



{kind=link}
Время чтения: 4 мин.
Содержание
- История первая: о потерянном процессорном времени.
- История вторая: о снижении количества ошибок.
- История третья: о том что мы точно знаем когда не работали внешние сервисы поставщиков услуг.
- История четвертая: о редких ошибках поставщиков сервисов.
- Что дальше?
- Итоги
История первая: о потерянном процессорном времени.
Развернули мы, значит, Elastic search с Kibana и подумали на что можно натравить ее для начала. Выбрали базу-кролика, ей оказалась база для сервис-деска. Собрали статистику журнала регистрации. И меня смутил большой объем повторяющихся каждые 10 минут транзакций. Начал разбираться, оказалось что выполняется абсолютно ненужное регламентное задание, которое перезаписывает абсолютно ненужный реквизит в тысяче заявок каждые 10 минут! Оставим архитектуру решения на совести разработчиков этого программного продукта. Выключив регламент мы, хоть и немного, но снизили нагрузку на наши сервера. Слава Kibana!

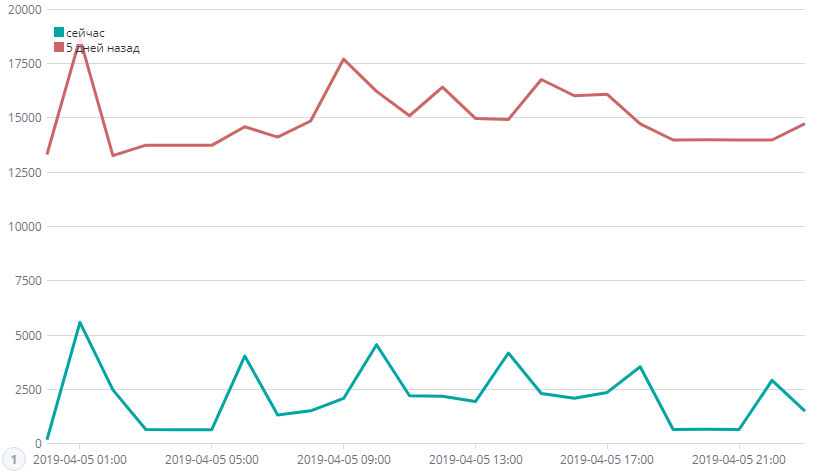
На графике видно, что все еще остались массовые обработки, но это нужные транзакции. Ужасная архитектура этого ПО для сервис-деска, конечно…
История вторая: о снижении количества ошибок.
Дальше анализировать базу сервис-деска стало неинтересно: аномалий выявлено не было, выгрузка в Elastic работала хорошо и не нагружала базу. Настало время заняться серьезными делами и я натравил обработку выгрузки ЖР на нашу самую основную и рабочую базу.
Что мне было интересно изначально: статистика по количеству и видам ошибок, которые бывают у нас в программе, количество транзакций по пользователям, количество ошибок по пользователям и все вот это вот.
Увидев количество ошибок, я немного опешил, но, взяв себя в руки, начал разбираться. Без систематического анализа ЖР никто и никогда не знает о том что происходит в программе, на чем она спотыкается, о чем молчат пользователи. А так как ЖР анализировать стандартными средствами смерти подобно, то никто и никогда стандартными средствами этого не делает, кроме мазохистов, их в расчет не берём.
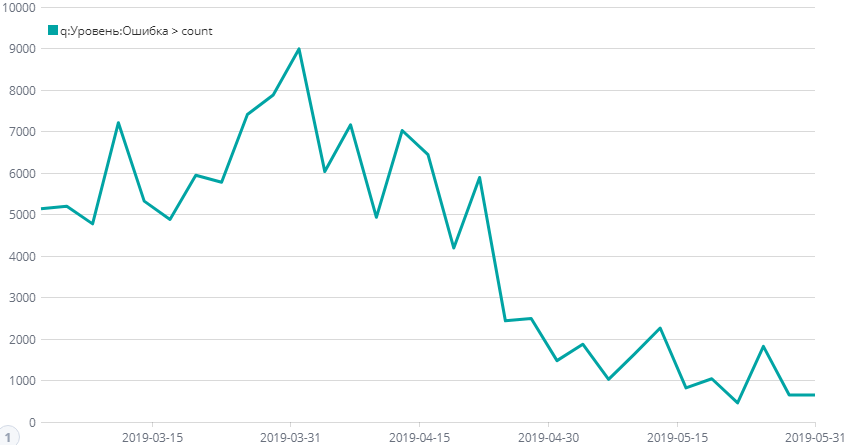
Итак, фильтр по ошибкам показал что ошибок много и самое приятное, что примерно 60% ошибок генерит один тип. Ошибка, которую ребята все никак не брались исправить, т.к. ну очень много нужно было переделывать. Переделали, снизили количество. Следующая массовая ошибка, переделали. Следующая массовая ошибка, переделали. Вот примерный график снижения ошибок. Почему ошибки ещё есть спросите вы? А про это история под номером три.

