Данная статья актуальна для программистов и администраторов SQL-версии 1С:Предприятия 7.7 с УРБД. Если использовать 1С: Предприятие 7.7 (SQL) достаточно интенсивно, может происходить поломка (разъехались остатки, обрушились индекы, перестали проводиться документы из-за ошибок SQL и т.д.., в общем база "накрылась"). Можно проводить проверку, переиндексацию базы на SQL Server, мараковать с объектами 1С, копировать и удалять объекты, использовать всякие выгрузки-загрузки, но все это совсем не айс. Когда обмены в распределенной базе данных 1С Предприятия 7.7 выполняются достаточно интенсивно, решить проблему можно универсальным способом без плясок с бубном с помощью УРБД за 10-20-30 минут.
Когда не помогает DBCC DBREINDEX ("RA4674")...
Violation of primary key constraint 'PK_RA4674'. Cannot insert duplicate key in object
Эта статья для администраторов и программистов 1С, если Вы не имеете достаточных знаний и полномочий, выполнять эти манипуляции на реальных данных нельзя (пока не научитесь).
Статья описывает порядок восстановления периферийных и центральных баз УРБД (в обмене участвуют все объекты, компонента "Расчет" не используется).
Если в периферийной базе некоторые объекты не мигрируют в ЦБ или наоборот в центральной базе есть объекты, которых не должно быть в перефирийке, использование этого способа восстановления не опробовано, при обмене необходимо учтитывать возможные несоответствия, которые можно выявить сравнением структуры объектов и модулей конфигураций центральной и периферийной базы и настройки правил обмена.
Как восстановить работоспособность информационной базы 1С:Предприятие 7.7 (SQL) на распределенке (УРБД)? Используем следующей рецепт (Windows Server 2003 + MS SQL 7), в случае файловой базы можно опустить шаг 5:
1) Пользователям периферийной базы отправляем команду Пуск - Выполнить -> net send * за 10 минут до начала операций "через 10 минут всем выйти из 1С7.7!" Начинаем в конфигураторе выполнять обмен. Для тех, кто не в курсе как это делается - пример порядка ручного обмена в УРБД.
2) В конфигураторе центральной базы выполняем автообмен (выгрузку из центральной базы в периферийные базы). Для этого в
центральной базе устанавливаем флажки (выгрузка "префикс периферийной базы ПБ").
3) Повторное сообщение net send "Всем выйти из 1С7.7!" Если закрывашка встроенна в базу, воспользуемся ей.
4) Выгоняем всех пользователей из периферийной базы. Закрываем на сервере открытые файлы периферийной базы: Пуск - Мой компьютер - Управление - Общие папки - Открытые файлы - контекстное меню - все задачи - закрыть открытый файл. Желательно выгонять пользователей не в одиночку, ато если они успеют "пролезать" в базу sql тогда мароки по их выгону гораздо больше.
5) Удаляем сеансы периферийной базы на сервере SQL - в Query Analyzer хранимой процедурой sp_who смотрим кто в базе, в дальних колонках написано название базы, и на всех жертвах, кто остался в нашей периферийной базе выполняем команду "kill НомерПроцесса".
6) Иногда (после длительной яростной "зомби-фермы" с пользователями с многократным глубоким проникновением в 1С и выкидыванием) базу данных для обмена открыть невозможно. Файлы закрыты, процесса на SQL сервере нет, а в мониторе пользователь висит. В этом случае удаляем из временные файлы из профиля пользователя и вре менные файлы 1С из общего профиля. Неисключено, что прийдется перезагружать сервер 1С.
//Если бы мы просто выполняли обмен, а не восстановление периферийной базы, то порядок действий был бы следующий. В
//периферийной базе выполняем обмен - загрузку из центральной в периферийную и выгрузка из периферийной в центральную
//(для этого запускаем в конфигураторе периферийной базы автообмен и устанавливаем флажки загрузка ЦБ и выгрузка ЦБ, где
//ЦБ - префикс центральной базы). Пишем пользователям периферийной базы сообщение "можно работать в 1С". Вместо этого делаем следующее:
7) В поломанной периферийной базе выполняем обмен - выгрузка из периферийной в центральную (для этого запускаем в конфигураторе периферийной базы автообмен и устанавливаем флажок выгрузка в ЦБ).
8) Для всех периферийных баз, где не нужно восстанавливать бекап, выполняем загрузку из центральной и выгрузку в центральную.
9) В центральной выполняем обмен - загрузку из периферийной базы в центральную (загрузка ПБ) для всех периферийных баз.
10) Средствами SQL Server делаем бекап центральной базы и загружаем его в ту периферийную, которая не работает. В центральной базе предварительно стоит обрезать журнал регистрации SQL (сделать shrink) потому что он тоже размножится по периферийным базам когда мы загрузим в них Бекап. Шринк делается как написано в отдельной статье //infostart.ru/public/168314/
11) Удаляем в новой периферийной базе таблицы 1SDWNLDS, 1SUPDTS, CJ7287, CJ7289. Таблицы CJ7287, CJ7289 относятся к компоненте "Расчет" и способ их преобразования при замене периферийной базы централкой мне не известен, но заменить их из бекапа не удается, в центральной базе они бывает портятся (нарушена структура индексов CJ7287, CJ7289 и центральная база без монопольного режима не стартует) .
12) В таблице _1SDBSET есть поле DBSTATUS, оно может принимать следующие значения: P - Центральная M - Текущая N - Периферийная (непроинициирована) C - Периферийная. Редактируем таблицу в новой периферийной базе 1SDBSET, удаляем в ней все строчки кроме строчки данной периферийной ПБ и центральной ЦБ базы. В оставшихся двух строчках меняем статусы, в колонке DBSTATUS переназываем, меняем местами значения полей M и P.
13) В новой периферийной базе в таблице _1ssystem меняем префикс центральной ЦБ на префикс периферийной ПБ.
14) В новой периферийной базе в конфигураторе прописываем соединение с SQL базой.
15) Актуализируем оперативные итоги в периферийной базе (Управление оперативными итогами - делаем расчет оперативных итогов) и последние документы из последовательностей проводим текущей датой.
