Основные причины неоптимальной работы запросов

Итак, запросы бывают оптимальными или наоборот, тяжелыми. Бывает даже так, что один небольшой запрос приводит работоспособность системы в достаточно плачевное состояние. И вот, исходя из рассмотрения различных решений, попавшихся мне на глаза в последнее время, я и собрал наиболее часто встречающиеся причины неоптимальной работы запросов:
- Первая причина – это разработчик. Сразу скажу, что я сам являюсь разработчиком, но это – мое мнение, может быть, у вас сложилось другое.
- Еще бывают случаи, когда архитектор решения не предусмотрел подходящий регистр, позволяющий получать аналитическую информацию с большей эффективностью для системы.
- Также нередко происходят ситуации, когда директор предприятия сокращает бюджет, или распределяет его, размазывая по сроку предоставления таким образом, что собрать систему к моменту ее запуска просто не на что.
- Или иногда ответственные за проект лица принимают решение о запуске системы без предварительной опытной эксплуатации.
- И еще бывают случаи, когда администратор базы данных просто не имеет представления о том, что необходимо для стабильной работы СУБД.
Эти факторы могут прямо или косвенно повлиять на то, что запросы будут работать неоптимально. Но я буду, в основном, говорить именно про текст запроса, потому что это – самая основная и первая причина неоптимальной работы запросов.
Чем «портят» запросы программисты?
Как это выглядит? Я вам из Барнаула привез самолетик, к которому спроектировал довольно большое крыло в надежде на то, что он так лучше полетит. Но происходит примерно так: самолетик падает плашмя вниз. То же самое с запросами. Разработчик, предполагая использование в запросе каких-то навороченных решений, может воспроизвести такой текст запроса, который «не полетит», поскольку его результат становится тяжелым, как и в случае с этим самолетиком.

Итак, сконцентрируемся на тексте запросов. Что может «утяжелить» запрос? Здесь перечислены основные причины такого «утяжеления», про все это подробно написано на всем известном сервисе http://its.1c.ru/, очень доступном, открытом – вы можете принимать это во внимание.

Безусловно, самым часто встречающимся случаем является неиспользование отборов внутри виртуальных таблиц. Я думаю, что нет ни одного разработчика 1С, кто не знает этого правила, однако в реальных решениях такие ошибки все-таки встречаются довольно часто. Причем их могут совершать даже разработчики с многолетним стажем
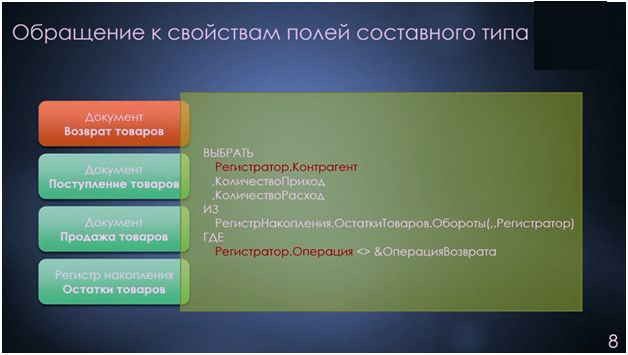
Вторая ситуация, на мой взгляд, уже является более сложной для выявления – это обращение к полям составного типа без типизации, которая бы сократила число используемых источников.
В данном примере вы видите, что без указанного здесь условия фильтрации, при обращении к регистру накопления на стороне СУБД без необходимости были бы выбраны данные документа «Возврат товаров». Такая ситуация тоже встречается достаточно часто.
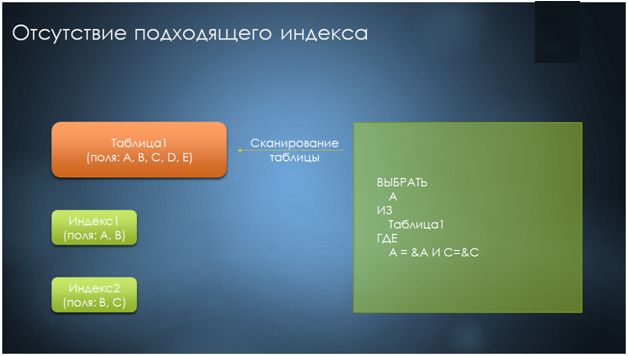
Чуть реже, но тоже в значительной мере встречаются моменты, когда нет подходящего индекса.
Почему-то иногда прикладные разработчики говорят: «подготовка подходящего покрывающего индекса – это не наша обязанность, мы же просто прикладные разработчики». Соответственно, когда нужно получить данные с отбором по полю A и C, они, не имея подходящего индекса, довольствуются тем, что происходит сканирование кластерного индекса или же таблицы.
Методика оптимизации запросов

Сама методика оптимизации запросов описана в открытых источниках (диск ИТС). Ничего нового (или почти ничего нового) я вам не скажу. Но важно научиться применять эту методику, вовремя вспомнить о ней, увидеть неоптимальный код в своем решении – это дано не каждому. Несмотря на это, сделать правильные выводы из готовых рекомендаций намного проще, чем увидеть проблему в своем коде самому.
Неожиданные результаты применения методики оптимизации запросов
Итак, методика оптимизации запросов у нас имеется, вы можете ее использовать, все замечательно. Однако ее практическое применение может оказаться с неожиданными результатами. Я о таких неожиданных результатах знал давно, поэтому специально для доклада подготовил несколько примеров.
