



{kind=link}
В 1С8 существует всем известный замечательный механизм регламентных заданий, который позволяет автоматизировать выполнение в фоне различных обработок, построение отчётов и прочих подобных операций. Регламентные задания, в ходе своего выполнения, используют механизм фоновых заданий. Регламентное задание, стартуя например, по расписанию, вызывает выполнение фонового задания, которое в свою очередь и реализует соответствующий код обработчика.
Изучая возможности работы с регламентными заданиями, я столкнулся с тем, что иногда, для балансировки нагрузки на сервере, необходимо ограничивать число одновременно выполняющихся заданий. Штатный механизм предоставляет, конечно, возможность управления стартом заданий по расписанию и т.п., но вот именно для управления балансировкой необходимо выдумывать велосипед. Собственно о таком велосипеде я и пишу. Сразу оговорюсь, что представленный механизм - лишь одна из многих вариаций на тему параллельной обработки данных и уж точно никаким образом не претендует на законченное решение. Впрочем, как мне кажется, сделав некоторые очевидные доработки, описанный механизм можно использовать и в рабочих базах.
Итак, суть механизма заключается в использовании двух регламентных заданий - Диспетчера и Менеджера заданий очереди (Эта идея зацепила меня при прочтении замечательной заметки на Хабре - https://habrahabr.ru/post/255387/).
Первое из них, а именно Диспетчер, обеспечивает простую постановку в очередь заданий, которые должны выполниться, но которых нет в этой самой очереди. Второе задание, т.е. Менеджер, обеспечивает запуск заданий и соответствующее управление очередью. Здесь стоит остановиться подробнее, т.к. Менеджер обрабатывает задания очереди с учётом их приоритета и ограничений на количество одновременно выполняющихся фоновых заданий. Кроме того, он группирует задания определенного вида в своего рода "пакеты" и затем (так же с учётом приоритетов и ограничений по числу одновременно выполняющихся фоновых заданий) выполняет такие "пакеты" в рамках отдельных фоновых заданий.
Теперь по реализации.
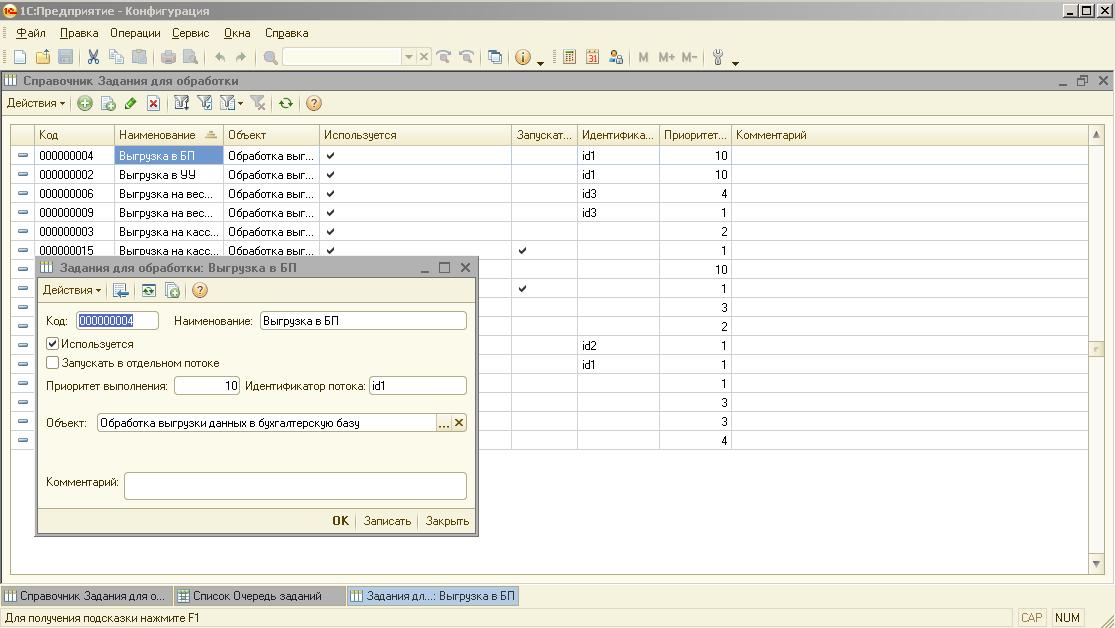
1)В программе имеется справочник "Задания для обработки", в котором собственно и хранятся объекты обработки (т.е. задания). В принципе, такими объектами могут служить различные процедуры или программы загрузки/выгрузки, регламентные задания и прочее. Однако, поскольку это лишь основа механизма, то как таковых объектов обработки не задано, сейчас это вообще просто условный реквизит "Объект" строкового типа, а единственное действие, выполняемое при передаче программного кода такому объекту - минутное ожидание, т.е. пауза в 60 секунд. Понятное дело, если есть необходимость, чтобы задание при своём выполнении выполняло более изысканный код, то нужно соответствующим образом, в т.ч. используя реквизиты экземпляра элемента справочника "Задания для обработки", написать необходимый программный код. Тем не менее, для иллюстрации работы механизма, имеющихся сущностей вполне достаточно.
