Шринк? Что это и зачем?
Шринк (shrink) - это сжатие файлов данных для уменьшения занимаемого ими пространства на диске. Выполняется за счет перемещения страниц данных с конца файла в свободное пространство в начало файла. После этого страницы в конце файла становятся неиспользованными и это пространство может быть возвращено файловой системе.
В стародавние времена считалось нормальным выполнять шринк базы данных. Некоторые администраторы даже настраивали регламентные процедуры для "шринкования" вне рабочего времени. К счастью, такое уже редко где можно увидеть, но случаи еще есть.
Почему шринк не стоит делать регулярно на рабочем окружении? Вот основные причины:
- Сама по себе операция сжатия файла данных очень ресурсоемка и на больших базах может выполняться десятки часов, а то и больше. Также во время ее выполнения пользователи могут, и скорее всего будут, ощущать замедление работы системы.
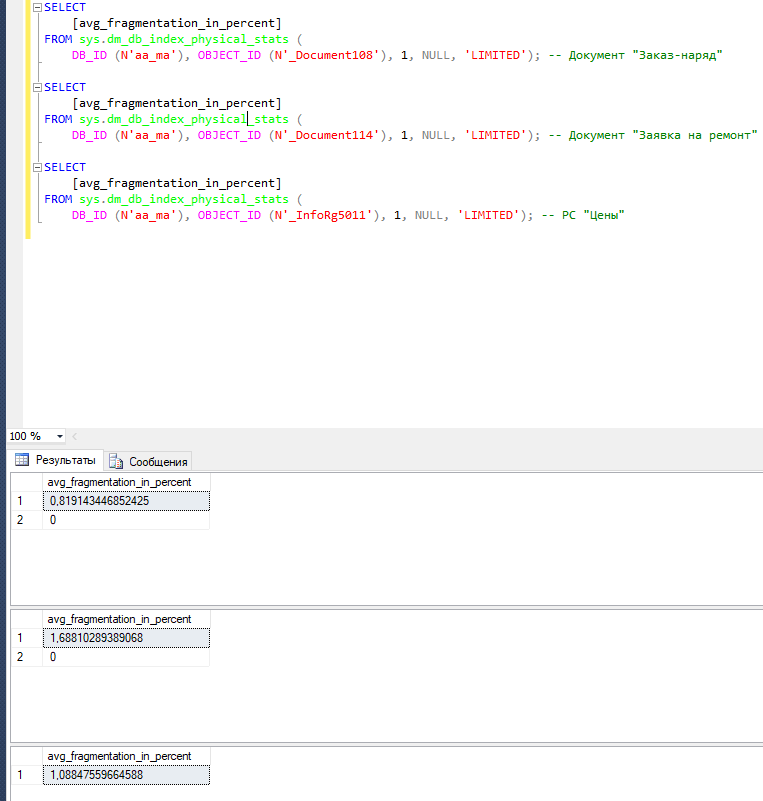
- Значительное снижение эффективности работы индексов. Шринк переносит страницы в начало файла, так он может перенести и индекс. Причем часть его страниц может быть в самом начале файла, другая где-то по середине, а третья вообще разбросана где попало. В итоге фрагментация индекса будет под 99.9%, что значительно снижает производительность. Индексы попросту не могут быть использованы должным образом. Спасти может только перестроение или реорганизация (иногда), но это снова может увеличит размер файла данных. Есть отличная статья об этом от Brent Ozar.
- Появление дополнительных задержек при увеличении файла данных. После шринка база занимает минимальный размер, но если информационная система жива, то новые данные в нее будут поступать снова и снова. Новые данные = нужно больше места. Каждое увеличение файла данных потребует дополнительных ресурсов. Оптимизировать можно уменьшив количество таких операций за счет большего шага автоувеличения файла в настройках базы данных. О влиянии на производительность можно узнать вооооот здесь.

Постойте! Но статья же о быстром шринке! Если сам по себе он так плох, то неужели статью можно уже закончить?
Конечно, нет! Бывают ситуации, когда шринк для базы целесообразен. Замете, целесообразен, но не обязателен!
Вот несколько кейсов, когда его стоит использовать:
- В базе данных произошли серьезные изменения. Например, вы удалили какой-либо исторический регистр из базы 1С, который занимал 100 ГБ. И если эти 100 ГБ важны и их нужно освободить на диске, то от шринка не уйти.
- Вы применили сжатие страниц для таблиц и индексов, что уменьшило размер занимаемых данных на 70%! А файл базы данных на диске не изменился! Снова шринк! Но опять же, если место и правда нужно под что-то освободить, ведь рано или поздно данные в базе смогут занять его снова.
