


{kind=link}
В данной статье покажу еще один инструмент хранения и визуализации записей журнала регистрации 1С.
Входная задача: Небольшая конфигурация на 1С Предприятие 8.2. Максимальная суточная активность - 150 чел. Информационная база генерирует ~ 0,5 млн записей логов в рабочие дни. Логи необходимо хранить в сторонней БД MS SQL. Также необходим гибкий инструмент хранения и визуализации логов, как текущего так и прошлого периода (3-5 лет). Использовать стек ELK (Elastic + Logstash + Kibana).
Решение: Будет реализована следующая инфраструктура:
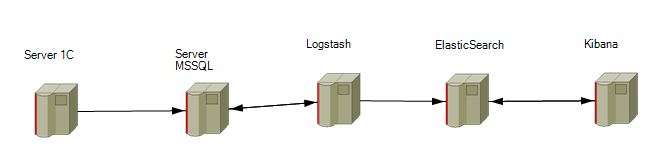
Последовательность действий:
1. Запись журнала регистрации 1С в базу MS SQL;
2. Отправка логов 1С из MS SQL в ElastisSearch;
3. Визуализация логов 1С в Kibana.
Реализация.
Запись журнала регистрации 1С в базу MS SQL
Механизм реализовал Алексей Бочков, описание и исходники в статье //infostart.ru/public/182820/
Для того, чтобы Logstash понимал, какие записи уже были отправлены в Elastic, а какие появились с момента последнего запуска - необходимо в таблице Events создать инкрементное поле id_log типа bigint (+ 8 байт на запись). Для этого в MS SQL Server Management Studio достаточно выполнить запрос:
USE [log1c]
ALTER TABLE [log1c].[dbo].[Events] ADD id_log bigint identity
где log1c - имя базы данных с логами.
В итоге, имеем базу данных MS SQL с актуальными логами информационной базы 1С, которые периодически считываются из файла ЖР.
Отправка логов 1С из MS SQL в ElastisSearch
На том, как устанавливать стек ELK (Elastic + Logstash + Kibana) останавливаться не буду, т.к. в Интернет есть много подробной информации. Например, установка на Windows, установка на Linux.
ПО на сервера установлено, переходим к настройке. Для загрузки из базы MS SQL в Logstash будем использовать jdbc-input-plugin.
На сервере Logstash внесем изменения в конфигурационный файл
input {
jdbc {
jdbc_driver_library => "C:\logstash-2.3.4\jdbc2\sqljdbc_4.2\rus\sqljdbc41.jar"
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
jdbc_connection_string => "jdbc:sqlserver://10.4.2.147\MSSQLSERVER:1433;DatabaseName=log1c"
jdbc_user => "logstash"
jdbc_password => "Qwerty123"
jdbc_fetch_size => "100000"
#clean_run => true
last_run_metadata_path => "C:\logstash-2.3.4\last_run\last_run"
statement_filepath => "C:\logstash-2.3.4\bin\SQLQuery.sql"
schedule => "* * * * *"
tracking_column => id_log
use_column_value => true
}
}
filter {
date{
target => "datetime"
match => ["datetime", "YYYY-MM-dd HH:mm:ss.SSS", "MMM dd YYYY HH:mm:ss.SSS", "ISO8601"]
}
}
output {
elasticsearch {
hosts => "10.4.2.90:9200"
index => "log1c-%{index_elastic}"
}
}
Разберем настройки подробнее.
jdbc_driver_library - путь к библиотеке jdbc драйвера, скачиваем с официального сайта
jdbc_driver_class - класс jdbc драйвера. Для MS SQL это "com.microsoft.sqlserver.jdbc.SQLServerDriver"
jdbc_connection_string => "jdbc:sqlserver://10.4.2.147\MSSQLSERVER:1433;DatabaseName=log1c" - 10.4.2.147 - IP адрес сервера MSSQL, MSSQLSERVER - Instance Name заданный при установке, 1433 - порт, log1c - БД с логами.