16) В режиме 1С: Предприятия устанавливаем константу "Префикс информационной базы Для УРИБ "ПБ"
17) Все, пишем пользователям периферийной базы сообщение "можно работать в 1С". После того, как научились выполнять такое восстановление периферийной базы, особенно если периферийных баз несколько, можно больше не делать ежедневные бекапы.
Техническое описание механизмов УРБД изложено в статьях
http://kb.mista.ru/article.php?id=20
http://kb.mista.ru/article.php?id=45&
http://argat.h11.ru/URBDStructure.html
http://1c.proclub.ru/modules/newbb/viewtopic.php?topic_id=258258&forum=2&viewmode=flat&order=ASC&start=all
Альтернативный метод "обрезки" ("свертки") базы 1С.77 на конкретную дату через УРБД
//infostart.ru/public/17072/
Плагин для лечения выгрузки и загрузки больших баз в 1С 7.7
//infostart.ru/public/15364/
Быстрый метод создания периферийной базы УРБД (скрипт SQL)
//infostart.ru/public/92564/
Перенос данных из 1С:Бухгалтерия 7.7 в БП 3.0 | Продукт является развитием и исправлением ошибок стандартной обработки для выгрузки данных из 1С Бухгалтерии 7.7 в Бухгалтерию 3.0 | Предоставляем техподдержку | Обновляем на новые релизы 1С | Перенос из 7.7 является сложным, и на рынке сложно найти специалистов 1С по "семерке" - наши сотрудники помогут вам выполнить переход в рамках техподдержки предлагаемого переноса данных!
Конфигурация предназначена для организации offline доступа клиента (покупателя) к информации о товарах, услугах или дисконтных картах посредством сканирования штрих-кода. Основная цель – мгновенно предоставить наиболее актуальную информацию о цене, остатках, наименовании товара (услуги) или накоплениях, держателе, состоянии дисконтной карты.
Обработка и правила обмена данными для выгрузки документов и всех связанных с ними справочников из 1С7.7 ТиС 9.2 в 1С8.3 БП 3.0 через файл XML. В типовых конфигурациях уже есть такое решение. Это немного доработанные правила и сама обработка выгрузки, добавлена возможность устанавливать отбор по выгружаемым документам по Фирме, Контрагенту, Складу, Проекту, Автору, ЮрЛицу. А также это внешняя обработка, что даёт возможность адаптировать её под нетиповую ТиС.
Обработка и правила тестировались на платформах: 1С: Предприятие 7.7 и 1С: Предприятие 8.3.18.1334. На типовых конфигурациях: «Торговля + склад», редакция 9.2 (7.70 1004) и «Бухгалтерия предприятия» редакция 3.0 (3.0.96.30).
Начните вести учет в УТ 10.3!
Перенесите все свои данные в УТ 10.3 в любом месяце года и продолжите вести учет!
Программа перенесёт любое количество баз с документами и остатками в больших количествах.
Обработка выгрузки выполнит проверку исходных данных и сформирует отчет о найденных ошибках в справочниках и документах.
Партии переносятся с себестоимостью. Штрихкоды номенклатуры загружаются. Цена переносится. Автор консультирует.
Как известно, Бухгалтерия 7.7 не имеет штатной возможности для обмена с ЗУП 3.1. Данная разработка пригодится тем, кто перешел с ЗиК 2.3 на ЗУП 3.1, но вынужден по каким-то своим причинам оставаться на Бухгалтерии 7.7.
Обработка позволяет выгружать данные из ТиС 7.7 в конфигурации 8.3 для сдачи отчетности, для переноса данных при переходе на 8.3, для организации обмена внутри компании при использовании разных версий 1С в структурных подразделениях или формирования отгрузочных накладных для клиентов.
При переходе на новую версию 1С в период параллельной эксплуатации может возникнуть необходимость обратной конвертации данных (по правилам КД версии 2.1) из 1С:Предприятие 8.3 в 1С:Предприятие 7.7 для переноса данных из 1С:Предприятие 8.3 в 7.7. Сделать это поможет следующая инструкция по КД2 о том, как создать новую конвертацию из 8.3 в 7.7, сохранить модуль и правила загрузки данных, сделать загрузку данных. КД2.
Описание технологии загрузки любых адресов из 1С 7.7 с разложением по ФИАС в современные конфигурации 1C 8.3 на примере ERP. Предлагаемый способ просто чудо, он гарантирует результат, он очень простой и качественный! Моя обработка является синтаксическим анализатором, который подставляет в строку грязного адреса выражение "Дом №" и "Корпус", благодаря чему грязные адреса 7.7 сами очень хорошо раскладываются по значимым полям ФИАС - заполняется область, город, улица, дом, корпус.. все раскладывается само с помощью встроенного механизма современных конфигураций 1С 8.3, который написали сами сотрудники фирмы 1С!
1С:Предприятие 7.7. Управление распределенными базами данных
Управление распределенными базами данных (УРБД) - компонент системы программ 1С:Предприятие 7.7. Инструмент, предназначенный для работы базы данных в распределенном пространстве. При помощи этого механизма решается много разных задач, таких как работа удаленного склада, консолидация информации с филиалов, работа бухгалтера на дому (для плохих бухгалтеров, дома надо отдыхать :-)), еще много всего. Техническую документацию механизма воссоздавать здесь не буду, для этого есть довольно много ресурсов в сети, или сайт производителя, фирмы 1С, у которого или партнеров которого можно приобрести этот продукт. Остановлюсь на информации, которая не опубликована (или я не находил), а именно - о внутреннем устройстве системы и возможностях, лежащих за пределами задекларированных производителем.
Схема данных и принципы работы системы.
Информация в системе организована довольно просто. Это обусловлено простотой механизма и ориентацией всего 1С:Предприятия 7.7 на небольшие фирмы, у которых даже сетевик приходящий, не говоря об администраторе баз данных. Все должно быть предельно просто, функционально ограничено и иметь минимальную возможность ошибки. ER-диаграмма схемы данных приведена на рис.1.
Основная таблица, содержащая описаня баз данных, участвующих в обмене - _1SDBSET. Ниже приведен перечень ее основных полей.
