ElasticSearch разрабатывается крайне успешным стартапом в Калифорнии с 2012 года - https://www.elastic.co/.
Позволяет загрузить в единое хранилище данных разнородную информацию в JSON-формате, а затем производить выборки детальной и агрегированной информации.
Это не реляционная база данных. Взаимосвязей между разнородными объектами нет, поэтому сфера применений для учетных задач ограничена, но многие технологические задачи можно решать весьма эффективно.
Основные преимущества для пользователей 1С при хранении истории изменений объектов в ElasticSearch:
1) Не требуется сложного конфигурирования и установки ElasticSearch. Только скачать и распаковать архив, а затем запустить bat-файл (работает поверх JAVA).
2) Вся информация хранится во внешнем, по отношению к информационным базам 1С, хранилище данных. Основная база данных не перегружается "балластом".
3) ElasticSearch индексирует ВСЮ загружаемую информацию. Практически любая небольшая выборка данных с любыми условиями будет выполняться за миллисекунды.
4) При изменении структуры метаданных в 1С не требуется проводить реструктуризацию в ElasticSearch. Удаленные поля будут доступны в предыдущей информации, новые - в новой.
Особенности, которые важно учитывать:
Например:
1) все поступающие строковые поля ElasticSearch автоматически разбивает на слова и индексирует отдельно. т.е. теоретически можно искать информацию по всему массиву разнородных объектов просто указав ключевое слово. На практике это выливается в некоторые проблемы, например, с GUID. Переданные для поиска GUID система разбивает на части по символу "-" и выдает совсем нерелевантный результат. Чтобы этого не происходило нужно отключить "анализ" поля перед записью первых объектов отправив команду на типизацию таких полей для данного вида объектов.
В данном примере мне этого делать не хотелось, поэтому для ключевых полей, по которым происходит выборка версий, из GUID'а удалены тире, что сделало его монолитным "словом". Это решает задачу выборки данных для отчета по версиям. Если нужны иные варианты выборок, то нужно предусмотреть эту особенность.
2) Если объект сериализовать в XML, то платформа в атрибутах указывает тип значения для каждого ссылочного реквизита, в итоге обратная десериализация проблем не вызывает. Аналогичный механизм для JSON появится только в платформе 8.3.7 - http://v8.1c.ru/o7/201501json/index.htm.
В итоге для однозначной идентификации значения в реквизитах объектов мне показалось удачным использовать функцию ЗначениеВСтрокуВнутр.
3) ElasticSearch не поддерживает версии объектов. Поэтому каждую версию нужно хранить как уникальный объект, а логически наборы версий объединять по дополнительному полю.
Отмечу, что выложенный пример конфигурации не является полноценным решением, а лишь демонстрирует способ применения механизма, хотя и вполне применим для продуктивной системы.
Разработано и протестировано на 8.2 и 8.3.
Для сериализации\десериализации в JSON используется разработка Александра Переверзева //infostart.ru/public/119601/
Принципиальная схема работы:
1) В подписке на событие "ПриЗаписи" выполняется сериализация объекта в JSON.
2) Добавляется служебная информация типа даты изменения и автора версии.
3) Данные синхронно записываются в ElasticSearch до окончания транзакции. Т.е. при отмене транзакции версия останется. Это можно решить, переделав механизм на асинхронный: при изменении объекта фиксировать сам факт, а в отдельном фоновом задании выполнять сериализацию в JSON и отправку данных. У обоих вариантов свои плюсы и минусы.
4) В отчете по версиям система выбирает 10 последних версий объекта и отображает их реквизиты. Каждый результат поиска также возвращает общее количество найденных объектов, поэтому всегда можно получить программно все объекты.
Для запуска механизма на своей базе необходимо:
1) Установить на целевой машине JAVA и прописать переменную JAVA_HOME.
2) Скачать и запустить ElasticSearch.
3) Объединить целевую конфигурацию с файлом Elastic.cf (2 общих модуля, 2 константы, 2 подписки на события, 2 обработки).
4) скорректировать подписки на события - указать только те объекты, которые необходимо версионировать. Можно оставить как есть (все объекты), но в крупных базах с интенсивной работой, скорее всего, будут проблемы с быстродействием.
5) В режиме Предприятия заполнить константы.
АдресИнстанса - имя компьютера и порт с ElasticSearch (для локальной машины - localhost:9200).
ПрефиксБазы- произвольный идентификатор текущей ИБ латинскими строчными буквами\цифрами (чтобы данные нескольких баз не перемешивались), например, "buh1".
Попробовать записать любой версионируемый объект и удостовериться через обработку "ElasticSearch_ПросмотрВерсий", что данные записались в ElasticSearch и выдаются обратно.
