ПАРСИНГ САЙТОВ НА 1С
Всем добрый промежуток времени между задачами! Вот и мне прилетела задачка с просьбой вытащить с вышеуказанного сайта данные о ломбардах. Поначалу задача показалась мне крайне тривиальной, но, как оказалось, за пятнадцать минут ее не решить, а в вылезших на поверхность мелочах скрывалось десяток различных демонов. Полагаю, что демонов этих вполне хватит на статью, которая, надеюсь, будет интересна местным (и не только) читателям.
ВВЕДЕНИЕ
Обычно для парсинга сайта нужно просто взять страницу и найти на ней определенные теги. Совсем юные дарования просто читают строки одну за другой и проверяют их на наличие какой-то комбинации символов, после которой они ожидают увидеть те или иные полезные данные. Более взрослые товарищи используют для этого XPath.
Мне пришлось использовать следующие объекты: ЧтениеJSON, ЧтениеXML, HTTPСоединение и HTTPЗапрос ну и ПостроительDOM, с помощью которого мы будем парсить через XPath.
Но давайте по-порядку.
С ЧЕГО НАЧАТЬ?
Современный сайт - это не просто сгенерированная чем-то веб-страница - это веб-приложение с AJAX и прочими динамическими штучками. Для того, чтобы начать, нужно определиться, что перед нами за сайт и как он хранит данные.
Самое простое - это посмотреть код сайта, который пришел с сервера и отобразился у нас в виде веб-страницы. Если посмотреть на указанный сайт, то видно, что список интересующей нас информации не отдается весь целиком. Но давайте разберем все предельно подробно.
Итак, загрузив сайт ломбарды.рф мы видим следующую картину:

Здесь мы видим, что нам доступна только маленькая часть списка. За остальными нужно лезть через "Еще результаты".

Если мы посмотрим код, то по этой кнопке дергается сервис (data-url="/lombards/load_more.php?category=&sort=&minloan=&maxloan=&region="). Если мы откроем в браузере эту ссылку, то увидим вот такую интересную штуку:
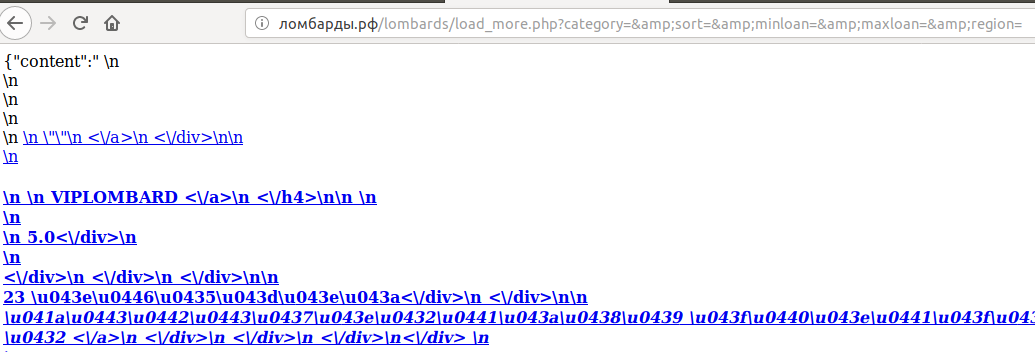
Как подсказывает нам ({"content":" \n) в начале строки - это JSON. 1С умеет его читать, поэтому давайте начнем с простого - создадим HTTP-запрос и обработаем ответ.
СОЗДАНИЕ HTTP-СОЕДИНЕНИЯ, ВЫЗОВ ЗАПРОСА И ОБРАБОТКА ОТВЕТА
Для создания HTTP-соединения и запроса в 1С есть простые объекты, которые прямо так и называются:
С = Новый HTTPСоединение(Адрес);
З = Новый HTTPЗапрос(Урл);
После того, как мы прочитали JSON и распарсили его, получили такой вот объект:

В объекте есть два поля: content и remaining, в первом находится HTML страницы, а во втором - количество оставшихся элементов.
Давайте попробуем засунуть значение в ДокументDOM, чтобы можно было написать к нему XPath:
П = Новый ПостроительDOM;
Х = Новый ЧтениеXML;
Х.УстановитьСтроку(СС["content"]);
ДОМ = П.Прочитать(Х);
Р = Новый РазыменовательПространствИменDOM(ДОМ);
Результат = ДОМ.ВычислитьВыражениеXPath(".", ДОМ, Р, ТипРезультатаDOMXPath.Любой);
Итак, что тут происходит? Я прочитал JSON в соответствие СС, после чего создал построитель ДОМ, которым прочитал XML из СС["content"]. Но у меня вывалилась первая ошибка:
{ВнешняяОбработка.ЧтениеЛомбардов.Форма.Форма.Форма(20)}: Ошибка при вызове метода контекста (Прочитать)
ДОМ = П.Прочитать(Х);
по причине:
Ошибка разбора XML: - [8,41]
Фатальная ошибка:
Opening and ending tag mismatch: img line 7 and a
Что там у нас в 7-й строке? Тег img, который не закрывается!
<img src="http://xn--80abkzflr3g.xn--p1ai/upload/iblock/74a/74a8c12d4c7acf804a0812b501bd0d5a.jpg" alt="">
Да, мы можем прочитать данные в ДокументHTML вместо DOM, но тогда нам не будет доступен XPath. Также мы не можем просто так взять и поправить все ">" на "/>" - есть такие теги, которые содержат внутренние элементы. Надеюсь Вы теперь понимаете, почему почтенные веб-разработчики просят соблюдать стандарт и не писать "<br>" вместо "<br />" (кстати, не стоит путать стандарт XML и нечто от 1С об именовании переменных).
Благо, что у нас в img всегда есть alt, по которому мы сможем узнать, что тег надо закрыть. Итак, давайте исправим это:
Ст = СтрЗаменить(СС["content"], "alt="""">", "alt="""" />");
Но ничего не вышло:
Ошибка разбора XML: - [39,1]
Фатальная ошибка:
Extra content at the end of the document
Что на этот раз? Тут все просто - 1С не может прочитать неполный документ, т.е. все теги документа должны быть в одном корневом контейнере. Исправить это нетрудно:
Ст = "<main>" + СтрЗаменить(СС["content"], "alt="""">", "alt="""" />") + "</main>";
В итоге при чтении XML в DOM у нас пока больше нет ошибок. На том же PHP у меня нет ошибок сразу - я могу любую ересь в него прочитать и применить к прочитанному XPath. Но это так - лирическое отступление.
XPATH-ВЫРАЖЕНИЯ В 1С
Для того, чтобы применить ограниченный функционал XPath в 1С прежде всего нам нужен ДокументDOM и РазименовывательПространствИменDOM. Если со смыслом первого объекта как-то можно смириться, то вникнуть в смысл второго у меня пока не получается - я просто инициализирую его через документ - и все:
Р = Новый РазыменовательПространствИменDOM(ДОМ);
Результат = ДОМ.ВычислитьВыражениеXPath("//div[@class='item-info']", ДОМ, Р);
В результате мы получим объект с типом "РезультатXPath". Для получения элемента нам нужно просто вызвать его функцию "ПолучитьСледующий()":
Пока Истина Цикл
Узел = Результат.ПолучитьСледующий();
Если Узел = Неопределено Тогда Прервать;
КонецЕсли;
// какой-то полезный код
КонецЦикла;
У нас на странице будет 5 элементов, которые мы получили с помощью запроса "//div[@class='item-info']". Мы выбрали все элементы "div" у которых атрибут "class" равен "item-info".
Итак, мы получили элементы XML, в которых содержатся имена и адреса ломбардов. Можно лазить за ними через всю эту иерархию ДОМ'а, а можно просто применить XPath к указанным узлам. Если посмотреть внимательно на файл, то можно увидеть, что имя ломбарда содержится в div'е с классом "item-info__title", там же и ссылка на страницу с телефоном (в действительности - на ее редирект). А адрес находится в теге "<address>". Давайте напишем для них XPath-выражения:
Результат1 = ДОМ.ВычислитьВыражениеXPath("//div[@class='item-info']", ДОМ, Р);
Пока Истина Цикл
Узел = Результат1.ПолучитьСледующий();
Если Узел = Неопределено Тогда Прервать;
КонецЕсли;
Результат2 = ДОМ.ВычислитьВыражениеXPath("./div[@class='item-info__title']/h4/a/text()", Узел, Р, ТипРезультатаDOMXPath.Строка);
Результат3 = ДОМ.ВычислитьВыражениеXPath("./div[@class='item-info__title']/h4/a/@href", Узел, Р, ТипРезультатаDOMXPath.Строка);
Результат = Результат + "
|ИМЯ: " + Результат2.СтроковоеЗначение + "
|Урл: " + Результат3.СтроковоеЗначение;
КонецЦикла;
В результате мы получим что-то такое:
ИМЯ:
VIPLOMBARD
Урл: /lombards/yuvelirnye/10370
ИМЯ:
Chronoland
Урл: /lombards/yuvelirnye/10374
ИМЯ:
AUTO-PERSPECTIVA
Урл: /lombards/avtomobiley/10442
ИМЯ:
Кредиты Населению Автоломбард
Урл: /lombards/avtomobiley/10443
ИМЯ:
Гольфстрим (Профсоюзная, 127Б)
Урл: /lombards/avtomobiley/10504
Дальше нам придется прочитать данные по ссылке и получить уже из обычного HTML информацию об адресах, телефонах и прочем.
ИТОГ
В ходе парсинга я столкнулся со следующими проблемами:
- Редирект. По указанной в Урл странице находится страница с перманентным редиректом. Взять из нее адрес не составит никакого труда. а определить ее можно по 301-й ошибке в ответе веб-сервера.
- Наличие в комментарии двух минусов подряд ("--"). Такой комментарий ДОМ 1С не читает и вы получите эксепшн. Как бороться? СтрЗаменить - наше все.
- Закрывающийся тег </b> без открывающегося. Просто удалял все <b> и </b>.
- Тег <br> - менял на <br />, но можно просто удалить.
- "&" в текстовых полях - надо менять на "&", иначе 1С такой XML не прочитает.
- Ну и не надо читать весь HTML - начните с <body> и им же заканчивайте (для этого сайта лучше начать и закончить тегом <main> - он там как раз есть).
- Вишенка на торте - скрытый параметр, подставляемый в урл JSON-а, получаемого PHP-скриптом. Найдите его сами - в качестве домашнего задания. Подскажу - можно воспользоваться консолью хрома и запустить сбор данных о производительности - там будут все запросы, а в них, в свою очередь, будут все параметры.
- Удачи!
Вступайте в нашу телеграмм-группу Инфостарт
