



Изначально я использовал связку grep (cygwin) + perl, команды были что-то из разряда:
grep '' -rh --include '*.log' | perl descr.pl
или
cat */*.log | perl descr.pl
Первый вариант предпочтителен т.к. мы не зависим от количества вложенных директорий.
Вот собственно скрипты которые выложены на kb
Надеюсь я не нарушил никакое авторское право :). Сразу бросается в глаза, что эти скрипты написаны по одному шаблону и во всех трех присутствует одна и та же ошибка (не будем об этом).
Данные скрипты маленькие, емкие, лаконичные если хотите, и весьма быстрые. Однако они не самодостаточные, т.е. они не агрегируют duration, не выводят количество, по сути эти скрипты некий промежуточный этап, потом результат можно дополнительно обрабатывать AWK или SED'ом, что не очень удобно и не всем доступно (с точки зрения доступности скилов).
Решил я написать перловый скрипт который агрегирует произвольные значения (duration, потребление памяти, да что захотите), хитро группирует колстек (выбрасывает из него все нечитаемые символы, цифры и всякие ",:;' ), но в консоль выводится все красиво. Скрипт был написан, ознакомиться можно в репе, данный скрипт на вход принимает различные параметры (сортировка, группировка, топ). Вроде все ок, но потом я подумал, все же зачем людям ставить к себе cygwin, надо искать файлы перлом, сказано - сделано. Однако, такой скрипт работал на несколько порядков медленнее. Например если скрипт который читает из StdIn выполнялся 10 сек. то скрипт который читал файлы уже тратил около 15 минут. (обрабатываемый объем естественно одинаков)

Видимо это из-за того, что я регулярку натравливал на весь файл
Решил было распараллелить процесс чтение из файлов, но perl нормально не параллелится и это было мое последнее разочарование, после которого я потерял интерес к perl'у.
perl нормально не параллелится
Тут стоит внести ясность, перл конечно умеет работать "параллельно", но в режиме кооперативной многозадачности, для этого в перл есть т.н. корутины (coroutines) или модуль AnyEvent
Схематично это можно представить так:
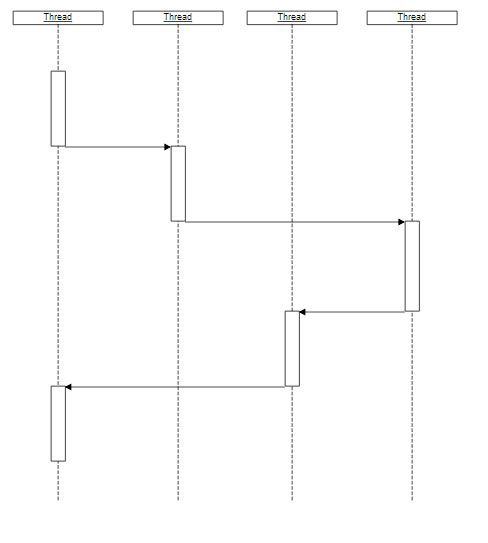
т.е. управление передается от корутины к корутине, но общее время выполнение будет такое же как если бы код выполнялся линейно.
К тому же, исторически все же перл создан под linux, в linux можно было бы создать отдельные процессы (fork) и радоваться, но в винде не создается отдельный процесс при выполнении fork(). Есть еще AnyEvent::Fork::Pool, но запустить пример из cpan мне так и не удалось. (особо не старался если честно)
В целом мое впечатление о перле - синтаксис удобный, но язык тяжелый для изучения
После этого я переключился на Golang, параллельность у Go это его сильная сторона. В Go есть свои корутины, в Go они называются горутины. Горутины из себя представляют треды которые работают как в кооперативной многозадачности, так и параллелятся по процессам. Как результат был написана консольная утилита (ссылка на репу в конце статьи).
Архитектура утилиты получилась такая такая:
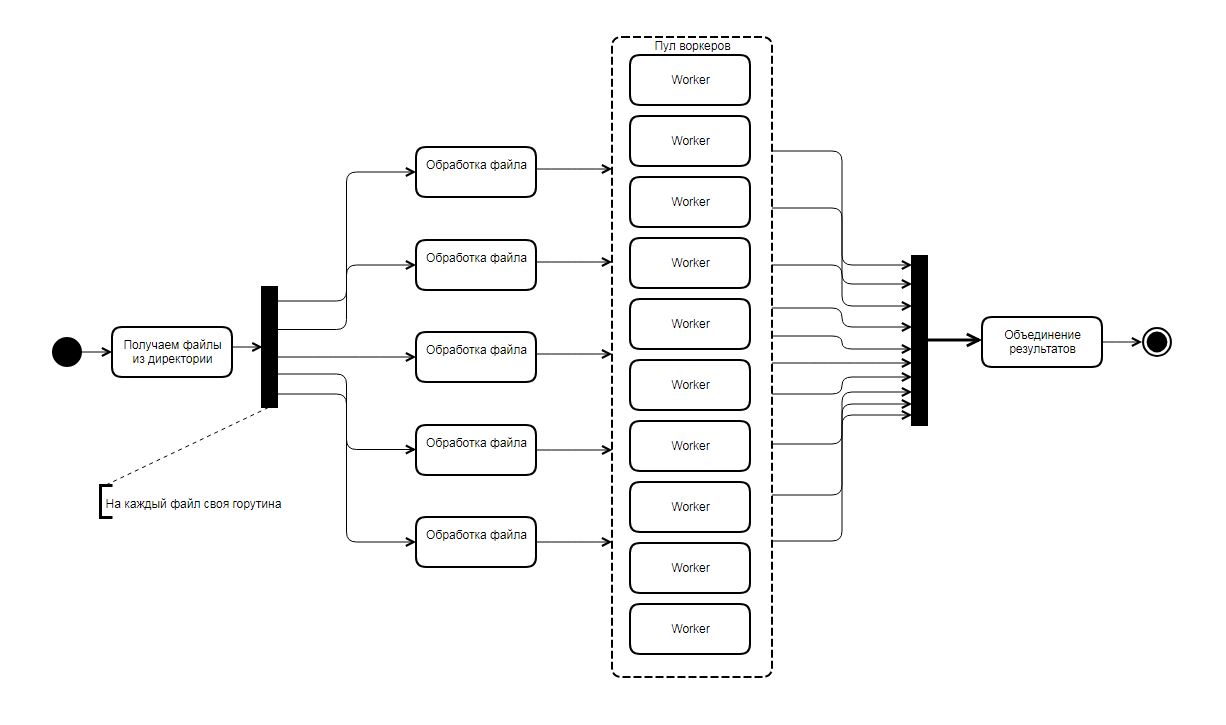
Каждый файл обрабатывает отдельная горутина, каждая такая горутина разбирает файл на такие части:
41:56.637012-1,SCALL,2,process=rphost,p:processName=ZKGU_KBR,OSThread=15448,t:clientID=20,t:applicationName=BackgroundJob,t:computerName=SP-SRV1,t:connectID=293645,SessionID=11,Usr=DefUser,ClientID=17,Interface=12af46e1-4f3e-4446-a753-519e54d55f48,IName=IObjectLocksStor,Method=2,CallID=33656,MName=clearObjectLocks
41:58.602000-0,CONN,1,process=rphost,OSThread=15448,ClientID=20,Txt=Incomming connection closed: long still
41:58.602001-10966996,CONN,0,process=rphost,OSThread=15448,t:clientID=20,t:clientID=20,t:computerName=SP-SRV1,t:applicationName=BackgroundJob,t:connectID=293645,Calls=11
42:01.551000-0,CONN,0,process=rphost,OSThread=5148,Txt='Ping direction statistics: address=[::1]:1541,pingTimeout=5000,pingPeriod=1000,period=10296,packetsSent=10,avgResponseTime=0,maxResponseTime=0,packetsTimedOut=0,packetsLost=1,packetsLostAndFound=1'
42:11.847000-0,CONN,0,process=rphost,OSThread=5148,Txt='Ping direction statistics: address=[::1]:1541,pingTimeout=5000,pingPeriod=1000,period=10296,packetsSent=10,avgResponseTime=0,maxResponseTime=0,packetsTimedOut=0,packetsLost=1,packetsLostAndFound=1'
42:17.588001-0,EXCP,0,process=rphost,OSThread=16304,Exception=0874860b-2b41-45e1-bc2b-6e186eb37771,Descr='src\LicenseBaseImpl.cpp(5203):
0874860b-2b41-45e1-bc2b-6e186eb37771: Ошибка программного лицензирования. Error=10004(0x00002714): Операция блокирования прервана вызовом WSACancelBlockingCall.
File=src\LicenseBaseImpl.cpp(5144)'
42:18.508012-0,EXCP,0,process=rphost,OSThread=10848,Exception=acea3e6e-3687-4792-8319-09c009274c9a,Descr='src\RHostImpl.cpp(5456):
acea3e6e-3687-4792-8319-09c009274c9a: Рабочий процесс не найден'
(раскрасил для наглядности)
Каждая такая часть поступает на обработку пулу воркеров, по дефолту пул состоит из 10 воркеров (воркер - отдельная горутина, которая работает в фоне и ожидает на вход каких-то данных для обработки), размер воркеров может меняться параметром, об этом далее.