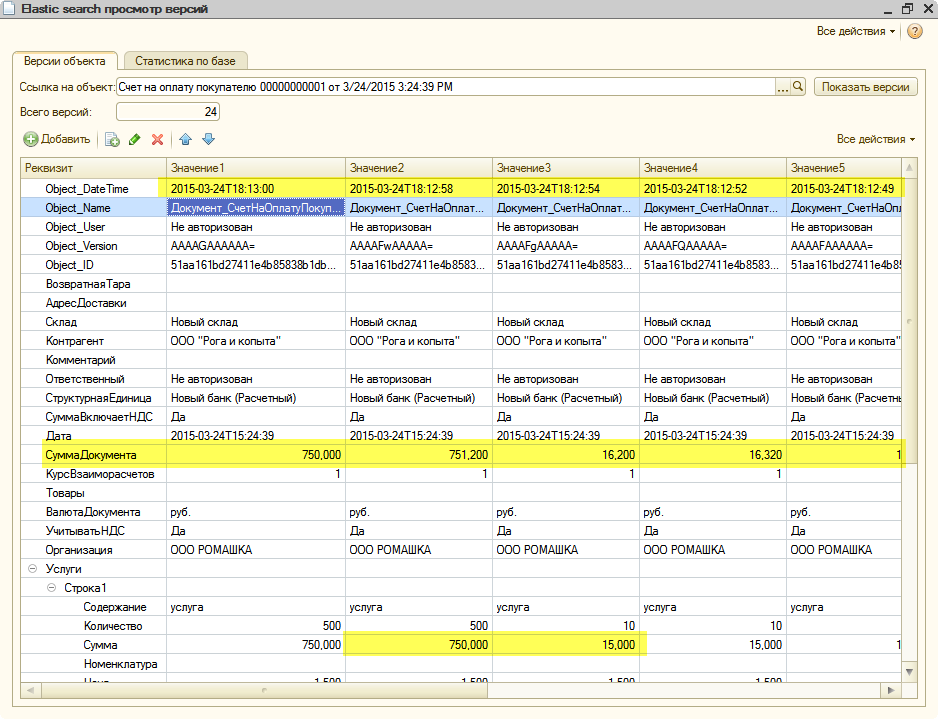
Список версий по документу:
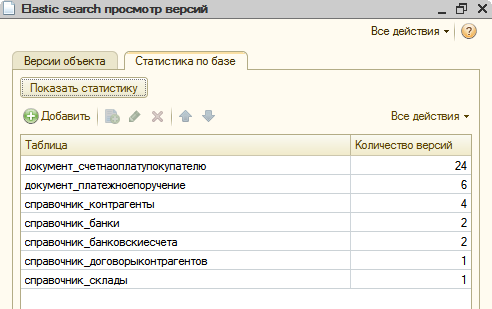
Статистика по версиям в базе ElasticSearch:
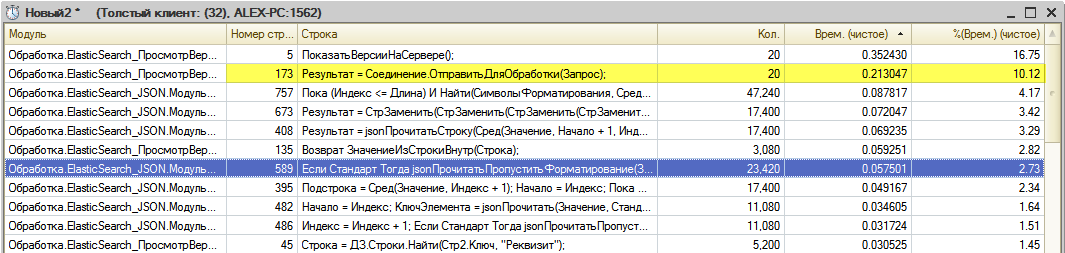
По поводу быстродействия - я не тестировал именно журнал изменений объектов на больших данных. Но анализ объемного технологического журнала показал, что скорость выборки 10-20 событий из индекса с парой тысяч записей и с 20'000'000 записей примерно одинакова.
Судя по замеру в данном примере - на выполнение 20 запросов, каждый из которых возвращает 23Кб JSON, потребовалось 0,2 секунды.
P.S. На подходе два аналогичных механизма для технологического журнала и журнала регистрации.
Планирую сделать на базе своих существующих разработок:
Периодическая загрузка событий из журналов регистрации в базу MS SQL Server (с исходниками)
Загрузка файлов технологического журнала в базу MS SQL (с исходниками)