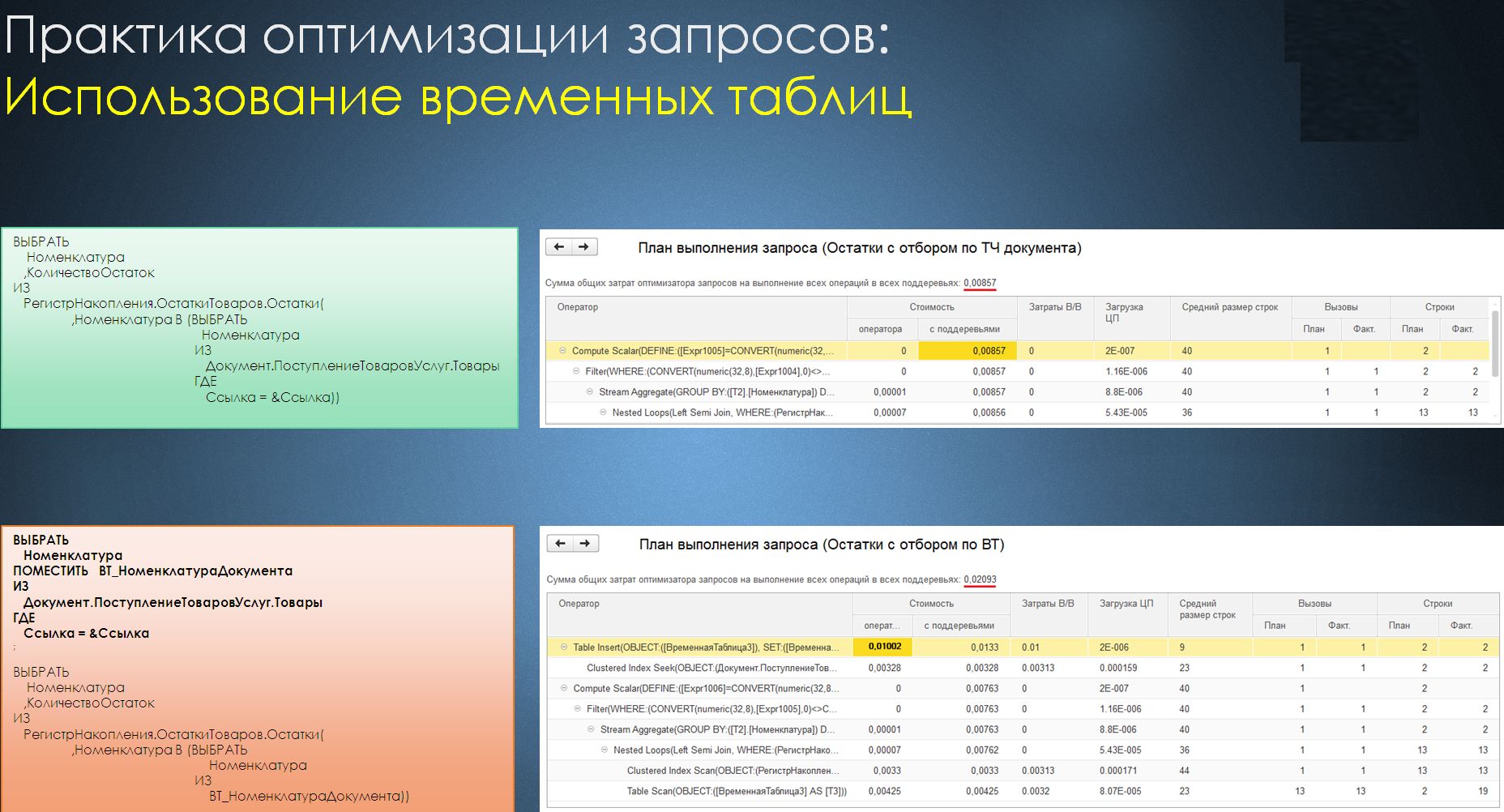
Итак, в первом примере вы видите, что идет обращение к виртуальной таблице остатков. При этом в первом случае для отбора по товарам документа используется вложенный запрос, а во втором случае – вложенный запрос с использованием временной таблицы, что, по идее, должно предоставить нам возможности для более эффективной работы с данными. Однако этого не происходит.
Справа показаны замеры скорости исполнения, сделанные с помощью всем известной обработки с диска ИТС «Консоль запросов для управляемого приложения 8.3», позволяющей видеть затраты на исполнение запроса для сервера MSSQL. Как вы видите, в данном случае использование временной таблицы не привело к более быстрому результату, поскольку затраты на ее создание оказались более существенными, чем работа с вложенным запросом. Такое очень часто встречается на практике.
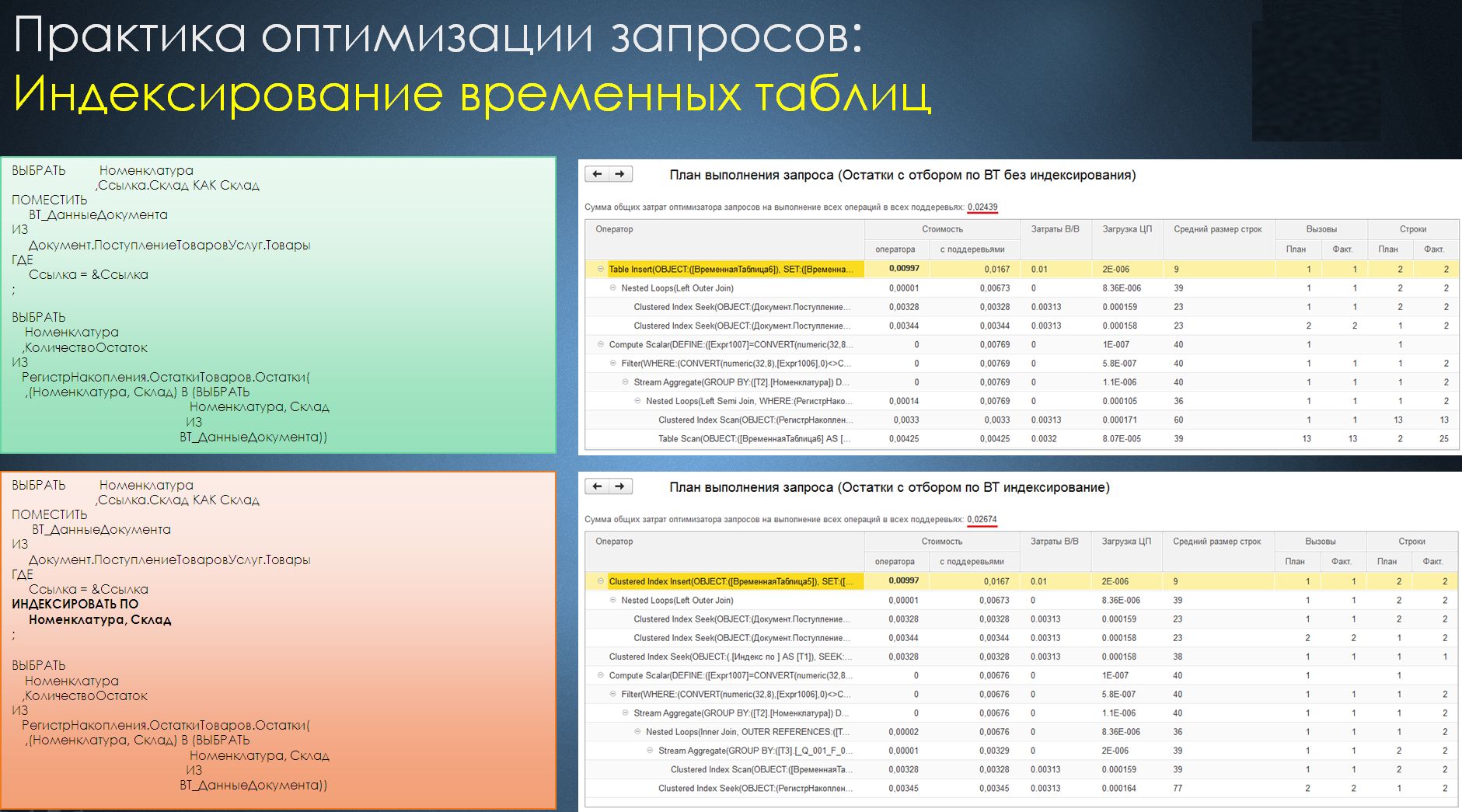
Другой случай, который также может привести к неожиданному результату, – это затраты на индексирование временных таблиц. Нередко при индексации временной таблицы, в которую помещается небольшое количество записей, мы не получаем прироста производительности, а наоборот, затрачиваем время на то, чтобы проиндексировать временную таблицу (несем накладные расходы и не получаем при этом никакого ускорения).
