Меня зовут Александр Галанов, я – разработчик 1С в команде Ozon Express. Опыт работы с 1С у меня более 5 лет. Есть опыт работы с другими языками. Расскажу о проекте, который мы реализовали у нас в компании, и о том, как я применил на нем свои знания работы с GitLab CI.
Расскажу:
-
Что мы имели на начало проекта, и чего хотели добиться.
-
Как у нас устроена работа с GitLab CI.
-
Что мы реализовывали в ходе нашего проекта.
-
И какую выгоду от этого получили.
Начало проекта

Когда мы начинали этот проект, мы хотели:
-
Контролировать технический долг и исправлять ошибки до того, как они станут legacy.
-
Внедрить автотесты, чтобы не прогонять одни и те же самые тесты вручную при выпуске релиза.
-
Обновлять стейдж и прод автоматически, чтобы не нужно было участие человека, и чтобы не нужно было дежурить ночью во время технологического окна.
-
И также, если все-таки какие-то ошибки окажутся на проде, доставлять hotfix-расширения в максимально сжатые сроки.
Что мы имели в начале проекта

Что мы имели на начало проекта в техническом плане?
-
В качестве основы у нас была ERP 2.5.
-
Разработку мы ввели в EDT.
-
Для версионирования использовали Git, и уже имелся свой сервер GitLab.
-
Для постановки задачи использовалась Jira.
-
И команда QA использовала Allure EE.

У нас был следующий флоу разработки.
-
Была основная ветка мастер, которая отражала собой состояние рабочей базы.
-
И в начале каждого спринта создавалась релизная ветка – каждый разработчик, беря какой-то тикет, создавал от релизной ветки свои ветки-фичи. В них, соответственно, реализовывалась задача.
-
После чего отправлялся мерж-реквест на влитие в релизную ветку.
-
И после того, как все задачи были влиты в релизную ветку, и QA давали добро на обновление, релизная ветка вливалась в мастер, и из нее обновлялась рабочая база.
-
А если после обновления мы находили какие-то критичные ошибки, которые мешали работе пользователей, мы создавали ветку с префиксом hotfix – в ней реализовывалось расширение для быстрого устранения этой проблемы.

И какие же у нас есть варианты автоматизации?
Самый простой на первый взгляд вариант – это руками.
-
Затраты на внедрение будут минимальны.
-
Но потери команды будут расти с каждым релизом.
-
И также никуда не девается человеческий фактор – всегда можно запустить не тот скрипт, не с теми параметрами, не в той последовательности, и все сломается.
Jenkins.
-
Jenkins уже надо настроить и потратить на это больше времени.
-
Но зато дальше он все делает сам.
-
Хотя, как я уже сказал, мы используем GitLab и добавление Jenkins было бы добавлением еще одного звена. Как известно, если мы говорим о какой-то сложной системе, вероятность того, что она сломается – это вероятность того, что сломается какой-либо из ее элементов. И добавляя еще одну систему, мы эту вероятность, естественно, увеличиваем.
И третий вариант – GitLab CI.
-
Его также нужно настроить.
-
Но дальше он все делает сам.
-
И это не будет добавлением какого-то нового элемента – большая часть команды уже работает с GitLab. Через него идет версионирование, через него мы проводим код-ревью, мы отправляем мерж-реквесты, и этот инструмент не будет новым для других членов команды.
Поэтому первый вариант мы отбросили сразу, потому что он не сулит нам ничего хорошего. И выбрали GitLab CI.
GitLab-CI

Как же организована работа GitLab CI?
-
У нас есть центральный сервер GitLab,
-
В репозитории мы размещаем в корне специальным образом сформированный YML файл, где у нас описаны: джобы – какие-то работы, которые должны быть выполнены; и этапы сборки, которые мы имеем.
-
И при каждом событии CI – push кода, мерж-реквест или ручной запуск – сервер GitLab анализирует этот YML-файл и смотрит, какие же работы по этому событию должны быть запущены.
-
И дальше скрипты по работам, которые должны быть запущены, отправляются на раннеры.
Раннеры – это удаленные компьютеры, на которых запущен GitLab-runner, и на которых выполняются эти скрипты. В ходе работы этих раннеров мы можем получать:
-
кэш, который может быть потом повторно использован, чтобы ускорить следующие прогоны тех же самых этапов;
-
и артефакты – файлы, которые мы получили в результате выполнения скрипта. Они могут быть как использованы в последующих этапах, так и могут быть скачаны через веб-интерфейс GitLab.

По каждому событию, если у нас есть какие-то джобы, которые должны быть по нему выполнены, у нас генерируется пайплайн.
На слайде – пример пайплайна, который у нас генерируется по релизной ветке. У него есть соответствующие стейджи (этапы):
-
Info
-
Build
-
Test
-
Stage (обновление стейджа)
-
Ready-to-prod (подготовка к обновлению прода).
Также у нас в этом пайплайне есть панель, где мы можем перейти:
-
на результаты тестирования, если мы их, конечно, отправляем в этот пайплайн;
-
и также посмотреть, допустим, отчет о качестве кода.

