Меня зовут Сергей Крайнев, я более 20 лет в ИТ, из них 10 лет – с платформой 1С. Последние пару лет занимаюсь тем, что имплементирую в процессы ИТ-департамента новые практики – тестирование, мониторинг, оптимизацию производительности и вообще DevOps.
Мы поговорим про многопоточность и другие способы ускорения тестирования на стеке Vanessa Automation. Забегая вперед, скажу, что все приемы, которые будут рассмотрены, позволили нам ускориться буквально на порядок.
Проблемы однопоточного тестирования и способы ускорения
Зачем нам нужно было ускорять тестирование:
-
Мы считаем, что тестирование – это неотъемлемый этап разработки. А поскольку наша цель – быстрее приносить ценность бизнесу, нам нужен более короткий цикл разработки.
-
Если задача не была протестирована, она не помещается в релизное хранилище и не попадает в прод.
-
У нас достаточно много тестов, и мы не всегда успеваем их прогнать в полном объеме. Чтобы не задерживать процесс, нужен способ прогонять их быстрее.
-
Иногда у нас перед релизом бывают срочные задачи, по которым нужен быстрый прогон. Если мы не ускорим этот процесс, нам придется либо рисковать и нести в прод непротестированную задачу, либо не включать такие задачи в релиз. Ни один, ни другой вариант нас не устраивает.
Какие способы ускорения существуют?
-
Можно использовать параллельный запуск тестов:
-
Реализовать много контуров прогона – через докеры, виртуалки и так далее. Мы об этом говорить не будем, у Валерия Дыкова был прекрасный доклад о том, как они работают с Yandex.Cloud, рекомендую посмотреть.
-
В Vanessa Automation можно настроить для тестирования много потоков – и далее я расскажу, как.
-
-
Можно оптимизировать процесс тестирования:
-
Есть способы существенно ускорить существующие этапы – мы их тоже сейчас рассмотрим.
-
Можно даже отказаться от некоторых ненужных тестов, как бы это странно ни звучало.
-
И тестировать не все и не всегда.
-
Расскажу, почему нас не устроило тестирование в один поток на одной базе. Казалось бы, если тестов немного, никаких проблем нет – можно запускать тестирование локально на своем компьютере.
Но когда количество тестов измеряется сотнями или тысячами, время прогона возрастает:
-
На одном контуре невозможно сделать больше нескольких прогонов в сутки. А нам надо больше.
-
Когда запуск содержит значительное количество сценариев, Vanessa Automation их не очень хорошо отрабатывает: долго грузит, долго прогоняет, долго формирует отчет. Проще настроить несколько отдельных запусков последовательно.
-
В конечном итоге мы все равно упираемся в постанализ. Если что-то упало, а у нас уже запущен следующий тест, разобраться в причинах падения сложно. В общем, плохо.
Можно тестировать все накопленные изменения ночными сборками – когда мы аккумулируем все изменения, а ночью прогоняем полное тестирование и утром смотрим результат. Но тут тоже есть риски:
-
Сложнее разобраться с результатами – если что-то упало, неочевидно, кто в этом виноват, и кому возвращать задачу на доработку.
-
Могут быть ломающие процесс обновления на серверах. Если инфраструктурщики согласованно или не очень что-то обновляют ночью, процесс может просто упасть. Тогда никакого результата утром может вообще не быть.
Проблемы многих потоков и параллельного тестирования на нескольких базах
Но и при выполнении тестирования в многопоточном режиме тоже есть проблемы:
-
Множество потоков подразумевает параллельность, а параллельность неизбежно ведет к росту нагрузки. Чем выше нагрузка, тем мощнее нужен сервер, а это расходы по инфраструктуре. Но есть и хорошая новость: если у вас есть недозагруженные серверы, вы сможете их задействовать.
-
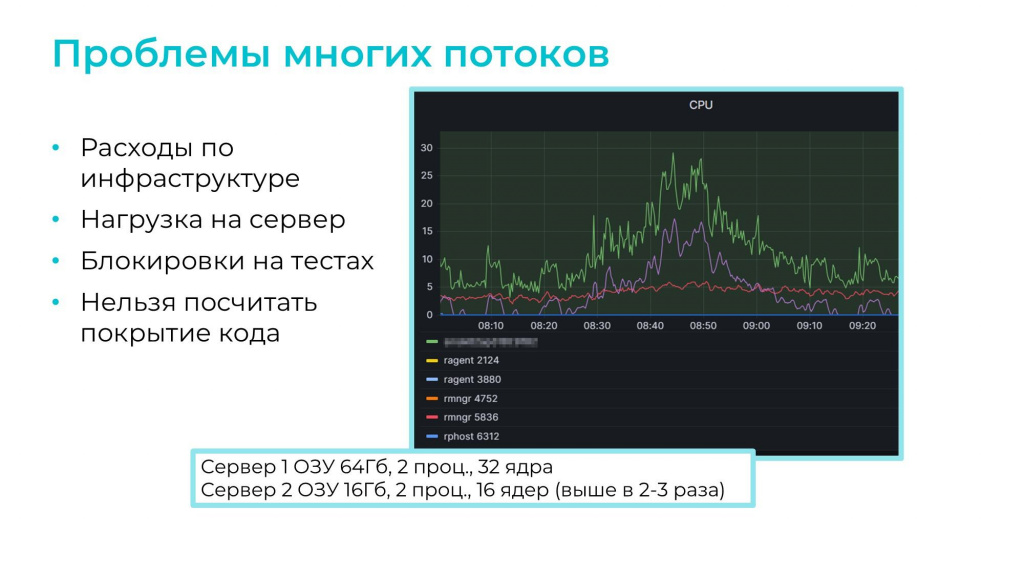
А нагрузка на сервер на самом деле значительная. На слайде показан график загрузки наших серверов:
-
у первого 64 гигабайта ОЗУ, 32 ядра и два процессора – в пике нагрузка на CPU занимает около 30%;
-
второй менее мощный сервер на 16 ядер – в пике нагрузка на CPU может доходить даже до 80%.
-
-
Еще один недостаток параллельности выполнения – блокировки на тестах.