Получается, что результирующее быстродействие запроса во многом будет зависеть от реальных данных, для которых он будет использоваться.
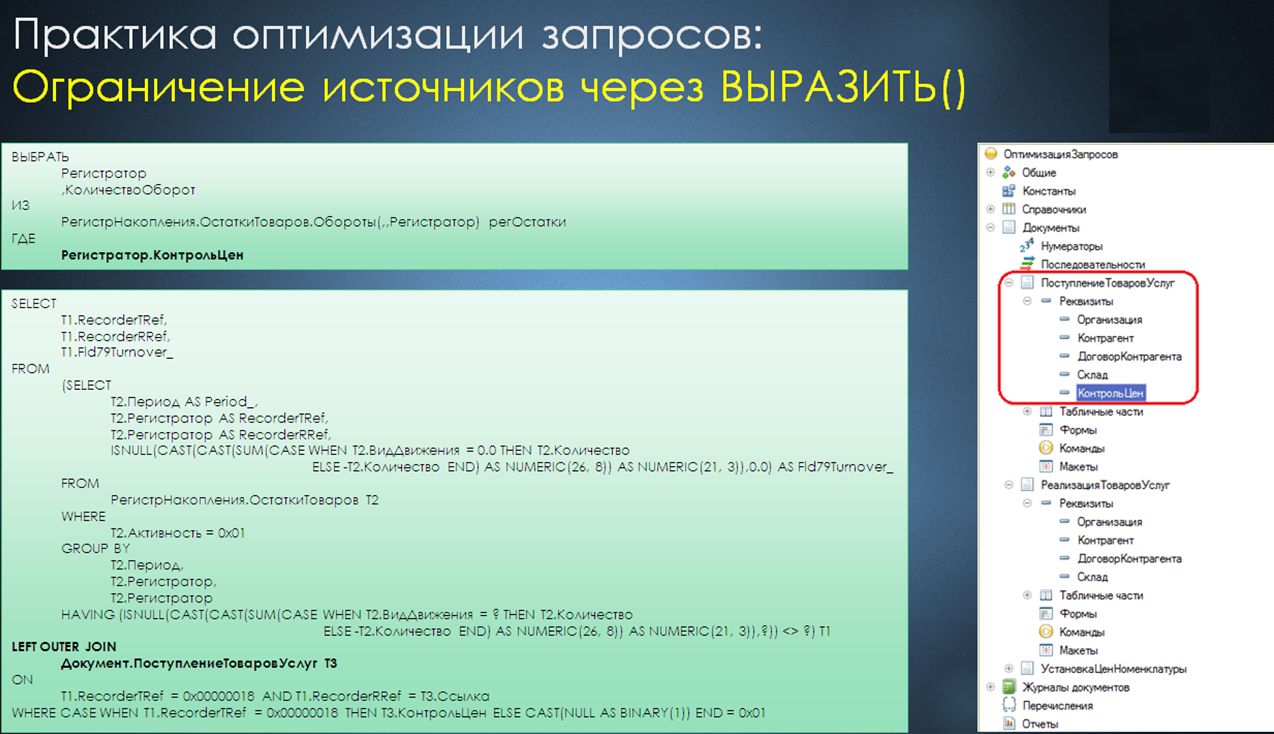
Другая ситуация: я нередко вижу, что разработчики, используя правила составления запросов, описанные на ИТС или где-то еще, искаженно воспринимают информацию в части, например, работы с вложенными свойствами полей составного типа.
Например, на слайде показан текст запроса, демонстрирующий обращение к полю составного типа «Регистратор» (а именно к его вложенному свойству «Контроль цен»). Здесь видно, что запрос, в конечном счете, не производит обращения к документу «Реализация товаров и услуг», поскольку свойства «Контроль цен» у этого вида документов нет, и, соответственно,сама платформа не генерирует никаких дополнительных левых соединений. А на практике я встречаю чрезмерные усилия разработчиков (не всех, конечно), направленные на то, чтобы исключить лишние источники данных, хотя они в этом случае и так не будут подключены. И это тоже нередко встречающаяся ситуация.