Каждый элемент справочника "Задания для обработки" имеет:
*флаг "Используется" (по сути это включение/выключение задания);
*флаг "Запускать в отдельном потоке" (задания с установленным флагом будут запускаться в отдельных фоновых заданиях, а задания со сброшенным могут запускаться последовательно по несколько штук в одном фоновом задании);
*поле "Приоритет выполнения" (чем меньше число (по умолчанию - 10), тем выше приоритет выполнения данного задания);
*поле "Идентификатор потока" (задания с одинаковыми идентификаторами потока будут выполняться в дном фоновом задании, при условии, что флаг запуска в отдельном потоке у таких заданий сброшен);
*поле "Объект" (Строка, но после небольших доработок, м.б. использован как идентификатор объекта, в который будет передаваться программный код для выполнения);
*поля "Наименование" и "Комментарий" (предназначение этих полей очевидно)
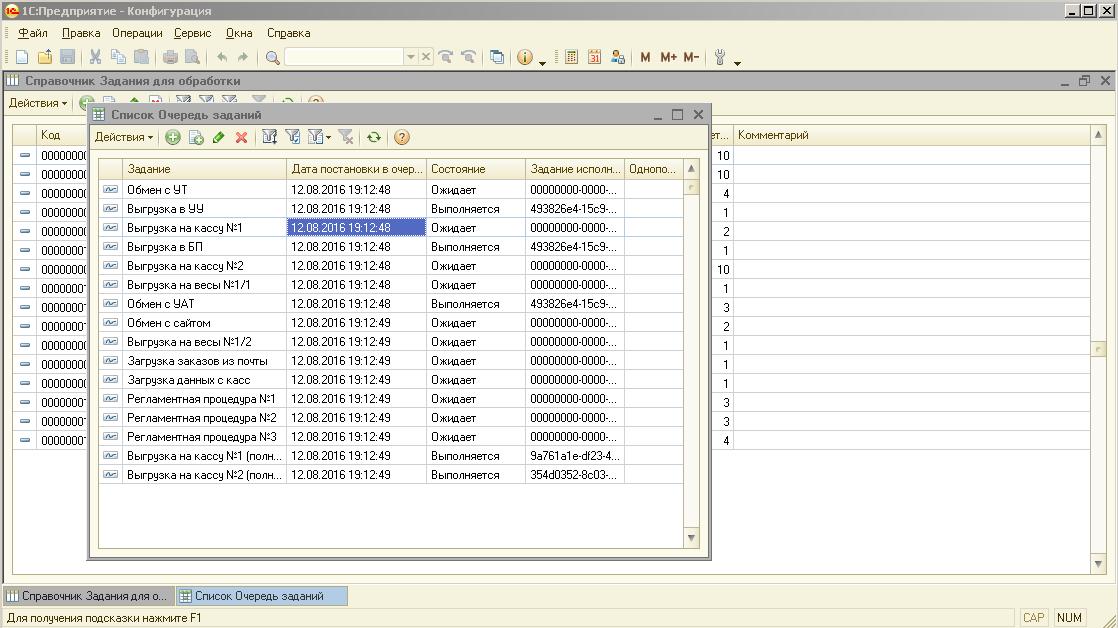
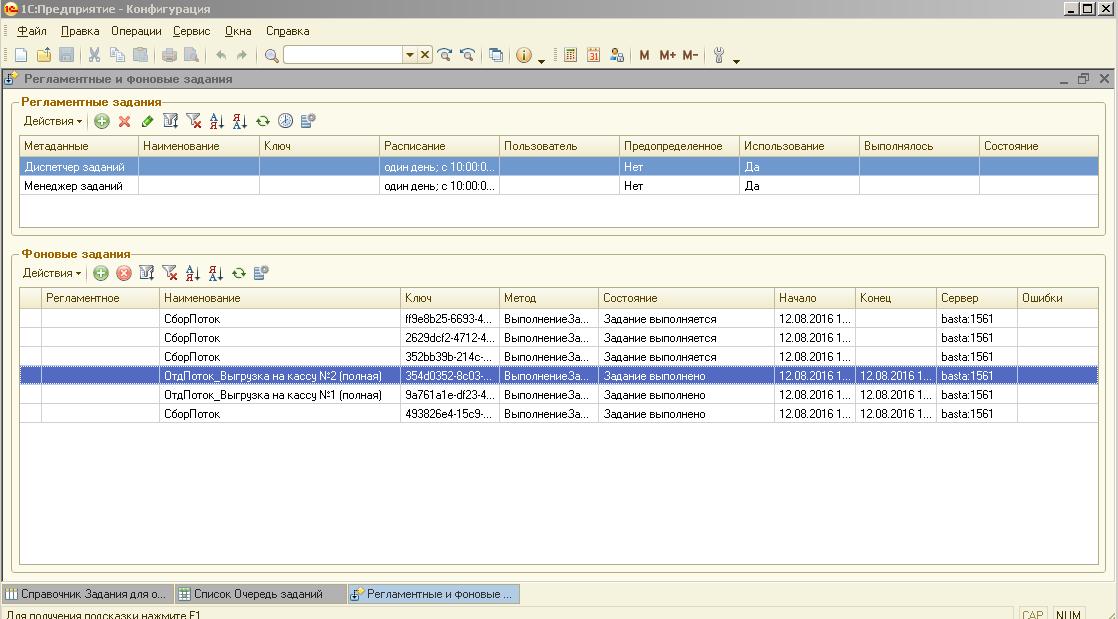
2)По расписанию, скажем каждые 5 минут, в системе запускается Диспетчер (регламентное задание "Диспетчер заданий"), который получает из справочника "Задания для обработки" все включенные задания, т.е. которые нужно выполнять, а затем, те из них, которых нет в очереди - туда и помещает. Более ничего Диспетчер не выполняет.
3)Как уже было отмечено выше, в механизме существует ещё и Менеджер (второе регламентное задание - "Менеджер заданий"), основной задачей которого является запуск заданий и очистка очереди (по окончанию выполнения заданий). Менеджер, как мне кажется, должен запускаться чаще, чем диспетчер, т.к. его работа напрямую влияет на скорость выполнения заданий очереди (у меня он запускается раз в минуту). Сразу после старта Менеджер получает параметры, определяющие количество потоков (одновременно выполняемых фоновых заданий) для выполнения разных видов заданий очереди. После этого, Менеджер удаляет из очереди отключенные задания (вдруг их кто-то выключил), а также удаляются (из очереди) выполняющиеся задания, по которым не найдено активных фоновых заданий. После корректировки очереди, Менеджер получает нераспределенные по потокам задания из очереди и распределяет их по потокам. Причем, распределив то, или иное задание, Менеджер сразу запускает его выполнение. Вначале распределяются задания, запускаемые в отдельных потоках. Делается это с учётом их приоритета и наличия вакантных ресурсов, т.е. лимита по количеству параллельно выполняющихся заданий данного вида (одно задание на один поток). Если такой лимит для старта задания отсутствует, то задание не распределяется (т.к. по сути в данный момент нет свободных ресурсов для его выполнения). Следом идёт очередь распределения заданий, которые могут быть объединены для выполнения в рамках одного фонового задания. Последовательность распределения таких заданий следующая - сначала распределяются задания с заполненными идентификаторами, а затем с пустыми. Распределение по потокам выполнения и в этом случае происходит с учётом приоритетов и наличия ресурсов. По окончании выполнения каждого из заданий, программа (точнее обработчик каждого из фоновых заданий) выполняет удаление соответствующего задания из очереди.
В общем, это основные моменты, которые дают понимание моего "велосипеда".
На последок ещё раз отмечу, что это не готовое решение, а лишь пример, или если угодно - основа для построения более сложного механизма. Так, например, поскольку в регистр очереди довольно часто осуществляется запись, то для повышения производительности можно подумать об использовании при этом управляемых блокировок и транзакций. А если ещё и "запилить" к этому что-то вроде расписания выполнения заданий (из справочника "Задания для обработки"), а также систему логирования результатов их выполнения и сбора статистики(в т.ч. по загрузке ресурсов, времени ожидания и выполнения и т.п.), то можно получить интересное решение.
В добавление к указанной статье с Хабра, считаю необходимым указать ещё парочку:
//infostart.ru/public/306865/
http:// /news/2015-12-04-threads-data/