






{kind=link}
С нейронными сетями я познакомился довольно давно. Отношение к ним, как к средству решения прикладных задач, у меня довольно противоречивое. С одной стороны, ни одной задачи, для которых я использовал сети, решить с удовлетворяющим меня результатом я так и не смог (но нужно оговориться, что и задачи были сверхсложные), а с другой стороны, удалось в достаточной степени оценить мощь аналитического потенциала нейронных сетей и их способность давать оценки и прогнозы на самых разнообразных множествах.
Так как интерес мой к сетям периодически возникал на протяжении последних лет, то идея написать обработку для построения и обучения нейронной сети витала, что называется, в воздухе. Однако, реализовать идею удалось только в последние несколько (честно, даже не помню сколько) месяцев. Борьба за себя - это прежде всего борьба с собой, а точнее, с собственной ленью и невежеством. И этот раунд остался за мной:) Так как делал прежде всего для себя - выкладываю то, что получилось, совершенно даром.
Что из себя представляет данная разработка? Перечислю основные возможности и функционал. При этом имеем в виду и помним, что реализована она только на управляемых формах.
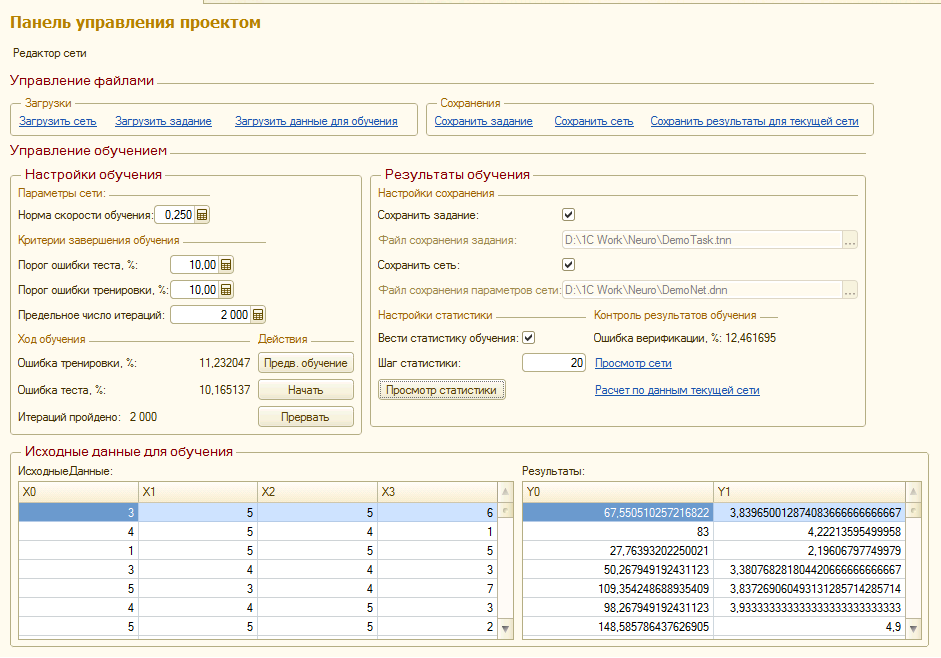
1. Панель управления проектом. В принятых мной терминах под заданием понимается совокупность собственно нейронной сети, исходных данных для обучения, настроек параметров обучения и сохранения результатов. Панель управления проектом позволяет редактировать компоненты задания (кроме нейронной сети), управлять процессом обучения и контролировать результаты обучения сети. Также присутствуют возможности сохранения и загрузки заданий и готовых сетей. Отдельно отмечу наличие опции сохранения результатов. Если в проекте имеется загруженная / созданная сеть и загружен массив исходных данных то по параметрам сети происходит расчет и выгрузка результатов во внешний файл (таблицу значений или книгу Excel). Аналогично можно узнать результаты возвращаемые сетью для любого набора интерактивно введенных аргументов.