DBSIGN Код базы данных
DBDESCR Описание
DBSTATUS Статус базы. M-центральная, C-периферийная
DBUUID GUID базы. Уникальный идентификатор базы, присваемый при создании
В принципе, достаточно. Остальные поля настроечные - в них хранятся имена файлов обмена, признаки установленного автообмена, адреса и все такое. Всеми этими параметрами можно спокойно управлять с конфигуратора. Следует отметить, что в центральной базе в этой таблице хранится перечень всех баз данных информационного пространства, в периферийной - только себя и центральной.
Следующая таблица, играющая немаловажную роль в работе механизма - _1SSYSTEM Это таблица, в которой хранятся данные об общих настройках базы, таких как точка актуальности, дата рассчитанных бухгатерских итогов, etc. В частности, УРБД касаются такие поля:
DBSIGN Код этой базы
DBSETUUID GUID информационного пространства
Вот и все, касаемо настройки базы данных. Удалите данные из таблицы _1SDBSET - база станет центральной. Удалите поле DBSIGN в таблице _1SSYSTEM, а поле DBSETUUID забейте ноликами вместо чисел - она станет еще и нераспределенной (вопреки предупреждению, выдаваемому системой при распределении базы данных). Манипулируя этими полями, с распеределенным информационным пространством можно делать практически что угодно - переподчинить базу другой базе, переподчинить базу другому информационному пространству.
Таблица, в которой буферизируются изменения - _1SUPDTS. Очень полезная таблица, применять ее можно в задачах, лежащих за областью применения УРБД. Например, одно из моих решений в области аналитических систем для пополнения своей базы данных из базы 1С пользуется именно этой таблицей. В базе-источнике 1С заведена фиктивная периферийная база данных, изменения, которые отражены в этой таблице, обрабатываются уже моим механизмом, для которого важно иметь информацию об измененных с последнего импорта данных объектах.
DBSIGN Код базы, для синхронизации с которой записывется изменение
TYPEID ID типа объекта
OBJID ID объекта
DELETED Признак физического удаления объекта
DWNLDID ID сессии УРБД
При любом изменении объекта система добавляет в таблицу запись для каждой базы данных, в которую должны эти изменения отправиться. Если объект физически удален, в поле DELETED пишется флажок D. В поле TYPEID записывается идентификатор типа объекта (это число, которым идентифицирован объект в конфигураторе), в поле OBJID - идентификатор самого объекта. При выполнении сеанса УБРД все записи из буфера выгружаются в текстовый файл в определенном формате. В поле DWNLDID записывается идентификатор сессии для записей, в которых этот идентификатор не проставлен. Таким образом, в каждую выгрузку уходят все записи, подтверждение приема которых не поступало. При получении подтверждения сесии, идентификатор которой записан в это поле, или любой другой последующей сессии, запись из буфера удаляется.
Последняя, и самая неинтересная таблица - _1SDWNLDS. В ней собрана информация о незакрытых (неподтвержденных) сессиях обмена УРБД в разрезе баз данных. При приходе первого же подтверждения приема данных записи обо всех сесиях, подтвержденной и предыдущих, удаляются.
Структура пакета обмена данными.
Пакет обмена данными - zip-архив, в котором содержатся 2 или 3(если изменялась конфигурация в центральной базе) файла. Файл 1Cv77Dld.id несет в себе информацию о сессии обмена. Содержит единственную строчку
{"Download ID",A37F7532-5939-42F1-BEC8-3FEABB70A128,"EKC",CE395095-F690-42B0-B954-0B99208FC947,"ECM",D76EE5A2-B06E-4E03-8B05-F81138819F59,"2184|EKC"}
A37F7532-5939-42F1-BEC8-3FEABB70A128 GUID сессии обмена данными
"EKC" код базы-отправителя
CE395095-F690-42B0-B954-0B99208FC947 GUID базы-отправителя
"ECM" код базы-получателя
D76EE5A2-B06E-4E03-8B05-F81138819F59 GUID базы-получателя
"2184|EKC" ID сессии обмена данными
Эта же информация повторяется в файле с данными. Назначение этого файла для меня до сих пор загадка, видимо он служит для того, чтобы при попытке обработать старый файл быстро, не открывая большого файла с данными, выругаться, что файл уже принимался системой. Файл 1Cv77Chs.dat несет в себе информацию, которая подлежит синхронизации. Состоит из нескольких узлов. В первом узле, без названия, повторяется информация с файла 1Cv77Dld.id. Во втором - "Distributed data" - расшифровывается эта информация. Не знаю зачем, видимо для улучшения читаемости. Важен подузел этого узла Acknowledgements, который несет подтверждение приема предыдущих выгрузок. Далее идет информация об измененных объектах системы, а именно:"Constants", "References","Documents", "Accounts", "Template Operations" (константы, справочники, документы, счета и типовые операции, соотв). После узлов, несущих информацию об измененных объектах, идут узлы с информацией об удаленных "Deleted References","Deleted Documents","Deleted Accounts","Deleted Template Operations" Информация в файле структурирована имеет древовидную структуру, где ветки отделены знаками {}, а листья "". Путем довольно несложных операций по замене/вставке символов легко преобразуется в XML, с которым можно работать из любого языка программирования, либо поддерживающего OLE, либо имеющего собственный анализатор XML.
Технология работы
Механизм работает очень просто. Система на своем уровне регистрирует изменения в буфере, потом формирует файл выгрузки. Файл выгрузки содежрит в себе информацию о текущей сессии, подтверждение принятия предыдущих файлов обмена, и информацию об измененных и удаленных объектах. При приеме файла выгрузки система удаляет информацию о подтвержденных сессиях, загружает измененные объекты и удаляет удаленные. При удалении удаленных объектов проверяется ссылочная целостность, и если она нарушается - объект не удаляется, а отмечается как измененный. При формировании ответной выгрузки объект, удалить который не удалось, уедет по-новому, как измененный, и успешно загрузится в базу данных. В принципе, по технологии работы все. Инструмент доступен и серьезен :-), как и все продукты этого производителя.