-
И неявная проблема – нельзя посчитать покрытие кода. Мы используем для снятия покрытия утилиту Coverage41C, а она, к сожалению, может считать покрытие кода только в один поток.
Нужно понимать, что когда мы говорим про многопоточное тестирование, мы точно говорим про несколько баз. На одной базе много потоков не сделаешь – мы в любом случае упираемся в ограничения по блокировкам, поэтому у нас для многопоточного тестирования используется несколько баз.
-
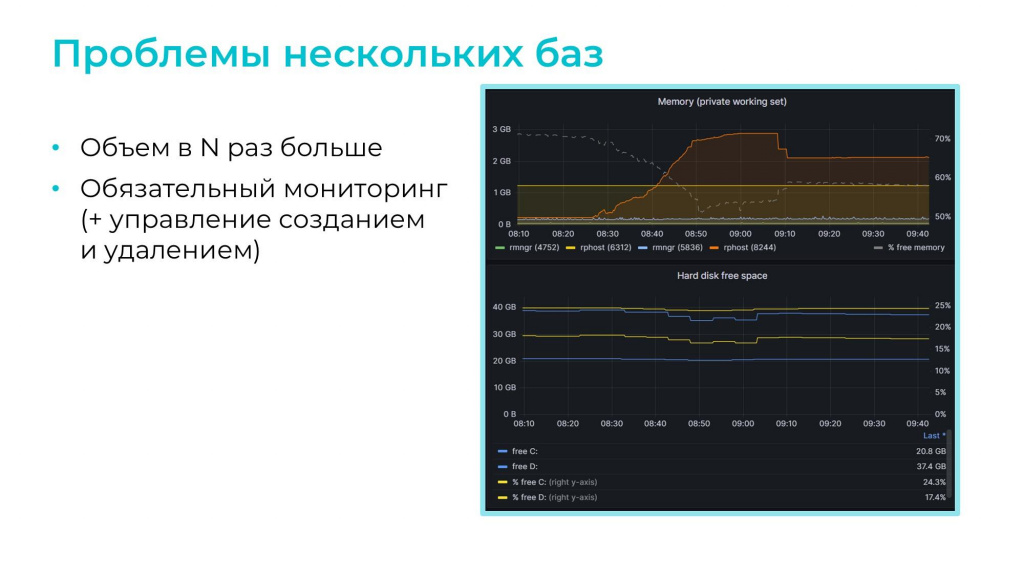
Поскольку мы разворачиваем для тестирования несколько баз, значит, общий объем занятой памяти и места на диске сразу становится в несколько раз больше. Насколько больше? Мы используем пустые базы с фикстурами, где на одну базу приходится 600-1200 МБ. Нас это устраивает.
-
Более того, мы не используем статические базы – мы создаем базы динамически при помощи пакетного режима конфигуратора, и через некоторое время удаляем их также динамически. Чтобы управлять созданием и удалением баз нам нужно мониторить количество занятой памяти и свободное место на диске, без контроля их оставлять опасно
Мониторинг и инфраструктура
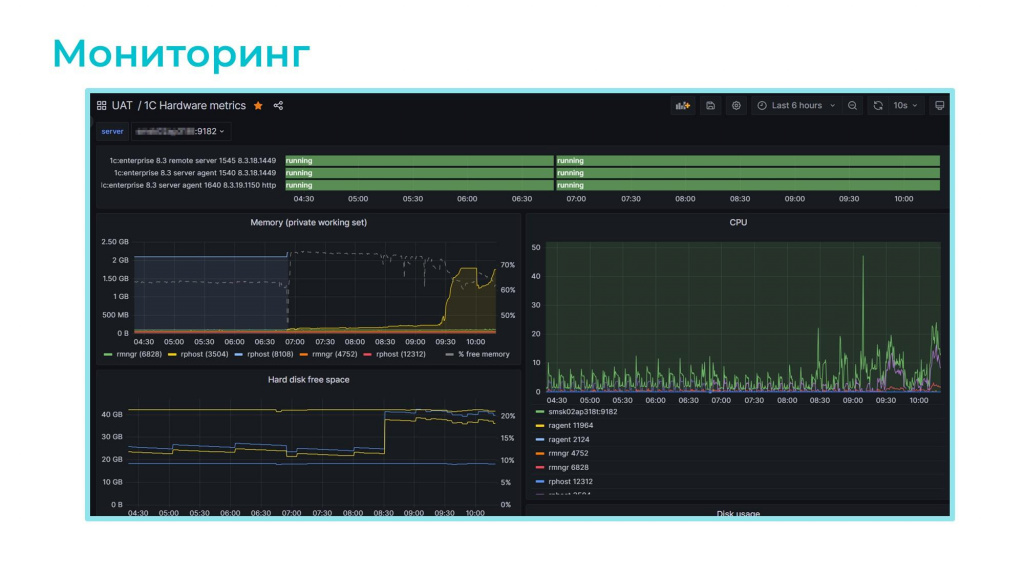
Мониторинг у нас организован с помощью Windows-экспортера, который выгружает метрики по железу в Prometheus, откуда данные попадают в Grafana и визуализируются в удобном дашборде.
Здесь можно отслеживать работу сервисов, загрузку CPU, расход оперативной памяти и, самое главное, свободное место на дисках.
В репозитории на Github можно скачать исходники этого дашборда и применить его у себя.
Для организации процесса тестирования мы используем следующее ПО:
-
Сервер сборок Jenkins и дополнительную ноду (еще один агент), чтобы у нас всегда было два потока – если один занят, может работать второй.
-
Два сервера приложений 1С, хотя на самом деле одного вполне достаточно. С их помощью мы динамически создаем базы под управлением MS SQL, делаем прогон и после этого разбираемся, что там было не так. Если что-то упало, то разработчик или тестировщик могут туда зайти, изучить ошибки, при необходимости запустить ручной прогон и разобраться в причинах. Через некоторое время такие базы удаляются по регламенту.
-
Сердце всей этой конструкции – скрипт powershell, «запускалка» для многопоточного прогона комплектов Vanessa Automation. Он стартует комплекты, делает ряд отчетов и в конце концов выгружает результаты в Allure/
-
Несмотря на то, что разработка ведется в хранилищах 1С, исходный код мы храним на сервере GitLab, потому что он позволяет интегрироваться с SonarQube для оценки качества кода. И туда же мы еще добавляем покрытие, которое собираем через Coverage41C.

