Меня зовут Виталий Подымников, я работаю в отделе корпоративных внедрений фирмы «1С». Мы курируем большие проекты, где ведется промышленная разработка под корпоративных заказчиков. На наших проектах всегда много разработчиков, а мы отвечаем, в том числе, за организацию их работы – пишем регламенты и выстраиваем пайплайн вендорского контроля качества кода.
Когда я думал, какой из наших инструментов будет наиболее полезен сообществу, я исходил из принципа Парето – выбирал то, что требует 20% усилий, но приносит 80% результата, чтобы вы смогли при минимуме затрат получить максимальную пользу и быстро начать свой путь в мир инженерных практик.
Поэтому я решил поделиться нашими наработками по дымовому тестированию – рассказать об инструменте, который мы давно и успешно используем.
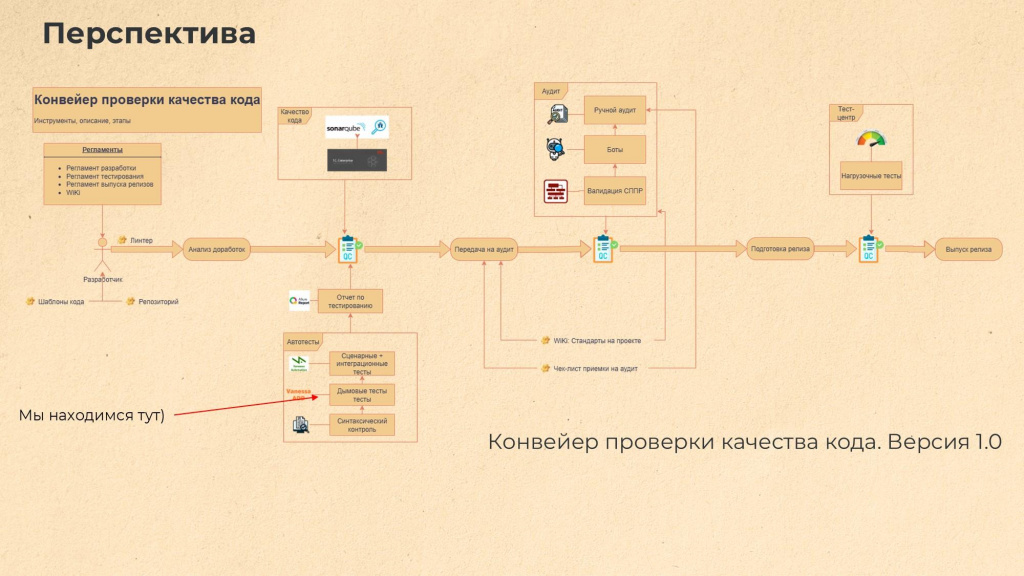
На картинке представлена небольшая перспектива того, как у нас сейчас выглядит конвейер проверки качества кода (первая его версия) – показаны основные контрольные точки проверки качества разработки программных решений, инструменты и регламенты, которыми мы пользуемся. В целом этот конвейер довольно большой и развесистый, но мы сейчас рассмотрим только небольшую его часть – в левом углу. Этот кусочек очень полезный, и я про него расскажу.
Дымовые тесты в мире 1С. Существующие фреймворки

Что вообще такое дымовые тесты именно в мире 1С? Для меня дымовые тесты – это все, что не связано с бизнес-логикой конкретного приложения, некая базовая функциональность любого решения на платформе 1С. Например, к дымовым тестам относится:
-
классическое открытие форм: вне зависимости от решения – в Бухгалтерии, ERP, где угодно – формы должны открываться;
-
механизм печати – он тоже унифицированный и везде одинаковый (по крайней мере должен быть таким);
-
запись элементов (справочники, документы);
-
ввод на основании и т.д.
Еще к одной особенности дымовых тестов можно отнести то, что в них мы можем автоматизированно тестировать какие-то вещи кодом.
На данный момент, насколько я знаю, есть три фреймворка для дымового тестирования:
-
Дымовые тесты Vanessa Automation.
Это хороший и очень популярный фреймворк, где каждый дымовой тест представляет собой отдельный feature-файл.
Этот файл ничем не отличается от обычного сценарного теста.
К сожалению, для большой промышленной разработки это не всегда удобно. Тесты нужно постоянно актуализировать. Например, при добавлении нового документа, для проверки его базовой функциональности надо сгенерировать новый feature-файл. Это определенные затраты времени и сложности с погружением каждого разработчика в механизмы формирования дымовых тестов. -
Дымовые тесты YAxUnit.
Он стильный, модный, молодежный, но все-таки больше заточен на модульные тесты, и до недавнего времени дымовые тесты там были, скорее, в пилотном режиме. Кроме этого, у YAxUnit достаточно высокий порог вхождения – чтобы писать для него тесты, нужно освоить большое количество справочного материала.
На самом деле мы попробуем на следующем проекте перенести наши наработки на этот фреймворк, но время этого переноса еще не пришло и ждет своего героя. -
Дымовые тесты xddTestRunner, который входит в состав Vanessa ADD.
Внутри Vanessa ADD существует два продукта: bddRunner, который предназначен для функционального тестирования и xddTestRunner – для дымового.
Все дымовые тесты для xddTestRunner реализованы в виде обработок: т.е. каждый вид теста – это отдельный EPF-файл.
Например, дымовой тест на открытие форм – это обработка, которая так и называется, «Тесты_ОткрытиеФормКонфигурации.epf».
Главное преимущество xddTestRunner (киллер-фича) в том, что все тест-кейсы генерируются кодом на основании заданных алгоритмов. Поэтому нет необходимости создавать отдельные тесты для каждого вида документа или в целом для каждой конфигурации – при появлении в конфигурации нового объекта система автоматически добавляет для него соответствующий тест-кейс.
Основные принципы дымового тестирования Vanessa ADD

Рассмотрим особенности стандартного фреймворка Vanessa ADD.
Его разработка ведется в репозитории на GitHub. Установить его можно с помощью менеджера пакетов OneScript командой:
opm install add
После установки в папке OneScript/lib появится каталог add со всеми нужными для фреймворка файлами.
Все настройки тестов, включая исключения, хранятся в файле <ПутьКadd>\tools\json\xUnitParams.json
Благодаря этому json-файлу настройки не нужно прописывать внутри обработок вручную, можно управлять ими централизованно.
Дымовые тесты в Vanessa ADD делятся на два типа: серверные и клиентские.
-
Клиентские тесты могут вызывать клиентские методы – открывать формы и выполнять действия с клиентской стороны, что-то дергать с клиента на сервере.
-
Серверные тесты выполняются целиком на стороне сервера.
Расскажу на простом примере, как формируется тест-кейс.
Допустим, у нас есть некая абстрактная конфигурация, и нужно убедиться, что любые справочники в ней записываются корректно.
Чтобы это проверить, нам нужно создать из этой конфигурации демо-базу и запустить в ней дымовой тест для записи элементов справочников – пройтись по всем справочникам и попытаться записать по несколько элементов каждого типа. Для этого в xUnitParams.json требуется выполнить действия:
-
добавить настройку о том, что тест для записи элементов справочников используется – установить ("Используется":true), такая настройка есть для всех тестов;
-
если я хочу выбрать, например, какое-то количество первых или последних элементов из справочника каждого вида – добавить настройку "КоличествоПервыхЭлементов":5 или "КоличествоПоследнихЭлементов":5 (эти элементы будут выбраны запросом);
-
если моя конфигурация построена на БСП, и некоторые ее справочники не должны записываться в интерактивном режиме, добавить исключения. Проверяем все, кроме того, что описано в этом блоке.
Например: "Исключения":[
"ИдентификаторыОбъектовМетаданных",
"ИдентификаторыОбъектовРасширений",
"ПредопределенныеВариантыОтчетов",
"ПредопределенныеВариантыОтчетовРасширений",
"*ПрисоединенныеФайлы"
]
В результате при загрузке этого теста Vanessa ADD создает набор тест-кейсов: читает настройки (сколько видов элементов взять, какие есть исключения), запросом получает элементы, которые нужно записать, и формирует на каждый элемент отдельный тест-кейс.
Получается, что запись каждого элемента – это тест-кейс, в котором записано конкретно: «Сходи, пожалуйста, в такой-то справочник, возьми такой-то элемент и попробуй его записать. Если он не записывается, то выброси ошибку».
Vanessa ADD поддерживает два режима работы:
-
Ручной запуск тест-кейсов (для отладки) – мы интерактивно открываем в базе обработку xddTestRunner. В основном, ручной запуск используется для первоначальной настройки – когда мы еще не готовы запускать тесты автоматически, а просто отлаживаем их, смотрим, с каким результатом они проходят.
-
Автоматический запуск тест-кейсов (регулярный) – запускается в фоновом режиме из cmd-файла или шага пайплайна и генерирует результаты прохождения тестов в двух форматах: в Allure или в JUnit. Мне больше нравится Allure – в нем получается более показательно и удобно. Формат JUnit показывается «из коробки» в пайплайнах Гитлаба, можно сходу увидеть общее количество упавших тестов. Но для анализа и интерактивной работы с большим количеством тестов такой формат не очень удобен.
Вот так выглядит оригинальный репозиторий Vanessa ADD на GitHub. Обратите внимание, что дымовые тесты там уже довольно давно не обновлялись, последние изменения – четыре года назад.
Наш вариант фреймворка за это время серьезно эволюционировал – претерпев, наверное, уже третью версию того, как его удобнее использовать.
Наш вариант Vanessa ADD

В репозитории https://github.com/Arcius7012/add_plus вы можете увидеть результат этих доработок – я выложил туда все, что можно было выложить публично.
Общий принцип доработки был такой – мы использовали Vanessa ADD как «черный ящик» и вносили изменения только с исправлением ошибок или важным для нас функционалом. Примерно по такому же принципу, как дорабатываются типовые решения от вендора.
Расскажу, что мы сделали в рамках доработки оригинальной Vanessa ADD.
-
Плагин «ЗагрузчикФайла».
В оригинальной версии при запуске серверных тестов на клиент-серверной базе настройки из файла не учитывались, приходилось их прописывать прямо в серверном тесте. Это неудобно, потому что для каждой конфигурации нужны свои параметры. В нашей версии плагина мы настройки пробрасываем в тест. -
Ручной запуск через xddTestRunner.
Реализовали простую доработку, чтобы настройки при открытии подхватывались из настроек последнего запуска. -
Группировка для отчетов. Плагины «ГенераторОтчетаAllureXMLВерсия2» и «ГенераторОтчетаJUnitXML».
В оригинальной версии все тесты отображались единым списком. У нас они сгруппированы в блок «Дымовые тесты».
Также у нас есть блоки «Сценарные тесты», «Интеграционные тесты». В перспективе планируется добавить еще блок «Нагрузочные тесты», чтобы тоже анализировать их результаты, например, в Allure. -
Унификация тестов.
Привели их структуру и настройки к единому стилю и добавили кодификацию.
Когда тестов более 50 видов и они выводятся в Allure единым списком, получается простыня, в которой сложно ориентироваться.
Поэтому мы присвоили нумерацию и переформулировали названия так, чтобы выглядело однотипно. -
Добавлено 9 новых тестов, 6 тестов значительно переработано.

На картинке слева показано, как сейчас выглядит структура папки с обработками для дымового тестирования на одном из наших рабочих проектов.
Видно, что:
-
все дымовые тесты разбиты по трем группам (подробнее о разделении ниже);
-
каждому тесту присвоен уникальный код, чтобы было проще по ним ориентироваться;
-
все дымовые тесты называются и выводятся в Allure единообразно.
Справа – пример того, как мы переделали настроечный файл:
-
Добавили информацию, для какой конкретно конфигурации и номера ее редакции эти тесты предназначены.
От редакции к редакции что-то может меняться, искать по истории гита неудобно. В стандартном варианте настроек тестов этого не хватало. -
Сделали для настроек тестов сортировку и группировку. Теперь можно по коду теста быстро находить нужную настройку.
-
Добавили для тестов некоторые параметры, которых там не хватало.

Все дымовые тесты мы условно разделили на три основные группы.
В первую группу входят общие тесты, которые проверяют базовую работоспособность конфигурации.
На скриншоте показан отчет Allure с результатами тестирования для нашей флагманской конфигурации на текущем проекте – «Управление холдингом». Видно, что у нас сейчас каждую ночь запускаются около 50 тысяч разнообразных тест-кейсов.
Общие тесты прогоняются при каждом обновлении конфигурации. Например, при переходе на новый релиз мы обязательно запускаем весь набор, чтобы убедиться, что основные механизмы работают корректно.
Расскажу обзорно, сильно не вдаваясь в детали, некоторые особенности тестов:
-
Проверка сортировки объектов – проверяет сортировку всех групп метаданных по алфавиту. При разработке в EDT это важно.
-
Проверка компоновки макетов СКД – часто ломается. Бывает, что из регистра, например, удалили какое-то измерение\реквизит\ресурс, а в нескольких отчетах (встроенных или дополнительных) это используется. Отчеты перестают работать, и упавший тест об этом сразу сигнализирует.
-
Проверка записи элементов справочников и Проверка записи групп справочников – казалось бы, ерунда, но падает регулярно.
Например, часто забывают, что справочник иерархический, и не проверяют в коде, что это не группа. Или добавляют новый обязательный реквизит, а в обработчике обновления не реализуют его заполнение.
В результате ни один существующий элемент справочника не записывается. Дымовой тест это сразу выявит. -
Проверка формирования печатных форм – тоже частенько падает, проверяет только что нет исключений при формировании печатной формы, не проверяет макет самой печатной формы.
-
Проверка настроек тестов – проверяет, что конфигурация, на которой мы запускаем тесты, соответствует конфигурации, прописанной в настроечном файле. То есть мы не запускаем, например, анализ на ЗУПе с настройками УХ или наоборот.
При большом количестве конфигураций тест полезный и мы его отдельно контролируем. -
Проверка ввода на основании – все, что можно ввести на основании, должно вводиться без ошибок. Сам тест у нас сейчас активно дорабатывается под все наши конфигурации, скорее всего его позже в репозитории обновлю.
-
Проверка проводок документа – перепроводим старые документы и проверяем, чтобы существующие движения у них не менялись.
На скриншоте видно, что у нас много «упавших» тестов, потому что сейчас идёт активная разработка, и мы пока не приводили все к порядку – подобные расхождения фиксируются в технический долг и будут устранятся перед финальной сдачей работ.

Следующая группа – тестирование ролей и полномочий.
Сама группировка родилась из пожеланий заказчика, но оказалась полезной и наглядной.
На больших конфигурациях новые роли стараются делать атомарными, а конкретные бизнес-роли мы собираем уже на уровне профилей доступа из атомарных (как кирпичики).
Например, мы создаем новый документ, и к нему всегда идут две атомарные роли – на чтение и изменение.
Также на больших системах обязательна настройка RLS. Мы используем производительный режим работы, и нам нужно контролировать, что, во-первых, разработчик не забыл настроить RLS в роли, а во-вторых, что для производительного режима у нас выполнены доп.настройки (модуль менеджера и предопределенные элементы регистров в справочнике идентификаторы объектов метаданных).
На картинке видно, что на нашей УХе проверяется порядка 3 тысяч атомарных ролей.
Проверить вручную корректность заведения 3 тысяч ролей в EDT – задача долгая и однообразная. В конфигураторе задача в принципе не реализуемая в разумные сроки.
На текущем проекте я ровно один раз провел аудит ролей вручную (потратил примерно неделю, в фоновом режиме) и больше никогда в жизни не хочу этим заниматься.
При этом тесты, которые проверяют ровно тоже самое, прогоняются на нашей УХе максимум 10 минут.
10 минут автоматически или неделя рабочего времени – существенная разница.
Тест 2.07 проверяет еще и корректность нарезки атомарных ролей. Его мы пока не выложили публично. Как только перенесем все настройки наружу в настроечный файл – выложим.

Третья группа тестов проверяет соответствие регламенту разработки.
Очень надеюсь, что у всех есть регламент разработки, хотя бы в виде избранных стандартов с ИТСа.
Обычно судьба регламента разработки на любом проекте одинакова: в лучшем случае новый разработчик прочитает его в первый день работы, а все дальнейшие его изменения разработчику уже будут совсем не интересны. И пока мы не начнем требовать от разработчиков исправлять все нарушения регламента, никто ему не будет следовать.
Поскольку нам не хотелось тратить свое время на то, чтобы находить стандартные нарушения регламента вручную, мы решили покрыть дымовыми тесты все, что можно проверить автоматизированно.
Например, у нас есть тесты:
-
Проверка объектов метаданных конфигурации поставщика – мы проверяем, чтобы наши разработчики ничего из конфигурации поставщика не удалили. У нас разработка ведется в EDT, конфигурация снята с поддержки – можно удалить вообще все что угодно. Да, есть специальный плагин для запрета, но при масштабной разработке его использование вызывает определенные сложности.
-
Проверка префикса в предопределенных элементах и Проверка префикса в новых объектах и реквизитах – проверяем, чтобы разработчики не забывали ставить префиксы нашим объектам и добавленным реквизитам.
-
Проверка префикса свойств новых объектов – наоборот, если объект с префиксом, реквизит у него должен быть без префикса.
-
Проверка синонима объектов и свойств с префиксом – проверяем, чтобы в синонимах объектов не было префикса.
-
Проверка включения объектов с префиксом в подсистему – для быстрой фильтрации внутри конфигурации все наши новые объекты должны быть включены в одну их служебных подсистем..
-
Проверка форм новых объектов по шаблону – конфигурации у нас сложные, недостаточно просто создать новый справочник и документ, требуется также его единообразно наполнить в соответствии с исходной конфигурацией.
Все формы должны соответствовать единому интерфейсу, в них должны поддерживаться все нужные нам механизмы (наши или БСП).
Мы для каждой конфигурации реализовали шаблоны. Они прямо так и называется: «Справочник.Шаблон», «Документ.Шаблон» – в таких шаблонах содержатся все формы и все минимальное наполнение, которое должно быть во всех наших справочниках/документах.
Когда разработчик приступает к созданию нового объекта, он должен его создавать не с нуля, а копировать и обогащать имеющийся шаблон.
Таким образом, на выходе получается стандартизированная форма и общие механизмы.
Сам тест проверяет, что формы новых объектов соответствуют шаблонам по-элементно.
Причем у нас там есть еще и сущность – версия шаблона. Если мы с какого-то момента решили шаблон поменять, мы также меняем номер версии в шаблоне.
Тест покажет, какие формы сделаны на устаревшей версии и их требуется актуализировать. -
Проверка реквизитов документов «Комментарий» и «Ответственный»
-
Проверка вариантов отчетов – мы используем стандартную подсистему БСП «Варианты отчетов».
Например, на нашей текущей УХ около 150 штук новых добавленных отчетов.
Все отчеты должны быть размещены в панели отчетов и не выводится непосредственно в интерфейс. Также в каждом отчете должно быть задано описание вариантов отчета - что это за отчет и какие данные он показывает.
Тест проверяет, что у нас, во-первых, все эти отчеты не выведены непосредственно в интерфейс, варианты имеют понятные названия и задано описание варианта.
Какое именно описание – уже другой вопрос. Это мы смотрим на код-ревью.

Еще одна особенность нашей версии Vanessa ADD – это механизм пропуска тестов.
Когда мы запускаем полный набор дымовых тестов, мы хотим быть уверенными, что все тесты точно отработали.
Некоторые тесты могут не запускаться – просто из-за того, что для них нет данных. Например, у меня на проекте есть конфигурация, где нет вообще ни одного документа – там проверять проводки документов не имеет смысла.
Если тест пропущен по настройке либо отсутствуют тестовые данные, он отображается серым цветом и помечается как «Пропуск теста», а в описании указывается причина – что именно с ним произошло.
Т.е. в нашей версии отчета Allure всегда показываются результаты по всем тестам. Тем более, что все тесты пронумерованы по порядку и визуально сразу видно, что ничего не потерялось.
Установка и использование

Теперь о том, как все это устанавливать и использовать:
-
Есть файл env.json, где задаются базовые параметры, чтобы не указывать их в команде запуска cmd-файла. Пример env.json выложен в репозитории, но возможность его использовать была и в стандартном фреймворке – это не то, что мы придумали.
-
Есть два служебных файла Vendor.json и Vendor_predefined.json, где хранятся структура объектов конфигурации поставщика и предопределенные элементы поставщика.
Так исторически сложилось, что их два, и мы не стали объединять их в один.
Эти файлы нужны для того, чтобы понять, какие объекты или реквизиты объектов в конфигурации наши, а какие – пришли от вендора. -
Чтобы вручную эти служебные файлы не создавать, в репозитории выложена обработка ВыгрузкаОбъектовМетаданныхКонфигурации.epf. Открываете демо-базу чистого типового релиза, запускаете эту обработку, нажимаете «Сохранить» и указываете каталог – она выгружает вам два этих файла в нужном формате.
-
Файл smoke.json – именно в нем сейчас хранятся настройки тестов..
-
Мы используем два cmd-файла для ручного прогона тестов. Они нужны в тех случаях, когда не используется контур ci и мы просто хотим прогнать набор дымовых тестов локально, на своей машине:
-
Первый файл – smoke_run.cmd. Он очищает результаты предыдущих прогонов и запускает тесты на выполнение. Для файла smoke_run.cmd в папке examples репозитория есть три примера – для запуска на файловой и серверной базах, а также для прогона только общих тестов.
-
Второй файл – smoke_allure.cmd, запускает Allure. Сам Allure у нас есть прямо внутри репозитория, ничего дополнительно устанавливать не надо. Запускаете и он покажет последний результат прогона тестов.
-
-
Если говорить про большие системы, где используется контур ci, то для них мы вынесли все тесты в отдельный служебный репозиторий, предназначенный именно для автоматических унифицированных шаблонов и тестов. Получается, что у нас для различных систем используется единый набор тестов. Разница только в настройках.
-
Чтобы смотреть результаты прогонов, мы публикуем отчеты Allure на отдельном веб-сервере. Пайплайны публикуют результаты прогона тестов там и оттуда их может посмотреть любой пользователь, даже без учетки в гитлабе.
Работа с возражениями

Обычно, когда приходишь в команду и говоришь: «Я вам принес классный инструмент, давайте его попробуем!», все кивают: «Да, здорово, интересно! Спасибо, что рассказал! Но использовать мы его, конечно, не будем». И в качестве аргументов всегда говорят примерно одно и то же в разных вариациях:
-
«Нам нужно обучение: мы сначала курсы пройдем, научимся, а потом через полгодика посмотрим». Здесь никакого дополнительного обучения не нужно. Понятно, что на первоначальную настройку, возможно, придется потратить условно неделю, но этого достаточно. Выделите одного разработчика, он за неделю все запустит, и больше никого дополнительно учить не надо – все тест-кейсы генерируются автоматически.
-
«Нужны отдельные люди на тесты». Вообще не нужны. Фишка в том, что тест-кейсы генерируются автоматически на основании метаданных. Максимум, что нужно – это забивать исключения, но это минимальные трудозатраты на уровне погрешности.
-
«Нужен DevOps и инфраструктура» – то же самое. Здесь плюс в том, что никакой инфраструктуры в принципе не требуется. Я могу просто накатить CF-файл релизной сборки на свою локальную базу и прямо на ней прогнать тесты. Мне для этого не нужен никакой CI/CD контур. Я прямо на своей машине это делаю и на ней же в браузере смотрю результаты отчета Allure. Не нужно получать административные доступы, согласовывать свои действия с безопасниками, и все остальное.
-
«Это приведет к удорожанию разработки». Если для сценарного тестирования такое возражение справедливо, то для дымового – нет. Тут затрат – буквально копейки. Максимум потратить 5 минут на то, чтобы новые исключения забить, если тест упал, и вы проверили, что это действительно исключение. Либо это ошибка, и тогда ее нужно поправить. Но никакого удорожания по сути нет.
Единственная затрата – первоначально это запустить, и все, дальше оно работает само.
Если для запуска сценарных тестов надо со всеми договариваться, убеждать, выстраивать процессы, то для дымовых ни с кем договариваться не нужно.
Можно и в одиночку на своем компьютере все это запустить и проверять. Польза от дымовых тестов есть, ловится что-то регулярно.
Зато будет подстраховка при выпуске релиза, потому что выпускать релиз вообще без тестов – неразумно. Надо хотя бы минимальный набор тестов прогонять.
И в завершение – минутка занимательной информации. Если настроить дымовые тесты и прогнать их на демо-базах типовых конфигураций – практически везде найдутся ошибки: где-то не открывается форма, где-то – не формируется отчет или не записывается справочник. Я ловил подобные случаи практически в каждой конфигурации, поэтому и решил поделиться нашими наработками. И если для меня использовать дымовые тесты – это уже что-то само собой разумеющееся, то в сообществе их почему-то пока не все используют. А это нужно.
Вопросы и ответы
Обратил внимание, что у вас порядка 70 тысяч тестов. Сколько времени занимает их выполнение? И какую базу вы используете для прогона – нужно ли ее как-то дополнительно заполнить или настроить?
Для дымового тестирования мы используем ту же базу, что и для демонстрации – ту, в которой готовятся примеры для показа нашей работы заказчику. Разворачиваем локально бэкап этой базы и прогоняем тесты.
По времени: на моем компьютере полный прогон занимает около 50 минут. Если исключить тесты на открытие форм, время сокращается примерно вдвое, потому что половина времени уходит именно на открытие форм. В ci-пайплайне тесты проходят ночью – там это занимает порядка двух часов, потому что используется Linux и там чуть более сложная инфраструктура.
Почему эти изменения не попали в основной репозиторий Vanessa ADD?
Потому что изначально я все делал для себя – как внутренний инструмент. А когда работаешь сам, можно двигаться быстрее: не нужно никого спрашивать, согласовывать, ждать проверок. Сделал, работает – и отлично.
Мы договорились, что по ошибкам я сделаю pull request.
Есть ли смысл запускать тесты по всем объектам метаданных, если клиент какие-то метаданные не использует – например, работает только с небольшой частью отчетов?
Это же быстрые тесты. Они почти не занимают времени. Если вам нужно проверить корректность работы конкретных важных отчетов – тогда это уже сценарные тесты, а не дымовые. В сценарных тестах важно не просто убедиться, что отчет формируется, но и что он отображает корректные данные. Такие тесты пишем только на ключевые отчеты, которые критичны для пользователей.
Vanessa Automation вам не нравится, потому что там нужно писать feature-файлы?
Vanesa Automation мне нравится – в ней удобно писать сценарные тесты. Но в части дымовых тестов у нее каждый тест – это отдельный feature-файл. А у меня в день добавляется по 20 документов, и каждый раз генерировать на них feature-файлы (или учить всех разработчиков, как это делать) – слишком трудоемко.
Мне больше нравится подход к дымовому тестированию, реализованный в Vanessa ADD.
Вообще, если посмотреть на пирамиду тестирования, дымовые тесты находятся в самом низу – под юнит-тестами. Потому что дымовым тестам не нужно обучать разработчиков, развивать культуру тестирования – просто настраиваешь, и все работает.
Насколько я понял, готовых настроек под ERP в репозитории сейчас нет. Насколько трудоемко будет их добавить?
Мы делаем настройки только тогда, когда в них есть потребность. Сейчас в репозитории сделаны ветки под ЗУП, Управление холдингом и БСП, и скоро добавятся настройки под MDM НСИ. Отличия между ветками – только в настройках.
Еще в ближайшее время у нас будет проект по ERP Управление холдингом – для него настройки, скорее всего, тоже будут добавлены. Тогда можно будет сравнить эти настройки с файлом для Управления холдингом – и дельта, скорее всего, подойдет под ERP.
Или вы можете сами подготовить настройки для ERP и выложить в их в виде pull-request’а. В этом, собственно, смысл open source – каждый может внести свой вклад. Мы выложили свои наработки, а кто-то их доработает под ERP, и все смогут использовать общие результаты. Это гораздо продуктивнее, чем когда каждый разрабатывает свой инструмент в изоляции.
А как вы проверяете, что после релиза движения документа поменялись местами – строки те же, цифры те же, но порядок другой?
В тесте по проверкам проводок документа есть настройка "СравнениеДвиженийБезНомераСтроки":true, при помощи которой мы можем сравнивать движения, игнорируя порядок строк. Нам же главное, чтобы в наборе движений совпадало общее количество строк и суммы движений по приходу и расходу. А если до перепроведения было пять строк, а после перепроведения – 17, это уже ошибка.
А тест просто фиксирует старые движения документа, перепроводит документ в транзакции, получает новые движения, откатывает транзакцию и сравнивает две таблицы.
Насколько быстро можно собрать исключения по объектам метаданных, если мы только начали тестировать новую базу?
Можно взять готовые настройки из репозитория и при необходимости их доработать. Когда я впервые настраивал тесты, я просто запускал тестирование вручную и проверял, где падает – ошибка это или ожидаемое поведение. Если это не ошибка – добавлял в список исключений. И прогонял заново до тех пор, пока все исключения не будут зафиксированы в настройках.
А внешние отчеты и обработки в дымовых тестах тоже учитываются?
Они тестируются точно так же, как и встроенные отчеты и обработки. Но для них же сначала нужно установить в демо-базу актуальные версии. Для этой цели у меня есть отдельный репозиторий с расширением, которое позволяет держать исходники внешних отчетов и обработок в Git, дорабатывать их там и «по кнопке» актуализировать версии в базе – я даже писал статью про это когда-то.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт