



Постоянный процесс поиска узких мест в производительности обслуживаемой базы или баз - это архиважная задача, которая должна решаться в первую очередь. Мы должны делать так чтобы наши сервисы работали быстро и пользователи были довольны. Но тут у нас с технической стороны возникают вопросы:
- Как найти проблемные участки в коде, решение которых даст наиболее ощутимый эффект?
- С чего лучше всего начать выполнять оптимизацию?
- Где проблема находится в конфигурации?
- Какую нагрузку дают эти запросы? Какая длительность выполнения? Как часто повторяются?
На такие вопросы мы сегодня дадим ответ - расскажем об одном из возможных путей решения. Инструменты, которые нам понадобятся БЕСПЛАТНЫ - Фреймворк Мониторинг производительности. От вас понадобится холодная голова и 15 минут свободного времени. Работаем в режиме: быстро, просто, качественно и точка.
Шаг 1. Настройка загрузки длительных запросов
Искать долгие и длительные запросы, которые выполняются 50-100 с и более мы сможем, если подключим замер Длительные запросы (смотрим в статье 5 простых шагов и 15 минут на разворачивание инструмента мониторинга проблем производительности базы 1С).
Только в этом случае время сохранения запросов мы установим в районе 5с, при желании можете уменьшить это время самостоятельно. Но значения меньшие 1с ставить не рекомендуем, вам будет достаточно для начала и такого порогового значения.
Шаг 2. Настройка замера - Частотный анализ запросов
Когда мы смотрим журнал запросов, то мы видим множество замеров. Есть запросы длительностью 5 с, 8 с и другие. Как нам понять, какова причина того что этот запрос попал в замер? Возможно, в этот момент пользователь попал на блокировку или сервер просел под выполнением какого-либо отчета, т.е. это была случайность. Иными словами, оптимизировать запрос, который выполняется 1 раз в месяц, неэффективная цель. Смотрим рисунок ниже в качестве иллюстрации примера.
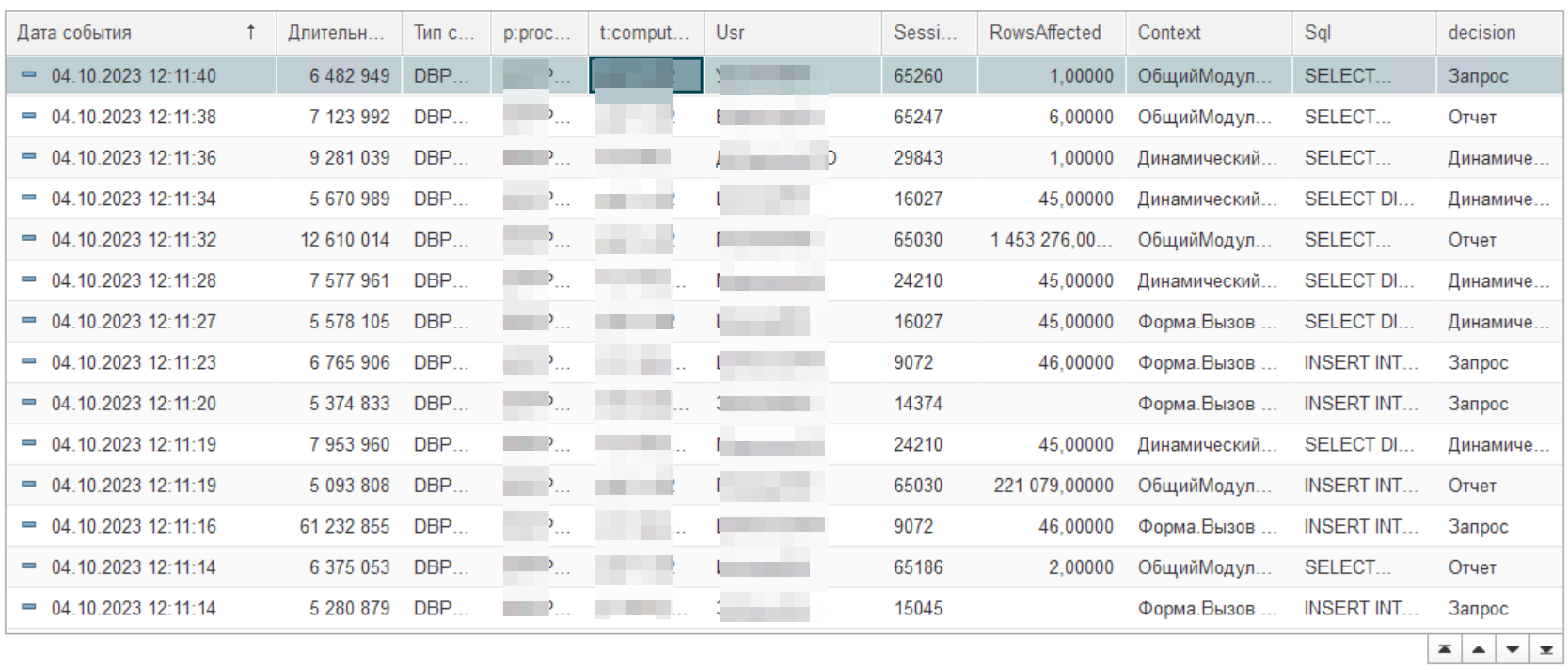