Фильтрация внутри виртуальных таблиц
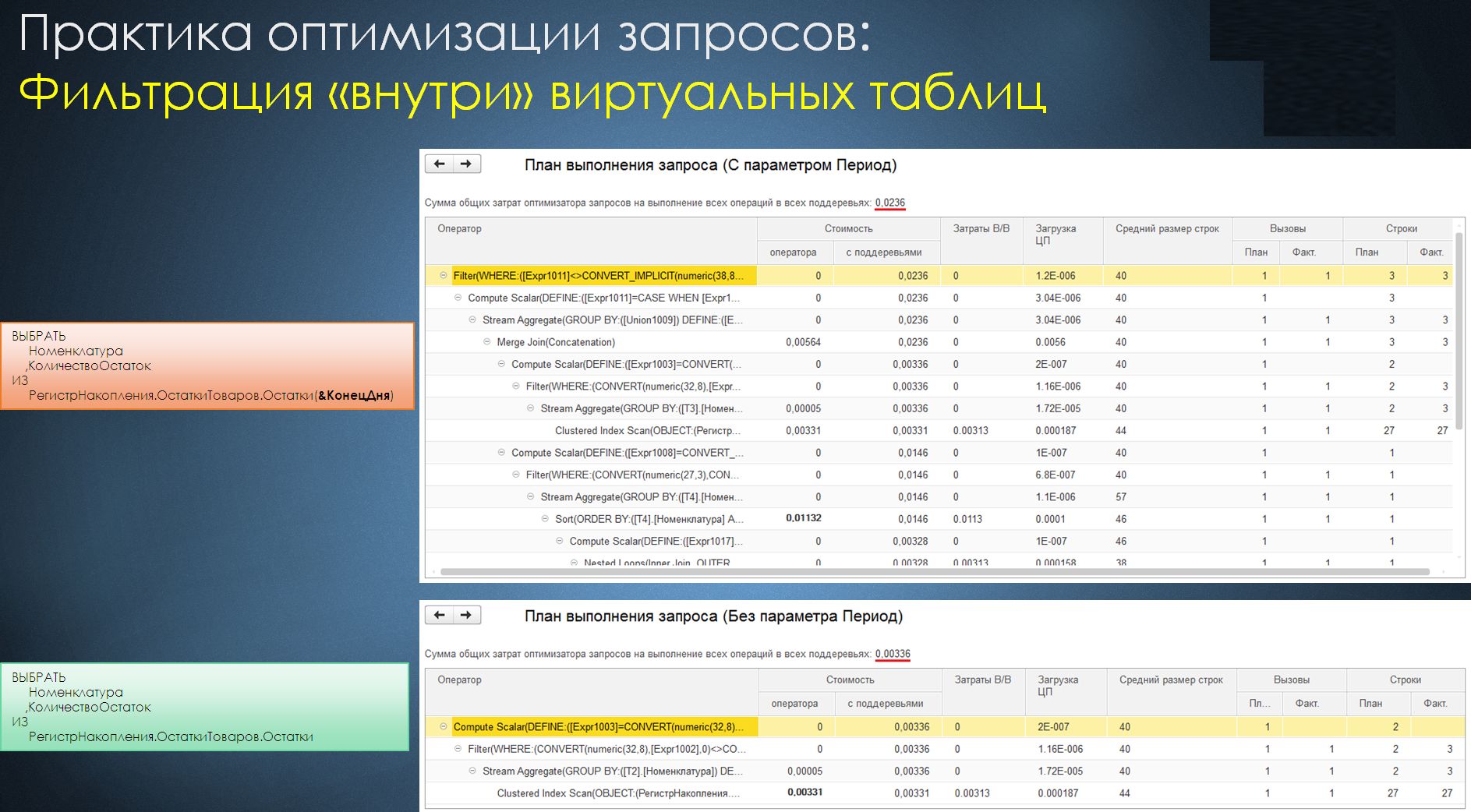
Еще одна интересная ситуация – это фильтрация внутри виртуальных таблиц.
Как вы понимаете, использование параметра «Отбор по периоду» при получении актуальных данных не требуется. И если произвести получение остатков на актуальную отметку времени без использования этого параметра, мы получим данные с использованием одного источника – физической таблицы итогов. А при указании в этом значении любого подходящего периода (например, будущего времени сегодняшнего дня, который тоже будет указывать на необходимость получения актуальных остатков), у нас уже произойдет получение данных из двух источников – таблицы итогов и таблицы движений. И в результате мы получим значительное снижение производительности запроса. Такая ситуация тоже очень часто встречается.
Использование критериев отбора для получения некластеризованного индекса
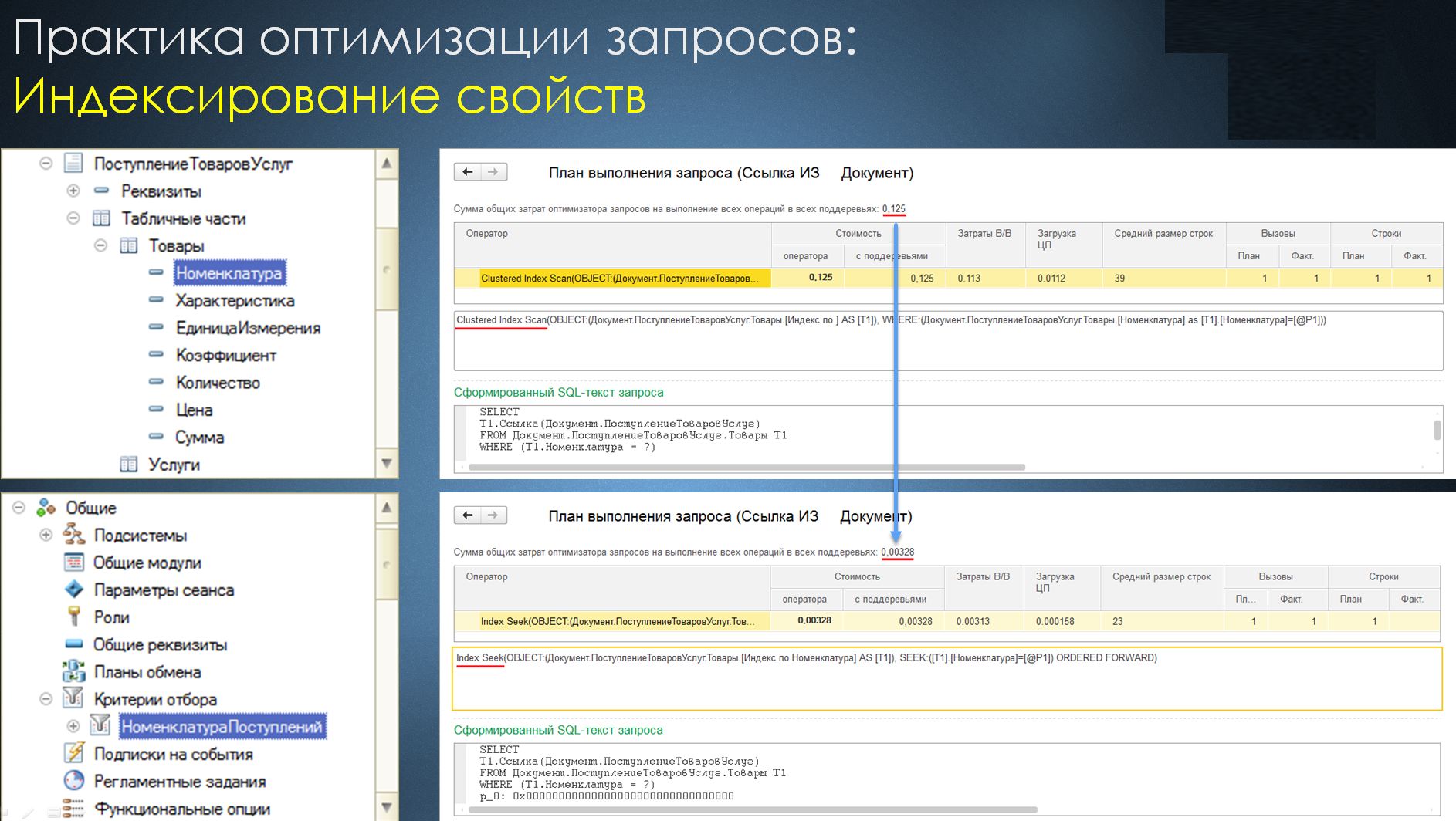
Однако в возможностях, которые предоставлены нам платформой, есть и неявные способы повышения производительности за счет «неявного индексирования» (так я назвал этот способ). Например, если нам необходимо осуществить выборку данных по табличной части документа с отбором по номенклатуре, то в случае, если этот реквизит табличной части не проиндексирован, мы можем получить низкопроизводительный запрос. Поэтому, если мы хотим, чтобы у нас был построен индекс для эффективной выборки данных с отбором по этому полю, мы можем воспользоваться способом «неявного индексирования» – добавить критерий отбора. При этом мы получим необходимый индекс для такой выборки, не усложняя себе работу по обновлению текущей конфигурации в дальнейшем.