Несколько слов о том, какие настройки Vanessa Automation могут повлиять на качество тестирования в многопоточном варианте.
В однопоточном варианте стабильность прогонов выше, и если у вас тест работал в однопоточном варианте, не факт, что он всегда будет хорошо работать многопоточно.
Иногда встречаются «мигающие» сценарии: в одной сборке они проходят, а в другой падают без видимой причины. Запускаем руками – опять все нормально. Непонятно.
К счастью, в версии 1.2.041.1 Vanessa Automation появилась опция повторного прогона сценариев, минимизирующая такие «мигающие» падения.
Стратегии ввода данных

Нельзя не сказать про выбор стратегии ввода данных. Существует два основных подхода:
-
Эталонная база (копия с прода). В этом варианте плюс только один: пока вы еще разбираетесь в тестировании, с него проще начать, потому что достаточно развернуть копию и сразу тестировать. Все остальное плохо: большой объем, хитросплетения зависимостей и длительные процессы реструктуризации при обновлении.
-
Пустая база с фикстурами. С этим вариантом начать сложнее, потому что каждый тест дополнительно должен подготовить под себя окружение, и приходится сначала разбираться, что ему нужно. С другой стороны, это позволяет контролировать актуальность тестов. Допустим, мы удалили реквизит в справочнике «Контрагенты» или наоборот, добавили новый и сделали его обязательным. Сценарий генерации данных в этом месте упадет, и сразу будет понятно, что его нужно актуализировать – это плюс. А еще в этом варианте получаются быстрый накат обновлений и меньше объемы – мы можем быстро заполнить базу, а потом загружать ее в другие через dt-ник.
Мы сразу стали использовать второй вариант. У нас используется «голый» cf, предварительно адаптированный для запуска. В него подгружаются начальные данные: данные по организации, курсы валют, рабочий календарь и прочее. После этого уже можно запускать сценарии.
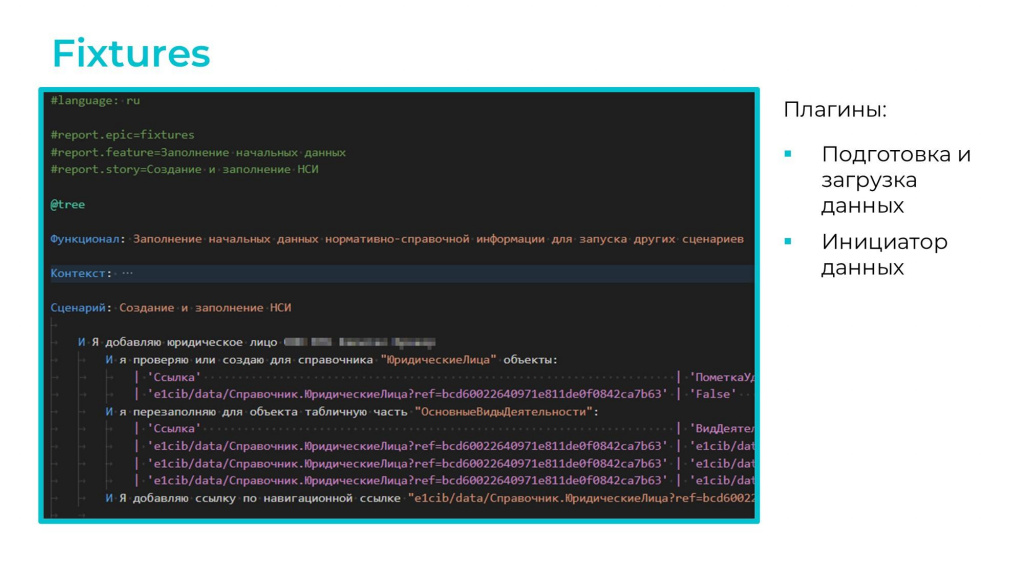
Что касается работы с фикстурами – мы вообще не используем для генерации данных макеты. У нас в качестве фикстур выступают те же самые фичи, которые мы получаем с помощью двух плагинов Vanessa Automation:
-
Подготовка и загрузка данных.
-
Инициатор данных.
Это дает возможность контролировать всю историю изменения фикстур в Git – отследить по коммитам, как они менялись, не открывая для этого конфигуратор.
Причем здесь же в заголовке с помощью директив
#report.epic=
#report.feature=
#report.story=
можно отнести эту фикстуру к конкретным эпику, истории, фиче – это помогает нам строить красивые отчеты в Allure.
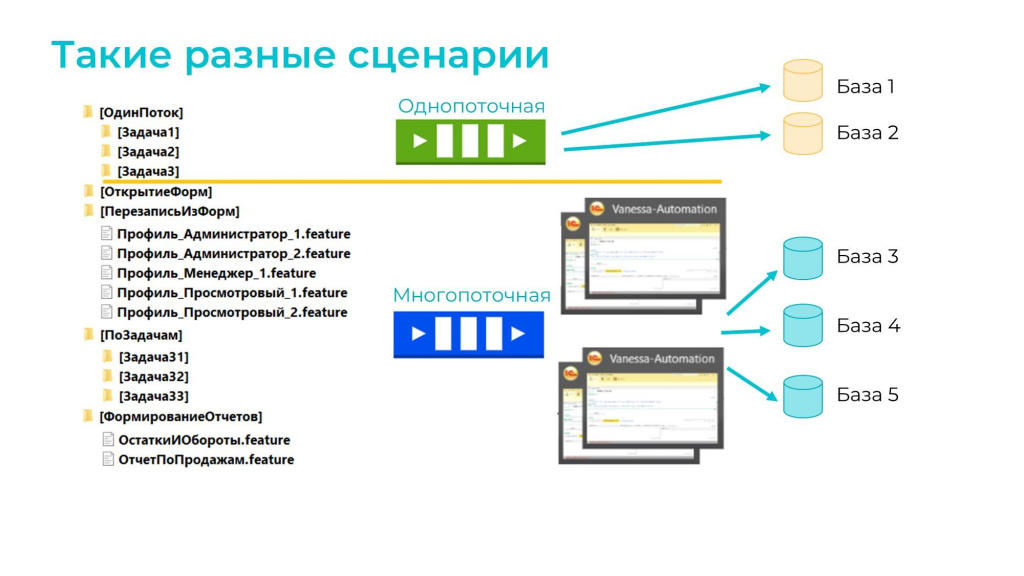
Тонкости многопоточного прогона. Как правильно запустить 1000 тестов
Допустим, мы решили перейти на многопоточность и создали 5 баз, на каждой из которых запускается по 5 потоков.
Казалось бы: 5x5=25, и мы сейчас поднимем скорость в 25 раз. Нет, так не получится. В худшем случае сервер просто погаснет от такой нагрузки. Если все-таки он выживет и запустится, то часть тестов просто упадет, а скорость вырастет всего в два-три раза. На это есть две причины:
-
Первая – блокировки.
-
А вторая причина – тесты могут друг другу мешать: первый тест подготовит для себя какие-то данные, написал что-то в регистр, а второй тест пришел и вычистил все оттуда. Первый приходит, а там уже ничего нет – возникает ошибка.
Чтобы этого избежать, тесты нужно сначала разделить на категории, каждая из которых запускается по разным правилам:
-
Длительные и многовариантные сценарии для тестирования бизнес-процессов, в которых мы создаем НСИ, запускаем регламентные задания, может быть где-то в середине делаем какие-то промежуточные сравнения и в конце сверяем это все с эталоном. Такие сценарии рассчитаны на 10-20 минут и могут закончиться ошибкой, если параллельно с их выполнением в базе будет работать кто-то еще. Их нельзя запускать в многопоток, поэтому мы их оставляем по-прежнему в один поток на одной базе – т.е. несмотря на нашу многопоточность, часть тестов мы все равно гоним в один поток.
-
Фичи открытия и перезаписи форм (почти дымовые тесты). Мы делаем эти тесты из-под определенных пользователей с определенным набором ролей: «Администратор», «Бухгалтер», «Менеджер» и так далее. Открываем и проверяем только то, что им доступно – ходим по вкладкам, чтобы проверить работу динамических списков, записываем и так далее. Такое совершенно спокойно параллелится, можно делать в многопоток.
-
Короткие сценарии, не требовательные к ресурсам. Например, когда надо сформировать отчет под пользователем – мы загружаем в регистр остатки, формируем отчет и сравниваем его с эталоном. Эту категорию сценариев тоже можно запускать в многопоток.
После того как мы определили, какие сценарии у нас должны выполняться однопоточно, а какие – многопоточно, разобрались с категориями и разложили сценарии в древовидную структуру каталогов, описываем все эти параметры в скрипте.
Скрипт распределяет задачи по очередям:
-
В однопоточную очередь (зеленую сверху) помещаются все сценарии, которые должны выполняться строго последовательно
-
В многопоточную очередь загружаются остальные тесты
И для каждой очереди скрипт начинает стартовать комплекты Vanessa Automation (комплект – это менеджер тестирования плюс клиент тестирования).
-
Скрипт на базе №1 стартует комплект №1 и отдает туда задачу №1.
-
На базе №2 стартует комплект №2 и отдает туда задачу №2.
-
Когда базы, назначенные для очереди, заканчиваются, скрипт ждет освобождения одной из них, и когда она освобождается, стартует на ней комплект №3 и отдает ему задачу №3.
Аналогично обрабатывается многопоточная очередь:
-
Скрипт по очереди обходит все базы и стартует на них комплекты с задачами по профилям пользователей.
-
На следующей итерации он проверяет количество свободных потоков и продолжает стартовать комплекты с задачами уже на них. Например, если у нас предусмотрено 5 потоков, а первый поток мы уже заняли одним из комплектов, остается четыре свободных – стартуем комплекты на них.
-
И так далее, пока не исчерпается количество потоков.
Баланс между количеством потоков, баз, скоростью и нагрузкой
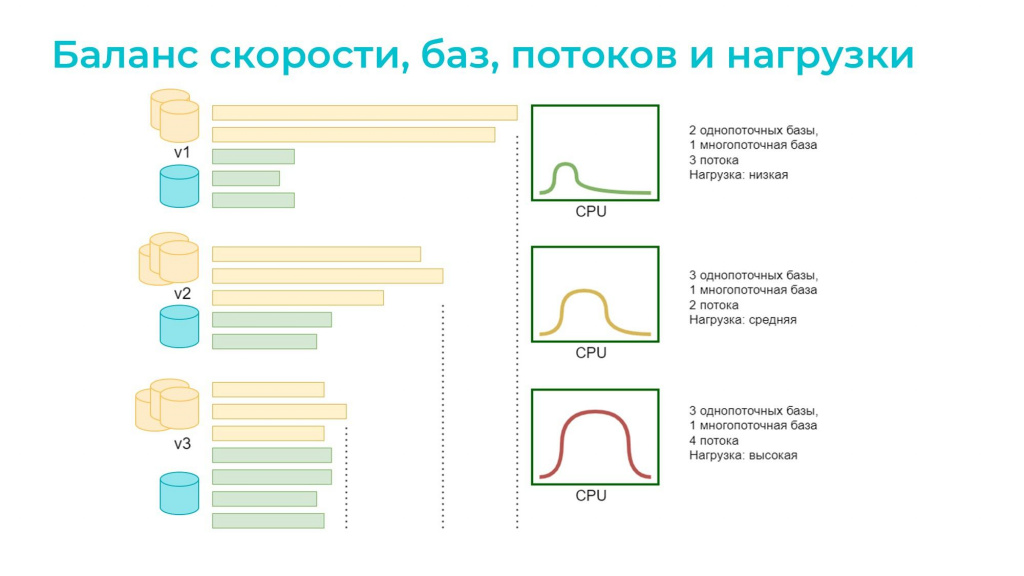
Чтобы понять, удалось ли что-то улучшить после распределения сценариев по категориям, мы анализируем результаты прогонов по временной диаграмме: видим, какие базы работали и как распределялась нагрузка.