- Вы готовите тестовую базу и удаляете из нее данные, чтобы она не весила 1ТБ. Без шринка тоже никуда, но вопрос производительности может быть неактуальным. Ведь это тестовая среда.
Вообщем, смысл думаю уже понятен.
Классический путь
Стандартный способ выполнить шринк файлов базы данных - воспользоваться такими командами как "SHRINKDATABASE" или "SHRINKFILE". Вот примеры.
-- Первым параметром указываем имя базы данных.
-- Вторым параметром указываем сколько процентов свободного пространства
-- данных мы хотим освободить
DBCC SHRINKDATABASE ('DatabaseName', 10);
или
-- Первым параметром указываем логическое имя файла.
-- Вторым параметром указываем целевой размер
-- для сжатия файла в мегабайтах.
DBCC SHRINKFILE ('LogicalFileName', 100)
Разница между ними заключается лишь в том, что "SHRINKDATABASE" сжимает все файлы данных и журналы транзакций для указанной базы, а "SHRINKFILE" применяет изменения только для указанного файла.
На практике использовать шринк всей базы данных практически никогда не приходится. Да что говорить, если сам шринк - это последнее дело, которое нужно делать, то необходимость применять его для всей базы вообще редкость. В случае если без него не обойтись, то лучше применять его для конкретного файла с помощью второй инструкции.
Также для каждой операции могут быть указаны дополнительные параметры, о который вы можете узнать по ссылкам:"SHRINKDATABASE" или "SHRINKFILE".
Выше мы уже говорили, что сам по себе шринк является болезненной операцией для базы данных как с точки зрения производительности, так и с позиции времени обслуживания. У Вас не должно остаться сомнений по поводу того, что стандартный способ ужать файлы очень неоптимальный и его регулярное применение не имеет никакого смысла.
Ах да, ни в коем случае не ставьте в настройках базы данных включенной опцию "Auto Shrink".
ALTER DATABASE [bsl] SET AUTO_SHRINK OFF WITH NO_WAIT
Все еще сомневаетесь? Прочитайте перевод статьи от разработчика Microsoft, который имел прямое отношение к алгоритму сжатия файлов.
Быстрее, выше, сильнее
Есть и другой способ сжать файл данных, при этом он будет быстрее, т.к. стандартные операции шринка будут использоваться по минимуму.
Речь идет о переносе данных из одной файловой группы в другую, при котором есть два пути:
- Старую файловую группу, из которой данные перемещены, после этого удаляют.
- Если исходную файловую группу удалить нельзя (например, если это группа "PRIMARY"), то ее можно обработать стандартной операцией шринка. В любом случае это будет быстрее, чем использовать стандартное сжатие на исходном файле.
На сколько перемещение данных в новую файловую группу быстрее, чем стандартный шринк? Трудно сказать, т.к это зависит от дисковой подсистемы, где находятся файловые группы, а также от объема BLOB-данных в базе. Как показала практика, чем больше таких данных хранится, тем медленнее выполняется шринк, тем быстрее будет работать сжатие через файловые группы.
На моем опыте использование этого подхода позволяло ускорить сжатие файла данных от 3 до 8 раз, да и последствий для производительности куда меньше.
Как это сделать для баз 1С? Допустим, у нас есть некоторая база "bsl" на инстансе SQL Server и мы решили ее сжать через файловые группы. Т.к. файловая группа по умолчанию только одна, то нужно добавить еще одну дополнительную и файл данных для нее.
-- Добавляем файловую группу
ALTER DATABASE [bsl]
ADD FILEGROUP [FOR_SHRINK]
GO
-- После добавляем новый файл данных для новой файловой группы
ALTER DATABASE [bsl]
ADD FILE (
NAME = N'AfterShrink',
FILENAME = N'F:\DBs\MSSQL14.MSSQLSERVER\MSSQL\DATA\AfterShrink.mdf' ,
SIZE = 8192KB ,
FILEGROWTH = 65536KB )
TO FILEGROUP [FOR_SHRINK]
GO
Теперь с помощью этих скриптов мы можем переместить все таблицы, индексы и даже BLOB-данные в эту файловую группу вот так.
EXEC dbo.sp_MoveTablesToFileGroup
-- Фильтр по имени схемы (LIKE-оператор)
@SchemaFilter = '%',
-- Фильтр по имени таблицы (LIKE-оператор)
@TableFilter = '%',
@DataFileGroup = 'FOR_SHRINK', -- Имя файловой группы назначения (куда переносим)
-- 1 означает "Перенести все кластерные индексы", то есть таблицы, где есть первичный ключ / кластерный индекс
@ClusteredIndexes = 1,
-- 1 означает "Переместить все дополнительные индексы"
@SecondaryIndexes = 1,
-- 1 означает "Перенести все кучи" - то есть таблицы без кластерного индекса.
@Heaps = 1,
-- 1 - значит только сгенерировать скрипт, ничего выполнять не нужно. 0 - сразу выполнить перемещение
@ProduceScript = 0
Скрипт не универсальный, по крайней мере в текущей его версии, и не может перенести таблицы, в которых, например, только одно поле с BLOB-типом. Для баз 1С это таблица "DBSchema" с описанием структуры базы данных, которую автоматически в новую файловую группу переместить нельзя. Для этого нужно выполнить немного ручной работы:
BEGIN TRANSACTION
GO
CREATE TABLE dbo.Tmp_DBSchema
(
SerializedData varbinary(MAX) NOT NULL
) ON FOR_SHRINK
TEXTIMAGE_ON FOR_SHRINK
GO
ALTER TABLE dbo.Tmp_DBSchema SET (LOCK_ESCALATION = TABLE)
GO
IF EXISTS(SELECT * FROM dbo.DBSchema)
EXEC('INSERT INTO dbo.Tmp_DBSchema (SerializedData)
SELECT SerializedData FROM dbo.DBSchema WITH (HOLDLOCK TABLOCKX)')
GO
DROP TABLE dbo.DBSchema
GO
EXECUTE sp_rename N'dbo.Tmp_DBSchema', N'DBSchema', 'OBJECT'
GO
COMMIT
Так как файловую группу "PRIMARY" удалить нельзя, то мы можем ее сжать через стандартный шринк. Это уже будет работать гораздо быстрее, чем выполнение этой операции до переноса данных.
-- Сжимаем файл основной файловой группы 'PRIMARY'
DBCC SHRINKFILE('bsl', 0)
В итоге все данные перемещены в новую файловую группу, что можно проверить с помощью этого скрипта.
По ссылке выше в своей статье Paul S. Randal этот способ рекомендовал использовать вместо стандартного сжатия данных. Так почему бы не прислушаться? Если бы исходную файловую группу можно было бы удалить (если это не "PRIMARY"), то можно было бы сделать следующее.
-- Удаляем все данные из файла перенося их в другие файловые группы
-- Подробнее о параметре смотреть здесь:
-- https://docs.microsoft.com/ru-ru/sql/t-sql/database-console-commands/dbcc-shrinkfile-transact-sql?view=sql-server-2017
DBCC SHRINKFILE ('AfterShrink', EMPTYFILE);
GO
-- Удаляем пустой файл
ALTER DATABASE [bsl] REMOVE FILE [AfterShrink]
GO
-- Удаляем файловую группу
ALTER DATABASE [bsl] REMOVE FILEGROUP [FOR_SHRINK]
GO
В этом случае файл на диске, на котором ранее располагалась исходная файловая группа, был бы сначала освобожден от всех данных, в потом удален. "PRIMARY" удалять нельзя, т.к. она содержит различную служебную информацию о базе, которую также и переместить в другую файловую группу нельзя.
Конечно, у этого способа есть минус - он требует больший объем свободного места на диске, т.к. при перемещении данных исходный файл сразу не уменьшается в размере. Но по сравнению с остальными плюсами и недостатками стандартного шринка - это может быть несущественным.
База в базу
Можно пойти дальше и переносить данные не в новые файловые группы, а в новую базу данных. Довольно радикальный способ, но работоспособный. Можно выделить несколько основных способов перемещения таблиц и индексов между базами:
- Использовать Bulk-операции, как, например, описано здесь.
- Штатный мастер импорта и экспорта данных
- Использовать утилиту "sqlpackage.exe", входящую в состав SQL Server Data Tools.
- Сгенерировать скрипт с помощью SQL Server Managment Studio
- Использовать операцию "INSERT INTO".
Подробнее на этом способе останавливаться не будем. За более подробной информацией и развернутыми примерами Вы можете обратиться к отличной статье о шести различных способах передачи данных между базами для SQL Server.
Вы все еще шринкуете?
На этом все. Думаю, в публикации не открыл особо ничего нового для сообщества, но может хотя бы скрипты пригодятся. Главное помнить - шринку нет места в продакшене! Хватит шринковать! :)
Другие ссылки

DatabaseCompressionTool — сжатие и свертка любой базы 1С
Инструмент DatabaseCompressionTool (DCT) позволяет безопасно сжать и свернуть любую базу 1С, освободив сотни гигабайт и увеличив производительность системы. Доступна демо-версия для оценки эффективности.
Вступайте в нашу телеграмм-группу Инфостарт