Исключительные ситуации и подводные камни
Коллизии
Коллизии, или конфликты распределенной обработки данных есть везде, где есть оная обработка. Их можно минимизировать, их можно успешно разрешать, но от них никуда не денешься. Порой они могут приносить достаточно много проблем. В УРБД принят метод разрешения коллизий с приоритетом центральной базы данных. Таким образом, при конфликте изменения, сделанные в периферийной базе, затираются, и принимаются изменения в центральной. Это несколько неправильно, особенно неправильно то, что этот метод прошит жестко и не поддается настройке штатными средствами. На мой взгляд, более логичным было бы сделать приоритетными изменения, сделанные в базе, откуда родом объект, (я молчу про пользовательскую настройку метода разрешения конфликта для каждого типа объектов). В принципе, возможна реализация пользовательского менеджера разрешения конфликтов. Но это уже выходит за рамки статьи.
Сбои настроек
Иногда по непонятным причинам крошатся настройки распределенной базы данных. На моей практике такое встречалось несколько десятков раз. Симптомами слета настроек является внезапное поведение периферийной базы данных, как центральной, непринимание файла выгрузки как файла из неизвестной базы, etc. В этом случае наиболее простой выход из ситуации - держать первые (инициализационные) выгрузки периферийных баз, и выгрузку центральной сразу после распределения. В случае слета настройки базы необходимо заново загрузить соответствующую выгрузку и перенести информацию, касаемую УРБД в сбойную базу. Если же этого файла нет - тоже ничего страшного. Информация о настройках описана в этой статье и идет в файле обмена данными.
Надежность автообмена
Пользоваться встроенными механизмами передачи данных 1С (почтовая рассылка) я не рекомендовал бы. У него есть ряд огромных недостатков.
Он шлет некриптованные файлы. Защита файла при помощи пароля архиватора ничего, кроме улыбки, не вызывает.
Он шлет файлы только по одному адресу.
Он их не всегда шлет, равно как и не всегда забирает.
Операционной системе необходимо иметь прописанного почтового клиента по умолчанию.
В случае незакрытой кем-то пользовательской сессии обмен просто не выполнится
И еще много всего
Поэтому, если Вы желаете наладить безлюдный автообмен информацией - лучше напишите (или закажите) скрипты, которые это делают без приведенных мною недостатков.
Ошибки в работе механизма миграции
Механизм выгрузок/загрузок информации УРБД - самый надежный механизм, который я видел реализованным в 1С. Но иногда и он дает сбои. На моей практике я замечал порядка десяти дублирований данных, и столько же - недоставаний их. Практика у меня обширная, как по времени, так и по количеству распределенных баз, которые случалось организовывать и обслуживать, поэтому приведенную статистику можно считать ничтожной в процентном отношении. Но забывать про нее тоже нельзя. Посему я рекомендую проводить сверку на предмет количества записей в таблицах периферийной и центральной баз данных. В регулярные регламентные работы эту можно не включать, но будет гораздо приятней, если этот сбой заметите Вы, а не разгневанный пользователь.
Казусы бизнес-логики
Из описанных мною подводных камней системы самый страшный - когда при проектировании бизнес-логики распределенной системы не учитывали ее распределенность, особенно если назначение системы - не простая консолидация данных самостоятельных бизнес-единиц, а автоматизация одной, но распределенной, например, задачи автоматизации удаленного склада, магазина, или отдела продаж. Приятно наблюдать округленные глаза девочки, которая обнаружила изменения в своем документе после сеанса УРБД, который поменяла на свой вкус другая девочка, и, естесственно, забыла об этом сказать. Еще хуже, когда это изменение сразу не замечено, а обнаружено впоследствии, при инвентаризации, например. Несмотря на то, что проблема выходит за рамки предметной области распределенных баз данных, а в равной степени касается и обычных многопользовательских систем, поверьте - изрядная доля шишек будет сыпаться на механимз и должностное лицо, ответственное за его поддержку. Поэтому, если у Вас на УРБД работает офис и удаленный склад - не надо заводить и проводить расходную накладную менеджеру в центре. В свою очередь, если ее не проводить - есть все шансы продать уже проданный товар несколько раз. Решает вопрос уже прикладной механизм резервирования, а также цепочка документов приказ на выдачу/выдача, вместо всеобемлющей расходной накладной.
Резюме
Управление распределенными базами данных от 1С - для 1С:Предприятие 7.7 лучшее, на мой взгляд, решение для организации собственно распределенных баз. Такие недостатки, как ограниченная функциональность, невозможность фильтровать объекты для миграции по определенному значению полей, невозможность организации системы по принципу "снежинка" довольно просто и дешево устраняются несложным вмешательством в системные таблицы и файлы обмена данными. Экплуатационные ошибки и сбои системы - во-первых, я еще не видел бессбойных систем, во-вторых, нормально налаженный процесс администрирования минимизирует последствия этих сбоев практически до нуля. Ибо знаемая и задокументированная ошибка - не баг, а фича. В целом, деньги, которые стоит компонента, она отрабатывает полностью.
Я давно использую метод описанный в статье для восстановления периферийных баз. Я имею ввиду подмену испорченной периферийной SQL базы базой централки с последующим редактированием таблиц. Также удаляю таблицы если мне нужно оставить скажем одни справочники. Но обычно придерживаюсь принципа если база "шевелится" - выгрузка и загрузка. И все становится на место. Иногда приходилось делать из периферийки централку удалением таблицы 1SSYSTEM. Так что если у Вас УРБД можно спать спокойно. Одновременно сразу все не накроется. Есть еще более жесткие методы к урбд. Это редактирование DAT файла в архиве при обменах. Тот кто делал это тот меня поймет.
(2) Yuris, можете сказать, зачем и как делается редактирование DAT файла в архиве при обменах?
Вы имеете ввиду вот это? Альтернативный метод "обрезки" ("свертки") базы 1С.77 на конкретную дату через УРБД
Исходные даные:
база 7-ки более 12GB с данными за 4 года. УРБД - центр+7 перифериек. Конфига самописная, когда-то на основе типовой "Бухгалтерии".
