




Немного занимательной теории и практики
Нейросеть можно рассматривать в виде черного ящика с некоторыми входами и выходами. Ключевой особенностью, привлекающей исследователей, является то, что она умеет обучаться и абстрагировать входные данные, т.е. в некотором смысле «думать». Чаще мы слышим, что их используют для распознавания чего-либо (изображения, голоса), но меня в рамках данной работы интересует «распознавание закономерностей» входных данных. А конкретно – распознавание нейросетью экономических данных и параметров бизнес процессов – того, чем наполнены базы данных 1С.
Т.е., говоря математическим языком, нейросеть может научиться отображать любую функцию входных сигналов. Это может быть как простейшая зависимость (линейная, парабола), так и то, что с помощью математической функции выразить невозможно(как раз то, что и бывает в жизни). Т.е. сеть может научиться понимать любой принцип и использовать его на данных, которых не было в обучающей выборке, и это не простое запоминание примеров и не простая экстраполяция. Это гораздо больше того, что можно получить с помощью обычной статистики.
Пример 1
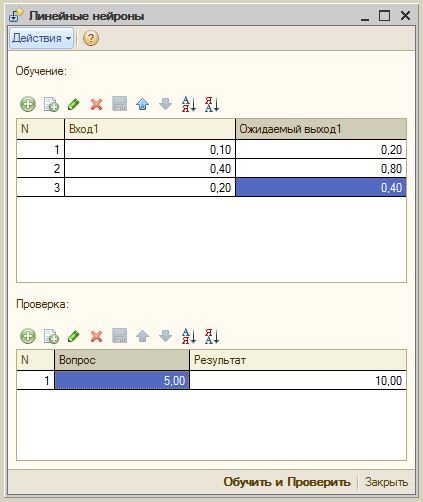
Для проверки этой гипотезы я сделал самую простую сеть, состоящую из линейных нейронов. У нее 1 вход, 1 выход и 10 нейронов вообще без функции активации (тестовая обработка ЛинейноеПрохождение). И провел с ней эксперимент.
Важно! В тестовой обработке я не делал нормализацию(в отличии от рабочей), поэтому на вход надо подавать числа от 0 до 1: 0.1, 0.2 и т.д.

Я подавал на вход число от 0 до 1, а на выход это число, умноженное на «2» как на картинке. И сеть, обучившись, понимает и это, т.е. понимает, что 5*2=10,6*2 = 12 и т.д.! При этом само действие умножение нигде не прописано в явном виде. Т.е. сеть, обучившись, поняла принцип. С таким же успехом можно научить ее «делить на 3», «прибавлять 5» и т.д. Фантастика! Рекомендую попробовать самим.
Пример 2.
На самом деле линейные нейроны и однослойные сети могут мало чего. Если я ничего не путаю, то вроде есть даже теорема, доказывающая, что линейные нейроны могут отобразить только линейную зависимость. По крайней мере если попробовать вводить что-то типа «корень из двух», «корень из 3х» и т.д. а потом проверить результат. то получается совсем пальцем в небо. К тому опять же доказано, что количество слоев в такой сети также не имеет значения (что один что 2 – все равно), а это уже не интересно, т.к. именно в скрытых слоях происходит магия.
