





{kind=link}
Преамбула:
Думаю, следует, как обычно, начать с общих понятий, и уже потихоньку опущусь к самой конфигурации. Эта публикация больше может показаться и статьей...
Вступление:
А все началось с того, что на сервере просто в какие-то из моментов попросту пропала память.
Процессор: 2х Intel Xeon X5660 2.8 ГГц
ОЗУ: 96 ГБ.
ОС:Win server 2008 R2 enterprise SP1 64x
MS SQL Server 2012. Выделено памяти 50 ГБ.
1С Сервер 64 (8.3.6.2237)
УТ11 (11.1.9.56) – 9 баз. Самая большая база – 110 Гб, Общий объем баз- 150 ГБ
Поднимались соответсвующие вопросы на официальном сайте партнеров, но, как обычно время шло, проблема жила. То есть нет на сегодняшний день никакой панацеи - это очень и очень хлопотный труд, и готовьтесь пройти полный [...цензура...] до решения этой проблемы. Я уж и не говорю, сколько пришлось промониторить объемов журнала и сколько раз настроить кластер сервера 1С, чтобы в какой-то момент утечка просто пропала. То есть получается, что нет чего-то конкретного, чтобы Вы нажали что-то и у Вас утечки ушли, эта работа очень комплексная и устранять придется все комплексно и, как мне кажется, каждый из случаев уникальный, кому-то просто помогает перезапуск rphost. ТЖ не показывает утечку памяти, а лишь только на подозрение, то есть показывает, какой объем памяти был не освобожден. Вот только ТЖ не знает о том, что этот объем памяти мог быть освобожден в действительности только позже. Это очень просто воспроизвести обычно на штатном отчете Товары организаций в УТ 11, в ТЖ будут идти как бы утечки, но rphost.exe потом освободится, и такого рода поиск очень сильно ставит в тупик с поиском утечек в коде 1С... Но все же, вручную анализировать такие талмуты файлов просто нереально и хочется иметь хоть какой-то инструмент, в котором можно будет быстренько наложить определенные отборы, например, в момент проблем, которое попало в счетчики Perfomence Monitor и дальше иметь хоть какую-то картинку.
В БОЙ !!!
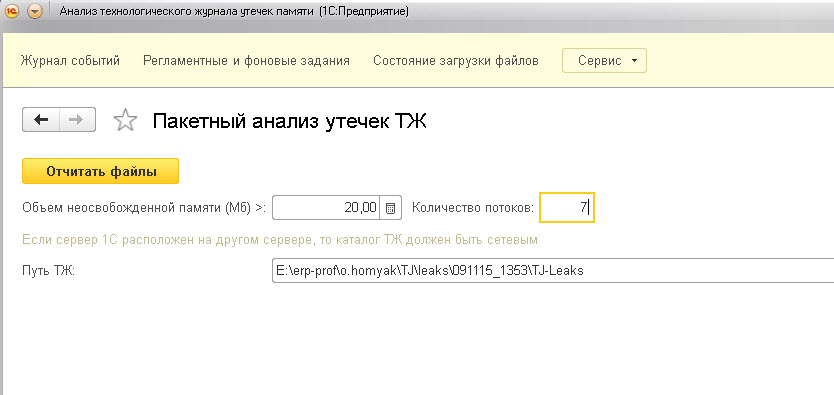
Для использования конфигурации следует использовать платформу не младше 1С:Предприятие 8.3 (8.3.6.2237). Конфигурация рассчитана для клиент-серверного использования. Здесь я сделал подход отчитки файлов в несколько потоков, максимум можно задействовать 7 потоков, но следует вначале проэкспериментировать и поэтому по умолчанию установил 1 поток. Потому как отчитка файлов очень серьезно нагружает кластер, если задействовать много потоков, будьте внимательны.
Как работать с конфигурацией?
Когда готовы файлы ТЖ, необходимо их скопировать в отдельный каталог или отключить запись ТЖ, поскольку в реал-тайме 1С удерживает файлы и не дает к ним доступа для чтения.