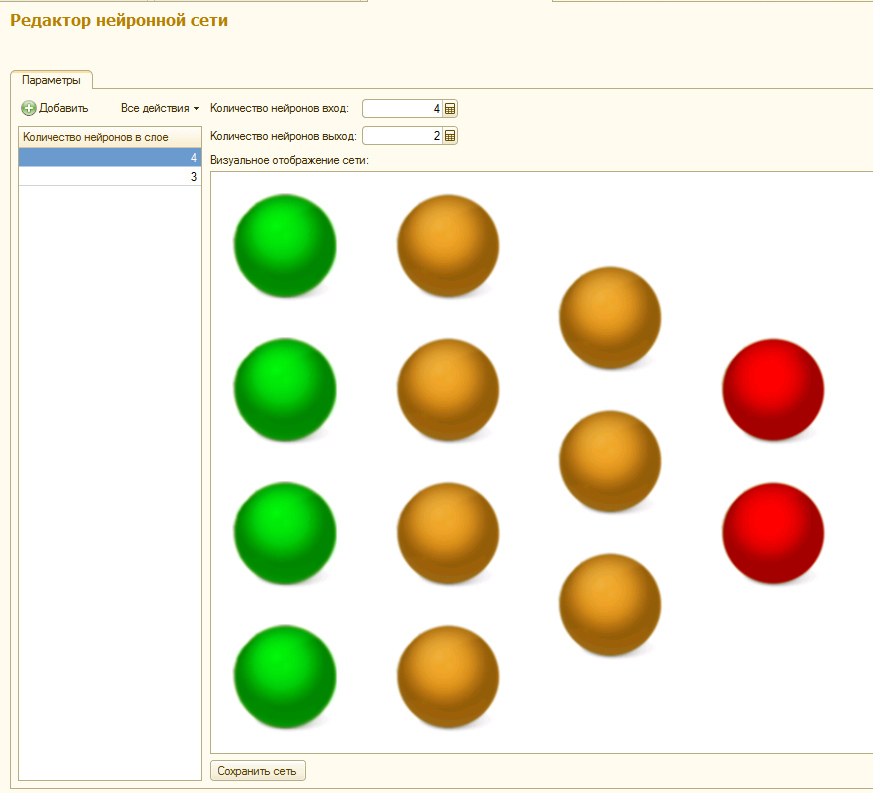
2. Редактор нейронной сети (многослойного персептона). Дает возможность создавать и редактировать нейронную сеть. Визуально сеть отображается в виде структуры из разноцветных шаров. Зеленые шары - входные ядра, красные - выходные, а желтые - ядра внутренних слоев. Имеется возможность устанавливать количество слоев и ядер в них. Для загруженных заданий и сетей, а также в случае, когда для обучения проекта уже были загружены данные, количество входных и выходных ядер принимается равным количеству существующих аргументов и результатов. При нажатии кнопки "Сохранить сеть" происходит сохранение сети в параметрах обработки и инициализация начальных весов ребер случайным образом. То есть даже если мы не изменяли структуру сети ее можно очистить от результатов предыдущего обучения заново сохранив в редакторе.
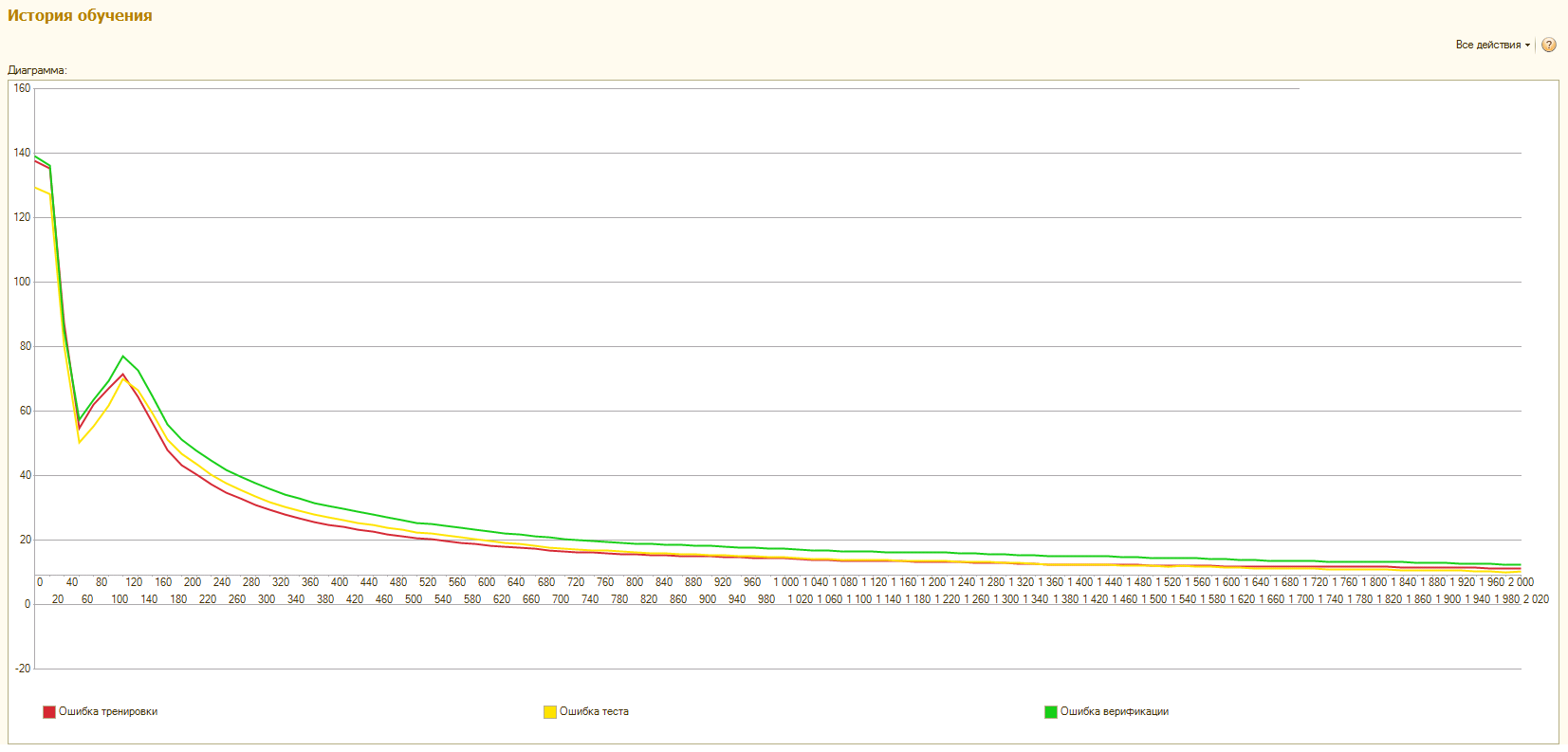
3. Подсистема анализа хода обучения. Подсистема очень проста и представляет собой график, демонстрирующий ход обучения сети в данном проекте. Шаг сбора статистики и общее число шагов обучения настраиваются в "Панели управления проектом". Статистику нельзя видеть в real time по ходу обучения. Она является такой же составной частью проекта, как сеть и массивы данных для обучения и будет обновлена и записана в проект по завершению обучения вместе с новыми параметрами сети. Соответственно если в загруженном проекте при предыдущем обучении была включена опция ведения статистики то просмотр графиков ошибок аппроксимации доступен сразу после загрузки задания (проекта).