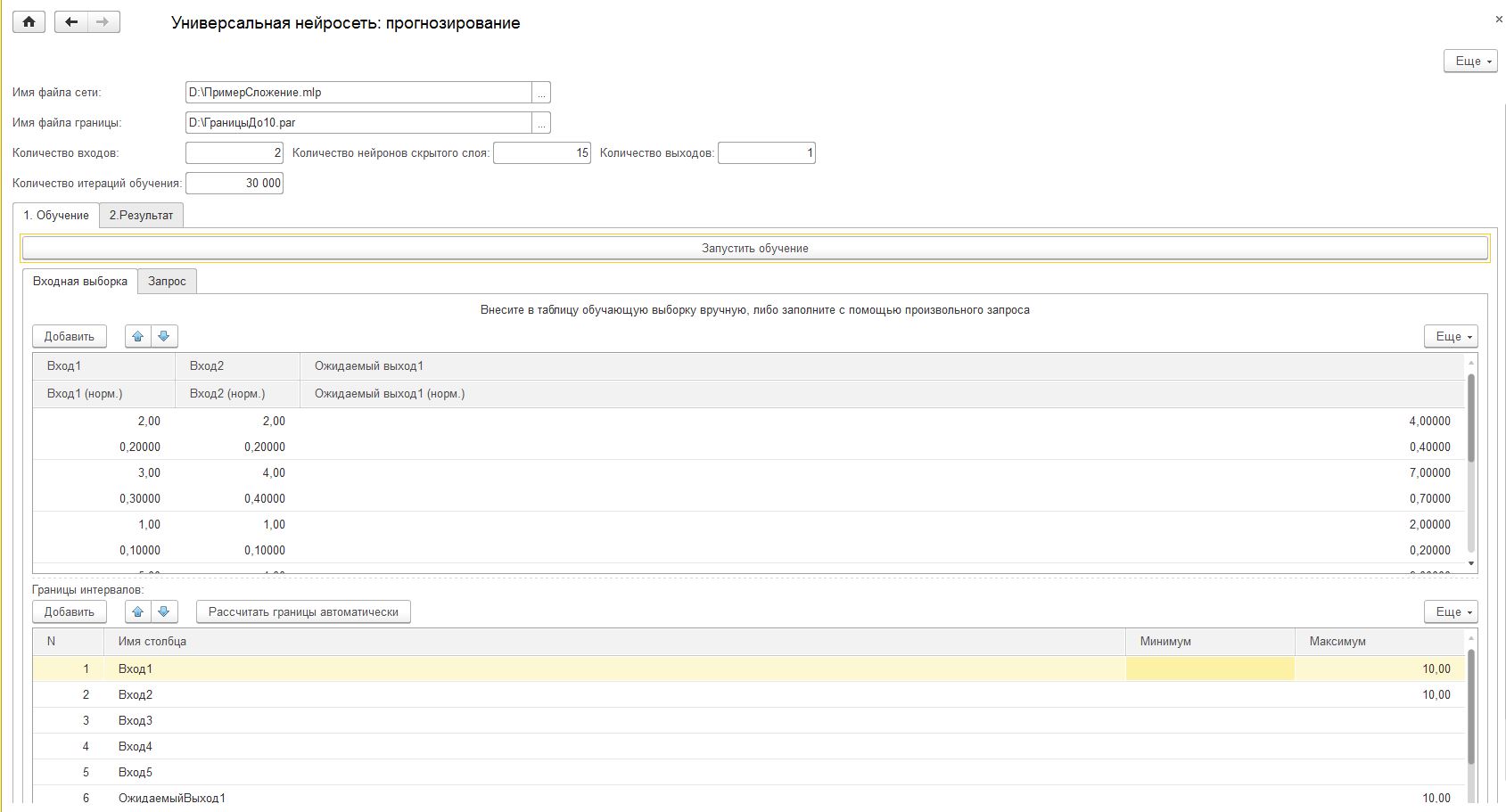
Поэтому 2-й пример я предлагаю сделать на основной рабочей обработки НейросетьПрогнозирование. Которая построена на нелинейных нейронах и имеет уже несколько входов и полноценный скрытый и выходной слой (об этом подробно в следующем разделе)
Кроме того, особенно важен это пример для того, чтобы проверить, насколько обработка умная и насколько ей можно доверять прогнозировать важные данные. Ведь если вы предложите коммерческому директору инструмент, который, например, будет устанавливать цену товара, ему захочется понять, насколько он точен.