Разворачиваем конфигурацию на серверной площадке. В меню Сервис, выбираем "Пакетный анализ утечек ТЖ", после чего необходимо указать каталог ТЖ. Размещение должно быть таковым, чтобы после родительского каталога шли каталоги rphost_. Анализируются только каталоги первого уровня и только с маской rphost_. В меню сервис также есть обработка отчитки конкретного лог-файла, результат которой будет выведен визуально в табличной части. Бывают моменты, что надо проанализировать только определенный файл для понимания.
Хочу подчеркнуть, что здесь будут загружены только те свойства, у которых есть значение Memory, и они в указанном пороге Мб (даный порог рассчитывается, поскольку в ТЖ указано в байтах). Также система пытается найти после события CALL или SCALL свойство LEAKS и, если находит, то автоматически привяжет его к текущему событию вызова.
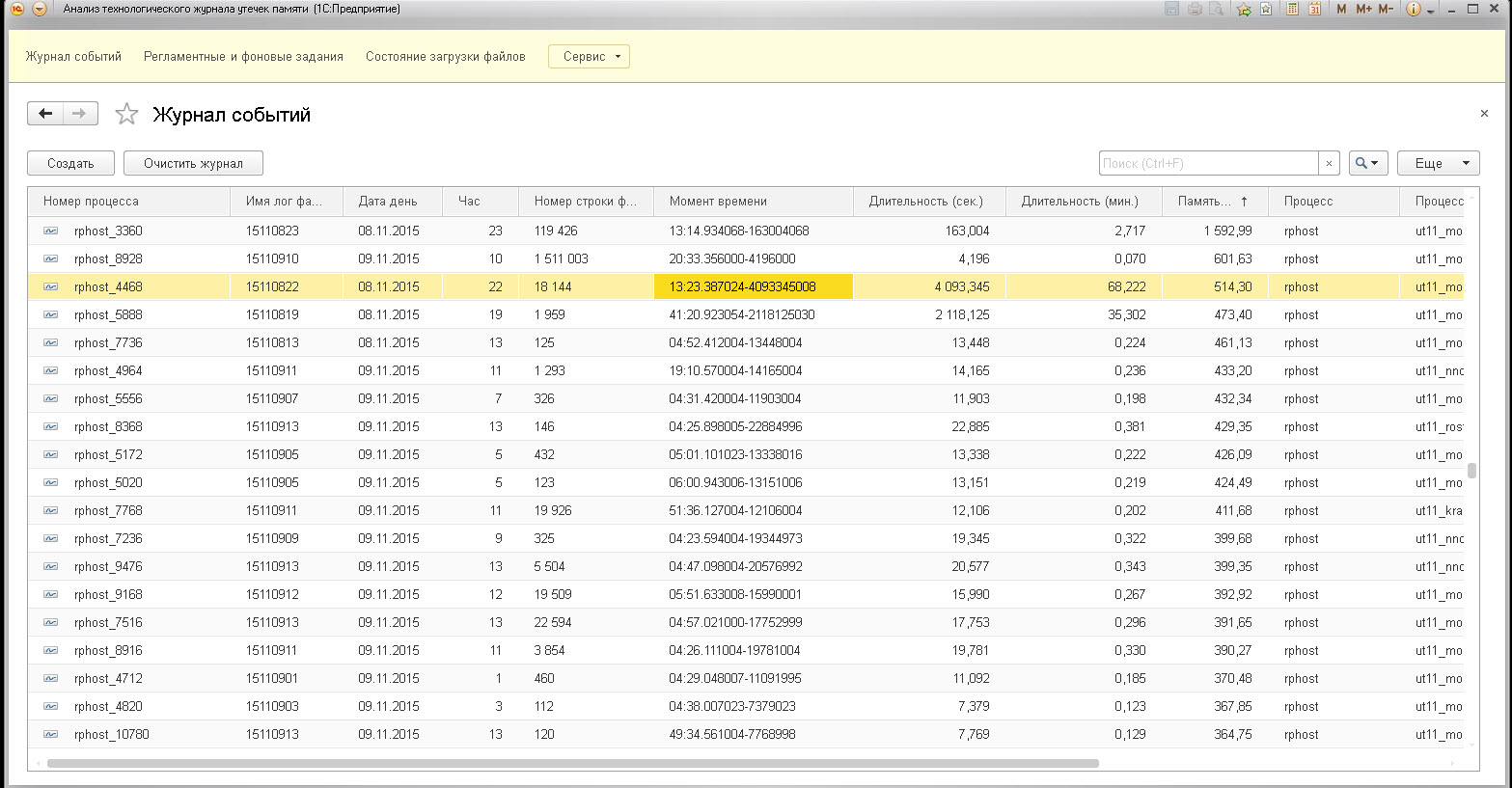
В меню регламентые и фоновые задания можно просмотреть процесс выполнения, а также более конкретно можно это увидить в "Состояние загрузки файлов", где видно, какой именно файл загружает или уже загружен и каким из потоков фоннового задания. Обработано строк с шагом обновления 1000 строк (так что не удивляемся, если файл в состоянии Готов и 0 строк)
Рекомендации:
Рекомендации по настройке logcfg.xml, для анализа не следует перегружать журнал другими настройками, я не могу гарантировать адекватного поведения отчитки данных.
<?xml version="1.0" encoding="UTF-8" ?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log location="D:\TJ-Leaks" history="24">
<event>
<eq property="name" value="call" />
</event>
<event>
<eq property="name" value="leaks" />
</event>
<property name="all" />
</log>
<leaks collect="1">
<point call="server" />
</leaks>
</config>
Также весьма рекомендую использовать редактор EmEditor Professional сайт разработчиков для интерактивного открытия log-файлов больших размеров. 1С , во-первых, открывая такой файл, очень сильно забирает память и во-вторых если она файл не может открыть то просто вылетит. Редактор порадовал, ограничение его 254 Гб текстового файла и самое интересное, открыв файл в 2.5 Гб я увидил лишь 300 Мб которую взял на себя данный редактор.