jdbc_user, jdbc_password - логин/пароли для доступа к БД
jdbc_fetch_size - размер выборки из БД
tracking_column - имя колонки, значение которой будет отслеживаться (то самое инкрементное поле id_log)
last_run_metadata_path - путь к файлу, где храниться значение отслеживаемой колонки
use_column_value => true - включаем использование отслеживаемого столбца (на запрос будет добавляться условие Where, в параметр sql_last_value будет вставлено значение из файла last_run_metadata_path)
statement_filepath => "C:\logstash-2.3.4\bin\SQLQuery.sql" - путь к файлу с запросом SQL
schedule => "* * * * *" - расписание, периодического выполнения запроса к БД, в формате Cron.
Текст запроса в файле "C:\logstash-2.3.4\bin\SQLQuery.sql"
SELECT
e.*
,i.[Name] AS "InfobaseName"
,a.[Name] AS "AppName_str"
,c.[Name] AS "ComputerName_str"
,et.[Name] AS "EventName"
,mp.[Name] AS "MainPorts"
,sp.[Name] AS "SecondPortsName"
,md.[Name] AS "MetadataName"
,md.[Guid] AS "MetadataGUID"
,s.[Name] AS "ServerName"
,u.[Name] AS "UserName_str"
,u.[Guid] AS "UserGUID"
,FORMAT(e.[datetime], 'yyyy-MM', 'en-US') as 'index_elastic'
FROM [log1c].[dbo].[Events] e
left join [log1c].[dbo].[Infobases] i ON (e.[InfobaseCode] = i.[Code])
left join [log1c].[dbo].[Applications] a ON (e.[InfobaseCode] = a.[InfobaseCode] AND e.[AppName] = a.[Code])
left join [log1c].[dbo].[Computers] c ON (e.[InfobaseCode] = c.[InfobaseCode] AND e.[ComputerName] = c.[Code])
left join [log1c].[dbo].[EventsType] et ON (e.[InfobaseCode] = et.[InfobaseCode] AND e.[EventID] = et.[Code])
left join [log1c].[dbo].[MainPorts] mp ON (e.[InfobaseCode] = mp.[InfobaseCode] AND e.[MainPortID] = mp.[Code])
left join [log1c].[dbo].[SecondPorts] sp ON (e.[InfobaseCode] = sp.[InfobaseCode] AND e.[SecondPortID] = sp.[Code])
left join [log1c].[dbo].[Metadata] md ON (e.[InfobaseCode] = md.[InfobaseCode] AND e.[MetadataID] = md.[Code])
left join [log1c].[dbo].[Servers] s ON (e.[InfobaseCode] = s.[InfobaseCode] AND e.[ServerID] = s.[Code])
left join [log1c].[dbo].[Users] u ON (e.[InfobaseCode] = u.[InfobaseCode] AND e.[UserName] = u.[Code])
WHERE
e.id_log > :sql_last_value
Итого, при первом запуске Logstash в Elastic выгрузятся все записи из БД log1c (sql_last_value=0), при последующем запуске будут считываться только вновь добавленные записи (последнее считанное значение id_log будет храниться в файле last_run_metadata_path и передаваться в качестве переменной через sql_last_value)
Визуализация логов 1С в Kibana
Если ElasticSearch и Kibana установлены на одном сервере, то дефолтных настроек будет достаточно. В нашем случае - на разных серверах, поэтому необходимо внести правки в конфигурационные файлы.
Для ElasticSearch в файл elasticsearch.yml
network.host: ["127.0.0.1", "10.4.2.90"]
network.port: 9200
discovery.zen.ping.unicast.host: [IP_адреса]
Для Kibana - файл kibana.yml
server.port: 5601
server.host: "10.4.2.91"
elasticsearch.url: "10.4.2.90:9200"
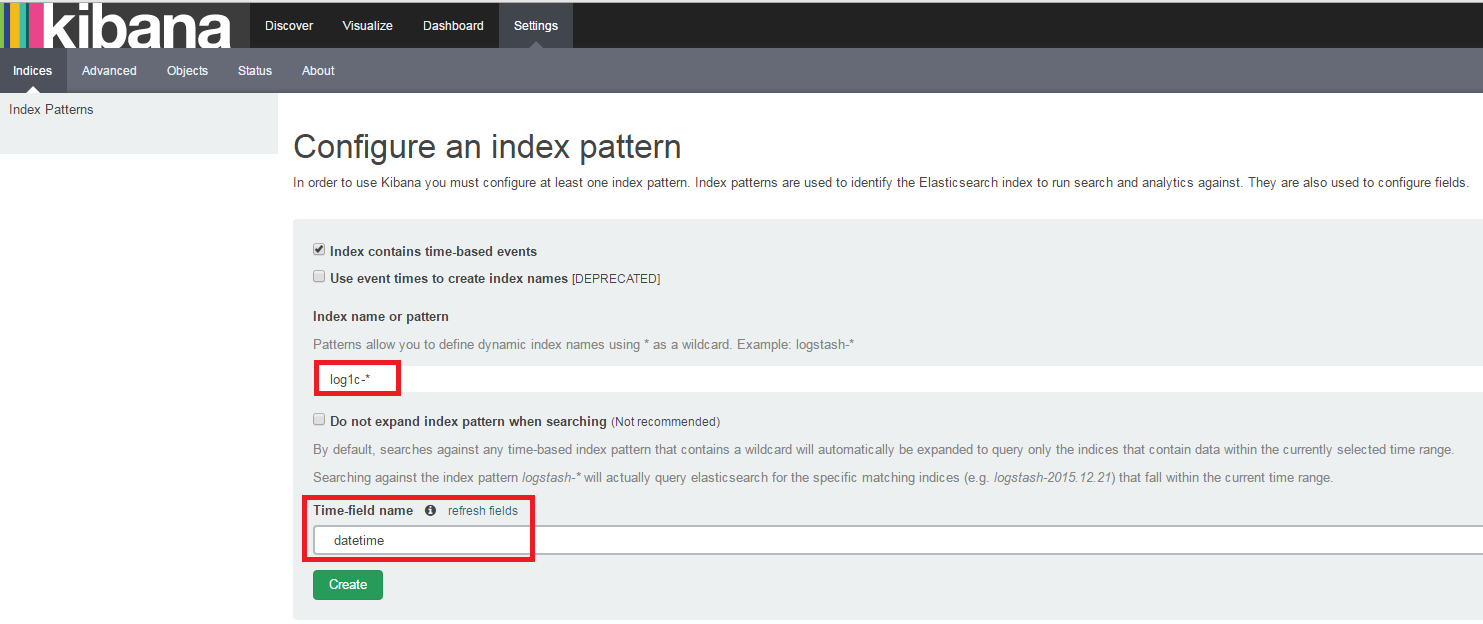
Самая приятная часть - анализ и визуализация логов. Вводим в браузере "10.4.2.91:5601", на вкладке Settings создаем новый шаблон индекса:

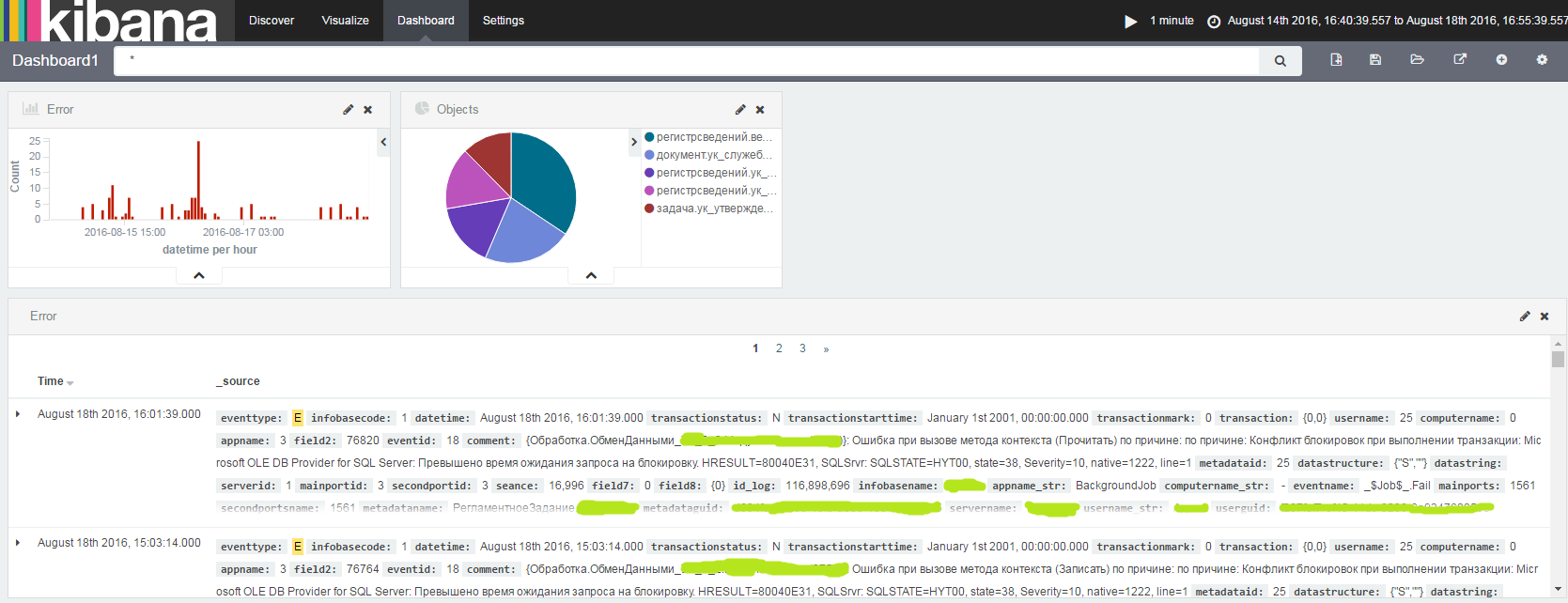
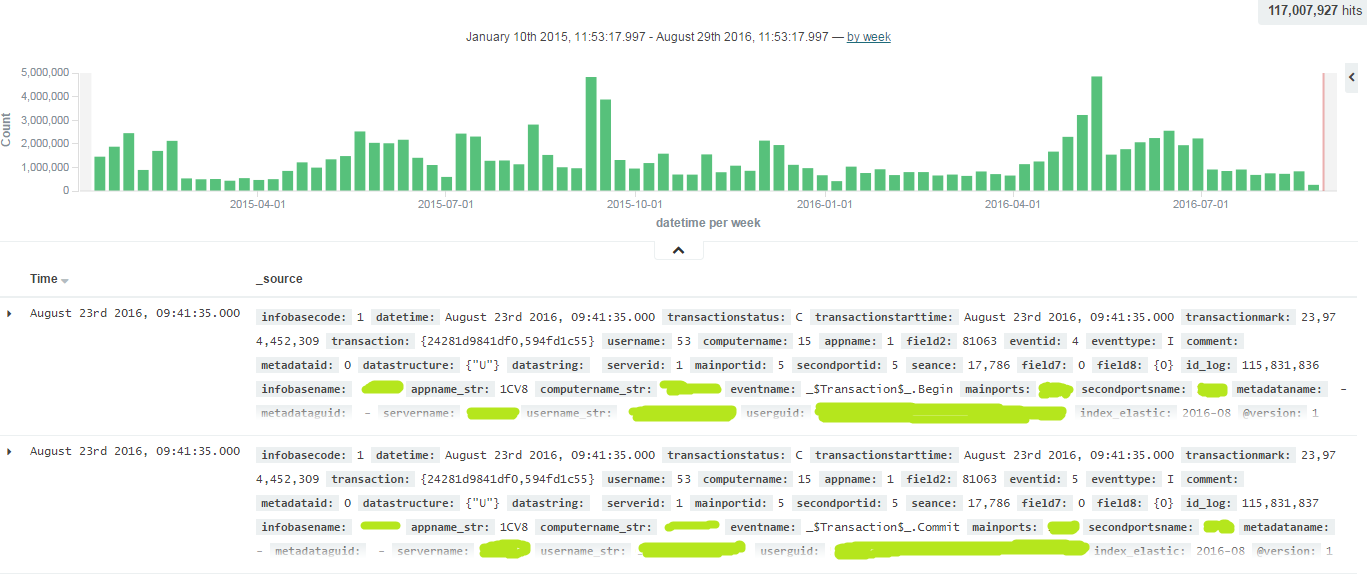
На вкладке Discover появятся все логи журнала регистрации 1С:

Запрос на сервер Elastic для отбора всех ошибок ЖР:
{
"query": {
"match": {
"eventtype": {
"query": "E",
"type": "phrase"
}
}
}
}
Все поиски и визуализации можно вывести на dashboard, задать период анализа логов (например за последний час) и частоту обновления из Elastic.

Возможности резервного копирования и восстановления в ElasticSearch реализованы очень интересно. Управление через HTTP запросы в формате JSON.
Сначала, необходимо создать репозиторий.
curl -XPUT 'http://l0.4.2.90:9200/_snapshot/backup1' -d '{
"type": "fs",
"settings": {
"location": "/elastic-backup",
"compress": true
}
}'
где type - тип хранилища, куда будут складываться бэкапы. Для дефолтной установки доступна только файловая система. С дополнительными плагинами можно реализовать хранение на Azure Cloud, HDFS и AWS S3.
location - путь хранения
compress - сжимать ли бэкапы, по умолчанию true.
Репозиторий создан, можно бэкариповать - создадим snapshot1 в репозитории backup1:
curl -XPUT "10.4.2.90:9200/_snapshot/backup1/snapshot1?wait_for_completion=true"
Для восстановления данных:
curl -XPOST "10.4.2.90:9200/_snapshot/backup1/snapshot1/_restore"
Посмотреть текущие индексы:
curl -XGET "10.4.2.90:9200/_cat/indices/?pretty"
Удалить индекс "log1c-2014-02" - все логи за февраль 2014 г.:
curl -XDELETE "10.4.2.90:9200/log1c-2014-02/?pretty"
Более полный список команд по работе с ElasticSearch - тема для отдельной статьи.
Замечания:
1) В данной статье не рассматриваются вопросы безопасности/разграничения доступа к ElasticSearch/Kibana, настройка сертификатов, кластеризация и масштабирование ElasticSearch, т.к. это не входило в изначальную задачу.
2) Выбранная архитектура миграции логов 1С -> MS SQL -> ELK обусловлена только лишь поставленной задачей. В Production логи не будут храниться в БД и ElasticSearch, дублирую друг друга.
3) Размер БД в 500 ГБ уже требует большого количества ресурсов и операций чтения с диска при выполнении запроса от Logstash к MS SQL. Можно было бы на MS SQL создать архивную БД, в которую выгружать прочитанные Logstash'ом данные. Тогда таблица, в которую пишутся данные из 1С и читаются в Logstash, будет иметь небольшой объем (буфер).
Итоги по задаче. В ходе выполнения задачи, была достигнута главная цель статьи - демонстрация механизма получения и анализа данных в ElasticSearch из БД MS SQL.
Спасибо.
P.S. Возможно, вам будет интересна предыдущая статья Мониторинг количества сеансов 1С на базе PRTG
Вступайте в нашу телеграмм-группу Инфостарт