Более взвешенное решение мы сможем принять, если будет информация о количестве повторений такого запроса в день или месяц. И в этом случае нам будет проще принять решение. В итоге мы хотим получить отчет вот в такой форме:
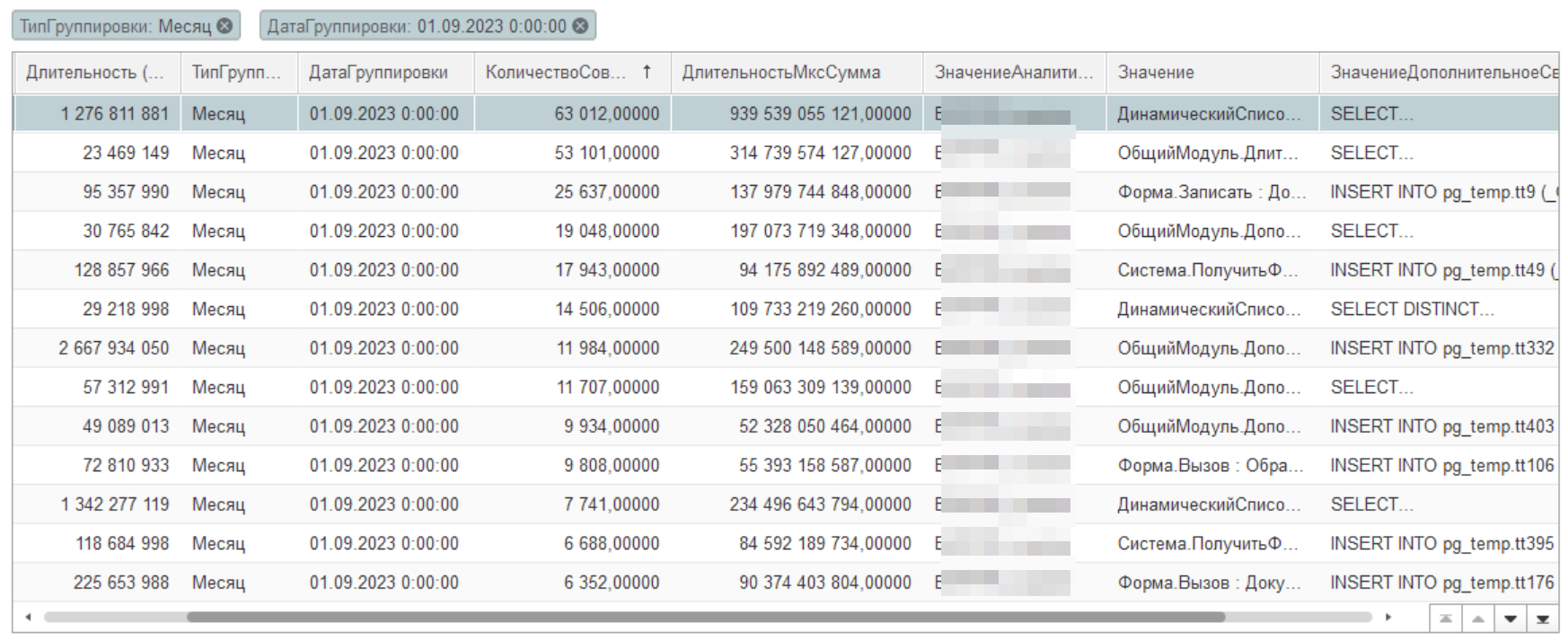
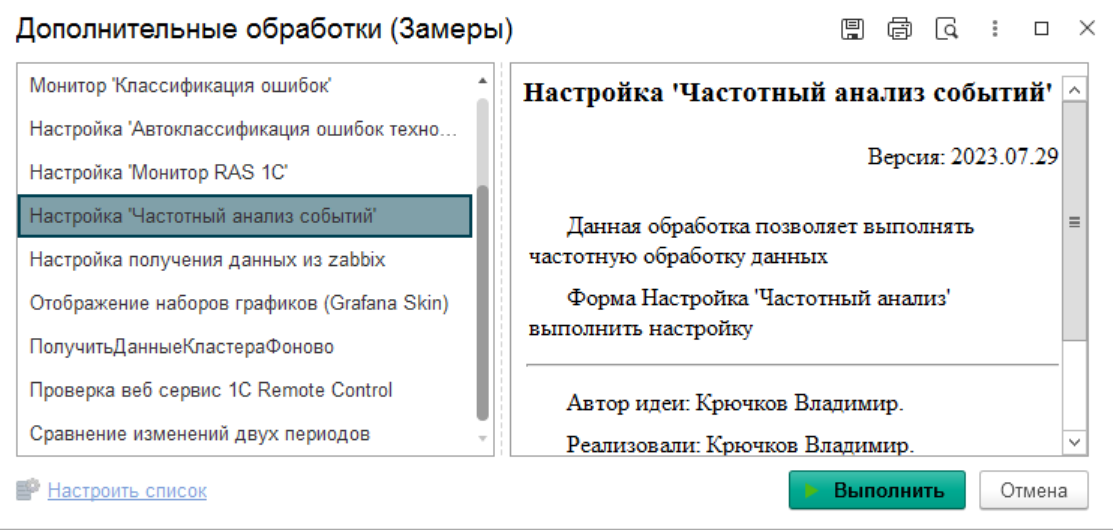
Для того чтобы получить требуемую информацию, нами был специально создан плагин Частотный Анализ (кроме частоты запросов можно считать частоту появления различных ошибок, блокировок и другую технологическую информацию). Принцип работы этого плагина похож на принцип работы плагина для Postgres pg_state_statements с отличием. Мы можем сохранить контекст точки вызова в коде 1С. Что позволит с большим успехом выполнять поиск проблемного участка в конфигурации. Теперь давайте выполним настройку этого замера:
а) Скачиваем плагин ЧастотныйАнализ.epf с репозитария Фреймворка. И загружаем его в дополнительные отчеты и обработки. Обязательно указываем подсистему замеры и режим работы в статус использование.
