В Amplitude наша цель — предоставить простую в использовании интерактивную аналитику продуктов, чтобы каждый мог найти ответы на свои вопросы о продукте. Чтобы обеспечить удобство работы, Amplitude должен быстро предоставить эти ответы. Поэтому, когда один из наших клиентов пожаловался на то, сколько времени потребовалось для загрузки раскрывающегося списка свойств события в пользовательском интерфейсе Amplitude, мы приступили к детальному изучению проблемы.
Отслеживая задержку на разных уровнях, мы поняли, что одному конкретному запросу PostgreSQL потребовалось 20 секунд для завершения. Для нас это стало неожиданностью, так как обе таблицы имеют индексы в соединяемом столбце.

Медленный запрос
План выполнения PostgreSQL для этого запроса был для нас неожиданным. Несмотря на то, что в обеих таблицах есть индексы, PostgreSQL решил выполнить Hash Join с последовательным сканированием большой таблицы. Последовательное сканирование большой таблицы занимало большую часть времени запроса.

План выполнения медленого запроса
Я изначально подозревал, что это может быть из-за фрагментации. Но после проверки данных я понял, что в эту таблицу данные только добавляются и практически не удаляются оттуда. Так как очистка места с помощью VACUUM здесь не очень поможет, я начал копать дальше. Затем я попробовал этот же запрос на другом клиенте с хорошим временем ответа. К моему удивлению, план выполнения запроса выглядел совершенно иначе!

План выполнения того же запроса на другом клиенте
Интересно, что приложение A получило доступ только к 10 раз большему количеству данных, чем приложение B, но время отклика было в 3000 раз больше.
Чтобы увидеть альтернативные планы запросов PostgreSQL, я отключил хеш-соединение и перезапустил запрос.

Альтернативный план выполнения для медленного запроса
Ну вот! Тот же запрос завершается в 50 раз быстрее при использовании вложенного цикла вместо хэш-соединения. Итак, почему PostgreSQL выбрал худший план для приложения A?
При более тщательном рассмотрении предполагаемой стоимости и фактического времени выполнения для обоих планов предполагаемые соотношения стоимости и фактического времени выполнения были очень разными. Основным виновником этого несоответствия была оценка стоимости последовательного сканирования. PostgreSQL подсчитал, что последовательное сканирование было бы лучше, чем 4000+ сканирований индекса, но в действительности сканирование индекса было в 50 раз быстрее.
Это привело меня к параметрам конфигурации random_page_cost и seq_page_cost. Значения PostgreSQL по умолчанию 4 и 1 для random_page_cost, seq_page_cost, которые настроены для HDD, где произвольный доступ к диску дороже, чем последовательный доступ. Однако эти затраты были неточными для нашего развертывания с использованием тома gp2 EBS, которые являются твердотельными накопителями. Для нашего развертывания случайный и последовательный доступ практически одинаков.
Я изменил значение random_page_cost на 1 и повторил запрос. На этот раз PostgreSQL использовал Nested Loop, и запрос выполнялся в 50 раз быстрее. После изменения мы также заметили значительное снижение максимального времени отклика от PostgreSQL.
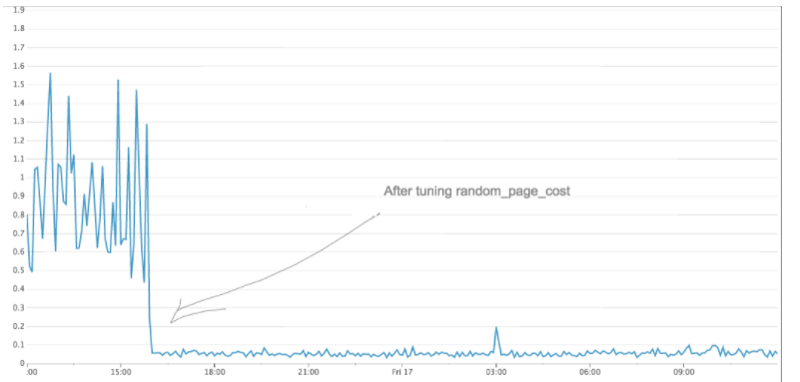
Общая производительность медленного запроса значительно улучшилась
Если вы используете SSD и используете PostgreSQL с конфигурацией по умолчанию, я советую вам попробовать настроить random_page_cost и seq_page_cost. Вы можете быть удивлены сильным улучшением производительности.
От себя добавлю, что я выставил минимальные параметры seq_page_cost = random_page_cost = 0.1, чтобы отдать приоритет данным в памяти (кэш) над процессорными операциями, так как у меня выделено большое количество ОЗУ для PostgreSQL (размер ОЗУ превышает размер базы на диске)
Вступайте в нашу телеграмм-группу Инфостарт