На графике динамика снижения количества ошибок в нашей системе.
История третья: о том что мы точно знаем когда не работали внешние сервисы поставщиков услуг.
Цель была минимизировать количество ошибок и своевременно реагировать на новые всплески. В результате, пришли к тому, что основной поток ошибок стали генерировать внешние поставщики услуг, когда их сервисы лежат.
Например, сервис проверки ИНН в типовой бухгалтерии или сервис одного известного оператора ЭДО. И есть ещё один классный цифровой продукт, который выключается как по расписанию в 20.30, как будто рубильник у них там кто-то дёргает. Прикольно, че. Только вот перфекционист во мне рыдает, когда я вижу огромное количество ошибок и хочу это все поправить, но не могу! Боль.

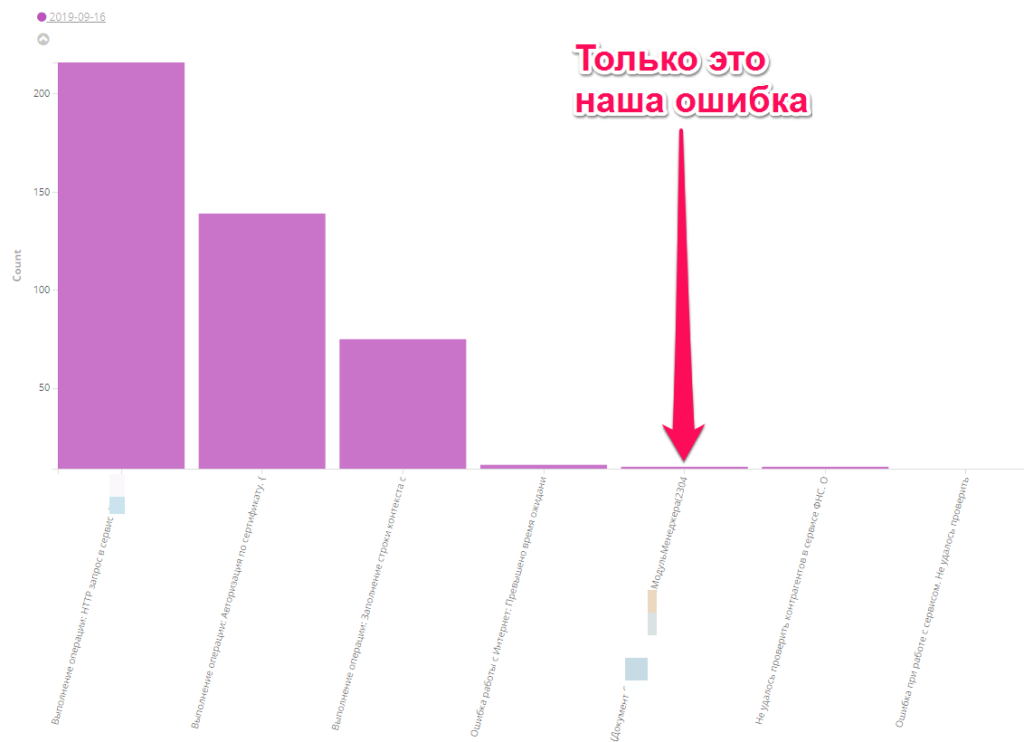
Вот график, на котором за один день 16.09.2019 выбраны все ошибки из журнала регистрации. Всего ошибок 602. Наша ошибка одного типа и всего 10 событий. Это успех.
История четвертая: о редких ошибках поставщиков сервисов.
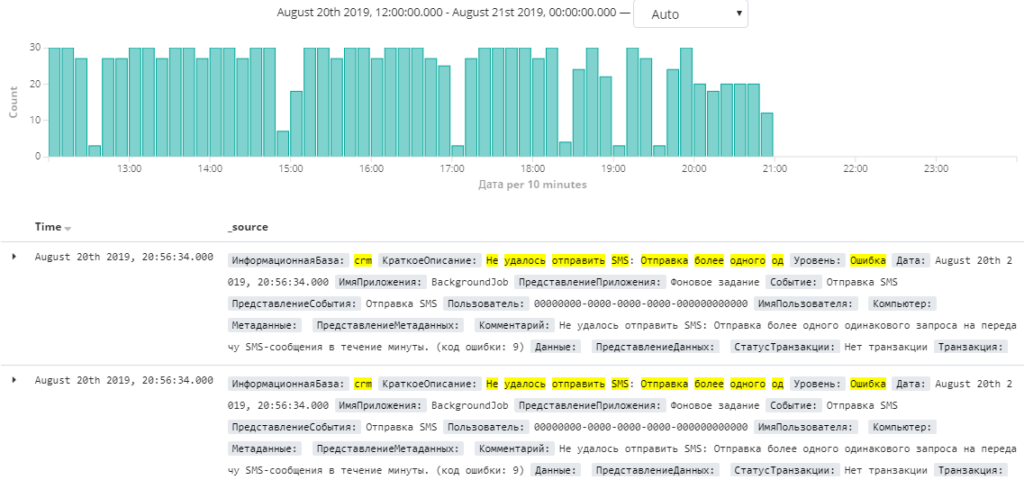
Отправляли мы смски через один из сервисов. Все казалось нам хорошо, пока мы не начали анализировать журнал регистрации. Оказалось, что некоторые номера этот сервис не проглатывал и в тестовых условиях воспроизвести такое просто было невозможно. Самое прекрасное: после нескольких попыток этот сервис отключался на некоторое время. Ошибку нашли и заботливо исправили. Слава Kibana!

На графике видно блокировку при многократной отправке одинаковых неправильных запросов.
Что дальше?
Сейчас мониторинг происходит все же несистемно. Захожу я или мои ребята и смотрим как дела. Что мне хочется получить в итоге? Мониторинг, который не будет зависеть от человека. В этом мне поможет ElastAlert.
Каждый раз, когда количество определенного типа ошибок за определенное время пробивает дно потолок и начинается неприятный такой сквозняк, то наш ElastAlert будет самоотверженно создавать инцидент в системе сервис-деска и бравые программисты будут фиксить ошибки. Или даже когда будет наблюдаться тренд на рост количества ошибок, то тоже будет создан тикет на анализ проблемы.
Таким образом будет обеспечен системный мониторинг: ошибок станет меньше, пользователи станут счастливее.
И ещё одна идея: воспользоваться мощными возможностями Microsoft Power BI для более глубокого анализа журнала регистрации, но для этого нужно оплачивать сервис, а ROI всего этого пока непонятен.
И ещё одна идея: засунуть туда логи технологического журнала, ведь что там происходит мы узнаем только при анализе проблем производительности. А вдруг там есть что-то подобное первой истории?
Итоги
Резюмируя вышесказанное: Elastic search и Kibana действительно классные продукты и действительно помогают решать проблемы анализа журнала регистрации. Не только в теории, но и на практике.
Всем спасибо за внимание!
Вступайте в нашу телеграмм-группу Инфостарт