Результат работы воркера это определенная структура, каждый воркер накапливает внутри себя map'ы результатов, по окончанию обработки файлов у нас получается 10 (по количеству горутин) map'ов, они в свою очередь объединяются в общую мапу отдельной горутиной.
map - структура данных в Go, в perl аналог - хэш, в 1С - соответствие
В результате на выходе мы получаем некий контекст (программист задает, что будет контекстом) и некие агрегируемые поля (агрегация всегда осуществляется по полю value, а вот откуда будет браться значения для value определяется программистом)
Вывод результата получается такой:
Для события EXCP
(rphost) EXCP, количество - 7 'src\VResourceInfoBaseImpl.cpp(1113): 580392e6-ba49-4280-ac67-fcd6f2180121: Ошибка работы сеанса Ошибка при выполнении запроса POST к ресурсу /e1cib/logForm: 60c686dc-798f-4d17-aadb-a90156a16eb8: Сеанс отсутствует или удален ID=1204924e-c4ad-43e0-a801-78dca981c70d (rphost) EXCP, количество - 7 'Сеанс отсутствует или удален ID=3c12c449-3c3a-48fb-a1c4-f01869814f97 (rphost) EXCP, количество - 2 'Сеанс отсутствует или удален ID=f8467c59-27ca-4ed9-8768-5f48b6f9ce92
для события CALL
(ИмяБазы) CALL, количество - 9, MemoryPeak - 8317991
ОбщийМодуль.Вызов : ОбщийМодуль.ДлительныеОперацииВызовСервера.Модуль.ОперацииВыполнены
(ИмяБазы) CALL, количество - 1, MemoryPeak - 950231
ОбщийМодуль.Вызов : ОбщийМодуль.СтандартныеПодсистемыВызовСервера.Модуль.СкрытьРабочийСтолПриНачалеРаботыСистемы
(ИмяБазы) CALL, количество - 1, MemoryPeak - 726808
ОбщийМодуль.Вызов : ОбщийМодуль.ИнтернетПоддержкаПользователейВызовСервера.Модуль.ПередНачаломРаботыСистемы
(ИмяБазы) CALL, количество - 1, MemoryPeak - 1454045
ОбщийМодуль.Вызов : ОбщийМодуль.МенеджерОборудованияВызовСервера.Модуль.НайтиРабочиеМестаПоИД
(ИмяБазы) CALL, количество - 1, MemoryPeak - 1210482
Форма.Вызов : Обработка.РезультатыОбновленияПрограммы.Форма.ИндикацияХодаОбновленияИБ.Модуль.ЗагрузитьОбновитьПараметрыРаботыПрограммыВФоне
в данном случай value выбрано MemoryPeak, можно выбрать duration, как напишите регулярку.
Шаблон для вывода может переопределять программист.
Параметры которые принимает утилита:
- -SortByCount - признак того, что нужно сортировать результат по количеству
- -SortByValue - признак того, что нужно сортировать по значению
- -io - признак того, что данные будут поступать из потока stdin
- -Top - ограничение по количеству выводимого результата
- -Go - количество горутин в пуле (по умолчанию 10)
- -RootDir - директория где будет осуществляться поиск
И для профилирования:
- -cpuprof
- -memprof
Пример использования:
ParsLogs.exe -RootDir=C:\Logs
В данном случае поиск логов будет производиться по каталогу "C:\Logs"
Также можно применять в тандеме с grep'ом
grep '' -rh --include '*.log' | ParsLogs.exe -io
Пример сочетания параметров
ParsLogs.exe -RootDir=C:\Logs -Top=10 -SortByCount
Будет выведено 10 результатов отсортированных по количеству
Немного сравнения с перлом:
Для примера был взят мой перловый скрипт с агрегацией и объем логов ТЖ 2.8г
grep '' -rh --include '*.log' | perl CallDurationsMem.pl скрипт выполнялся ~ 10 минут
grep '' -rh --include '*.log' | ParsLogs.exe -io примерно 3 минуты зависит от того сколько внутри регулярок применяется к блоку данных
ParsLogs.exe -RootDir=C:\Logs примерно 2 минуты
Пробовал парсить 30Гб логов, ушло около 2ч.
Кто-то скажет, так перловый скрипт видимо написан не оптимально, я соглашусь, я в перле новичок, так же как и в Go, т.е. считаем, что оба эти приложения написаны не особо оптимально (кстати в Go написать менее оптимально вероятности куда больше, т.к. там нужно не забывать тот факт, что структуры и большинство типов передаются по значению)
Профилирование приложения показало, что основную нагрузку на приложение дает регулярка:
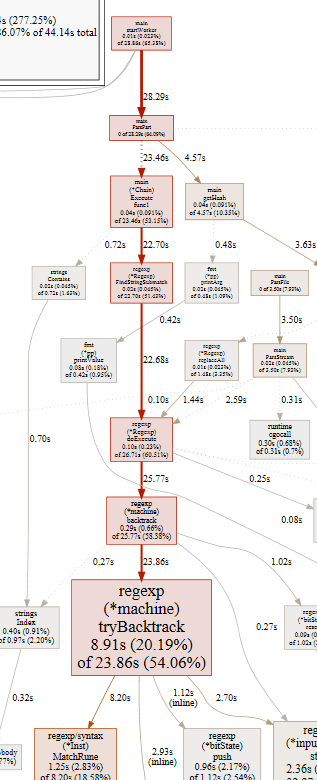
По этому скорость обработки логов напрямую зависит от того насколько оптимальна написана регулярка и сколько этих регулярок под капотом. Регулярок может быть несколько т.к. в приложении был применен pattern chain of responsibility, об это будет рассказано далее.
Если вы захотите присоединиться к разработке, ниже информация для вас:
Как уже писалось выше, в архитектуре решения был применен pattern chain of responsibility (кому интересно вот статья как накостылить этот паттерн на 1С). Основная структура в коде это Chain и интерфейс IChain который чаще всего будет претерпевать изменения. Структура Chain это есть один из звеньев в цепочки ответственности
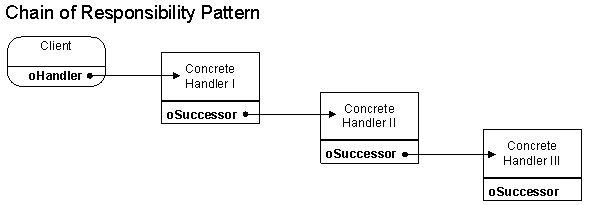
Цепочка строится в методе BuildChain() (метод в пакете Tools)
func BuildChain() *Chain {
Element1 := Chain{
regexp: regexp.MustCompile(`(?si)[,]CALL(?:.*?)p:processName=(?P<DB>[^,]+)(?:.+?)Module=(?P<Module>[^,]+)(?:.+?)Method=(?P<Method>[^,]+)(?:.+?)MemoryPeak=(?P<Value>[\d]+)`),
AgregateFileld: []string{"event", "DB", "Module", "Method"},
OutPattern: "(%DB%) CALL, количество - %count%, MemoryPeak - %Value%\n%Module%.%Method%",
}
Element2 := Chain{
regexp: regexp.MustCompile(`(?si)[,]CALL(?:.*?)p:processName=(?P<DB>[^,]+)(?:.+?)Context=(?P<Context>[^,]+)(?:.+?)MemoryPeak=(?P<Value>[\d]+)`),
NextElement: &Element1,
AgregateFileld: []string{"DB", "Context"},
OutPattern: "(%DB%) CALL, количество - %count%, MemoryPeak - %Value%\n%Context%",
}
Element3 := Chain{
regexp: regexp.MustCompile(`(?si)[,]EXCP,(?:.*?)process=(?P<Process>[^,]+)(?:.*?)Descr=(?P<Context>[^,]+)`),
NextElement: &Element2,
AgregateFileld: []string{"Process", "Context"},
OutPattern: "(%Process%) EXCP, количество - %count%\n%Context%",
}
return &Element3
}
Метод должен возвращать всегда ссылку на последнее звено в цепочке. Используется это так, выполняется метод "звена" Execute, если он вернул nil и есть следующий элемент в цепочке,тогда вызывается Execute следующего элемента. В Execute выполняется регулярка + кой какие пляски, чтобы можно было удобно работать с именованными группами захвата.
- regexp - шаблон регулярного выражения. Группы захвата обязательно должны быть именованными, в Go это делается так (?P<Имя> .....)
- NextElement - ссылка на предыдущее звено цепочки
- AgregateFileld - имена групп захвата по которым будет производиться агрегация
- OutPattern - шаблон по которому будет выводиться результат. В примере выше маркер %count% нигде не задается, это количество подходящих элементов в группе (при агрегации), давайте считать этот маркер "системным". Группа захвата содержащие значение которое будет суммироваться должна называться Value (имя групп регистрозависимое). Например, если мы захотим агрегировать значения duration, тогда регулярка будет такой `(?si)[\d]+:[\d]+\.[\d]+[-](?P<Value>[\d]+)[,]CALL(?:.*?)p:processName=(?P<DB>[^,]+)(?:.+?)........`
Проект располагается на github, буду рад, если кто-то присоединится к проекту.
Вступайте в нашу телеграмм-группу Инфостарт