файл инициализации периферийной базы в архиве - почти 2GB. Не знаю как на 27-м релизе, но до 21-го господа 1С-ники так и не поменяли вшитый zip, поэтому выгрузить данные, которые в итоге в архиве будут весить более более 2GB, не представляется возможным - старый zip не понимает файлы более 2GB. (Поправка - представляется возможным:Плагин romix-a
Как следствие размеров базы - практически невозможно работать: операторы ругаются, всякие манипуляции типа перепроведение / дальнейший обмен по УРБД и т.д. ОООЧЕНЬ трудоёмки (точнее "времяёмки")
Требуется:
в кратчайшие сроки обрезать базу (оставить текущий год)
Испробовано:
все типовые и "не совсем" типовые методы (свертка, пометка на удаление прошлого периода), рокет-ланчеры (и прочие OLE) и т.д. Не испробованы прямые запросы к SQL на удаление, по причине невладения ничем кроме языка 1С.
Основная проблема:
очень долгая пометка на удаление документов прошлого периода, а так же исходное условие задачи - простые юзеры - опера и бухи - не заносят новые остатки в "пустую" базу ручками, обеспечение "преемственности" периодов - если поправили что-то в обрезанном периоде - изменения должны отразиться в рабочем периоде
Решение:
1). создаем документ в конфиге, который при проведении будет писать за собой проводки и движения по регистрам (если требуется - по заданному фильтру), рассчитанные на "сам себя": т.е. после проведения такого дока (проводится на дату обрезки) имеем в базе на дату этого дока "удвоенные" остатки по бух. счетам и регистрам остатков.
2). берем копию исходной базы, оставляя в ней все справочники (без DH, DT, RA, RG, 1Cxx). Так же остаются файлы УРБД, кроме 1CUPDTS (совсем забыл - фишка метода - УРБД! Если база нераспределенная - придется распределить))).
3). в "старой" базе проводим наш чудо-документ (у меня он называется "Архив"). Делаем выгрузку в периф. базу из "старой" таким образом, чтобы выгрузился ТОЛЬКО НАШ "АРХИВ" (просто убиваем перед проведением "Архива" 1SUPDTS.DBF и CDX)
4). путем несложных манипуляций с файлом обмена УРБД превращаем его из "исходящего" во "входящий" для центра (меняем заголовок, счетчики, "Acknowledgements". Структура файла обмена здесь: , менять надо основное содержимое файла DAT во "входящем" файле для новой базы, который изначально берем из "входящего" файла любой периферийки из старой базы
5). Памятуя о том, что копия нашей "новой" базы - это "клон" "старой", грузим в "новую" базу сей подкорректированный уже "входящий" файл обмена. Вуаля - в итоге в новой базе имеем документ "Архив", со всеми проводками и движениями регистров, которые формируют остатки на дату "Х". Один минус - ссылки в проводках и движениях регистров на документы обрезаемого периода выглядят как <Объект не найден/ ID> (со ссылками на справочники, константы и перечисления все в порядке - в "новую" базу в п. 2) мы не взяли только документы и движения по ним)- нас сие не устраивает, поэтому см. пункт 6).
6). для документа "Архив" пишем обработку (она у меня - в самом документе на кнопке его формы висит), которая, перебрав все движения дока "Архив"(проводки и регистры), "проинициализирует" все ссылки (документы и, если надо, справочники) из движений (тупо "Записать()"). Эту операцию делаем ОПЯТЬ ЖЕ ПРЕДВАРИТЕЛЬНО УДАЛИВ 1SUPDTS - чтобы в выгрузке у нас оказалось ТОЛЬКО ТО, ЧТО НАМ НУЖНО!
7). смотрим и повторяем пунк 4). и 5). - с итоге имеем в "новой" базе "восстановленные" документы, на которые ссылается наш "Архив". Идея проста - при обмене УРБД, если базе подсовывают док (справочник), который в ней отсутствует (был удален, даже совсем)- 1С его ВОССТАНАВЛИВАЕТ. Минус - "восстановленные" доки будут проведенными - в "старой"-то базе они проведены! а в "новой" базе они нужны помеченные на удаление - просто как ссылки "остатков". Но теперь пометить эти доки на удаление занимает не 3-4-5... суток (я так и не дождался окончания "эксперимента"), как на "полной" базе, а от 2 минут до 1 часа (в зависимости от размеров аналитики остатков). Другое решение - при выполнении пункта 4). эти доки перед загрузкой "пометить" в "утробе", чтобы они с обменом УРБД "приехали" уже помеченными - это еще не реализовано за неимением времени - надо основательней поковырять структуру DAT-файла обмена.
8). документы за текущий период так же переносим в "новую" базу через обмен УРБД, проинициализировав (Записать()) документы за нужный период. Перепроведение доков текущего периода - не обязательно. Если в точке "обрезки" с остатками все впорядке - перепроводить не надо, т.к. доки в текущем периоде с Обменом приедут из старой базы СО ВСЕМИ СВОИМИ ДВИЖЕНИЯМИ, а "Архив" притащит как раз ССЫЛКИ НА ЭТИ ДВИЖЕНИЯ.
Ну вот вкратце метод - РЕАЛЬНО ОПРОБОВАННЫЙ (база "порезана" в августе 2007-го, на сегодня полет нормальный).
P.S.
про "преемственность" - если меняем что-то в "старой" базе - перепроводим "Архив" и снова грузим его через УРБД в "новую".
Здесь есть АКТУАЛЬНАЯ проблема: при одновременном создании документов и справочников в обеих базах ID объектов "двоятся" и при обмене "затираются". Точнее решение то есть - работать в старой базе не в Центре, а в периферийке, в аналоге которой в новой базе НИКТО НИЧЕГО не создает...
P.P.S.
На SQL все так же работает на ура - проверено 20.04.08- разрезал базу размером почти 20Гб с 7-мью периферийками, на все-про-все ушло 7 часов.
Еще момент: если режем центральную с периферийными - чтобы потом быстро выгрузить новые периф. базы, достаточно в таблице _1SDBSET значение "C" поля "DBSTATUS" сменить на "N",
чтобы осуществить первичную выгрузку в периферийные с ТЕМИ ЖЕ идентификаторами. Старые идентификаторы позволят подгрузить уже в новую базу обмены с перифериек, если,
например, нет возможностью заменить базы "разом" во всех подразделениях.