4. Модуль обработки. Модуль обработки я также выделяю в отдельную подсистему из-за наличия экспортных функций и процедур, позволяющих проводить обучение сетей и получать результаты расчетов из сети, используя внешние вызовы. Собственно для меня эти функции и являются самыми важными в разработке. Файл со спецификацией проекта прилагается и любой проект, созданный любым способом в соответствии с данной спецификацией может быть обучен, и может быть получен нужный результат из созданной в соответствии со спецификацией сети. Но так как на практике создание, редактирование и обучение сетей довольно трудоемкий и творческий процесс, то визуальные редакторы и панель управления - вполне логичный шаг для упрощения и повышения качества работы. Но еще раз повторюсь - в теории можно было бы обойтись без них, так как модуль обработки представляет собой полностью достаточный функционал для работы с готовыми заданиями и сетями. Остальные подсистемы это лишь мой вариант дизайна кухни для их приготовления.
Теперь немного расскажу о параметрах сети и о процессе обучения.
Среди множества активационных функций нейронов для данного проекта я выбрал логистический сигмоид Ферми. Самая популярная функция в нейронных сетях и (если понимаете в чем суть обучения) очень просто дифференцируема.
Алгоритм обучения - обратное распространение ошибки. За подробностями, если интересно, к Google.
Норма скорости обучения - адаптивная. На страте принимается значение, указанное в параметрах, но по ходу обучения скорость обучения может меняться. Принцип модификации скорости состоит в том, что в случае когда между шагами обучения направление градиента для ребра сети не меняется скорость обучения умножается на коэффициент К>1, а в случае изменения знака градиента множитель К становится <1. Таким образом, норма обучения хотя и остается важнейшим параметром обучения, но ее неправильный выбор может быть в значительной степени скорректирован модификаторами.