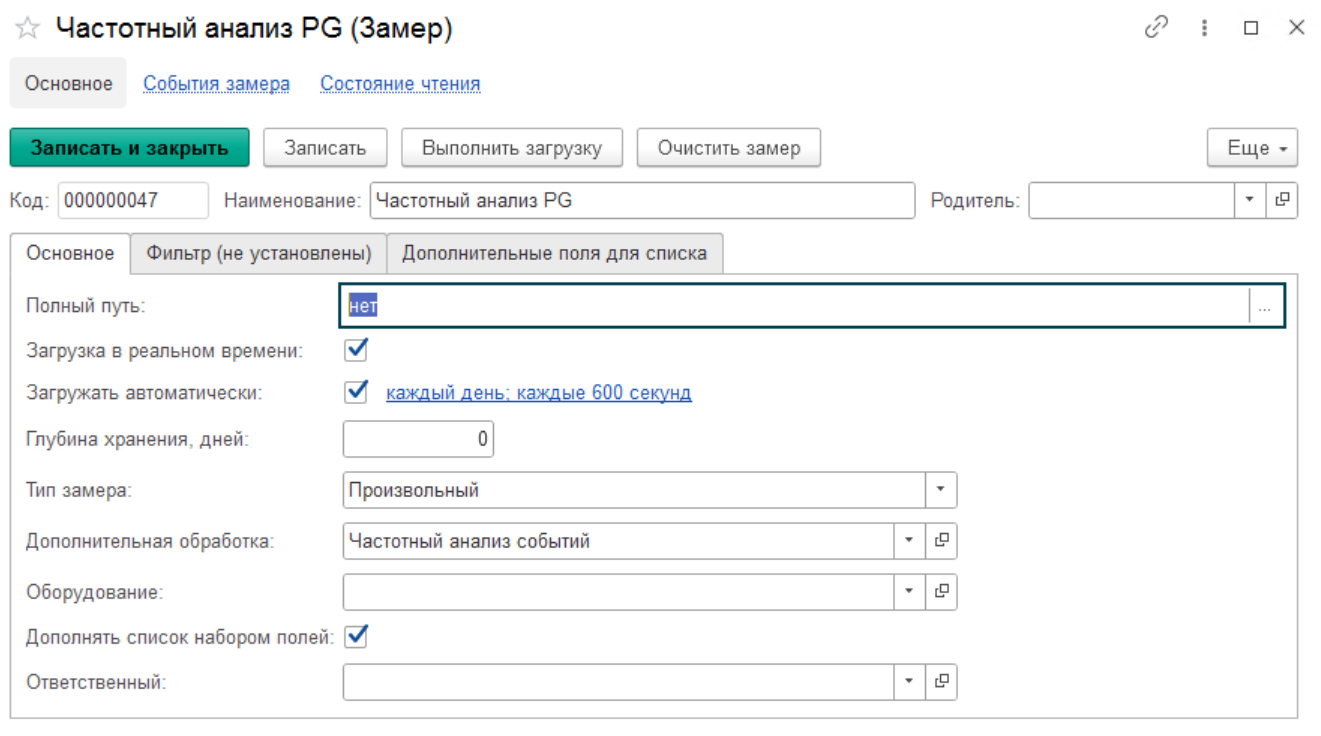
б) Создаем новый замер, который назовем Частотный анализ. Указываем некоторые параметры, которые являются обязательными:
- Наименование - Частотный анализ
- Путь к файлу - пишем слово нет
- Загрузить в реальном времени - истина
- Загружать автоматически - истина. Еще дополнительно настраиваем расписание работы.
- Тип замера - произвольный. И сразу указываем имя дополнительной обработки - Частотный анализ.epf
- Глубина хранения дней - для того чтобы замеры не копились вечно, рекомендуем указать параметр отличный от 0. Выбирать следует с учетом группировок, если вы поставили группировку месяц и хотите сохранять два последних месяца, то ставьте период 90 дней.
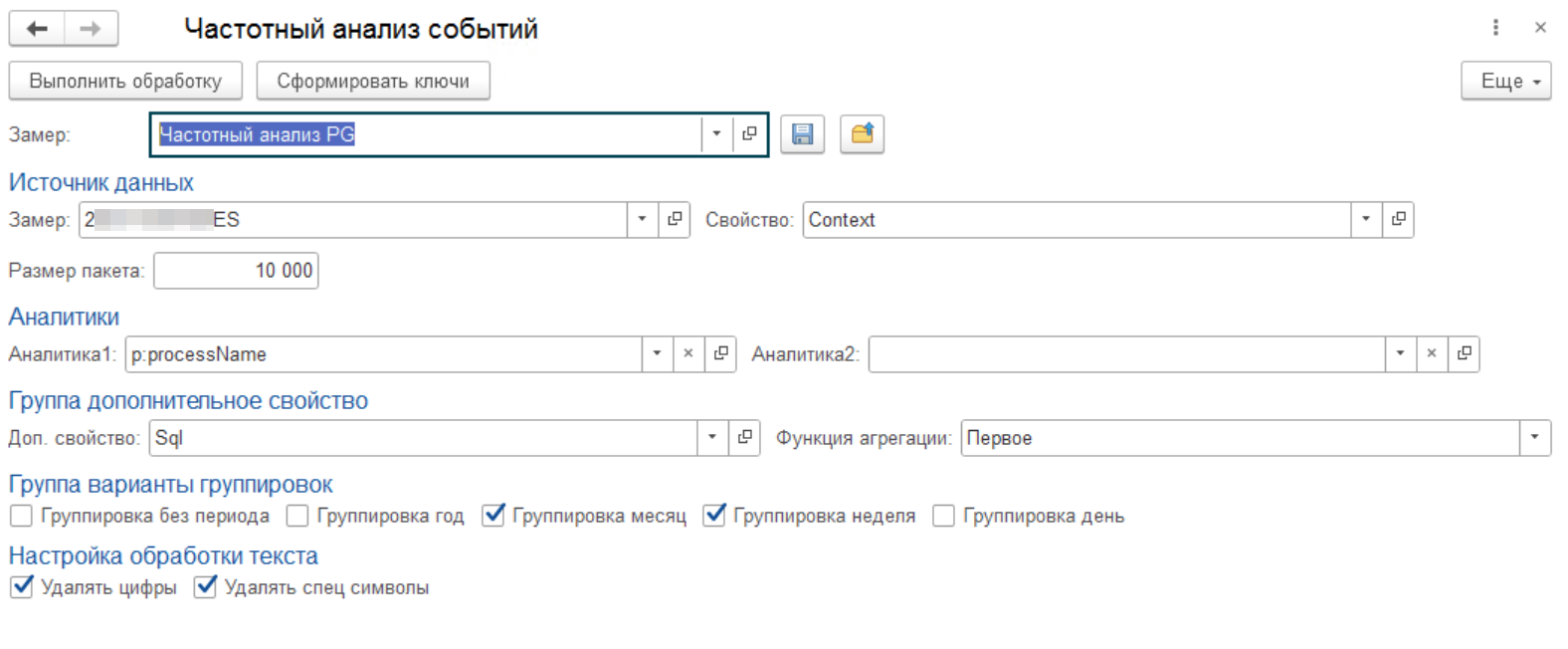
в) Выполняем настройку плагина по созданному замеру. Теперь мы будем выполнять самый интересный этап создания нового замера. Мы постарались сделать эту процедуру прозрачной и понятной. Сначала мы запускаем форму настроек плагина в дополнительных обработках.
Далее настраиваем форму по своим критериям.
- Замер - Частотный анализ. Это тот замер для которого мы делаем настройки. Пункт б).
- Источник данных Замер - Длительные запросы. Замер, который мы создали на первом шаге. Данный замер у вас уже есть или вы его должны создать отдельно в соответствии с инструкцией, которая приведена на шаге 1 (ссылка на статью).
- Источник данных Свойство - Context, это то свойство, по которому мы будем искать совпадения.
В данном случае самый удобный параметр это контекст. Если выбрать запросы, то нам будут мешать параметры, которые платформа автоматически добавляет в SQL запрос, к тому же различные комбинации RLS также будут дробить результат. - Размер обрабатываемого пакета, мы установили в 10000 строк
- Аналитика 1 - p:processName. Это имя базы, нам понадобится чтобы разделять замеры по различным базам.
- Дополнительное свойство - SQL - SQL текст запроса. Это параметр будет сохраняться в результирующем списке замера.
- Функция агрегации - Первое. Указывает как будет сохраняться значение при подсчете совпадающих строк.
- Первое - будет браться из первой записи,
- Последнее - будет обновляться от каждой последней записи,
- Слияние - все строки будут складываться (будьте аккуратнее с этим параметром, т.к. могут получиться очень огромные простыни текста),
- Максимум - берется максимальное,
- Минимум - минимальное.
- Варианты группировок. Определяет в каких временных разрезах будет идти расчет. Мы считаем что самые удобные варианты - месяц и неделя. Будут создаваться отдельные записи замеров с датой начала периода (например 01.10.2023 00:00:00 для начала месяца)
- Без периода
- Год
- Месяц
- Неделя
- День
- Обработка текста. Позволяет убирать лишние и паразитные значения, для того чтобы повысить вероятность совпадения.
- Удалять цифры - будут удаляться все цифровые символы (0-9)
- Удалять спец символы - эта настройка оставит только буквы А-Яа-яA-Za-z.
После выполнения настроек сохраняем и выполняем первую обработку или дожидаемся запуска регламентного задания.
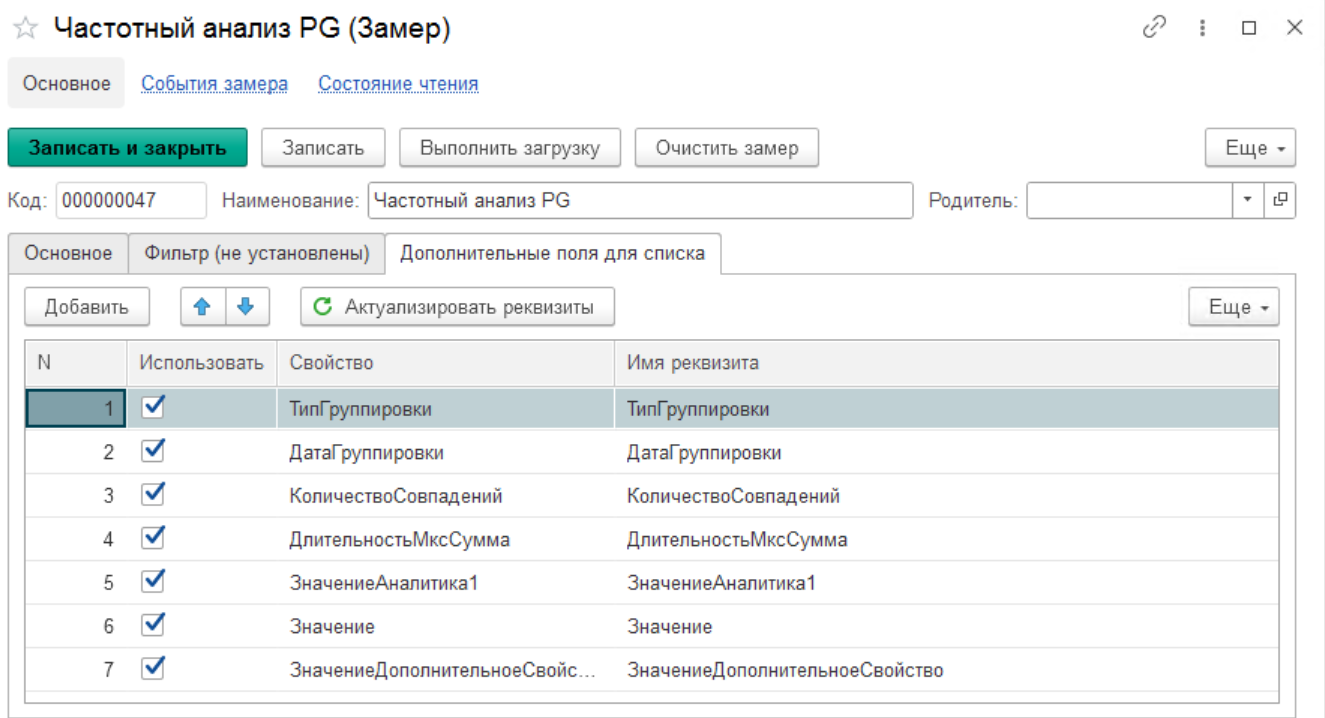
г) Настраиваем отображение списка замера. Указываем дополнительные поля для удобства работы в списке. Мы рекомендуем добавить следующий набор полей:
- Тип группировки - выводит информацию о выбранных группировках - месяц, год, неделя, день
- Дата группировки
- Количество совпадений - показывает количество совпадений шаблонов. Для этого свойства обязательно поставьте признак числовой. Тогда вы сможете в журнале выполнять по нему сортировку.
- Длительность мкс сумма - суммарное время выполнения всех похожих запросов.
- Значение аналитика 1 - выводится аналитика группировки 1, в нашем случае имя базы СУБД.
- Значение - само значение аналитики
- Значение дополнительное свойство - произвольное значение выбранного свойства замеров, в нашем случае SQL текст запроса.
Шаг 3. Выполняем анализ результатов
После того как мы выполнили все необходимые настройки, запустили обработку данных, мы можем наконец-то провести анализ полученных результатов и создать задачки на исправление найденных проблемных запросов. Сначала выполним сортировку по количеству совпадений (или по суммарной длительности) и возьмем первое событие.
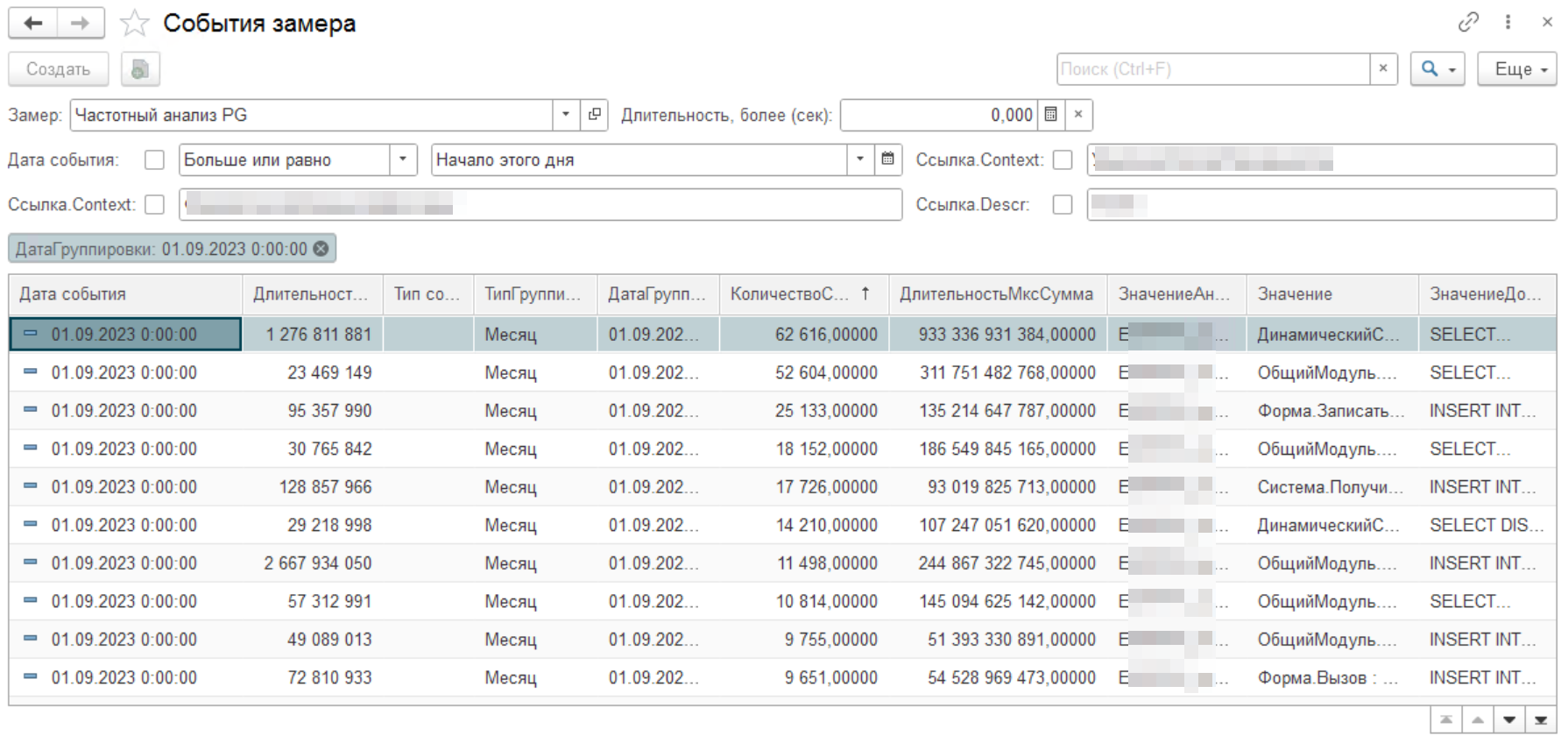
Давайте посчитаем среднее время выполнения запроса 933 336 с / 62 616 = 15 с. Время его работы в месяц 259 часов или почти 11 дней. Как вы понимаете данная проблема требует оптимизации.
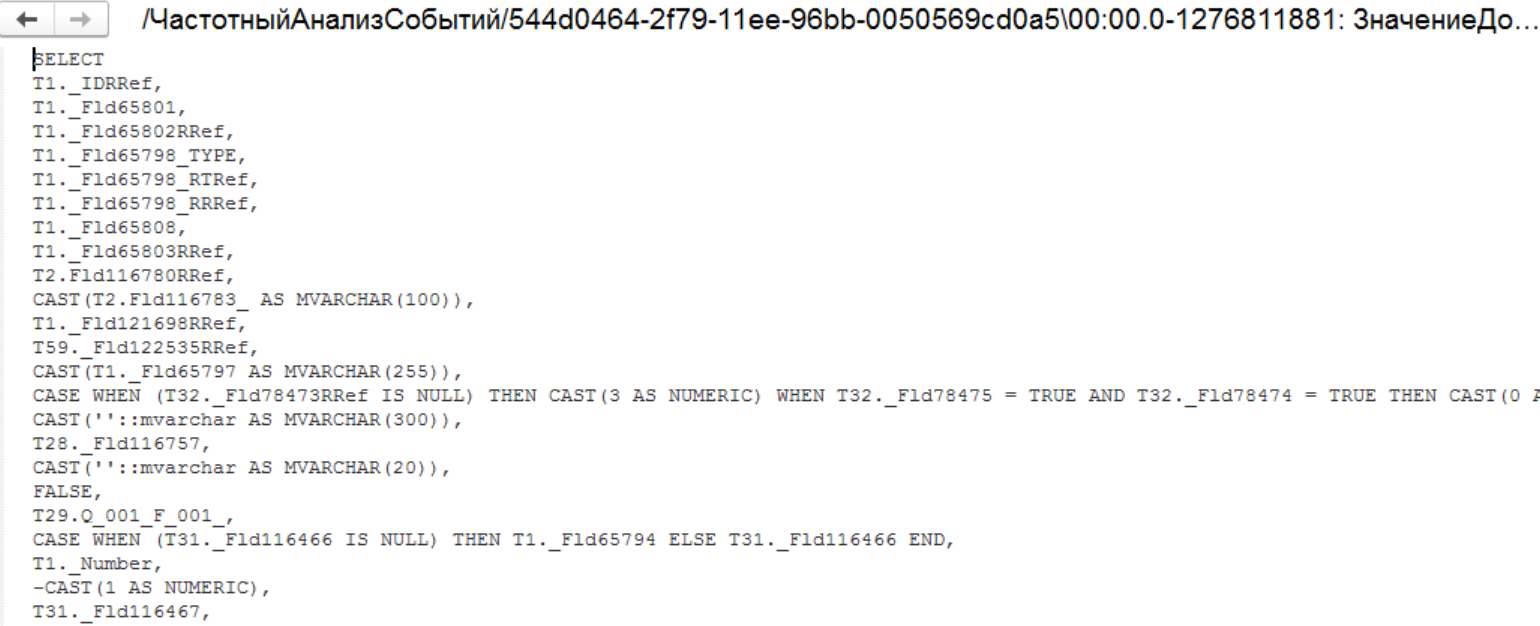
Смотрим контекст:

У нас есть даже SQL запрос, который мы можем выполнить. Разбор данного случая мы приведем в отдельной статье. Это тоже очень интересный отдельный случай. Тот момент, когда в тиражной конфигурации применяют не очень хорошее решение с точки зрения производительности, но зато, казалось бы, отличное с точки зрения пользователя.
Дальнейший разбор, анализ и исправление этой ситуации мы проведем в следующей статье. Ожидайте...

P.S. У нас совсем недавно вышел новый релиз фреймворка. Кроме текущего плагина частотного анализа событий у нас теперь есть поддержка разбора технологического журнала под linux, спасибо GenVP, два новых отчета - контроль изменения производительности и количество сеансов лицензий.