Паралельно разрабатывая эту конфигурацию наблюдал такое:
Точнее сказать, здесь ничего такого нет и понятно, что для склеивания одной строки с другой нужно время, чтобы выделить участок памяти. Вопрос, а если времени нет и это влияет на производительность, что тогда? Благо разработчики 1С дали такой выход, и эта возможность появилась с релиза 8.3.6.1977. Сразу хочу подчеркнуть, что эти функции не будут работать, если конфигурация работает в режиме совместимости. Так вот, выкладываю замеры (прикрепил изображение с замером наблюдения) производительности при обычном склеивании строк и при использовании новой возможности СтрСоединить().
В закомментированой части кода, не побоюсь этого слова, поражающее ускорение, что в принципе порадовало. И, в общем, мне удалось сэкономить не одну минуту работы. Поскольку файлы анализа более 6 млн. строк.
Собственно, только хотел поделиться интересной заметкой. Для начала, чем бежать и переписывать все склеивания строк, думаю, следует просто убедиться, что выигрыш действительно будет.
Выдержка из синтаксис помощника:
Глобальный контекст (Global context)
СтрСоединить(<Строки>, <Разделитель>)
Тип: ФиксированныйМассив; Массив.
Массив, содержащий объединяемые строки.
Тип: Строка.
Строка, которая будет вставлена между объединяемыми строками.
Если параметр не задан, строки будут объединены слитно друг с другом.
Значение по умолчанию: Неопределено.
Тип: Строка.
Строка, содержащая соединенные исходные строки с разделителем между ними.
Соединяет массив переданных строк в одну строку с указанным разделителем.
Доступность:
Тонкий клиент, веб-клиент, сервер, толстый клиент, внешнее соединение.
Спасибо всем, кто нашел время и дочитал все это до конца и решился попробовать этот инструмент.
Вступайте в нашу телеграмм-группу Инфостарт