





{kind=link}
Ключевые возможности:
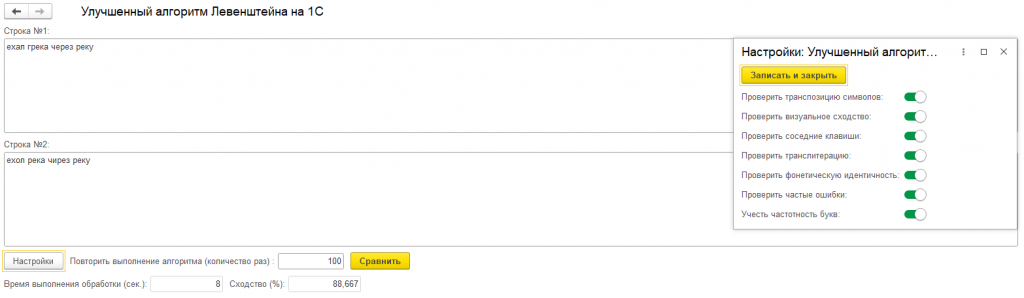
📊 Умное вычисление расстояния между строками
-
Расширенный алгоритм Левенштейна с адаптивными весами замены символов
-
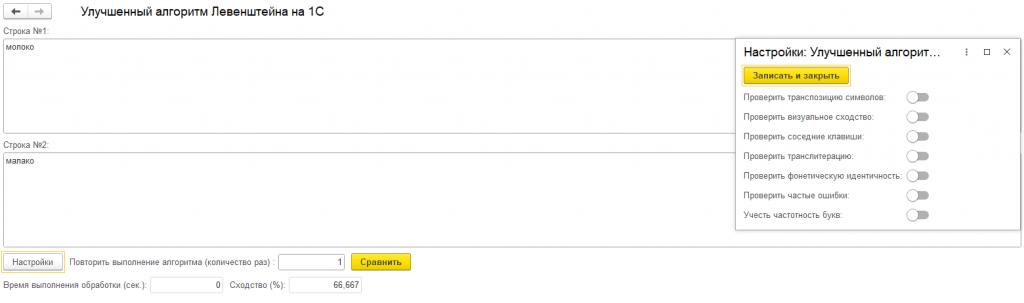
Процентное выражение схожести от 0% до 100%
-
Нормализация входных данных (автоматическое удаление пробелов и приведение к нижнему регистру)
🎯 Учет лингвистических особенностей:
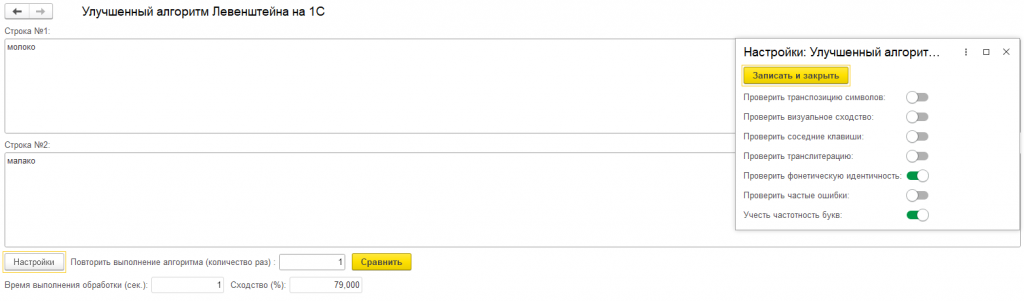
1. Фонетическая идентичность
Учитывает буквы, которые звучат одинаково:
"е" <-> "э", "и" <-> "ы", "о" <-> "а", "г" <-> "х", "ч" <-> "щ" ...
2. Частые орфографические ошибки
Распознает типичные замены:
"з" <-> "с", "т" <-> "д", "п" <-> "б", "ж" <-> "ш", "в" <-> "ф" ...
3. Визуальное сходство
Учитывает похожие по начертанию буквы:
"ш" <-> "щ", "м" <-> "н", "и" <-> "й", "ц" <-> "у", "л" <-> "п" ...
4. Соседние клавиши на клавиатуре
Определяет вероятные опечатки из-за близкого расположения клавиш в русской раскладке.
5. Транслитерация
Распознает замены русских букв на похожие латинские:
"а" <-> "a", "е" <-> "e", "у" <-> "y", "о" <-> "o", "с" <-> "c" ...
6. Учет частотности букв
-
Редкие буквы ("ф", "ц", "щ", "э", "ъ") - высокая стоимость замены
-
Частые буквы ("а", "о", "е", "и", "н") - низкая стоимость замены
Гибкая настройка параметров
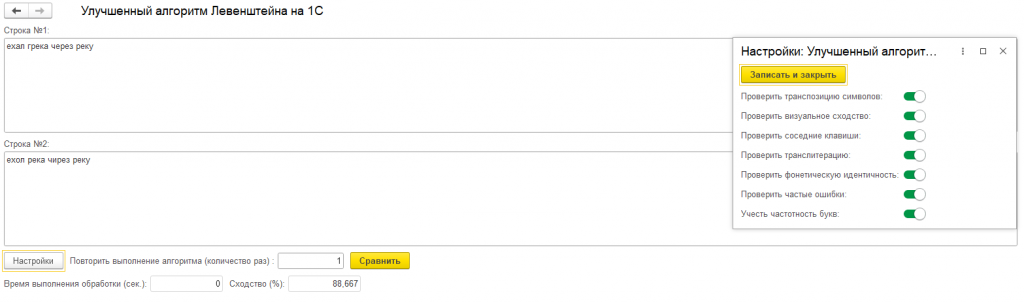
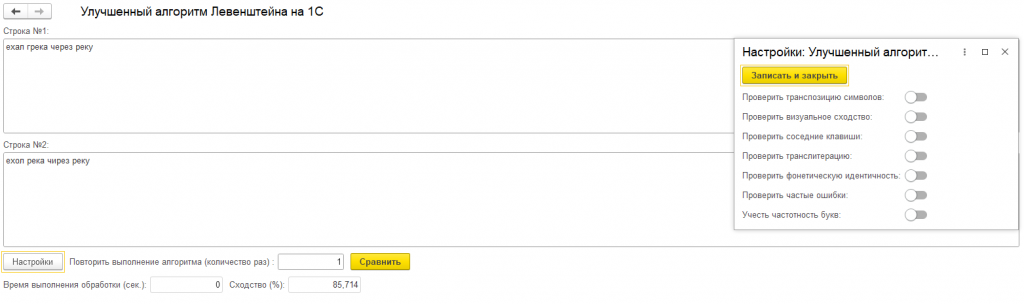
Обработка позволяет включать/выключать различные типы проверок через структуру параметров или в пользовательском интерфейсе:
Настройка весов алгоритма
В данной функции вы сможете самостоятельно установить коэффициенты для настройки точности работы алгоритма (чем больше коэффициент "скидка", тем выше будет результат сравнения, если условие проверки было выполнено).
Функция ПолучитьСтоимостьЗамены(Символ1, Символ2, СтруктураПараметров) // Основные настройки весов данного алгоритма
Символ1 = Символ1;
Символ2 = Символ2;
КоэффициентЧастотности = 1;
Стоимость = 1; // Значение, которое показывает как сильно отличаются символы
Скидка = 0; // Значение, которое уменьшает стоимость
// Полное совпадение
Если Символ1 = Символ2 Тогда
Возврат 0; // Если символы идентичны стоимость = 0;
КонецЕсли;
// Фонетически идентичные звуки (минимальная стоимость)
Если СтруктураПараметров.ПроверитьФонетическуюИдентичность Тогда
Если ПроверитьФонетическуюИдентичность(Символ1, Символ2) Тогда
Скидка = Скидка + 0.3; // 30% скидка
КонецЕсли;
КонецЕсли;
// Буквы, которые часто путают (средняя стоимость)
Если СтруктураПараметров.ПроверитьЧастыеОшибки Тогда
Если ПроверитьЧастыеОшибки(Символ1, Символ2) Тогда
Скидка = Скидка + 0.25; // 25% скидка
КонецЕсли;
КонецЕсли;
// Похожие по начертанию буквы
Если СтруктураПараметров.ПроверитьВизуальноеСходство Тогда
Если ПроверитьВизуальноеСходство(Символ1, Символ2) Тогда
Скидка = Скидка + 0.15; // 15% скидка
КонецЕсли;
КонецЕсли;
// Соседние клавиши на клавиатуре
Если СтруктураПараметров.ПроверитьСоседниеКлавиши Тогда
Если ПроверитьСоседниеКлавиши(Символ1, Символ2) Тогда
Скидка = Скидка + 0.15; // 15% скидка
КонецЕсли;
КонецЕсли;
// Буква случайно написана на английском
Если СтруктураПараметров.ПроверитьТранслитерацию Тогда
Если ПроверитьТранслитерацию(Символ1, Символ2) Тогда
Скидка = Скидка + 0.2; // 20% скидка
КонецЕсли;
КонецЕсли;
// Стоимость от частоты употребления букв в русском языке
Если СтруктураПараметров.УчестьЧастотностьБукв Тогда
КоэффициентЧастотности = УчестьЧастотностьБукв(Символ1, Символ2);
КонецЕсли;
Стоимость = Макс(0.1, Стоимость - Скидка) * КоэффициентЧастотности;
// Полная замена
Возврат Стоимость;
КонецФункции
Гибкая настройка параметров
Обработка позволяет включать/выключать различные типы проверок через структуру параметров или в пользовательском интерфейсе:
СтруктураПараметров = Новый Структура;
СтруктураПараметров.Вставить("ПроверитьСоседниеКлавиши",Истина);
СтруктураПараметров.Вставить("ПроверитьТранслитерацию",Истина);
СтруктураПараметров.Вставить("ПроверитьТранспозициюСимволов",Истина);
СтруктураПараметров.Вставить("ПроверитьФонетическуюИдентичность",Истина);
СтруктураПараметров.Вставить("ПроверитьЧастыеОшибки",Истина);
СтруктураПараметров.Вставить("ПроверитьВизуальноеСходство",Истина);
СтруктураПараметров.Вставить("УчестьЧастотностьБукв",Истина);
Технические особенности
Архитектура решения
-
Модульная структура - разделение на основные и вспомогательные функции
-
Гибкая система весов - адаптивная стоимость замены символов
-
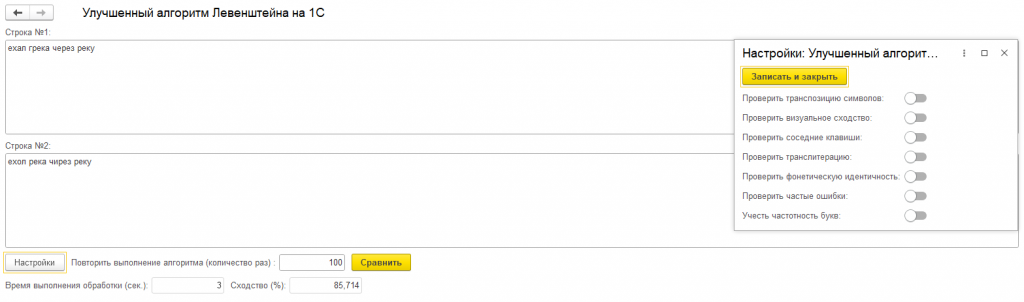
Оптимизация производительности - эффективное использование массивов
Алгоритмические улучшения
-
Транспозиция символов - учет перестановки соседних букв
-
Динамические коэффициенты - автоматическая корректировка весов
-
Нормализация результата - приведение к интуитивно понятному проценту схожести
Области применения
-
Поиск дубликатов в справочниках контрагентов, товаров, номенклатуры
-
Коррекция опечаток при вводе данных пользователями
-
Нечеткий поиск в больших массивах информации
-
Сравнение наименований при интеграциях и загрузках данных
Преимущества перед классическим алгоритмом
| Критерий | Классический Левенштейн | Улучшенный алгоритм |
|---|---|---|
| Учет фонетики | Нет | Да |
| Учет раскладки клавиатуры | Нет | Да |
| Распознавание транслитерации | Нет | Да |
| Учет частотности букв | Нет | Да |
| Гибкая настройка | Нет | Да |
Заключение
Данная обработка представляет собой инструмент для решения практических задач сравнения строк в системах на платформе 1С. Благодаря учету множества лингвистических и поведенческих факторов, алгоритм обеспечивает значительно более точные результаты по сравнению с классическими методами, что делает его незаменимым в задачах очистки данных и нечеткого поиска.
Обработка может встраиваться в справочник "Дополнительные отчеты и обработки" или открываться как внешняя. Также обработка совместима с платформами 1С:Предприятие 8.n
Бонус
Тут представлен полный код из второй обработки "Только алгоритм Левенштейна (без дополнительных проверок)". С помощью него будет легче понять саму работу алгоритма, которая заключается в создании матрицы и дальнейшем её заполнении с получением конечного результата.
&НаКлиенте
Функция ВыполнитьОбработку()
Если ЗначениеЗаполнено(Строка1) И ЗначениеЗаполнено(Строка2) Тогда
РасстояниеЛевенштейна = РасчитатьРасстояниеЛевенштейна();
НаибольшаяДлинаСтроки = Макс(СтрДлина(Строка1),СтрДлина(Строка2));
Сходство = (1 - РасстояниеЛевенштейна / НаибольшаяДлинаСтроки) * 100; // Преобразование полученного расстояния в проценты
КонецЕсли;
КонецФункции
&НаКлиенте
Функция ПолучитьМассивИзСтроки(Строка) // Массив, где каждый элемент массива это символ переданной строки
МассивСтрок = Новый Массив;
Для Счетчик = 1 По СтрДлина(Строка) Цикл
Символ = Прав(Лев(Строка,Счетчик),1);
МассивСтрок.Добавить(Символ);
КонецЦикла;
Возврат МассивСтрок;
КонецФункции
&НаКлиенте
Функция ПолучитьМатрицу(Строка1, Строка2) // Матрица размером - длина первой строки на длину второй строки
Матрица = Новый Массив;
ПерваяСтрока = Истина;
Для Счетчик1 = 0 По СтрДлина(Строка2) Цикл
СтрокаМатрицы = Новый Массив;
СтрокаМатрицы.Добавить(Счетчик1);
Для Счетчик2 = 1 По СтрДлина(строка1) Цикл
Если ПерваяСтрока Тогда
СтрокаМатрицы.Добавить(Счетчик2);
Иначе
СтрокаМатрицы.Добавить(Неопределено);
КонецЕсли;
КонецЦикла;
ПерваяСтрока = Ложь;
Матрица.Добавить(СтрокаМатрицы);
КонецЦикла;
Возврат Матрица;
КонецФункции
&НаКлиенте
Функция РасчитатьРасстояниеЛевенштейна() // Заполняем последовательно матрицу
Матрица = ПолучитьМатрицу(Строка1, Строка2);
Массив1 = ПолучитьМассивИзСтроки(Строка2);
Массив2 = ПолучитьМассивИзСтроки(Строка1);
НомерСтрокиМатрицы = 0;
Для каждого Элемент1 Из Массив1 Цикл
НомерСтрокиМатрицы = НомерСтрокиМатрицы + 1;
НомерКолонкиМатрицы = 0;
Для каждого Элемент2 Из Массив2 Цикл
НомерКолонкиМатрицы = НомерКолонкиМатрицы + 1;
ЭлементМатрицы1 = Матрица[НомерСтрокиМатрицы-1][НомерКолонкиМатрицы-1];
ЭлементМатрицы2 = Матрица[НомерСтрокиМатрицы][НомерКолонкиМатрицы-1];
ЭлементМатрицы3 = Матрица[НомерСтрокиМатрицы-1][НомерКолонкиМатрицы];
НаименьшийЭлемент = Мин(ЭлементМатрицы1, ЭлементМатрицы2, ЭлементМатрицы3); // Выбираем наименьшее значение из трех соседних элементов матрицы
Если Элемент1 <> Элемент2 Тогда // Если символы двух строк не равны тогда к выбранному ранее наименьшему элементу прибавляем стоимость(1)
Матрица[НомерСтрокиМатрицы][НомерКолонкиМатрицы] = НаименьшийЭлемент + 1;
Иначе
Матрица[НомерСтрокиМатрицы][НомерКолонкиМатрицы] = НаименьшийЭлемент;
КонецЕсли;
КонецЦикла;
КонецЦикла;
Возврат Матрица[НомерСтрокиМатрицы][НомерКолонкиМатрицы]; // Это последний элемент полученной матрицы, который и является расстоянием Левенштейна
КонецФункции
Проверено на следующих конфигурациях и релизах:
- 1С:ERP Управление предприятием 2, релизы 2.5.24.68
Вступайте в нашу телеграмм-группу Инфостарт