(3) вообще-то и здесь оно есть
зачем на proclub ссылку?
(5) Структура как раз идентична, миграция разная)))
Вобщем автор, много слов, и как-то сумбурно все. Плюс зачем упоминание про CJ7287, CJ7289 ?? (компонента "Расчет")
(10) ander_, я отдельно упомянул, что хоть таблицы CJ7287 и CJ7289 не используются, с ними периодически возникают проблемы в 1С с использованием распределенки, много о проблемах с этими таблицами можно найти в гугли, только рецепты их исправления сложнее, чем здесь мной описанный.
Ай маладец, а что будешь делать с объектами, которые не мигрируют в ЦБ ?
Т.е те, для которых миграция - "место создания" ?
Всё, алес - всё твоё "восстановление" коту под хвост
+ нигде не упоминается в статье, что нужно прибить все объекты, которых не должно быть в этой перефирийке во всех табличках.
>17) Все, пишем пользователям периферийной базы сообщение "можно работать в 1С". После того, как научились выполнять такое восстановление периферийной базы, особенно если периферийных баз несколько, можно больше не делать ежедневные бекапы.
Какой-то изысканный бред.
При нормально настроенной системе бэкапов все это не нужно.
вместо описываемого геморроя проще сделать пару скрипотов или отработок.
Актуальность поднимать распределенку только лишь ради бекапа я в данной публикации не обосновывал, хотя действительно получилось похоже, согласен. То, что обмен между идентичными базами повышает надежность опровергнуть нельзя. Кроме того, базы 1С могут работать с разной производительностью, например если в них разное количество пользователей или если есть внешние источники данных (например ком-соединение).
Можно найти объект, на котором прерывается загрузка данных обмена из периферийной в центральную базу (которую очень не хочется восстанавливать из образа).
В общем есть еще одна интересная статья на эту тему
суть в том, что таблицы 1С (напрммер таблицу регистра или таблицу журнала) можно соединять с таблицей регистрации плана обмена (_1supdts) для поиска проблемного объекта на котором прерывается обмен. Сначала смотрим журнал регистрации:
затем в поле DOCNO ищем тот документ, на котором прекратилась загрузка (последний загружннный по журналу регистрации оказался сбойным):
распроводим сбойный документ или удаляем из таблицы (_1supdts) сбойную запись и весь пакет загружается.
текст запроса восстановить загрузку данных обмена в 1с 7.7
найти и исправить ошибку отказ от обмена следующий по таблице _1supdts документ, на котором прекратилась загрузка (следующий по таблице _1supdts документ за загружнным по журналу регистрации оказался сбойным)
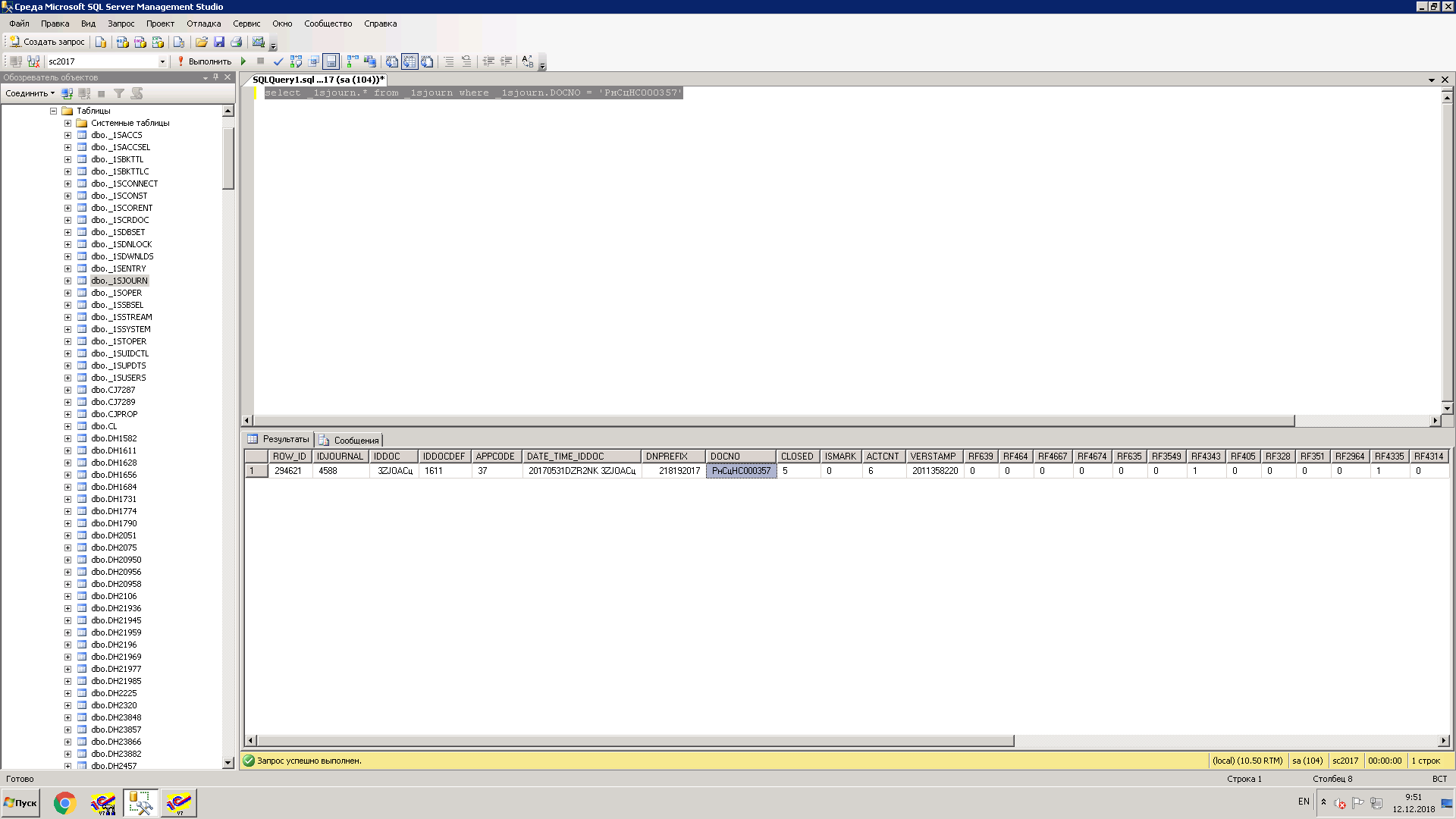
sel ect _1SJOURN.*, _1supdts.* from _1SJOURN
inner join _1supdts
on _1SJOURN.IDDOC = _1supdts.OBJID
1С:Повторяющиеся ключи (duplicate key) и потерянные проводки
Сначала определения.