-
В первом примере мы поделили сценарии вообще наугад – взяли две желтые однопоточные базы и одну зеленую многопоточную, где запустили три потока. На диаграмме видно, что зеленая база поработала и остановилась – дальше просто бездельничала, все остальное происходило на желтых базах. Нагрузка в зеленой зоне – есть куда улучшать.
-
Во втором варианте мы добавили еще одну однопоточную базу и немного уменьшили количество потоков для многопоточной базы. Смотрим результаты прогона – время выполнения сократилось. При этом нагрузка все еще в допустимой зоне – можно попробовать сделать еще быстрее.
-
Казалось бы, надо добавить баз, но мы можем пойти другим путем – переносим часть сценариев из однопоточного режима в многопоточный и немного увеличиваем число потоков в многопоточной базе. Если все будет хорошо, никто никому не будет мешать, значит можно и дальше продолжать так делать. Смотрим на временную диаграмму – отличный результат. Но неожиданно оказывается, что нагрузка, предположим, выросла до 90%. Это плохой вариант, потому что любая дополнительная нагрузка приведет к зависаниям и падениям тестов по таймауту. Поэтому такой красивый вариант опять придется разоптимизировать: добавить потоков и т.д.
В общем, это интересная задача на оптимизацию всех параметров: баз, потоков и контроля нагрузки.

На слайде показан реальный скриншот с реального проекта. Это та самая временная диаграмма, которую нам собирает со всех этих запусков Powershell-скрипт.
-
Наверху четыре однопоточных базы – их нагрузка тут показана голубым, оранжевым, розовым и желтым цветом.
-
Внизу – две многопоточные базы, в каждой из которых по 6 потоков. Они показаны зеленым и бирюзовым цветом.
Видим, что нагрузка используется достаточно хорошо.
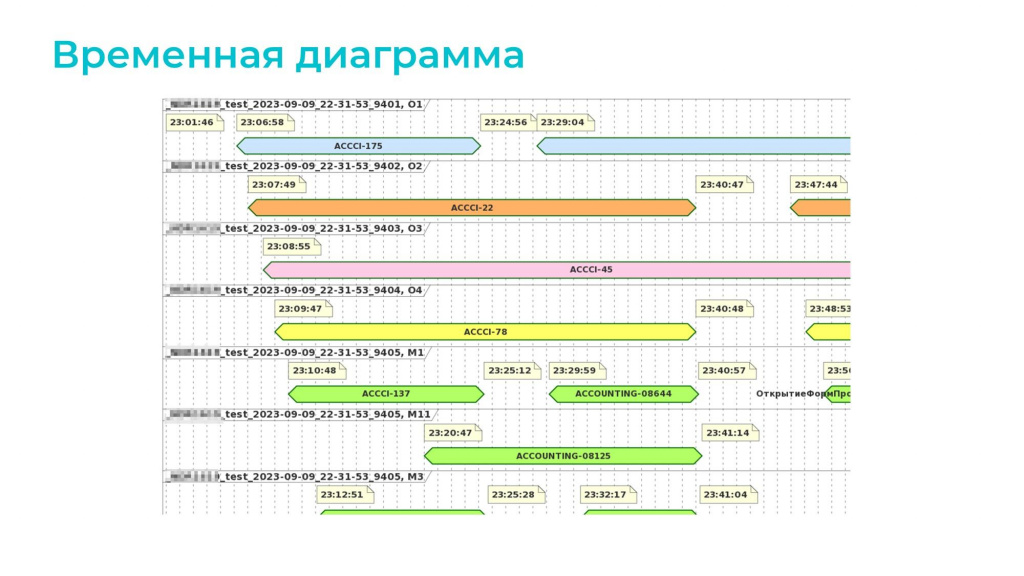
Если увеличить детализацию, можно увидеть, как выполняются отдельные сценарии. Это тоже помогает при разборе проблем: если тест упал, можно увидеть, что происходило до этого и выяснить, не мешал ли ему другой процесс
Обратите внимание на «лесенку» на диаграмме: голубая база запускается первой, оранжевая – второй, розовая – третьей так далее. Это сделано специально – если мы запустим все потоки одновременно, то сервер и клиент тестирования просто встанут. Скрипт это учитывает и добавляет небольшую задержку между запусками.
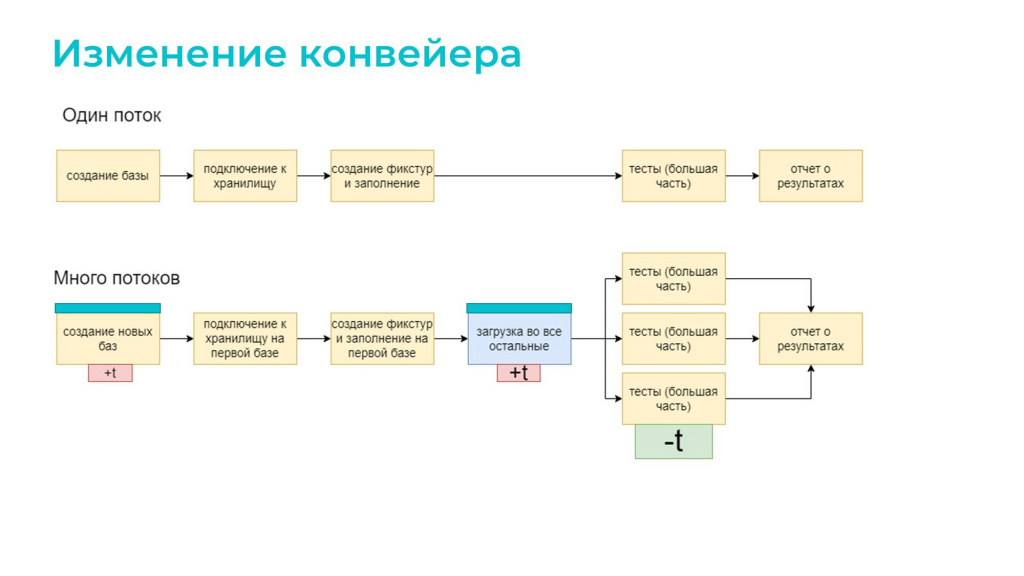
Казалось бы, при переходе к многопоточному режиму мы должны были многое изменить в нашем конвейере, но на самом деле практически ничего не изменилось – мы просто добавили блок подготовки баз.
Т.е. на этапе создания баз и фикстур мы сначала все заполняем в первой базе (у нас изначально 6 баз, а заполняем мы только в одной), а в остальные пять просто загружаем dt-шник. Это реально быстро. Причем мы это делаем параллельно: загрузка dt-файла занимает максимум минуту.
Оптимизация. Быстрые тесты
После внедрения многопоточности мы действительно получили некоторое ускорение, но было ощущение, что этого недостаточно. Стали думать, как еще улучшить.
Вспомнили, что в сценариях Vanessa Automation можно проставлять теги. Например, если я разрабатываю определенные бухгалтерские отчеты, я могу разметить свои тесты определенным тегом, и при доработке этой функциональности запускать только эту часть тестов с отчетами, а остальное – не запускать. Но здесь есть проблемы.
-
Деление тестов по тегам нельзя делать слишком крупным или слишком мелким.
-
Про эти теги нужно всем рассказать: разработчики должны договориться о принципах – что именно им запускать по своей задаче. Потому что разработчики не всегда ограничиваются только изменением отчета: правки могут затрагивать движения, обработки и другие объекты. В общем, получается довольно сложно.
Мы решили пойти по другому пути и просто из наших тысяч тестов сделали выжимку, куда надергали только самые критичные проверки:
-
Сценарии открытия и перезаписи форм – в быстром варианте мы проверяем только два профиля: «Полные права» и «Только просмотр».
-
Тесты на неважную функциональность из быстрого варианта убрали.
-
Из многовариантных сценариев оставили только два обязательных, чтобы пройти только основную ветку бизнес-процесса.
Наша задача была – получить максимум покрытия тестами при минимуме их количества.

Назвали это «быстрыми тестами» и договорились обозначать их тегом @fast. В итоге:
-
количество тестов по каждому из продуктов уменьшилось в 2-3 раза;
-
при этом качество тестирования осталось на уровне 90%. Это значит, что из 10 потенциальных ошибок 9 выявляются быстрыми тестами, а последняя 10-я «добирается» при полном прогоне.
Преимущества многопоточного прогона
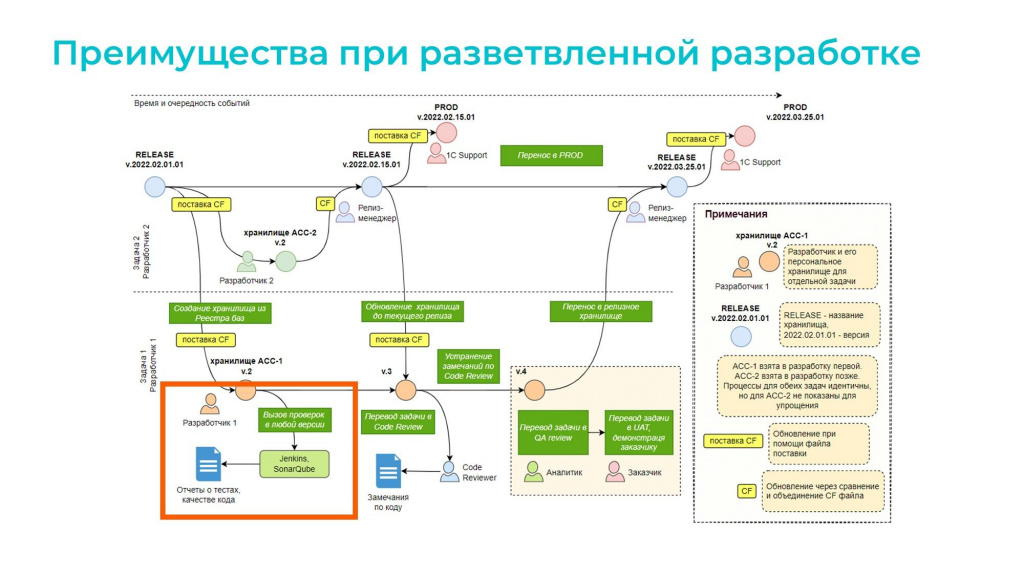
Как это работает для разработчиков? На конференции Infostart Event 2022 Saint Petersburg я рассказывал, как мы используем технологию разветвленной разработки для хранилищ.
У нас каждая задача имеет свое собственное хранилище, где разработчик может делать, что хочет – в том числе запускать тесты.
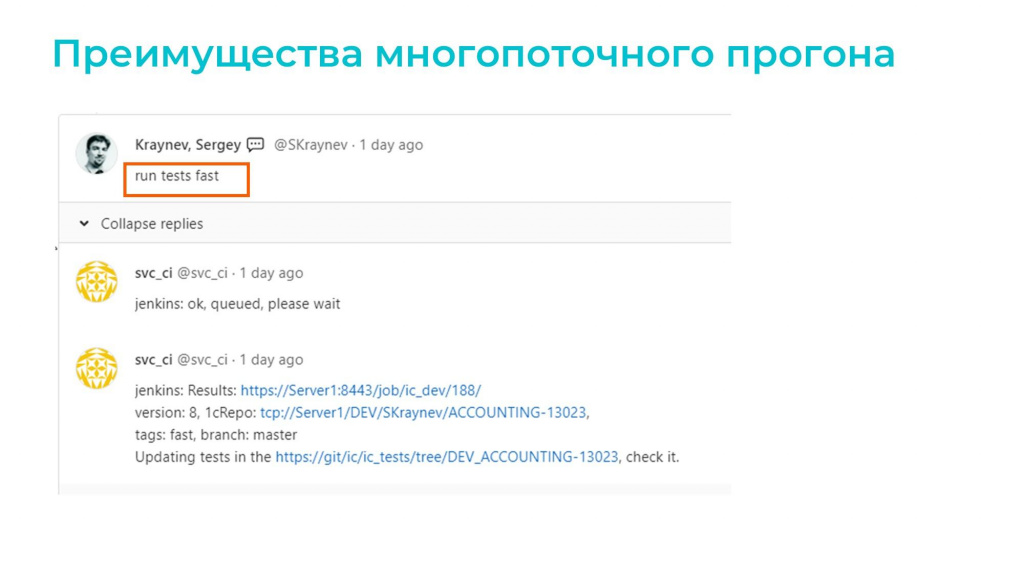
Для этого ему достаточно в merge request, который связан с этим хранилищем, добавить комментарий
run tests fast
что означает «запустить тесты с тегом fast».
Jenkins обрабатывает этот комментарий, делает прогон и возвращает результаты прямо в merge-реквест.

При этом разработчик не ограничен только быстрыми тестами, он может запустить:
-
run tests – полный набор тестирования;
-
run tests -branch ACCCI-109 – тесты из конкретной соседней ветки. Например, я знаю, что после моих изменений тесты у другого разработчика развалятся. Я могу дать ему доработанный набор тестов из своей ветки, чтобы он их у себя прогнал.
Таким образом разработчики могут в любой момент проверить свой код и убедиться, что их изменения не ломают систему.
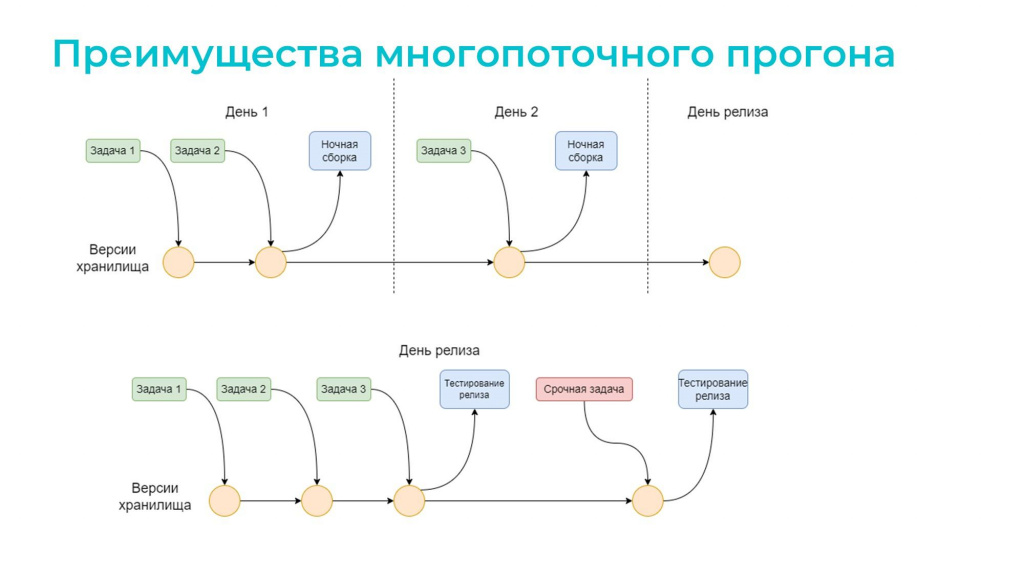
Теперь о выпуске релизов – мы их выпускаем раз в неделю.
-
Если неделя спокойная, задачи начинают попадать в релизное хранилище уже с первых дней.
-
Например, в понедельник положили первые две задачи. Они «зеленые», потому что быстрые тесты по ним уже прошли, и есть 90% уверенности в их корректности.
-
Вечером запускается ночная сборка, утром мы получаем результат. Если все хорошо – двигаемся дальше. Если нет – исправляем функциональность или дорабатываем тесты. Времени достаточно.
-
На следующий день добавляем новые задачи, снова ночная сборка и так до конца недели.
-
К пятнице может сложиться ситуация, что все задачи уже проверены и «зеленые» – релиз можно выпускать без дополнительных тестов.
-
-
Но бывает и по-другому: сборка может происходить в один день.
-
Тогда мы в первой половине дня складываем задачи в релизное хранилище, а вечером прогоняем полный набор тестов. Если все успешно – готовимся к релизу.
-
А еще часто бывает, что кто-то неожиданно прибегает и говорит: «Срочно несем в прод еще вот эту задачу! Бизнес очень хочет!»
Если бы у нас был только однопоточный прогон, мы бы ничего не успели – опять была бы дилемма: либо не нести эту функциональность в релиз, что плохо, либо нести и бояться, что тоже нехорошо. Поэтому «красная» задача такая не потому, что она срочная. «Красная» она потому, что по ней вообще не было тестов.
А с многопоточным тестированием мы успеваем прогнать не только быстрые, но и полные тесты еще раз, и успеваем к релизу.
-
Скорость и производительность

И, наконец, про скорость. На слайде результаты прогонов для двух наших продуктов:
-
Большая конфигурация на 660К строк – это верхний график.
-
И маленькая конфигурация на 220К строк – это нижний график.
Сравнение времени прогонов:
-
Синяя плашка – это прогон в один поток. Тестирование в один поток мы все равно раз в неделю используем, чтобы узнать новое значение процента покрытия при изменении конфигурации и тестов. Полный комплект тестов (сейчас это 6900+ штук) в один поток прогоняется 16 часов.
-
В многопоточном режиме полный прогон тестов для большой конфигурации занимает два часа.
-
А быстрый прогон – самая маленькая полоска – 50-56 минут.
На маленькой конфигурации примерно так же.
На этом можно было бы уже и остановиться, но мы решили искать новые пути оптимизации.
Стали думать, что еще можно улучшить.
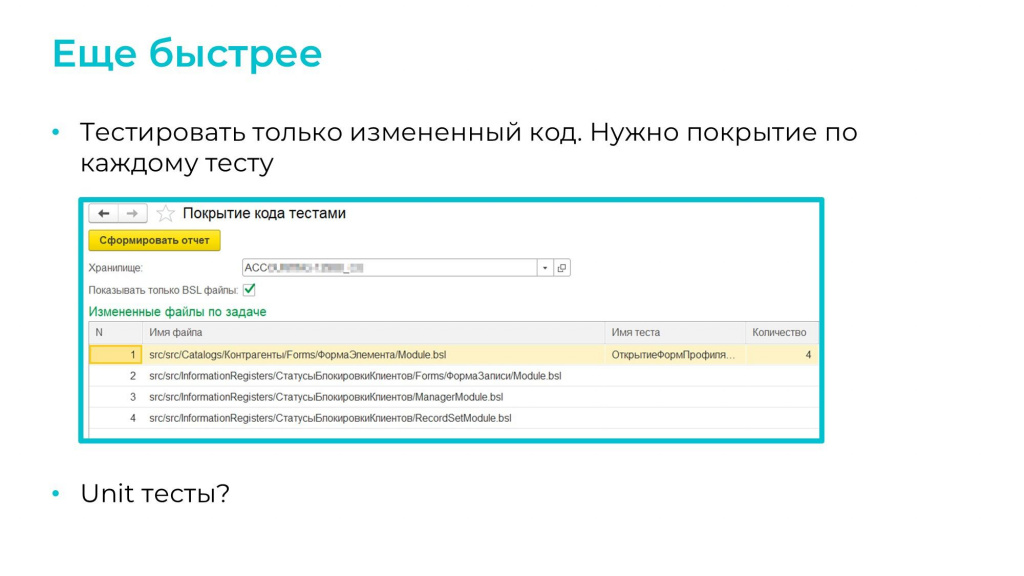
Возникла идея тестировать только измененный код. А для этого нам нужно понимать, какие тесты покрывают эту функциональность, т.е. нам нужно покрытие по каждому тесту.
Казалось бы, это легко можно сделать: запускаем первый тест, снимаем покрытие с помощью Coverage41C – сохраняем в первый файл. Потом запускаем второй тест – сохраняем во второй файл, и так далее.
Собираем результаты прогона, где с одной стороны у нас – все файлы покрытия, а с другой стороны – измененные файлы. Теперь нам остается по номерам строк это сматчить.
Все бы хорошо, но так не работает. Потому что существующие файлы покрытия сняты на релизном хранилище, а хранилище-то уже уехало, и если кто-то сдвинулся по коду, то мы ничего не получим.
Наверное, можно по хэшам все это сматчить, но бывают вынужденные случаи, когда разработчик берет и полмодуля обработки перемещает куда-нибудь в общий модуль – и все, все разъехалось.
Поэтому пока просто используем простой отчет, который показывает, были ли вообще тесты по этим файлам.
Можете сказать: «У вас больше 6900 тестов, это 100%-ное покрытие?» Нет, у нас покрыто всего лишь 16% кода. Т.е. для некоторых модулей может быть четыре теста (как на скриншоте), а может быть ноль тестов. В этом случае при изменении этого модуля имеющиеся тесты запускать бесполезно – они ничего не покажут. Даже если ошибки были, мы о них не узнаем.
Другой способ ускорения – это переход к модульным Unit-тестам. Над этим тоже пока думаем.
Многопоточность – это не сложно
Выводы:
-
Многопоточность реально ускоряет процесс тестирования. Мы без нее уже просто не живем, один поток нас уже не устраивает.
-
Я уверен, что эту схему можно внедрить в любой конвейер. Это не сложно.
-
И в этой схеме всегда есть возможность что-то улучшить и оптимизировать. Я уверен, что при желании это получится.
И полезные материалы:
-
https://github.com/git22ura/is2023 – наш скрипт-запускалка на Powershell. Там же лежит дашборд для Grafana и настройки для Windows-exporter, которые позволяют посмотреть, как обстоят дела с вашими процессами rphost, rpmngr и т.д.
-
https://github.com/1c-syntax/Coverage41C и https://github.com/Pr-Mex/vanessa-automation – ссылки благодарности. Хочу сказать спасибо большое авторам Vanessa Automation и Coverage41C за создание и поддержку таких классных проектов.
Вопросы и ответы
Почему вы переносите подготовленные данные на тестовые базы через выгрузку-загрузку dt? В чем проблема делать это средствами SQL?
Мы сначала подключаем первую базу к хранилищу, накатываем туда нашу конфигурацию, далее прогоняем сценарии для первоначального заполнения. После этого выгружаем подготовленные данные в dt-файл, который загружаем в остальные тестовые базы.
Так исторически сложилось, но да, наверное, можно улучшить.
Вы показывали форму, которая позволяет определить, покрыт ли модуль тестами, чтобы тестировать только измененный код. Что это за форма, и зачем она нужна?
У нас в отдельном репозитории лежат файлы покрытия по каждому тесту, полученные через Coverage41C. Дальше мы просто сравниваем эти файлы с измененными в данном коммите модулями.
Пока мы знаем только – были ли на этот модуль тесты ранее, чтобы понять, имеет ли смысл запускать тестирование или сначала нужно написать на эту функциональность тест.
Но вообще была идея определять, какие тесты отвечают за измененные объекты и запускать только их. Но это не всегда будет правильно, поэтому мы запускаем просто быстрое тестирование на каждый коммит.
Сколько времени занимает сбор покрытия на все 6900+ тестов?
Сбор покрытия входит в тот однопоточный прогон на 16 часов, который мы запускаем раз в неделю при обновлении тестов. Все тесты запускаются последовательно и по результатам выполнения каждого теста сохраняются отдельные файлы покрытия. Т.е. чтобы собрать покрытие, нужно прогнать все тесты, а в однопоточном режиме это занимает 16 часов. Мы этот прогон используем только для сбора покрытия. Обычно мы используем быстрый или полный прогон.
Как вы заполняете фикстуры, если нужно проверить отчеты? Вы под них заполняете регистры полностью – перетягиваете их из рабочей базы, или только частично?
Все это происходит внутри самой фичи. Мы для конкретного кейса заполняем только то, что ему нужно.
Часть фикстур заполняется сразу при создании базы?
Да. Это те вещи, которые будут нужны для всех: валюты, организация, значения констант. Все остальные тесты будут на них опираться.
То, что используется в нескольких тестах, можно сделать заранее. Например, если для нового теста нам нужен контрагент, мы смотрим, есть его УИД уже в тестах или нет. Если выясняется, что это какой-то предопределенный или псевдопредопределенный элемент, то почему бы не сделать фикстуру, мы все равно два раза будем заводить?
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт