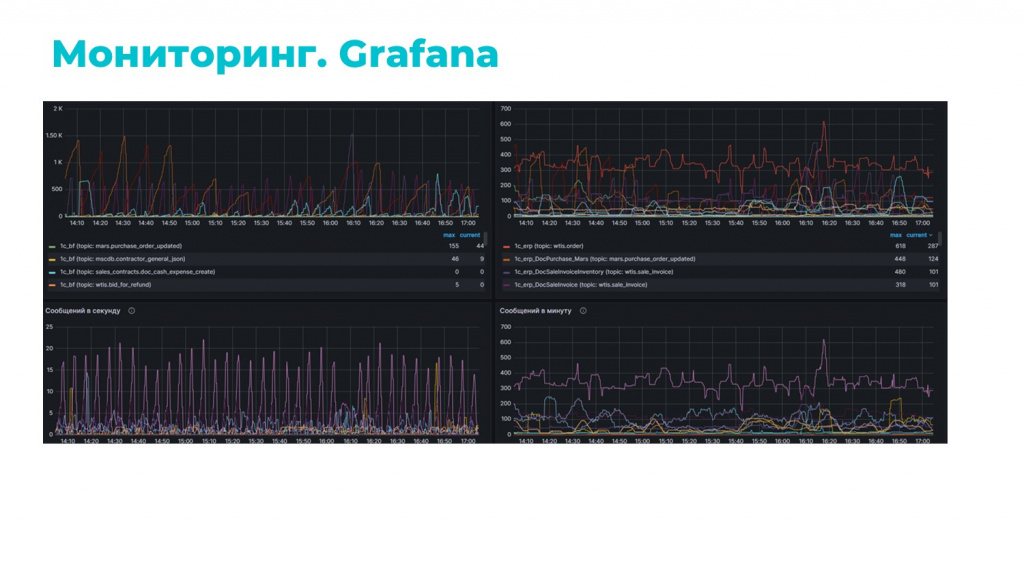
Вторая часть мониторинга построена на связке Prometheus + Grafana.
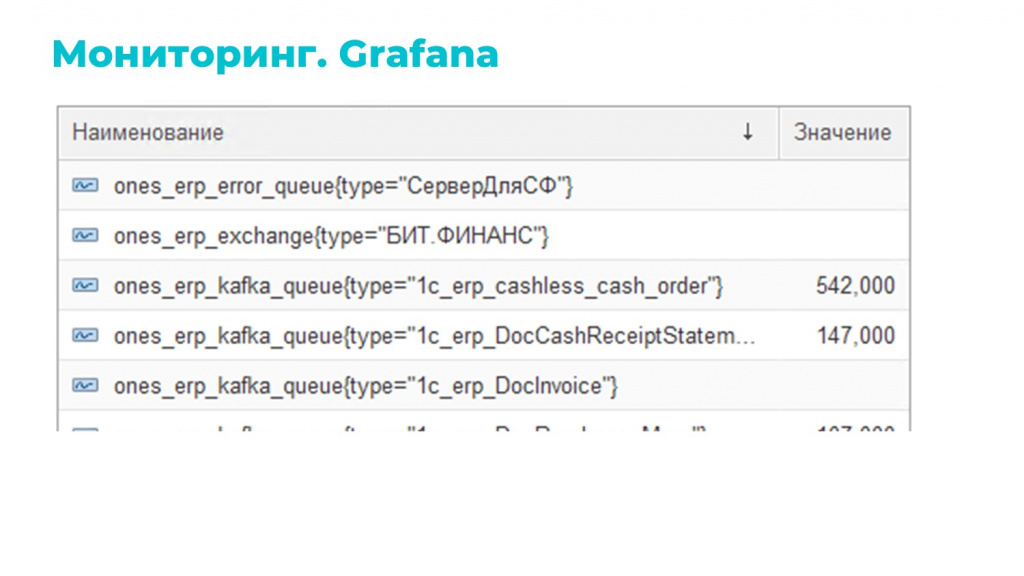
Здесь мы используем отдельный регистр, куда регламентным заданием собираем данные, которые хотим мониторить. Причем регламентное задание у нас настроено средствами БСП с помощью обычной внешней обработки – это тоже сделано для удобства, чтобы без обновления конфигурации на лету менять его логику.
Данными для мониторинга являются все те регистры, о которых я рассказывал: регистр отложенной очереди, регистр ошибочных сообщений, регистр обработки входящих сообщений и прочее.
Мы их агрегируем, группируем по нужным критериям и в итоге получаем самоактуализирующийся мониторинг, который подхватывает все изменения и отображает по ним проблемы.