Повторяющиеся ключи это значения из набора столбцов некоторой таблицы, которые встречаются в данной таблице более одного раза.
Потерянные проводки это строки таблицы _1SENTRY или _1SOPER.
Вы спросите – «Почему данные термины используются в заголовке темы вместе?». Потому, что часто (хотя и не всегда) потерянные проводки проявляются как строки с повторяющимися ключами.
В одной из моих статьей я уже писал как бороться с повторяющимися ключами. Теперь же рассмотрим ситуации, при которых возникают сообщения об ошибках в результате появления повторяющихся ключей. А таковых бывает несколько. Набираем в известном всем Books Online (BOL) сочетание «duplicate key», сортируем по колонке «Местонахождение» и перемещаемся на строки с разделом «Troubleshooting». Получаем:
Native error Код ошибки SQL Severity Уровень «серьезности» ошибки Текст ошибки
1505 14 CREATE UNIQUE INDEX terminated because a duplicate key was found for index ID %d. Most significant primary key is '%S_KEY'.
Невозможно создать уникальный индекс так как в талибце найдены повторяющиеся ключи
1508 14 CREATE INDEX terminated because a duplicate row was found. Primary key is '%S_KEY'.
Невозможно создать кластерный индекс так как в таблице найдены повторяющиеся ключи
2601 14 Cannot insert duplicate key row in object '%.*ls' with unique index '%.*ls'.
Невозможно вставить строки (обновить строки) в таблице, так как для нее создан уникальный индекс и строка с таким ключом уже есть в таблице
Первые две ошибки случаются когда предпринимается попытка создания индекса (уникального или кластерного). Третья ошибка происходит при попытке вставки записи (либо изменении поля существующей записи) и при этом нарушается уникальность уже существующего индекса.
В том же BOL в качестве способа нахождения повторяющихся ключей указан такой оператор:
Select field,…, fieldN form table group by field,…, fieldN,
здесь field,…, fieldN – набор полей таблицы, по которому создан индекс, уникальный которого нарушается. Это конечно неудобно, так как приходится пролистывать весь запрос для нахождения повторяющихся ключей. Удобнее будет использовать следующий запрос:
select field,…, fieldN, "Count"=count(*) from Table Group by field,…, fieldN having count(*)>1
После получения списка повторяющихся ключей, остается решить какие из них нужно оставить, а какие удалить.
Теперь вернемся к потерянным проводкам. Часто такие сообщения появляются для таблиц _1SENTRY и _1SOPER. Поэтому метод описанные выше также подходит для исправления данных в таблице проводок и операций. Однако кроме этого существуют специфичные для 1С методы борьбы с потерянными проводками:
Поставить признак для документа, создающего бухгалтерские проводки, «Всегда создавать операцию». Данный способ лучше всего применять для конфигураций, которые еще не «в бою», то есть только на этапе создания. При разработке конфигурации для SQL платформы всегда ставьте признак «Всегда» ;) для уменьшения вероятности возникновения потерянных проводок.
Отмена проведения + проведение документа (ов). Обычно не помогает документам, у которых не стоит признак создавать операцию всегда. И именно при проведении документа возникает данная ошибка.
Выгрузка – загрузка данных. Очень действенный метод, но очень долгий.
Тестирование + исправление конфигурации. Иногда помогает.
Что рекомендую. Сначала пробуйте отменить проведение документа и провести его заново. Иногда бывает трудно определить у какого документа потерялись проводки. В этом случае данная операция может занять столько же (если не больше) времени сколько загрузка и выгрузка. Если не поможет – тестирование + исправление конфигурации. Если не поможет – почистить проводки с помощью метода борьбы с повторяющимися ключами, провести документ(ы). Крайняя мера – загрузка – выгрузка. Изменение признака операции на «создавать всегда» приведет к пересчету бухгалтерских итогов, поэтому данная операция сравнима по времени с выгрузкой – загрузкой и тестированием с пересчетом итогов. Данную операцию я не применял, но думаю, что ее можно использовть вместо тестирования – исправления конфигурации. В любом случае если вы исправили положение, то для всех бухгалтерских документов лучше поставить признак создавать операцию всегда.
Еще в данной статье хотелось бы обратится к другой моей статье , в которой подробно был изложен способ нахождения потерянных проводок. Этот способ основывается на другом предположении, а именно на том, что потерянные проводки (операции) не принадлежат ни одному из документов. В статье был приведен скрипт, с помощью которого можно получить список потерянных проводок. На его основе легко получить другой скрипт, который сможет удалить такие проводки:
-- есть проводки по непроведенным документам
-- такое безобразие нужно "покоцать"
delete from _1sentry (nolock)
where docid in (select iddoc from _1sjourn (nolock)
where closed=0)
-- есть проводки, но нет соответствующих документов
-- такое безобразие нужно "покоцать"
delete from _1sentry (nolock)
where docid not in (select iddoc from _1sjourn (nolock))
-- есть проводки, но нет соответствующих операций
-- такое безобразие нужно "покоцать"
delete from _1sentry (nolock)
where docid not in (select docid from _1soper (nolock))
-- есть операции, но нет соответствующих документов
-- такое безобразие нужно "покоцать"
delete from _1soper (nolock)
where docid not in (select iddoc from _1sjourn (nolock))
-- проверка правильности заполнения DATE_TIME_DOCID в _1sentry
-- вместо проверки - замена на правильный DATE_TIME_DOCID
update _1sentry set DATE_TIME_DOCID=_1sjourn.DATE_TIME_idDOC
from _1sjourn (nolock)
--select _1sentry.DATE_TIME_DOCID,_1sjourn.DATE_TIME_idDOC
from _1sentry (nolock), _1sjourn (nolock)
where _1sentry.DOCID=_1sjourn.idDOC and
_1sentry.DATE_TIME_DOCID<>_1sjourn.DATE_TIME_idDOC
-- здесь можно сделать установку поля APPCODE, которое содержит
-- флаги, к какой компоненте принадлежит документ (см. статью на
-- hare.ru в разделе Коллективный разум про структуру базы)
-- поле устанавливается для определенного вида документа IDDOCDEF
-- то есть известно какой документ, по какой компоненте делает
-- движения
-- проверка правильности заполнения APPCODE в _1Sjourn
--Update _1Sjourn set appcode=appcode+32
--where appcode<32 and IDDOCDEF<>1356 and
-- iddoc in (select docid from _1sentry (nolock))
-- 32 – заменить на нужный APPCODE
-- 1356 –заменить на нужный IDDOCDEF
-- проверка базы - можно раскомментировать
--dbcc checkdb
-- переиндексация базы данных - можно раскомментировать
--exec _1sp_dbreindex
Запускать этот скрипт лучше всего на копии базы – мало ли что. Важное замечание – если с помощью скрипта удаляются проводки по операции, то восстановить их потом будет очень трудно, в то время как удаление проводок по документам не так страшно (их всегда можно перепровести).
Вот и все. Пишите мне, если у вас есть свои методы борьбы с описанными ситуациями – пополним наш арсенал вашим оружием!
Удачной борьбы с потерянными проводками и повторяющимся ключам – глюками 1С!
Пришлось бороться с сообщением "Изменения конфигурации не загружались в ИБ из которой пришел файл переноса"
1) Делаем выгрузку из ПБ;
2) Изменяем конфу в ЦБ и пытаемся загрузить выгрузку -> получаем: “Изменения конфигурации не загружались в ИБ из которой пришел файл переноса”;
3) Делаем выгрузку из ЦБ. Обязательно загружаем этот архив на ПБ, иначе часть документов из ЦБ не выгрузится в ПБ;
4) Просмотрщиком открываем файл 1Cv77Dld.id (выгрузки ЦБ) и наблюдаем строчку похожую на:
{“Download ID”,B32CA7C5-4FC6-431D-ABF8-2A5E6F7658F9,“KL”,3BB40AD2-5DDA-4E39-83BB-ADB5C65A081F,“ЦБ”,8BAA3284-2B8C-450E-868F-781896A54BC4,“9|KL”}
(ага! запоминаем цифру 9);
5) Распаковываем файл 1Cv77Chs.dat, прибывший из ПБ;
6) Ищем строчку похожую на {“8|ЦБ”}} (за ключевым словом Acknowledgements, у меня 4-я сверху);
7) Меняем 8 на 9 и запаковываем обратно;
8) Теперь в ЦБ все замечательно загружается!
Подводя итоги:
1) Номер выгрузки из ЦБ в файле 1Cv77Dld.id всегда должен соответствовать номеру выгрузки из ПБ в файле 1Cv77Chs.dat.
2) ВНИМАНИЕ!!! Такой фокус не рекомендуется проделывать при структурных изменениях конфигурации!
Ссылка на источник:
20) можно открыть в SQL таблицу _1сupdates и удалить строку с ид базы приемника и всеми нулями.
Проверено, действительно работает, данные загружаются.
SEL ECT [DBSIGN]
,[TYPEID]
,[OBJID]
,[DELETED]
,[DWNLDID]
FR OM [sc2017].[dbo].[_1SUPDTS] where _1SUPDTS.DBSIGN = 'Сб ' and _1SUPDTS.typeid = 0
GO
delete fr om _1SUPDTS wh ere _1SUPDTS.DBSIGN = 'Сб ' and _1SUPDTS.typeid = 0
Решение задачи восстановления документа ранее введенного и отсутствующего в базе.
В Центральной базе **** в адрес контрагента **** была создана накладная № РнСцНС000357 от 19.07.2018 и счет-фактура № СфСцНС000815 от 19.07.2018 в сумме 32 300,00 руб. В настоящее время этих документов в базе нет. Необходимо выяснить причину, почему эти документы исчезли из базы, выявить еще пропавшие по этой же причине документы, а также восстановить все исчезнувшие документы в базе строго с номерами, с которыми они были созданы, и предоставить их список.
Поиск отсутствующих документов выполняем следующей обработкой:
//*******************************************
Процедура Сформировать()
Префикс = "РнСцНС000";
ЧастьНомера = 0;
СчетчикЦикла = 0;
Док = СоздатьОбъект("Документ");
Для СчетчикЦикла = 1 По 999 Цикл
НомерСтр = СокрЛП(СчетчикЦикла);
Если СтрДлина(НомерСтр)=1 Тогда
НомерСтр="00"+НомерСтр;
ИначеЕсли СтрДлина(НомерСтр)=2 Тогда
НомерСтр="0"+НомерСтр;
КонецЕсли;
НомерДок = Префикс+НомерСтр;
РезПоиска = Док.НайтиПоНомеру(НомерДок,ТекущаяДата(),"Реализация");
Если РезПоиска>0 Тогда
Сообщить(Док);
Иначе
Сообщить("Не найден "+НомерДок);
КонецЕсли;
КонецЦикла;
КонецПроцедуры
Показать
Оказывается, пропал документ всего один.
Странно, что при поиске в журнале регистрации по представлению найден другой документ "РнСкНС060885" введенный исторически ранее чем проблемный, привязанный в журнале регистрацию по uid к этому представлению "РнСцНС000357".
В базе данных 1C 7.7, в журнале _1sjourn найден по номеру документ который не отображается в общем журнале документов 1С 7.7
требуется восстановить документ "РнСцНС000357".










{kind=link}