Здесь стоит также сказать, что же это за YML-файл, в котором мы описываем структуру работ. Здесь пример описания одной из работ – обновление одной из баз стейджа.
Тут у нас довольно широкие возможности:
-
мы можем указать, какие скрипты должны быть выполнены;
-
по каким условиям у нас должна выполняться или не выполняться эта работа;
-
как она должна выполняться – возможно, она должна запускаться автоматически или, наоборот, нужно, чтобы ответственный сотрудник зашел в интерфейс GitLab и запустил эту работу вручную, когда это будет нужно;
-
также мы можем указать какие-то дополнительные параметры – допустим, переменные запуска пайплайна, которые потом будут доступны скриптам в качестве переменных окружения;
-
как вы можете здесь увидеть, в самой нижней строчке мы запускаем скрипт OneScript.

И хочу вкратце сказать, почему же мы используем именно OneScript для реализации функциональности CI? Тут есть несколько преимуществ.
-
OneScript может поддерживать любой член команды. Ревью CI-скриптов может проводить любой член команды, потому что после 1С порог вхождения не то что минимальный – можно сказать, что он практически отсутствует. Сотрудники, которые проводят ревью кода именно по конфигурации, они же могут провести и ревью кода CI скриптов.
-
Скрипты, написанные на OneScript, можно проверять теми же самыми инструментами. Например, с помощью BSL-плагина SonarQube, которым мы проверяем нашу основную конфигурацию, им же мы проверяем и скрипты CI.
-
Следующий немаловажный момент – когда мы хотим реализовать CI на проекте, мы всегда стоим перед выбором. Нам пригласить DevOps-а, которого мы должны будем погрузить в специфику работы с 1С, рассказать ему про какие-то особенности 1С, рассказать ему про какие-то особенности EDT, особенности сборки? Либо же мы можем взять разработчика 1С, который есть в команде, и сказать ему, что нам нужно реализовать CI, и твоя задача изучить, как работает GitLab CI. Последний вариант, на мой субъективный взгляд, будет проще, потому что на том же сайте GitLab есть исчерпывающая документация. Да, она на английском языке, но она требует базовых знаний английского, и предельно понятна.
-
Также OneScript имеет по сравнению с конфигуратором такие недостающие инструменты, которых часто не хватает, как:
-
нативную поддержку регулярных выражений;
-
нативную поддержку получения переменных окружения;
-
и с помощью директивы #Использовать мы можем импортировать какие-то другие модули, что, несомненно, тоже будет плюсом.
-

На этом слайде вы можете увидеть пример скрипта, который запускает проверку SonarQube. В целом, если человек работал с 1С, то понять код, написанный на OneScript, для него не составит каких-либо проблем.
Сборка проекта

Первой задачей, которая перед нами стояла, была сборка проекта
-
Эта задача довольно требовательна к жесткому диску и оперативной памяти, поэтому она запускалась на отдельном раннере с тегом build. В GitLab-CI мы раннерам можем присваивать какие-то теги, и эти же теги присваивать работам – тогда эти работы уйдут на выполнение именно на ту группу раннеров, которую мы указали.
-
В ходе выполнения у нас в артефакты сохранялись собранная конфигурация и файл log.txt (вывод параметра /Out).
-
Самым длительным этапом оказался процесс сборки из проекта EDT в cf-файл . Мы пытались его по-разному ускорить – например, пробовали кэшировать workspace, и даже сначала в ряде прогонов это показывало ускорение почти в два раза. Но в итоге мы увидели, что иногда это приводит к тому, что, наоборот, у нас процесс сборки шел слишком долго и даже уходил за тайм-аут. Поэтому в итоге нам пришлось от кэширования отказаться.

Следующим моментом было обновление после сборки баз стейдж и прод.
В случае обновления прода перед нами стояла следующая задача – у нас имеется технологическое окно в 4 часа утра, в которое мы обновляем рабочую базу. Когда мы даем CI указание обновить рабочую базу, нам нужно, чтобы он это сделал не немедленно, а в следующие 4 часа утра.
GitLab CI позволяет указывать задержку – мы можем указать, что у нас работа выполняется как delayed, и что она стартует, допустим, через 30 минут:
when: delayed
start_in: 30 minutes
Но он позволяет указать именно статическую задержку, а нам нужна была динамическая.
Поэтому мы создали отдельный раннер с тегом delayed – и в его настройках указали, что на нем может сразу выполняться до 20 работ параллельно.
На этот раннер отправлялись работы, которые выполняли роль задержки – они выполнялись в холостую до наступления 4 часа утра. Каждые 5 минут они проверяли – не настало ли нужное время. Если оно наступало, то работа завершалась, и CI запускал следующий этап – обновление рабочей базы.

Из одного проекта у нас обновлялось сразу несколько баз prod. Они у нас обновлялись в соответствии с определенным регламентом – сначала копия рабочей базы загружалась в соответствующую базу stage, и проводилась попытка обновить именно stage, чтобы проверить, что на prod все пройдет успешно.
Такой порядок был реализован с помощью директивы needs – мы указывали, что такая-то работа запустится только тогда, когда будут выполнены работы, указанные в секции needs.
-
Для обновления базы A мы указываем, что запуск обновления прода может быть запущен только после того, как у нас выполнено обновление стейджа A.
-
То же самое – для базы Б.
Так мы можем разграничивать обновление рабочих баз – обновлены могут быть только те, у которых stage уже был обновлен успешно.
Если какую-то работу нужно запустить, не дожидаясь выполнения всех остальных работ, мы указываем в секции needs пустой массив – таким образом у нас реализована сборка.
Потому что перед сборкой выполняется этап info, и там есть две работы, которые выполняют функции оповещения и смены бейджей – для старта сборки проекта их дожидаться нет необходимости.
Проверка качества кода
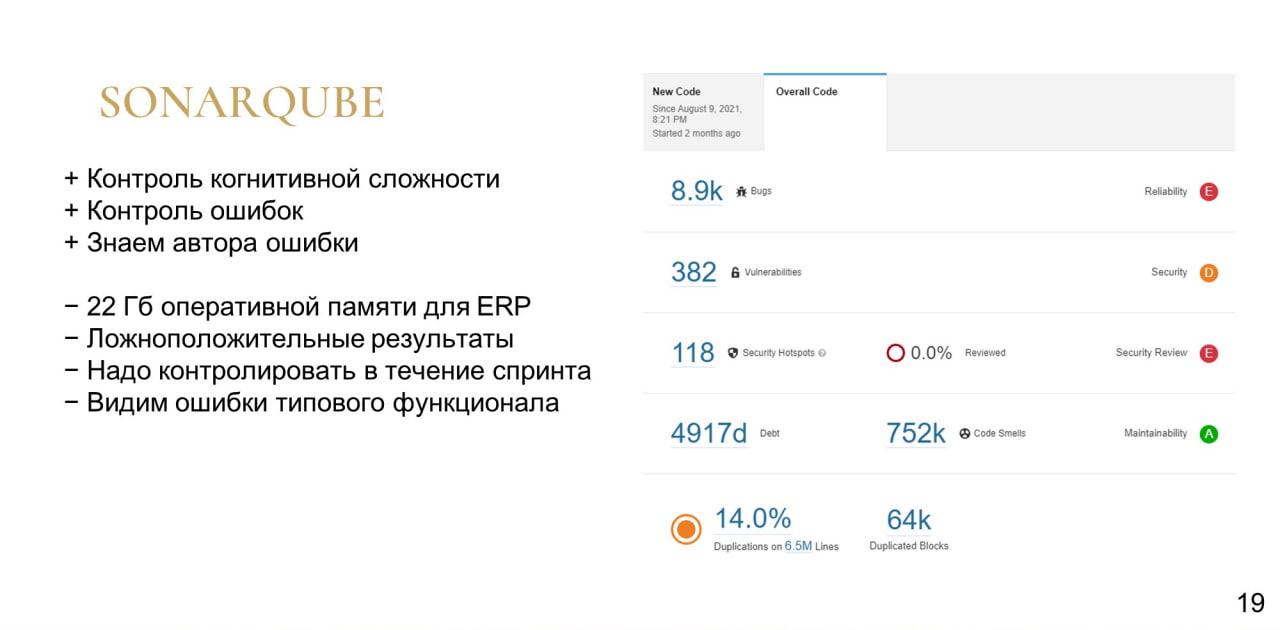
Следующим этапом была проверка качества кода – для этого мы, естественно, использовали SonarQube.
-
Он позволяет не только находить в коде ошибки.
-
С его помощью мы также можем контролировать когнитивную сложность – это избавляет нас от появления в конфигурации функций на тысячу строк и функций с большим уровнем вложенности.
-
А благодаря использованию Git мы точно знаем автора ошибки.
Но у SonarQube есть свои минусы.
-
Допустим, для запуска SonarScanner на проверку проекта ERP требуется 22 гигабайта оперативной памяти.
-
Иногда SonarQube выдает ложноположительные результаты, которые не всегда удается регулировать.
-
Плюс для работы с SonarQube нужен ответственный сотрудник, который в течение спринта будет контролировать, что разработчики не забили на оповещения об ошибках, завели по ним тикеты и отметили их статус, что это не брошено на самотек.
-
Также в SonarQube мы видим ошибки в типовой функциональности. К счастью, мы можем их отсеять двумя способами:
-
Во-первых, на слайде вы можете видеть, что у нас есть вкладка «Новый код». Мы можем указать какую-то точку – допустим, последняя проверка в момент последнего поднятия версии ERP. И мы увидим ошибки только с этого момента.
-
Во-вторых, при просмотре имеющихся ошибок можно также использовать отборы.
-

Кроме этого, мы использовали проверку непосредственно конфигуратором:
-
Ее преимущество в том, что она находит некоторые ошибки, которые иногда не видит SonarQube.
-
Но у нее тоже есть ложноположительные результаты.
-
И нам все-таки необходимо разбирать вывод, хранить какой-то «белый список» и обновлять его. Это не очень удобно.
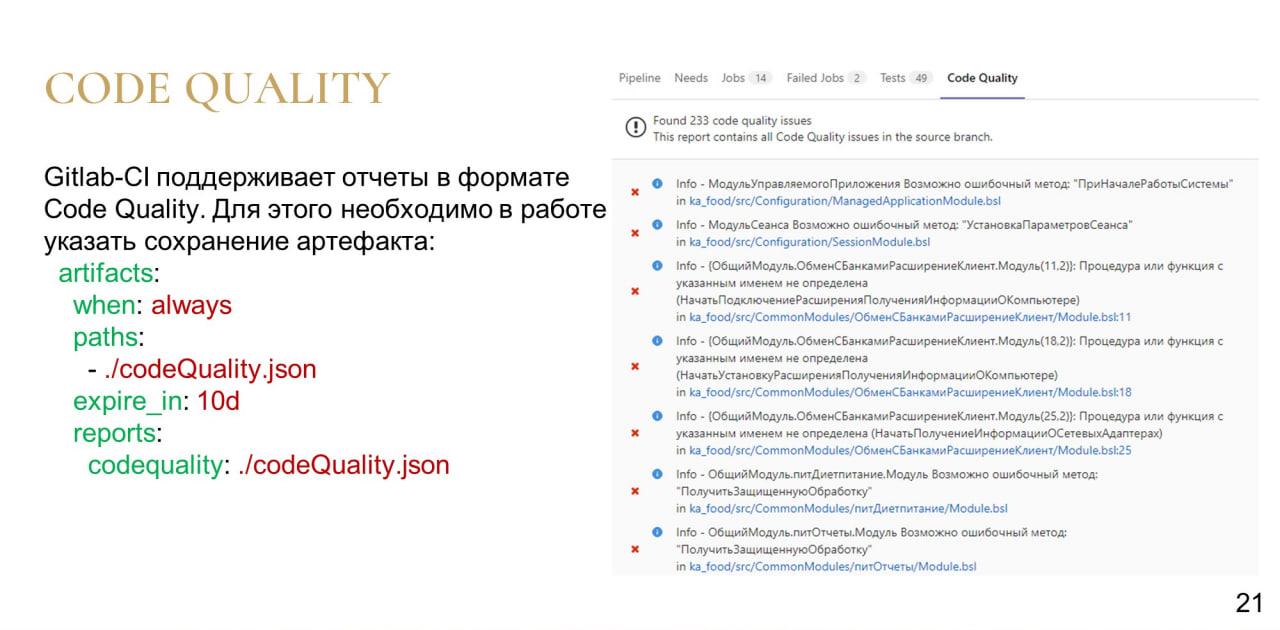
Но, к счастью, GitLab CI поддерживает отчеты в формате code quality.
Например, мы можем приложить в качестве артефакта сборки отчет в соответствующем формате, и тогда у нас в пайплайне появится вкладка code quality, где у нас будет:
-
список ошибок с указанием конкретных файлов, в которых есть эти ошибки, и даже, если есть такая возможность, с указанием конкретной строки;
-
также у ошибок есть свои статусы, и мы сначала видим ошибки с более критичным статусом, а в конце, допустим, со статусом info.

Но есть одна проблема, потому что проверка конфигуратором вводит у нас такое вот полотно ошибок, которое надо еще разобрать, а передать надо уже готовый JSON.

Но если мы присмотримся поближе, мы увидим, что это не так уж и сложно.
Все, что нам нужно:
-
Во-первых, указать соответствие имен объектов метаданных и прочих объектов тому, как они называются в проекте EDT.
-
Если для ошибки у нас указана конкретная строка, нам необходимо передать ее в location.
-
Остальной текст ошибки будет описанием и пойдет в поле description.
-
Если это ошибка из белого списка, мы присваиваем статус severety: “info” (иначе “major”).
Если у нас есть ошибки не из белого списка, джоб в CI завершает работу с ошибкой, чтобы в pipeline можно было увидеть, что у нас что-то не то.
Автотесты

Следующим этапом были автотесты.
Для автотестов мы, конечно же, использовали Vanessa.
-
Это замечательный инструмент, который убирает необходимость прогонять одни и те же тесты вручную.
-
Но стоит заметить, что все же нужны компетенции по написанию тестов.
-
И если мы хотим использовать именно ванессу вместе с CI, есть некоторые свои особенности при настройке раннеров.

Главная особенность при настройке раннеров заключается в следующем:
-
Если мы хотим иметь скриншоты ошибок, нам, во-первых, нельзя заходить на эти раннеры по RDP – для удаленного доступа на таких раннерах у нас был установлен VNC.
-
Сам раннер должен быть запущен не как служба Windows – поэтому для запуска gitlab-runner.exe был реализован автоматический вход под техническим пользователем.
В противном случае вместо скриншотов к нам приходили черные квадраты.

Общий алгоритм был следующий:
-
Мы запускаем тесты через vrunner vanessa.
-
При наличии ошибок мы дописываем в отчет Allure данные журнала регистрации
-
Результаты тестирования мы отправляем на сервер Allure
-
В настройках CI указываем, что файл результата приложен к сборке как артефакт.
-
А в секции JUnit еще дополнительно указываем, что у нас есть отчет в формате JUnit.
После этого результаты тестирования в формате junit нам доступны для просмотра как в GitLab, так и в Allure – причем в Allure мы можем дополнительно увидеть скриншоты ошибок и данные журнала регистрации.

Дополнительно Vanessa позволяет писать автоинструкции. Это однозначный плюс. Это позволяет:
-
Во-первых, создавать как минимум шаблоны сценарных тестов силами аналитиков – такие инструкции легко перезаписывать при изменении интерфейса.
-
Но необходимо все же тогда провести какое-то обучение аналитиков по работе с Vanessa.
-
Дальше необходима дополнительная настройка. Требуется софт, который будет синтезировать речь, записывать видео, склеивать его. Плюс если мы хотим, чтобы это все красиво интерактивно выглядело – с движением мышки, с плавным вводом текста – лучше всего использовать опубликованную базу. Соответственно, дополнительно еще требуется публикация.
-
И такие сценарные тесты все равно требуют доработки команды QA.
Hotfix расширения

Дальше вкратце расскажу про hotfix расширения.
Если все-таки ошибки попадали в основную конфигурацию, и они попадали на рабочую базу, то мы создавали ветку с префиксом hotfix, для которой автоматически генерировался pipeline.
В этом pipeline было, по сути, всего два джоба:
-
Build – на базе stage собиралось расширение и выгружалось в артефакты.
-
Prod – после того, как QA проверит, что расширение действительно работает, он вручную запускал второй джоб, который уже доставлял этот cfe на рабочую базу.
Соответственно, сборка занимала от 15 минут, а доставка cfe на прод – менее 10 минут.

Хочу заметить, что расширения у нас являются именно экстренным механизмом исправления ошибок.
Потом все эти изменения все равно вносились также в основную конфигурацию.
А при очередном обновлении релиза все расширения с префиксом hotfix удалялись.
Пользовательские задачи
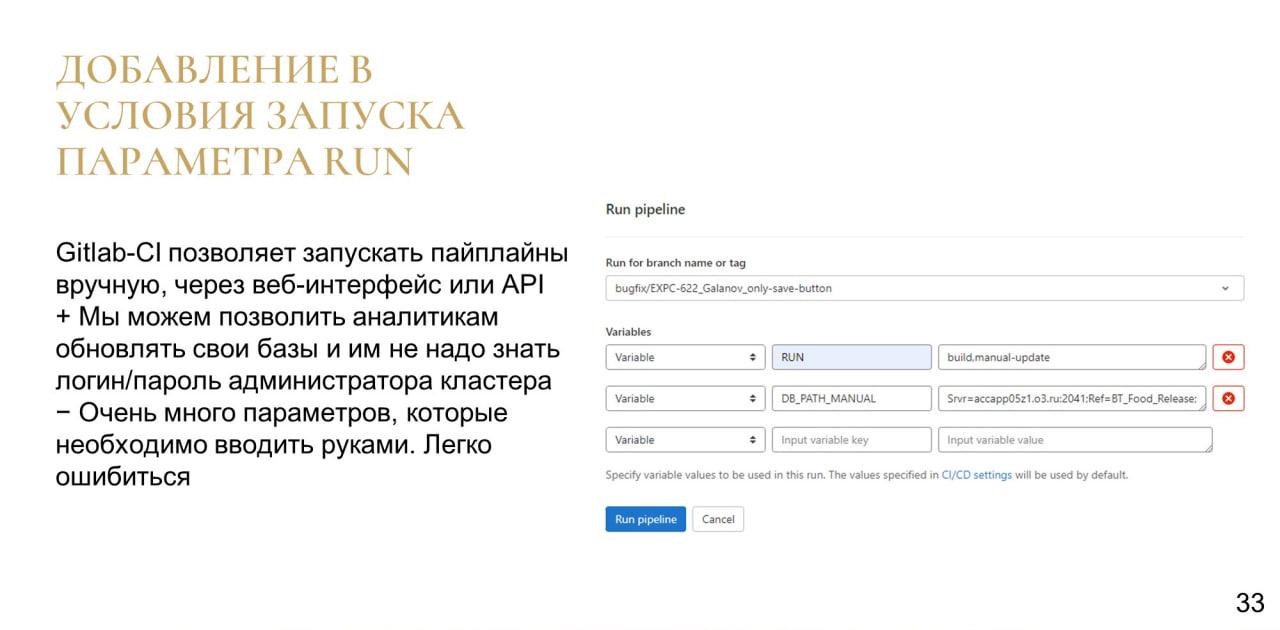
Дальше хочу рассказать, как мы решили облегчить жизнь нашим коллегам.
Итак, у нас уже есть CI, который может обновлять базы. Который знает логин, пароль администратора кластера и может сбрасывать сеансы, блокировать базу, разблокировать базу. Так почему бы нам не дать этот инструмент нашим коллегам, которым часто нужно обновлять какие-то модельные стенды или свои базы?
Поэтому мы добавили параметр RUN.
Через веб-интерфейс GitLab мы можем указать, что для такой-то ветки мы хотим запустить pipeline с определенными переменными:
-
В переменной RUN мы указываем, что нужно сделать
-
Во второй переменной в данном примере указывается, какую именно базу нужно обновить собранной конфигурацией.
Но когда очень много параметров делать это через веб-интерфейс GitLab может быть не очень удобно.

К счастью, GitLab имеет свой API – довольно простой. Простым запросом к API мы можем запустить pipeline.
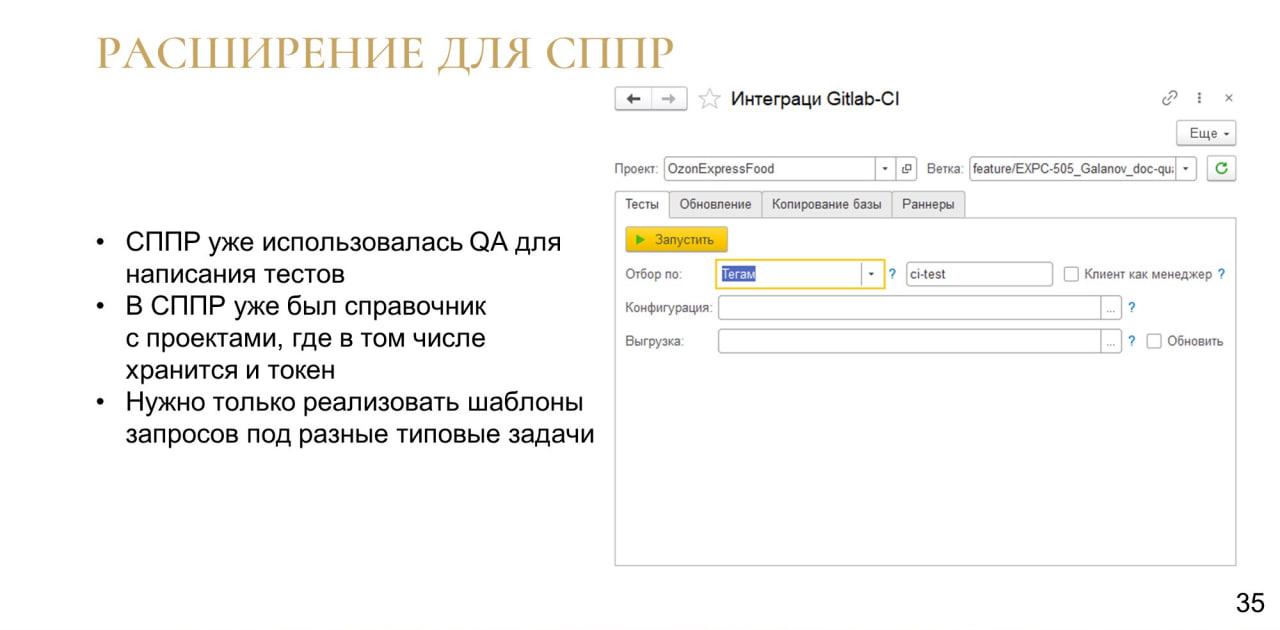
У нас в команде QA-инженеры уже используют СППР, а в СППР уже есть справочник с проектами, где есть токен доступа.
Поэтому мы сделали расширение, через которое можно запускать какие-то типовые задачи, которые мы делаем с помощью CI, относящиеся именно к облегчению жизни коллег.
Хочу заметить, что это расширение мы собираем и доставляем на рабочую базу СППР также с помощью GitLab CI.
Интеграции с сервисами

Дальше вкратце расскажу про интеграцию с сервисами.
Для общения внутри команды мы используем Slack. Поэтому мы создали, во-первых, бота на api.slack.com и создали два технических канала.
-
В первый приходили вот такие оповещения о статусе сборки конфигурации и о статусе обновления баз stage и prod.
-
А во второй приходили оповещения о тестах, если они прошли неудачно.
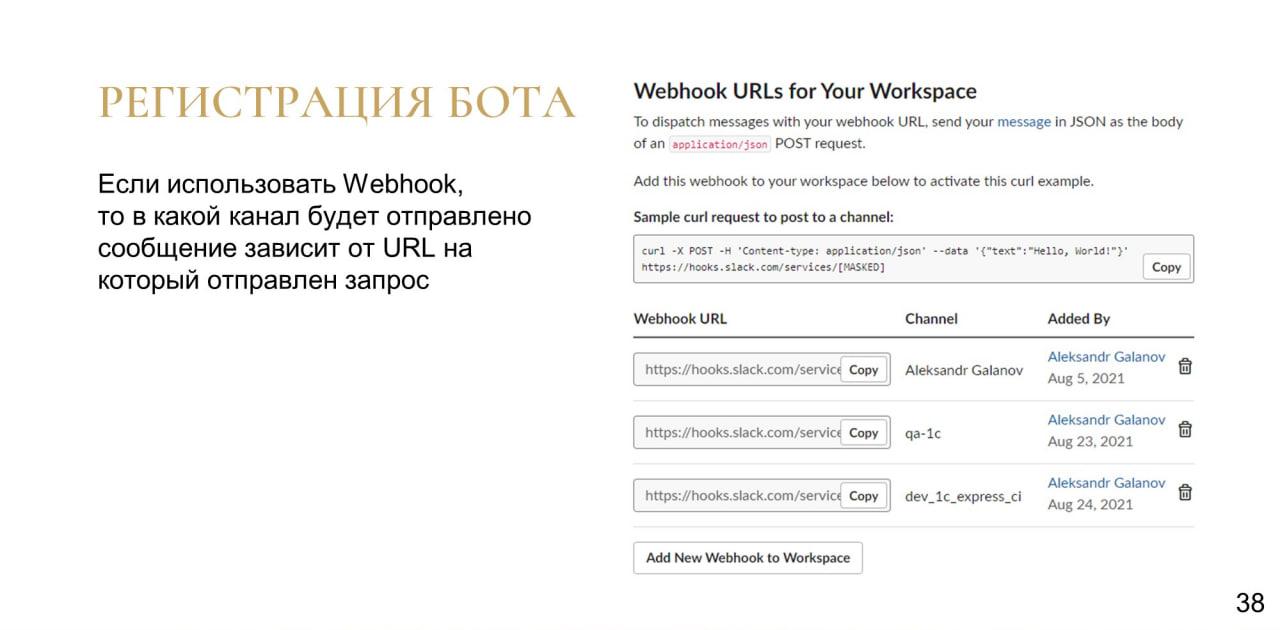
Зарегистрировать бота не составит каких-либо проблем. И отправить сообщение через webhook, опять же, будет очень просто.
Мы регистрируем webhook для каждого канала. И, отправляя запрос на определенный URL, в котором, по сути, одно поле – это само сообщение, мы реализуем его отправку в этот самый канал.

Как я сказал, мы у себя используем Jira, где для тикетов применяем механизм версий.
К сожалению, иногда бывает так, что кто-то забывает указать в своем тикете планируемый релиз в поле fix version. Либо после того, как изменения по задаче все-таки были влиты (допустим, это какая-то экстренная доработка) мы можем забыть для нее указать fix version.
Чтобы это решить, мы сделали следующее. Мы с помощью команды:
git log --pretty=format:"%s" master..release
можем получить список всех коммитов, которые у нас появились в релизной ветке с момента ее отделения от мастера.
А дальше, пройдя их регулярными выражениями, мы можем получить тикеты. Потому что у нас есть общее соглашение, что тикеты называются как:
feature/[Тикет]-[Фамилия]-[Описание]
Поэтому мы однозначно можем получить список тикетов версии и дописать в них fix version, если он где-то не был написан.
Что нам дал CI?

Итак, что же нам дал CI?
Во-первых, контроль технического долга.
-
Код соответствует методическим рекомендациям.
-
Нам легко контролировать ошибки, которые могли вдруг ускользнуть при ревью.
-
Да, необходимо актуализировать белые списки при обновлении версии ERP.
-
Но экономия времени на проверке кода будет неоценима.

Также сценарное тестирование.
-
Оно начинает экономить время уже на третьем-четвертом прогоне. И если вы еще не используете Vanessa на своих проектах, решительно рекомендую.
-
У нас реализуется проверка каждой сборки – но на это не тратится время команды.
-
К результатам тестов всегда можно вернуться в Allure, ну или, опять же, в самом веб-интерфейсе GitLab.

И дальше обновление без участия человека.
-
Больше не надо тратить время на обновление базы – не надо никого дергать с вопросами, если тебе необходимо, чтобы обновили какой-то модельный стенд.
-
Больше не надо назначать дежурного для обновления во время технологического окна.
-
И пароль от кластера знает только CI.
Вопросы
Планируется ли выложить вот эти YML-файлы, какие-нибудь файлы настроек, (естественно, без секретных данных) в Open Source?
Не могу сейчас ответить на этот вопрос, потому что для меня, как для работника Ozon Express, это все-таки является интеллектуальной собственностью компании. Это нужно, опять же, уточнить. Но хочу сказать, что я в будущем планировал написать на Инфостарте серию статей по именно настройке GitLab CI, потому что, как я сказал, хотя описание того, как необходимо формировать YML файлы, есть на сайте GitLab, но там требуется некоторое знание английского языка и, опять же, это не такой распространенный все-таки в среде 1С инструмент, как Jenkins.
У вас на слайдах было написано про Code quality для GitLab. Что официальный формат для GitLab?
Да, если зайти в документацию GitLab по GitLab CI, там есть целый раздел по поводу того, в каком формате можно отправлять в GitLab отчеты. При этом code quality и отчеты в формате JUnit по тестам — это не единственное, что можно отправлять. Там есть целый раздел по поводу того, какие именно в секции reports мы можем отправлять отчеты. Там, допустим, можно собирать какие-то метрики, которые мы будем потом просматривать в GitLab. И вот я сейчас все на память не вспомню, но там довольно обширный набор того, что можно отправлять, что потом будет отображаться в самом пайплайне. И набор тех форматов, которые он поддерживает, время от времени увеличивается.
Это случайно не в Enterprise Edition версии GitLab? Есть такое в Community-версии?
JUnit точно есть штатно. Code quality тоже, по-моему в комьюнити-версии есть. Нужно проверить.
Где вы храните пароли к скриптам, к 1C и так далее? Те переменные, которые на слайде были показаны, они в общем-то в явном виде хранятся, и если у тебя есть доступ к репозиторию, ты видишь все пароли. Как вы делаете?
На слайде было показано только те переменные, которые у нас указаны именно в самом YML файле, который несомненно виден в репозитории, и все, кто имеет право просматривать этот репозиторий, могут узнать пароль, если мы его там занесем. Поэтому, естественно, мы так не делаем.
В настройках CI у пользователей с правом мейнтейнер есть возможность назначать переменные, которые будут по умолчанию отправлены всем пайплайнам.
Там мы именно и храним пароли, они у нас становятся доступны как переменные окружения при выполнении скрипта. И нам дополнительно еще доступно указать для этих переменных флаг masked, и тогда они будут скрыты.
Если у нас где-то эта переменная еще, допустим, в логах проскользнет, она будет гитлабом заменена на слово masked.
Поэтому мы можем, допустим, для цели отладки выводить, допустим, команды, которые у нас дергаются гитлабом, и не бояться, что там проскочит какая-то чувствительная информация, потому что, поскольку эти все переменные имеют признак masked, гитлаб их сам скроет.
Есть особенность, насколько я понял, что вот это маскирование выполняется регулярными выражениями, и в описании к этим переменным указано, что не все символы можно использовать, не менее трех и так далее. Вот вы не сталкивались с этим вопросом?
Да, есть такое ограничение. Когда мы столкнулись, мы просто немного изменили пароль так, чтобы он мог быть маскирован.
Чем полезны секретные переменные? Иногда выясняется, что используются очень простые пароли. Например, кто-то поставил пароль 1 или 12, и потом, когда в логах смотрели, неожиданно какое-то простое сообщения, и там вместо цифр звездочки. Начинаем смотреть, оказывается, сообщение совпало с паролем, и это сообщение маскируется. И очень легко вычислить такой пароль.
Но в целом могу сказать, что у нас внутри Озона, в том числе, используется Vault для хранения паролей, и в перспективе у нас намечено, что в будущем было бы хорошо на него перейти.
Но этот проект у нас довольно молодой, поэтому это пока еще в планах.
Как вы боретесь с большим количеством этих переменных? Потому что когда большой стейдж, получается очень много баз, логины, пароли, пути и так далее.
Я могу сказать так. У нас сам GitLab поддерживает возможность прямо в репозитории писать вики-страницы. И вот пока лучшее, что мы придумали – это вики-страницу, в которой именно описаны переменные по разделам.
Смотришь раздел, где должна находиться эта переменная, находишь ее. Смотришь, какая именно что делает, и дальше находишь ее уже в настройках.
В будущем, конечно, хотелось бы перенести это, возможно, в расширение для СППР чтобы там это хранить для пользователей только с определенными ролями, с возможностью изменений. Но это все пока еще в планах.
Пока приходится хранить этот огромный список в секретах GitLab. И не очень удобно ориентироваться в нем, конечно.
У меня вопрос про конвертер отчета, который передает результаты синтаксической проверки конфигурации в SonarQube. Это какой-то открытый инструмент или вы вручную все это конвертируете?
Нет, этот инструмент был именно написан в рамках этого проекта, потому что, когда мы решили, во-первых, использовать вот эту проверку конфигуратором, мы ее получили, но мы поняли, что работать с ней неудобно.
И тогда мы начали смотреть, какие есть варианты как-то удобнее с этим работать и как раз наткнулись в документации GitLab на описание Code Quality.
И решили, что было бы хорошо написать какой-то конвертер. Он, сразу скажу, несовершенен. У нас есть часть случаев, которые он не обрабатывает или обрабатывает некорректно. Мы еще постепенно иногда что-то отлавливаем и доотлаживаем. Но в целом он позволяет более удобно видеть новые ошибки, видеть, к какому файлу они относятся, и что это за ошибка.
В vanessa-runner уже есть похожий инструмент – команда syntax-check, которая как раз реализует эту проверку в разных режимах, разбирает выхлоп от конфигуратора и тоже собирает ее формат JUnit, формат Allure. Может быть, стоит туда как-то тоже вложиться, сделать там такое же решение по аналогии? Это опенсорсный инструмент.
Возможно, я подумаю на эту тему.
Вы рассказали, что у вас все запускается через GitLab CI, а потом показали еще Jira. Из Jira что-то запускается или Jira просто показывает?
Нет, из Jira ничего не запускается. Jira была показана в том контексте, что мы используем там релизы, и в релизы у нас набиваются какие-то задачи, которые в рамках релиза были сделаны.
Релизы попадают те, у которых в поле fix version указан этот релиз. Но иногда бывает так, что для какой-то задачи забывают указать fix version. И, соответственно, у нас CI пробегает эти тикеты и находит те, в которых у нас не заполнено fix version, а должно быть. И записывает туда нужное значение через API Jira.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Moscow Premiere.
|
30 мая - 1 июня 2024 года состоится конференция Анализ & Управление в ИТ-проектах, на которой прозвучит 130+ докладов.
Темы конференции:
Конференция для аналитиков и руководителей проектов, а также других специалистов из мира 1С, которые занимаются системным и бизнес-анализом, работают с требованиями, управляют проектами и продуктами!
|