Обучающая выборка. Все переданные в качестве аргументов и результатов данные рандомно делятся перед началом обучения на 3 части (Тренировочная, Тестовая и Верификационная) в соотношении 7:2:1. Причем этот рандом каждый раз разный и данные делятся перед каждым циклом обучения. В итоге Вы видите картину, что при запуске второго (третьего и т.д.) цикла обучения одного и того же проекта ошибки аппроксимации могут на первых шагах резко просесть или подскочить. Это не от того что была взята не та сеть - просто новый рандом выборок и новые значения ошибок.
Что же это за выборки? Тренировочная - понятно. Тестовая - не участвует прямо в обучении, но ее ошибка видна в процессе. Судя по значению тренировочной ошибки, а точнее видя ее динамику в сравнении с ошибкой тренировки можно судить о том не переучена ли сеть (ошибки расходятся) и вообще насколько адекватно данным построена модель сети.
Верификационная выборка - не видна пользователю до самого конца обучения. Так как в процессе обучения мы можем следить за тестовой выборкой, то она тоже косвенно является объектом обучения. В данном случае верификация - финальный и самый непредвзятый судья качества получившейся сети.
Классический пример переучившейся сети это когда ошибки тренировки и теста сначала снижаются, а потом расходятся и ошибка теста бесконечно возрастает. Сеть, возможно, сумела "запомнить" всю тренировочную выборку и теперь подстраивается не под обобщающие характеристики всей выборки, а "шлифует" только тренировочные данные. Как правило это случается когда исходная выборка слишком мала или слишком однородна и / или количество внутренних слоев и нейронов при этом слишком велико.
Теперь о способах запуска процесса обучения из формы обработки. Их всего 3:
1. Обычный запуск процесса. Стартуем обучение в текущем сеансе и ждем окончания. Так как до окончания вызова сервера ничего на клиент вернуть нельзя - ждем и надеемся, что все будет хорошо.
2. Запуск через фоновое задание из внешней обработки. Думаю, что здесь все более или менее понятно. Естественно, что обработка должна быть зарегистрирована в справочнике дополнительных отчетов и обработок и в конфигурации должна присутствовать БСП версии не ниже 1.2.1.4. В этом случае у меня все прекрасно работает.
3. Запуск через фоновое задание обработки конфигурации. Это если Вам так понравится обработка, что Вы начнете ее регулярно использовать и встроите в конфигурацию. Здесь, конечно, можно было бы рекомендовать Вам сделать запускающий фоновое задание допил, но можно попробовать и через БСП. Вот только версия должна быть даже не знаю уже какая, но довольно свежая.
Варианты с запуском в фоновом задании наиболее удобны и информативны, так как на форме все-таки что-то можно еще делать, да и информация по ходу обучения периодически обновляется за счет получения и обработки сообщений от фонового задания.
Пару слов скажу еще об опции предварительного обучения. Не буду давать ссылку на умную статью, где доказывается, что предварительный подбор весов нейронных синапсов дает существенный прирост в качестве и сокращение времени обучения сети. Скажу лишь что поверил уважаемым кандидатам наук на слово. Написал блок предварительного подбора и оценки начальных весов и... существенного прогресса не заметил. Здесь уж или лыжи не едут или со мной не все так как нужно, но опцию сохранил. Можете пользоваться перед началом обучения новой сети, а можете не пользоваться.
Что в приложенном архиве? Описание состава проекта сети (спецификация) для самостоятельной разработки проектов (MSWord), демо-файлы проекта и сети, а также набор из 2-х файлов демо данных. Данные - это таблицы значений с наборами аргументов и результатов.
Обработка выложена отдельным файлом для удобства обновления и замены новыми версиями. Самая важная часть дополнительных материалов – спецификация проекта сети содержится в справке обработки, так что в принципе можно скачивать только саму обработку для экономии $m. Функционал и документацию при этом Вы получите в полном объеме.
На этом, думаю, стоит заканчивать. Текста и так получилось многовато. Естественно, что по ходу использования обработки на конкретных данных и реальных примерах, у Вас будет возникать множество вопросов и замечаний. Основные ответы и советы приведены выше – то есть сначала внимательно читаем описание. Есть также справка в главной форме обработки. Ее тоже можно почитать. Ну а для всего остального, что не описано или не понятно – комменты.