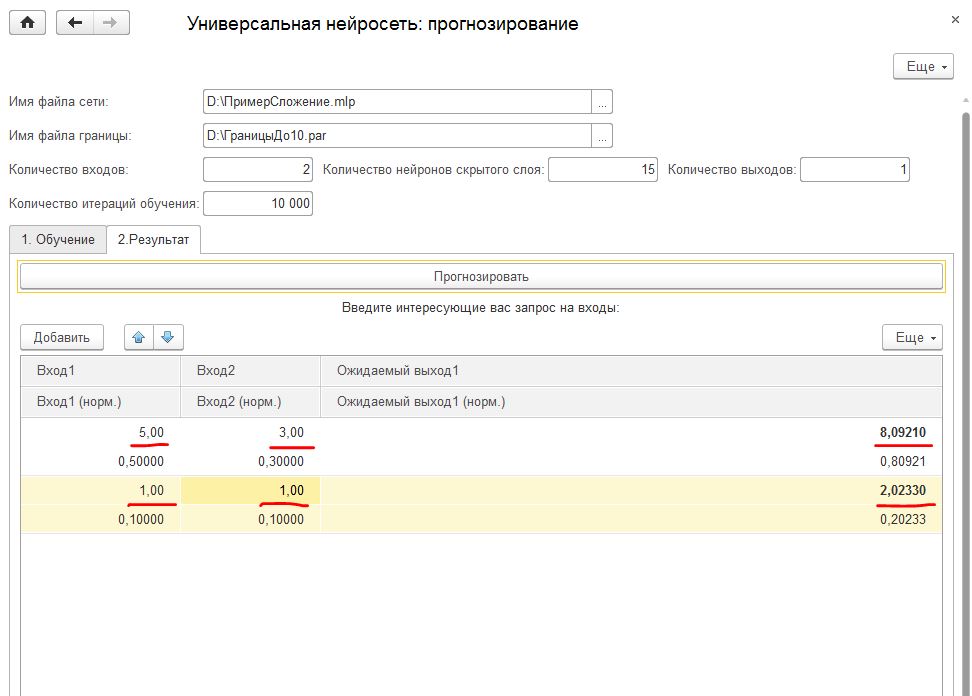
Эксперимент: я подаю на входы 2 числа, а на выход – их сумму.

Естественно изначально сеть не умеет ни складывать, ни производить никакие другие математические действия. Ее нейроны на момент обучения инициализированы случайными весами. Тем не менее, проанализировав выборку 30 000 раз или больше, она успешно находит зависимость и обучается сложению! С таким же успехом ее можно научить чему угодно. Попробуйте сложени3 3х чисел, умножение, корни что угодно… Конечно, калькулятор из нее так себе, т.к. точность низкая, но сам факт того, что сеть сделала нужные выводы и распознала зависимость, поистине потрясающий! Можно попробовать задать меньше итераций обучения, тогда будет результат с большой погрешностью, но все равно сеть будет понимать, что 1 + 1 меньше, чем 5+5. А если повысить количество итераций, то сеть приблизится к совершенству.
Как устроены нейросети в обработках. Немного сухих фактов
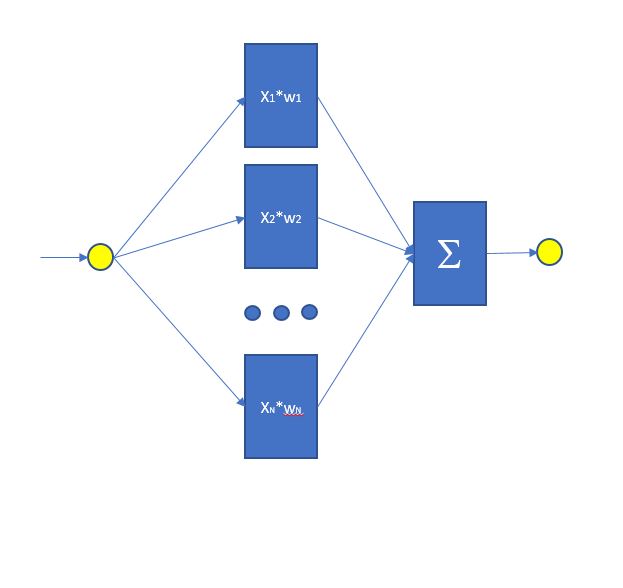
Для Примера 1 я использован совсем примитивную сеть с линейными нейронами без какой либо функции активации. Т.е. каждый нейрон просто умножает поступающий сигнал X на некий вес w и на выходе это все суммируется сумматором который вообще ничего не умножает а просто суммирует входы. Веса изначально задаются случайными числами, а потом вычисляется Общая ошибка между входом и выходом сети и веса корректируются на эту погрешность. Т.н. градиентный спуск. Т.е. сеть при создании содержит случайные веса, потом ей подают много раз входную выборку и она настраивает веса таким образом чтобы ошибка между входом и выходом была минимальна при любых значениях входной выборки. В этом заключается принцип работы любых нейросетей, даже совсем других типов. Веса – это и есть память сети. В нашем мозге это соотвествует соединению между нейронами т.е. синапсам. Вот ее схема:

В следствии своей простоты такая быстро обучается, а в следствии своей линейности она здорово вычисляет линейные функции – без всякой погрешности в отличии от второй сети. Такие сети используют для обработки сигналов и удаления шумов например.