И опять же, эта теория описана на ИТС.
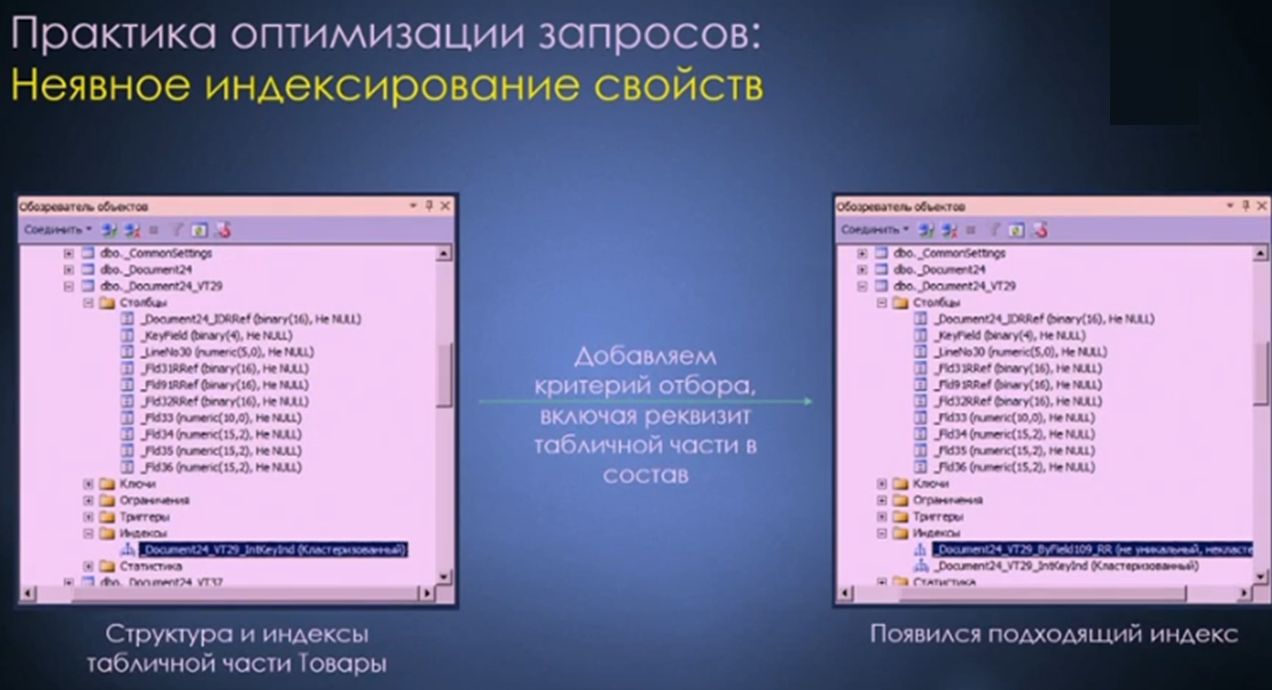
Что происходит при добавлении критерия отбора на стороне СУБД, вы, наверное, знаете: создается дополнительный подходящий покрывающий индекс, необходимый для исполнения нашего запроса. Вот, пожалуйста, он здесь представлен. После добавления критерия отбора мы получаем некластеризованный индекс, который может эффективно использоваться для выполнения нашей конкретной задачи.
Неправильное использование критерия отбора

Однако при использовании критерия отбора для выборки определенных номенклатурных позиций из документов различных видов мы не получим той эффективности, которую можем получить, используя аналогичное по функциональности, но более объемное по написанию объединение запросов. Это связано с тем, что в первом случае физически на стороне СУБД будет сформирован гораздо более сложный запрос, чем во втором случае. Как вы здесь видите, запрос с объединением работает более эффективно, чем использование критерия отбора.

Соответственно, прямое использование критерия отбора для извлечения данных в запросе является неэффективным способом, но сам критерий при этом не является бесполезным, его главная роль в том, чтобы организовать соответствующий некластеризованный индекс на стороне СУБД. В частности, на данном слайде хорошо видно, что удаление критерия отбора приводит к значительному замедлению запроса.
Это – те основные моменты, которые мы можем отметить в процессе оптимизации тех или иных запросов. И эта методика, как я уже говорил, описана в открытом источнике на ИТС. В частности, там есть информация о том, как можно, используя критерии отбора, получить нужный индекс, не меняя типовую конфигурацию.
Как правильно оптимизировать запросы?

Я пришел к выводу, что для того, чтобы правильно оптимизировать запросы, необходимо и достаточно использовать 8 пунктов, которые представлены здесь на слайде.
- Самое главное, на что хотелось бы обратить внимание, это то, что прежде чем приступить к оптимизации того или иного запроса, необходимо выяснить, как часто он выполняется и нужно ли его вообще оптимизировать. Если запрос исполняется один раз в три года, то смысл в такой оптимизации отпадает.
- Также я хочу отметить самую распространенную, на мой взгляд, причину неоптимальной работы запросов – это получение «лишних» данных. Иногда достаточно всего лишь «отсечь» ненужные источники, чтобы запрос «полетел». Отбросить лишнее, на мой взгляд, является самым первым, что вам необходимо выполнить. Соответственно, я отметил это в начальных пунктах данного порядка оптимизации запросов.
- Кроме этого, очень важно правильно оценить:
- Стоимость исполнения запроса,
- Затраты ввода/вывода,
- А также затраты процессора на исполнение данной операции на стороне СУБД.
Для этого у нас есть специальная обработка «Консоль запросов для управляемого приложения 8.3», позволяющая при использовании сервера MS SQL визуально увидеть план запроса, затраты, понесенные на его исполнение, и пр.
- Ну и, безусловно, не забывайте оптимизировать систему в тех же условиях, в которых она и работает.
