Задача. Выбрать все записи из регистра по заказу.
На первый взгляд это тривиальная задача с простым запросом
ВЫБРАТЬ
ВыручкаИСебестоимостьПродаж.АналитикаУчетаНоменклатуры КАК АналитикаУчетаНоменклатуры,
ВыручкаИСебестоимостьПродаж.Количество КАК Количество
ИЗ
РегистрНакопления.ВыручкаИСебестоимостьПродаж КАК ВыручкаИСебестоимостьПродаж
ГДЕ
ВыручкаИСебестоимостьПродаж.ЗаказКлиента = &ЗаказКлиента
Но, когда начинаем разбирать план запроса, видим, что наш запрос выполняет полное сканирование таблицы и отбирает всего две записи.

Необходимо избавиться от сканирования (операция Index Scan), а «попасть» в индекс и получить на выходе операцию Index Seek. Т.к. операция поиска в индексе менее затратная по ресурсам и времени.
1) Определим, какие у нас есть индексы (https://its.1c.ru/db/metod8dev/content/1590/hdoc)

2) Смотрим структуру регистра

Для того, чтобы у нас был индекс по измерению, это п3 из таблицы п1, нам необходимо, чтобы измерение было проиндексировано. Можно установить признак индексировать, и тогда задача будет решена, но регистр типовой и, к примеру, нам запрещено снимать с поддержки типовые объекты. Тогда мы снова обращаемся к таблице с индексами и видим, что можно использовать индекс по регистратору, и наша задача сводится к тому, чтобы найти регистраторы по заказу и только потом выбрать эти записи.
ВЫБРАТЬ
РеализацияТоваровУслуг.Ссылка КАК Ссылка
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ
Документ.РеализацияТоваровУслуг КАК РеализацияТоваровУслуг
ГДЕ
РеализацияТоваровУслуг.ЗаказКлиента = &ЗаказКлиента
ИНДЕКСИРОВАТЬ ПО
Ссылка
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
ВыручкаИСебестоимостьПродаж.АналитикаУчетаНоменклатуры КАК АналитикаУчетаНоменклатуры,
ВыручкаИСебестоимостьПродаж.Количество КАК Количество
ИЗ
РегистрНакопления.ВыручкаИСебестоимостьПродаж КАК ВыручкаИСебестоимостьПродаж
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ВременнаяТаблица КАК ВременнаяТаблица
ПО (ВыручкаИСебестоимостьПродаж.Регистратор = ВременнаяТаблица.Ссылка)
Просмотрим план запроса, который значительно увеличился
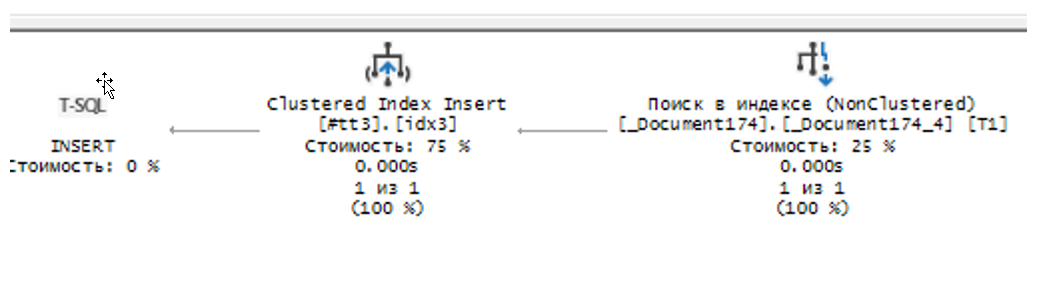
Разберем сам план. Первый запрос — это помещение во временную таблицу документов реализации с отбором по нашему заказу.
Видим, что так же используется поиск в индексе. Почему происходит поиск в индексе, если в типовом решении данное поле не индексировано у документа ?
Снова обращаемся к статье про индексы объектов
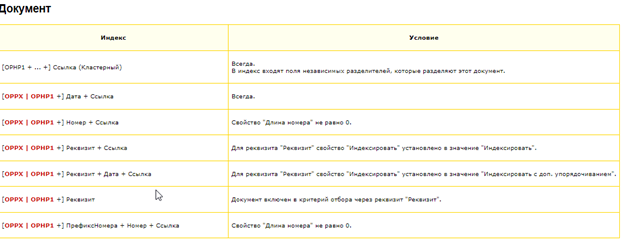
Нам подходит индекс либо реквизит, если оно индексировано, но это не наш случай, либо критерий отбора. Смотрим типовые критерии отбора

И видим, что есть отбор по Заказу клиента --> план запроса будет использовать этот индекс.
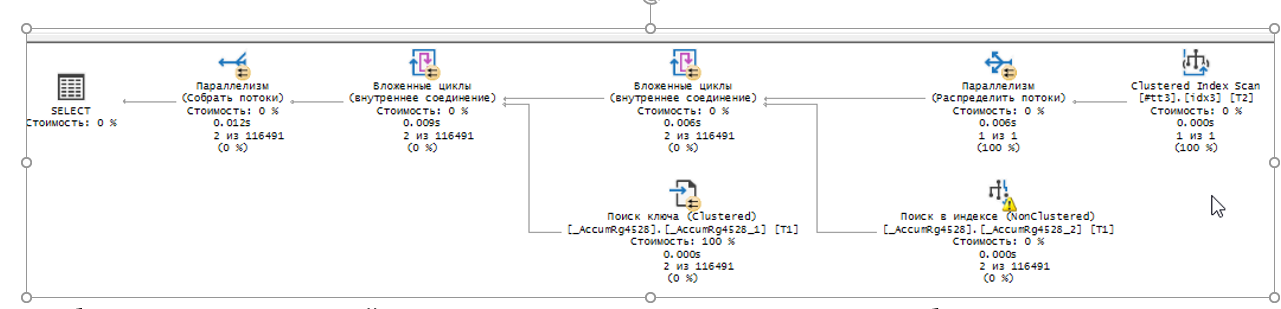
Переходим к анализу второго плана запроса. Разобьем его на части.
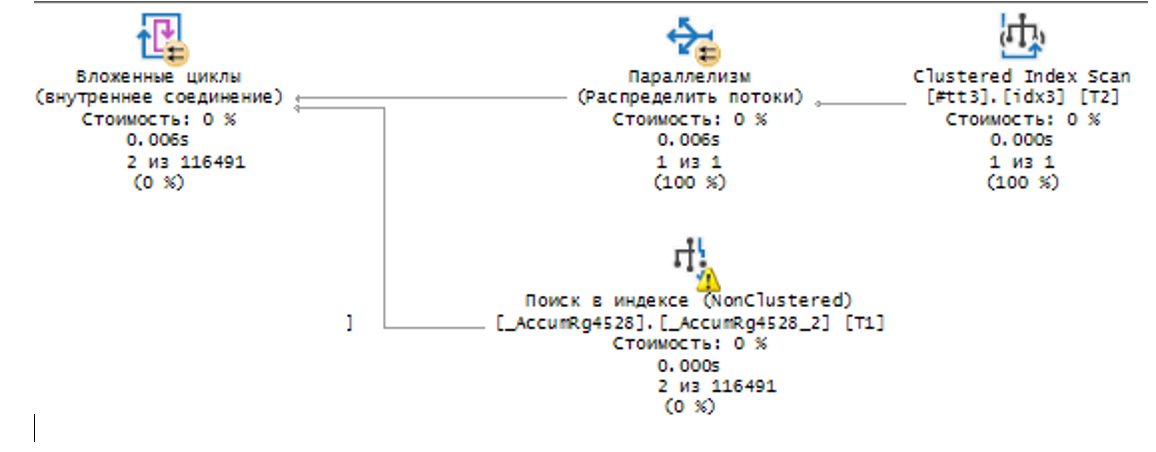
В данной итерации происходит перебор строк из нашей временной таблицы запроса 1 и поиск этой записи в индексе.

Мы добились того, что происходит не перебор всех записей, а именно обращение к записи по индексу.
На этом этапе мы уже выиграли более чем в два с половиной раза процессорного времени.
При изначальном запросе у нас предполагаемая стоимость ЦП = 0,32, сейчас 0,12 остальными итерациями можно пренебречь в плане запроса, т.к. их стоимость < 0,0001
А зачем нам вторая часть запроса?
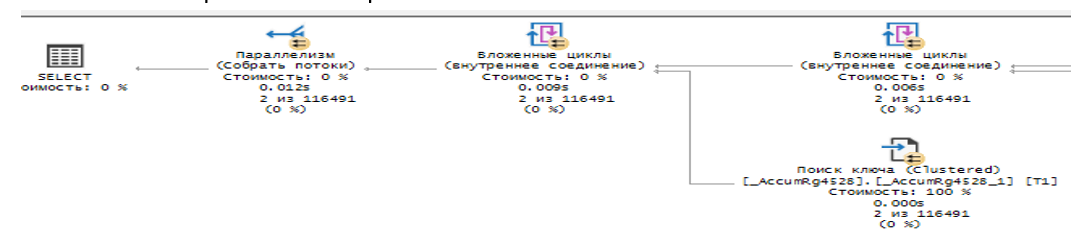
В ней происходит перебор строк нашего соединения, описанного выше, и поиск в кластерном индексе, также поиск происходит не перебором строк, а поиск по индексу. Это необходимо для того, чтобы получить количество ВыручкаИСебестоимостьПродаж.Количество КАК Количество, т.к наш индекс ничего не знает об этом поле, нам это значение необходимо получить из кластерного индекса.

На очень простом и маленьком примере мы смогли облегчить жизнь процессору СУБД более чем в 2,5 раза.
Вступайте в нашу телеграмм-группу Инфостарт