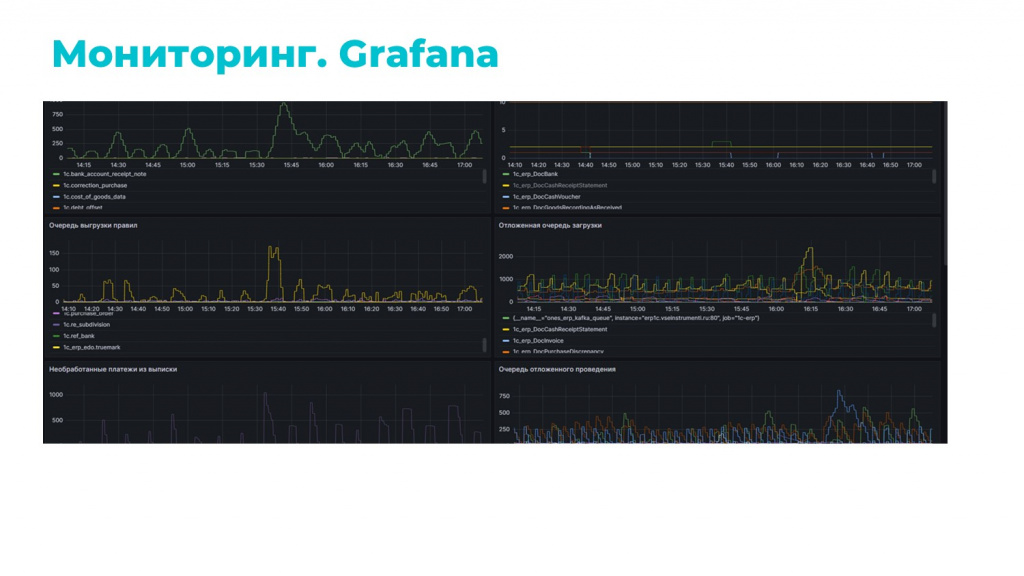
Выглядит этот мониторинг примерно так, как на слайде
Итоги
Итоги:
-
Проблему скорости мы решили за счет многопотока, Kafka и правильной работы с ошибками.
-
Масштабируемость мы получили за счет изоляции фоновых заданий и их горизонтального масштабирования на отдельные рабочие сервера.
-
В отказоустойчивости, гарантии доставки и маршрутизации нам помогла Kafka.
-
Гибкость нам дала наша подсистема настроек «Правила обмена».
-
А автоматический актуализирующийся мониторинг – заслуга правильной архитектуры и наглядных средств визуализации.
Надеюсь, что мой доклад вдохновит вас на создание подобной системы. Каждый из описанных подходов по отдельности несложен, а вместе они позволяют построить надежный и эффективный обмен, которым можно по-настоящему гордиться.

Переведите интеграции 1С на новый уровень
Реализуем устойчивый обмен данными между 1С и внешними системами — без сбоев и ручной рутины.
Вопросы и ответы
Насколько, на ваш взгляд, оправдан ваш подход как замена стандартного механизма РИБ? Имеет ли смысл отказаться от РИБ и рассматривать каждый объект как отдельное сообщение?
В моем понимании наш подход более стабильный – и именно это его основной плюс. Конечно, стандартные механизмы РИБ, обмены по COM или через файлы в формате «Конвертации данных» тоже можно применять и поддерживать, но на больших объемах, как показывает практика, стабильность критична. А типовые решения часто работают нестабильно.
Как при отложенном проведении быть с регистрами, которым нужна актуализация данных в момент проведения? Допустим, мы не можем провести реализацию, не проконтролировав остатки.
Согласен, отложенное проведение подходит не для всех случаев. Мы это используем, потому что у нас есть документы, которые приходят тысячами в день. Плюс мы не контролируем складские остатки в оперативном режиме, поэтому можем позволить себе такой подход. Но вы правы – универсальным его назвать нельзя.
Сама Kafka сколько потоков у вас читает – один или больше?
Пока в один. Kafka читает быстрее, чем 1С успевает обрабатывать даже в несколько потоков (прим. ред. в 2025 появились очереди в несколько десятков млн событий в сутки и появилось многопоточное чтение)
Используете ли вы Schema Registry для валидации данных?
Пробовали Avro Schema Registry, но не прижилось. Сейчас рассматриваем Protobuf, но пока ответственность за структуру данных лежит на конечных пользователях. Почему Avro не взлетела? Думаю, дело в частых коллизиях, которые оказалось проще решать через правила.
Как у вас организован запуск потоков?
Мастер-задание ставит блокировку на регистр отложенной очереди, получает из него порции по установленному в настройках количеству сообщений и рассчитывает границы порции через функцию ТекущаяУниверсальнаяДатаВМиллисекундах() – на слайде, где показана структура регистра, это видно. Дальше выдает информацию по границам отдельным рабочим потокам – поток получает запись, читает ее, проверяет, что она за это время не была изменена, обрабатывает и удаляет.
Мастер-поток постоянно отслеживает количество активных рабочих потоков, сравнивает его с количеством, установленным в настройках, и при необходимости стартует новые.
Вы убираете ошибки в отдельный регистр. Не случалось ли такого, что этот регистр начинал стремительно расти, потому что каждая ошибка плодила следующие? Насколько я знаю, это одна из причин, почему типовой обмен Kafka и вообще интеграция, построенная на событийном подходе, при ошибке останавливается, чтобы не плодить их каскадом.
У нас есть алерты на резкие всплески ошибок. Если фиксируется всплеск, мы останавливаем конкретный обмен и разбираемся. На этапе внедрения такие проблемы встречались часто, но сейчас по очереди за месяц набегает максимум 20-30 ошибок, т.е. с каскадным ростом мы уже давно не сталкивались.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт