
Добрый день, уважаемые коллеги.
Небольшая предыстория. Основной целью проекта являлась консолидация двух достаточно больших нетиповых баз ЗУП 2.5 (общее количество подразделений 140, сотрудников 4700). Базы ЗУП до нас дорабатывались и сопровождались другими подрядчиками, а нас привлекли именно на консолидацию. После консолидации пользователи сообщили о сильно возросшей длительности операции заполнения документа «Начисление зарплата сотрудникам». Собственно с этого момента я подключился к этому вопросу.
Часть I – Подготовительная:
Если театр начинается с вешалки, то любая оптимизация начинается с установки подсистемы «Замеры производительности» из БСП. Как внедрять и что за подсистема неплохо описано, например, в этой статье //infostart.ru/public/193233/, поэтому на этом подробно останавливаться не буду. Описание самой методики APDEX хорошо дано на kb.1c.ru, а так же у Славы Гилева http://www.gilev.ru/apdex-teoriya/ и Антона Гусева (наш сотрудник - http://antongusev.ru/article2.html).
Если вкратце, то методика APDEX является широко распространенным международным стандартом оценки производительности информационных систем и является:
- объективной: оценка не зависит от субъективных факторов (эмоции, мнения и т.п.);
- прикладной: оценка отражает реальную производительность прикладных операций, а не абстрактные технические показатели;
- интегральной: оценка учитывает все аспекты работы системы, все требования бизнес-логики системы и удобство работы каждого пользователя;
- количественной: оценка является численной для того, чтобы можно было сравнивать производительность, полученную при разных обстоятельствах (например, до и после оптимизации);
- качественной: оценка интерпретируется в терминах «хорошо» - «плохо».
Сказать, что у нас дела были плохо – это значит не сказать ничего  . Оценка показывала «неприемлемо».
. Оценка показывала «неприемлемо».
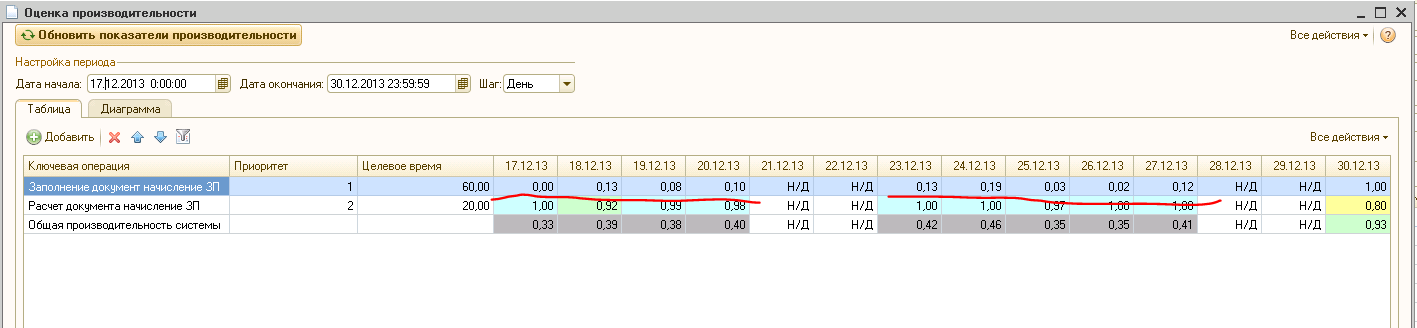
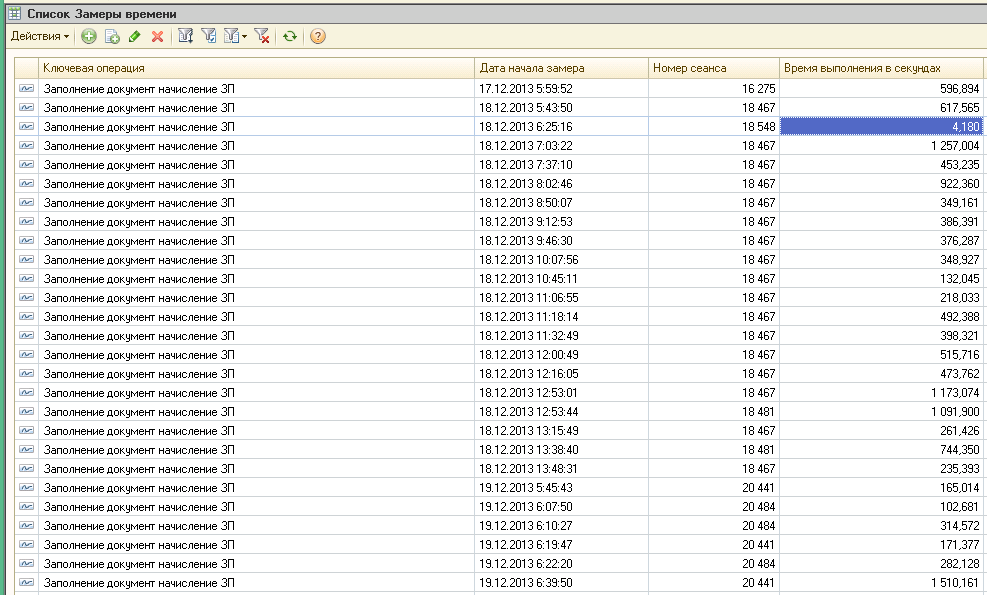
Время выполнения в максимуме иногда достигало 20 минут (см. ниже).
Теперь понятно, ЧТО нужно оптимизировать, пока непонятно КАК. Идем дальше…
Часть II – Неудачная, но длинная
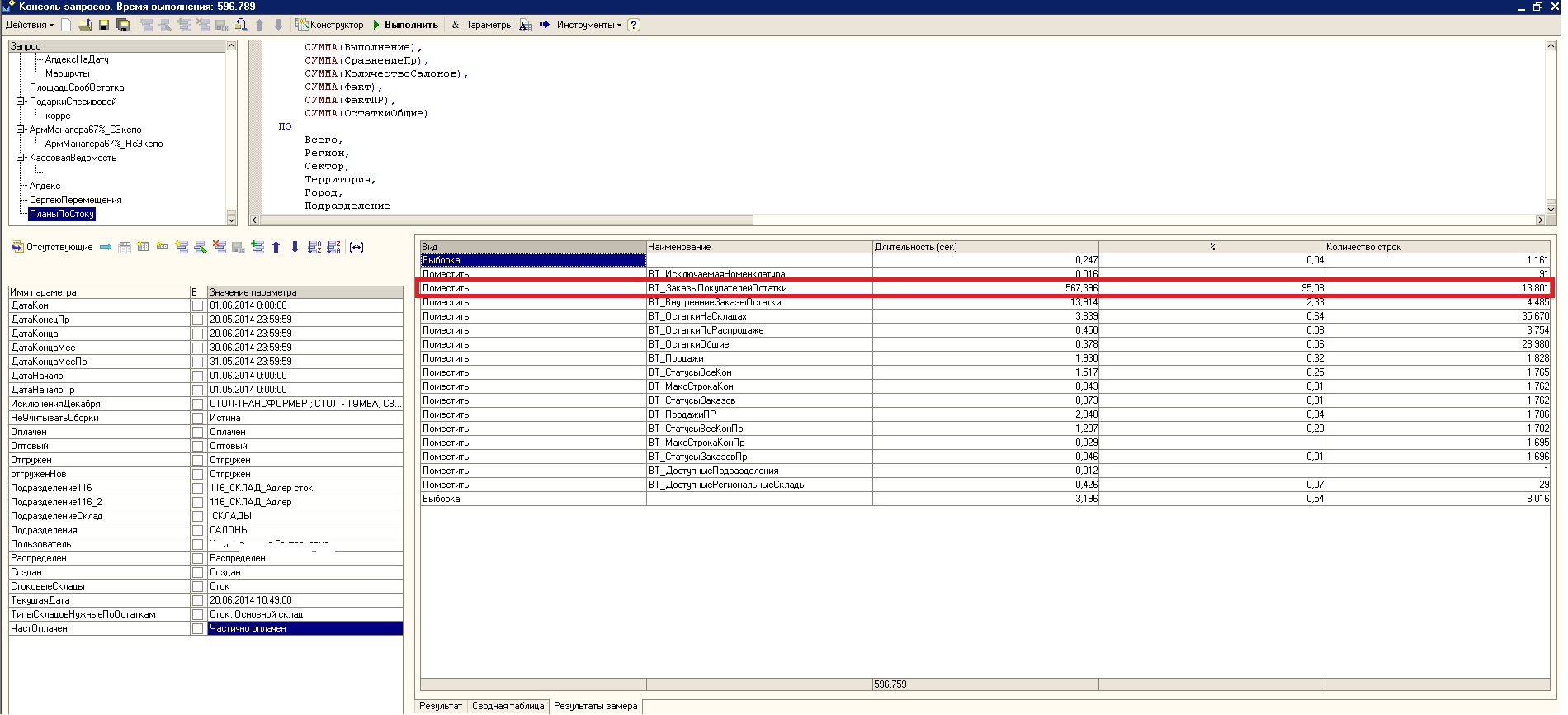
Естественно, что первым делам был сделан замер производительности средствами 1С. Он обрадовал и не обрадовал одновременно. 95% на один запрос из 10 минут - это конечно хорошо, так как мы сходу нашли «узкое место», с другой стороны – не стоит рассказывать про монструозность запросов в ЗУП о которых ходят легенды. Запросы на тысячу строк кода и десятками временных таблиц, собираемый по кусочкам из разных мест. К сожалению, мне попался именно такой запрос – соответственно, как я говорил выше, провести нормальный рефакторинг кода, учитывая полное отсутствие каких-либо комментариев со стороны разработчиков ЗУП, дело мягко говоря неблагодарное.
Простой перезапуск запроса через консоль в тестовой базе подтвердил достаточно длительное время выполнения запроса, но пытаться найти вручную один «плохой» запрос из пары десятков не очень хотелось. Было принято решение запустить запрос через SQL Profiler, т.к. через него я смогу сузить область поиска «плохого» запроса.
Запускаем Microsoft SQL Profiler (performance tools в Пуск). Как запустить SQL Profiler и подключиться к нужному серверу – выходит за рамки статьи – это более подробно описано в других местах (sql.ru / BOL).
Запускаем новый trace со следующим набором событий (Events) (см. ниже). Можно уменьшить выборку колонок, которые будут собираться, но для упрощения можно просто выделить все - пока не принципиально.
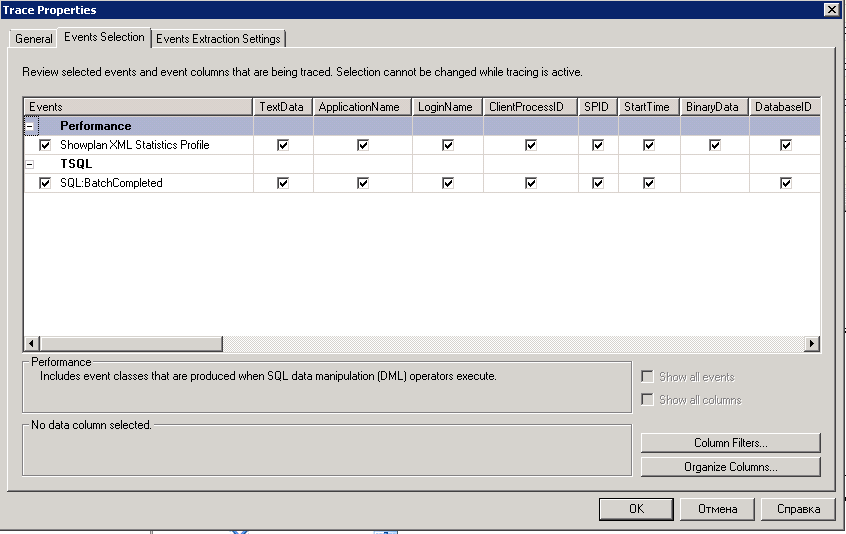
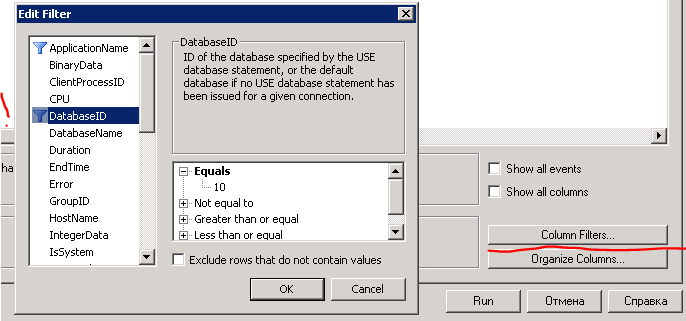
Не забываем установить фильтры событий, чтобы не собирать всякий «мусор» (т.е. события других баз, в т.ч. основной базы, напоминаю, что мы работаем в тестовой базе). Чтобы узнать ID базы можно выполнить запрос select DB_ID ( [ 'database_name' ] ) в SQL Server Management Studio
Стартуем трейс перед началом заполнения и останавливаем после завершения. Дальше выгружаем его в таблицу для удобства работы.
Для простоты можно выгрузить в tempdb с каким-нибудь простым именем, потом эту таблицу можно не задумываясь удалить. Находим длительные операции запросом
SELECT *
FROM [tempdb].[dbo].[temp]
ORDER BY Duration DESC
//temp – название таблицы в которую выгрузили трейс из Profiler
Пример выполнения запроса на скриншоте ниже (немного другого :), но суть та же)

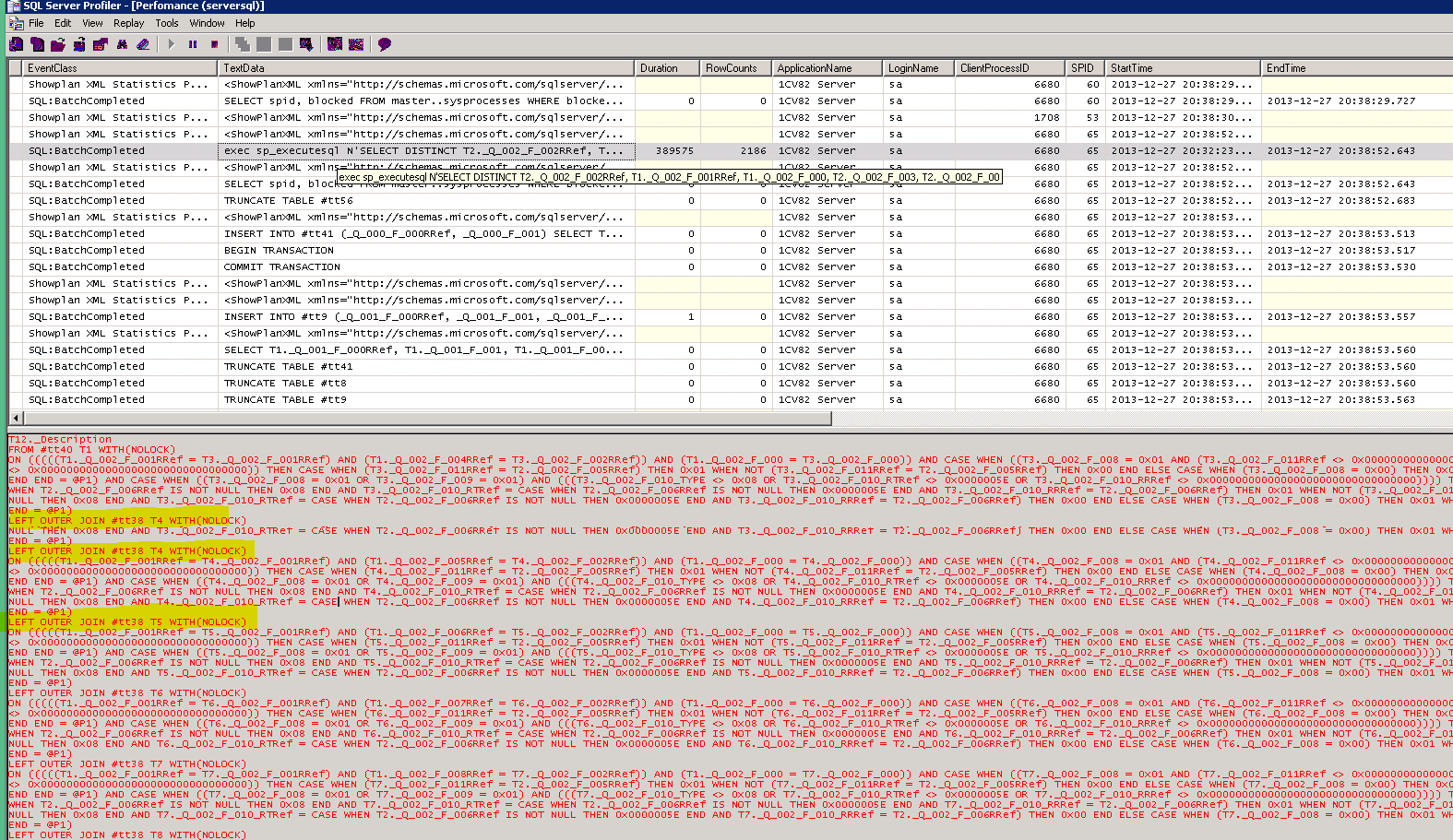
Видим две строчки с ОЧЕНЬ высоким Duration с ними и будем разбираться. В MS SQL Profiler находим по StartTime – EndTime (все строчки расположены по возрастанию EndTime). Проанализируем вторую строчку, как наибольшую. Находим строчку в замере Profiler’а.
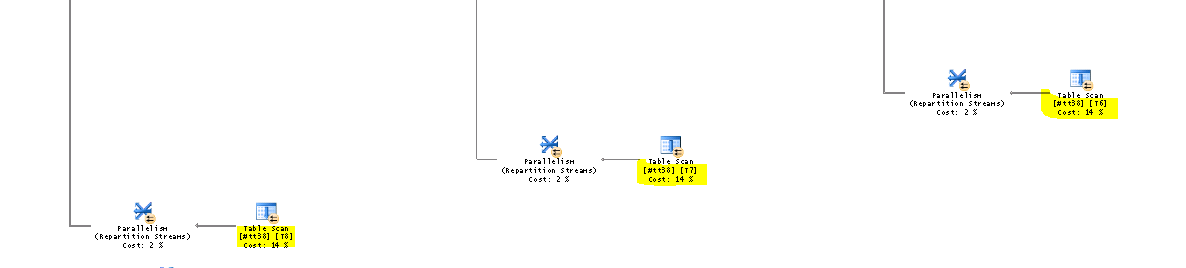
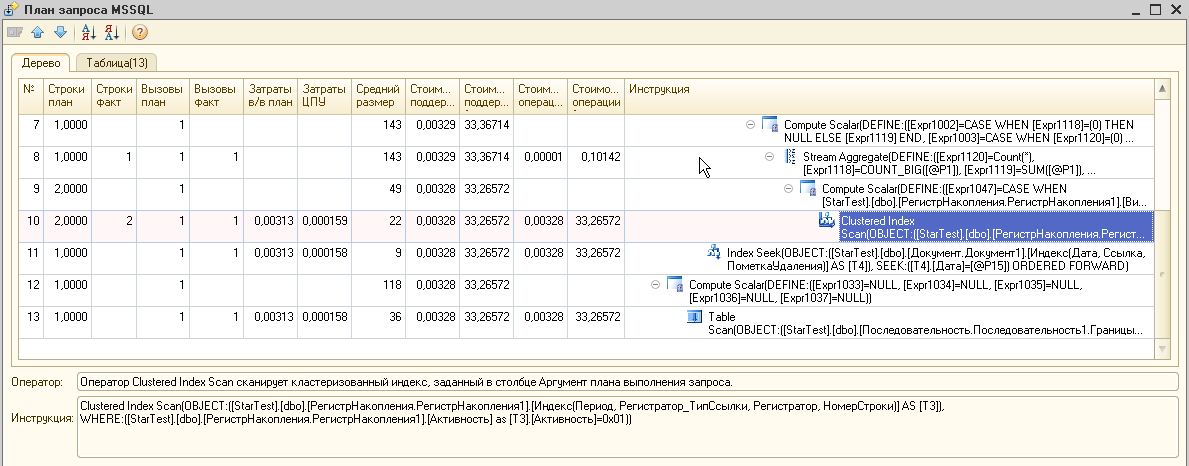
Смотрим план запроса (это строчка сразу НАД найденной строкой). Этим кстати и объясняются все танцы с бубном вокруг выгрузки трейса в таблицу, так как у планов выполнения запроса нет метрики Duration и найти план выполнения запроса без привязки к основному запросу крайне затруднительно. Не буду приводить полный ПВЗ, а покажу только его часть – в ПВЗ видим постоянные table scan с весом в 14% каждый с одной и той же таблицей #tt38.
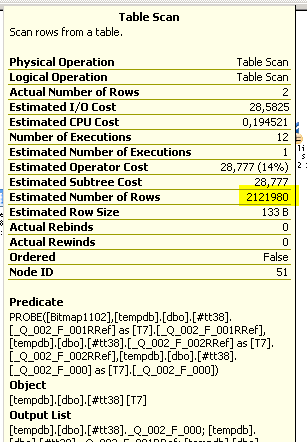
Смотрим таблицу #tt38 в ней обнаруживается 2 миллиона строк (см. ниже)!!! Явная ошибка именно в этой таблице - в данных по зарплате по одному подразделению не может быть такого количества записей даже с самой маленькой детализацией (если только не предположить, что у сотрудников посекундная тарификация :))
Находим наш запрос в 1С. Вот он - куча левых соединений с таблицей ЗначенияПоказателей.

Я думаю у многих возникает вопрос: «А как найти аналог запроса 1С по известному нам запросу SQL?». Для этого есть следующие «помощники»:
- известные объекты в запросе SQL (т.е. когда SQL обращается не к временной, а к какой-то физической таблице). Соответствие между объектами 1С и объектами СУБД можно получить при помощи метода ПолучитьСтруктуруХраненияБазыДанных(), а дальше уже поиском находим нужный запрос
- необычные агрегатные функции (максимум, среднее или количество различных)
- структура запроса (например: два левых соединения и одно прямое с вложенным подзапросом) достаточно точно указывает на запрос 1С
- условия соединений
Это последний (результирующий) запрос в пакете. Разбираться надо с таблицей #tt38 (это кстати вторая строка по длительности в трейсе – insert into #tt38). Аналогичным образом находим ПВЗ для таблицы #tt38 (см. ниже).
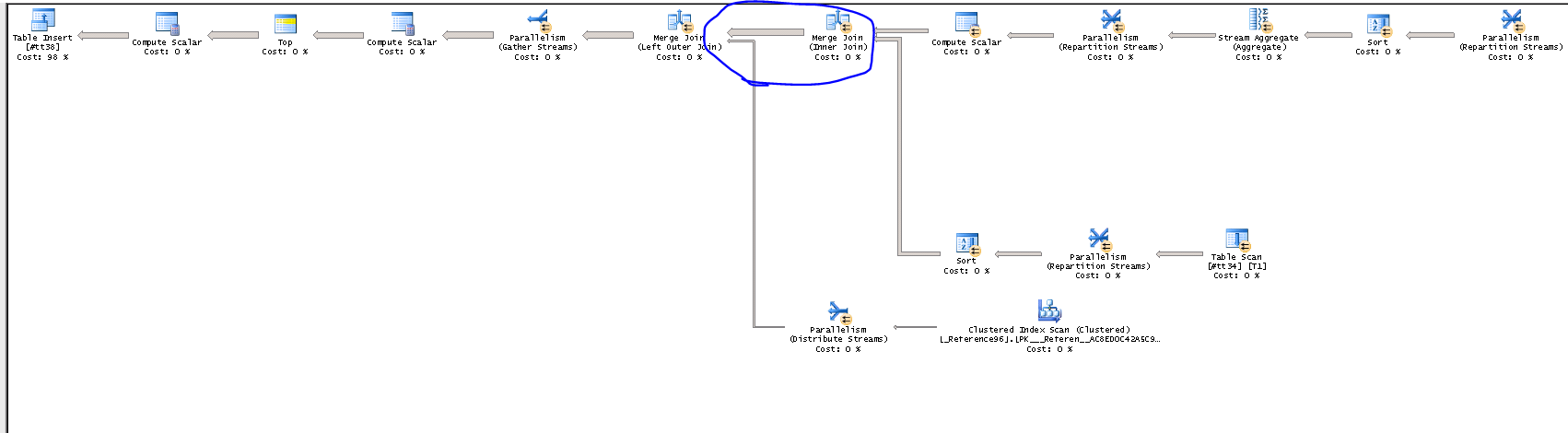
Проблема начинается в выделенном фрагменте (именно с этого момента возникает 2 миллиона строк), на входе у нас приходит две таблицы на 3000 строк, которые объединяются. Подумал, что стоит на всякий случай проверить - нет ли ошибки при объединении, так как уже было сказано выше - 2 млн. строк быть не должно.
Мы уже знаем, что нам нужна таблица ЗначенияПоказателей - ниже приведен текст проблемного запроса. И действительно была обнаружена ошибка в соединении, которая выделена подчеркиванием (в конце запроса).
ВЫБРАТЬ
ПоследниеЗначенияПоказателей.Период КАК ПериодДействия,
ЗначенияПоказателей.Физлицо,
ЗначенияПоказателей.Показатель,
ЗначенияПоказателей.ИсходноеЗначение,
ЗначенияПоказателей.Значение,
ЗначенияПоказателей.Валюта,
ЗначенияПоказателей.ВводитсяВВалюте,
ЗначенияПоказателей.КурсВалюты,
//pma(
ВЫБОР КОГДА ЗначенияПоказателей.Показатель.ВидПоказателя = Значение(Перечисление.ВидыПоказателейСхемМотивации.ПоДолжности) ТОГДА Истина ИНАЧЕ Ложь КОНЕЦ КАК ПоДолжности,
//++ SMI 29.04.13
ВЫБОР
КОГДА ЗначенияПоказателей.Показатель.ВидПоказателя = ЗНАЧЕНИЕ(Перечисление.ВидыПоказателейСхемМотивации.ПоПодразделению)
ИЛИ ЗначенияПоказателей.Показатель.ВидПоказателя = ЗНАЧЕНИЕ(Перечисление.ВидыПоказателейСхемМотивации.ПоПодразделениюИСотруднику)
ТОГДА ИСТИНА
ИНАЧЕ ЛОЖЬ
КОНЕЦ КАК ПоПодразделению,
//-- SMI 29.04.13
ЕСТЬNULL(ЗначенияПоказателей.Подразделение, Значение(Справочник.Подразделения.ПустаяСсылка)) КАК Подразделение,
ЕСТЬNULL(ЗначенияПоказателей.Должность, Значение(Справочник.ДолжностиОрганизаций.ПустаяСсылка)) КАК Должность
//pma)
ПОМЕСТИТЬ ЗначенияПоказателей
ИЗ
ЗначенияПоказателейИсходныйПериодДействия КАК ЗначенияПоказателей
ВНУТРЕННЕЕ СОЕДИНЕНИЕ (ВЫБРАТЬ
МАКСИМУМ(ЗначенияПоказателей.ПериодДействия) КАК ПериодДействия,
ПериодыФизлиц.Период КАК Период,
ЗначенияПоказателей.Физлицо КАК Физлицо,
ЗначенияПоказателей.Показатель КАК Показатель,
//pma(
ВЫБОР КОГДА ЗначенияПоказателей.Показатель.ВидПоказателя = Значение(Перечисление.ВидыПоказателейСхемМотивации.ПоДолжности) ТОГДА Истина ИНАЧЕ Ложь КОНЕЦ КАК ПоДолжности,
ВЫБОР КОГДА ЗначенияПоказателей.Показатель.ВидПоказателя = Значение(Перечисление.ВидыПоказателейСхемМотивации.ПоПодразделению) ТОГДА Истина ИНАЧЕ Ложь КОНЕЦ КАК ПоПодразделению,
ЕСТЬNULL(ЗначенияПоказателей.Подразделение, Значение(Справочник.Подразделения.ПустаяСсылка)) КАК Подразделение,
ЕСТЬNULL(ЗначенияПоказателей.Должность, Значение(Справочник.ДолжностиОрганизаций.ПустаяСсылка)) КАК Должность
//pma)
ИЗ
ЗначенияПоказателейИсходныйПериодДействия КАК ЗначенияПоказателей
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ПериодыФизлиц КАК ПериодыФизлиц
ПО ЗначенияПоказателей.Физлицо = ПериодыФизлиц.ФизЛицо
И ЗначенияПоказателей.ПериодДействия <= ПериодыФизлиц.Период
СГРУППИРОВАТЬ ПО
ЗначенияПоказателей.Физлицо,
//pma(
ВЫБОР КОГДА ЗначенияПоказателей.Показатель.ВидПоказателя = Значение(Перечисление.ВидыПоказателейСхемМотивации.ПоДолжности) ТОГДА Истина ИНАЧЕ Ложь КОНЕЦ,
ВЫБОР КОГДА ЗначенияПоказателей.Показатель.ВидПоказателя = Значение(Перечисление.ВидыПоказателейСхемМотивации.ПоПодразделению) ТОГДА Истина ИНАЧЕ Ложь КОНЕЦ,
ЗначенияПоказателей.Подразделение,
ЗначенияПоказателей.Должность,
//pma)
ПериодыФизлиц.Период,
ЗначенияПоказателей.Показатель) КАК ПоследниеЗначенияПоказателей
ПО ЗначенияПоказателей.Физлицо = ПоследниеЗначенияПоказателей.Физлицо
И ЗначенияПоказателей.Показатель = ПоследниеЗначенияПоказателей.Показатель
И ЗначенияПоказателей.ПериодДействия = ПоследниеЗначенияПоказателей.ПериодДействия
//pma(
И (ПоследниеЗначенияПоказателей.ПоДолжности И ЕСТЬNULL(ЗначенияПоказателей.Подразделение, Значение(Справочник.ДолжностиОрганизаций.ПустаяСсылка)) = ПоследниеЗначенияПоказателей.Подразделение ИЛИ Не ПоследниеЗначенияПоказателей.ПоДолжности)
И (ПоследниеЗначенияПоказателей.ПоДолжности И ЕСТЬNULL(ЗначенияПоказателей.Должность, Значение(Справочник.ДолжностиОрганизаций.ПустаяСсылка)) = ПоследниеЗначенияПоказателей.Должность ИЛИ Не ПоследниеЗначенияПоказателей.ПоДолжности)
//pma)
Как обычно получили две новости – хорошую и плохую. Начинаем с «хорошей» – нашли ошибку в старом коде. «Плохая» – ошибка не влияет ни на качество (нет данных, на которых она бы проявилась), ни (что логично исходя из кода) на производительность операции (повторный аналогичный анализ опять показал 3000 записей на входе и 2 млн строк при объединении). Но, как говорится, – «все что ни делается – всё к лучшему» (с). Во-первых, ошибку все равно нашли, а во-вторых, еще больше сузили область поиска проблемного запроса. Теперь стало понятно, что ошибка кроется в большом количестве записей на входе (3000) в таблицу ЗначенияПоказателей.
Часть III – Удачная и короткая:
Чтобы проанализировать запрос заполнения таблицы ЗначенияПоказателей, пришлось собрать текст запроса из двух разных мест (хорошо, что только из двух :)). Итоговый текст ~1200 строк и 25 запросов в пакете (напоминаю, что это только ЧАСТЬ(!) общего запроса).
После беглого анализа результатов запроса в консоли 1С было обнаружено следующее, что в таблице ЗначенияЕжемесячныхПоказателей было декартово произведение сотрудников подразделения и всех значений показателя ОтработаноДнейВДолжности по всем подразделениям и сотрудникам организации, а нам этот показатель нужен только для подразделения, значит не хватает условия по подразделению и сотруднику в условии соединения.
Смотрим запрос:
ВЫБРАТЬ РАЗЛИЧНЫЕ
ЗначенияПоказателейСхемМотивации.ПериодДействия КАК ПериодДействия,
ДвиженияРаботников.Физлицо КАК Физлицо,
ЗначенияПоказателейСхемМотивации.Подразделение КАК Подразделение,
ЗначенияПоказателейСхемМотивации.Показатель КАК Показатель,
ЗначенияПоказателейСхемМотивации.Значение КАК Значение,
ЗначенияПоказателейСхемМотивации.Валюта КАК Валюта
ПОМЕСТИТЬ ЗначенияЕжемесячныхПоказателей
ИЗ
ВТДвиженияРаботников КАК ДвиженияРаботников
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ЗначенияПоказателейСхемМотивации КАК ЗначенияПоказателейСхемМотивации
ПО (ЗначенияПоказателейСхемМотивации.Организация = ЗНАЧЕНИЕ(Справочник.Организации.ПустаяСсылка))
И (ЗначенияПоказателейСхемМотивации.ПериодДействия = НАЧАЛОПЕРИОДА(&парамНачало, МЕСЯЦ))
И (ВЫБОР
КОГДА ЗначенияПоказателейСхемМотивации.Показатель.ВидПоказателя = ЗНАЧЕНИЕ(Перечисление.ВидыПоказателейСхемМотивации.Индивидуальный)
ИЛИ ЗначенияПоказателейСхемМотивации.Показатель.ВидПоказателя ЕСТЬ NULL
ТОГДА ДвиженияРаботников.Физлицо = ЗначенияПоказателейСхемМотивации.Сотрудник.Физлицо
КОГДА ЗначенияПоказателейСхемМотивации.Показатель.ВидПоказателя = ЗНАЧЕНИЕ(Перечисление.ВидыПоказателейСхемМотивации.ПоПодразделению)
ТОГДА ДвиженияРаботников.Подразделение = ЗначенияПоказателейСхемМотивации.Подразделение
КОГДА ЗначенияПоказателейСхемМотивации.Показатель.ВидПоказателя = ЗНАЧЕНИЕ(Перечисление.ВидыПоказателейСхемМотивации.ПоПодразделениюИСотруднику)
ТОГДА ДвиженияРаботников.Физлицо = ЗначенияПоказателейСхемМотивации.Сотрудник.Физлицо
И ДвиженияРаботников.Подразделение = ЗначенияПоказателейСхемМотивации.Подразделение
ИНАЧЕ ИСТИНА
КОНЕЦ)
ОБЪЕДИНИТЬ
ВЫБРАТЬ РАЗЛИЧНЫЕ
ЗначенияПоказателейСхемМотивации.ПериодДействия,
ДвиженияРаботников.ФизЛицо,
ЗначенияПоказателейСхемМотивации.Подразделение,
ПоказателиСхемМотивации.Ссылка,
ЗначенияПоказателейСхемМотивации.Значение,
ЗначенияПоказателейСхемМотивации.Валюта
ИЗ
ВТДвиженияРаботников КАК ДвиженияРаботников
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ЗначенияПоказателейСхемМотивации КАК ЗначенияПоказателейСхемМотивации
ПО (ЗначенияПоказателейСхемМотивации.Организация = ЗНАЧЕНИЕ(Справочник.Организации.ПустаяСсылка))
И (ЗначенияПоказателейСхемМотивации.ПериодДействия = ДОБАВИТЬКДАТЕ(НАЧАЛОПЕРИОДА(&парамНачало, МЕСЯЦ), МЕСЯЦ, -1))
И (ВЫБОР
КОГДА ЗначенияПоказателейСхемМотивации.Показатель.ВидПоказателя = ЗНАЧЕНИЕ(Перечисление.ВидыПоказателейСхемМотивации.Индивидуальный)
ИЛИ ЗначенияПоказателейСхемМотивации.Показатель.ВидПоказателя ЕСТЬ NULL
ТОГДА ДвиженияРаботников.ФизЛицо = ЗначенияПоказателейСхемМотивации.Сотрудник.Физлицо
КОГДА ЗначенияПоказателейСхемМотивации.Показатель.ВидПоказателя = ЗНАЧЕНИЕ(Перечисление.ВидыПоказателейСхемМотивации.ПоПодразделению)
ТОГДА ДвиженияРаботников.Подразделение = ЗначенияПоказателейСхемМотивации.Подразделение
КОГДА ЗначенияПоказателейСхемМотивации.Показатель.ВидПоказателя = ЗНАЧЕНИЕ(Перечисление.ВидыПоказателейСхемМотивации.ПоПодразделениюИСотруднику)
ТОГДА ДвиженияРаботников.Физлицо = ЗначенияПоказателейСхемМотивации.Сотрудник.Физлицо
И ДвиженияРаботников.Подразделение = ЗначенияПоказателейСхемМотивации.Подразделение
ИНАЧЕ ИСТИНА
КОНЕЦ)
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.ПоказателиСхемМотивации КАК ПоказателиСхемМотивации
ПО ЗначенияПоказателейСхемМотивации.Показатель = ПоказателиСхемМотивации.ПоказательПредыдущегоПериода
И (ПоказателиСхемМотивации.ПредыдущийПериод)
При заполнении временной таблицы ЗначенияЕжемесячныхПоказателей идет соединение Движений и ЗначенийПоказателей в условии соединения идет ВЫБОР КОГДА с различными вариантами по ВидамПоказателей
Были указаны виды:
- Индивидуальный
- ПоПодразделению
- ПоПодразделениюИСотруднику
Если не один из указанных, то ИСТИНА (то есть без ограничений), т.е. если вид показателя не равен ни одному из указанных, то фактически появляется соединение по ИСТИНА, что равно перемножению таблиц. Излишне говорить, что именно это и происходило 
Причина ошибки - в программу предыдущими разработчиками было добавлено новое значение перечисления показателя «ПоКадровымДаннымСотрудника», который заполняется по подразделению и должности и который не был описан в условии соединения.
Решение – добавить новое условие в ВЫБОР КОГДА по новому виду показателя.
Скорректированный код запроса приводить не буду – логика понятна.
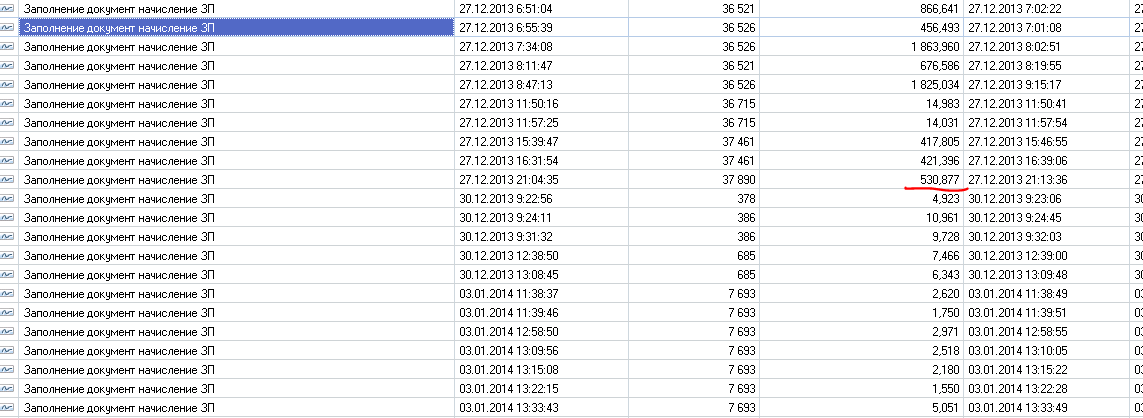
Время выполнения текущего запроса снизилось с 2 секунд до 0.2 секунд и снизилось количество записей до 300.
IV часть – Заключительная и опять короткая :)
Результаты оптимизации стали видны сразу:
- Невооруженным взглядом – время заполнения документа изменилось с «очень долго» на «практически мгновенно».
- Вооруженным – APDEX изменился с «неприемлимо» до «отлично».

Замеры выполнения ДО и ПОСЛЕ оптимизации разделены красным маркером.
ВЫВОДЫ
- План выполнения запросов MSSQL из SQL Profiler удобно использовать для анализа и оптимизации «узких мест» в больших «многоэтажных» запросах и либо находить, либо сужать область поиска неоптимального или некорректного кода, особенно когда проводить рефакторинг кода запроса крайне затруднительно или невозможно.
- Анализ планов выполнения запроса так же помогает выявить запросы, которые сами по себе выполняются достаточно быстро по отношению к общему времени выполнения запроса, но которые критическим образом сказываются на общем времени выполнения. Такие "некорректные" запросы очень тяжело выявить используя только стандартные средства 1С без визуализации плана выполнения.
- Когда у тебя руки чешутся, чтобы сделать что-нибудь полезное – проверь не сделал ли это кто-нибудь до тебя (с) Здесь я имею ввиду – Консоль запросов 1С с одновременной возможностью просмотра плана выполнения запроса из SQL Profiler. Такая обработка уже есть – //infostart.ru/public/56973/ - автор Ararat. Пока, к сожалению, воспользоваться ей не довелось, но судя по отзывам и рекомендациям – там все нормально, и она отработает так как надо. Думаю, что с такой обработкой я бы решил задачу быстрее, так как с Profiler'ом было бы поменьше работы. Так что думаю обработка из разряда - must have.
- Начинать любую оптимизацию лучше всего с внедрения подсистемы «Оценка производительности» и установки замеров времени выполнения, чтобы четко отслеживать результаты оптимизации.
- На производительности могут сказываться неочевидные и труднонаходимые ошибки в коде. (с) Капитан Очевидность
- Очередное подтверждение правила, если что-то стало медленно работать – 90% что надо искать «кривой» код
В качестве P.S., крайне рекомендую к прочтению статью Славы Гилева «Влияние оптимизатора запросов на производительность 1С» - в ней очень хорошо показана вся внутренняя кухня оптимизатора СУБД, плана выполнения запроса и всего остального. Статья из разряда «must read», особенно тем, кто готовится к Эксперту по ТВ или просто хочет чуть лучше понимать как оно "ТАМ" работает :)
Вступайте в нашу телеграмм-группу Инфостарт



{kind=link}