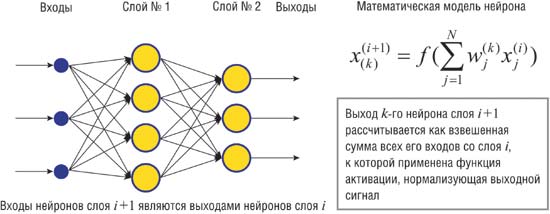
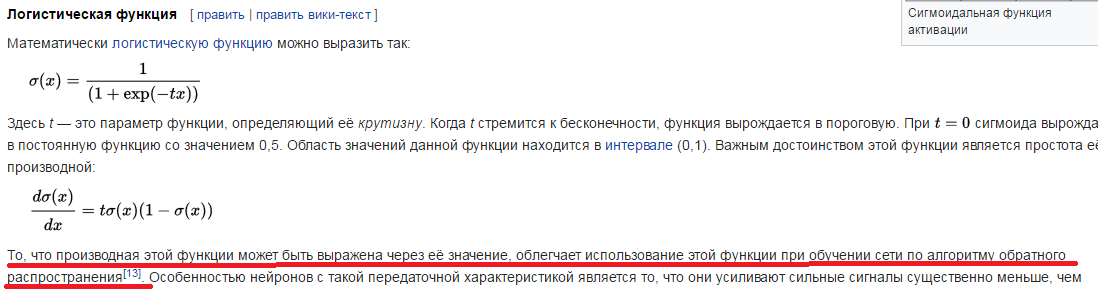
Вторая сеть более сложная – она имеет 3 слоя – входной, выходной и скрытый. Это классический многослойный перцептрон (MLP) , который известен с 60х годов и в там виде он наверняка знаком всем студентам. Сеть состоит из элементов с нелинейной функцией активации (у меня используется «сигмоид», что тоже является распространённым вариантом). На картинке взятой из интернета изображена примерная схема:

Определенную сложность применительно к задаче прогнозирования представляет из себя нормализация и масштабирование входных данных и интерпретация результата. Т.к. сигмоид работает в диапазоне от 0 до 1 на выходе также от 0 до 1. Значит данные надо нормализовать на входе и денормализовать на выходе, т.е. сначала привести к диапазону 0-1 а потом развернуть в нормальное число.
Почему я написал это на 1С а не использовал сторонние фреймворки для анализа данных?
- Чтобы было легче встраивать в решения и не зависеть от сторонних продуктов. Например встроить в форму заказа предсказание на какую скидку рассчитывает клиент или какой товар ему предложить в этот раз
- У нейросетей есть особенность – чтобы их использовать надо их понимать. Код на языке 1С дает преимущество для 1С-программиста для понимания механики работы
- Наконец, это несложно запрограммировать на языке 1С и 1С вполне «тянет» эту задачу на обычных компьютерах. В 1С теперь есть все необходимые функции – случайное число, экспонента и другие математические функции.
Методика применения в реальной жизни
Особенность нейросетей заключается в том, что ее параметры надо подбирать под реальную задачу. Видимо из-за этого они не применяются в массовых продуктах. Подобными вещами занимаются computer scientists (к сожалению не знаю чему это понятие соответствует у нас) Но на мой взгляд тут нет ничего сложного, и принцип можно сформулирует так: если подобрать методом научного тыка такие параметры сети, чтобы она распознавала известные значения из выборки с той точностью, которая вас устраивает(а проверить это легко т.к. результат тоже известен), то можно считать что она обучена хорошо и неизвестные значения она также хорошо будет распознавать. Т.е. примерно как в Примере 2 – ввести данные, проверить на уже известных Вам, но не известных сети данных (т.е. те что не вводились в выборку) и посмотреть то что будет.