Продукт для интерактивного изучения методов оптимизации запросов
Как вы видите, вся статья связана с демонстрацией практических результатов, которые я получил в процессе переписывания неоптимальных запросов. Но как научиться оптимизировать запросы, если нет подходящих инструментов? Размышляя над этим, мы решили создать продукт«Интерактивное изучение методов оптимизации запросов».
Это решение выложено на Инфостарте, есть даже бесплатный вариант, вы можете его использовать и получить эти навыки.
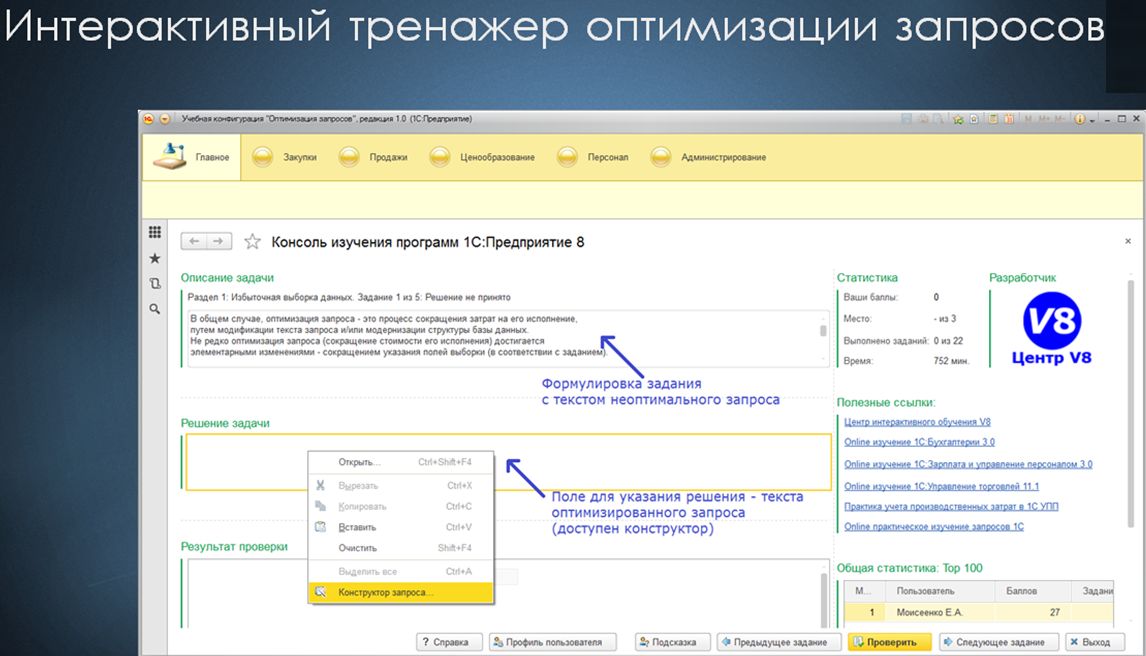
Система работает в интерактивном режиме. Что это значит? Вы открываете специальную информационную базу, в рамках которойзапускается обработка «Консоль изучения программ 1С:Предприятие», взаимодействующая с нашим интерактивным сервисом. В этой обработке представлено задание, содержащее запрос, требующий оптимизации. И ваша задача – переписать этот запрос вручную или с использованием конструктора запросов.
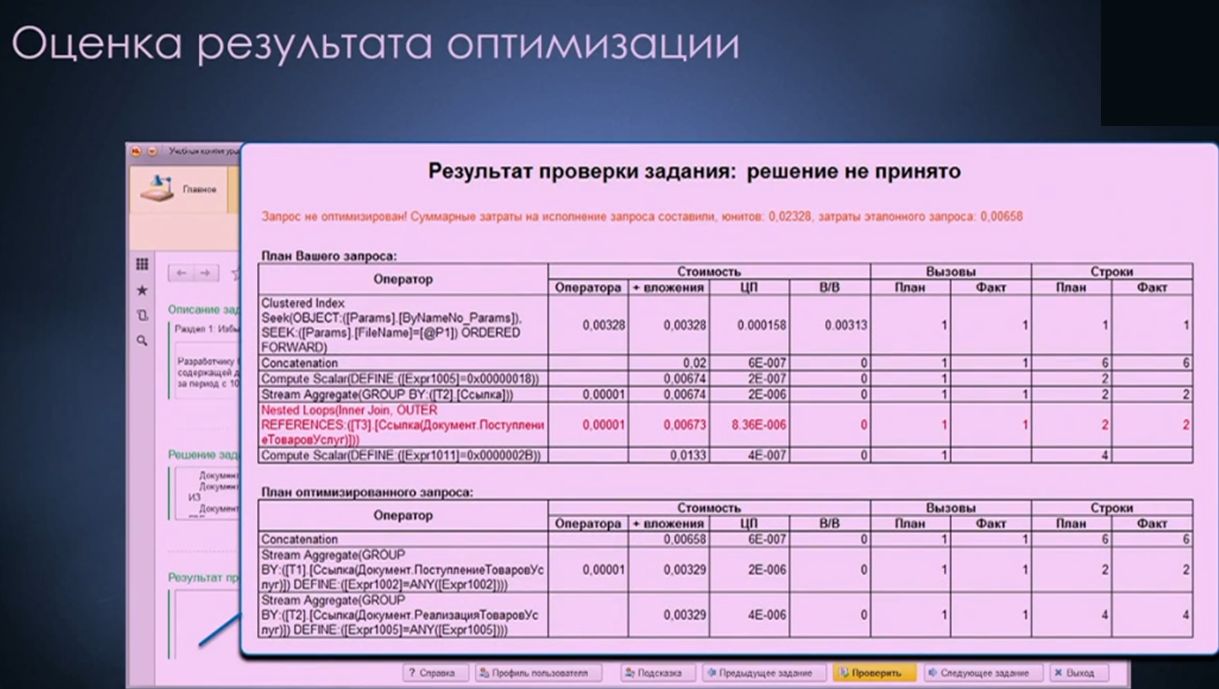
После проверки вашего решения (для этого есть специальная кнопка «Проверка») вы получаете оценку исполнения вашего запроса (производится сравнение времени исполнения вашего запроса и эталонного, текст которого вам изначально недоступен). Если ваши затраты меньше или равны затратам на исполнение эталонного запроса, ваш запрос является эффективно оптимизированным.
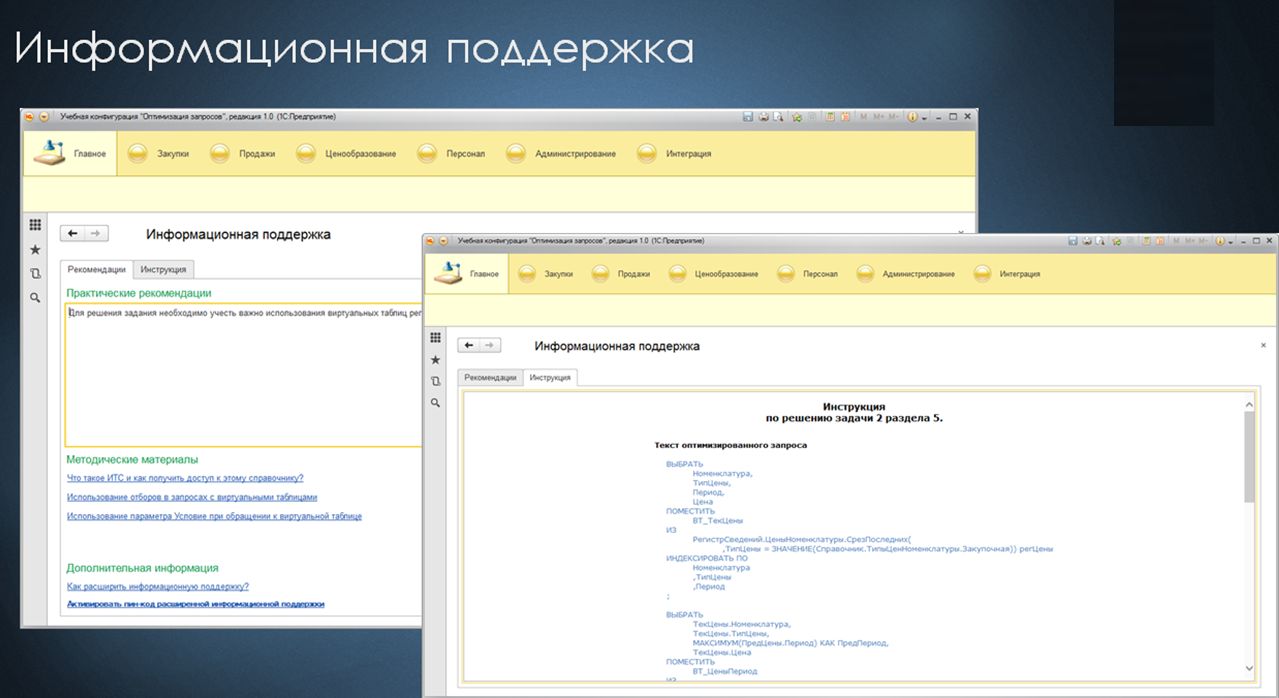
Если у вас возникают какие-либо сложности, вы всегда можете обратиться к информационной поддержке:
- Представлены ссылки на краткие рекомендации методистов;
- На материалы сервиса «Статьи ИТС»;
- И, безусловно, дана сама инструкция, которая содержит текст эталонного запроса. Вы можете использовать этот эталонный запрос, пройти задание и увидеть, в чем же была разница между вашим запросом и оптимизированным.
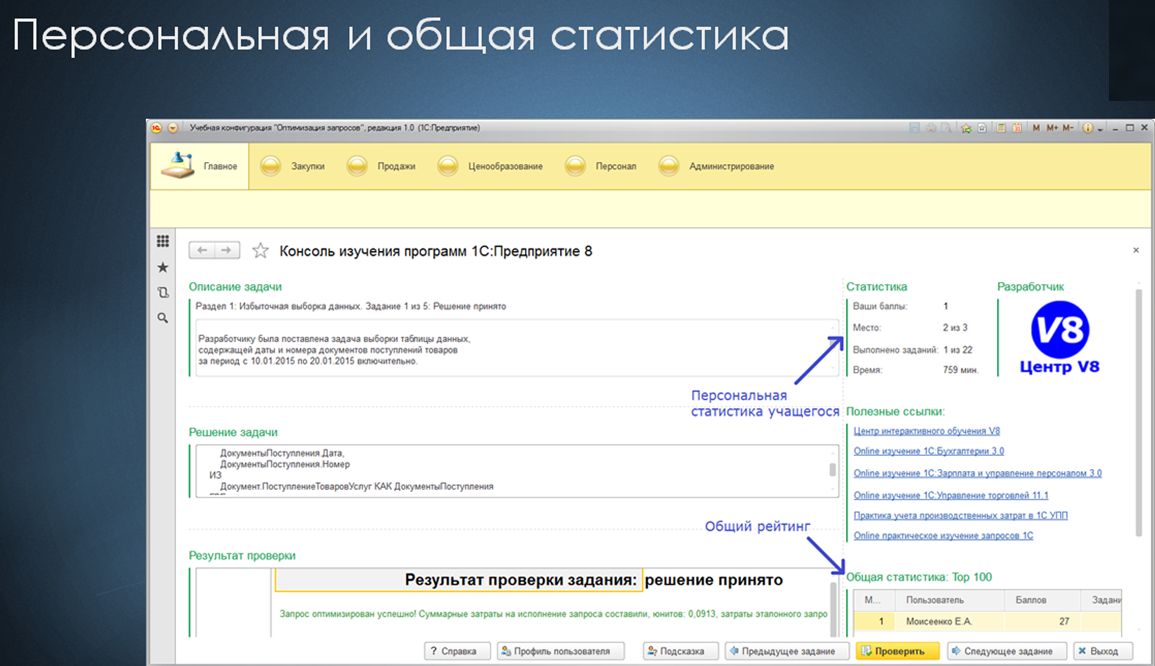
В процессе прохождения заданий система строит статистику. Это – такой дополнительный бонус, который мотивирует людей к более эффективной работе с данным решением. Если вы используете подсказку, то количество баллов, начисляемое вам за решение задания, уменьшается. Но пока вы не решите текущего задания, перейти к следующему невозможно. Это практика всех наших образовательных программ.
Решение опубликовано на сайте Инфостарт – //infostart.ru/public/374023/ .
Архитектура корпоративной системы интерактивного обучения
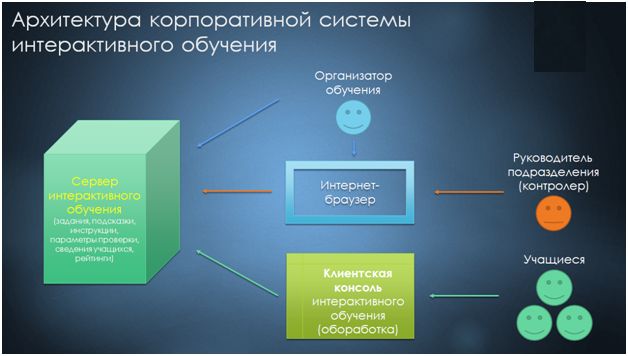
Хочу отметить важный момент: мы создали специальную возможность организации интерактивного обучения для корпоративных клиентов, которая позволяет, используя нашу технологию, организовать сервер интерактивного обучения, содержащий ваши задания для подготовки специалистов согласно вашим программам аттестации для ваших конфигураций.
Порядок работы с сервером интерактивного обучения следующий:
- Организатор обучения направляет учащимся приглашения к исполнению заданий или прохождению аттестации.
- Руководитель подразделений, используя интернет-браузер или прямое подключение к информационной базе сервера интерактивного обучения, отслеживает результат. Для предоставления веб-страницы результата используется http-сервис.
- Учащиеся получают доступ к заданиям посредством запуска обработки «Консоль изучения программ». Ее технология основана на использовании веб-сервисов – она очень легкая, не требующая каких-то мега-соединений, ресурсов и прочего. На нашем проекте мы видели одновременное использование сервиса количеством человек свыше 1000.
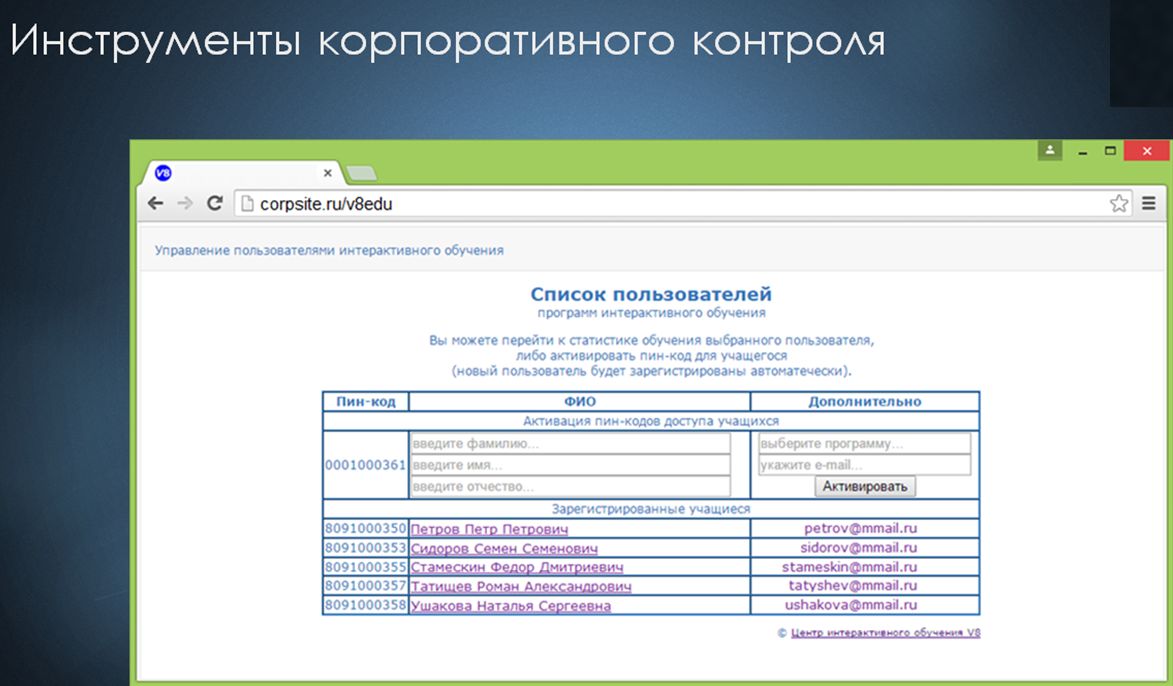
Вот пример той статистики, которую видит руководитель подразделения. Статистика генерируется http-сервисом «Сервер интерактивного обучения».
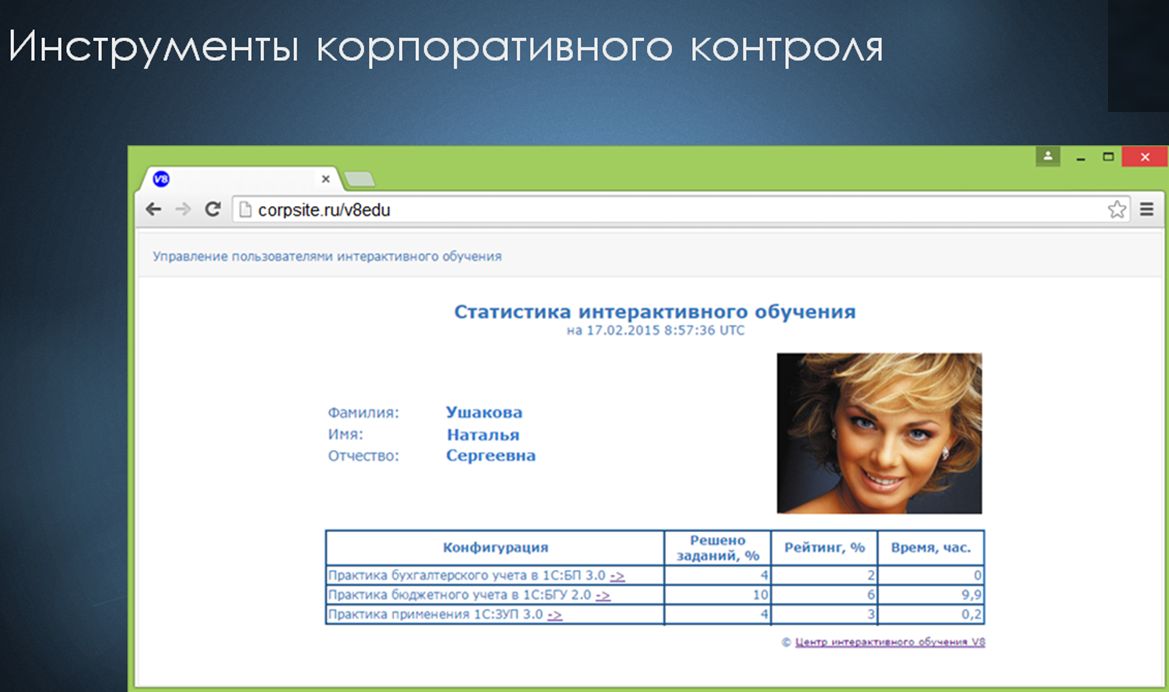
Это позволяет видеть информацию о том, какой из сотрудников по каким образовательным программам получил те или иные результаты. Также есть возможность получить более детальную информацию по каждой образовательной программе.
****************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2015 CONNECTION 15-17 октября 2015 года.
Приглашаем вас на новую конференцию INFOSTART EVENT 2019 INCEPTION.