Я бы сформулировал тут такие этапы:
- Выбрать данные, которые влияют на прогноз. Например, размер скидки и сезон влияет на увеличение выручки, а размер задолженности нет (хотя может тоже влияет?)
- Загрузить обучающую выборку с помощью запроса на закладке «Запрос». Она должна отражать суть – т.е. в ней должны быть характерные данные. Не обязательно загонять туда всю статистику – можно ограничиться выборкой «Первые 10», «Первые 100». Опять же состав выборки – тоже требует некоторого осмысленного выбора
Логические значения (да/нет) лучше кодировать как -1 и 1. А вот с дискретными так. Допустим у вас есть 4 сезона. Неправильно будет подавать на 1 вход «зима»=1, «весна»=2, «лето»=3, а правильнее будет задействовать 4 входа (1,0,0,0) (0,1,0,0), (0,0,1,0). А вот если будет только «высокий» и «низкий» сезон то сгодится 1 вход с «1»и «0»
- Выбрать количество нейронов скрытого слоя. Тут есть интересная особенность: если выбрать слишком мало, то сеть будет «тупой» - она не сможет выучить сложную зависимость (только очень простую), а если слишком много то сеть будет не «думать» а «зазубривать» возможные варианты. Нужно что то среднее – чтобы нейроны конкурировали и «думали». Это подбирается под задачу. Четкого принципа тут нет.
Конечно есть еще много других нюансов: выбор количества слоев, выбор типов нейронов в слоях, топология связей между нейронами и вообще разные типы нейросетей, разные алгоритмы обучения. Об этом есть целая наука и она постоянно развивается. Но конкретно выбранный тип сети довольно неплохо справляется с задачами, с которыми мне приходится сталкиваться на 1С.
Как работать с обработкой
- Указать файлы в которые будет сохраняться рассчитанные веса сети(синапсы) и границы интервалов. Т.к. большие сети рассчитываются довольно долго их можно рассчитать 1 раз, а потом использовать или, например, посылать другим пользователям
- Задать параметры сети и количество итераций
- Заполнить вручную или запросом обучающую выборку и границы интервалов и обучить сеть.
- Далее пользоваться: вводить данные на закладке Прогнозирование и получать прогноз
Примеры использования в конфигурациях 1С
Просто кратко перечисляю список нескольких возможных вариантов использования конкретно этой сети и обработки (часть из собственной практики)
- Предсказать количество продаж товара с выбранной ценой в определенный сезон (розница). На вход подаются цена товара в течении дня и сезон. На выход – продажи в течении дня
- То же что и в предыдущем примере но еще в сочетании с наличием в ассортименте товаров-конкурентов (тоже розница). Вот тут хорошо себя проявляет сеть т.к. статистикой уже сложно просчитать
- Предложение списка товаров покупателя на основе его предпочтений. Товар имеет ряд свойств. Под каждого покупателя заводится своя сеть (храниться в контрагенте) которая обучается на основе фактов продаж товара с введенными свойствами.
- Оценка риска давно используется во всех банках и страховых, но принцип и возможности конкретно этой сети позволяют сделать свою оценку на любой базе 1С под свои задачи
- Примерно как с оценкой риска можно обучить сеть на то какою скидку дать покупателю чтобы он купил товара максимально исходя из его предыдущих покупок и некоторых специфических для отрасли параметров.
- Вычисление сроков ожидаемых платежей(исходя из текущей задолженности, даты последнего платежа и других параметров платежной дисциплины) для прогнозирования бюджета
Заключение
Как оказалось 1С без всяких скидок хорошо справляется с обработкой нейросетями. Такая реализация как у меня не юзает базу данных в процессе обучения и использования вычисляя все в памяти. Кстати сохранять веса в файл тоже удобно – их можно посылать в другие места. Например обучить на одном магазине и послать в только что открывшийся магазин. Или выложить тут на Инфостарте.
UPD 27.11.18 Опубликован пример отчета : //infostart.ru/public/950619/
Я буду рад если кто то присоединится к этому проекту и расскажет о своём применении нейросетей, задаст вопросы.
Вступайте в нашу телеграмм-группу Инфостарт



{kind=link}